











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares em
SciELO
Similares em
SciELO  Similares em Google
Similares em Google 
 Permalink
PermalinkIntroducción
Desde la teoría clásica de los test, un coeficiente de confiabilidad es definido como la proporción de varianza verdadera que existe en la medición realizada (Lord & Novick, 1968). Los coeficientes de confiabilidad, entre ellos el a (Cronbach, 1951) que se usa de forma más frecuente, habitualmente trabajan con la suma directa de los puntajes (puntaje compuesto; X) de un conjunto de p medidas (X) (p .e., ítems). Es decir, X = X1 + X2 +X3 Xp.
Además, para el uso del coeficiente α, debe cumplirse que X1 = 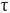 1 + ε1; donde
1 + ε1; donde 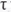 y ε representan el puntaje verdadero y el error de medición, respectivamente; y para dos o más ítems sería: 1 = 2=3 = … = n (- equivalencia esencial) y Cov(εn εm ) = 0; n ≠ m (errores independientes). No obstante, a pesar de la popularidad del coeficiente a, existen autores que brindan argumentos en contra de su uso por diversos motivos, principalmente porque sus dos supuestos fundamentales, tau-equivalencia y ausencia de errores correlacionados, son difíciles de lograr en la práctica (Dunn, Baguley, & Brunsden, 2014; Green, & Yang, 2009a, Sijtsma, 2009), lo que lleva a resultados sesgados de la estimación de la confiabilidad de los puntajes. Si no se cumple la tau-equivalencia, se subestima el monto estimado de varianza verdadera, es decir, que el α obtenido sea considerado como el límite inferior de la confiabilidad (lower bound) (Eisinga, Groteiiiiuis, & Pelzer, 2012); y si existen errores correlacionados, se aprecia una sobreestimación del coeficiente (Dunn et al., 2014; Green & Yang 2009a, Yang & Green, 2010). Ante ello,es conveniente buscar alternativas más precisas desde lo empírico y lo conceptual, donde pueda analizarse la confiabilidad aun cuando esos supuestos no se cumplan (Dunn et al., 2014; Green & Yang, 2009b). Además, su uso no es recomendado para medidas ordinales como los ítems en escalamiento Likert (Dominguez, 2012; Elosua, & Zumbo, 2008), y aunque con opciones de respuesta mayores que cinco pueden considerarse como medidas continuas (Remthulla, Brosseau-Liard & Savalei, 2012), el exceso de asimetría y curtosis puede sesgar la estimación.
y ε representan el puntaje verdadero y el error de medición, respectivamente; y para dos o más ítems sería: 1 = 2=3 = … = n (- equivalencia esencial) y Cov(εn εm ) = 0; n ≠ m (errores independientes). No obstante, a pesar de la popularidad del coeficiente a, existen autores que brindan argumentos en contra de su uso por diversos motivos, principalmente porque sus dos supuestos fundamentales, tau-equivalencia y ausencia de errores correlacionados, son difíciles de lograr en la práctica (Dunn, Baguley, & Brunsden, 2014; Green, & Yang, 2009a, Sijtsma, 2009), lo que lleva a resultados sesgados de la estimación de la confiabilidad de los puntajes. Si no se cumple la tau-equivalencia, se subestima el monto estimado de varianza verdadera, es decir, que el α obtenido sea considerado como el límite inferior de la confiabilidad (lower bound) (Eisinga, Groteiiiiuis, & Pelzer, 2012); y si existen errores correlacionados, se aprecia una sobreestimación del coeficiente (Dunn et al., 2014; Green & Yang 2009a, Yang & Green, 2010). Ante ello,es conveniente buscar alternativas más precisas desde lo empírico y lo conceptual, donde pueda analizarse la confiabilidad aun cuando esos supuestos no se cumplan (Dunn et al., 2014; Green & Yang, 2009b). Además, su uso no es recomendado para medidas ordinales como los ítems en escalamiento Likert (Dominguez, 2012; Elosua, & Zumbo, 2008), y aunque con opciones de respuesta mayores que cinco pueden considerarse como medidas continuas (Remthulla, Brosseau-Liard & Savalei, 2012), el exceso de asimetría y curtosis puede sesgar la estimación.
