











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
Para clasificar el riesgo en pacientes con dolor torácico, las guías ACC/AHA recomiendan realizar una anamnesis enfocada que incluya las características y duración de los síntomas relacionados con la presentación, junto con los factores asociados, y una valoración de los factores de riesgo cardiovascular1. Las vías clínicas de decisión son un conjunto de protocolos que se utilizan para definir el riesgo de pacientes que consultan con dolor torácico. Estas vías están diseñadas para ayudar a los profesionales de la salud a tomar decisiones informadas para la atención del paciente a partir de protocolos diagnósticos basados en la evidencia. Algunos ejemplos incluyen el HEART Pathway2, EDACS3, mADAPT4, NOTR5, 2020 ESC/hs-cTn6, y 2016 ESC/GRACE7. La guía enfatiza la importancia de utilizar una vía validada para identificar pacientes con bajo riesgo que pueden ser dados de alta de manera segura de la sala de urgencias sin exámenes adicionales; los profesionales de la salud deben utilizar su juicio clínico y seguir las guías establecidas para determinar la vía más apropiada para cada paciente1.
El procesamiento de lenguaje natural (PLN) es un área de informática y la inteligencia artificial que se enfoca en la interacción entre los computadores y los humanos usando lenguaje natural. Los transformadores son una arquitectura de red basada exclusivamente en mecanismos de atención, totalmente prescindiendo de las iteraciones y convoluciones8. Esta área implica el desarrollo de algoritmos y modelos que les permitan a los computadores entender, interpretar y generar lenguaje humano. Depende enteramente de un mecanismo de atención para trazar dependencias globales entre input y output, permitiendo un aumento importante en la paralelización y alcanzando resultados de avanzada en tareas de traducción automática.
ChatGPT fue lanzado el 30 de noviembre del 2022, basado en Generative Pre-trained Transformer 3 (GPT-3), un modelo de lenguaje autoregresivo que utiliza aprendizaje profundo para producir textos que simulan la redacción humana9; fue creado por OpenAI, un laboratorio de investigación de inteligencia artificial con sede en San Francisco. El entusiasmo que produjo su lanzamiento se transfirió rápidamente a la medicina, resaltando que, para enero del 2023, ya cuatro trabajos lo incluían como co-autor10-13, lo que suscitó un debate intenso14 que llevó a la retracción de dos de los documentos bajo el argumento de que ChatGPT no calificaba como autor según las guías de autor de la revista y las políticas editoriales de ética en la publicación15,16.
Con este artículo se busca investigar el potencial de ChatGPT para el procesamiento de lenguaje natural al seleccionar artículos dentro de una revisión sistemática y utilizar ChatGPT para asistir en la redacción de un trabajo. El artículo presentará una perspectiva general de la metodología empleada, incluyendo detalles de cómo se integró ChatGPT en el proceso de redacción, y tratará las implicaciones o direcciones futuras para la investigación en esta área.
Método
En el trabajo original17, nuestro grupo realizó una revisión sistemática de la literatura para evaluar la precisión diagnóstica de la prueba de troponina para el alta temprana de pacientes con sospecha de síndrome coronario agudo. Para ser elegibles para inclusión en esta revisión, los estudios tenían que ser ensayos controlados aleatorios que evaluaran el diagnóstico de dolor torácico en la sala de urgencias utilizando protocolos basados en la troponina de alta sensibilidad y midieran el alta temprana (antes de 4 a 6 horas) como resultado; a su vez, los criterios de exclusión incluían estudios que no tuvieran el alta temprana como su objetivo, estudios que evaluaran la troponina en combinación con otros biomarcadores, estudios que evaluaran la troponina en un único momento, y estudios que solo fueran publicados en forma de póster o resumen.
Para la identificación de los estudios relevantes, los autores realizaron una búsqueda de la literatura el 17 de mayo de 2021, utilizando tres bases de datos: MEDLINE, Cochrane, y Embase. Utilizaron términos de búsqueda como dolor torácico, síndrome coronario agudo, protocolos de diagnóstico acelerado, troponina de alta sensibilidad, departamento de urgencias, estratificación de riesgo, y descarte y confirmación rápida.
