











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
Permalink
Introducción
La curiosidad ha sido un tema ampliamente analizado durante más de un siglo en el campo de la psicología (Kashdan & Silvia, 2009), debido al impacto positivo y negativo que tiene sobre el comportamiento humano durante todas las etapas del desarrollo y su importante implicación en la educación. Las investigaciones sobre la curiosidad se dividen en dos grandes etapas (Loewenstein, 1994). La primera a inicios de la década de 1960, centrándose específicamente en tres cuestiones: (1) determinar las causas subyacentes de la curiosidad, (2) reflexionar sobre el porqué las personas buscan deliberadamente la curiosidad y (3) identificar los determinantes situacionales de la curiosidad. Aunque este período de investigaciones terminó sin lograr un gran impacto en la psicología, más adelante, a partir de 1970 y hasta finales de la década de 1980, la segunda etapa se centró en medir la curiosidad, y aunque no se logró producir escalas confiables y válidas, se hicieron aportes teóricos que intentaron definir a qué hace referencia la curiosidad, desarrollando diversas clasificaciones de este concepto.
No obstante, una deficiencia esencial de las tres grandes vertientes teóricas sobre curiosidad -las teorías pulsionales, la perspectiva de la incongruencia y el enfoque de la competencia-, desarrolladas en el período mencionado, es que, por separado, proporcionan una perspectiva incompleta de la curiosidad humana, y aún más importante, parece que las causas subyacentes de la curiosidad quedan sin respuesta (Loewenstein, 1994). Con base en estas limitaciones, Litman y Jimerson (2004) desarrollaron la noción de Curiosidad Epistémica (CE), originalmente propuesta por Berlyne (1954). El concepto CE hace referencia al deseo que motiva a las personas a adquirir nuevo conocimiento (i.e., conceptos, ideas y hechos), y eliminar lagunas de información con la finalidad de estimular sentimientos positivos de interés intelectual para reducir los estados indeseables de falta de información (Litman, 2008, 2019). Las fuentes de motivación para la CE son dos (Litman, 2005, 2007). Por un lado, tal como propone la teoría del nivel óptimo de excitación, las personas pueden ser curiosas porque consideran el aprendizaje de algo nuevo como algo emocionalmente gratificante y placentero (CE Tipo-I). Por otro, como asumen los teóricos de la pulsión, las lagunas de información producen sentimientos desagradables de incertidumbre, que las personas buscan reducir mediante la exploración y el aprendizaje (CE Tipo-D). La Tabla 1 muestra una perspectiva general de este constructo.
Investigaciones previas muestran que, en el contexto escolar la CE Tipo-I está asociada con metas de logro orientadas a la maestría, las cuales conducen a un mayor interés y compromiso; mientras que la Tipo-D predice las metas orientadas al desempeño o rendimiento, para las que la corrección, precisión y relevancia del conocimiento recién adquirido son aspectos fundamentales (Litman, 2008).

En el lugar de trabajo, la evidencia disponible señala que la CE Tipo-I estimula la motivación para desarrollar nuevas habilidades, y la Tipo-D impulsa la búsqueda de información necesaria para hacer frente a problemas o situaciones novedosas (Litman et al., 2010).
De manera adicional, estudios recientes señalan a la curiosidad como una de las virtudes cognitivas o epistémicas que los ciudadanos de una sociedad democrática moderna deben poseer (Kahan et al., 2017; Orona & Pritchard, 2022). En particular, porque las personas con un alto nivel de curiosidad tienden a explorar múltiples fuentes de información que pueden contradecir sus creencias prestablecidas, poniendo en marcha estrategias cognitivas y metacognitivas que les permiten informar sus juicios epistémicos (Barzilai & Chinn, 2018). Esto hace que la curiosidad sea un elemento importante, en un mundo en el que la adopción de creencias epistémicamente injustificadas (Lobato et al., 2014), como la ideología de la tierra plana (Landrum et al., 2021) y la confianza en las noticias falsas (Molina et al., 2022), son fenómenos que van en aumento. Tendencia que ha promovido esfuerzos para incorporarla, como parte del currículo escolar y la formación de los individuos (Chinn et al., 2021; Orona & Pritchard, 2022).