Así, desde el enfoque de ecuaciones estructurales (structural equation modeling, SEM), existen diversos planteamientos independientes acerca de la confiabilidad compuesta para medidas congenéricas. Por ejemplo, Raykov (1997) sugiere:
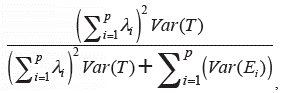
donde Var (T) es la varianza de la variable latente, λ¿ y Var (E i ) son los coeficientes de configuración (cargas factoriales) no estandarizados y las varianzas del error, respectivamente. Dicha expresión hace referencia a la proporción dela varianza explicada por el constructo en un puntaje compuesto, con respecto a la varianza de ese compuesto. Más adelante, surgio otra medida de confiabilidad en el marco SEM (Fornell y Larcker, 1981) expresada como:
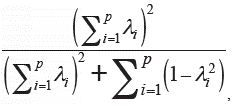
en la cual λi representa a los coeficientes de configuración estandarizados. En la ecuación del coeficiente ω (McDonald, 1999) figura 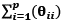 en lugar de
en lugar de 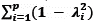 en el denominador pero ambas hacen referencia a la varianza del error (Raykov, 2001a). Es una expresión equivalente a la anterior (Raykov, 1997) cuando todos los coeficientes de configuración son estandarizados, y por ende su interpretación es similar.
en el denominador pero ambas hacen referencia a la varianza del error (Raykov, 2001a). Es una expresión equivalente a la anterior (Raykov, 1997) cuando todos los coeficientes de configuración son estandarizados, y por ende su interpretación es similar.
De este modo, estos métodos son útiles si se tiene en cuenta el grado de consistencia o interrelación de un conjunto de ítems que podrían ser usados para formar un compuesto, pero se concentran en compuestos no ponderados (Raykov 2001a), es decir estos procedimientos no consideran la variabilidad que puede existir entre los λ i usados al momento de configurar el puntaje total de un compuesto, ya que se sabe que cada λ i refleja la influencia del constructo en cuestión y está relacionado directamente con este. Por lo tanto, no proveen una evaluación de la confiabilidad del constructo en sí misma, lo que indicaría que los datos utilizados en estos métodos no reflejan óptimamente la variable latente (Geldhof, Preacher, & Zyphuer, 2014).
Además esos métodos presentan algunas limitaciones. Primero, si un ítem es afectado negativamente por la variable látante (posee un λ i con un signo negativo), aunque este sea de magnitud aceptable y coherente desde un punto de vista psicométrico (p. e., se justifica que el ítem tenga puntaje invertido) impactará de forma negativa en la estimación de los coeficientes antes mencionados. Segundo si existen ítems que no brinden mucha información acerca de la variable latente (coeficientes de configuración de magnitud baja), su permanencia impacta de forma significativa en la estimación de confiabilidad (Hancock & Mueller, 2001).
De este modo, la mejor opción es la combinación lineal ponderada con máxima confiabilidad (combinación lineal óptima, CLO), es decir, la medida que se concentra en los indicadores y puede diferenciar en el más alto grado a los sujetos examinados en el rasgo latente y que se asocia con la menor varianza de error posible (Raykov & Hancock, 2005). Entonces, en el marco sem, esta CLO se asocia de forma significativa con el puntaje del rasgo latente. Siguiendo esa lógica, para un compuesto ponderación sería: X = w 1X1 + w 2X2 + w 3X3… w pXp (para más detalles técnicos, ver Raykov, 2004). La expresión matemática es (Li, Rosenthal, & Rubin, 1996):
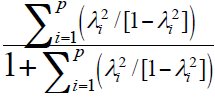
Donde λ i 2 es la confiablidad para cada X1, i= 1, 2, 3, .., p (Raykov, 2004). Dicha medida es la forma más general para casos de compuestos de medidas congénericas.
