



![Polyurethane copolymers of the type poly[(hexamethylene carbamate-butandiol)-co-(carbonato-co-ester)]](/img/en/prev.gif)







 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroduction
In the Petrochemical Industry exists considerable interest in the development of analytical methods that provide high-quality information in short time. Petrochemical industries routinely monitor and control transformation processes using analytical information. Traditionally, standardized methods are used to determine physicochemical properties of petroleum crude oils and their fractions. These methodologies are time-consuming and require a significant amount of sample. The development of methods for accurate and fast analysis has become an urgent need to control the quality of petroleum crude oils and their fractions or cuts production processes. A large number of analytical techniques including high-performance liquid chromatography (HPLC), nuclear magnetic resonance (NMR), mass spectrometry (MS), fluorescence spectroscopy, Raman and infrared spectroscopy have been widely applied to the analysis of hydrocarbons and their derivatives 1,2,3,4,5,6,7,8. These techniques provided excellent results in comparison with traditional methodologies of analysis; however, some of them are expensive and not always available in all laboratories.Fourier Transform Near Infrared Spectroscopy (FT-NIR) has been used as a promising alternative to replace traditional American Society for Testing and Materials methods (ASTM) to determine physicochemical properties of the petroleum crude oils and their fractions, because it requires a minimum sample treatment, the acquisition of spectra takes a few minutes and offers an acceptable repeatability for liquid and solid samples 6,7,8,9.
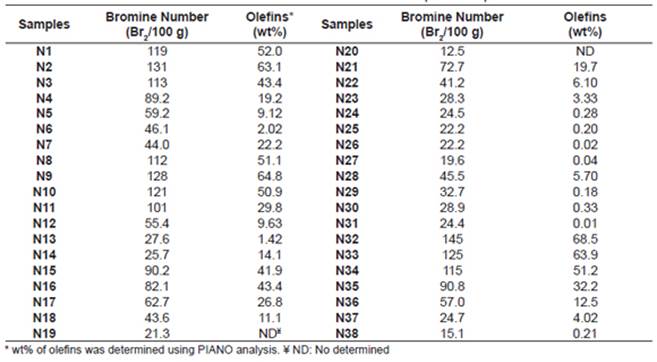
Bromine Number (BN) is standardized methodology (ASTM D 1159 10), to determine olefin contents in light fractions of petroleum (distillates <350oC). The BN value is the amount of bromine which reacts with 100 grams of sample.
Olefins are not present in virgin crude oils; they are produced during oil refining schemes which imply thermal and catalytic processing such as fluid catalytic cracking (FCC) to obtain gasoline and naphtha. Although olefins contained in gasoline can increase the octane number, they may have negative effects on engine deposits and exhaust emissions because of their active chemical properties, particularly about the formation of gums and photochemical smog 11. Hence, the bromine number is an important quality parameter of light fractions of petroleum crude oils.
The combination of FT-NIR and chemometrics models has allowed developing robust methods for the prediction of properties of complex samples, such as petroleum crude oil and their fractions. The principal component analysis (PCA) allows discriminating samples through the analysis of score and loading plots 12; while partial least squares regression (PLS-R) provides models for the prediction of different properties from spectroscopic data 13,14. In this work, we developed a methodology to predict the bromine number analysis of Colombian naphtha samples, based on the combined use of FT-NIR, PCA, and PLS regression. The accuracy of the PLS regression for predicting bromine number was established by evaluating the root mean square error of prediction (RMSEP) and root mean square error of calibration (RMSEC) as well as the correlation coefficient (R2). Although PLS regression is the chemometric method most widely used in combination with spectroscopic data, it is well known that the greatest problem in the methodology is the assumption of linear spectral data-property relationship. This assumption may be unacceptable for systems with strong intermolecular or intramolecular interactions, including π-stacking 15,16,17,18. Therefore, also, we performed a Multiple Polynomial Regression to develop the MPR, we used principal components (PC) of the NIR spectral data of the naphtha samples, as inputs or X-variables
Experimental
Samples
Thirty-eight Colombian naphtha samples were used in this work. Conventional bromine number analysis was determined by electrometric titration (ASTM D1159) 10. One Mettler Toledo model T90 titrator was used. The temperature for the analysis spanned 0-5ºC, according to the standardized method. Table 1 shows results of bromine number and olefins obtained via the ASTM method.
