










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkProspectiva
versão impressa ISSN 1692-8261
Prospect. vol.12 no.2 Barranquilla jul./dez. 2014
https://doi.org/10.15665/rp.v12i2.288
http://dx.doi.org/10.15665/rp.v12i2.288.
Desarrollo de un algoritmo para determinar el riesgo de muerte en pacientes dentro de una Unidad de Cuidado Intensivo utilizando Regresión Múltiple no Lineal
Development of an algorithm to establish the death risk for patients on an Intensive Care Unit using Non Linear Multiple Regression
Cindy María García García1, José David Posada Aguilar2, Jair Villanueva Padilla3
1 Ingeniera Electrónica y en Telecomunicaciones, Semillero de Investigacion, Universidad Autonoma del Caribe, Barranquilla, Colombia. Grupo de Investigación (IET-UAC),
2 Magister en Ingenieria Mecanica, Profesor Titular, Universidad Autónoma del Caribe, Grupo de Investigación (IET-UAC), Barranquilla, Colombia.
3 Magister en Ingeniaría Biomédica, Profesor Titular, Universidad Autónoma del Caribe, Grupo de Bioingeniería,CEBI-UAC. Barranquilla, Colombia
Email: jdposa@gmail.com.
Recibido 23/05/14, Aceptado 22/06/2014
Citar como: C.M.Garcia, J.D.Posada, J.Villanueva, "Development of an algorithm to establish the death risk for patients on an Intensive Care Unit using Non Linear Multiple Regression", Prospect, Vol 12, N° 2, 49-56, 2014.
Resumen
Los sistemas de clasificación de la severidad de la enfermedad han sido utilizados por décadas por médicos en todo el mundo dentro de la Unidad de Cuidado Intensivo, como un indicativo del estado de salud del paciente y la probabilidad del riesgo de muerte del mismo. A pesar de la aceptación de dichos sistemas de clasificación, se ha demostrado que no tienen los resultados más precisos, es por esta razón que los científicos e ingenieros han probado diversas técnicas para buscar mejorar dichos sistemas. En este artículo se presentan los resultados del desarrollo de un algoritmo para la determinación del riesgo de muerte utilizando regresión múltiple no lineal y su comparación con los resultados obtenidos con el sistema de clasificación tradicional SAPS I. Partiendo de una base de datos de mediciones de parámetros fisiológicos para 4000 pacientes, se realiza un procesamiento extendido de la misma, aplicándosele análisis de datos y probándose las técnicas de regresión múltiple no lineal: Árbol de regresión, Regresión logística, Máquina de Vector de Soporte y Redes Neuronales Artificiales. Los mejores resultados se obtuvieron con la técnica Máquina de Vector de Soporte, logrando superar el desempeño del sistema SAPS I.
Palabras clave: Parámetros fisiológicos, Regresión Múltiple no Lineal, Riesgo de muerte, Sistemas de clasificación de la severidad de la enfermedad, Unidad de Cuidado Intensivo.
Abstract
Systems for scoring the severity of illness had been used for decades on the Intensive Care Unit (ICU) of Health Care Institutions as indicators of the patient’s health and risk of death. Even after being accepted worldwide, it has been proved that these systems have limitations and do not provide the most accurate results, it is because of this that scientists and engineers have tried different techniques in order to improve these systems. This article presents the results of the development of an algorithm that uses non-linear multiple regression to establish the death risk for patients in the ICU, and the comparison of those results with the ones given by the SAPS I traditional scoring system. Parting from a database of physiological variables measurements for 4000 patients, an extended processing of this database is made together with data analysis, to finally apply the nonlinear multiple regression techniques: Regression trees, Logistic Regression, Support Vector Machine and Artificial Neural Networks. The best results were obtained with the Support Vector Machine technique, having a better performance in comparison with the SAPS I score.
Keywords: Physiological variables, Non Linear Multiple Regression, Death risk, Systems for Scoring Severity of Illness, Intensive Care Unit.
