











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introducción
La fotogrametría, se puede definir actualmente como la ciencia de obtener información de confianza de propiedades de superficies y objetos sin el contacto físico con estos, y para medir e interpretar esta información"(Schenk, 2005). Como antecedente, la fotogrametría inició con la invención de la cámara fotográfica a finales del siglo XIX para medir distancia entre objetos, o proporciones de estos objetos por el análisis fotográfico. Hoy en día, con los avances tecnológicos, la fotogrametría se ha aprovechado para la digitalización 3D de objetos por medio de software; ya sea para imprimirlo en 3D, colocar el modelo en un medio de entretenimiento; o para un enfoque más investigativo (Mikrut, S., Mikrut, 1992; Lane, Richards and Chandler, 1993; Beltran et al., 2018; Goodbody, Coops and White, 2019).
El software de fotogrametría se basa en los conceptos de key points" y "tie points" para generar la imagen 3D. en primer lugar, key point (KP) es un punto que destaca en la imagen por una diferencia de contraste, brillo, saturación o color con sus alrededores; cabe destacar que este punto puede variar en número pixeles. En segundo lugar, tie-point (TPM), es cuando el software reconoce el mismo key point en varias imágenes, y lo utiliza de anclaje y referencia para la renderización 3D; junto a otros parámetros como ángulo de la foto, enfoque del lente, distancia en que se tomó la foto, y puntos de referencia del fondo de la imagen, entre otros (Julien, Fauqueur, Nick , Kingsbury and Ryan, 2006; Harris Geospatial Solutions, 2020).
Siendo el primer paso para la digitalización 3D el proceso de tomar las fotos, el siguiente paso es denominado "mask" de las fotos en el software (Agisoft© Metashape). Hacerle un "mask" a una foto, es seleccionar las áreas de la imagen que no hacen parte del objeto de interés al que se quiere renderizar en 3D, ya sea porque es parte del fondo, o es una sección del modelo en la que no se está interesado (Uchida, 2013; Gray et al., 2019). Agisoft, permite configurar la anulación de este mask por KP o TPM. En una ejecución del software por KP, se considera cualquier punto que se encuentre en esa imagen y lo ignora, pero si encuentra ese KP en otra imagen, considera este punto sin omitirlo. Por otro lado, si es por TPM, cualquier KP que encuentre en esa zona con mask, será ignorado, independientemente de que se encuentre posteriormente en otra imagen sin mask (R&D work Agisoft LLC, 2006).
Teniendo en cuenta lo anterior, la selección de masks en el software, por KP, o por TPM, tiene un procesamiento y conceptualización diferente, es decir cuando se realiza por KP, hay que hacer un mask imagen por imagen, proceso que se puede tardar entre 90 a 120 minutos por cada 32 imágenes. Mientras el proceso realizado por TPM, se toma una foto del fondo sin el objeto de interés, se hace un mask general de dicha foto, y si se considera necesario, se hace mask de pequeñas áreas que hayan salido en otras fotos (por ejemplo, mano del investigador). Con este último método, el proceso de mask se puede tardar 4 minutos o menos, sin embargo, se requiere conocimiento de técnicas con mayor control de los elementos de fondo, iluminación y sombras, además de asegurarse que el objeto de interés este en el centro de la bandeja rotatoria (Uchida, 2013).
Posterior al masking, el software hace el sub-proceso de "alignment". Aquí utiliza los TPM para determinar la orientación y posición de las fotos en cuanto al objeto de interés. El resultado es considerado como "sparse point cloud model", el cual muestra la ubicación espacial de los TPM, y también se obtiene representado en rectángulos azules la posición de cada foto de manera individual. Si en el punto de procesamiento de la imagen hay diferencias entre los resultados que presenta el software y la realidad, se debe restar continuidad al proceso y reiniciar una nueva sesión de fotos. Los sub-procesos de "Matching" y "alignment", son responsables del "Tie Points"(Fathi and Brilakis, 2011; Su, Hang, Jampani, Varun, Sun, Deqing, Maji, Subhransu, Kalogerakis, evangelos, Yang, Ming Hsuan, Kautz, 2018).