Dicho lo anterior, es importante contar con escalas de curiosidad que hayan sido validadas psicométricamente, en el mayor número de contextos posible. En este sentido, la de Litman ha sido analizada en siete estudios (Huang et al., 2010; Karandikar et al., 2021; Litman, 2008; Litman et al., 2010; Litman & Mussel, 2013; Piotrowski et al., 2014), utilizando su versión original en inglés, así como traducciones al alemán, chino, hindi y neerlandés. En todos ellos, se contrastó un modelo unifactorial con uno bifactorial y se encontró que el segundo tuvo siempre un mejor ajuste. Adicionalmente, la consistencia interna fue muy buena (a > .70), al igual que las cargas factoriales (> .45).
Los hallazgos de estas investigaciones indican que, muy probablemente, la escala de CE I/D posee: (1) la estructura teórica propuesta, (2) una buena consistencia interna en sus dos dimensiones, así como (3) ítems con correlaciones entre moderadas y altas con la CE. No obstante, la mayoría de las validaciones psicométricas del inventario de CE (71%) se han realizado en sociedades educadas, industrializadas, ricas y democráticas, como las de EE. UU., Alemania y los Países Bajos, y sólo dos en comunidades de otra índole como China (Huang et al., 2010) e India (Karandikar et al., 2021).
En consecuencia, es necesario evaluar la escala fuera de contextos anglosajones o europeos, pues la evidencia señala que la estructura de constructos que se creían universales, como la de los cinco grandes factores de la personalidad, no se ha podido replicar, cuando se han estudiado en sociedades de pequeña escala, en algunos países de bajos ingresos y para ciertas lenguas (Smaldino et al., 2019).
El presente estudio representa el primer esfuerzo que evalúa psicométricamente el inventario de CE I/D en un contexto mexicano e hispanohablante. Los objetivos de la investigación son los siguientes: (1) comparar dos modelos estructurales de CE, el unidimensional y el bidimensional, que han sido evaluados en estudios previos; (2) examinar los residuales correlacionados entre ítems, pues este tipo de asociaciones se han observado en las versiones china (Huang et al., 2010) y neerlandesa (Piotrowski et al., 2014) del inventario, lo que puede afectar negativamente el ajuste de los modelos y producir estimaciones de consistencia interna infladas (Flora, 2020; Heene et al., 2012; Pascual-Ferrá & Beatty, 2015); (3) evaluar la invarianza configural, métrica, escalar y estricta (Putnick & Bornstein, 2016; Van de Schoot et al., 2012), con respecto al género o sexo.
Método
Diseño o tipología del estudio
Aunque existen varios sistemas de clasificación para los diseños de investigación empírica en psicología, en este estudio se utilizó la desarrollada por Ato et al. (2013). En tal sentido, se realizó una investigación instrumental, que es una categoría en la que se incluyen todos aquellos trabajos que analizan las propiedades psicométricas de nuevos instrumentos de medida o de pruebas ya existentes, que han sido traducidas y adaptadas.
Participantes
El presente estudio utilizó una muestra de conveniencia compuesta por 334 personas mayores de edad (245 mujeres y 89 hombres) de la zona urbana de la ciudad de Culiacán, capital del estado de Sinaloa, en el noroeste de México. El rango de edad fue de 18 años a 50 años (m=33, DE = 9). La escolaridad de los participantes se distribuyó de la siguiente manera: 6% primaria, 14% secundaria, 20% bachillerato, 6% carrera técnica, 58% licenciatura y el 1% posgrado. Por lo que la muestra no es representativa de la población en la que se aplicó el instrumento, ya que no se implementó ninguno de los tipos de muestreo probabilístico reconocidos en la literatura (Sarstedt et al., 2018). No obstante, aun con sus limitaciones, el muestreo por conveniencia es un método de captación de participantes aceptado en investigaciones en educación y psicología (Mosleh et al., 2021; Wootton et al., 2022). Únicamente se incluyeron personas mayores de edad, debido a que el inventario original en inglés está diseñado para esta categoría de individuos, y no hay adaptaciones para niños y adolescentes.