Se le solicitó al ChatGPT que revisara los títulos identificados en la búsqueda inicial para seleccionar los que cumplieran con los criterios de inclusión. Luego, se extrajeron los resúmenes de los trabajos seleccionados por medio de una reevaluación de los criterios de inclusión y consideración de los elementos para exclusión. Finalmente, ChatGPT revisó los artículos a texto completo de la selección anterior para determinar cuáles artículos se incluirían en la revisión sistemática. Los resultados obtenidos fueron luego comparados con los de la búsqueda original, evaluando si se habían identificado nuevos estudios que no habían sido seleccionados anteriormente o si hubo errores luego de descartar cualquier de los cinco trabajos que fueron incluidos.
Los investigadores utilizaron la plataforma chatpdf.com18 para generar las diferentes secciones del documento en inglés con vigilancia rigurosa previo al lanzamiento de GPT-4 el 14 de marzo de 2023. El proceso implicó cargar los documentos de referencia seleccionados y solicitar un resumen, seguido por la creación de componentes clave para la presentación o discusión, informados por el material de referencia. En algunas ocasiones se solicitaron varias opciones de redacción para una oración o un párrafo, basadas en diferentes conceptos. Finalmente, se procesó el texto completo para derivar conclusiones, y se analizó cada sección del documento para producir un resumen estructurado. Los investigadores o bien escogieron de las opciones proporcionadas o solicitaron nuevas versiones basadas en selecciones prometedoras. Además, en varias oportunidades introdujeron sus propias ideas o modificaciones. Se siguieron los parámetros predeterminados de la plataforma sin modificaciones respecto a la temperatura o sanciones.
La revisión sistemática original fue aprobada por el comité de ética e investigación de la Fundación Universitaria de Ciencias de la Salud y se encuentra registrada en PROSPERO bajo el código CRD42021255495.
Resultados
El tamizaje inicial identificó 3509 estudios, de los cuales cinco cumplieron con los criterios de inclusión en la investigación original19-23. La revisión por título realizado por ChatGTP identificó 25 artículos relacionados con el diagnóstico de dolor torácico y los protocolos de diagnóstico para síndromes coronarios agudos o infarto de miocardio utilizando la troponina. Luego de una revisión de los resúmenes, se descartaron otros 14 estudios, dejando 11 para revisión de texto completo. De estos, ChatGPT finalmente eligió seis. La evaluación por los investigadores indicó que el HEART Pathway Randomized Trial a un año24 y una evaluación de adherencia del mismo trabajo25 fueron excluidos por considerarse duplicados. Otro artículo también se excluyó porque era una presentación en un congreso26.
Finalmente, se seleccionaron tres artículos para inclusión en la revisión sistemática: el ensayo aleatorio HEART Pathway20, una comparación del 2-Hour ADAPT vs. HEART Pathway21, y el RAPID-TnT23, los cuales también fueron identificados en la búsqueda original. El proceso de selección de estudios se muestra en el diagrama PRISMA (Fig. 1).
