











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
I. Introduction
FOOD security has become a pressing challenge due to rapid population growth, climate change, and water scarcity, especially in developing countries [1]. Globally, modifications and adaptations are made through agricultural practices to improve soil fertility and mediate climatic changes; therefore, the environmental impacts of agriculture must be evaluated in terms of water, nutrients (soil), and atmospheric components [2]. National and departmental government entities support emergent agricultural endeavors that provide a good opportunity to increase levels of production and commercialization of products [3].
Avocado (Persea americana Mill) of the Hass variety is the most common commercial avocado crop in the world due to its contents of essential nutrients and important phytochemicals [4]. This fruit is grown in Colombia, where the Hassavocado production system has expanded in recent years due to excellent economic opportunities and the high unmet domestic demand [5]. Departments in which Hass avocados are cultivated include Tolima, Antioquia, Caldas, Santander, Bolívar, Quindío, Cesar, Valle del Cauca, Risaralda and Cundinamarca [6]; in Risaralda, avocado is grown in 13 of the 14 municipalities. To address problems associated with avocado cultivation, approaches from information and communication technologies (ICT) are adopted, such as precision agriculture and crop data collection in real time [7]. Relevant topics in ICT for the agricultural sector include procedures for digital management of geographic information about crops, decision-making systems for mechanization of processes based on georeferencing, and information systems used for epidemiological early warnings [7] [ 8].
However, difficulties have been observed in managing Hass avocado given the variability in the edaphoclimatic conditions of the department, which has effects such as heterogeneity of fruit quality. In addition, the lack of scientific work limits the understanding of the specificities of cultivation in the region. This study proposes the development of a model to determine the current and potential cultivation areas for avocado (Persea americana Mill) var. Hass in the department of Risaralda based on edaphoclimatic and fruit quality variables using current trends in precision agriculture and machine learning. The results contribute to technological developments in the agricultural sector, with the department's Hass avocado growers being beneficiaries.
II. Background
Machine learning (ML) is an important decision-support tool in fields such as crop yield prediction, and it can support decisions about which agricultural products to grow and what to do during the growing season of crops. Therefore, several machine learning algorithms have been applied to support research aimed at predicting or estimating crop yield, where the most commonly used characteristics are temperature, precipitation, and soil type [9]. In this sense, the different applications of the data obtained from the soil, such as the selection of a dataset for training as well as the selection of soil environmental covariates, could boost the precision of machine learning techniques [10].
One of the instruments used within machine learning is crop-oriented recommendation systems. Based on the variables provided within these systems, a model is created that predicts or suggests which crop can be grown. The models use historical data, such as climatic data (temperature, humidity, pH, and precipitation) and fertilizer application (nitrogen, potassium, and phosphorus) [11]. The application of machine learning techniques supports processes associated with data analysis [12]. In [13], it is mentioned that different artificial intelligence techniques have been proposed. Among those techniques that have been integrated into precision agriculture, more specifically into the field of crop recommendation systems, algorithms such as k nearest neighbors (KNN), similarity-based models, ensemble-based models, and neural networks take into account various characteristics that are external in nature, such as meteorological data and the soil profile, to provide the best recommendations. The most important attributes of the data are obtained using techniques such as principal component analysis (PCA) and linear discrimination analysis (LDA), and the extracted attributes are used to train models such as the naïve Bayes classifier (NBC), random forest, and KNN. The selection of training data and performance evaluation are based on test data and rely on techniques such as cross-validation, RMSE, or precision statistics. Obtaining reliable crop yield predictions during cultivation is difficult, as crop production varies according to various climatic conditions, such as the dry period and temperature. It increases the need for analysis of crop production in different climatic conditions. Therefore, in [14], the automatic learning method was analyzed, and it is reported that random forest, a supervised algorithm, has the capacity to analyze crop growth in relation to the current climatic conditions and biophysical changes. Similarly, in [10], the ability of the random forest algorithm to predict soil classes from different training datasets and extrapolate this information to a similar area was evaluated.
Another opportunity to consider is machine learning models/algorithms and their possible applications to geospatial data. Special attention is given to the models that are based on artificial neural networks (multilayer perceptron, general regression neural networks, self-organized maps), statistical learning theory (support vector machines) [15], geostatistical techniques such as ordinary kriging [16], or algorithms such as random forest and random forest spatial interpolation (RFSI) [17].
To visualize different crops and their associated characteristics, high-resolution yield maps are used. These maps are an essential tool in modern agriculture and are obtained through spatial interpolation; however, spatial interpolation is generally performed using methods that can be computationally demanding [18]. To this end, some work has been carried out to explicitly consider spatial analyses in machine learning approaches. It includes observations made at the prediction location using random forest and comparing these predictions with those based on deterministic interpolation methods, such as ordinary kriging, regression kriging, and random forest for spatial prediction (RFsp). For studies focused on precipitation and temperature, RF generally outperformed regression kriging, inverse distance weighting, and RFsp; in addition, RF was substantially faster than RFsp [17].
III. Methodology
This study seeks to formulate a recommendation for a model that will use the random forest algorithm and integrate three data sources: climatic, building, and fruit quality variables. Following the construction of the model, the development of an information system is proposed to determine current and potential areas of Hass avocado cultivation in the department of Risaralda based on edaphoclimatic and fruit quality variables. This work will be performed under the following project: "Development of an information system to determine current and potential areas of cultivation for Hass avocado (Persea americana Mill) in the department of Risaralda based on edaphoclimatic and fruit quality variables (Research Project contract 424-201 MinCiencias)”. To construct a suitable and precise machine learning model for this project, relevant datasets will be obtained; then, the data will be preprocessed. The data will be cleaned, and spatial data in the form of geographical coordinates will be added to each data point. Data creation will be performed according to the selected machine learning algorithm, and evaluations of the results obtained from the test and training phases of the model will be carried out. Finally, predictions of the potential for land cultivation will be created.