Coeficiente H: medida de confiabilidad del costructo
Conforme a lo expresado anteriormente, el coeficiente de máxima confiabilidad puede considerarse como un índice de confiablilidad del constructo. Si cada λi refleja la influencia del constructo, y mientas mayor es su magnitud, el constructo se ve mejor representado. Entonces, ese coeficiente cuantifica el grado en que el constructo es «capturado» por la información encontrada en sus indicadores mensurables (Hancock & Mueller, 2001; Greene & Brown, 2009; Raykov & Hancock, 2005). Dado que en un sistema de variables latentes se asume que un constructo es perfectamente confiable, la variabilidad de los valores obtenidos en distintas muestras se debe a la falta de precisión de los ítems que reflejan dicha variable latente (Hancock & Mueller, 2001). De esta forma, la modificación algebraica del coeficiente de máxima confiabilidad propuesta por Hancock, y Mueller (2001), el coeficiente H se expresa como:
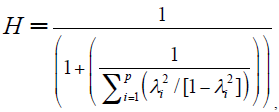
Donde 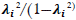 es la proporción de la varianza de la i-ésima variable explicada por el constructo con respeto a la proporción no explicada (al elevar λ
i
al cuadrado
,
queda al margen del signo original de λ
i
), por lo cual el coeficiente H está en función de la confiabilidad del ítem (λ
i
2
), recopilando esta información a través de las p variables que refleja el constructo.
es la proporción de la varianza de la i-ésima variable explicada por el constructo con respeto a la proporción no explicada (al elevar λ
i
al cuadrado
,
queda al margen del signo original de λ
i
), por lo cual el coeficiente H está en función de la confiabilidad del ítem (λ
i
2
), recopilando esta información a través de las p variables que refleja el constructo.
El coeficiente H funciona como una estimación de la confiabilidad del constructo, y se interpreta como el porcentaje de la variabilidad de la variable latente explicada por los indicadores (Mueller & Hancock, 2001), siendo deseable que sea ≥ .70. En este sentido, supera la limitación de los metodos anteriores al no estar influenciada por el signo de los coeficientes de configuración (Geldhof et al., 2014), y además nunca será menor que la confiabilidad del mejor indicador 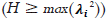 .
.
Finalmente, también puede aplicarse para medidas multidimensionales. De forma similar al αestratificado (Cronbach, Schoenemann, & McKie, 1965), el coeficiente H puede calcularse para medidas que evalúen más de un consftructo, e incluso para obtener mejores resultados (Widhiarso, 2007). No obstante, ese incremento podría estar influido más por la cantidad de ítems.
Cálculo y aplicaciones en análisis psicométríco
El cálculo del coeficiente H se podría hacer manualmente, pero también puede hallarse en el output del programa EQS como Maximal Weighted Internal Consistency Reliability. Cabe mencionar que si se trata de un instrumento multidimensional, el coeficiente H se considera con base en la totalidad de los ítems, por lo que se recomienda calcularlo para cada factor por separado. Asimismo, su cálculo no forma parte del output de resultados en programas como Mplus o AMOS. El autor del manuscrito ha creado un archivo en MS Excel para calcular el coeficiente H y está disponible al lector sin costo.
A continuación se brindarán tres ejemplos aplicativos para el coeficiente H. Con fines de comparación, adicionalmente fueron calculados el coeficiente α con intervalos de confianza (IC; Dominguez & Merino, 2015a) y el coeficiente ω.
El primer ejemplo se enfoca en una medida tau-equivalente. La Escala de Autoeficacia para situaciones Académicas (EAPESA) evalúa las creencias que tiene el estudiante con respecto a sus capacidades para hacer frente a las demandas en el ámbito académico y cuenta con evidencias de validez en cuanto a su estructura interna y su relación con otros constructos (Dominguez 2014a; Dominguez, Villegas, Yauri, Mattos, & Ramírez, 2012; Dominguez, Villegas, Cabezas, Aravena, & De la Cruz, 2013). Fueron evaluadas con la EAPESA 215 personas (79.5% mujeres). A través del programa EQS 6.2, fueron obtenidos índices de ajuste satisfactorio para el modelo unidimensional (congenérico): SB-X2 (27)= 52.100 (p<.01), CFI= .969 RMESEA (IC90%)=.066 (.038, .092), y al modelar las restricciones para la tau-equivalencia el ajuste tambien fue bueno SB-X2 (35) = 65.840 [p <.01], CFI = .962 RMSEA [IC90%] = 064 [.040, .088]). Además, al ser las diferencias entre los CIF del modelo congénerico y tau-equivalente menores que .01 (Cheung & Rensvold, 2002)" los ítems del EAPESA son tau-equivalentes. Para la EAPESA, el coeficiente α fue de .901 (IC95 % .872, .923), la confiabilidad compuesta (ω) obtuvo un índice de .902, y el coeficiente H de .906.