Instrumentos
Se utilizó la Escala de Curiosidad Epistémica (Epistemic Curiosity Scale, SCE) de Litman et al. (2010), traducida al español de México. La escala está conformada por 10 ítems, divida en dos subdimensiones: CE Tipo-I (5 ítems) y CE Tipo-D (5 ítems). El intervalo de respuesta en la escala Likert es de 1 = casi nunca, 2 = a veces, 3 = a menudo y 4 = casi siempre. La Tabla 2 muestra ejemplos de ítems para ambos tipos de CE.
Procedimiento
La adaptación lingüística de la escala se hizo en cuatro etapas. En la primera, un grupo de investigadores -hablantes nativos de español del campo de la educación, con dominio del idioma inglés-, realizó una traducción directa de la escala del inglés al español (American Educational Research Association et al., 2014; González-Bueno et al., 2017). En la segunda etapa, otro grupo de investigadores -hablantes nativos de inglés con dominio del español- hizo una traducción inversa o retrotraducción del español al inglés (Sierra et al., 2013), para verificar y precisar la estructura semántica de los ítems. En un tercer momento, considerando las modificaciones surgidas de las traducciones se implementó la estrategia de jueces inter pares, con la finalidad de llegar a un consenso en la estructura del instrumento. Por último, se realizó una prueba piloto con el objetivo de detectar problemas de claridad y compresión en el instrumento (Reyes-Sosa & Molina-Coloma, 2018; Streiner & Norman, 2008), concluyéndose, con base en los comentarios obtenidos, que no se debía alterar la redacción de los ítems.
El cuestionario en su versión final se administró mediante la plataforma Google Forms y se envió a los participantes a través del correo electrónico y WhatsApp, entre el 20 y el 31 de agosto del 2021. Es importante especificar que previo al envío del cuestionario, a cada participante se le presentó el estudio y su finalidad. Así, una vez autorizaban participar se les solicitaba su información para enviarles el cuestionario. Al inicio del cuestionario se presentó una explicación del propósito de la investigación, y se les invitó a evaluar cada enunciado según su respuesta conforme a la escala. Además, se presentó un formato de consentimiento informado en donde se explicaba a los participantes que todas sus respuestas eran anónimas y que los resultados del estudio serían utilizados solo con fines académicos.
Aspectos éticos
El consentimiento informado y el procedimiento de la investigación se ciñeron a los lineamientos éticos de la Declaración y Acuerdos de Helsinki, los de la Sociedad Mexicana de Psicología (2010) y de la American Psychological Association (2020), para la investigación con humanos a través de medios digitales. Dado que la investigación es de tipo instrumental -que reúne datos totalmente anónimos a través de Internet y no evalúa constructos psicológicos clínicos-, se considera que no representa riesgos conocidos para los participantes (Sánchez-Villena et al., 2022).
Análisis estadístico de datos
Todos los análisis se hicieron en la versión 4.1.2, del lenguaje R para cálculo estadístico y RStudio como interfaz gráfica. Los análisis factoriales se realizaron mediante los paquetes lavaaan (Rosseel, 2012) y semTools (Jorgensen et al., 2021), en sus versiones 0.6-9 y 0.5-5 respectivamente. La normalidad de los datos se evaluó mediante el paquete mvnormalTest (Zhang et al., 2020), aplicando el test de Mardia para la de tipo multivariante, y el de Shapiro-Wilk para la univariante. No se realizó un Análisis Factorial Exploratorio (AFE), ya que es un método que se debe utilizar si no existe una fuerte justificación a priori para un modelo teórico particular (Auerswald & Moshagen, 2019), y la estructura latente de la escala de Litman ha sido evaluada en siete estudios. Por tanto, se procedió a realizar Análisis Factoriales Confirmatorios para contrastar los modelos.

