











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
En estos tiempos de transformación digital, industria 4.0, automatización, procesamiento de datos e introducción de diversas soluciones tecnológicas para soportar la toma de decisiones, tecnologías como internet de las cosas (internet of things (IoT)) y la analítica de datos se presentan como alternativas de gran valor para impactar de forma positiva en el modelo de negocio de las organizaciones de diferentes sectores productivos, entre ellos el agro. La recolección y adquisición de datos que registren el comportamiento de lo que sucede en los procesos es determinante; por tanto, elegir soluciones e implementaciones de IoT es una opción acorde a esta necesidad. En la agricultura, las soluciones IoT se han convertido en herramientas ideales para la adquisición de datos sobre cultivos, aplicación de fungicidas y abonos, entre otros. Esta necesidad lleva a la instalación de sensores para la recolección permanente de datos, en combinación con mediciones muy variadas, y con valores en distintas magnitudes y formatos. Por ello, al contar con un elevado volumen de datos, se requieren de tecnologías que preparen y procesen estos datos de forma adecuada, para así obtener información que aporte valor y soporte a la toma de decisiones.
Las acciones para procesos como el tratamiento del suelo y el cultivo para la producción de alimentos tienen una importancia en diferentes regiones del mundo, ya que favorecen la economía, aunque también suponen una transformación del medio ambiente natural. Las implementaciones de soluciones IoT pueden brindar apoyo para alcanzar un mejor rendimiento del suelo y minimizar el detrimento del medioambiente.
Los avances en cuanto a sensorización y al uso de las nuevas tecnologías en la agricultura, enfocados en mejorar la producción, su calidad y cantidad, y la reducción de costos de la agricultura y del impacto ambiental, han abierto el camino al concepto de agricultura inteligente. Aquí, el agricultor puede obtener en tiempo real métricas, estadísticas e informes confiables -a partir del procesamiento automático de estos- que le permiten tomar decisiones acertadas.
El escenario ideal es que el agricultor disponga de un tablero informativo (dashboard) con la cantidad adecuada de información; estos datos serán indispensables para tomar decisiones acertadas con base en su propia experiencia, y las cuales posiblemente un algoritmo no esté en capacidad de sugerir, o tal vez el mismo agricultor no desea automatizarlas, ya que influyen en la estrategia de su negocio. En este contexto, un agricultor debe visualizar información reducida, pero crucial y determinante. Para que sea reducida, en general, debe disponerse de grandes volúmenes de datos, que luego deben reducirse con técnicas de analítica de datos, para extraer información crucial. La necesidad principal de un agricultor es conseguir la mayor cantidad posible de su producto con la máxima calidad.
Para un caficultor, contar con información precisa sobre las condiciones del cultivo resulta fundamental para evaluar posibles cambios en escenarios hipotéticos y tomar decisiones estratégicas en cada fase del proceso, con el fin de maximizar la producción y la calidad del grano. En este artículo se propone el diseño de una red experimental basada en IoT que recolecte datos sobre las variables agroambientales de un cultivo de café en la finca Las Acacias, del municipio de Salento (Quindío), para finalmente presentar y reflexionar sobre el valor que agregaría un modelo de inteligencia artificial orientado a apoyar al caficultor, optimizar recursos y mejorar los resultados productivos.
A continuación se detallan los objetivos específicos de investigación:
Analizar los patrones de comportamiento de las variables agroambientales registradas mediante sensores IoT, para así determinar su relación con las condiciones del cultivo y su impacto en la toma de decisiones agrícolas.
Organizar y estructurar los datos recopilados por la red experimental IoT, para así transformarlos en información útil y estandarizada, lo cual facilitará su análisis y aplicación en el manejo del cultivo de café.
Diseñar y evaluar modelos de aprendizaje automático que generen predicciones precisas a partir de los datos agroambientales, desde las cuales se proporcionen herramientas de apoyo y gestión eficiente del cultivo, además de la mejora de la producción.
