











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
Esta investigación surgió del interrogante de si los estudiantes universitarios de español como segunda lengua (L2) y como lengua de herencia (LH)1 adquieren las herramientas necesarias para las diferentes situaciones comunicativas a las que pudieran enfrentarse según su nivel de competencia lingüística. Los participantes de este estudio son estudiantes de español de nivel intermedio de una universidad urbana en Texas. Se investigó si podían llevar a cabo tareas que requieren el uso de un discurso2 formal -como solicitar una beca o dirigirse a su supervisor-, así como de un discurso informal -como conversar en un ambiente familiar o en una fiesta-. Este proyecto se centró en la escritura, en una de las cuatro habilidades de la lengua.3
La hipótesis de este estudio es que hay diferencias, por un lado, en la escritura de ambos grupos, como consecuencia tanto de una distinta adquisición del español, como diferente exposición a esta lengua; y por otro, entre el discurso formal y el informal, puesto que las características discursivas cambian según el estilo y el nivel de formalidad, especialmente a nivel léxico.
Dado que los hablantes de lh han tenido una exposición de la lengua principalmente en contextos informales -como en el hogar o en otros ambientes familiares (Valdés, 2001, p. 2)-, se esperaba que no les fuera problemático desarrollar una escritura informal. Por otro lado, el desarrollo de un discurso formal podría representarles un mayor esfuerzo, debido a una menor exposición a la lengua en contextos formales o académicos. En cambio, se previó lo contrario para los estudiantes de L2: que poseían más estrategias para desarrollar una escritura formal, debido a que han estado expuestos a un español más prescriptivo en un contexto escolar, y, en tales condiciones, que no poseyeran suficientes estrategias para elaborar un discurso informal, suponiendo que no han tenido adecuada exposición a contextos informales.
Por ello, se aboga por una enseñanza de diferentes registros en las clases de español. Si bien una de las metas de la enseñanza de lh es desarrollar una variedad prestigiosa (escrita y oral) como la que se usa en el contexto académico (Valdés, 1995), también es importante desarrollar otros registros de la lengua, principalmente porque en muchas ocasiones la comunicación apremia un habla coloquial. Lo mismo se puede señalar de los estudiantes de L2, que han estado principalmente expuestos a un registro formal, pero cuyo acercamiento a otros registros de la lengua ha sido escaso o nulo.
La presente investigación se adjunta al marco teórico de la pedagogía crítica de la lengua, pues uno de los objetivos de este estudio es validar la adquisición y el uso de variedades locales, registros y estilos alternativos al estándar4 (Gutiérrez y Fairclough, 2006). Dado que no todos los contextos -orales o escritos- exigen el uso de un español formal, es importante proporcionar a los estudiantes de español herramientas que les permitan desarrollar una conciencia lingüística de los diferentes registros (Gutiérrez y Fairclough, 2006) y una conciencia crítica del uso de la lengua (Fairclough, 1989, 1992), que les posibilite ampliar el dominio de la misma en distintos contextos, según la situación y la relación con los interlocutores.
El objetivo de este estudio es comparar la escritura de estudiantes de español con diferente experiencia de exposición a/adquisición de la lengua, es decir, estudiantes de L2 y de lh, en lo referente a las estrategias léxicas que utilizan para diferenciar una escritura formal de una informal. Esta investigación indaga si ambos grupos poseen las mismas estrategias o si hay diferencias entre las dos poblaciones.
Las variables que se analizaron son: “tipo de vocabulario”, “densidad léxica”, “diversidad léxica” y “frecuencia de uso” de las palabras.
Marco teórico
La pedagogía crítica de la lengua (pcl), propuesta por Norman Fairclough (2010), proporciona el marco teórico de esta investigación. Según la pcl, los estudiantes de idiomas deben ser críticos en el aprendizaje de la lengua que estudian, en el sentido de inquirir no solo los fenómenos lingüísticos, sino también los fenómenos sociales que rodean a la lengua que están adquiriendo. Este marco integra el factor social dentro de la pedagogía de la lengua. Promueve que los estudiantes adquieran el conocimiento necesario y desarrollen herramientas que les permitan instrumentalizar el uso de la lengua a su favor, según las distintas situaciones comunicativas. Por ello, la pcl consiste, esencialmente, en desarrollar una práctica emancipadora (Fairclough, 2010, p. 530). En otras palabras, la pcl pretende posibilitar que los estudiantes cuestionen críticamente ideologías lingüísticas y sociales que habían dado por hecho.
Debido a que los participantes de este estudio pertenecen, por un lado, a un grupo minoritario (lh) y, por otro, a un grupo con una cultura diferente a la cultura de la lengua meta (L2), la pcl posibilita que los estudiantes desarrollen la lengua no solo dentro del contexto escolar y con un uso hegemónico, sino que este se expanda a otros usos y contextos, como son el contexto de habla/escritura informal, dialectos vernáculos u otras expresiones de grupos minoritarios.
Tradicionalmente se ha establecido como meta, en la enseñanza de lenguas, una alfabetización estandarizada, para que aquellos estudiantes que no posean un registro prestigioso puedan adquirirlo. Sin embargo, esto ha devaluado y estigmatizado a variedades consideradas como no estándares. Según Fairclough (1989), lo anterior se debe a la idea tradicional de que la lengua es teleológica y su meta debe ser la transmisión de diversos significados. No obstante, el uso de la lengua tiene otras metas, como construir ideologías, reflejar relaciones sociales, incluyendo relaciones de poder: “it is also a matter of expressing and constituting and reproducing social identities and social relations, including crucially relations of power” (Fairclough, 1989, p. 237).