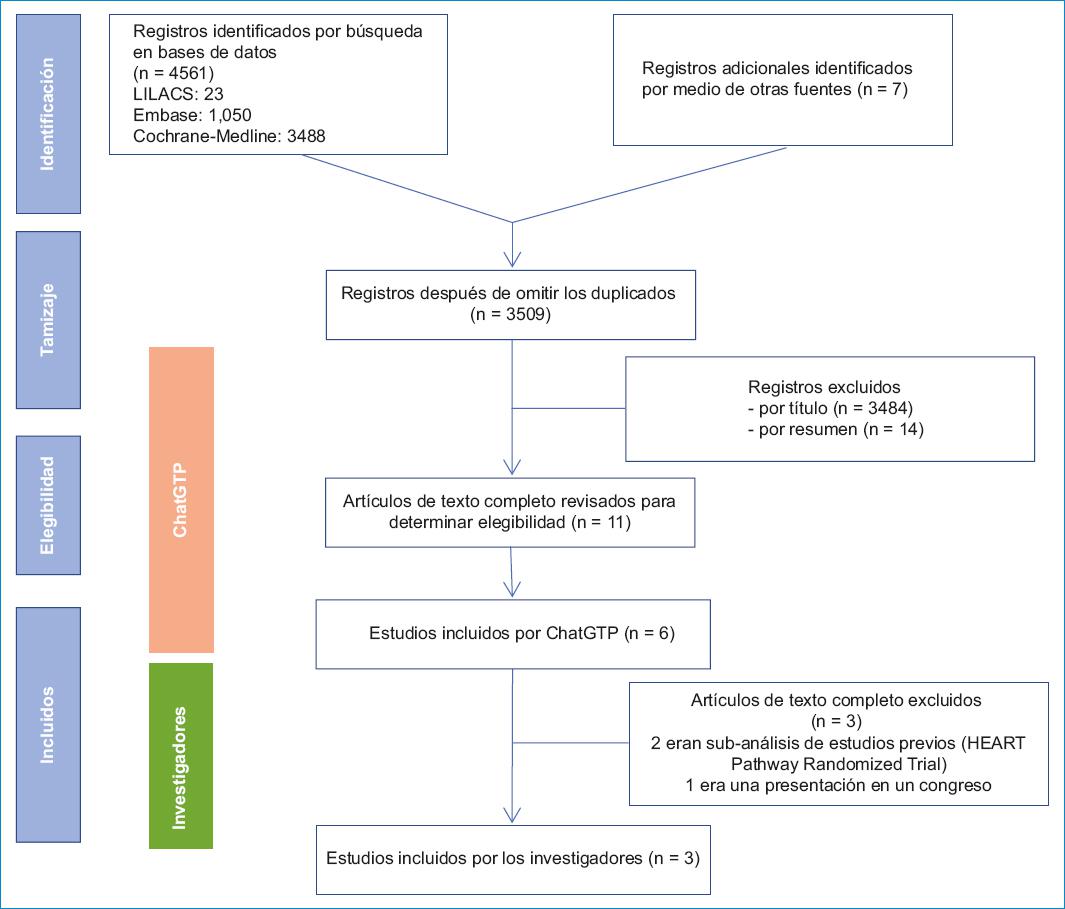
La tabla 1 muestra un resumen de la metodología utilizada en los tres estudios incluidos y los dos estudios que no fueron identificados. La tabla 2 resume los resultados principales obtenidos en los diferentes estudios, resaltando que, entre los 4130 pacientes incluidos en los tres ensayos clínicos, 2985 (72.3%) tuvieron un alta temprana, con las tasas más altas observadas en los grupos de 0/3 h ESC (91.0%) y 0/1 h ESC (72.0%), seguidos por los grupos de EDACS (41.6%), HEART (39.7%), y ADAPT (30.5%), y las tasas más bajas en los grupos de tratamiento convencional (18.4%).
Tabla 1 Características de los estudios incluidos
| Estudio | Vías clínicas de decisión | Tipo de estudio | Número de pacientes | Troponina utilizada | Desenlace primario |
|---|---|---|---|---|---|
| Estudios identificados por GTP | |||||
| Mahler, 201520 | HEART | Unicéntrico | 282 | ADVIA Centaur platform TnI-Ultra assay (Siemens) | Pruebas cardíacas objetivas (pruebas de estrés o angiografía) a 30 días |
| Cuidados habituales | |||||
| Than, 201621 | EDACS | Pragmático unicéntrico | 560 | Abbott Architect troponina I de alta sensibilidad (hs-cTnI) | Alta exitosa (6 horas) |
| ADAPT | |||||
| Chew, 201923 | Protocolo de 0/1-horas | Multicéntrico de no inferioridad | 3,288 | hs-cTnT; Roche Diagnostics Elecsys 5a generación | MACE a 30 días |
| Protocolo ESC de 0/3-horas | |||||
| Estudios no identificados por GTP | |||||
| Than, 201419 | ADAPT | Unicéntrico | 544 | Abbott Architect troponina I de alta sensibilidad (hs-cTnI) | Alta exitosa (6 horas) |
| Cuidados habituales | |||||
| Body, 201722 | MACS | Unicéntrico | 60 | hs-cTnT; Roche Diagnostics Elecsys | Alta exitosa (4 horas) |
| Usual care | |||||
ADAPT: protocolo acelerado para evaluar el dolor torácico por medio de troponinas [accelerated diagnostic protocol to assess chest pain using troponins]; HEART: anamnesis, ECG, edad, factores de riesgo, troponina [history, ECG, age, risk factors, troponin]; EDACS: puntaje de evaluación de dolor torácico en el departamento de urgencias [Emergency Department Assessment of Chest Pain Score]; MACS: escala de síndromes agudos coronarios de Manchester [Manchester Acute Coronary Syndromes Scale]; MACE: eventos cardiovasculares mayores [major cardiovascular events].