El segundo ejemplo tuvo base la aplicación de la Escala de Cansancio Emocional (ECE), que evalua el estado de agotamiento emocional del estudiante con respecto a sus actividades académicas, y presenta evidencias de confiabilidad y validez en estudios realizados con universitarios peruanos (Dominguez 2013; 2014b). Se usó la muestra del ejemplo 1. Los índices de ajuste mostraron magnitudes aceptables para el modelo congenérico (SB-X2 (35) = 77.680 [p <.01], CIF= 976, RMSEA [IC 90%] = .075 [.053, .098]), pero al modelar las restricciones para la tau-equivalencia, aunque el ajuste fue bueno (SB-X2 (44) = 124.228 [p < .01], CFI = .954, RMSEA [IC 90 %] = .092 [.073, .111]), las diferencias en el CFI fueron mayores que .01 (Cheung & Rensvold, 2002), lo cual indica que los ítems del ECE no son tau-equivalentes. En este caso, el coeficiente α fue de .875 (IC95 % .839, .903), la confiabilidad compuesta (ω) obtuvo un índice de .878, y el coeficiente H, de .895.
Finalmente, para su uso en medidas ultrabreves de dos ítems, se tomaron los datos del análisis psicométrico del Cuestionario de Regulación Cognitiva de las Emociones (CERQ-18; Dominguez, & Merino, 2015b). El CERQ-18 evalúa nueve estrategias cognitivas de regulación emocional (dos ítems por subescala). Dentro del modelo, fueron consideradas para el presente ejemplo dos de las subescalas: Culpar a otros, y Autoculparse. Los λi de Culpar a otros fueron de .858 y .739; y de Autoculparse, .499 y .930. Se escogieron debido a que los λi, al interior de esas difieren notoriamente entre sí. En el primer caso, el coeficiente α fue de .710 (IC 95% .647, .763), la confiabilidad compuesta (ω) obtuvo un índice .780, y el coeficiente H de .800. Finalmente, en cuanto a la subescala Autoculparse, el coeficiente α fue de .604 (IC 95%.525 .673), la confiabilidad compuesta (ω) obtuvo un índice de .697, y el coeficiente H parece ser robusto ante estas discrepancias.
Coeficiente H y su aplicación en análisis bifactor confirmatorio
Para este ejemplo, se tomaron parte de los resultados preliminares de un estudio bifactor con el CERQ-18 (Dominguez, 2015). Debido a las elevadas correlaciones interfactoriales observadas en estudios previos en la versión completa (CERQ-36; Dominguez, & Medrano, 2016) y breve (CERQ-18; Dominguez & Merino, 2015b), se planificó un estudio que modele un factor general que sea capaz de explicar la variabilidad conjunta de esas subescalas (Reise, 2012).
De esta forma, se modelaron dos grandes factores generales: Estrategias desadaptativas (Culpar a otros, Autoculparse, Rumiación, y Catastrofización), y Estrategias adaptativas (Aceptación, Poner en perspectiva, Reinterpretación positiva, Vocalización en los planes, y Vocalización positiva). La hipótesis general fue que los factores generales explicarían más varianza que los factores específicos. Si bien los resultados brindaron evidencias a favor de esta hipótesis mediante índices de ajuste aceptables, e índices adicionales favorables a ello como el ECv (Explained Common Variance;Reise, Scheines, Widaman, & Haviland, 2013), el PUC (Percentage of uncontaminated correlations; Reise et al., 2013) y el (0h (Zinbarg, Yovel, Revelle, & McDonald, 2006), la aplicación del coeficiente H pudo ser un complemento importante.