1. Introducción
Las Unidades de Cuidado Intensivo (UCI) representan un gran porcentaje del presupuesto empleado dentro de una Institución Prestadora de Salud, por lo que la priorización de la atención y el uso eficiente de los recursos físicos, tecnológicos y humanos dentro de estas siempre se han constituido en un tema de interés para dichas instituciones, especialmente en las últimas décadas. [1] El deseo de la comunidad médica es que los servicios en Cuidados Intensivos tengan una relación costo-beneficio favorable para las instituciones de salud, sin dejar de proveer el mejor tratamiento posible a los pacientes. En concordancia a lo que reporta la revisión de la literatura especializada, una de las herramientas más importantes para alcanzar dicho propósito son los sistemas de clasificación de severidad o gravedad de enfermedades, los cuales han ayudado al personal médico a través de las últimas décadas en la toma de decisiones en aspectos relacionados con el diagnóstico, el tratamiento y la asignación de recursos utilizados en la atención del paciente; de forma adicional, permiten al personal médico determinar el impacto que ciertos medicamentos, cirugías u otras intervenciones tienen sobre la mortalidad de los pacientes en una UCI.
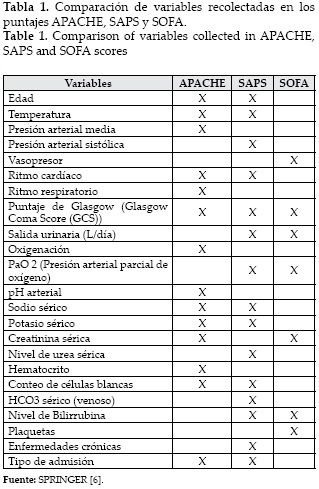
Algunos de los sistemas utilizados en la actualidad son el SAPS [2] (por sus siglas en inglés, Simplified Acute Physiology Score), APACHE [3], (por sus siglas en inglés, Acute Physiology an Chronic Health Evaluation) y SOFA [4] (por sus siglas en inglés, Sepsis-related Organ Failure Assessment), los cuales emplean la peor medición (el valor más relacionado con una condición de salud en deterioro) de aproximadamente 10 parámetros fisiológicos del paciente (ver Tabla 1) en las primeras 24 horas en su instancia en la UCI, se escoge este número de parámetros, porque se busca que representen el estado de los órganos principales del organismo: riñón, hígado, corazón, pulmones, entre otros. Dependiendo del sistema utilizado, se le asigna un determinado puntaje a cada uno de los parámetros fisiológicos conforme a la medición existente, dichos puntajes se suman, y el valor resultante se introduce en una ecuación de regresión logística, que arroja una evaluación de la severidad de la enfermedad del paciente, y con la cual también se puede predecir mortalidad [5][6].
A pesar que estos sistemas de clasificación de severidad o gravedad de enfermedades son utilizados a diario dentro de las UCI, investigaciones como [7], muestran que dichos sistemas presentan diversos problemas como son: precisión variable dependiendo del tratamiento aplicado o del grupo de pacientes, mala calibración, e incluso pueden resultar no útiles con las nuevas tecnologías, las nuevas prácticas clínicas o cambios en las normas de atención. Es aquí donde surge la necesidad de la Comunidad Médica de desarrollar un método más eficiente para la determinación del riesgo de muerte en pacientes dentro de una UCI.
Es por esto que en investigaciones recientes, se han utilizado diversos métodos para mejorar los índices actuales, como regresión logística [8][9], combinada con redes bayesianas [10] y modelos de cadenas de Markov [11], ensambles de redes neuronales [12], maquinas de vectores de soporte (SVM) [13] y modelos aditivos [14]. Todas estas investigaciones lograron mejorar los índices ya existentes y mas usados, y algunas de ellas como [14] fueron probadas en entornos clínicos reales.