Sin embargo, el método de estimación no fue el de Máxima Verosimilitud o ML (Maximum Likehood). Este estimador asume que los datos son continuos y se ajustan a una distribución normal multivariada, lo que frecuentemente no es así en las ciencias sociales y del comportamiento. En estas áreas a menudo se emplean escalas con opciones de respuesta que siguen una escala ordinal tipo Likert, las cuales deben tratarse como datos discretos (Shi et al., 2020). Aplicar el estimador ML a la matriz de covarianza de datos categóricos ordenados, introduce errores en la especificación del modelo, produciendo estimaciones de parámetros sesgadas, errores estándar inexactos y una estadística de X 2 engañosa (Sellbom & Tellegen, 2019; Shi et al., 2020; Verhulst & Neale, 2021; Xia & Yang, 2019). Por estas razones, las recomendaciones recientes (DiStefano et al., 2019; Sellbom, & Tellegen, 2019) indican que es mejor realizar un análisis factorial ordinal, mediante una versión con corrección robusta del estimador DWLS (Diagonally Weighted Least Squares), que para este estudio fue el de medias ajustadas WLSM (Weighted Least Squares Means adjusted).
Factores que afectan el ajuste del modelo
Existe una serie de factores que pueden afectar sustancialmente los resultados de los análisis factoriales, y dar lugar a soluciones inadmisibles, como son las cargas factoriales bajas, entre otras consecuencias indeseables. Uno de estos elementos son los valores atípicos multivariantes, es decir, casos con puntaciones extremas en múltiples variables o un patrón atípico de puntuaciones; la recomendación es buscar estos valores antes de realizar análisis factoriales (Bowen & Guo, 2012; Kline, 2015). Para este estudio, los datos atípicos se analizaron mediante el paquete MYN de R (Korkmaz et al., 2014), aplicando el método cuantílico ajustado, basado en la distancia de Mahalanobis, en el que los valores por encima del cuantil 97.5 de la distribución X2 son considerados atípicos (Filzmoser et al., 2014).
Otro factor importante que afecta negativamente el ajuste, así como la consistencia interna, son los residuales correlacionados o correlaciones residuales, es decir, la diferencia entre las covarianzas o correlaciones observadas y las predichas por el modelo, entre cualquier par de ítems (Flora, 2020; Kline, 2015). Estas asociaciones fueron explícitamente modeladas, después de realizar un primer análisis factorial sin ellas, si presentaban valores > | .100| (Bowen & Guo, 2012; Heene et al., 2012; Kline, 2015), comparando posteriormente, los modelos con y sin residuales modelados. Así mismo, debido a que este tipo de correlaciones produce alfas de Cronbach (a) inexactos e inflados (Pascual-Ferrá & Beatty, 2015), se decidió incluir el Omega de McDonald (ω), ya que al añadir estas asociaciones en el modelo factorial, ω es más confiable que a (Flora, 2020; McNeish, 2018). Se puede argumentar que, para datos categóricos el alfa ordinal es un mejor indicador. No obstante, aunque atractiva, esta estadística de fiabilidad es cuestionable y su uso debe evitarse (Chalmers, 2018; Flora, 2020).
Criterios utilizados para evaluar el ajuste del modelo
Para determinar el nivel de ajuste de los modelos se utilizaron los valores propuestos por Doğan y Özdamar (2017), así como por Sideridis y Jaffari (2021), para los índices de bondad de ajuste con excepción del SRMR. Para este último, se usó el valor recomendado por Heene et al. (2011) y por McNeish y Wolf (2021). Adicionalmente, se incorporó el ECYI (Expected Cross-Validation Index), como medida de comparación entre el modelo unidimensional y el bidimensional, en el que el mejor modelo es el que presenta un valor más bajo (King-Kallimanis et al., 2011).
