










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkTecnoLógicas
versão impressa ISSN 0123-7799versão On-line ISSN 2256-5337
TecnoL. no.30 Medellín jan./jun. 2013
Artículo de Investigación/Research Paper
Modelo de Sistema Experto para la Selección de Personal Docente Universitario
Expert System Model for Educational Personnel Selection
Héctor A. Tabares-Ospina1, Duvan A. Monsalve-Llano2, Daniel Diez-Gomez3
1MSc. en Ingeniería de Sistemas, Facultad de Ingeniería, Instituto Tecnológico Metropolitano, Medellín-Colombia, htabares@udea.edu.co
2Facultad de Ingeniería, Instituto Tecnológico Metropolitano, Medellín-Colombia, duvanmonsalve74201@correo.itm.edu.co
3Facultad de Ingeniería, Instituto Tecnológico Metropolitano, Medellín-Colombia, danieldiez76030@correo.itm.edu.co
Fecha de recepción: 22 de agosto de 2012 / Fecha de aceptación: 18 de junio de 2013
Resumen
Se presenta, en este artículo, un modelo de sistema experto para la selección de personal docente universitario. Esta labor no es una tarea trivial, debido a la subjetividad que puede presentarse en su evaluación. Este proceso se puede complementar usando un sistema de apoyo a la toma de decisiones. El sistema desarrollado se dividió en cuatro fases: toma de requisitos, diseño, implementación y puesta en marcha. Con el prototipo software, se logró modelar el conocimiento específico del experto en recursos humanos, lo que permitió obtener una recomendación sobre el tipo de contrato al que puede aspirar un docente universitario, dependiendo de su perfil profesional.
Palabras clave: Sistema experto, selección de personal docente, perfil de candidatos
Abstract
The staff selection is a difficult task due to the subjectivity that the evaluation means. This process can be complemented using a system to support decision. This paper presents the implementation of an expert system to systematize the selection process of professors. The management of software development is divided into 4 parts: requirements, design, implementation and commissioning. The proposed system models a specific knowledge through relationships between variables evidence and objective.
Keywords: Expert system, Educational Personnel Selection, candidate profile.
1. Introducción
El objetivo fundamental de este artículo consiste en realizar un estudio sobre los problemas de selección de personal docente. Esto ha sido una de las constantes preocupaciones en el Departamento de Personal del Instituto Tecnológico Metropolitano –ITM-, debido a la dificultad que existe en formalizar adecuadamente las relaciones humanas. En todos estos procesos la subjetividad está presente como una característica permanente, lo que llevó para su solución, al desarrollo de un Sistema Experto (SE) del tipo determinista, titulado: ExpertoRH_ITM (ExpertoRecursosHumanos_ITM), en el cual se confirmó que los SE brindan grandes posibilidades en el campo de la gestión de personal.
Este trabajo comienza con el estado del arte de los SE, usados para modelar la experiencia humana. A continuación se presenta la metodología utilizada para la implementación de este sistema. Continúa el artículo mostrando las pruebas de validación y los resultados más importantes. Finaliza, presentando las principales conclusiones del trabajo investigativo y el esbozo de trabajos futuros.
1.1 Los sistemas expertos
Un Sistema Experto -SE- es una aplicación informática que, sobre una Base de Conocimientos (BC), posee información de uno o más expertos, para solucionar un conjunto de problemas en un área específica. La BC es un tipo especial de Bases de Datos (BD) para la gestión del conocimiento, que posee una considerable capacidad de deducción a partir de la información que contiene. La diferencia entre la BD y la BC consiste en que el primero almacena únicamente hechos (afirmaciones que sirven para representar conceptos, datos, objetos, etc.) y las funciones del motor de la BD son las de edición y consulta de los datos. El segundo, puede almacenar además de hechos (base de hechos que describen un problema) un conjunto de reglas. Una regla es una estructura condicional que relaciona lógicamente la información contenida en la parte del antecedente, con otra información contenida en la parte del consecuente. En una BC las reglas se sirven de esos hechos para que el Motor de Inferencia (MI) obtenga razonamiento deductivo automático, seleccionando las reglas posibles para solucionar un determinado problema, y así conseguir información que no se encuentra almacenada de forma explícita.