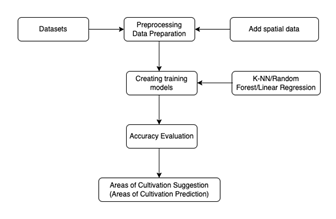
Description of the Dataset.
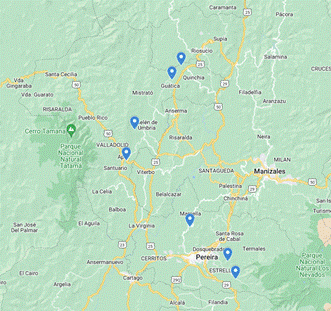
Field sampling will be carried out to collect data on soils, fruit quality, and climatic conditions from the Hass avocado-producing farms of the municipalities of Pereira, Dosquebradas, Santa Rosa de Cabal, Marsella, Apía, Belén de Umbría, Gúatica and Quinchía, department of Risaralda. The first dataset will include data from seven (7) LynkBOX CLIMA PLUS climatic stations that have been installed on the different farms located in the municipalities selected for the study (Fig. 2), allowing the data of climatic variables to be recorded. Temperature (°C), relative humidity (%), precipitation (mm), solar radiation (W/m2), and wind speed (m/s) data will be recorded for a year. The second set of data will be based on a soil fertility analysis, and pH and contents of organic matter, potassium (K), calcium (Ca), magnesium (Mg), sodium (Na), and phosphorus (P) will be evaluated according to Colombian technical standards NTC 5264, 5403, 5349 and 5350. Additionally, the third dataset will be derived from the analysis of fruit quality samples, and variables such as fruit dry matter, quality, moisture, and calcium content will be determined.
Data Preparation.
The data will have different formats within the datasets generated, as observed in the datasets described above; therefore, it will be imperative to clean and normalize the data for later use in the model. To address missing data, the random forest algorithm [19] will be used. A process for scaling the data or normalization will also be carried out to convert the dates and times of the different data sources.
Random Forest.
When the datasets are configured, the prediction process will be carried out using the random forest algorithm and local spatial information, that is, data on the spatial dependencies and complex spatial patterns that arise [20]. The initial data training will be performed using the random forest algorithm; this algorithm is based on decision trees and generates a prediction through a series of division rules. The spatial correlation between the data obtained is not included in the standard random forest output, and it will be taken into account that the nearby data contain information about a prediction location. Therefore, additional spatial variables will be incorporated into the random forest model.
Accuracy Assessment.
Accuracy metrics, such as accuracy and root mean square error (RMSE), will be used to verify predictions [17].
Accuracy is a metric that delivers the total percentage of elements that are classified correctly, where the percentage is denoted as a value between 0 and 1; the higher the value is, the more accurate the model.
The root mean square error (RMSE) is a periodically realistic quantity between the statistical value of the population and the samples predicted by the model. RMSE refers to an anomaly between the expected values and the observations. These individual changes are detected as anomalies when the calculations are estimated as prediction errors, and the calculations are performed using data samples known as prediction errors. The square is then quantified to obtain the RMS value of a set of data values [21].
IV. Results
The model is developed and implemented on a two-core MacBook Pro Intel Core i5 computer, and the programming language used is Python with the scikit-learn library. The model is run using the random forest algorithm. A test of the model is established with the independent variables being relative humidity, precipitation, solar radiation, wind speed, wind direction, and the variable to be predicted being ambient temperature.
Model Parameterization.
To tune the model, cross-validation or k-fold cross-validation is chosen, where two separate datasets were created from the original data: a training set (and test set) and a validation set, where k-fold = 100.
Hyperparameters and Metrics for the Evaluation of the Decision Tree Model.
In the process of constructing the random forest model, the number of trees is set to 100 (n_estimators = 100), and the default values are retained for the rest of the hyperparameters. The number of trees was selected by using k-fold validation. The evaluation metrics yielded the following results: accuracy = 97.9536827 and RMSE = 0.6800923.
Evaluation of the Model.
After parameterization and training of the model, a prediction of ambient temperature based on climatic variables is obtained from the random forest model. Table I shows the importance of the explanatory variables (in percentage) in the model.
Table I Importance of explanatory variables in the model.
| No. | Variable | (%) |
|---|---|---|
| 1 | Relative humidity | 74.9 |
| 2 | Precipitation | 10.1 |
| 3 | Solar radiation | 8.3 |
| 4 | Wind speed | 4.2 |
| 5 | Wind Direction | 2.5 |
Model Test.
The model is tested with a dataset constructed of the previously described variables. The prediction of ambient temperature obtained is in the range of 14 to 40 degrees Celsius, which is considered a required temperature for the cultivation of this fruit [22].
V. Conclusions
Generating a prediction of potential areas for crop cultivation based on machine learning algorithms allows Hass avocado producers to make decisions based on factors such as temperature, rainfall, and soil conditions. The information system proposed under the execution of this project (contract 424-201 MinCiencias) will make it possible to determine, based on predictions, if the current production areas of the avocado crop are the most appropriate and identify the potential areas of cultivation.

