











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
Introducción
Los algoritmos basados en inteligencia artificial brindan un punto de apoyo a los médicos que, en conjunto con el paciente y el resto del equipo multidisciplinario, están en la búsqueda de herramientas que permitan tomar las mejores decisiones posibles.
Un área específica de investigación que sigue en pleno desarrollo para la cirugía torácica es el desarrollo de sistemas de clasificación de riesgo individualizado prequirúrgico. Debido a la constante búsqueda de medios para reducir la morbilidad asociada a los manejos quirúrgicos utilizados en cirugía de tórax, en este estudio abordamos las complicaciones asociadas al manejo quirúrgico del neumotórax desde un enfoque preventivo.
Partiendo de la experiencia en un centro asistencial, basado en características preoperatorias, transoperatorias y postoperatorias, enfocamos nuestro algoritmo para generar un modelo de red neural artificial que lleve a seleccionar la mejor técnica de abordaje del neumotórax, permitiéndonos en tiempo real determinar cuáles son las variables que influyen en una menor incidencia de complicaciones postoperatorias, y así generar una herramienta complementaria para apoyar el juicio clínico en favor de un mejor resultado para el paciente.
Métodos
Diseño del estudio
Estudio observacional retrospectivo, realizado en el Servicio de Cirugía Torácica del Hospital Santo Tomás en la ciudad de Panamá, República de Panamá. El universo correspondió a todos los pacientes admitidos con diagnósticos de neumotórax, primario o secundario, que requirieron manejo quirúrgico, entre enero de 1991 y diciembre de 2016. La decisión sobre el tipo de cirugía fue tomada de acuerdo con la experiencia del cirujano y el método quirúrgico recomendado en la literatura internacional. Todos los pacientes de la cohorte estudiada fueron operados por el mismo cirujano, lo cual minimizó la heterogeneidad del procedimiento y evitó el efecto de distintas curvas de aprendizaje en los resultados.
Los pacientes se dividieron en dos grupos, con neumotórax primario (NP) y neumotórax secundario (NS). Los datos clínicos recolectados para el análisis estadístico incluyeron: sexo, edad, persistencia del neumotórax, recurrencia del neumotórax, año en el cual se realizó la cirugía, procedimiento quirúrgico realizado, sangrado intraoperatorio, complicaciones, presencia de fuga prolongada y días intrahospitalarios. Adicionalmente se colectaron los datos de la realización de pleurodesis, bien fuera con talco, abrasión, pleurectomía o tienda pleural, para el análisis de subgrupos. Para el cálculo de la estancia intrahospitalaria ajustada se excluyeron a los pacientes con una estadía mayor de 14 días y los pacientes de los cuales no se disponía la información.
Base de datos
En este estudio se utilizó como fuente de información una base de datos creada por los médicos de la Sección de Cirugía Torácica, mediante el registro de la información retrospectiva obtenida de los expedientes físicos en un documento en formato xlsx del programa Microsoft Excel® (Microsoft Corporation, Redmond, USA). Para poder utilizarlos como base de datos en el modelo de inteligencia artificial se procedió a cambiar el formato en un archivo de tipo csv o valores separados por comas, por sus siglas en inglés.
Mediante el lenguaje de programación Python (Python Software Foundation, Delaware, USA) versión 3.9.6, se procedió a la transformación secuencial de datos, eliminando primero los caracteres especiales, creando luego un diccionario que transformara las abreviaturas en palabras, y posteriormente reduciendo a letras minúsculas todas las letras contenidas en la información de cada variable. Se eliminaron las celdas vacías creando columnas con información completa sin valores vacíos, con el mismo formato de texto y datos válidos para ser procesados. Una vez los datos fueron limpiados, se procedió a usar la librería de Python pandas (Python Data Analysis Library) versión 1.4.1, para transformar la información a un data frame, que sirvió como base de datos y punto de partida para almacenar información en variables de prueba y validación, que finalmente fueron utilizadas por nuestros modelos.
Modelo de inteligencia artificial
Nuestro modelo consiste en una red neural artificial cuya representación esquemática se puede apreciar en la Figura 1. Se trata de una red neural de topología multicapas, con una capa de input o variables de ingreso que recibe N variables en su primera interacción. Este número de variables de ingreso se modifica para obtener distintas variantes del modelo y evaluar la sensibilidad, especificidad y área bajo la curva de cada modelo.
