











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
El pronóstico de la demanda del sector turístico es un tema reconocido a nivel mundial. Diversos estudios emplean modelos de pronósticos para su caracterización y análisis de comportamiento, identificando, por ejemplo, co variables con incidencias significativas o patrones estacionales y tendencias (Guizzardi & Mazzocchi, 2010). Muchos de estos modelos van desde la teo ría clásica, o econométrica, hasta propuestas que comparan modelos clásicos con redes neuronales, como sucede en el trabajo de Claveria y Torra (2014).
Algunos temas relacionados con la teoría de modelos de pronósticos clá sicos, como es el caso de la regresión, presentan problemas asociados con la presencia de sesgos al pronosticar, debido a que cuando se prolonga el pe ríodo de predicción en el modelo con parámetros fijos se puede incurrir en predicciones erróneas. En otros casos hay algunos supuestos de los residuales que no se cumplen con facilidad, por presentar problemas como valores muy extremos, o un cambio repentino en el curso normal de una serie de tiempo.
Cuando la escala de la variable de respuesta inicial es de tipo discreto se pueden usar modelos de pronóstico basados en la distribución Poisson, y si toma valores de respuesta muy altos (más de 100) es posible realizar pronós ticos aproximados con modelos basados en datos con distribución Normal. Otros estudios aplicados a datos de conteo muestran algunos modelos sim ples como distribuciones empíricas o modelos de suavización exponencial. Kolasa (2016) compara pronósticos realizados con distribuciones empíricas, con la Poisson y Binomial Negativa; por otro lado, Wallström y Segerstedt (2010) comparan el método de suavización exponencial con otros como el de Croston.
Se observa, entonces, que la literatura exhibe estudios que muestran resul tados de pronósticos elaborados con modelos clásicos basados en la distribu ción normal o en la Poisson, pero también estudios de modelos con diferentes teorías de estimación como la bayesiana (Zellner, 1996; Valencia, 2016).
La comparación de pronósticos de la demanda del sector turístico en Me dellín es un tema que no ha sido abordado en Colombia usando modelos de regresión clásica y de regresión Bayesiana. En este trabajo se propone com parar un modelo de pronósticos econométrico clásico con dos bayesianos: uno basado en la regresión del autor Zellner, que asume una distribución normal para los datos y parámetros, y otro basado en MCMC (Monte Carlo por Cadenas de Markov), que asume la distribución Poisson para los datos y parámetros bajo la Distribución Normal Multivariada. Estos modelos son aplicados al caso de entradas de turismo a la ciudad de Medellín, Colombia, sin modificar las distribuciones de probabilidad iniciales para este trabajo. Es to puede proponerse en futuras aplicaciones, incluso, con diferentes formas de muestreo.
Con esta investigación se busca responder los siguientes interrogantes: ¿cuáles variables tienen más incidencia sobre la llegada de turistas a la ciu dad (fechas, clima, estaciones, meses)?, ¿con cuáles modelos es posible ajustar mejor la dinámica de demanda de turismo?, ¿la teoría Bayesiana es útil para efectuar pronósticos sobre la demanda de turismo?
Este artículo se presenta en el siguiente orden. En la sección I, se mues tra una revisión de literatura. En la sección II, se muestran los modelos a estimar e indicadores comparativos. En la sección III, se presentan los re sultados, donde se mostrará una exploración de datos y los modelos estima dos para ambas series de turistas (colombianos y extranjeros). La sección IV muestra la discusión de resultados. Finalmente se presentan las conclusiones y referencias.
I. Revisión de la literatura
El turismo en el mundo ha sido un tema de interés para la economía de muchos países (Crouch, 1995; Guizzardi & Mazzocchi, 2010; Lim, 1999; Peng, Song & Crouch, 2014; Zhou, Bonham & Gangnes, 2007). La deman da en este sector ha sido analizada desde el punto de vista de pronóstico en numerosos estudios a nivel internacional (Guizzardi & Stacchini, 2015; Song, Gao & Lin, 2013; Liu et al., 2014). Algunas de las revisiones literarias muestran una descripción completa de los métodos usados en la modelación y pronós tico de las demandas turísticas, que van desde las perspectivas econométricas clásicas has las nuevas técnicas de pronóstico emergentes, que emplean teoría estadística o matemática (Witt & Witt, 1995; Li, Song & Witt, 2005; Song & Li, 2008).