Para contrarrestar dicha idea tradicional de la lengua, Fairclough propone la pcl. Esta pedagogía se inserta dentro de un modelo de aprendizaje adecuado a la instrucción de lenguas, el cual contiene tres elementos principales: texto, interacción y contexto. En la interacción ocurre el proceso de producción y de interpretación del texto; en el contexto se obtienen las condiciones sociales de producción y de interpretación, lo cual refleja la importancia entre el texto y el contexto en una situación determinada. Según lo anterior, un modelo de lengua que se use en la educación escolarizada debe estar socialmente constituido.
El modelo propuesto por Fairclough (1989) desarrolla la conciencia crítica del entorno del estudiante y su capacidad para contribuir y modelar el mundo social. El objetivo de la pcl es que esta acompañe al desarrollo de las capacidades intelectuales para producir un discurso propio e interpretar el discurso de otros. Tal conciencia facilita un discurso emancipador y se puede desarrollar de manera individual o colectiva. Para llevar a cabo esto, Fairclough propone el modelo de enseñanza que se muestra en la Figura 1.

Figura 1 Modelo de aprendizaje propuesto por Norman Fairclough en el marco de la pedagogía crítica de la lengua
Según Fairclough, este modelo consta de dos principios rectores:
El enlace entre la conciencia y la práctica: el desarrollo de las habilidades potenciales de la lengua de los niños depende del enlace entre practicas discursivas significativas y la conciencia crítica de la lengua.
Edificar a partir de la experiencia: la conciencia crítica de la lengua debe partir de las capacidades existentes en la lengua y las experiencias de los niños. (Fairclough, 1989, p. 240; la traducción es mía)
El desarrollo de las capacidades en la lengua depende del enlace significativo entre la práctica y la conciencia. Este enlace sugiere qué es lo que se debe enseñar a los estudiantes sobre la lengua. Como el desarrollo de las habilidades de la lengua requiere de la conciencia crítica, los estudiantes deben tener acceso al modelo de aprendizaje que se presenta en la Figura 1 y desarrollar un metalenguaje que les posibilite hablar del lenguaje mismo.
La enseñanza debe partir de la experiencia previa de los estudiantes. Es decir, la conciencia crítica se desarrolla a partir de las capacidades en la lengua que ya poseen y las experiencias previas de los estudiantes (Fairclough, 1989, pp. 241-242).
En concordancia con la pcl, este trabajo propone valorar discursos no estándares en situaciones que requieran un habla o una escritura informal. A continuación, se presenta un repaso de estudios previos, seguido de las variables estudiadas.
Estudios previos
Uno de los primeros estudios sobre la adquisición de vocabulario fue el que llevó a cabo Raúl Ávila (1991). Una de las variables que analizó es la “densidad léxica”.5 Utilizó dos corpus para su análisis: uno de textos escritos (más de 4000 textos, alrededor de 750 000 palabras) por niños mexicanos entre 9 y 12 años de edad, y el otro de grabaciones orales (250 entrevistas, alrededor de 420 000 palabras) de adultos mexicanos entre 17 y 70 años. El investigador dividió a la población en cinco grupos según la edad (10, 12, 17-29, 30-49, 50 o más). Los resultados mostraron un incremento continuo de la densidad léxica (del) según aumentaba la edad.
En el mismo año, Ana M. Haché (1991) realizó un estudio sobre riqueza léxica en ochenta estudiantes de sexto y octavo grado en la República Dominicana. Las variables sociales incluidas fueron “sexo”, “edad” y “nivel socioeconómico”. Los participantes escribieron una narración de algún paseo que hubieran tenido en la playa o cualquier otro lugar. Se encontró una variación de la riqueza léxica según la edad: a mayor edad, el porcentaje de vocablos aumenta. Igualmente, se halló una mayor riqueza léxica en los varones -contrario a los resultados de Torres (2003) -, excepto en sexto grado, donde no hubo diferencias entre los sexos. Por último, la variable de “nivel socioeconómico” no discriminó en cuanto al porcentaje de vocablos, pero sí en cuanto al intervalo de las palabras nocionales6 (pan), según el cual los participantes de estrato social alto tuvieron un índice menor que los de estrato medio-bajo.
Antonia Torres (2003) estudió la riqueza léxica en el número de vocablos diferentes y el intervalo de aparición de pan (léxicas) en relación con cuatro variables sociales: “grado escolar”, “centro educativo” (público o privado), “sexo” y “nivel sociocultural”. Recopiló 140 escrituras de un tema libre en escuelas primarias, secundarias y preparatorias, públicas y privadas, en Tenerife. Se analizaron las primeras cien palabras de cada texto. Los resultados mostraron índices de riqueza más elevados en las escuelas privadas, que se incrementaban según avanzaban los niveles de escolaridad -sin embargo, el incremento ocurrió tanto en las escuelas públicas como en las privadas-. En cuanto al “sexo”, los escritos de las mujeres mostraron una mayor riqueza léxica que los de los hombres. Finalmente, se encontraron promedios más favorables según asciende el estrato sociocultural.
Fairclough y Belpoliti (2016) analizaron 226 ensayos de estudiantes universitarios de español como lh de nivel principiante en Texas. Estudiaron la riqueza léxica en tres variables: “densidad léxica”, “frecuencia de uso” de palabras y “variación léxica”. Los resultados muestran un promedio de 46,4 % de del, es decir, un porcentaje alto de palabras funcionales. Las investigadoras interpretan lo anterior como el reflejo de un inventario léxico limitado y de una escritura con rasgos de oralidad.
En cuanto a la frecuencia de uso, encontraron que el 92,9 % de las palabras pertenecían a las 1000 palabras más frecuentes según el diccionario de frecuencia de Davies (2006), o sea, correspondientes a un vocabulario básico.
Finalmente, el índice de Guiraud (palabras diferentes entre la raíz del total de palabras) mostró muy poca variación léxica: un promedio de 4,05 en dicho índice. Las palabras utilizadas pertenecían a las categorías de verbos y sustantivos, principalmente.