Tanto con la BD como con la BC se pueden realizar consultas dinámicas. En el primer caso, es la posibilidad que tiene el usuario final para configurar la consulta en tiempo de ejecución. En el segundo caso, el usuario introduce la información del problema actual en la base de hechos y el sistema empareja esta información con el conocimiento disponible en la base de conocimientos para deducir nuevos hechos (Giarratano & Riley, 2001).
Los SE pueden clasificarse en dos tipos principales, según la naturaleza de problemas para los que están diseñados: deterministas y estocásticos. Los SE que tratan problemas deterministas son conocidos como “sistemas basados en reglas”, porque sacan sus conclusiones basándose en un conjunto de reglas utilizando un mecanismo de razonamiento lógico (Sahin & Tolun, 2012).
Los sistemas que tratan problemas estocásticos, es decir, problemas que involucran situaciones inciertas, necesitan introducir formas para medir la incertidumbre. Algunas medidas de incertidumbre son los “factores de certeza” y la “probabilidad”. Estos SE utilizan una distribución de probabilidad conjunta de un grupo de variables para describir las relaciones de dependencia entre ellas, y así sacar conclusiones usando fórmulas de la teoría de probabilidad. Para una definición más eficiente de la distribución de probabilidad conjunta se utilizan modelos de redes probabilísticas, entre los que se incluyen las redes de Markov y las redes Bayesianas.
Un detallado estudio sobre SE está más allá del ámbito de esta sección. En Liebowitz (2013) se ofrece un estudio con referencias específicas.
1.2 Antecedentes
La literatura presenta numerosos estudios de aplicación de SE. En la década del 90, distintos trabajos analizaban la posibilidad de la implementación de un SE para remplazar la experiencia de un profesional de recursos humanos cuando realiza un proceso de selección (Doney & Briggs, 1988). Dichas investigaciones llevaron a plantear el uso de un SE como la solución ideal para sistematizar este tipo de procesos. No obstante, los costes para su desarrollo hicieron que su mantenimiento fuera inviable.
En (Mockler & Dologite, 1992) se describe un SE desarrollado e implementado en Digital Equipment Corporation, compañía americana pionera en la fabricación de minicomputadores, para ayudar en la gestión de recursos humanos. La discusión de este sistema se centra en los problemas de aplicación de los sistemas basados en conocimientos en grandes entornos corporativos, haciéndolo inexacto e incoherente.
El interés por la utilización de SE aumentó, e incluso se expandió hacia otras áreas, como por ejemplo el uso militar, dentro del proceso de selección de los postulantes al Ejército de los Estados Unidos (Storey, 1996). No obstante, por razones propias de seguridad, no tuvo mayor grado de aceptación.
En (Chen & Cheng, 2005) se propuso un método de clasificación difusa para el problema de selección de personal. El método utiliza la distancia métrica para clasificar los candidatos. Su principal dificultad residía en la representación difusa de algunos tipos de conocimiento.
Scarborough, et al. (2006) describe un modelo de utilidad patentado en los Estados Unidos. Es un sistema informático automatizado, basado en la inteligencia artificial que usa una variedad de técnicas para proporcionar la información que ayuda en la selección de empleados. Su principal limitante es que el sistema no detecta preguntas redundantes e ineficaces en la base de conocimiento.
Golec & Kahya (2007) presenta un modelo difuso para generar posibles soluciones en las cuales el proceso de adecuación de un empleado con un determinado trabajo, se realiza a través de una competencia. Este trabajo presenta una estructura jerárquica integral de selección y evaluación de un empleado, con un ejemplo que demuestra la viabilidad del método. La representación difusa del conocimiento es su principal dificultad.
Recientemente, debido a los avances en la tecnología de la información, en Chien & Chen (2008) se desarrollaron sistemas de apoyo a la toma de decisiones y sistemas expertos para mejorar los resultados de la gestión de recursos humanos. Este estudio usó un marco de minería de datos, basada en un árbol de decisión y reglas de asociación, para generar lineamientos útiles para la selección de personal. Los resultados pueden proporcionar reglas de decisión relacionados con la información sobre el desempeño laboral. Su principal dificultad se refiere a la descripción de los árboles de decisión y las reglas de asociación.