No obstante, en Colombia algunos estudios realizados se han centrado en el análisis del gasto, o en los servicios que se ofrecen al turista. Den tro de este grupo de trabajos se puede resaltar el efecto de la seguridad y el comercio, abordado por Bonilla y Moreno (2010), quienes, mediante un modelo de datos de panel, encuentran que los arribos de viajeros extranjeros es tán inversamente relacionados con los secuestros, y el índice de intercambio comercial lo hace de forma positiva. Otros trabajos han analizado las diná micas locales de los movimientos de viajeros. Cerda y Leguizamón (2005), por ejemplo, encuentran por medio de modelos hedónicos que la demanda interna de agentes nacionales por consumo de un bien turístico depende en gran manera del perfil del jefe de hogar, su poder adquisitivo y la composi ción familiar. A nivel de municipalidades o locaciones específicas, por ejem plo el caso de Cartagena, los estudios se centran en observar el impacto de las fluctuaciones cambiarias en la demanda turística (Galvis & Aguilera, 1999)2. Ahora bien, no se ha hecho un comparativo en pronósticos que evalúe los efectos estacionales de las demandas turísticas para la ciudad de Medellín, caracterizando a su vez, algunos factores controlables, que son importantes para proveer herramientas de planeación para el sector turístico y fomentar estrategias de mejoras en los servicios que se ofertan.
El tipo de modelos propuestos para el pronóstico, a nivel internacional, varía acorde con algunas características de las series de demandas turísticas, por ejemplo, hay estudios de su comportamiento lineal o no lineal (Chen, 2011); pero también se estudia la relación de flujos de turistas con las capa cidades de alojamientos (Zhou et al., 2007), o la inherencia de esta demanda con su ciclo de negocios (Guizzardi & Mazzocchi, 2010).
Existen modelos en los que se relaciona el pronóstico de demandas, con la optimización de recursos, como el caso de demandas e inventarios; para ello, se han usado muchos modelos estadísticos clásicos (Bes & Sethi, 1988; Gutiérrez & Vidal, 2008; Choi, Li & Yan, 2003; Samaratunga, Sethi & Zhou, 1997; Sarimveis et al., 2008) y luego su salida es usada para modelar los in ventarios. Vidal, Londoño y Contreras (2004), por ejemplo, implementan téc nicas sencillas de pronósticos y de control de inventarios. Cohen y Dunford (1986) proponen un modelo basado en una distribución empírica para la de manda y afirman que el requerimiento de una distribución normal para los residuales de los modelos ARIMA (Modelos Integrados Autorregresivos de Medias Móviles) y de regresión no se cumple en muchos casos. Shoesmith y Pinder (2001) emplean modelos VAR (Vector Autorregresivo) y BVAR (Ba yesian Vector Autorregresivo), usando pocos datos de la demanda de los pro ductos estudiados.
Frente a modelos para datos de conteo, existen trabajos comparativos recientes, basados en distribuciones empíricas, Poisson y Binomial negativa, presentados en Kolasa (2016), el cual está basado en Syntetos et al. (2011). A partir de una comparación de indicadores de error con probabilidad, estos trabajos encuentran un mejor desempeño de modelos basados en distribu ción empírica en comparación con los de la distribución Poisson y Bootstrap. Por su parte, Wallström y Segerstedt (2010) presentan el suavizado exponen cial simple (SES-Single Exponential Smoothing) versus Croston y algunas variaciones, aplicados para demandas intermitentes o no3, y encuentra que el modelo SES tiene mejor desempeño frente al de Croston cuando utiliza diferentes indicadores de error para elegir el mejor modelo. Para el caso del tema turístico, se encuentra el trabajo de Hellström (2002) que estima mode los de valor entero autorregresivos de media móvil (INARMA) para estudiar la interacción entre la elección del número de viajes de ocio de los hogares y el número de pernoctaciones.
La estadística Bayesiana ha ganado importancia para efectuar pronósti cos hace algún tiempo. Por ello, se han elaborado diferentes trabajos y textos basados en inferencia predictiva, valor esperado o modelos dinámicos baye sianos que muestran su utilidad para elaborar pronósticos, de forma univaria da o multivariada, basados en información a priori para los parámetros, para los datos y, quizá, información de expertos (Fei, Lu & Liu, 2011; Harrison & Stevens, 1976; De Mol, Giannone & Reichlin, 2008; Neelamegham & Chinta gunta, 1999; West & Harrison, 1997; Valencia, 2016). Un modelo de regresión Bayesiana, que es desarrollado en Zellner (1996), se basa en una distribución no informativa para los parámetros y una distribución normal para los datos, lo cual es posible suponer de manera aproximada cuando la serie de datos tie nen valores muy grandes, así sean discretos, como son la cantidad de turistas de las series temporales de este trabajo. Este modelo será usado para pronosticar la serie mensual de turistas que ingresan a la ciudad de Medellín, en el periodo temporal de 2007 a 2014, y su ajuste será comparado con un mode lo de pronósticos econométrico clásico, y otro bayesiano basado en MCMC (con MCMCpoisson), para determinar así, cual es el mejor modelo que facilite la mejor interpretación del comportamiento de dicha serie de turistas.