Trabajos relacionados
La búsqueda bibliográfica arrojó información sobre agricultura inteligente y la manera como es potenciada por las soluciones IoT (Espinoza García et al., 2019). Respecto al cultivo de café, se encuentran estudios como el de Parada Molina et al. (2020), quienes analizan cómo las variaciones del clima pueden afectar al cultivo del café en el periodo de floración y durante el inicio del crecimiento del fruto. Todos estos datos se encargan de proporcionar modelos de predicciones que ayudarían a tomar acciones correctivas ante cierto tipo de situaciones. También existen alternativas de bajo costo para la recolección de datos mediante IoT (Ossa Duque 2017) para situaciones en las cuales no se cuenta con altos presupuestos. Hay trabajos donde se exploran distintas arquitecturas como los de Kalyani y Collier (2021); Montoya Muñoz et al. (2022); Rodríguez et al. (2021); y los que estudian esta tendencia en utilizar dichas tecnologías (Sinha y Dhanalakshmi, 2022).
Una vez que los dispositivos y sensores para la adquisición de datos se encuentren configurados, instalados y en funcionamiento, es necesario procesar la información para construir un sistema que acompañe al caficultor en el proceso de toma de decisiones agronómicas fundamentadas. En primera instancia, se requiere confianza en los datos, a pesar de que los dispositivos y sensores pueden tener complicaciones en su funcionamiento, o de que en eventualmente entreguen datos erróneos provocados por fallas en ellos mismos. En Montoya Muñoz y Caicedo Rendón (2020) se detalla un algoritmo que aísla valores atípicos (outliders) en los datos adquiridos por los sensores y así lograr una mayor confiabilidad.
Cuando se busca desarrollar un modelo de predicciones, se debe disponer de gran cantidad de datos a adquirir durante todas las fases del cultivo, como también aquellos después de la cosecha, incluyendo los observados y medidos cuando el producto (granos de café) ya está disponible para su comercialización. Es decir, cuando el caficultor ya tiene los granos de café, los analiza y clasifica según la calidad obtenida. Todos estos datos son necesarios para generar un modelo de predicción. En este punto, se debe determinar qué parámetros medir durante el proceso, cuáles deben conocerse acerca del suelo, qué mediciones efectuar para conocer el clima, entre tantos otros que deben ser obtenidos sin sobredimensionar la cantidad de dispositivos y sensores utilizados. Varshitha y Choudhary (2022) proponen un modelo de aprendizaje automático (machine learning) que, mediante los datos recolectados, logran estimar la tasa de fertilidad del suelo y el rendimiento de sus cultivos. Faria et al. (2024) también utilizan modelos de aprendizaje automático para predecir el rendimiento en las plantaciones de café mediante atributos del suelo y de la planta. Los autores obtuvieron datos de un campo de 55 hectáreas durante dos temporadas consecutivas, por medio de diferentes tasas de fertilización.
Con un enfoque similar, Aworka et al. (2022) combinan datos climáticos para predecir el rendimiento del suelo para los cultivos. En este caso, cuando no existe inversión suficiente en tecnología para la adquisición de datos, es posible aprovechar la información meteorológica pública.
El trabajo de Bakthavatchalam et al. (2022) proporciona un enfoque para la agricultura de precisión mediante sistemas IoT y algoritmos de aprendizaje automático, con énfasis en la recomendación de cultivos. En el trabajo se utilizan sensores para medir parámetros como nitrógeno, fósforo, potasio, pH, temperatura, humedad y precipitaciones; además, almacenan los datos en la nube, donde un modelo de aprendizaje supervisado predice cultivos con altos rendimientos. Los autores proporcionan las bases para la selección de una red perceptrón multicapa (multilayer perceptron (MLP)) como algoritmo principal para la predicción agrícola, gracias a su capacidad para manejar múltiples variables de entrada y generar resultados en sistemas no lineales. El modelo MLP demostró más precisión y consistencia en la clasificación, comparado con otros algoritmos, como JRip y decision table, debido a su capacidad para modelar relaciones no lineales entre variables, como los niveles de nutrientes, el pH y las condiciones climáticas, que son esenciales en la agricultura de precisión.