El software prosigue en crear un "Dense point cloud". En el cual, se aprovecha la información adquirida en el alignment en cuanto a profundidad, calidad y enfoque de las imágenes; para reconocer puntos adicionales de anclaje similares entre las imágenes. Ya teniendo una mayor cantidad de puntos de anclaje en el dense cloud, el software puede crear la malla (MESH), la cual consiste en formas poligonales del modelo 3D en donde sus vértices son precisamente los puntos de anclaje generados en el dense cloud. El Dense point cloud se crea por el proceso "Dense cloud", que está conformado por los subprocesos "Depth map generation" y "Dense cloud generation". Mientras que el proceso de "MESH" solo tiene un subproceso que es "Processing" (Levine, Paulsen and Zhang, 2012).
Si bien con el MESH el software propone dar color al modelo, las características de las superficies en este punto son alejadas de la realidad. Para superar esto, se procede a crear el "texture", que como su nombre lo indica, otorga a los polígonos textura para aumentar su fidelidad al modelo original. El proceso de "texture" está compuesto por los subprocesos "UV mapping" y "Blending" en la tridimensionalidad del modelo (Lai et al., 2018).
Para poder realizar los procesos previamente mencionados se necesita tanto el trabajo de unidades de procesamiento de computación (CPU) y unidades de procesamiento gráfico (GPU). En ambas hay distintos modelos en el mercado que difieren en potencia, calidad y precio. Además, muchos software son programados para aprovechar ciertas estructuras físicas de CPU o GPU particulares, por lo que es común que un software tenga mejor desempeño en un procesador de menor potencia comparado con uno de mayor potencia, simplemente porque está mejor optimizado para dicho procesador(Song, Mu and Zhou, 2017; Teodoro et al., 2017).
Agisoft© Metashape tiene dos configuraciones para generar los procesos. Puede hacer uso mixto de CPU o GPU en todos sus procesos, o puede usar un aceleramiento de GPU. En este último se usa el GPU en los procesos de "image matching", "depht maps generation" y "mesh generation". El manual del usuario del software recomienda usar los dos CPU y GPU, sin embargo, si hay al menos un GPU discretamente potente (Nvidia® pertenecientes a la serie GeForce GTX o AMD® pertenecientes a la serie Raedon), recomiendan el uso único de GPU. Cabe destacar que los CPUS hechos por la marca comercial Intel tienen un GPU integrado de poca potencia, por lo que, en teoría, un solo CPU relativamente potente de esta marca puede ser suficiente para suplir todos los procesos. Por otro lado, los CPUS hechos por la marca comercial AMD carecen de estos GPUS integrados, por lo que, si se va a usar un CPU de esta última marca, se debe comprar un GPU por aparte(Radeon, 1969; Nvidia, 1995; R&D work Agisoft LLC, 2006).
2. Metodología
Obtención y selección de las fotos de cortes encefálicos
Se buscó entre los intentos de fotogrametría anteriormente guardados, cuál de ellos tenía el renderizado más parecido a la realidad, los criterios de selección fueron fidelidad de polígonos y fidelidad de textura, los cuales son parámetros netamente cualitativos del software para procesar imagen Agisoft© Metashape. Todos los modelos son procedentes de encéfalos completos extraídos con los protocolos estándares del Neurobanco del Grupo de Neurociencias de Antioquia.
Selección de equipos de cómputo
Se usaron cuatro computadores para hacer las pruebas. El primero de ellos, es un computador portátil (Laptop) que cuenta con un CPU de gama media, y la GPU integrada en dicho procesador (E1); que se incluye en el estudio cómo funciona el software sin una GPU externa. El segundo, es un computador portátil para juegos de video (gaming laptop) con un CPU de gama media y un GPU de gama alta (E2). El tercero, es un computador de escritorio (Desktop), que tiene un CPU y GPU de gama media (E3); y el último es un computador de escritorio (Desktop) que tiene un CPU y GPU de gama alta (E4). Las especificaciones de los equipos se pueden encontrar en la Tabla 1. Se ignora otros parámetros que se pueden considerar importantes (memoria RAM o características del disco duro), ya que se han visto poco relevantes en los procesos.
TABLA 1 ESPECIFICACIONES TÉCNICAS DE LOS EQUIPOS DE COMPUTACIÓN.
| Equipo | CPU | GPU |
| E1 | Intel i5-7200U | HD Graphics 620 |
| E2 | Intel i5-6300HQ | Nvidia GTX 960M |
| E3 | Intel i5-8400 | Nvidia GTX 1050Ti |
| E4 | Intel i7-8700 | Nvidia GTX 1060 |
En la Figura 1 se observan características de los CPUS que se usaron, junto con otras opciones del mercado, se recomienda ver como punto de comparación el Avarage Bench (Avg. Bench) y precio. El Avg. Bench como la comparación del hardware, con un hardware seleccionado por el portal web; mientras que los precios son los oficiales del mercado en USA. Los otros parámetros pueden ser ignorados.