II. Métodos
Para iniciar el análisis en series temporales, se hace un corte en la serie de datos, de N valores, T(T < N) serán usados para analizar correlación y análisis descriptivo y para estimar modelos; los N − T restantes serán usados para validar la estimación y para determinar si el modelo tiene una capacidad de pronóstico adecuada. Se realiza un análisis estadístico detectando inicial mente valores atípicos y problemas de variabilidad de los valores de demanda turística de la ciudad de Medellín.
A. Modelo econométrico
El modelo econométrico es un modelo de regresión que contempla va riables autorregresivas endógenas, así como otras exógenas que pueden estar asociadas a la respuesta zt (Caridad y Ocerin, 1998; Bowerman, Oconnell & Koheler, 2007), partiendo de la ecuación general dada por (1):
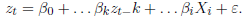 () 1
() 1
Dentro de las covariables a estudiar se encuentran: rezagos de primer or den y estacional, el tiempo, una variable sinusoidal, variable mes como factor, temperatura, IPC, TRM y el consumo de energía por actividad económica. Se realizará un proceso de selección de variables de tipo paso a paso, vali dando el modelo final con las premisas de residuos (normalidad, varianza e incorrelación) y obteniendo al final el indicador de ajuste MAPE (error medio absoluto porcentual) y error relativo de pronóstico, con mayor eficiencia para la predicción. Estos indicadores de error serán comparados con el modelo de regresión clásica.
El MAPE suele ser útil para expresar de una forma simple, en términos porcentuales genéricos, el error cometido, incluso para alguien que no tiene idea de lo que constituye un error de “grande” como, por ejemplo, lo relativo a grandes montos de dinero; en especial, este indicador puede ser adecuado para cantidades que son mayores de una unidad. Cuando toma valores cerca nos a cero, se recurre más a menudo a utilizar el indicador MSE (Mean Square Error), RMSE (Root of Mean Square Error), sMSE (scale Mean Square Error) (Kolasa, 2016), o incluso la medida sMAPE (symmetric Mean Absoute Per centage Error) (Wallström & Segerstedt, 2010), ya que no incrementa más el porcentaje de error en estos casos cercanos al cero. Autores como Petris, Pe trone y Campagnoli (2009), quienes muestran en su libro aplicaciones de los modelos dinámicos bayesianos usando el software R, mencionan que el MA PE es una de las estadísticas más usadas para comparación de pronósticos, y se utiliza junto con otras dos: MAD (Mean Absolute Deviation) y MSE o RMSE, para comparar modelos.
En este trabajo se usan los criterios RMSE, MAPE y sMAPE (ver ecua ciones (2), (3) y (4)) para medir el desempeño en el ajuste y pronóstico sobre estimaciones de modelos clásicos y bayesianos, con respuestas que toman va lores muy altos y diferentes de cero, como son las series de tiempo de cantidad de turistas usadas aquí. Además de esto, se realizan procesos de selección y pruebas con relación a la significancia de covariables y, adicionalmente, prue bas de normalidad.
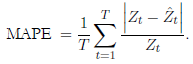 ()2
()2
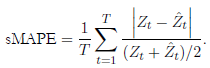 ()3
()3
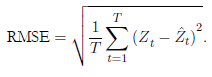 ()4
()4
B. Modelo de regresión lineal bayesiano basado en la normal para los datos
En la teoría de la toma de decisiones, la probabilidad juega un papel fun damental. Las probabilidades previas de estados de la naturaleza pueden ser consideradas a priori con un carácter subjetivo, pero pueden diferir un poco de las reales (Hillier & Hillier, 2007). Con base en los principios del teorema de Bayes, al combinar el producto entre una probabilidad a priori con una condicionada a un hecho se obtiene lo que se conoce como probabilidad a posteriori. Estos principios son utilizados por la estadística bayesiana para inferir, por ejemplo, usando predicciones (Gill, 2007; Gelman et al., 2004).