Acquisition of NIR Spectra
FT-NIR spectra were recorded on a Bruker VERTX 70v spectrometer with a spectral resolution of 8cm-1 over the range of 4000-13500cm-1, at 20±0.10C and 32 scans acquisition. Despite the fact that in the majority of works the acquisition of spectra is reported with 4cm-1, the aim of selecting a resolution of 8 cm-1 was to reduce the acquisition time to one-half, an important aspect for analyzing a high number of samples. The spectrometer is equipped with a deuterated L-alanine doped triglycine sulfate detector (DLaTGS) and a transmittance sample cell of quartz with 0.5mm optical path. The acquisition time for 32 scans was approximately 30s.
The background spectrum of air was collected for every sample before the analysis in the single beam mode. The spectral files were transformed to ASCII format using the IR Solution software and exported to The Unscrambler software, version X. Five naphtha samples were randomly chosen; ten spectra were recorded for each sample on ten different aliquots. Standard deviation determined was approximately 1x10-3 (in absorbance units) for any wavenumber.
Data analysis
Processing of spectroscopic data obtained including spectral pre-treatment, PCA, PLS, and validations was performed with the UnscramblerX and MPR was carried out with MATLAB® software.
Principal components analysis
PCA permits to find out samples pattern and which spectral intensities contribute most to this difference. PCA was done through the Unscrambler Software Version X by using Nonlinear Iterative Partial Least Squares algorithm (NIPALS). This algorithm handles missing values and is suitable for computing only the first few factors of a data set. The low information was extracted from the three principal components.
PLS regression
PLS-R was used to establish the relationship between NIR spectral intensities and the bromine number of naphtha samples. PLS-R is a useful procedure to find a common structure between one or more characteristic properties of the samples, called independent variables or simply Y variables, and the spectral intensities, called dependent variables or X variables. In our case, the bromine number in the naphtha samples is the Y variable, while the NIR spectral intensities are X variables. The linear PLS model finds a few variables, which are estimates of the latent variables (LVs) or their rotations. These variables are called X scores, and they are predictors of Y, and also model X; i.e., both Y and X are assumed to be, at least partly, shaped by the same LVs. X scores are estimated as linear combinations of the original matrix of X variables with the weighted coefficients, Wka* (a = 1, 2,..., A). This could be more clearly seen in Equation 1.

Where k denotes the number of X variables or spectral intensities, and i is the number of samples 19. The regression model can be written according to the Equation 2

meaning that the observed response values are approximated by a linear combination of the values of the predictors. The coefficients of that combination are called regression coefficients or b coefficients. These coefficients are calculated from X scores and Y score. A deeper analysis of the relationship between scores is beyond the scope of this paper, but it is correctly explained by Wold et al. 19. Regression coefficients summarize the relationship between all predictors and a given response. For PLS, the regression coefficients can be computed for any number of components; i.e., for every latent variable, there are different b coefficients. When X variables have been centered, all predictors are brought back to the same scale; the coefficients show the relative importance of the X variables in the model. Predictors with a the regression model; a positive coefficient shows a definite link with the response, and a negative coefficient indicates a negative relationship. Predictors with a small coefficient are negligible.