En este contexto, si uno de los factores específicos obtiene un coeficiente H ≥ .70, puede considerarse como un factor de grupo robusto, además del factor general (Rodríguez, Reise, & Haviland, 2015). De este modo, los resultados detallados en la tabla 1 indican que luego del modelamiento bifactor, los coeficientes de configuración de los factores específicos y general difieren en magnitudes, trayendo como secuencia H < .70 para todos los factores específicos, brindando de ese modo evidencia adicional a favor del factor general.

Comentarios finales
En vista de que el uso adecuado del coeficiente a se ve restringido por sus supuestos, y si se utiliza al margen de su cumplimiento la estimación puede estar sesgada. Por ello se han desarrollado alternativas para la evaluación de la confiabilidad desde el marco SEM, aunque esos métodos pasan por alto la heterogeneidad de los coeficientes de configuración en una estructura factorial. Para superar esta limitación, se planteó el coeficiente H y su aplicación como medida de confiabilidad del constructo, como cálculo complementario a los realizados con las técnicas habituales.
Por otro lado, aunque los ejemplos presentados no son representativos de todas las condiciones posibles, pueden ser útiles para ejemplificar el comportamiento del coeficiente H. Dicho indicador parece ser robusto cuando los coeficientes de configuración difieren entre sí (incumpllmiento de la tau-equievalente), ya que si bien los ítems evalúan el mismo constructo, este puede afectarlos en diferente intensidad.
No obstante, existen algunas observaciones vinculadas con el cálculo e interpretación. En primer lugar, de forma similar al coeficiente α, parece que su magnitud está influida por la cantidad de ítems que existen, ya que a más ítems la sumatoria 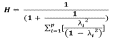 , que forma parte la expresión propuesta (Hancock & Mueller, 2001) es mayor, por lo que el coeficiente H aumentaría de forma espuria. A modo de ejemplo breve, con λ
i
= .40 para cada ítem, cuando se cuenta con 10 ítems la magnitud de H es .656; con 20 ítems, H = 792; y con 30 ítems, H = .851. No obstante, son necesarios estudios de simulación que reflejen diferentes condiciones experimentales para reafirmar este argumento, y desarrollos posteriores que permitan lograr un ajuste apropiado de su magnitud en función del número de ítems a fin de no sobredimensionar su valor.
, que forma parte la expresión propuesta (Hancock & Mueller, 2001) es mayor, por lo que el coeficiente H aumentaría de forma espuria. A modo de ejemplo breve, con λ
i
= .40 para cada ítem, cuando se cuenta con 10 ítems la magnitud de H es .656; con 20 ítems, H = 792; y con 30 ítems, H = .851. No obstante, son necesarios estudios de simulación que reflejen diferentes condiciones experimentales para reafirmar este argumento, y desarrollos posteriores que permitan lograr un ajuste apropiado de su magnitud en función del número de ítems a fin de no sobredimensionar su valor.
En segundo lugar, al prescindir del signo del coeficiente de configuración para su cálculo, si el factor analizado cuenta con ítems en escala invertida (fraseo en dirección opuesta al constructo),se debe realizar un análisis previo del efecto del método (EM) asociado a esos ítems (Lance, Dawson, Birkelbach,& Hoffman, 2010; Spector, 2006),toda vez que no sea posible hacer un fraseo que evite esa dirección. Una vez que se determina que el EM es irrelevante, puede calcularse el coeficiente H.
Finalmente, no existen reportes de la alteración de su magnitud ante la presencia de errores correlacionados como ocurre con el coeficiente a (Pascual-Ferrá & Beatty, 2015) y (0 (Raykov, 2001b). En ese caso, cabe la posibilidad de que en futuros estudios pueda agregarse un factor corrector a su expresión matemática a fin de lograr una estimación más precisa de la confiabilidad del constructo.
Para concluir, queda claro que el coeficiente H es una medida complementaria que puede ser de ayuda en los procesos analíticos orientados al reporte de las propiedades psicométricas de los instrumentos de evaluación, y aunque algunos desarrollos metodológicos quedan pendientes, es una alternativa interesante dentro del marco analítico de los modelos de ecuaciones estructurales.