En Gungor et al. (2009) se desarrolló un sistema de selección de personal basado en el proceso de análisis jerárquico difuso AHP (Analytic Hierarchy Process), el cual ha demostrado ser muy efectivo en los procesos de toma de decisiones multicriterios, que consiste en encontrar la mejor opción entre un conjunto de alternativas factibles. Entre los diversos métodos de la toma de decisión multicriterio, se considera un subgrupo que incluye aspectos de costos y beneficios. Uno de ellos es el método TOPSIS (Technique for Order Performance by Similaritiy to Idea Solution), técnica para ordenar las preferencias mediante similitud a la solución ideal. Su principal dificultad es la necesidad de un equipo de varios expertos en el dominio del conocimiento, que proporcionen la información pertinente al sistema informático.
Kelemenis & Askounis (2010) utilizaron la técnica difusa de orden de preferencia por similitud (TOPSIS), basado en un umbral de veto o impedimento que evalúa las alternativas mediante una clasificación (ranking) de los aspirantes a ocupar una vacante, dependiendo de su perfil profesional. Las técnicas difusas presentan como problema la dificultad para establecer reglas de control.
La selección de empleados es un componente crítico de una organización exitosa. Muchos criterios importantes de selección de personal, tales como la capacidad de toma de decisiones, la adaptabilidad, la ambición y auto organización, son imprecisos para evaluar. En Akhlaghi (2011) se propone la teoría de los conjuntos aproximados (RST- Rough Sets Theory) como un nuevo enfoque matemático a la vaguedad y la incertidumbre. Es una herramienta muy adecuada para hacer frente a los datos cualitativos y a diversos problemas de decisión relacionados con los factores de selección de personal. Su principal problema versa sobre la imprecisión de los resultados finales sino se cuenta con variables cuantitativas que alimente el modelo.
Balezentis et al. (2012) consideran que dado el carácter incierto, ambiguo y vago del proceso de selección de personal, se requiere de un método robusto que maneje la aplicación de múltiples criterios para la toma de decisiones, MCDM (Multicriterial Decisión Making). En este artículo, se expone el método de evaluación multiobjetivo MULTIMOORA (Multi‐Objective Optimization by Ratio Analysis) difusa para el razonamiento lingüístico en la toma de decisiones en grupo, permitiendo la agregación de las evaluaciones subjetivas realizadas por el personal de recursos humanos, ofreciendo un procedimiento más sólido de selección siempre y cuando sea reducido el número de variable de entrada del modelo.
A pesar de lo anterior, es un reto implementar en software una evaluación global de las capacidades de un candidato, teniendo en cuenta todas las características del cargo a ocupar. Esta es una razón por la cual en el ITM se ha trabajado en el diseño de modelos computacionales usando SE, como el expuesto en (Primorac & Mariño, 2011) diseñado para asistir decisiones turísticas (dicho artículo fue tomado y adaptado para los propósitos de este trabajo investigativo). Se pretende superar las limitaciones de los previos modelos expuestos, referidos a la exactitud y precisión de los resultados finales.
2. Materiales y métodos
Los actores que intervienen en el aplicativo ExpertoRH_ITM son: el ingeniero de sistemas que en este caso hace las veces de ingeniero del conocimiento (IC), el experto en el dominio de conocimiento sobre recursos humanos (EDC) y los usuarios finales (UF) que interactúan con el sistema con miras a encontrar una respuesta posible a sus inquietudes.
La metodología abordada para la implementación del SE contempló las siguientes etapas:
a. Identificación del problema, en este caso, la selección de personal docente utilizando un prototipo software.
b. Selección de la variable objetivo y sus valores. El EDC definió como variable objetivo el tipo de contratación al que puede aspirar a aplicar un docente. Los valores posibles que puede asumir la variable son: no aplica, catedrático, ocasional, de carrera.
c. La selección de las variables de entrada y sus posibles valores: sobre la base del conocimiento del EDC, se seleccionaron el conjunto de variables de entrada relevantes. En el modelo abordado en este trabajo las preferencias están determinadas por los indicadores que se detallan en la Tabla 1.