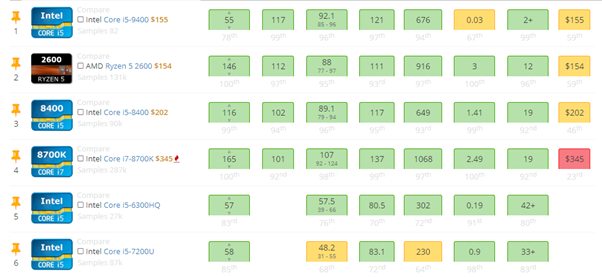
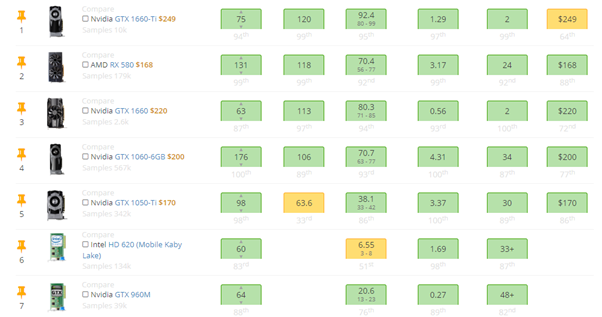
En la Figura 2, se presentan las características de los GPUS que se usaron, junto con otras opciones del mercado, se recomienda ver como punto de comparación el Average Bench (Avg. Bench) y precio. El Avg. Bench es la comparación de ese hardware, con un hardware seleccionado por el portal web; mientras que los precios son los precios oficiales del mercado en USA.
Mask de fotos y renderización de los modelos
En cada uno de los equipos, se hicieron dos masks. Uno para renderizar en KP y otro para renderizar en TPM. A su vez, a cada uno de los Masks, se le hizo dos renderizados, uno que usaba la configuración mixta de CPU y GPU, y otro que usaba la configuración de uso único de GPU. A cada uno de los modelos obtenidos, se le hizo una cinética del tiempo en realizar cada uno de los subprocesos y procesos, además, se guardaron los parámetros utilizados y aplicados del modelo en caso de futuros procesamientos de imagen, este proceso metodológico, en síntesis, se resume en la Figura 3.

Cinéticas de comparación de resultados en el renderizado
Los resultados del tiempo se presentarán en segundos. De tal forma que tendremos diferencia absoluta y razón de tiempo) , se considerará significativo en la práctica, cualquier razón de tiempo que sea mayor de 1,15 y menor de 0,87. Asimismo, se compararán los resultados entre las renderizaciones sin TPM (Tie Points Masking) y con TPM; como los resultados entre renderización de configuración mixta y con GPU. Por último, se analizarán individualmente los resultados entre los diferentes equipos en cada una de las categorías de renderización sin TPM ni GPU, con GPU, con TPM, y con TPM y GPU.
3. Resultados y discusión
Durante el procedimiento computacional, se hicieron 16 renderizaciones cuyos valores se presentan en la Tabla 2. El menor tiempo de renderización fue en el equipo L4 con TPM y GPU (195 s); y el mayor fue en el equipo L1 con solo GPU. Se ve que hubo diferencia en tiempo en cada una de las renderizaciones, excepto en L4 sin TPM ni GPU, y L4 con GPU. tienen relación con el desempeño de los procesos. El promedio de tiempo en L1, L2, L3 y L4 es de 2462 s, 583 s, 306 s y 261 s respectivamente.