Tabla 2 Efectividad de los protocolos aplicados
| Estudio | Vías clínicas de decisión | Alta temprana | MACE a 30 días | Sensibilidad (%) | VPN (%) | Tiempo de estancia |
|---|---|---|---|---|---|---|
| Estudios identificados por GTP | ||||||
| Mahler, 201520 | HEART | 56 (39.7%) | 0 | 9.3 | 100.0 | 9.9 horas |
| Cuidados habituales | 26 (18.4%) | 0 | 8.2 | 100.0 | 21.9 horas | |
| Than, 201621 | EDACS | 133 (41.6%) | 0 | 22.1 | 99.1 | 6 horas |
| ADAPT | 90 (30.5%) | 0 | 14.9 | 100.0 | 6 horas | |
| Chew, 201923 | Protocolo 0/1 horas | Efectivo: 748 (45%) Esperado: 1,187 (72%) |
17 (1.0%) | 88.1* | 99.6** | 4.6 horas |
| Protocolo ESC 0/3 horas | Efectivo: 545 (33%) Esperado: 1,493 (91%) |
16 (1.0%) | NA | 99.4** | 5.6 horas | |
| Estudios no identificados por GTP | ||||||
| Than, 201419 | ADAPT | 52 (19.3%) | 1 | 97.9 | 98.1 | 6 horas |
| Cuidados habituales | 30 (11.0%) | 0 | 100.0 | 100.0 | 20 horas | |
| Body, 201722 | MACS | 17 (26%) | 3 | 100.0 | 100.0 | 1 día |
| Cuidados habituales | 5 (8%) | 3 | 100.0 | 100.0 | 1 día | |
*Para confirmar.
**Para descartar.
ADAPT: protocolo acelerado para evaluar el dolor torácico por medio de troponinas [accelerated diagnostic protocol to assess chest pain using troponins]; HEART: anamnesis, ECG, edad, factores de riesgo, troponina [history, ECG, age, risk factors, troponin]; EDACS: puntaje de evaluación de dolor torácico en el departamento de urgencias [Emergency Department Assessment of Chest Pain Score]; MACS: escala de síndromes agudos coronarios de Manchester [Manchester Acute Coronary Syndromes Scale]; MACE: eventos cardiovasculares mayores [major cardiovascular events].
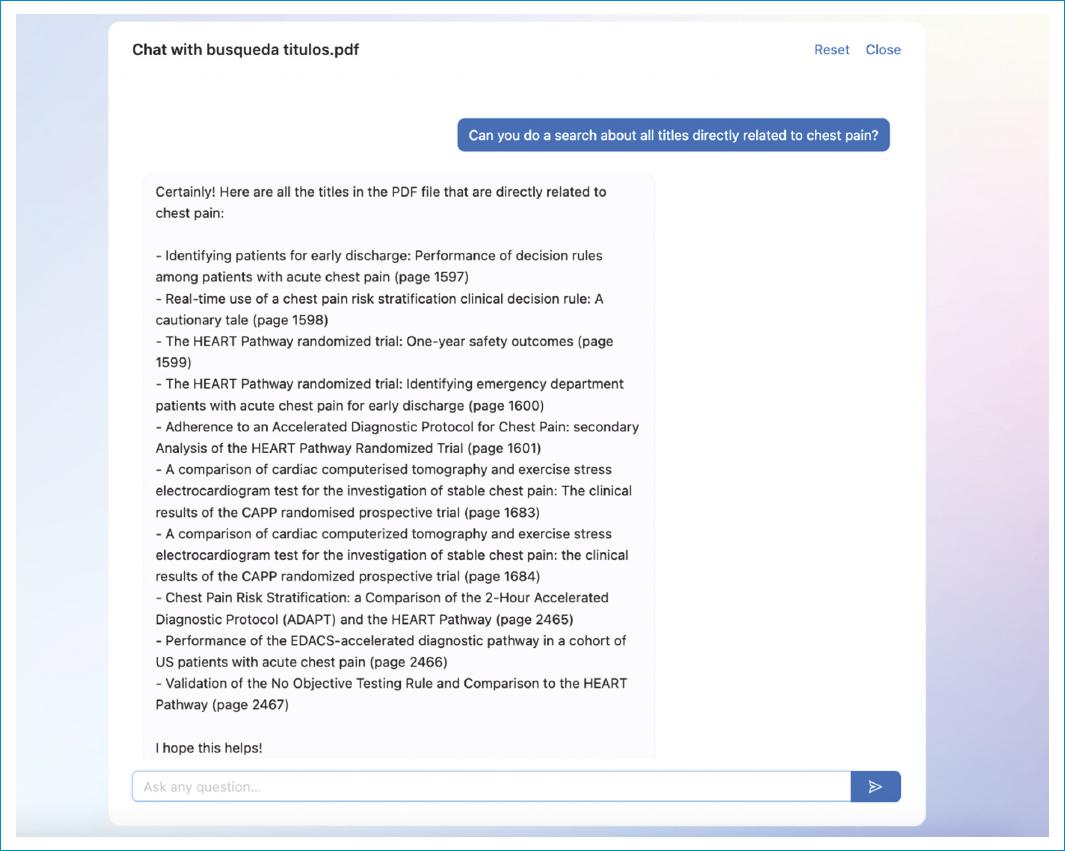
El material suplementario incluye varias sesiones realizadas con ChatGPT, las cuales recopilaron las respuestas obtenidas en el proceso de revisión desde los títulos hasta el texto completo, como también en el proceso de redacción del artículo. La figura 2 muestra un ejemplo de una de estas sesiones.