Multiple Polynomial Regression (MPR)
MPR is a particular form of linear regression in which the correlation between independent variable X and the dependent variable Y is considered as an nth order polynomial. In a view to performing the regression, principal components (PC) for each sample were used as independent variables and bromine number (BN) values as dependent variables. So, multiple polynomial regression can be represented by the following Equation;

Where air (i,j = 1, 2, 3…) are the coefficients that model the relationship between BN and PC for each sample 20. The goal of MPR is to determine the values of air and minimizing the error, ε.
NIR analysis
Figure 1 shows the NIR spectra of naphtha samples, all showing very similar spectra. In Figure 1, it is though to differentiate between the NIR spectra of heavy and light naphtha samples. However, it is possible to find small differences in the region spanning from 4400-4800cm-1, in particular between the heaviest and light naphtha samples. The bands spanning the region 4400 to 4800cm-1 region correspond to a combination of the fundamental vibrational modes =CH- stretch and C=C stretch. Also, appreciable differences in the region spanning from 5200 to 6500cm-1 can be observed, due to overtones of the vibrational modes corresponding to asymmetric and symmetric stretching of C-H bonds in methyl and methylene group in aliphatic and aromatic compounds. However, even though it is posible to differentiate the naphtha samples through six bands located at 4258, 4335, 4393, 5716, 5866 and 6113cm-1, only after modeling is it possible to know if these differences are associated with the Y variable (bromine number).
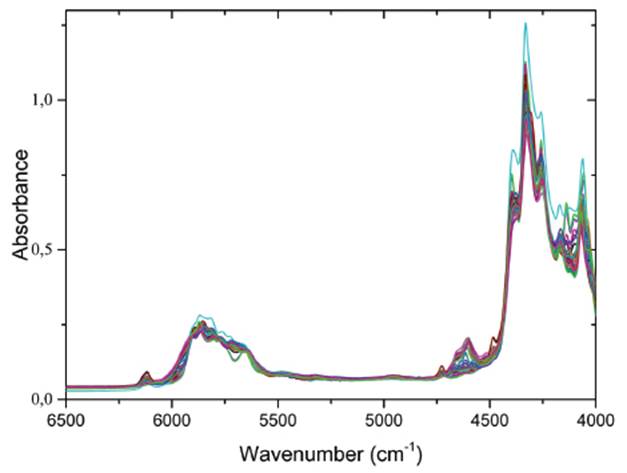
Figure 2a and 2b shows average FT-NIR spectra of heavy and light naphtha samples in the 6500-4000cm-1 range. The overall spectral features were similar to each other. However, slight differences are observed around 4600cm-1, corresponding to aromatic bands. Light naphtha samples show a higher concentration of aromatic compounds. These bands corresponding to olefin compounds, particularly from a combination of =C-H stretching at 3100-3000cm-1 and C=C ring stretching at 1600-1450cm-1.

Principal component analysis
Principal component analysis was performed using three spectral regions: 4000-4800cm-1, 5200-6350cm-1, and 4000-6350cm-1. In all cases, the first three PCs explained more than 85% of the total variance. These three PCs were used as X-variables in multiple polynomial regression. Figs. 3 show the PCA performed on the three spectral regions.
The plots show two perfectly distinct groups of naphtha samples; twenty-four heavy naphtha samples with a range of bromine number spanning from 12.5 to 72.7 and a group of fourteen light naphtha samples with bromine number between 82.1 and 145. However, N14 y N32 have BN values out of this range. According to Figure 3a, 3b, and 3c, the N32 sample could be considered an outlier, while N14 has a percent of olefin similar to samples in the first range (Table 1). The discrimination between heavy and light naphtha samples occur in PC1; for the region spanning from 4000 to 4800 cm-1, heavy naphtha samples have negative values and light naphtha samples have positive values of PC1, while for the region spanning from 5200 to 6350cm-1, heavy naphtha samples have positive values and light naphtha samples negative values of PC1. The behavior of PC2 is entirely contrary.