TABLA 2 RESULTADOS DE RENDERIZACIONES (EN SEGUNDOS)
| Mt | At | TPt | DMGt | DCGt | DCt | Pt | MSt | UVt | Bt | Tt | Tiempo total | M | S | |
| L1 | 445 | 14 | 459 | 171 | 57 | 228 | 42 | 42 | 36 | 129 | 165 | 894 | 14 | 54 |
| L1 (TPM) | 466 | 22 | 488 | 168 | 64 | 232 | 65 | 65 | 36 | 146 | 182 | 967 | 16 | 7 |
| L1 (GPU) | 3840 | 16 | 3856 | 108 | 62 | 170 | 51 | 51 | 16 | 138 | 154 | 4231 | 70 | 31 |
| L1 (TPM) (GPU) | 3339 | 21 | 3360 | 100 | 74 | 174 | 52 | 52 | 40 | 132 | 172 | 3758 | 62 | 38 |
| L2 | 277 | 7 | 284 | 105 | 42 | 147 | 26 | 26 | 57 | 77 | 134 | 591 | 9 | 51 |
| L2 (TPM) | 299 | 19 | 318 | 104 | 48 | 152 | 29 | 29 | 40 | 86 | 126 | 625 | 10 | 25 |
| L2 (GPU) | 259 | 10 | 269 | 122 | 47 | 169 | 35 | 35 | 41 | 92 | 133 | 606 | 10 | 6 |
| L2 (TPM) (GPU) | 245 | 11 | 256 | 26 | 55 | 81 | 35 | 35 | 38 | 102 | 140 | 512 | 8 | 32 |
| L3 | 138 | 5 | 143 | 67 | 21 | 88 | 16 | 16 | 27 | 46 | 73 | 320 | 5 | 20 |
| L3 (TPM) | 141 | 4 | 145 | 63 | 21 | 84 | 17 | 17 | 26 | 46 | 72 | 318 | 5 | 18 |
| L3 (GPU) | 138 | 5 | 143 | 67 | 21 | 88 | 16 | 16 | 27 | 46 | 73 | 320 | 5 | 20 |
| L3 (TPM) (GPU) | 132 | 4 | 136 | 14 | 24 | 38 | 18 | 18 | 26 | 50 | 76 | 268 | 4 | 28 |
| L4 | 107 | 4 | 111 | 79 | 16 | 95 | 16 | 16 | 18 | 39 | 57 | 279 | 4 | 39 |
| L4 (TPM) | 112 | 4 | 116 | 73 | 18 | 91 | 18 | 18 | 25 | 43 | 68 | 293 | 4 | 53 |
| L4 (GPU) | 107 | 4 | 111 | 79 | 16 | 95 | 16 | 16 | 18 | 39 | 57 | 279 | 4 | 39 |
| L4 (TPM) (GPU) | 78 | 4 | 82 | 11 | 18 | 29 | 17 | 17 | 25 | 42 | 67 | 195 | 3 | 15 |
Considerando todos los procesos, la cinética de mayor tiempo fue la que tuvo en cuenta el procedimiento de Alignment, seguido de Texture, Dense Cloud y MESH. El proceso que aparenta ser más sensible es Dense Cloud, seguido por Alignement, Texture y MESH. Se puede observar que, a partir de los equipos de menor potencia, parámetros como el Dense Cloud son más lentos que el Texture (llegando a ser un 38 % más rápido), pero a medida que aumenta la potencia de la tarjeta gráfica, el Dense Cloud es más rápido (en su mejor relación, hasta 2,31 veces más rápido), lo que optimizaría en grandes proporciones el procesamiento de imágenes como se presenta en la Tabla 3.
TABLA 3 RELACIÓN TPM CON EL TIEMPO DE RENDERIZADO
| Tiempo sin TPM | Tiempo con TPM | Diferencia absoluta | Razón de diferencias | |
| L1 | 894 | 867 | 27 | 1,0311 |
| L1 GPU | 4231 | 3758 | 473 | 1,1259 |
| L2 | 591 | 625 | -34 | 0,9456 |
| L2 GPU | 606 | 512 | 94 | 1,1835 |
| L3 | 320 | 318 | 2 | 1,0063 |
| L3 GPU | 320 | 268 | 52 | 1,1940 |
| L4 | 279 | 293 | -14 | 0,9522 |
| L4 GPU | 279 | 195 | 84 | 1,4308 |
TPM= renderizado por Tie Point Masking. GPU= renderizado por acelaramiento de GPU. Mt= Matching time. At= Alignement time. TPt= Tie Points time. DMGt= Depth map generation time. DCGt= Dense cloud generation time. DCt= Dense cloud time. Pt= processing time. MSt= MESH time. UVt= UV mapping time. Bt= Blending time. Tt= Texture time.