En la Estadística Bayesiana, los parámetros de la ecuación de regresión no son fijos, sino que se pueden comportar acorde con una función de distribu ción, llamada a priori. Al utilizar el teorema de Bayes, es posible usar la premisa acerca de que el producto entre la distribución a priori para el parámetro y la verosimilitud de los datos genera un conocimiento de dicho parámetro, por medio de la distribución a posteriori. Zellner (1996) realiza la construcción del modelo de regresión a partir de las premisas: una distribución a priori no informativa: 1/σ, para los parámetros β, τ del modelo, y una distribución normal para los datos; con ello se construye la verosimilitud de la muestra. El producto entre dicha distribución a priori y la verosimilitud genera la a poste riori de dichos parámetros. Seguido a esto, la integral entre la distribución de los datos, multiplicada por la distribución a posteriori, genera la distribución predictiva bayesiana, función finalmente usada para pronósticos de la variable respuesta.
Zellner (1996) propone el uso de una distribución a priori no informativa: 1/σ para los parámetros. La función de verosimilitud de los datos, basada en la distribución normal, está dada por (5):
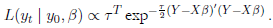 () 5
() 5
Luego del producto entre la distribución a priori por la verosimilitud (5) se obtiene la distribución a posteriori (6):
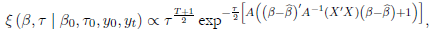 () 6
() 6
donde 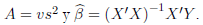
La distribución predictiva, obtenida luego de hacer la integral entre la dis tribución de los datos y la distribución a posteriori (6), es una distribución T de Student (Zellner, 1996), con la cual se generan las estimaciones de la respuesta buscada, en este caso: turistas colombianos y turistas extranjeros, usando X como la matriz de diseño donde se incluyen las covariables.
C. Modelo de regresión Poisson bayesiano
Este modelo parte de las premisas de una distribución Poisson para los datos y una distribución a priori Normal Multivariada para el vector de pará metros β, que permiten obtener una distribución a posteriori de los paráme tros del modelo de regresión. La estimación del modelo puede hacerse con el paquete MCMCpack del programa R (Martin, Quinn & Park, 2011), cuya fun ción MCMCpoisson, permite muestrear los parámetros de dicha distribución a posteriori, usando un algoritmo llamado Metropolis de caminata aleatoria. Con esto se obtienen estadísticas para cada uno de los parámetros, como la media o los percentiles, que se reemplazan como parámetros del modelo de regresión y, de ésta forma, encontrar la respuesta media, que es el logaritmo natural de la serie original de los datos.
En resumen, la base teórica parte de una distribución de los datos, yi
~ Poisson(mui), con la función link inversa para la media mui
= exp(Xβ), y el vector de parámetros β ~ N(b
0, B0
-1). Luego de hacer el producto de la distribución a priori por la de los datos, se obtiene la distribución a posteriori, de la cual se establecen condicionales por cada parámetro, y con éstas se hace el muestreo MCMC. De este modo se obtienen estadísticas de los parámetros β para la función inversa: 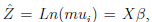 por ejemplo, la media y la mediana, y con cada una de éstas es posible escribir el modelo ajustado, pero es necesario transformar nuevamente la respuesta estimada
por ejemplo, la media y la mediana, y con cada una de éstas es posible escribir el modelo ajustado, pero es necesario transformar nuevamente la respuesta estimada 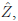 con exp(Z) = mui
en la escala original.
con exp(Z) = mui
en la escala original.
III. Resultados
Variables respuesta: Serie A: Turistas colombianos, Serie B: Turistas ex tranjeros. Periodo: años 2007 a 2014. N = 96, T = 72, periodos de pronós tico: 24 (2 años).
A. Análisis exploratorio
Es común medir la actividad económica por medio del PIB; no obstante, las cifras estadísticas oficiales pueden presentar un sesgo optimista sobre el crecimiento de la economía. Por tanto, se puede interpretar un indicador efec tivo como el IPC para que los agentes económicos de la industria del turismo en Colombia puedan establecer unas asociaciones posibles y, con ello, utilizar dichas relaciones en los procesos de toma de decisiones. Similarmente, la ac tividad económica asociada al consumo de energía puede servir, en general, para diagnosticar si las tendencias del turismo en Colombia se relacionan o no con dicho consumo, sin excluir el sector informal de la economía4, estimando su efecto con los modelos que se presentan aquí.
Para alcanzar diagnósticos aceptables, se probaron diferentes variables utilizadas en la literatura, optando por explorar factores e índices que, por su naturaleza, guardan una relación estrecha con el dinamismo de la economía y, por supuesto, con el turismo. Tal es el caso de la cantidad de kilovatios hora de energía gastados en la ciudad en actividades económicas residencial, industrial y comercial para el mes respectivo, covariables que son usadas en la exploración de los modelos clásicos. Sin embargo, como se verá, no todas estas variables muestran asociaciones importantes con el flujo turístico.