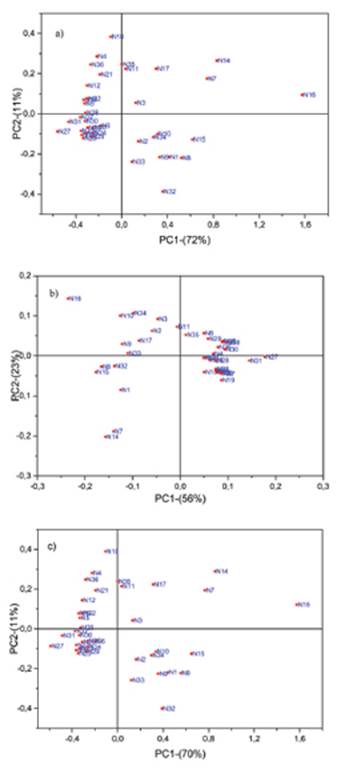
Figure 3 Scores plots of principal components PC1 and PC2 of thirty-eight naphtha samples in the region (a) 4000-4800cm-1 (b) 5200-6350cm-1 and (c) 4000-6350cm-1
Figures 4a and 4b show loading for PC1 of NIR spectral regions from 4000 to 4800cm-1 and from 5200 to 6350cm-1. As mentioned above, the bands in the spectral region between 4000 and 4800cm-1 mainly correspond to a combination of the fundamental vibrational modes C=C stretch of olefins in naphtha samples. While the spectral region from 5200 to 6350 essentially corresponds to overtones of the vibrational modes of symmetric and asymmetric stretching of C-H and =CH- bond in saturated unsaturated aliphatic compounds. Therefore, the first principal component (PC1) may be attributed to the olefin part in naphtha samples and the second one to aliphatic compounds.
PLS analysis
Intensities from FT-NIR spectra and bromine number for the studied naphtha samples were correlated using PLS regression. After dividing samples into the two groups, i.e., light and heavy naphtha samples according to PCA results, PLS regression was employed to build quantitative calibration models for each group.

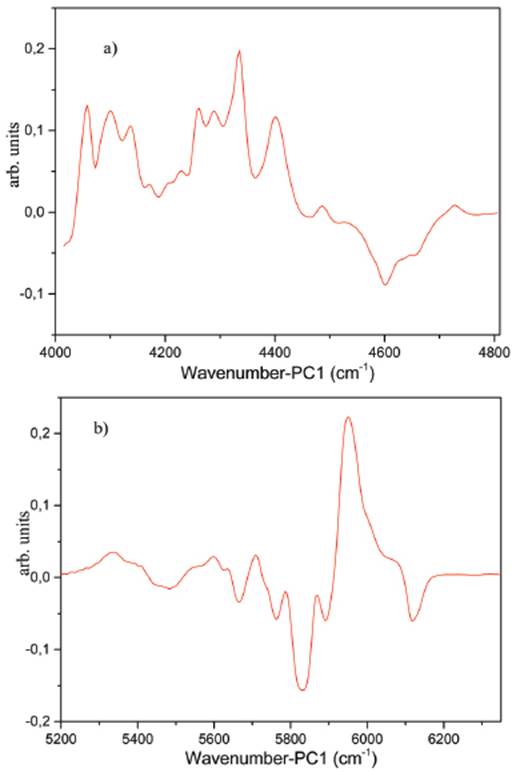
Figure 4 Loadings for PC1 of NIR spectral regions from (a) 4000 to 4800cm-1 and (b) 5200 to 6350cm-1.