Se observa que hay diferencia significativa con TPM en los equipos L2, L3 y L4 cuando se usa GPU. En el equipo L1 no hay diferencia significativa en ninguna configuración. Se ve que hay una mejora del rendimiento con TPM que puede ir desde un 18 % hasta un 43 %, que presenta una aparente relación positiva dependiendo de la potencia del GPU, de igual manera se hace mandatorio realizar un análisis de las relaciones y cinética del procesamiento gráfico de imágenes, ya que la aplicación del estudio tiene como fin, ilustrar la tridimensionalidad de los cortes encefálicos, por lo que se presenta en la Tabla 4 los resultados del procesamiento gráfico con el tiempo de renderizado:
TABLA 4 RELACIÓN GPU CON TIEMPO DE RENDERIZADO
| Tiempo sin GPU | Tiempo con GPU | Diferencia absoluta | Razón de diferencia | |
| L1 | 894 | 4231 | -3337 | 0,2113 |
| L1 TPM | 967 | 3758 | -2791 | 0,2573 |
| L2 | 591 | 606 | -15 | 0,9752 |
| L2 TPM | 625 | 512 | 113 | 1,2207 |
| L3 | 320 | 320 | 0 | 1,0000 |
| L3 TPM | 318 | 268 | 50 | 1,1866 |
| L4 | 279 | 279 | 0 | 1,0000 |
| L4 TPM | 293 | 195 | 98 | 1,5026 |
Se observa que hay diferencia significativa con GPU en todos los equipos, sin embargo, en los equipos L2, L3 y L4 solo ocurre cuando se usa TPM. En el equipo L1 parece tener un efecto nocivo en la ejecución del software, mientras que en los otros equipos mejora el rendimiento. Sin embargo, cabe resaltar que es curioso ver que no hay una relación directa respecto a la potencia del equipo, caso contrario al observado en la Tabla 3 cuando se compara en cada uno de los procedimientos con TPM.
Cuando se comparan los equipos L1, L2, L3 y L4 (Figura 4), se observa que todas las razones son significativas. El desempeño del equipo 4 también es significativo cuando se compara con L1 y L2 en todas sus configuraciones, no obstante, cuando se compara con L3 solo es significativo cuando se hace TPM y GPU juntos.
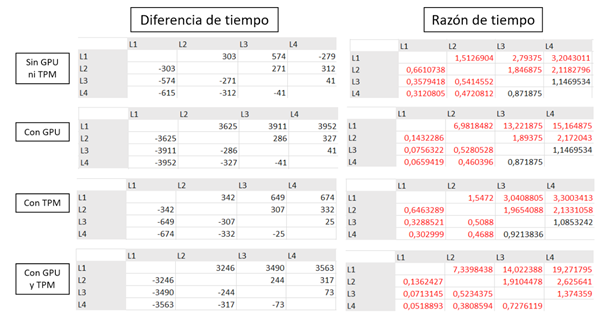
En la comparación de los renderizados sin GPU ni TPM, el menor resultado significativo es la comparación entre L1 y L2, donde el desempeño de L2 fue del 51 % mejor que L1; mientras que el mayor resultado significativo es entre L1 y L4, donde el desempeño de L4 fue del 320 % mejor que L1. Cuando se compararon los renderizados con GPU, el menor resultado significativo es entre L2 y L3, donde el desempeño de L3 fue del 89 % mejor que L2; y el mayor resultado significativo es entre L1 y L4, donde el desempeño de L4 fue del 1516.0% mejor que L1. Cuando se comparan los renderizados con TPM, el menor resultado significativo es entre L1 y L2, donde el desempeño de L2 fue del 54 % mejor que L1; y el mayor resultado significativo es entre L1 y L4, donde el desempeño de L4 fue del 330 % mejor que L1. Finalmente, cuando se comparan los renderizados con GPU y TPM, el menor resultado significativo es entre L4 y L3, donde el desempeño de L3 fue del 37% mejor que L4; y el mayor resultado significativo es entre L1 y L4, donde el desempeño de L4 fue del 1927 % mejor que L1.
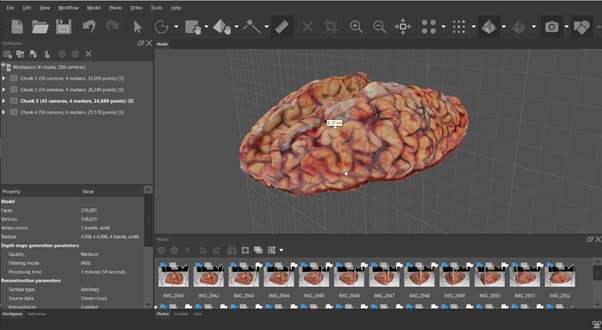
El hecho de que haya surgido la necesidad de rehacer un renderizado, nos indica que, bajo las mismas condiciones, un mismo proceso puede tener tiempos diferentes. No obstante, según la experiencia de los investigadores, la frecuencia que se den estos cambios en el tiempo de renderizado depende de la calidad de fotos (Figura 5) con las que se estén trabajando, y cuando se dan las diferencias, estas son realmente significativas y se pueden identificar desde el principio del renderizado, por lo que, según las especificaciones de la RAM y el trabajo gráfico, es preferible detener la ejecución y reiniciar el software. Los promedios de tiempo de renderizado mejoran, mientras aumenta la potencia de la combinación CPU con GPU. Además, al observar de una forma superficial de como un GPU aumenta el desempeño del proceso más largo (Alignment), y como convierte al segundo proceso más largo al tercero (Dense Cloud); se puede ver cómo va adquiriendo importancia el GPU en todo el renderizado, ya que la velocidad y el número de procesamientos con base en la cantidad de núcleos, es clave en la cinética del procedimiento del render.