Discusión
En este estudio se presentan los resultados del uso de una herramienta de PLN basado en GPT en el proceso de selección de artículos para una revisión sistemática. En su etapa actual de desarrollo, consideramos que ChatGPT es insuficiente por sí solo para identificar artículos en una revisión sistemática. Sin embargo, reconocemos su potencial como un suplemento valioso para las estrategias existentes. Aunque es evidente que la identificación del estudio por Body y colaboradores22 basado únicamente en el título (Factibilidad de la regla de decisión del Manchester Acute Coronary Syndromes para reducir de manera segura los ingresos hospitalarios: un ensayo controlado aleatorio piloto) es difícil, este no es el caso para el estudio de Than et al.19 (Un protocolo diagnóstico de dos horas para posible dolor torácico en el departamento de urgencias: un ensayo controlado aleatorio). No se encontraron trabajos parecidos en nuestra búsqueda de la literatura.
El ChatGPT ha sido sugerido como una posible herramienta en varios escenarios clínicos y de investigación, incluyendo apoyar la práctica clínica, facilitar la producción científica, identificar el posible mal uso en la medicina y la investigación y ayudar en la consideración de los temas de salud pública27. En cuanto a la redacción científica, ChatGPT puede ayudar a los investigadores y los científicos a organizar el material, generar un borrador, y hacer una revisión del texto. Al suministrar información bruta, ChatGPT puede también ayudar a redactar la sección de los métodos usados en el estudio, justificar el tamaño de la muestra, y describir las técnicas de análisis de datos. Al finalizar el manuscrito, es muy efectivo en el proceso de edición, donde es factible formatear y editar el lenguaje, redactar oraciones especialmente complejas de una manera más clara, y hasta resumir el texto completo para escribir un resumen apropiado28. En este artículo, se han podido verificar gran parte de estas funciones.