La invarianza configural se evaluó utilizando los valores citados en el párrafo anterior. Sin embargo, no hay consenso acerca de qué índices denotan un mejor ajuste, ni existe un conjunto de valores que puedan ser útiles para todas las situaciones con respecto a la invarianza métrica, la escalar y la estricta (Putnick & Bornstein, 2016). Por tanto, se utilizó la significancia de ΔX2 (p > .05), así como las pautas propuestas por Chen (2007) para cuando los tamaños de muestra son desiguales y el tamaño de cada grupo es menor que 300. Para la invarianza métrica, el modelo tuvo que cumplir con los siguientes requisitos: ΔCFI ≥ -.005, ΔRMSEA ≤ .010, y ΔSRMR ≤ .025. A la invarianza escalar y estricta, se les aplicaron los mismos criterios, con la excepción de ASRMR, que tuvo un umbral más riguroso (≤ .005). Adicionalmente, se consideraron valores de CFI y TLI ≥ .95, junto con un SRMR ≤ .10 (Rutkowski & Svetina, 2014).
Resultados
Análisis descriptivos de los ítems
La Tabla 3 expone los valores del análisis descriptivo y de normalidad de los ítems, el ítem 5 muestra el mayor puntaje promedio (M = 3.25), y el ítem 2 muestra el valor más bajo (M = 2.11).
Tabla 3 Medias, desviaciones estándar, asimetría y curtosis de la Escala de Curiosidad Epistémica
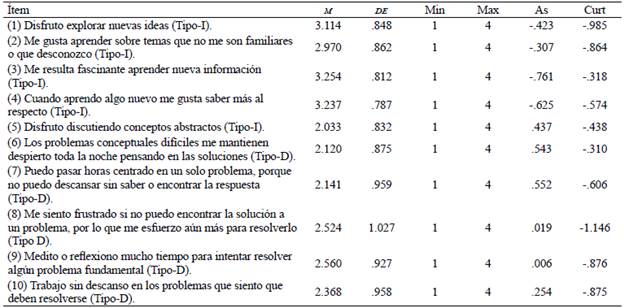
Nota. Min = Mínimo; Max = Máximo; As =Asimetría; Curt =Curtosis.
Aunque los valores de asimetría y curtosis de la Tabla 3 están por debajo del límite de ±3 para el primer indicador, y de ±10 para el segundo, recomendados por Kline (2015), los valores p del test de Mardia para normalidad multivariante, así como los de la prueba de Shapiro-Wilk para la univariante fueron < .05, indicando la ausencia de normalidad en los datos, lo que justifica el estimador utilizado para el análisis factorial de este estudio.
Evaluación del modelo unifactorial de Curiosidad Epistémica
No se identificaron valores atípicos. No obstante, el Análisis Factorial Confirmatorio (AFC) no tuvo un buen ajuste. Varios de los índices tuvieron valores subóptimos, incluyendo el CFI, el NNFI-TLI y el RMSEA. La consistencia interna evaluada mediante el α de Cronbach y el ω de McDonald fue satisfactoria. Sin embargo, el análisis de correlaciones residuales identificó diecinueve duplas de este tipo de asociaciones (véase Tabla 4).
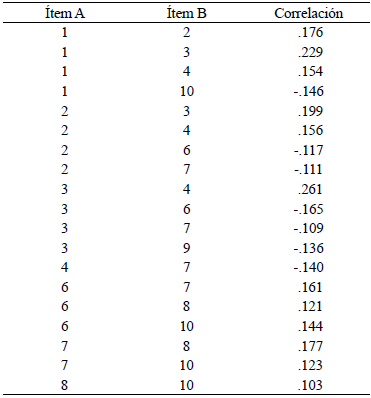
Después de agregar las correlaciones de la Tabla 4 al modelo, los índices indicaron un ajuste excelente, con excepción del ω de McDonald que disminuyó su valor de .79 a .67. La Tabla 5 presenta una comparación de los análisis factoriales de ambos modelos. A su vez, mientras que todos los ítems del modelo sin residuales correlacionados tuvieron cargas factoriales ≥ .398, al incluirlas en el modelo tres ítems tuvieron cargas factoriales < .374 (véase Tabla 6).