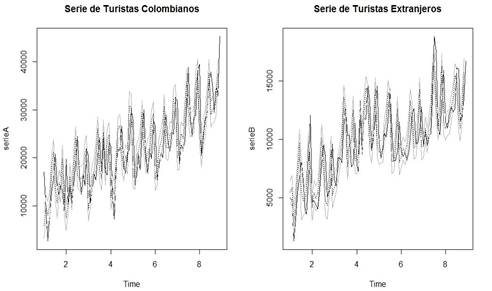
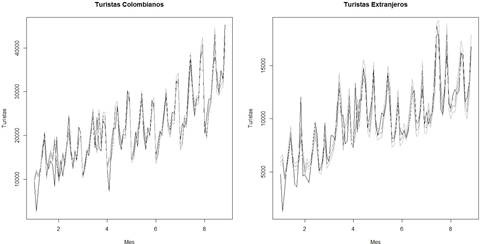
Las series tienen tendencias lineales crecientes, con una variación que po dría ser cíclica (Gráfico 1). La característica de las variables discretas puede ocasionar que sea necesaria una transformación en los datos para inferir acer ca de su comportamiento; sin embargo, para efectos de comparar la capacidad predictiva del modelo regresivo normal con el bayesiano, no se realizará dicha transformación.
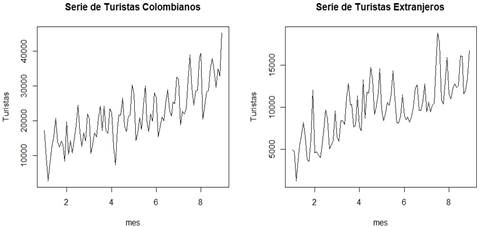
La serie A (turistas colombianos) presenta autocorrelación estacional, tal como se aprecia en los valores de autocorrelaciones significativas saliendo de las bandas de confianza, en los periodos estacionales semestrales en el Gráfico 2. Similarmente ocurre para la serie B (turistas extranjeros). Las característi cas encontradas en las series temporales muestran la necesidad de incorporar componentes que modelen estacionalidad y correlación (como variables auto rregresivas), así como variables indicadoras (que toman valores 1 o 0) (como el mes del año) o trigonométricas (senuidal o cosenoidal), probando hasta en contrar las variables con mayor significancia en el modelo. Si bien las series evidentemente no son estacionarias, dado que los valores de autocorrelación de los periodos entre 1 y L son estadísticamente diferentes de cero (ver Grá fico 2), la estimación del modelo de regresión tiene grandes ventajas por la inclusión de covariables que permiten modelar los componentes estacionales, como variables indicadoras y variables rezagadas que capturan este tipo de comportamientos y correlación de la serie. De esta manera se pueden generar residuales incorrelacionados, como se demuestra con el análisis presentado.
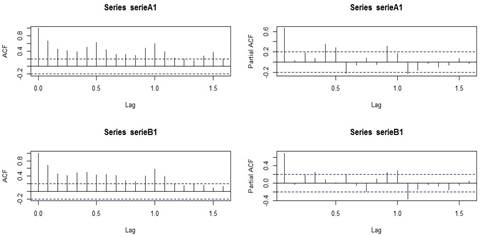
Gráfico 2 Autocorrelación y autocorrelación parcial para las series de tiempo: turistas colombianos, extranjeros
Al realizar un análisis del comportamiento de variables, como IPC, y el gasto energético de actividades económicas, como residencial e industrial (ver Gráfico 3), se aprecia un aparente grado de disminución en el tiempo, lo que es contrario a las series de turistas que tienen tendencia a incrementarse.
Gráfico 3 Comportamiento de variables explicativas IPC, actividad económica residencial, actividad económica industrial
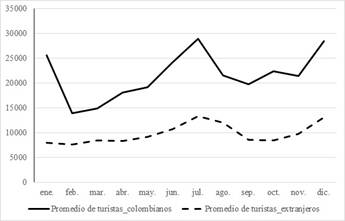
La exploración de los promedios de turistas por mes, que se observan en el Gráfico 4, refuerza el análisis de la incidencia de dicho factor sobre las series, pues se aprecia que en los meses de junio, julio, enero y diciembre es mayor el total de turistas colombianos, mientras que en los meses de julio, agosto y diciembre vienen más turistas extranjeros, ya que estos meses corresponden a las vacaciones de los países respectivos.
B. Modelo lineal econométrico
Los modelos se estiman tomando en consideración la autocorrelación de tectada previamente, para ello se incluyen rezagos de la misma serie; para la estacionalidad detectada, se incluye el mes como variable indicadora. Estos modelos ayudan de manera exploratoria a detectar los efectos más signifi cativos en relación con las covariables mencionadas, y con éstas mismas se pueden ajustar los modelos bayesianos posteriormente.