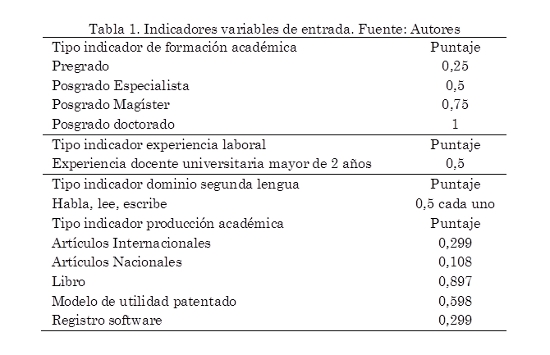
El proceso comienza identificando los rasgos y características, representadas en las variables de entrada, presentes o no en los valores que asume la variable objetivo identificada para el dominio del problema. A continuación se mencionan algunas cuestiones consideradas en este prototipo: i) formación académica de pregrado y posgrado, ii) experiencia docente medida en años, iii) dominio de una segunda lengua, iv) producción académica (publicación de artículos, libros, modelos de utilidad patentados, registros software). A cada característica se le asigna un peso de 0 a 1, dependiendo de su importancia relativa. La pregunta que tiene mayor influencia en el resultado final, es una cuestión de criterio del especialista en el dominio de conocimiento en recursos humanos.
d. Diseño de las preguntas. El desarrollo del cuestionario es la parte más complicada y en general es una actividad iterativa. El proceso se puede comenzar identificando los rasgos y características, representadas en las variables de entrada, presentes o no en los valores que asume la variable objetivo identificada para el dominio del problema. En esta fase intervinieron el IC y el EDC. La adquisición de la información relevante se obtuvo consultando con el EDC y el IC extrajo las principales características de los diferentes tipos de contratos para docentes universitarios. Con base a los rasgos identificados en el paso anterior, el IC y el EDC diseñan las reglas a evaluar y las preguntas a formular a los UF del sistema cuando interactúa con el subsistema de interfaz de usuario final. En la Tabla 2, se presentan las reglas a evaluar.

e. Implementación software. En las especificaciones de diseño del aplicativo ExpertoRH_ITM, se manejaron tres capas: interfaz, lógica de programa, datos; esto para lograr que la interfaz sea completamente independiente del sistema y la BC pueda alterarse sin tener que hacer cambios en la programación. La BC reside en un manejador de bases de datos. La base de reglas y el MI se implementaron en lenguaje PHP ambiente web con tecnología Synfony y lenguaje C# con tecnología .NET para ambiente de escritorio, utilizando el escenario de conectado para tener acceso al motor de la BD. En general, esta tecnología ofrece las capacidades para el desarrollo basado en Web, adaptada incorporando arquitecturas cliente-servidor o interfaces basadas en navegadores Web. El MI se ejecuta por lo general en el lado del servidor.
La arquitectura básica del aplicativo ExpertoRH_ITM se puede observar en la Fig. 1.
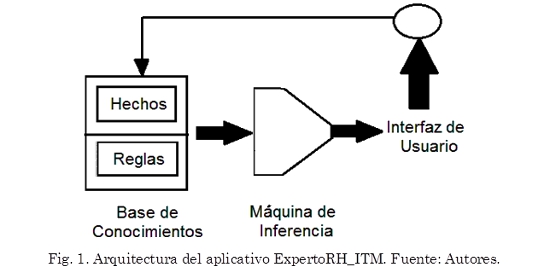
El programa ExpertoRH_ITM está compuesto por tres subsistemas: i) el editor de variablesde entrada (antecedentes) y salida (objetivos o consecuentes), ii) la base de conocimiento, iii) la interfaz de usuario final.
2.1 Editor de variables de entrada y salida
Con base en base a los rasgos identificados en las variables de entrada, el IC y el EDC las registran utilizando el subsistema editor de variables de entrada y salida. En la Fig. 2, se ilustran algunas formulaciones que estarán disponibles. El control combo titulado “Acciones” permite ingresar una nueva variable del tipo antecedente o consecuente.

2.2 Editor base de conocimiento
El archivo de las variables de entrada y salida se carga en el subsistema de adquisición del conocimiento. Inicialmente el sistema no contiene posibles reglas. Como se presenta en la Fig. 3, el EDC carga las variables generadas por el IC y configura las reglas en la base de conocimiento. Este proceso se repite hasta que se hayan configurado todas las soluciones posibles para cada una de las preguntas formuladas.