Cuando se usa TPM, este resulta ser solo benéfico en la configuración GPU, cuando este GPU es una tarjeta gráfica aparte, y no cuando es una integrada en el CPU (como es en el caso del equipo L1). No obstante, se recomendaría usar este tipo de mask aunque no se tenga una tarjeta gráfica aparte, ya que el tiempo de edición de fotos que se ahorra, alcanza a cubrir cualquier demora que se pueda dar en el tiempo de renderizado. Como es de esperar, el tiempo mejora, mientras se está en relación directa con la potencia en la relación CPU/GPU.
Cuando se usa la configuración con GPU, la mejora en tiempos de renderizado no tiende a ser tan lineal como en TPM. En primer lugar, es perjudicial colocar esta configuración cuando no se posee una tarjeta gráfica por aparte; por lo que se recomienda no usar esta configuración para este caso particular. Además, a pesar de que tanto el CPU y GPU del equipo L3 son mejores que su contraparte del equipo L2, el desempeño del segundo fue mejor que el primero, esta diferencia se debe a que el software no está optimizado para un hardware especifico, sin embargo, no estamos seguros si es en CPU, GPU o la interacción de estos dos; por lo que se demuestra, que es necesario hacer una prueba del hardware antes, con el software que se desea instalar, para asegurarse que la potencialidad del equipo pueda ser aprovechada al máximo.
4. Conclusiones
El estudio de las cinéticas de renderizado y relaciones en los sistemas CPU como unidad de procesamiento y GPU como unidad de procesamiento gráfico, facilitan la selección de los equipos adecuados para el procesamiento del software, buscando obtener la máxima respuesta y el aprovechamiento del recurso computacional. Teniendo en cuenta el estudio realizado, se recomienda el computador más accesible y acorde al recurso financiero, ya que el mejoramiento en el procesamiento de imagen para una fotogrametría, va a ser altamente significativa, por relación costo-beneficio de igual manera, se considera una mejor opción un equipo de escritorio (Desktop), que un computador portátil (laptop), dado que un computador portátil de la mismas características y potencia, tiende a ser mucho más caro, desde sus características físicas y sin diferencias funcionales.
Bajo una visión económica en el mercado, existen dos empresas de hardware, Intel y AMD. Las partes de AMD tienden a ser más baratas que sus contrapartes de Intel, pero tienen la desventaja que sufren calentamiento con el tiempo de trabajo, por lo que requieren sistemas más eficientes de refrigeración, lo que implicaría un costo adicional. Como perspectiva se tiene para un estudio futuro de un sistema de almacenamiento de imágenes de los diversos cortes encefálicos; la comparación de un sistema acoplado CPU y GPU de la misma compañía en venta e incluso en sistema hibrido. Consecuentemente, como no se hicieron las pruebas respectivas bajo las características de cada una de las compañías, no se puede concluir el efecto en la GPU del software Agisoft© Metashape en el procesamiento de las imágenes de encéfalo de las tarjetas de video de AMD, aunque la compañía no presenta ninguna opción real para hardware de sistemas de cómputo de alta gama, sin embargo, para equipos de gama media tiende a ser muy buena opción entre los consumidores.
De ser posible, se debería usar una torre con un CPU y GPU de gama alta, ya que cuando se usa la configuración TPM y GPU, el tiempo de renderizado es significativamente menor que los de gama media. Sin embargo, la mejor opción costo-efectivamente hablando se consideraría una combinación entre una CPU de gama media junto con una GPU de gama alta; ya que la pendiente de tiempo/potencia de CPU parece ser menor que la pendiente de tiempo/potencia de GPU, por lo que, si se le tiene que dar prioridad a un componente entre estos dos, sería al GPU.