Variables lingüísticas
Las variables analizadas en este estudio fueron: “tipo de vocabulario”, “densidad léxica”, “diversidad léxica” y “nominalizaciones”. En el apartado siguiente, se describe cada una de ellas.
Tipo de vocabulario
El tipo de vocabulario de las palabras de contenido se clasificó según el registro lingüístico al que pertenece: formal, neutral y coloquial. El vocabulario tiende a diferir según este registro. Además, ciertas palabras son más usadas en la escritura, mientras que otras se asocian con el discurso oral.
La relevancia del análisis del tipo de vocabulario radica en que la selección de una u otra palabra suele ser el principal indicador del nivel de formalidad o informalidad de un texto; siguiendo a Chafe y Danielewicz: “choosing lexical items is partly a matter of choosing aptly and explicitly, partly a matter of choosing the appropriate level” (1987, p. 9).
Tomando en cuenta las diferencias de registros, algunos diccionarios diferencian entre palabras “cultas”, “formales”, “coloquiales” e incluso “vulgares” y “despectivas”. En este estudio se utilizó el diccionario Using Spanish Synonyms de Batchelor (2006) para diferenciar el registro lingüístico al que pertenece el vocabulario que utilizaron los participantes.
Un segundo criterio para diferenciar el vocabulario es la longitud de las palabras: cuanto más extensa sea una palabra se considera más especializada y específica; en cambio, una palabra corta posee una mayor frecuencia de uso y, por lo tanto, es más general (Biber, 1988, p. 239).
Densidad léxica
Es la relación que existe entre el número de pan, léxicas o de contenido que aparecen en un texto, en contraste con el número total de palabras. Se espera que cuanto más formal sea un texto escrito, este posea mayor del: “written language becomes complex by being lexically dense: it packs a large number of lexical items into each clause” (Halliday, 2004, p. 654). Según Halliday, hay más densidad en los textos escritos que en los orales (2004, p. 654). Los elementos léxicos que contribuyen a la densidad son los sustantivos, los verbos, los adjetivos y los adverbios.
Otra manera de medir la diversidad léxica (dil) es por medio del intervalo de aparición (ida) propuesto por López Morales (1984). Esta fórmula, en lugar de dividir el número de palabras léxicas entre el total de las palabras del texto, divide el total de palabras del texto entre el número de pan. Por ello, cuanto menor sea el ida, mayor riqueza léxica tendrá el texto (López Morales, 1984, p. 92).
Diversidad léxica
Es la relación existente entre el número de palabras que aparecen solamente una vez, en contraste con el total de palabras del texto. Es un indicador de la riqueza léxica, pues se espera que cuanto mayor conocimiento del vocabulario tenga una persona, mayor será la dil en su producción escrita y oral, aunque principalmente escrita, ya que este tipo de discurso se caracteriza por un mayor uso de palabras de contenido y palabras distintas: “Sabemos que si un escritor posee un léxico amplio, la repetición de vocablos disminuye” (Torres, 2003, p. 436).
Es importante mencionar que en esta investigación se asumen como “vocablos distintos” aquellas palabras con el mismo morfema léxico y que, además, presenten diferentes morfemas gramaticales. Por ejemplo: los vocablos “la” y “las” se consideran vocablos diferentes, al igual que los vocablos “estás” y “estamos”.
Para medir la diversidad dentro de un texto se utiliza el índice de hárpax (hár), el cual se obtiene dividiendo el total de vocablos (palabras diferentes que aparecen en un texto) entre el número de vocablos de una frecuencia, es decir, los que ocurren solamente una vez (Haché, 1991; Torres, 2003). Este índice permite conocer las palabras que se utilizan solamente una vez en el texto. Cuanto más bajo sea el resultado, habrá mayor riqueza léxica.
Frecuencia de uso
Otra variable que se analizó es la “frecuencia de uso” de las palabras. Según Fairclough y Belpoliti (2016), el perfil de frecuencia léxica es un indicador del tamaño del vocabulario que una persona posee en su lexicón, así como un indicador de la calidad del vocabulario.
Para medir la frecuencia del vocabulario de los participantes se utilizó el Diccionario de frecuencia léxica de Davies (2006), que incluye las 5000 palabras más frecuentes del español.
Este diccionario etiqueta la palabra más frecuente “el/la” con el número 1 y el número de frecuencia avanza según disminuye la frecuencia de uso. En este sentido, mientras más alto es el número en Davies, menos frecuencia de eso tiene la palabra. Por ejemplo, “saber” tiene una frecuencia de 46 y “frialdad” tiene una frecuencia de 4827: la primera palabra se usa más frecuentemente que la segunda. Dado lo anterior, la riqueza léxica o el conocimiento del vocabulario es mayor cuando se utilizan vocablos con una menor frecuencia de uso.
Metodología
Participantes
Los participantes de este estudio eran estudiantes del programa de español como lh (N= 15) y de español como L2 (N= 15) de una universidad urbana en Texas al momento de recopilar los datos. Ambos grupos de participantes cursaban el segundo nivel de español intermedio, siendo ambos cursos equivalentes -en cuanto a nivel de competencia lingüística por lo menos pueden hablar sobre temas de la vida diaria en tiempo presente y formar cadenas de oraciones simples- en cada programa.
Instrumentos
Se utilizaron dos instrumentos de producción extensa. Los participantes escribieron dos composiciones como parte de las actividades de clase con el mismo tema: dar su opinión acerca del espanglish. Sin embargo, una de las composiciones debía estar dirigida a un/a amigo/a (situación informal) y la otra a su profesor/a de español (situación formal) (véanse Apéndices A y B).
Los escritos se realizaron en clase en dos sesiones diferentes, uno al inicio del semestre y el otro al final del mismo. Ambos grupos tuvieron entre 40 y 50 minutos para completar las dos composiciones.