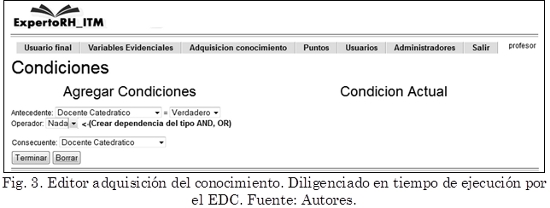
Es frecuente que diferentes sucesos estén correlacionados, siendo necesario realizar cierta pregunta si la respuesta seleccionada a la pregunta anterior lo requiere. El subsistema permite establecer dependencias por medio de su opción “Crear Dependencia”. Finalizado este proceso, las preguntas formuladas, las dependencias y la importancia asignada son guardadas en una base de datos.
2.3 Bases de datos
Todo el sistema está relacionado como una base de datos Access (MDB) titulada ExpertoRH_ITM.db, y centra su gestión en cinco aspectos principales: información personal del docente, experiencia profesional, formación académica, dominio de segunda lengua y producción académica. El esquema de la base de datos relacional que cumple con el planteamiento de los requisitos se presenta en la Fig. 4. El significado de las tablas y sus relaciones es el siguiente:
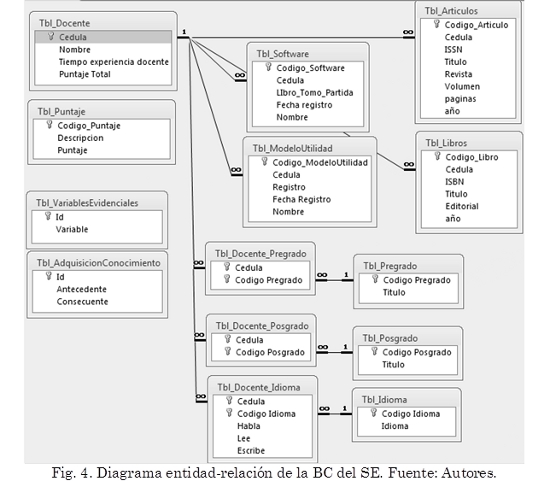
Tbl_Docente. Representa los datos básicos del docente
Tbl_Pregrado y Tbl_Posgrado indica la formación académica
Tbl_Idioma representa el dominio en segunda lengua
Tbl_Sofware, Tbl_ModeloUtilidad, Tbl_Libros y Tbl_Articulos informan la producción académica
Tbl_Puntaje, peso según indicador
Tbl_VariablesEvidenciales, variables de entrada o salida del SE
Tbl_AdquisicionConocimento, comprende el listado de reglas que evalúa el SE
El significado de los atributos que componen las diferentes tablas es explícito, de tal manera que los lazos entre las relaciones son fáciles de entender. Por ejemplo, el lazo que conecta Tbl_Docente con Tbl_Libros sirve para describir la editorial de un libro que ha publicado el docente.
La relación entre Tbl_Docente y Tbl_Pregrado, al tratarse de una relación con cardinalidad VARIOS a VARIOS, no está permitida por cuanto contradice la definición de llave primaria y las reglas de normalización de bases de datos. En estos casos, se hace necesario crear una nueva tabla que permita transformar las relaciones en cardinalidad UNO a VARIOS. De ahí que se haya creado la entidad relación Tbl_DocentePregrado, Tbl_DocentePosgrado y Tbl_DocenteIdoma.
2.4 Interfaz de Usuario Final
La Fig. 5, ilustra el subsistema de interacción con el UF en la Web. El subsistema de interacción con el UF, permite el acceso al conocimiento especializado, que puede consultarse interactivamente en cada paso, luego de seleccionar la variable de entrada y su valor en el recorrido desde el inicio a la meta. El cuestionario primero se presenta al EDC cuando utiliza el subsistema de adquisición del conocimiento para completar la BC y verificar como están relacionadas cada una de las opciones disponibles para recomendar una solución.

El funcionamiento general del subsistema de interacción con el UF es el siguiente: el UF selecciona el conjunto de variables evidenciables relevantes, y responde las preguntas planteadas por el SE. En el modelo abordado en este trabajo, las preferencias de los potenciales candidatos están determinadas por las variables: i) experiencia laboral, ii) formación académica, iii) dominio de segunda lengua, iv) producción académica.