La Tabla 1 muestra las tablas ANOVA tipo III estimadas para cada una de las series analizadas con los modelos de regresión.
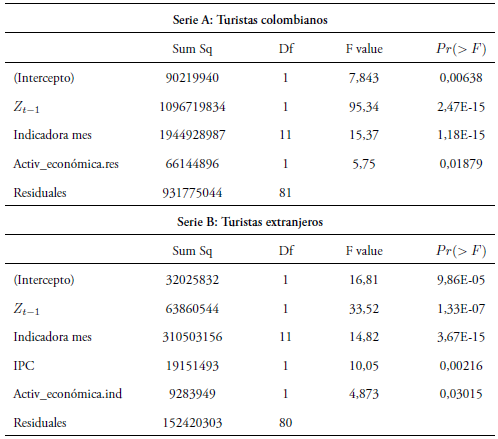
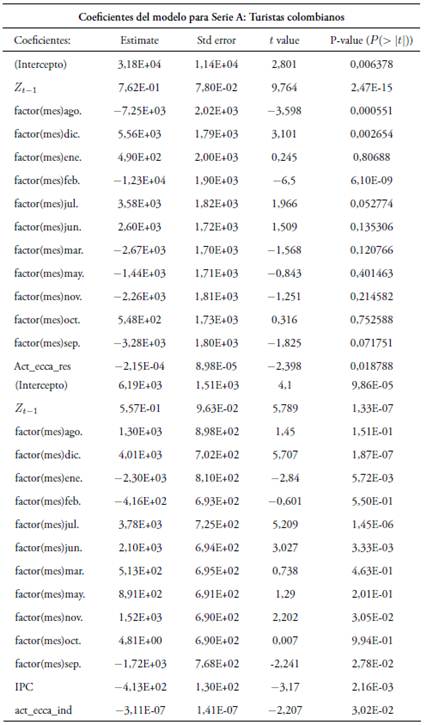
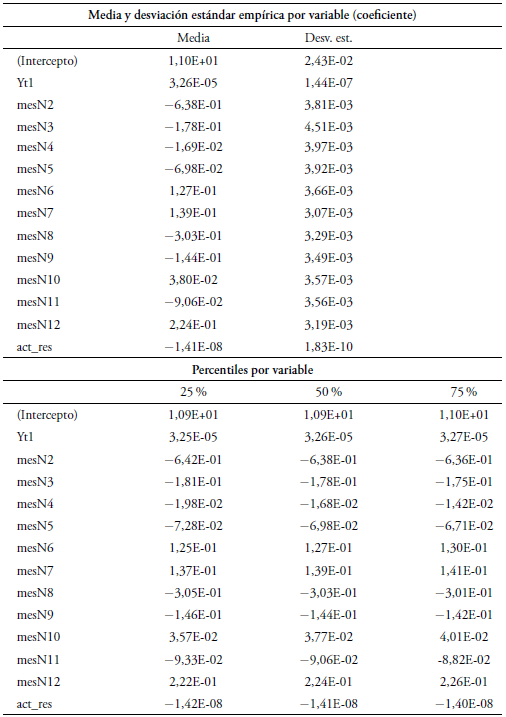
En las tablas ANOVA se aprecia que todas las variables quedan signifi cativas para explicar la respuesta (valor p < 0, 05) en los respectivos mode los, luego del proceso de selección por pasos. Los coeficientes estimados se aprecian en la segunda columna de la Tabla 2. El rezago de orden 1 (Zt−1) es significativo para explicar la cantidad de turistas, tanto colombianos co mo extranjeros, lo cual indica la dependencia con respecto al valor del mes anterior.
La Tabla 3 presenta los indicadores de ajuste para cada modelo estimado.

La tabla 3 muestra, en la primera línea, los valores MAPE de ajuste para el modelo de regresión clásica. El menor valor de error MAPE se da en la serie de los turistas extranjeros, con 14 %, y los colombianos, con 15 %. La incorrelación en todos los residuales se cumple; es decir, los residuales tienen estacionariedad, pero no se comportan bajo la distribución normal, en los dos primeros modelos de las series de turistas (valor p< 0, 05). Los residuales no se comportan con dicha distribución porque existen puntos atípicos que lo implican, pero no deben eliminarse porque, de hecho, su información es muy valiosa para la estimación de estos modelos. Se hacen transformaciones de las variables respuesta como logaritmo natural, raíz cuadrada y potencia de Box Cox. Sin embargo, ninguna mejora el problema de no normalidad5.