Teniendo en cuenta el panorama presentado, en este artículo se describe el proceso para el desarrollo de un sistema de clasificación de severidad o gravedad, partiendo desde el estudio de los principales parámetros fisiológicos del cuerpo humano y proponiendo el uso de una técnica de regresión múltiple no lineal (de forma alterna a la regresión logística de los sistemas actuales). Con esto, se buscó establecer la eficacia de dicho algoritmo frente a los sistemas de clasificación de severidad o gravedad utilizados en la actualidad, con la intención de constituir una base para el desarrollo de un sistema de clasificación de severidad de alta eficiencia en el futuro.
2. Metodología
Para el desarrollo del algoritmo para determinar el riesgo de muerte en pacientes dentro de una Unidad de Cuidado Intensivo, inicialmente se debe tomar la información relacionada con los parámetros fisiológicos medibles dentro de una UCI, procesarla, y con base en los resultados, determinar relaciones de causa y efecto entre las diferentes variables, para determinar el riesgo de muerte y desarrollar el sistema.
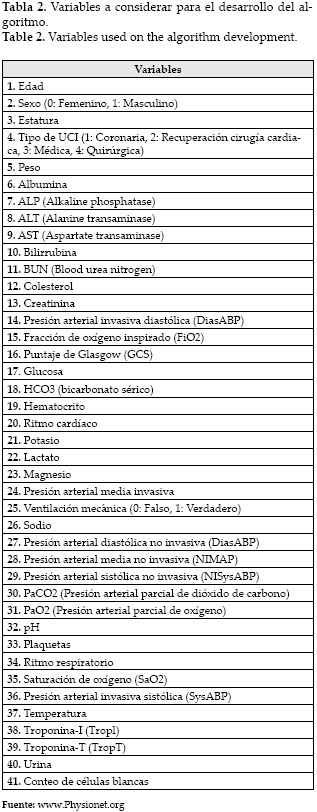
La muestra que se estudió corresponde a las mediciones de 41 parámetros fisiológicos en las primeras 48 horas desde el ingreso a la UCI para cuatro mil pacientes, indicando adicionalmente si el paciente fue dado de alta (sobrevivió) o murió. Este conjunto de datos fue provisto por la base de datos Physionet [7] en 2012. Las variables a utilizar pueden verse en la Tabla 2.
Para el desarrollo de este proyecto se llevó a cabo una revisión profunda de la literatura especializada, que permitió identificar las técnicas más utilizadas por otros investigadores, como un punto de inicio, con base en esto se procedió a identificar los parámetros fisiológicos significativos en la determinación del riesgo de muerte de un paciente en una UCI [8][9][10][11][12][13][14].
Posteriormente se inició con el análisis estadístico del conjunto de datos para determinar sus características. El análisis estadístico consistió en el estudio de las características del conjunto de datos para determinar las variables a considerar, el tipo de distribución que siguen y demás información requerida para el desarrollo del algoritmo.
Habiendo logrado esto, se realizó la extracción de características sobre el conjunto de datos y finalmente la aplicación de las técnicas de regresión múltiple no lineal a los mismos. Para terminar, se validó el desempeño del algoritmo a través cálculo de las medidas estadísticas: Sensitividad (fracción de muertes que fueron predichas) y Predictividad positiva (fracción de muertes que fueron predichas correctamente), y se compararon los resultados con los arrojados por el sistema de clasificación de severidad de las enfermedades SAPS I que fue evaluado en el mismo conjunto de datos.
3. Resultados
Siguiendo los pasos planteados con anterioridad, inicialmente se descarga el conjunto de datos de Physionet [7] que contiene información de mediciones de 41 parámetros fisiológicos para las primeras 48 horas de estadía del paciente en la UCI, estos se procesaron para conseguir una estructura adecuada al estudio. Así, se tiene inicialmente una estructura de datos de una fila y 4000 columnas (una columna por paciente), cada celda contiene a su vez tres celdas: La primera contiene las horas de medición (en formato hh:mm), la segunda contiene la variable medida, y la tercera el valor medido para la variable. Para cada paciente existían al menos 100 mediciones diferentes.