Análisis de los datos
El análisis de los datos se llevó a cabo con las primeras cien palabras en español de cada texto. Algunas investigaciones previas (Ávila, 1986; Biber, 1988; Cuba y Miranda, 2004; Haché, 1991; Torres, 2003; Zamora, 2013) también han utilizado solamente las primeras cien palabras, debido a que la diferencia de longitud de los textos afecta considerablemente el análisis estadístico.
En el caso de la frecuencia de aparición de cada palabra, habría mayor posibilidad de que una palabra aparezca más veces en textos más largos:
Raw frequency counts cannot be use for comparison across texts because they are not all the same length. This is, long texts will tend to have higher frequencies simply because there is more opportunity for a feature to occur. (Biber, 1988, p. 14)
Torres (2003) hace referencia a lo mismo: “es necesario que el texto tenga la misma extensión, porque así sabemos que las diferencias son debidas a una razón estilística y no a la desigual extensión de las composiciones” (Torres, 2003, p. 436).
Se tomó como unidad léxica la “palabra”,7 debido a que los textos analizados fueron originalmente escritos, y no transcritos de textos orales.
Se hicieron las siguientes modificaciones a los textos originales: 1) se eliminaron los nombres propios, las palabras en inglés y las creaciones léxicas; 2) se pusieron y quitaron acentos en las palabras que lo necesitaban (i. e. mas( más,8pádre ( padre); 2) se eliminó la palabra “spanglish/espanglish”, que aparecía varias veces debido al tema de las composiciones; 3) se separaron palabras que estaban juntas (i. e. sonbonitos ( son bonitos); 4) se eliminaron espacios innecesarios (i. e. en mi opiniónΦ, creo que ( en mi opinión, creo que), y 5) se reemplazaron abreviaciones por la palabra completa. Después de eso, se seleccionaron las primeras cien palabras de cada ensayo.
Como ya se mencionó, el tipo de vocabulario se analizó usando el diccionario Using Spanish Synonyms de Batchelor (2006). En este diccionario, “Register is conceived as the most important organizing criterion of the book” (Batchelor, 2006, p. 4).
Este diccionario organiza las entradas léxicas de manera alfabética; cada entrada léxica posee cierta cantidad de sinónimos, organizados según el registro al que pertenecen. Batchelor propone cuatro registros: R3 incluye vocabulario con un alto nivel de formalidad, R2 vocabulario neutro, R1 vocabulario coloquial y R1* vocabulario vulgar.
Se buscaron todas las palabras léxicas no repetidas en todos los textos y se etiquetaron con el registro correspondiente. Las palabras no encontradas en el diccionario se etiquetaron con 0 y se dejaron fuera de los cálculos estadísticos. Las palabras que en el diccionario aparecían marcadas con registro 3-2 o 2-1 se marcaron como 3 y 1 respectivamente, evitando el registro neutral en estos casos.
Para analizar la longitud de las palabras, se eliminaron las palabras funcionales y se contó el número de caracteres de todas las palabras léxicas de cada escrito; luego se sumó y se promedió el número de caracteres por grupo en las dos composiciones. Para ello se utilizó una aplicación llamada “ParamText tip” (Carreras-Riudavets et al., 2011). Esta aplicación fue desarrollada por Carreras-Riudavets, Santana-Herrera, Hernández-Figuero y Rodríguez-Rodríguez en la Universidad de Las Palmas de Gran Canaria como su proyecto de tesis. Se trata de un parametrizador morfológico de textos en español:
El ParamText TIP analiza el contenido léxico de un texto, extrayendo el número de párrafos, oraciones, palabras y caracteres. Asimismo, se extrae para cada uno de estos grupos el número de oraciones, de palabras y de caracteres de cada párrafo, el número de palabras y de caracteres de cada oración y el número de caracteres de cada palabra. Ofrece información métrica como la frecuencia de aparición de las palabras en el texto, el centro de gravedad de los vocablos, la distribución de las palabras según su primera aparición y su frecuencia de uso en el español. Asimismo, se muestra en una tabla el vocabulario completo utilizado en el texto. (Carreras-Riudavets et al., 2011)
El análisis de la del se llevó a cabo de forma manual, es decir, se contaron una por una las palabras léxicas en de cada texto. Dentro de esta clasificación están los verbos, los sustantivos, los adjetivos calificativos y los adverbios. No se tomaron en cuenta los adverbios y adjetivos que funcionaban como especificadores dentro de la oración, por ejemplo, “muchos hombres vinieron”; tampoco se contó la partícula “no”. Después de contar, se dividió el número de palabras léxicas entre el total de palabras de cada texto.
Para medir el ida, se dividió el total de palabras entre el número de palabras léxicas.
El análisis de la diversidad de vocablos podía hacerse de dos maneras, según la definición de “vocablo”. Para López Morales (1984) y Haché (1991), un “vocablo” es una palabra con el mismo lexema, pero con sufijos flexivos diferentes, esto es “mis” y “mi” se consideran vocablos diferentes. En cambio, para Ávila (1991) y Cuba y Miranda (2004), un “vocablo” es aquel que tiene el mismo lexema y puede variar en sus morfemas gramaticales, por ejemplo, “fue” y “fueron” se toman por un solo vocablo. En esta investigación nos decantamos por la primera opción.
Para medir la dil se utilizó la aplicación Complete Lexical Tutor v.8.3 (Bailey, 2015). Esta aplicación, entre otras cosas, mide la frecuencia de aparición de las palabras en un texto: permite conocer el número de ocurrencias de cada palabra, así como el porcentaje que representa dentro del texto. Se diseñó para analizar textos en inglés y en francés, pero también funciona con español para este tipo de análisis.