Cascella et al.27 evaluaron la capacidad de ChatGPT para entender y resumir información y sacar conclusiones basadas en el texto de las secciones de Introducción, Métodos y Resultados de un resumen; GPT pudo indicar correctamente el marco y resumir los resultados del desenlace primario de cada estudio. Sin embargo, tenía mayor probabilidad de resaltar hallazgos secundarios, a la vez que no se adhería estrictamente a los límites de longitud del texto en aras de presentar un mensaje relevante. Un experimento de Gao et al. puso a prueba la capacidad de ChatGPT de generar resúmenes basado en 50 títulos, los cuales fueron luego revisados por detectores de plagio, detectores de IA, y revisores humanos cegados. Los resultados indicaron que, aunque algunos resúmenes generados por ChatGPT fueron identificados correctamente como tales, los revisores humanos tuvieron dificultad en distinguir entre resúmenes escritos por humanos y los generados por ChatGPT29.
Como se indica en trabajos recientes30,31, la versión actual de ChatGPT tiene el potencial de generar información falsa, lo que se conoce en la inteligencia artificial (IA) como una alucinación o una alucinación artificial (una respuesta generada por IA que parece segura pero carece de justificación por sus datos de entrenamiento32); por lo tanto, es indispensable que los autores humanos examinen minuciosamente y validen cualquier información generada por ChatGPT antes de incorporarla en sus artículos. El uso de ChatGPT en la literatura científica plantea inquietudes acerca de la precisión y la integridad de los datos que genera; por lo tanto, la política y la práctica para la evaluación de los manuscritos científicos se debe modificar para mantener estándares científicos rigurosos31.
El uso de chatbots de IA como ChatGPT para la redacción científica plantea algunas inquietudes éticas y por lo tanto debe ser regulada. El increíble desarrollo de herramientas de IA puede llevar a un aumento significativo en el número de publicaciones de los investigadores, sin ser acompañado de un aumento real en su experiencia en ese campo. Por lo tanto, se pueden generar problemas éticos con respecto a la contratación de profesionales por parte de instituciones académicas que los califican de acuerdo al número de publicaciones en lugar de su calidad. Es importante resaltar que mientras ChatGPT puede apoyar en la redacción científica, no se debería utilizar como un reemplazo del juicio humano, y el producto siempre debe ser revisado por expertos antes de usarse28. Además, cualquier asistencia provista por la IA debe ser divulgada dentro del artículo30. Por otra parte, es fundamental reconocer que ChatGPT y otras herramientas de IA parecidas aún no son un reemplazo adecuado para los métodos tradicionales de búsqueda de la literatura fundamentados en guías metodológicas robustas y bases de datos establecidos. Estas herramientas de IA carecen de especificidad en la validación de la significancia estadística y calidad general de la información, por lo que son insuficientes como recursos independientes para la investigación académica.
Los hallazgos de un estudio reciente33 indican que la introducción de los GPT podría afectar aproximadamente el 80% de la fuerza laboral de los Estados Unidos, impactando por lo menos un 10% de sus tareas laborales. Además, cerca de un 19% de los trabajadores podría ver impactado al menos un 50% de sus tareas. Existe una preocupación por el posible mal uso de GPT en la medicina y la investigación, como por ejemplo inventar datos de investigación o resultados para cumplir con los requisitos de financiación o publicación, utilizar el modelo para generar diagnósticos o recomendaciones de tratamiento sin la validación o supervisión adecuada, y generar noticias falsas o desinformación28. Los investigadores en salud tienen la responsabilidad de establecer guías para el uso correcto de nuevas tecnologías como ChatGPT, mientras exploran sus beneficios, limitaciones y riesgos. A medida que surgen avances en este campo, es indispensable realizar adaptaciones rápidas para maximizar su potencial.
En conclusión, la integración de ChatGPT en el procesamiento de lenguaje natural es prometedora en el apoyo a la redacción de trabajos científicos, aunque el texto generado se debe evaluar críticamente para asegurar su precisión y validez. A pesar de la incertidumbre alrededor de su efectividad actual, nuestro estudio demostró que ChatGPT se puede utilizar para el tamizaje de artículos para una revisión sistemática; se requerirá de más evaluación a medida que avance la tecnología o se adapten los sistemas GPT para fines médicos. Además, se recomienda el uso de las vías clínicas de decisión para identificar correctamente el riesgo en pacientes con dolor torácico y guiar a los profesionales de la salud en la toma de decisiones informadas acerca del cuidado de los pacientes a partir de protocolos de diagnóstico basados en la evidencia.