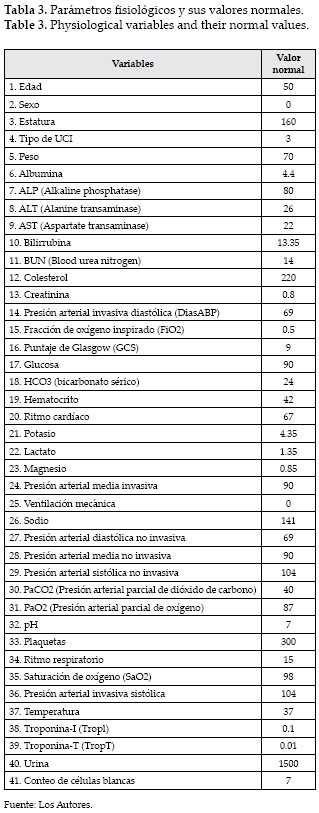
Para iniciar, se escogió el promedio, el valor máximo y el valor mínimo por variable como las características representativas del conjunto de datos. Así, se organizó una tabla de 4000 filas (una fila por paciente) y 123 columnas que contenía el promedio, valor máximo y valor mínimo por variable y por paciente, las primeras 41 columnas contenían el valor promedio para cada variable, las columnas 42 a 82 contenían el valor máximo para cada variable, y las columnas 83 a 123 contenían el valor mínimo para cada variable. Ya que los parámetros fisiológicos no se medían siempre en todos los pacientes, aquellos valores de promedio, valor máximo y mínimo de variables que no se medían se reemplazaban por el valor normal o esperado para dicha variable (ver la Tabla 3).
Con base en la información de la tabla resultante, se realizó un conjunto de gráficas preliminares y se percibió que había un gran número de valores fuera de los rangos posibles para las variables. En consecuencia, se realizó una "limpieza" de los datos, eliminando aquellos pacientes que presentaban valores imposibles para los parámetros fisiológicos estudiados en cualquiera de las tres características seleccionadas: promedio, valor máximo o valor mínimo. De esta manera, el conjunto de datos se redujo a 3479 pacientes, habiéndose eliminado más del 10% del conjunto de datos original. De estos 3479 pacientes, 420 morían y 3059 sobrevivían, lo que muestra que el conjunto de datos es desbalanceado.
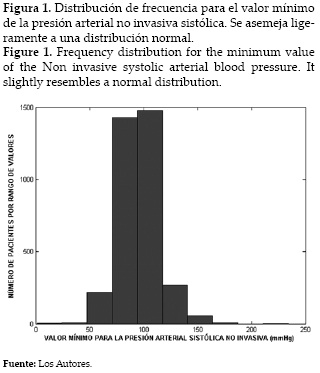
A partir de este set de datos, se generó un conjunto de gráficas exploratorias para, por medio de la visualización de la información, poder identificar patrones o características que diesen algún indicio para tener en cuenta en etapas posteriores del análisis. Estas gráficas incluyeron: el histograma para cada promedio, valor máximo y valor mínimo, para determinar la distribución de las variables (Figura 1); la distribución completa de los puntos para cada variable coloreándose de negro los puntos correspondientes a los pacientes que fallecían, y de gris los correspondientes a los pacientes que sobrevivían, esto con el fin de intentar identificar si se formaban grupos o clusters dentro de las mediciones que permitieran identificar si ciertos valores tomados por un parámetro estaban asociados con la muerte o supervivencia del paciente (Figura 2); y se graficó también el estado final del paciente (muerte o supervivencia) contra los valores tomados para cada una de las características seleccionadas por variable, para tratar de identificar si había alguna tendencia en el comportamiento entre la muerte o supervivencia y los parámetros fisiológicos, y determinar si existía alguna diferencia entre las medias de los valores que los parámetros tomaban dependiendo de si el paciente moría o no (Figura 3). Ninguna de las gráficas generadas permitió establecer una relación o tendencia concreta entre la muerte y los valores tomados por los diferentes parámetros fisiológicos; pues la mayoría de estos tendieron siempre a distribuirse alrededor de una línea central (el valor normal o la media para la variable respectiva), sin formar grupos. No se percibió tampoco una distinción clara entre los valores tomados para los pacientes que sobreviven y los que no sobreviven. Los valores promedio para pacientes que sobrevivían o morían eran muy similares, por lo que no se pudo establecer una relación concreta.