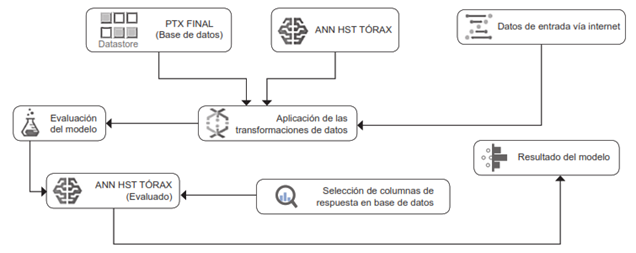
Figura 1. Representación visual del modelo predictivo final al ser desplegado como servicio en línea para evaluación en tiempo real de resultados.
El modelo inicial constaba de un número de 32 neuronas por capas y 8 capas ocultas. Se usó la función de activación ReLU en las capas intermedias, alternada con funciones sigmoideas en las distintas variantes; igualmente se cambió el número de epochs sobre los cuales sería entrenado el modelo. Estos cambios y las múltiples variaciones se deben al bajo número de datos con el que se contaba, en un intento para obtener diversos modelos y poder compararlos, no sólo entre sí sino también contra modelos que utilizan otros métodos de aprendizaje computacional.
En la última capa o capa de salida se utilizó una función sigmoidea para normalizar los valores en un rango de 0 a 1. Para la tarea de clasificación se usó la pérdida de entropía cruzada binaria, con el optimizador Adam y un tamaño del grupo o batch size de 512. Este modelo inicial fue modificado en múltiples variaciones y contrastado con otros modelos para reportar los datos obtenidos de la comparación estadística de modelos y los resultados clínicos sugeridos por el mejor modelo.
Entrenamiento del modelo
El proceso de entrenamiento se realizó usando datos obtenidos del data frame creado inicialmente, el cual se dividió de forma aleatoria usando el módulo test_train_split de la librería scikit-learn en su versión 1.0.2. Se crearon 4 variables denominadas x_train, x_test, y_train y y_test, a las cuales se les asignó el 75 % de los datos disponibles en las variables de entrenamiento; a las variables de prueba, que serían usadas para validar el modelo, se les asignó el 15 % de los datos restantes.
Luego de obtener el primer modelo, el cual ya fue descrito y se le asignó en nombre ptx pred 0.0.1, se procedió a realizar el entrenamiento y validación con los datos obtenidos y ajustarlo al menor error medio con la mayor precisión y puntuación F1. A cada variación de este modelo se le dio un nombre similar, aumentando en uno el final numérico del mismo, así obtuvimos los modelos ptx pred .2, .3, …, n. Cabe destacar que para cada variación del modelo se llevó a cabo una nueva distribución aleatoria de datos para asegurar un desconocimiento constante de los resultados por parte del modelo y enmascarar variables, lo que permitió que a pesar de tener un número relativamente pequeño de muestra, las mismas funcionaran de forma aleatoria para entrenar múltiples modelos, evitando la sobrealimentación del modelo o que el modelo aprendiera de antemano las respuestas esperadas, lo que lo convertiría en un modelo obsoleto al enfrentarse a datos desconocidos. Para asegurar que los modelos se enfrentarán a datos no evaluados en la etapa de entrenamiento, el 10 % de los datos restantes se mantuvo fuera desde la primera aleatorización y se usó como medio de validación para evaluar los resultados finales de los distintos modelos y sus múltiples variaciones.
Análisis estadístico
El análisis estadístico se realizó usando el programa SPSS (IBM, SPSS Inc, Chicago, USA) versión 17.0. Los datos categóricos se presentaron como frecuencias y porcentajes, la comparación se hizo utilizando la prueba de Chi cuadrado (prueba de dos proporciones N-1) y la prueba exacta de Fisher. Los datos paramétricos y no paramétricos continuos se presentaron como medias y desviaciones estándar (SD) y fueron evaluados utilizando las pruebas t de Student y U de Mann-Whitney respectivamente. Para el análisis de subgrupos, se dividieron en toracotomía abierta (TOR) y toracoscopia video asistida (TV). Debido al tamaño de nuestra muestra, en algunos subgrupos los cálculos de intervalos de confianza se realizaron utilizando el ajuste de intervalo de Wald. El valor de p menor de 0,05 fue considerado estadísticamente significativo.
Resultados
Según nuestros criterios de inclusión, en el periodo comprendido entre enero de 1991 y diciembre de 2016, un total de 106 pacientes requirieron manejo quirúrgico por neumotórax (primario o secundario). En la Tabla 1 se presentan los datos demográficos de esta población de estudio; cabe destacar que 70 pacientes fueron manejados por TOR y 36 pacientes por TV. Este es un aspecto importante para destacar ya que, si analizamos los datos como una serie de tiempo, podemos ver cómo ocurre un cambio en la relación TOR vs. TV. En los últimos quince años el uso de la VT fue muy superior a la TOR, en una relación de casi 4:1.