También existen propuestas como la de Nguyen et al. (2023), quienes ofrecen una plataforma diseñada sobre la base de las tecnologías clave de la agricultura inteligente: IoT, big data, inteligencia artificial, blockchain y tecnologías de trazabilidad. La plataforma se denomina INNSA (Innovative & Smart Agriculture) y está desarrollada para integrar tecnologías, promover y mejorar los sistemas de gestión de calidad, la trazabilidad y la gestión eficaz y sostenible de la cadena de suministro y de valor del café en Vietnam.
Metodología
Con el fin de reflexionar a partir de información recolectada de primera mano, se visitaron dos fincas para conocer un día típico laboral y entrevistar a expertos caficultores. Luego, se buscó definir una propuesta con el objetivo de que los caficultores pudieran disponer de información para tomar decisiones basadas en los datos recolectados de su finca. Las etapas del trabajo de campo fueron las siguientes:
Visitas a fincas y entrevistas: fincas Las Acacias y La Morelia.
Síntesis de la información: identificación de parámetros útiles para un caficultor.
Definición de una propuesta digital: el caficultor digital.
Definición de una red IoT y sensores: para finca Las Acacias.
Entrevistas y organización de la información
El sector cafetero en Colombia ha sido uno de los renglones principales y tradicionales que han contribuido de manera significativa a la economía y desarrollo social en la zona rural, la cual en su estructura social se compone de pequeños productores. En el caso del departamento de Quindío, de acuerdo con el Comité de Cafeteros del Quindío, en su informe de gestión de 2023, el área cafetera está compuesta por 5662 fincas que cubren 18 051 ha de cultivo de café.
En esta región, se adelantaron entrevistas informales en el municipio de Salento, que forma parte del Paisaje Cultural Cafetero (PCC), donde se desarrolla caficultura de montaña y que fue declarado Patrimonio de la Humanidad por la Unesco. Estas entrevistas llevaron a comprender la realidad de la producción del café en la región, y a sentar las bases de la propuesta de este artículo que, de manera anticipada, se mencionó: “caficultor digital”. Este es un concepto que se propone en este trabajo, y está relacionado con la inteligencia y la experiencia de un caficultor humano experto en el cultivo del café, modelado y adaptado para funcionar a través de estrategias de aprendizaje automático. Su objetivo es brindar soporte a quienes tienen a cargo los procesos del cultivo, ofrecer orientación práctica y generar predicciones útiles que faciliten la implementación de acciones efectivas para gestionar la cosecha y lograr una producción adecuada.
Entrevistas
En mayo de 2023 se realizaron entrevistas a caficultores expertos en dos fincas de la región: Las Acacias y La Morelia, ubicadas en el departamento del Quindío. La primera se encuentra en el municipio de Salento, donde la temperatura promedio es de 18 °C y cuenta con una población aproximada de 3000 habitantes en el casco urbano, y 5500 en la zona rural. Tiene un sistema productivo de café, ganadería, especies menores (conejos y gallinas), elaboración de compostaje y de explotación del turismo cafetero en sus instalaciones (figura 1). El café de la finca se comercializa directamente a los turistas que la visitan y hacen un recorrido denominado “ruta de café”, el cual consiste en una explicación detallada de la producción agrícola cafetera y del procesamiento y secado de café, todo esto llevado hasta la taza de café que el visitante se toma al finalizar el recorrido. El productor también vende el café por libras a diferentes almacenes y cafeterías en Colombia.