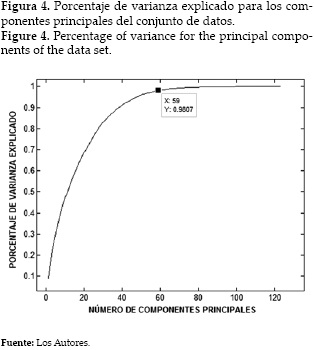
Después de haber realizado un análisis exploratorio inicial de los datos y haber determinado que no siguen un comportamiento uniforme ni lineal, se procede a buscar una herramienta estadística que permita disminuir la dimensionalidad del conjunto de datos, ya que se tienen 123 atributos; para este fin, se escoge la técnica de PCA (Principal Component Analysis o Análisis de Componentes Principales). Inicialmente, se estandarizan todos los datos y se obtiene la matriz de componentes principales utilizando MATLAB®. Dicha matriz es graficada y se calcula el número de componentes principales que se deben tomar para representar el 98% de la varianza del conjunto de datos, los cuales resultan ser 59 componentes principales. Dicha selección se puede evidenciar en la Figura 4.
A partir de la matriz con los 59 componentes principales, se transforman los datos originales estandarizados. A este nuevo conjunto de datos transformados es al cual se le aplicará la regresión múltiple no lineal. Para iniciar con el entrenamiento de los modelos de regresión múltiple no lineal, se procede a escoger los conjuntos de entrenamiento y validación. Como ya se dijo antes, el conjunto de datos es desbalanceado, ya que de 3479 pacientes, solamente 420 mueren y 3059 sobreviven. Si se hubiese tomado un conjunto de entrenamiento y validación al azar, era muy probable que en alguno de estos conjuntos hubiese quedado con un número muy pequeño o nulo de pacientes que fallecían, lo cual habría afectado el desempeño del modelo a entrenar, pues éste no habría contado con el número suficiente de casos de fallecimiento para que el algoritmo aprendiese a identificarlos. De esta forma, se escogió el conjunto de entrenamiento y validación para que contuvieran siempre un 70% de los pacientes que fallecían, al conjunto de entrenamiento se le agregaron 400 pacientes que sobrevivían, y al de validación, mil pacientes que sobrevivían (Grupo de validación equilibrado). Adicional-mente, se creó un conjunto de datos de validación que contenía el 70% de pacientes que fallecían y el resto de los pacientes que sobrevivían que no habían sido incluidos en el conjunto de entrenamiento, es decir, más de 3000 (Grupo de validación completo).
La técnica de regresión múltiple no lineal utilizada fue un arboles de decisiones, redes neuronales artificiales, máquinas de vector de soporte y regresión logística. Para todas las técnicas fueron utilizados los mismos conjuntos de entrenamiento y validación, a excepción de las redes neuronales artificiales, los cuales cumplieron los criterios antes mencionados pero los datos fueron seleccionados al azar.
La primera técnica utilizada fue los arboles de decisión. Fueron entrenados 10 árboles utilizando los datos transformados con 59 componentes principales. A los resultados, se les calculó las medidas estadísticas Predictividad Positiva (PPV, fracción de predicciones correctas para muerte del paciente) y Sensitividad (Se, fracción de muertes que son predichas), relacionadas con los términos TP: verdadero positivo, FP: falso positivo, y FN: falso negativo; y dadas por las siguientes fórmulas:
PPV = TP / (TP + FP) (1)
Se = TP / (TP + FN) (2)
El puntaje entregado por la base de datos Physionet para la técnica tradicional SAPS I es de 0.3125, que corresponde al valor mínimo entre la Predictividad Positiva y la Sensitividad del método utilizado. De esta manera, se calculó el puntaje o desempeño de los árboles de decisiones, inicialmente con el grupo de validación equilibrado; y ya que el desempeño no logró superar al del SAPS I a pesar de haberse entrenado 10 árboles diferentes, no se probó con los demás grupos de validación.