Tabla 5 Resultados del análisis para los modelos unifactoriales sin y con correlaciones residuales modeladas
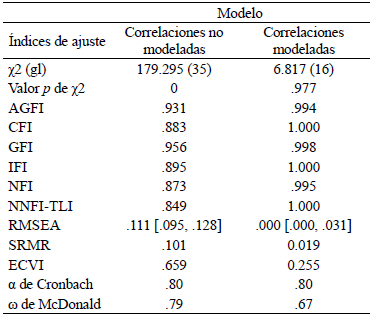
Nota. N = 334, gl = grados de libertad.
Tabla 6 Cargas factoriales para los modelos unifactoriales con y sin correlaciones residuales modeladas
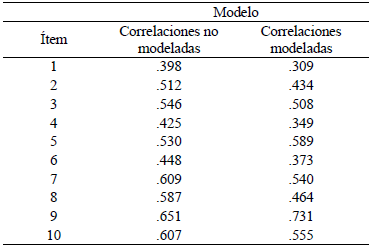
La invarianza de medición se evaluó utilizando el modelo con correlaciones, y se pudo comprobar que el modelo unidimensional posee invarianza configural, métrica, escalar y estricta. La Tabla 7 presenta los índices de bondad y el cambio o incremento (Δ) para cada tipo de invarianza.
Tabla 7 Índices de bondad de ajuste y cambio o incremento para cada clase de invarianza del modelo unifactorial

Nota. N = 334; grupo 1 (Hombres) n = 89; grupo 2 (Mujeres) n = 245.
Evaluación del modelo bifactorial de Curiosidad Epistémica
Al igual que en el caso del modelo unifactorial, no se identificaron valores atípicos. La correlación entre la CE Tipo-I y la Tipo-D fue moderada (.54), y todos los índices de bondad, excepto la significancia de X2, indicaron un ajuste aceptable. El α de Cronbach y el ω de McDonald también tuvieron valores satisfactorios. No obstante, se identificaron seis correlaciones residuales que se incorporaron al modelo estructural. Al volver a ejecutar el AFC, se examinaron de nuevo estas asociaciones, encontrándose que la del ítem 4 con el 9, así como la del ítem 5 con el 7 -que originalmente eran de .083 y .093, respectivamente-, aumentaron hasta ser mayores que .116. Por tanto, se incluyeron en el modelo factorial (véase Tabla 8).
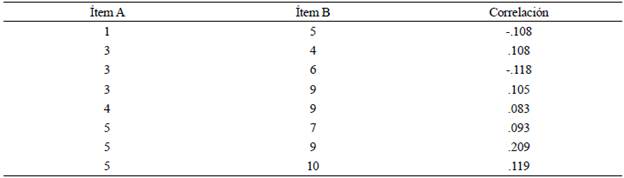
Una vez que las correlaciones de la Tabla 8 se incorporaron al modelo estructural, la asociación entre ambos tipos de CE siguió estando moderada (.45), todos los índices, incluyendo la significancia de X2, mostraron un mejor ajuste, el ECYI disminuyó su valor con respecto al modelo bifactorial inicial, y el ω de McDonald no se vio afectado por el modelado de correlaciones. La Tabla 9 presenta los resultados del análisis para ambos modelos. Adicionalmente, a diferencia del caso del modelo unidimensional, en el que después de modelar los residuales correlacionados, tres ítems presentaron cargas < .398, en el bidimensional, todos los ítems tuvieron cargas ≥ .495 (véase Tabla 10).