La interfaz que maneja la interacción entre el SE y el UF es altamente interactiva y sigue el patrón de la conversación escrito entre seres humanos. Por lo tanto, un requerimiento básico de la interfaz es la habilidad de hacer preguntas. Para obtener repuestas fiables del usuario, es necesario prestar especial cuidado en el diseño del cuestionario. Esto requirió diseñar la interfaz usando menús o gráficos.
La consulta transcurre en general según el esquema siguiente: primero se plantea al usuario la pregunta sobre su experiencia docente para alcanzar una determinación aproximada del contexto. El diálogo, por parte del sistema, está a menudo dimensionado para ir confirmando o rechazando hipótesis (por ejemplo, comprobación de la formación académica), o para realizar una aproximación sucesiva hacia un objetivo introducido de antemano (por ejemplo, un docente de carrera).
Una vez finalizado el diálogo, el componente explicativo suministra, si es necesario, el historial completo de la consulta. Con los datos definidos en los filtros, el sistema ExpertoRH_ITM simula al experto humano, usando el MI, para obtener razonamiento deductivo automático, aplicando un encadenamiento de reglas hacia adelante para contrastar los hechos particulares de la base de hechos con el conocimiento contenido en la BC y obtener conclusiones acerca de la consulta realizada. Para la evaluación de cada regla, el MI la convierte de notación infijo a posfijo. Seguidamente, el MI aplica una subrutina evaluadora de expresiones en notación posfija.
3. Resultados
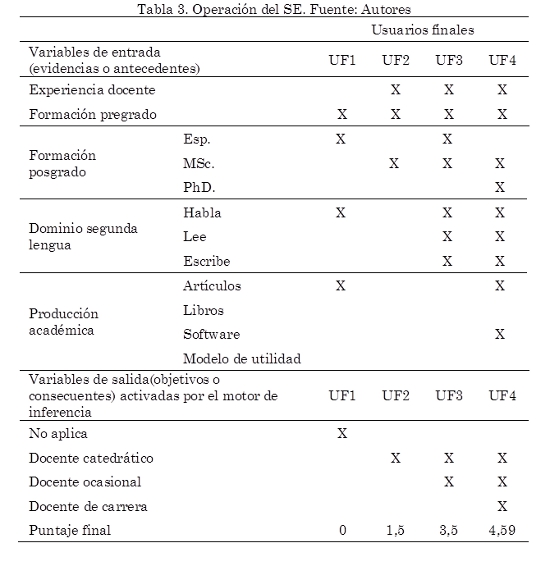
Para probar el sistema, se empleó el subsistema de interfaz de interacción con el UF. En la Tabla 3, se presenta la inferencia del SE ante 4 posibles tipos de UF. Como se observa, el SE determina exitosamente el tipo de contrato al que puede aspirar un docente en función de las variables de entrada seleccionadas.
Para lograr un mejor rendimiento del MI del sistema informático, ExpertoRH_ITM maneja la transaccionalidad de la base de datos y su procesamiento de manera local usando el escenario de desconectado, empleándolos recursos de la máquina en vez del servidor designado. Al tener un ambiente Web y una base de datos Access como premisa para el funcionamiento del prototipo software, se analizó que era muy ineficiente estar enviando peticiones al servidor de la base de datos para comprobar cada variable de entrada, más aun sabiendo que al ser un ambiente Web, varias personas podrían estar conectadas simultáneamente, enviando permanentemente peticiones para utilizar el sistema informático. Por lo tanto, con el propósito de tener un flujo de información más controlada y eficiente del MI, se separaron los procesos de obtener la información base (editor de preguntas), la adquisición de conocimiento y el motor de inferencia. Este último se evidencia cuando se almacena en la base de datos la información correspondiente a las reglas usadas para consultas (aprendizaje de las reglas usadas). Estas consultas dinámicas posibilitan al usuario configurar la pregunta en tiempo de ejecución, obviando la tarea de tener que quemar en código las reglas de búsqueda más comúnmente utilizadas, brindando mayor flexibilidad en la programación de los diferentes procedimientos del MI.