Esta aplicación contabilizó el total de palabras distintas en cada uno de los textos analizados. Después se dividieron las palabras diferentes entre el total de palabras (Types/Tokens).
Por otro lado, para obtener el hár, se dividió el total de vocablos entre los vocablos de una frecuencia, es decir, los que tenían solamente una ocurrencia. Por ejemplo, si en un texto de 100 palabras hay 45 palabras diferentes, y de estas últimas, algunas aparecen más de una vez y otras solo una vez. Supongamos que de las 45 palabras diferentes, 25 aparecen solo una vez; entonces, el hár sería de 1,8.
La frecuencia de uso de las palabras se midió utilizando A Frequency Dictionary of Spanish de Davies (2006). Las palabras de frecuencia 5000 a 2000 se clasificaron por intervalos de 1000; se contó con otro intervalo de 1000 a 501 y, finalmente, uno de 500 a 1.
Resultados
Los resultados se presentan según las variables estudiadas.
Tipo de vocabulario
Se analizaron las palabras léxicas sin contar sus repeticiones, es decir, solamente se contó una palabra por lexema, por lo que no debe confundirse el número de palabras léxicas analizadas en esta sección con el número de palabras léxicas analizadas en la del.
Desafortunadamente, no se encontraron todas las palabras presentes en los ensayos en el diccionario de Batchelor (2006). En el grupo de español como L2 no se halló un 46 % (100/217)9 de las palabras de la escritura informal ni un 38 % (78/207) de las palabras de la escritura formal. Mientras que en el grupo de español como lh no se encontró un 38 % (75/199) de las palabras en la composición informal ni un 43 % (97/227) de las palabras de la composición formal. Así que el análisis del tipo de vocabulario se llevó a cabo considerando únicamente las palabras clasificadas en alguno de los cuatro registros propuestos por Batchelor (2006).
Cabe mencionar que no se halló ninguna palabra perteneciente al registro R1* (vulgar).
En los dos tipos de texto, ambos grupos concentraron el mayor porcentaje de palabras en el R2 (neutral), con números muy similares. El número de palabras clasificadas en el R3 (formal) tiende a aumentar en la escritura formal, aunque no de manera significativa.
Por otro lado, no hubo diferencias en las palabras clasificadas como R1 (coloquial), por tener el mismo número de vocablos pertenecientes a este registro, a excepción del escrito formal del grupo de lh, donde solo aparecen dos palabras coloquiales.
En la Tabla 1 se presenta el número y porcentaje de palabras encontradas en el diccionario de Batchelor (2006), por grupo y tipo de texto.
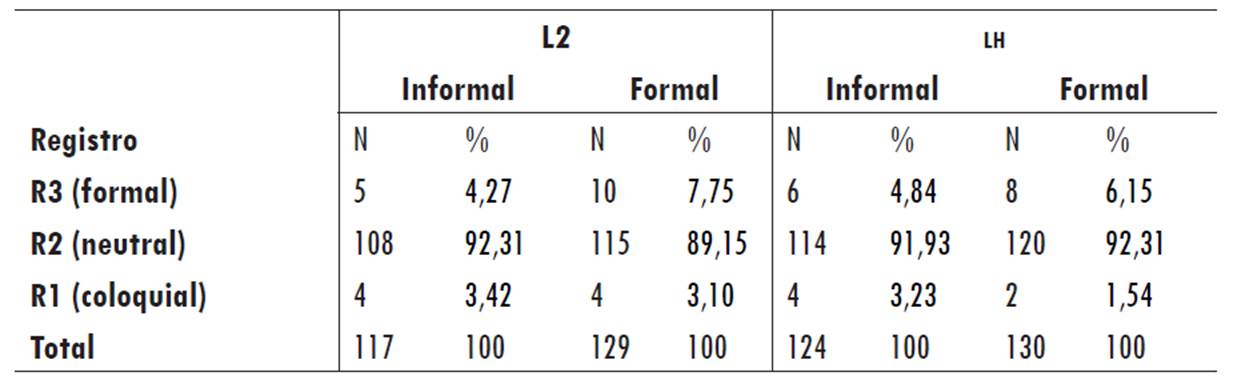
Se observa que la mayoría del vocabulario se concentra en el registro neutro, independientemente del tipo de texto -formal o informal- en ambos grupos. Esto significa que tanto los participantes de L2 como los de lh mostraron poca diversidad en cuanto al registro del vocabulario utilizado en ambas escrituras. Esto puede deberse a que los participantes no poseen un vocabulario formal, pero tampoco uno coloquial. También puede ser el resultado de que prestaron más atención en la expresión de sus ideas que en dirigirse de una forma apropiada a cada uno de los interlocutores previstos para cada texto.
En cuanto a la longitud de palabras léxicas, los participantes del grupo L2 tuvieron un promedio mayor en la extensión de palabras de contenido que los del grupo lh. El escrito formal (464,3) del grupo de L2 tuvo un promedio mayor de longitud de palabras que el escrito informal (445,9), mientras que los participantes del grupo lh mostraron resultados contrarios: el texto formal (430,2) tuvo un promedio menor de longitud de palabras que el texto informal (439,1).
La Tabla 2 muestra las estadísticas descriptivas de la suma de los caracteres de todas las pan encontradas en las escrituras formales e informales de ambos grupos.