De manera similar, se calcula la Predictividad Positiva y Sensitividad para los demás métodos, con los cuales además de utilizarse el modelo con las 59 componentes principales, se utilizaron también los datos transformados con las 123 componentes principales. Los resultados arrojados pueden verse en la Tabla 4.
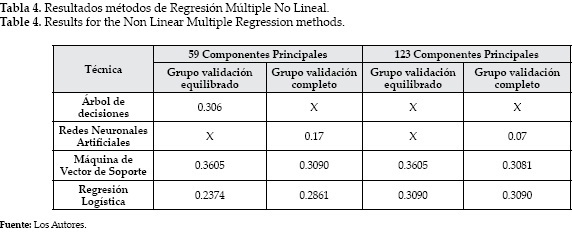
En conformidad a los resultados, se puede ver que el método que mejor desempeño tuvo fue el de Máquina de Vector de Soporte. Todos los métodos se probaron con diferentes grupos de entrenamiento y validación adicionales a los finalmente utilizados para entender la dinámica del modelo, y el método de SVM fue el único que alcanzó puntajes entre 0.40 y 0.45 cuando se utilizaba un conjunto de validación completo no con 1000 pacientes que sobrevivían sino con un número menor, entre 400 y 800. Se reportan los resultados para los grupos de validación descritos, pues estos grupos de validación fueron los que entregaron el mejor desempeño para ambos casos en SVM; al encontrarse el modelo con un grupo desbalanceado (grupo validación completo), pudo mantener un desempeño casi igual al del SAPS I.
4. Conclusiones
-
Tras haber desarrollado el proyecto descrito con la intención de aplicar las herramientas estadísticas e informáticas a favor de la ciencia médica, se puede concluir que se lograron los objetivos en el desarrollo de un algoritmo para la determinación del riesgo de muerte en pacientes en una Unidad de Cuidado Intensivo. Habiéndose realizado un estudio exhaustivo de la literatura especializada, se pudieron identificar los métodos de regresión múltiple no lineal más indicados para este proyecto.
-
Los resultados demuestran que es posible desarrollar un algoritmo que mejore el desempeño de los sistemas utilizados actualmente para determinar el riesgo de muerte, y es un tema en el cual vale la pena seguir ahondando, pues responde también a lo que se está trabajando mundialmente. El algoritmo desarrollado, a pesar de que tuvo un buen desempeño podría ser mejorado, y las limitaciones del mismo están relacionadas con el conjunto de datos con el que se contaba, pues se encontraron muchísimos datos corruptos y faltantes, no midiéndose todas las variables en todos los pacientes. Estas características disminuían la posibilidad de interrelacionar los parámetros fisiológicos entre sí, y con la mortalidad del paciente.
-
Para que se hubiese podido desarrollar un análisis más exhaustivo y un procesamiento más completo del conjunto de datos antes de ser aplicado a las técnicas de regresión, se debería haber contado con un computador con un procesador de mayor gama. Muchas de las operaciones de pre procesamiento y limpiado de la información tomaban demasiado tiempo, lo que hacía tedioso y lento el avance en esta etapa; esto también habría permitido detectar y eliminar los datos fuera de rango desde la información inicial, y no desde los datos ya procesados, lo cual causó la pérdida de los datos de más de 600 pacientes.