4. Conclusiones
El objetivo de este trabajo consistió en desarrollar el prototipo software ExpertoRH_ITM orientado a apoyar la toma de decisiones en la elección de personal docente, accesible desde la plataforma Web. El programa se consultará ante todo cuando exista un problema que no requiere solución inmediata y no se pueda o quiera recurrir primero al experto humano. Asimismo, el aplicativo sirve también al mismo experto que lo alimenta como diccionario dinámico, que mantiene el conocimiento de reglas antiguas, mientras se concentran en los nuevos desarrollos.
El prototipo de SE, usando un MI para obtener razonamiento deductivo automático, permite a los aspirantes a ser docentes en el ITM, obtener una recomendación sobre el tipo de contrato al que puede aspirar de acuerdo a los siguientes indicadores: i) experiencia laboral, ii) formación académica, iii) dominio de segunda lengua, iv) producción académica. ExpertoRH_ITM se encuentra registrado en Colombia, Dirección Nacional de Derecho de Autor, con número 13-33-159 del 3 de Mayo de 2012. El prototipo de sistema desarrollado está accesible en la dirección: http://www.itm.edu.co/trabajosdegradodestacados/index.html
Es de interés realizar otros estudios en el que se usen los SE en problemas que requieran inferencia determinista para hacer clasificaciones, por ejemplo de virus/antivirus, delitos, e intrusiones informáticas.
5. Agradecimientos
Esta sección reconoce la ayuda del profesor Jorge Iván Bedoya Restrepo, docente en el ITM de la asignatura Bases de Datos. Este trabajo es el inicio del proyecto de investigación interinstitucional con código P12208, aprobado según convocatoria interna del Instituto Tecnológico Metropolitano –ITM- cofinanciado con la Universidad de Antioquia -UdeA-, según convenio específico celebrado entre las partes No. 8703-002-2012. El proyecto se enmarca en la línea Gestion de la Energía Eléctrica (GIMEL), del programa Doctorado en Ingeniería, de la UdeA.
Referencias
Akhlaghi, E. (2011). A rough-set based approach to design an expert system for personnel selection. World Academic of Science, Engineering and Technology, 78, 245-248. [ Links ]
Balezentis, A., Balezentis, T., Brauers W. (2012). Personal selection based on computing with words and fuzzy MILTIMOORA. Expert Systems with Applications, 39, 7961-7967. [ Links ]
Chen, L., Cheng C. (2005). Selecting IS personnel use fuzzy GDSS based on metric distance method. European Journal of Operational Research, 803-820. [ Links ]
Chien, C., Chen, L. (2008). Data mining to improve personnel selection and enhance human capital: A case of study in high-technology industry. Expert Systems with applications, 34(1), 280-290. [ Links ]
Doney, D., Briggs S. (1998). Can HR expertise be computerized? Personnel Journal. Crain Communications, Inc. ISSN 0031- 5745. [ Links ]
Giarratano, J., Riley, G. (2001). Sistemas expertos. Principios y programación. International Thomson Editors. [ Links ]
Golec, A., Kahya, E. (2007). A fuzzy model for competency-based employee evaluation and selection. Computers and Industrial Engineering, 52, Ed. 1. [ Links ]
Gungor, Z., Serhadlioglu, G., Kesen S. (2009). A fuzzy AHP approach to personal selection problem. Applied Soft Computing, 9, 641-649. [ Links ]
Liebowitz, J. (2013). Expert Systems with applications. An International Journal. ELSEVIER, 40, edición 15. [ Links ]
Kelemenis, A., Askounis, D. (2010). A new TOPSIS-based multi-criteria approach to personal selection. Expert Systems with Applications, 37, 4999-5008. [ Links ]
Mockler, R.,Dologite, D. (1992). Expert systems for human resource management: development and implementation. System Sciences, 3, 129-132. [ Links ]
Primorac, C., Mariño, S. (2011). Un sistema experto para asistir decisiones turísticas. Diseño de un prototipo basado en la Web. Revista de investigación en turismo y desarrollo local, 4(10). Disponible en http://www.eumed.net/rev/turydes/10/index.htm [ Links ]
Sahin, S., Tolun R., (2012). Expert System with applications. International Journal, ELSEVIER, 39(4), 4609-4617. [ Links ]
Scarborough, D., Chambless, B., Becker, R., Check, F.(2006). Electronic employee selection systems and methods. Unicru, Inc. [ Links ]
Storey, S. (1996). Use of an expert system in the board selection process. United States Army War Collage. [ Links ]