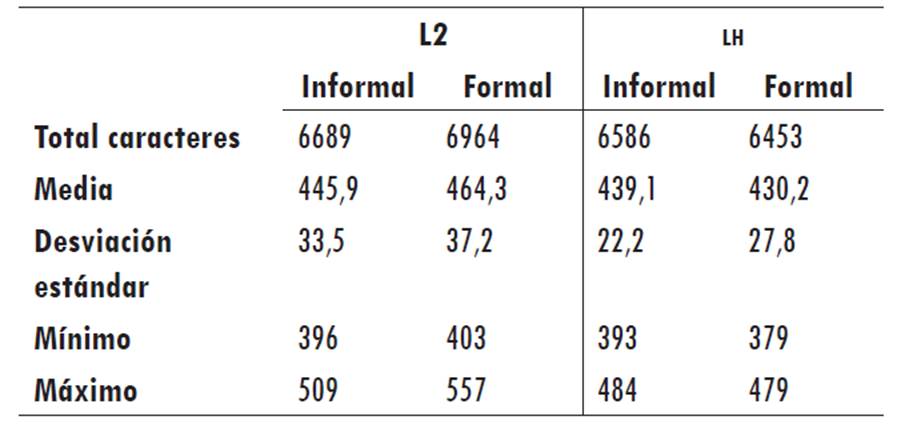
Las palabras se concentran entre los 400 y 500 caracteres en ambos textos y en ambos grupos. Se aprecia que los estudiantes de español como L2 mostraron una mayor longitud de caracteres en las palabras léxicas tanto del texto formal como del texto informal. No obstante, la diferencia de este grupo en comparación con el grupo de lh es escasa. En este sentido, la variable del número de caracteres de las palabras léxicas no reflejó diferencias entre los dos tipos de escritura ni entre los grupos.
Densidad léxica
La del aumentó un 2 % en la escritura formal del grupo de L2 y un 3 % en la escritura formal del grupo de lh. Por lo tanto, no se encontró mucha diferencia entre grupos ni entre textos nuevamente.
El ida, por la naturaleza de su fórmula, es inversamente proporcional al índice de del: cuanto más bajo sea el intervalo, mayor riqueza léxica tendrá el texto.
La Tabla 3 muestra el número de pan, el porcentaje de del y el ida por grupo y tipo de texto.
Tabla 3

DEL: Densidad léxica; IDA: Intervalo de aparición; L2: Segunda lengua; LH: Lengua de herencia; PAN: Palabras nocionales.
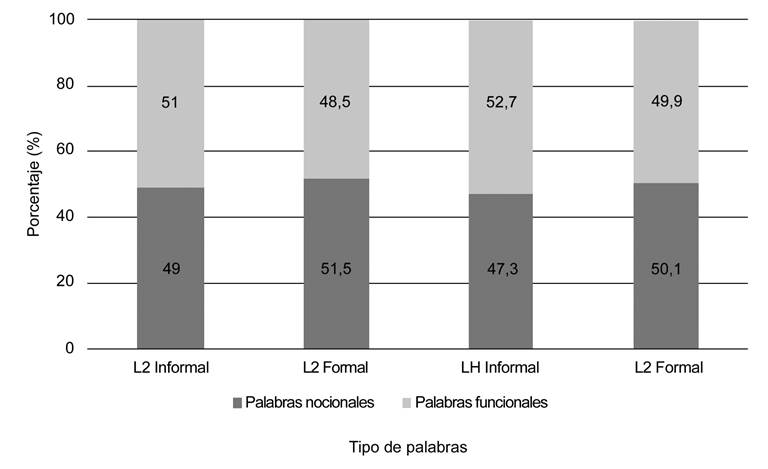
En la Figura 2 se muestran los porcentajes de palabras léxicas y palabras derivadas. Se puede notar que los participantes de lh presentan una mayor diferenciación entre el registro formal y el registro informal, en comparación con el grupo de L2.
Diversidad léxica
En lo que respecta a los resultados de la dil, el grupo L2 mostró una diferencia de un 3 % entre los dos textos. Contrario a lo esperado, el escrito informal tuvo una mayor diversidad.
Por otro lado, en el grupo de lh la dil aumentó un 2 %, según lo esperado. En ambos grupos, las diferencias porcentuales entre los textos formales e informales no fueron copiosas.
En cuanto al hár, el grupo de estudiantes de L2 obtuvo un índice de 1,46 en el texto informal y un 1,34 en el texto formal. Recuérdese que mientras más bajo es el índice, es mayor la dil. Por su parte, el grupo de estudiantes de lh mostró un índice de 1,27 y 1,47 para el texto informal y formal respectivamente.
Los resultados presentaron mayor número de palabras de una frecuencia en la escritura informal de los participantes de lh, y menor número en la escritura informal de los participantes de L2.
La Tabla 4 muestra el número de vocablos (V) encontrados, el número de vocablos de frecuencia 1 (vf1), el porcentaje de dil, así como el hár por grupo y tipo de texto.

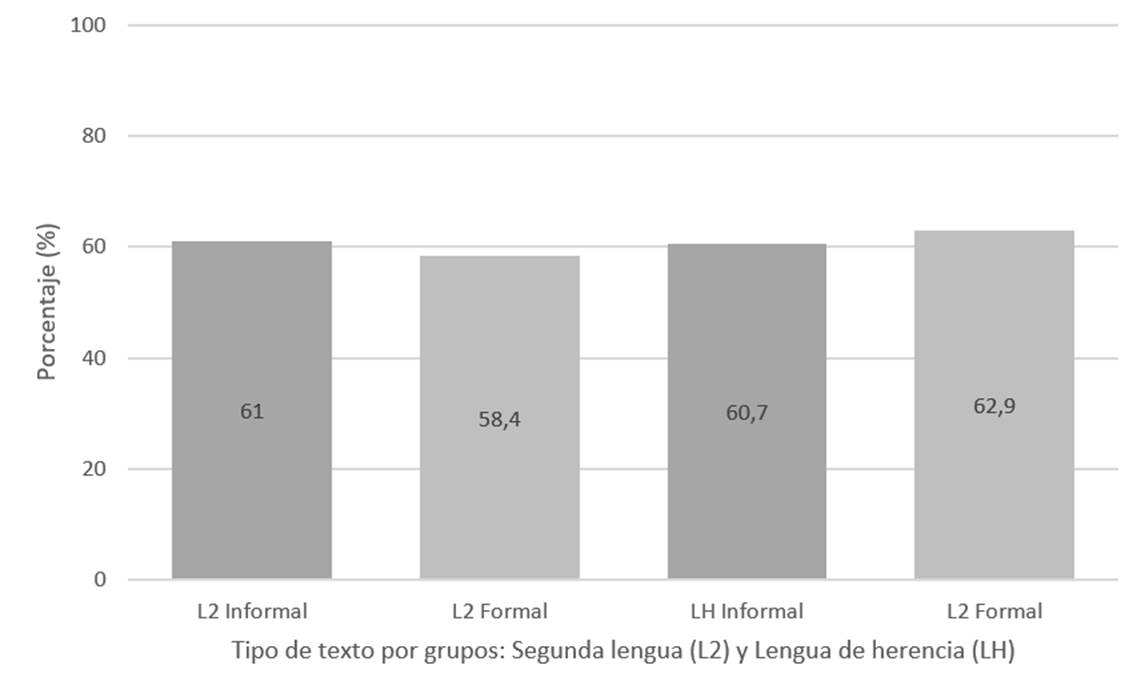
En la Figura 3 se muestran los porcentajes de la dil. Se puede observar cómo únicamente hay un aumento en el dil en el grupo de lh para el texto formal.