- Las herramientas estadísticas e informáticas muestran ser útiles para la resolución de problemáticas médicas, por lo que son estrategias que deben seguir implementándose. En particular, el estudio de los parámetros fisiológicos de pacientes dentro de una UCI con ayuda de la informática médica, puede llegar a permitir dentro del contexto colombiano y como ya se está dando en el mundo, que se logren avances y descubrimientos que les sirvan de herramientas de apoyo al personal médico y asistencial, y finalmente, al paciente.
Referencias
[1] S. Vairavan, L. Eshelman, S. Haider, et al, "Prediction of Mortality in an Intensive Care Unit using Logistic Regression and a Hidden Markov Model", Computing in Cardiology, vol. 39, pp. 393-396, 2012. [ Links ]
[2] W. A. Kanus, J. E. Zimmerman, D. P. Wagner, et al, "APACHE- acute physiology and chronic health evaluation: A physiologically based classification system", Crit Care Med, vol. 9, pp. 591, 1981. [ Links ]
[3] S. Lemeshow, J. Klar, D. Teres, et al, "Mortality Probability Models for patients in the intensive care unit for 48 or 72 hours: a prospective, multicenter study", Crit Care Med, vol. 22, pp. 1351-1358, Sep. 1994. [ Links ]
[4] Springer (2006). Comparison of variables collected in APACHE, SAPS and SOFA scores [Internet]. Disponible desde: <http://www.springerimages.com/Images/RSS/5-10.1186_1471-2334-6-132-0.> [Acceso 23 de mayo 2014] [ Links ].
[5] J. Vincent, R. Moreno, J. Takala, et al, "The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure", Intensive Care Med, vol. 22, pp. 707-710, 1996. [ Links ]
[6] J. Mata, "Escalas pronósticas en la Unidad de Terapia Intensiva", Revista de la Asociación Mexicana de Medicina Crítica y Terapia Intensiva, vol. 25, no. 4, pp. 234-241, 2012. [ Links ]
[7] Physionet 2012 Challenge (2012) [Internet]. Disponible desde: <http://www.physionet.org/challenge/2012.> [Acceso 23 de mayo 2014] [ Links ].
[8] C. H. Lee, N. M. Arzeno, J. C.Ho, H.Vikalo, & J.Ghosh, "An Imputation-Enhanced Algorithm for ICU Mortality Prediction". Computing in Cardiology, vol 39, pp 253-256, 2012. [ Links ]
[9] E. P. Goss, & H. Ramchandani, "Survival prediction in the intensive care unit: a comparison of neural networks and binary logit regression". Socio-Economic Planning Sciences, vol. 32(3), pp. 189-198, 1998. [ Links ]
[10] L. A. Celi, S.Galvin, G. Davidzon, J. Lee, D.Scott, & R. Mark, "A Database-driven decision support system: customized mortality prediction". Journal of personalized medicine, vol. 2(4), pp. 138-148, 2012. [ Links ]
[11] S. Vairavan, L. Eshelman, S. Haider, A. Flower & A. Seiver, "Prediction of Mortality in an Intensive Care Unit using Logistic Regression and a Hidden Markov Model". Computing in Cardiology, vol 39, pp 393-396, 2012. [ Links ]
[12] H. Xia, B. J. Daley, A. Petrie & X. Zhao, "A Neural Network Model for Mortality Prediction in ICU". Proc. Computing In Cardiology 2012, vol. 39, pp. 261-264, 2012. [ Links ]
[13] O. Luaces, F. Taboada, G. M. Albaiceta, L.A. Domínguez, P. Enríquez, & A. Bahamonde, "Predicting the probability of survival in intensive care unit patients from a small number of variables and training examples". Artificial intelligence in medicine, vol. 45(1), pp. 63-76, 2009. [ Links ]
[14] K. Hekmat, F. Doerr, A. Kroener, M. Heldwein, T. Bossert, A. M. Badreldin, & A. Lichtenberg, "Prediction of mortality in intensive care unit cardiac surgical patients". European Journal of Cardio-Thoracic Surgery, vol. 38(1), pp. 104-109, 2010. [ Links ]