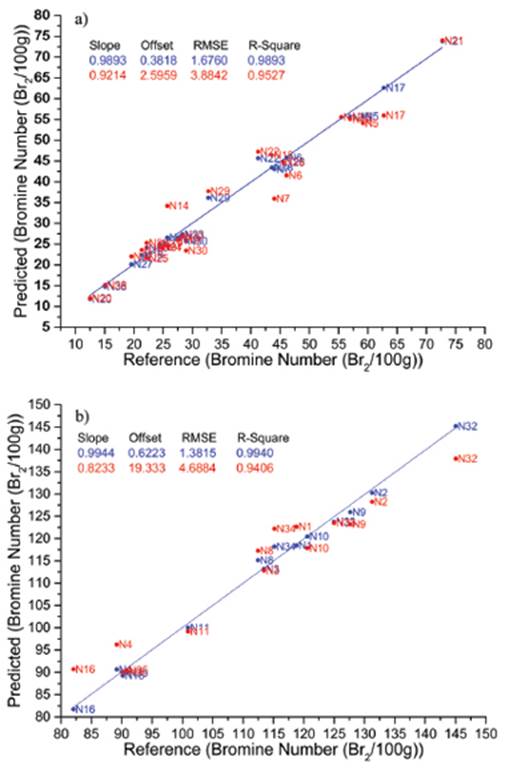
The spectral region that best related to BN was between 5200 and 6350cm-1. The development of predictive models was conducted in two stages; the first one consisted of building calibration models (Fig.4), and the second stage was the validation of the models. The evaluation of the calibration performance was assessed by the root mean squared error of calibration (RMSEC). The standard root mean squared error of prediction (RMSEP) for validation gives an evaluation of the predicted performance of the quantitative model obtained previously. The RMSEC and RMSEP were 1.68 and 3.88 for light naphtha samples, and 1.68 and 4.69 for heavy naphtha samples, respectively. The RMSEC and RMSEP are shown in Table 2 together with the NIR spectral regions, explained variance and factor numbers employed. In all cases, seven factors were used and just one sample (N17), in the model for light naphtha samples was eliminated as an outlier. When the spectral region from 5200 to 6350cm-1 was selected, the best RMSEP was obtained. If many variables (all wavenumber signals) are used, the model may be unstable; it means that small changes in the spectrum of the order of the spectral noise may produce statistically significant changes in the prediction. These results found in this research indicate that the NIR spectral data can be actually used for the bromine number estimation of naphtha samples.

PMR
To compare with PLS-R, multiple polynomial regression calibrations (MPR) was obtained. We used the same wavenumber range selected for PLS-R. Three first principal components (PC), were used as X variables and they explained more than 85% of the data variance. Figure 5 shows the best results when a third order polynomial function and twenty terms (PC1 PC2 PC3 PC1PC2 PC1PC3 PC2PC3 PC12 PC2 PC32 PC1PC2PC3 PC12PC2 PC22PC3 PC32PC1 PC12PC3 PC22PC1 PC32PC2 PC13 PC23 PC33 1) were used. The RMSEC value is 7.44Br2/100 g.
This value is very high compared to the one obtained via PLS-R. It is possible to use a fourth order polynomial function. However, thirty-five terms will be necessary. When a fourth order polynomial function is used, RMSEC can be decreased to as low as 1.00; however, this result can be due to over-fitting. The preceding results show that the spectral data-bromine number property relationship is linear.
Conclusion
In this study, the determination of bromine numbe of naphtha samples by FT-NIR coupled to PCA, PLS and MPR was studied. The PCA allowed identifying two groups of naphtha samples, i.e., light and heavy naphtha samples according to their bromine number. The PLS multivariate calibration allowed obtaining prediction model for determination of bromine number. RMSEC and RMSEP for light naphtha samples were 1.6760 and 3.8842, respectively. While for heavy naphtha samples, RMSEC and RMSEP were 1.3815 and 4.6884, respectively. Finally, results obtained using multiple polynomial regression were not successful, and its error of prediction is higher than the error of prediction obtained with PLS regression, probably because assumed hypothesis about the nonlinear relation between NB and FT-NIR signals is unacceptable. The validation results using PLS indicate that there are high consistencies between the FT-NIR prediction and those measured by the reference standard method (ASTM D1159). The proposed method is much faster than the reference method. This allows the determination of BN from a single spectrum, with the feasibility of further application for online monitoring.