Frecuencia de uso
Finalmente, la frecuencia de uso de las palabras utilizadas en los textos se concentró en las primeras 500 palabras, es decir, entre las 500 palabras más frecuentes en español. No se encontró registro de todas las palabras presentes en las composiciones; sin embargo, las palabras no halladas fueron pocas.
En los textos informales del grupo de L2 no se presentó registro de 13 palabras, mientras que en el texto formal del mismo grupo no se encontraron 16 palabras. En lo que respecta al grupo de lh, 13 palabras del texto informal y 16 palabras del texto formal no aparecieron registradas en el diccionario de Davies.
En ambos textos, los dos grupos obtuvieron más del 50 % en este rango de frecuencia. El grupo L2 mostró una media de frecuencia de 903,0 en la escritura informal, en contraste con una media de 805,4 en la escritura formal, contrario a lo que se esperaba, en tanto que el grupo de lh tuvo una media de 821,8 en la escritura informal y una media de 828,3 en la escritura formal. Nuevamente, no se observó gran diferencia entre ambos tipos de texto.
El grupo de L2 mostró un mayor uso de palabras con una frecuencia de uso menor en la escritura informal. Esto puede deberse a que escribieron al inicio del semestre la escritura formal, mientras que la escritura informal la hicieron a medio semestre, por lo que en este intervalo pudieron haber adquirido más vocabulario en español.
Por otro lado, las diferencias entre ambos tipos de escritura en el grupo de lh son insignificantes.
La Tabla 5 muestra los porcentajes de la frecuencia de uso del vocabulario según el diccionario de Davies (2006).

Discusión
Las diferencias encontradas entre los dos tipos de texto resultaron, con excepción de la longitud de palabras, según lo esperado: se reflejó un mayor número de las variables estudiadas en el texto formal. Sin embargo, las diferencias porcentuales no discreparon ampliamente unas de otras.
Con respecto a las diferencias entre los dos grupos, el grupo de lh presentó índices más elevados en comparación con el grupo de L2, excepto en la longitud de palabras.
A continuación, se presentan dos posibles hipótesis de por qué no se encontró una mayor diferencia entre los grupos como entre los tipos de texto.
La primera explicación es que los participantes prestaron más atención a la exposición de sus ideas que a la forma de dirigirse al destinatario de la composición. Esto ocurre porque, en la mayoría de los textos informales, los participantes se dirigen a su lector con un “hola” o un “hola, ¿cómo estás?” (13 en L2 y 11 en lh); después de eso, se dedican a presentar su opinión y todos utilizan la forma de tratamiento informal “tú”.
No obstante, en los textos formales, solamente 5 estudiantes del grupo L2 se dirigen al profesor, y de estos, solo 1 utiliza la forma de tratamiento formal “usted”.
Del grupo de lh, ningún estudiante de dirige directamente al profesor y todos utilizan el modo de tratamiento informal en estos textos. Cuando no se dirigen al destinatario, los participantes comienzan con la exposición de su opinión, con frases como “Yo creo que”, “En mi opinión”, “Estoy de acuerdo con”, etc. Esta falta de mención a quién se dirige el escrito sugiere que los participantes no hicieron mucho hincapié en el destinatario, sino en el desarrollo de sus ideas. Esto sugiere que descuidaron la tarea de expresarse en el registro formal e informal al momento de redactar sus textos.
La segunda figuración es que los participantes tienen, efectivamente, noción de los diferentes registros, pero estos no se manifestaron debido a que los participantes no poseen las herramientas que les permitan llevar a cabo tal diferenciación, esto es, no poseen un vocabulario más formal, ni ninguna de las otras estrategias léxicas analizadas para diferenciar los registros en el discurso escrito. Esto puede deberse a las limitaciones lingüísticas propias de los aprendices de una L2 y de una lh.
Asimismo, en aquellas escrituras en las que los participantes comenzaron dirigiéndose al receptor, no siempre lo hicieron de la forma esperada. Por ejemplo, todos los participantes de L2 que se dirigieron al destinatario lo hicieron de la manera esperada en la escritura informal con un “hola, ¿cómo estás?” o un “¡Saludos!”, mientras que algunos de los participantes de lh escribieron: “Estimado Juan” en la escritura informal, una introducción que se esperaría en un contexto formal.
En la escritura formal, los participantes de L2 también se dirigieron de modo informal a su profesor con un “¡Hola, profesor!”, mientras que los participantes de lh no hicieron referencia directa al destinatario del ensayo.