Tabla 9 Resultados del análisis para los modelos bifactoriales con y sin correlaciones residuales modeladas
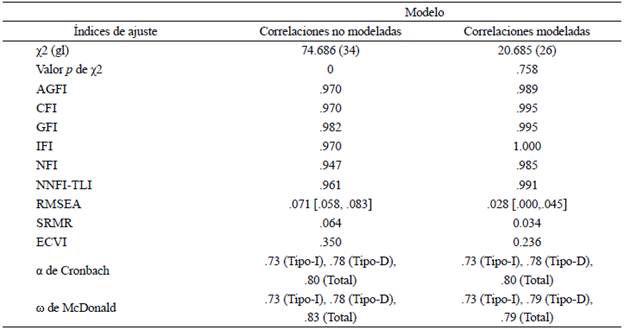
Nota. N = 334, gl = grados de libertad.
Tabla 10 Cargas factoriales para los modelos bifactoriales sin y con correlaciones residuales modeladas
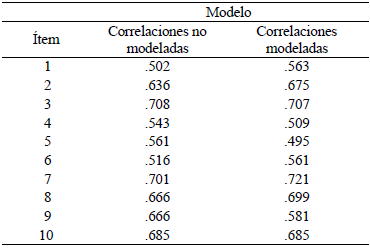
La invarianza de medición se evaluó utilizando el modelo con correlaciones residuales modeladas. Los resultados indican que el modelo estructural propuesto tiene invarianza configural, métrica, escalar y estricta. La Tabla 11 muestra los índices de bondad y el cambio o incremento (A) para cada categoría de invarianza.

Discusión
La presente investigación evaluó las propiedades psicométricas de la escala de CE I/D de 10 ítems desarrollada por Litman (2008), en un contexto mexicano e hispanohablante. Al igual que en estudios previos, se probó un modelo unifactorial y otro bifactorial. Inicialmente, el AFC indicó que el segundo modelo tenía un mejor ajuste que el primero. Sin embargo, el examen de los residuales correlacionados encontró que el unidimensional tenía 19 asociaciones significativas de este tipo y el bidimensional, 8. Estas correlaciones se incorporaron como parte de los análisis factoriales y el ajuste mejoró de manera sustancial, en particular para el modelo unidimensional. Si bien, a partir de los índices de ajuste, se podría concluir que el modelo unidimensional es mejor que el bidimensional (véase Tabla 12), esta apreciación sería engañosa, como se explica a continuación.
Tabla 12 Resultados del análisis para los modelos unifactorial y bifactorial con residuales correlacionados modelados
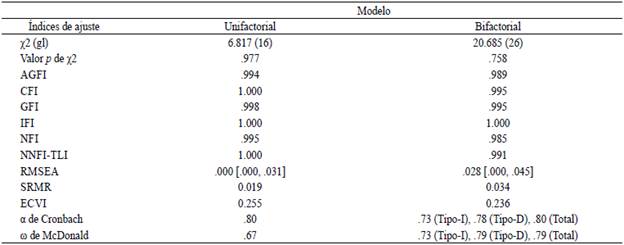
Nota. N = 334, gl = grados de libertad.
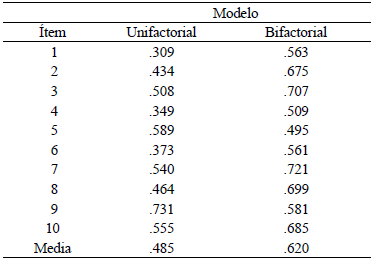
En primer lugar, el ECYI indica que el modelo bidimensional es ligeramente mejor que el de un factor. En segundo, el número de correlaciones residuales que hay que controlar es 58% menor en el modelo bifactorial (8 vs. 19). En tercero, la inclusión de un número tan alto de residuales correlacionados, como parte del modelo unidimensional, tuvo dos efectos perjudiciales significativos. Por un lado, la consistencia interna evaluada mediante el ω de McDonald se redujo sustancialmente, mientras que el α Cronbach se mantuvo constante, lo que indica que, ante la presencia de este fenómeno, α no es una medida confiable de consistencia interna (Flora, 2020; Pascual-Ferrá & Beatty, 2015). Por otro, tres ítems tuvieron un decremento importante en sus cargas factoriales, causando que la media de las cargas factoriales del modelo unifactorial fuese .485 y la del bifactorial .620 (véase Tabla 13).