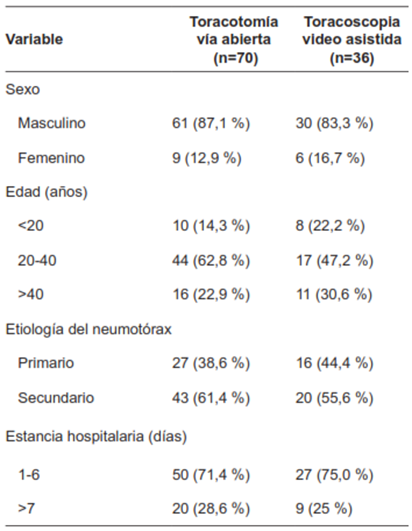
Se obtuvo un modelo, el cual fue denominado modelo predictivo final de red neural artificial. Este fue el mejor modelo estadístico y, por lo tanto, el modelo utilizado para el análisis posterior, ya que alcanzó una precisión media de 95,4 %, con un área bajo la curva de 0,991, con una desviación estándar de 0,064 y un valor de p de 0,003 (IC95% 0,877 - 0,992).
Entre las variables preoperatorias se pudo observar que la mayor contribución para el desarrollo de complicaciones postoperatorias en el manejo quirúrgico del neumotórax, basado en el peso independiente de las variables en el modelo, la tuvieron la edad (4,2 %), el neumotórax secundario (3,8 %) y el neumotórax derecho (3,5 %) (Tabla 2). Sin embargo, durante el análisis multivariado de regresión logística con la ocurrencia de complicaciones, sólo el neumotórax secundario alcanzó significancia estadística de forma individual (OR=0,524; p=0,05).
Tabla 2. Variables preoperatorias y su relación con el desarrollo de complicaciones postoperatorias en pacientes con manejo quirúrgico de neumotórax.
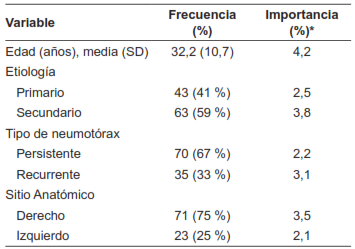
*Porcentaje de importancia que tiene la variable (peso dentro de la red neural) en relación con las otras variables computadas por el modelo.
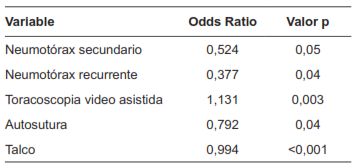
Con respecto a las variables trans y postoperatorias que se describen en la Tabla 3, la mayor significancia estadística la tuvieron el tipo de cirugía (14,1 %), el uso de autosuturas (5,2 %) y el uso de talco para la pleurodesis (11,9 %). En la regresión logística, los factores predictores independientes asociados a menor riesgo de complicaciones fueron TV (OR=1,131; p=0,003), utilizar autosuturas (OR=0,792; p=0,04) y usar talco para la pleurodesis (OR=0,994; p<0,001) (Tabla 4).
Tabla 3. Descripción de las variables trans y post-operatorias.
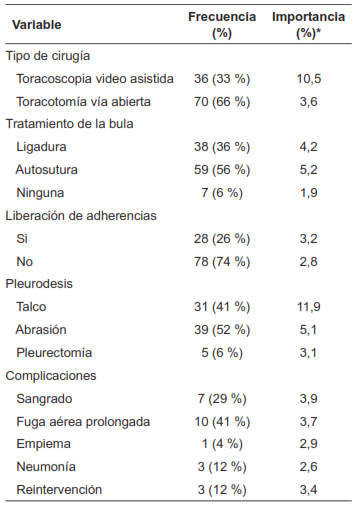
*Porcentaje de importancia que tiene la variable (peso dentro de la red neural) en relación con las otras variables computadas por el modelo.
Nuestro modelo definitivo de red neural presenta un área bajo la curva de 0,991 (p=0,003) con una precisión de 95,4 %.
Discusión
En los pacientes pertenecientes al grupo de riesgo normal con patologías torácicas cuyo manejo requiere intervenciones quirúrgicas podemos esperar hasta un 5 % de complicaciones postoperatorias 1. Debido a que el área de los sistemas de clasificación de riesgo personalizados en cirugía de tórax es un área en desarrollo y todavía no se han publicado estudios que generen la información necesaria para establecer sistemas de clasificación de riesgo individualizados 2, a la fecha no se cuenta con un punto de referencia estadístico desarrollado en un estudio previo para contrastar sus resultados con algún modelo similar al nuestro.