Se puede concluir que los estudiantes poseen un léxico formal e informal escaso y que el vocabulario que utilizan es principalmente neutro, con el cual se comunican en las diferentes situaciones, sin discriminar entre si estas son formales o informales. Este registro neutro, aunque posibilita la comunicación, no garantiza que esta sea adecuada en contextos claramente definidos como formales o como informales, en especial cuando el interlocutor es un hablante monolingüe o con poco conocimiento de las estrategias comunicativas de aprendices de español.
La longitud de las pan no contribuyó a diferenciar el nivel de formalidad de los textos, debido a que los resultados que se obtuvieron no mostraron un patrón claro, pues pese a que en el escrito formal del grupo de L2 hubo una mayor longitud de palabra, no ocurrió así en el grupo de lh.
La del aumentó en los ensayos formales en ambos grupos. Según esto, se puede concluir que los participantes intuyen que una escritura con un mayor número de palabras de contenido, es decir, evitar el uso de palabras generales con poco contenido semántico, incrementa sistemáticamente el nivel de formalidad de los textos.
Lo mismo se puede decir del resultado del ida y de la dil; aparentemente, los participantes intuyen que los textos más formales contienen mayor diversidad de vocabulario.
Sin embargo, tanto para la del como para la dil, los participantes no mostraron una diferencia en cuanto a registros lingüísticos en los textos mediante estas dos variables.
Según Fairclough y Belpoliti (2016), un porcentaje de dil bajo es un indicador de un inventario léxico limitado y un marcador de producción oral, pues un discurso con un número amplio de palabras funcionales suele relacionarse más con el habla que con la escritura.
Por su parte, los resultados del hár no mostraron diferencias entre los dos grupos ni entre los dos estilos de escritura.
En lo referente a la frecuencia de uso, los resultados fueron contradictorios en los dos grupos de participantes. En el grupo de lh, la producción fue conforme a lo que se esperaba, mientras que, en el grupo L2, los resultados fueron contrarios a los esperados, aunque con diferencias mínimas.
Con esta variable, se concluye algo semejante a lo que se señaló con respecto al tipo de vocabulario: los estudiantes tienen un vocabulario básico -dado que la mayoría de las palabras usadas se clasifican entre las primeras 500 palabas más usadas en español-, con el cual pueden comunicarse eficazmente en algunas situaciones, pero probablemente no puedan hacerlo en contextos bien definidos como formales; por ejemplo, un ensayo académico o en una petición de una beca escolar.
En suma, se concluye que las escrituras analizadas en los dos grupos de participantes no poseen suficientes elementos léxicos que las distingan como un estilo formal o como un estilo informal; en otras palabras, los marcadores de formalidad o de informalidad encontrados son tan escasos que no posibilitan que los textos se reconozcan clara y distintamente bajo uno de los dos registros. El registro que se observa en las composiciones es principalmente neutro -según el tipo de vocabulario- y básico -según la frecuencia de uso del vocabulario-. Mientras que la densidad y la diversidad, por encontrarse cercanas al 50 %, no aportan suficiente evidencia para definir la escritura como formal o como informal.
Debido a que el número de participantes de este estudio es limitado, en investigaciones futuras resultaría conveniente realizar un experimento similar con un mayor número de participantes. Asimismo, se podrían recopilar los datos tanto en inglés como en español para comparar los resultados de las composiciones en ambos idiomas. Si las diferencias de registro se logran apreciar en las composiciones en inglés, esto significaría que los estudiantes tienen conocimiento de estas diferencias, pero no son capaces de marcarlas en la escritura en español.
Algo que se podría mejorar es la redacción de las instrucciones, de modo que se enfatice la importancia de dirigirse al destinatario de manera apropiada según el nivel de formalidad que pida en cada situación.
Cabe mencionar que en este estudio se tomó como unidad léxica la “palabra”, pero la unidad léxica también puede ser asumida como “la palabra o el conjunto de palabras que tienen un solo significado” (Torres, 2003, p. 441). En este sentido, un tiempo compuesto constituiría una sola unidad léxica, lo cual es algo que se puede considerar en estudios futuros.
Una de las principales limitaciones del estudio fue el hecho de que no se encontró un número considerable de entradas léxicas en el diccionario de Batchelor (2006). Una opción para suplir esta carencia es combinar el uso de este diccionario con el de otros que categoricen las palabras de forma similar.
Por último, habría que hacer una comparación entre la comunicación oral y la comunicación escrita, para observar si hay diferencias entre estas dos modalidades. Como se expuso en la sección de estudios previos, se ha encontrado una marcada diferenciación de registros al comparar los registros orales con los registros escritos.
Las implicaciones pedagógicas de estos resultados apuntan hacia una necesidad de implementar, en el proceso de enseñanza-aprendizaje, las diferencias de registros tanto en las clases de español como L2, así como de lh, con el fin de que los estudiantes sean capaces de utilizar la lengua en diversas situaciones comunicativas. En este caso, los participantes tenían un nivel intermedio en español al momento de recoger los datos. Este nivel de competencia lingüística puede ser la causa de no encontrar diferencias marcadas entre los dos tipos de registros analizados.
Por otro lado, es posible que en niveles más avanzados se noten más las diferencias de registros. No obstante, si la instrucción en la enseñanza de lenguas no dedica tiempo a la diferenciación de registros y excluye la enseñanza de registros no estándares, es poco probable que los estudiantes adquieran las herramientas necesarias para poder expresarse en contextos formales o en contextos informales.
Como se señaló en la introducción, en la enseñanza de lh una de las metas es desarrollar una variedad prestigiosa o estándar. Esto puede garantizar que los aprendices adquieran vocabulario y expresiones más formales, pero ¿qué pasa con la adquisición de un registro informal?, ¿debería continuar relegado en la enseñanza de lh?