Tabla 13 Cargas factoriales para los modelos unifactorial y bifactorial con residuales correlacionados modelados
La invarianza de medición de la Escala de CE también se puso a prueba, y ambos modelos mostraron tener invarianza con respecto al género de los participantes. Esto significa que los hombres y mujeres de la muestra: (1) conceptualizan la estructura factorial incluyendo los ítems de la misma manera (invarianza configural); (2) interpretan los ítems de forma idéntica (invarianza métrica), y (3) utilizan la escala de la misma manera (invarianza escalar). Además, se comprobó la equivalencia completa del modelo de medición (invarianza estricta), lo que garantiza la comparación de resultados entre los grupos analizados. En este sentido, es importante señalar que, de las siete evaluaciones psicométricas mencionadas en la introducción, solo dos intentaron comprobar la invarianza del inventario (Huang et al., 2010; Karandikar et al., 2021), lo que indica que este sigue siendo un tema poco estudiado con respecto a la Escala de CE de Litman.
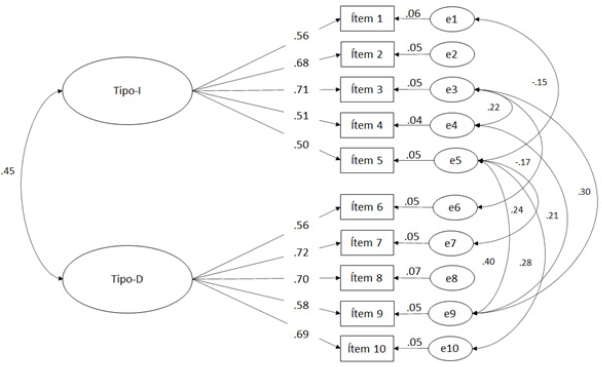
En resumen, los resultados de esta investigación muestran que el modelo bidimensional de CE presenta un mejor ajuste que el modelo unidimensional, incluso cuando las correlaciones residuales han sido modeladas coincidiendo con estudios previos, y que posiblemente, la escala sea invariante con respecto al sexo de las personas. La Figura 1 muestra este modelo de primer orden con dos factores correlacionados.
Ahora bien, esta investigación presenta dos grandes limitaciones que se exponen a continuación. Primero, aunque este es el primer estudio en un contexto latinoamericano, la muestra no fue representativa de la población, pues los participantes provienen de la zona urbana de una ciudad en el noroeste de México, y el número de hombres y mujeres fue desigual. Por tanto, los resultados no deben generalizarse a la población mexicana, ni a otras poblaciones hispanohablantes. Futuros estudios deberían utilizar una muestra más amplia y balanceada para evaluar las propiedades psicométricas de este inventario.
Segundo, si bien la inclusión de residuos correlacionados es un tema controvertido (Bandalos, 2021), la especificación post hoc de estos elementos es a menudo necesaria (Sellbom & Tellegen 2019), pues ignorar correlaciones sustanciales puede distorsionar en gran medida la solución (Ferrando et al., 2022). No obstante, su incorporación en los análisis realizados no se justificó teóricamente, lo que constituye una limitación (Domínguez-Lara, 2019) que debe ser subsanada en investigaciones subsecuentes, incluyendo el valor umbral para determinar si una correlación residual es significativa, ya que el usado en este estudio posiblemente haya sido demasiado bajo (Wahl et al., 2022).