En el Gráfico 5 se aprecian los valores observados (en negro), el ajuste (en línea punteada) de los modelos finales econométricos estimados para las series de turistas colombianos y extranjeros, y los respectivos intervalos de confianza al 95 %, bajo la distribución normal (en gris). Aunque se aprecia la mayoría de valores reales (en negro) dentro de los intervalos quedan por fuera algunos un poco extremos.
C. Modelos de regresión bayesiana
1) Regresión bayesiana basada en la distribución normal para los datos
Las variables explicativas que fueron encontradas significativas en el mo delo de regresión anterior, que reflejan el comportamiento que se visualizó en el análisis de autocorrelación, serán incluidas en estos modelos de regresión Bayesiana. En el primer modelo Bayesiano ajustado, se utiliza la fórmula con las covariables: rezago de orden 1, tiempo (tendencia), y como variable esta cional, el mes. En el Gráfico 6 se aprecia la línea de valores reales (en negro) vs valores ajustados (en línea punteada), para cada una de las series de tiempo de izquierda a derecha: turistas colombianos y extranjeros, con los respectivos intervalos del 95 % de probabilidad (en gris) de la distribución predictiva T de Student, con la cual se realizan los pronósticos.
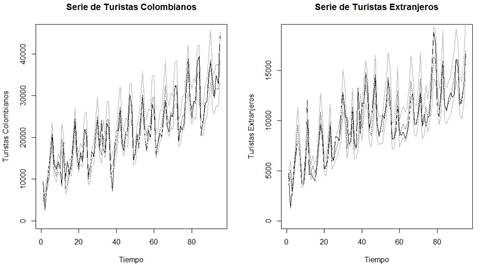
Gráfico 6 Ajuste de los modelos de regresión bayesianos bajo la distribución normal para los datos Nota: Intervalos del 95 % (límites bilaterales, en los percentiles 2,5 % y 97,5 %).
El ajuste del modelo bayesiano visto en el Gráfico 6 se basa en el percentil 50 de la distribución predictiva T de Student del modelo con la cuarta ecuación de la Tabla 4. Se observa cómo el ajuste se acerca mucho a la línea de datos reales. Además, los intervalos son un poco más amplios que los del modelo clásico y contienen más valores reales que los intervalos de éste.
Se estimaron diferentes modelos de regresión bayesiana con la distribu ción no informativa explicada en la sección I.B. Se usaron los percentiles 25 %, 50 % y 75 % de la distribución predictiva para encontrar diferentes valores ajustados acorde con cada ecuación previamente establecida y así determinar el mejor valor posible. Se estiman tres indicadores, MAPE, sMAPE, RMSE, con todos los valores observados vs los estimados. Estos resultados se mues tran en la Tabla 4.
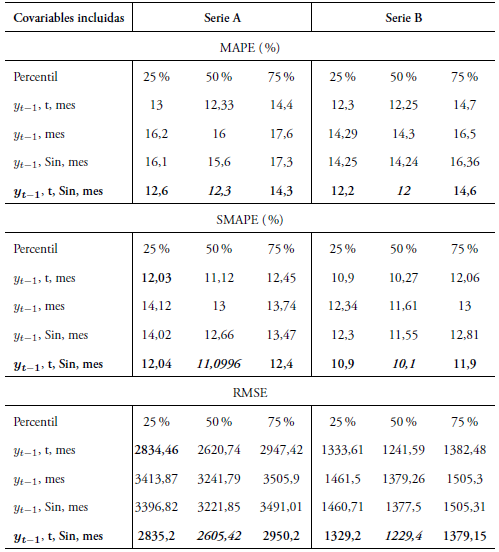
Los mínimos indicadores hallados son menores que los encontrados para el modelo de regresión econométrico de la Tabla 3, para los tres indicadores, siendo la cuarta la mejor ecuación de covariables: y t−1, t, Sin, mes (tabla 4). Los datos señalados en cursiva para esta ecuación en cada serie son los mejores, los cuales corresponden a la mediana (50 %). Los tres indicadores coinciden en el resultado, lo cual muestra la efectividad que tienen para este tipo de valores tan altos en las series de tiempo.
2) Regresión bayesiana basada en la distribución Poisson para los datos
Tomando en cuenta los resultados de significancia determinados con los modelos de regresión para las series de turistas, se usaron las covariables fi nales de mayores efectos sobre la respuesta para estimar los modelos de re gresión Poisson bayesiana, vía MCMC, llegando a los siguientes resultados.