Múltiples estudios citan la necesidad de llevar a cabo investigaciones prospectivas para determinar el mejor abordaje quirúrgico y la mejor técnica de pleurodesis, en caso de ser necesario, para tener el menor porcentaje de recurrencia y complicaciones postoperatorias 3-5, sin embargo, faltan estudios que determinen cuáles son las variables independientes asociadas a una mejor evolución clínica o que permitan la utilización de un sistema de medición de riesgo individualizado, que pueda ser aplicado a cada paciente como un ente propio, y no categorizarlo en un grupo de riesgo cuyas heterogeneidades pueden crear sesgos en contra del beneficio del paciente 5.
En la actualidad, en todos los campos de las ciencias hay múltiples modelos predictivos basados en sistemas de inteligencia artificial 6-8, ya que el análisis de bases de datos a través de redes neurales permite encontrar relaciones no lineales, que no son perceptibles a través de los métodos estadísticos tradicionales, además de crear sistemas que por medio de la transferencia de conocimiento se puedan aplicar en forma individualizada, brindando un cálculo de riesgo-beneficio para nuestro paciente en base a sus características únicas, lo que permite una medicina de mayor precisión y, teóricamente, mejor probabilidad de reducir la morbilidad asociada al tipo de procedimiento quirúrgico seleccionado para el manejo del neumotórax.
Nuestros hallazgos con respecto a las variables predictivas independientes coinciden con los reportados por Cardillo y colaboradores 8, donde las indicaciones más frecuentes para realizar video toracoscopia y pleurodesis con talco fueron el neumotórax recurrente (92,2 %) y la persistencia de fuga de aire (6,5 %), con un 2,0 % de complicaciones. Como lo describen Hallifax y colaboradores 9, no hay estudios aleatorizados prospectivos que evalúen la eficacia de la pleurodesis con talco vía VT, pero sí hay estudios retrospectivos en los cuales se demuestra una menor estancia hospitalaria y un menor número de complicaciones en los grupos a los que se le realizó pleurodesis con talco comparado con abrasión (p=0,116).
En nuestro estudio, el modelo definitivo de red neural satisface los criterios estadísticos de los objetivos planteados. Es relevante describir que se llegó a la significancia estadística a pesar de haber sido generado de una base de datos pequeña, lo que concuerda con estudios previos 10-11 en los cuales se plantean algoritmos para obtención de datos y mejora significativa de las características predictivas de las redes neurales, utilizando algoritmos optimizados para encontrar relaciones de causalidad entre variables a pesar de disponer de base de datos pequeñas.
Limitaciones del estudio
Existen varias limitaciones esperadas en nuestro estudio, ya que al depender de un sistema de datos extraídos manualmente de expedientes clínicos no digitalizados existe la posibilidad de error humano y pérdida de información, lo que se traduce en celdas vacías, que terminaron siendo eliminadas en el procesamiento de datos, perdiendo así posible información valiosa, que pudo o no haber modificado el resultado del modelo hacia una recomendación u otra.
Otra limitante de nuestro estudio es el tamaño de la muestra, ya que nos encontramos en la era del “big data” en la que muchos consideran que para entrenar un modelo se debe disponer de millones de datos10. En nuestro caso nos enfrentamos a un problema opuesto, el riesgo de infra alimentación de datos o “underfitting” 10,11,12. Sin embargo, con las técnicas de minería de datos, los cambios en los grupos de las variables que utilizamos como puntos de ingreso y cambios en los hiper parámetros, pudimos obtener un modelo con una respuesta estadísticamente significativa a partir de un pequeño número de datos 10,11.
Conclusión
En nuestra serie de pacientes, la toracoscopia video asistida, el uso de autosutura y la pleurodesis con talco fueron las variables que se asociaron a menor riesgo de complicaciones. Estos hallazgos, vistos desde la perspectiva de la introducción de nuevos métodos de análisis y síntesis de información, con las correspondientes limitaciones del estudio, muestran los beneficios que se podrían tener sobre una población de pacientes, permitiendo la evaluación como individuos con riesgos ajustados a sus comorbilidades, generando así mejores resultados postquirúrgicos.
Está claro que este estudio fue realizado con una muestra limitada y que es requerida validación externa, por lo cual consideramos de vital importancia la realización de un estudio prospectivo multicéntrico, para evaluar los cambios requeridos para obtener el mejor modelo posible y así, que el mismo se constituya en una herramienta de aprendizaje no supervisado con parámetros específicos, que sirva de apoyo en la toma de decisiones e influya positivamente en el desenlace postoperatorio de nuestros pacientes, reduciendo la morbilidad asociada a los procedimientos.