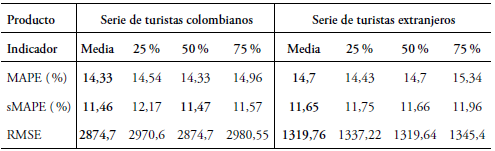
Los coeficientes se simulan de la distribución a posteriori, y la salida de R provee estadísticas de dichas muestras de cada coeficiente, como la media y diferentes percentiles. Con cada percentil es posible ajustar los valores de la regresión Poisson bayesiana. La Tabla 5 muestra la salida de R para la serie de datos de turistas colombianos, una tabla similar sale para la serie de turistas extranjeros, pero con las variables IPC y actividad económica industrial, como las variables encontradas para el modelo clásico. Con los valores de las medias y los percentiles 25 %, 50 % y 75 %, se pueden estimar 4 modelos por cada serie, cuyos indicadores de error MAPE, sMAPE y RMSE se muestran en la Tabla 6.
En la Tabla 6 se aprecian indicadores más altos que los encontrados en los modelos anteriores. Sin embargo, no son valores muy malos en compara ción con la regresión bayesiana anterior, pero son mejores que los del modelo clásico. Lo anterior podría dejar este modelo como alternativa frente a otros casos de datos discretos que no tengan escalas muy altas para aproximar el modelo de regresión bayesiana bajo la escala normal.
Tabla 6 Indicadores de error de los modelos de la regresión Poisson bayesiana
Fuente: elaboración propia.
En el Gráfico 7, donde se aprecia el ajuste en línea punteada y límites de confianza en color gris, se observan un poco más datos por fuera de los inter valos estimados para este modelo vía MCMC, situación que en los anteriores modelos puede derivar en mayores errores al pronosticar.
IV. Discusión
Es importante notar que la regresión Bayesiana, tanto el modelo baye siano basado en la aproximación normal de los datos como el basado en la distribución Poisson con muestreo por MCMC, puede proporcionar un re sultado adecuado para predecir demandas turísticas, en modelos con cova riables muy similares a las encontradas en la regresión clásica, con mejores indicadores de error de ajuste. Modelos que también pueden ser comparados con otros como los usados con distribución empírica, binomial negativa, de regresión Poisson con bootstrap, en (Kolasa, 2016), o modelos dinámicos li neales, o incluso, con intervención de expertos, aspecto que incrementaría la información para realizar planeación de recursos y disponibilidades hoteleras por mes, mejorando las posibilidades de ingresos.
Conclusiones
Se encontraron modelos con adecuada representación de la variación tem poral de las series de turistas que llegan a Medellín, colombianos o extranje ros, diferentes a los modelos clásicos, basados en Estadística Bayesiana. Así mismo, se hallaron indicios de comportamientos estacionales, reflejados en la presencia de la variable indicadora mes, además, se encontró un impacto significativo del valor de turistas rezagado de orden 1, para explicar el com portamiento de la cantidad de ambos tipos de turistas que llegan a esta ciudad, es decir, tiene una dependencia temporal de primer orden. Esto permitió ca racterizar el comportamiento de este sector de la economía colombiana, y con ello, ayudar en la planeación de dicho sector.
Al usar los indicadores de errores sMAPE y RMSE -que son muy útiles en casos generales, en especial robustos cuando las respuestas se acercan a cero- se corrobora que el indicador MAPE puede ser apropiado, pero solo en casos en los que los datos toman valores muy altos, como se ve en este trabajo, alrededor de 5000 o más turistas por mes.
La variable mes también es una variable estadísticamente significativa en las demandas de turismo de colombianos y extranjeros, resultado que permite identificar los periodos de mayor incidencia para la planeación de recursos hoteleros. Por ejemplo, para los colombianos, las vacaciones entre diciembre-enero y junio-julio representan temporadas para visitar la ciudad de Medellín, y anualmente se repite dicho comportamiento.
Las asociaciones negativas, encontradas con los gastos energéticos, po drían deberse a diversas razones, una de ellas puede ser que los periodos de mayor flujo turístico son las vacaciones de los sectores educativos; sin em bargo, es necesario usar otro tipo de técnicas investigativas para determinar si hay algún grado de disminución de actividades o alguna otra razón.
Puede considerarse para futuros estudios la planeación de disponibilidad de hoteles en la ciudad, analizando la incidencia del mes, dados los resultados de éste estudio. Con ello, se puede requerir mayores recursos en los meses encontrados con mayor incidencia de los turistas extranjeros, como son: julio, agosto y diciembre, temporadas en que también se programan eventos de ciudad como la feria de las flores, en agosto, y los alumbrados, en diciembre. Por todo esto es importante programar estrategias de atención y cobertura de los servicios requeridos por este tipo de turistas.