Descripción general de Las Acacias
La finca posee 20 000 árboles productivos, distribuidos en 4,5 ha, con una distancia de siembra de 1,20 metros entre árboles y 2,0 m entre calles. El 90 % de su área tiene una topografía montañosa. Las variedades sembradas son: Castillo® y Cenicafé. Los árboles de café empiezan a producir tres años después de sembrados, a diferencia del café cultivado a menos altura que empieza a arrojar cosechas después de dos años. El caficultor en esta finca no lleva un registro de las condiciones climáticas, aunque conoce muy bien los efectos que causan los cambios de temperatura -altas en el día a muy bajas por las noches-, lo cual genera quemaduras en las hojas (figura 2). Cuando el árbol sufre estas quemaduras, puede retrasar el rebrote dos meses, y afectar directamente la producción. El cambio de las condiciones climáticas también favorece el desarrollo de enfermedades y plagas, como la broca y la roya, lo cual redunda en una disminución en la producción y en calidad del grano.

En su trabajo, Kumari et al. (2024) estudian las variedades de enfermedades en las hojas del café, sus rasgos y características, así como la prevención; entre ellas se incluyen el óxido de las hojas, las manchas, la podredumbre y enfermedades de las raíces. Los autores también proponen un modelo para la detección temprana de estas enfermedades, con el objetivo de mejorar la productividad. Por su parte, Hitimana et al. (2024) tienen en cuenta las enfermedades foliares que pueden reducir el rendimiento y afectar la calidad de los granos. Los autores introducen una aplicación móvil para detectar estas enfermedades, la cual integra técnicas de visión artificial que habilita a los usuarios capturar imágenes de alta resolución de las hojas de café directamente en el campo y ser procesadas para una identificación de enfermedades. En su artículo, De Carvalho Alves et al. (2022) utilizan algoritmos de aprendizaje automático para determinar el rendimiento del café, a partir de los cuales se obtienen umbrales de nutrientes para lograr un alto rendimiento, con el aumento en el vigor en el manejo de fertilizantes.
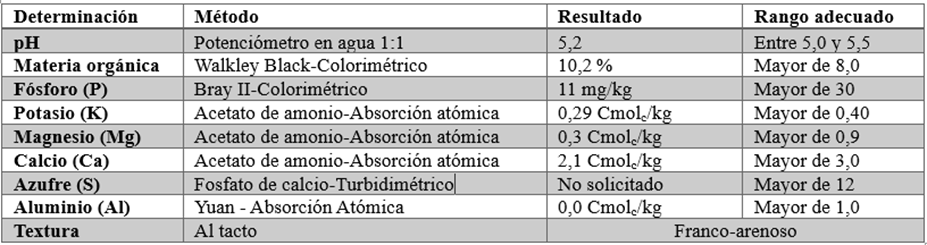
La época de mayor cosecha se presenta entre abril y junio. En esta finca hacen zoca (renovación del tronco del árbol del café) cada ocho años. Es importante para un caficultor conocer la fertilidad del suelo, y para ello es necesario realizar los estudios pertinentes para mantener niveles adecuados de nutrientes para una óptima producción, incrementar la resistencia de las plantas a plagas y enfermedades, y mejorar la calidad de las cosechas. La fertilidad del suelo depende de varios factores como el agua, micro- y macronutrientes, materia orgánica, pH y clase textural, que aportan diferentes beneficios a los cultivos. La producción y calidad de los cultivos se ven afectadas por prácticas de fertilización inadecuadas, que carecen de una base de información específica, como el análisis de suelos. Este análisis proporciona detalles sobre las características físicas y químicas del suelo, y es crucial para determinar los métodos de fertilización más adecuados. En Las Acacias se adelantan estudios del suelo cada uno o dos años, y una muestra se visualiza en la tabla 1.
Considerando un escenario en donde el uso de tecnología y la digitalización es muy escasa, y las posibilidades de realizar una inversión importante son pocas, se tuvo que orientar la propuesta para que se pudieran utilizar datos meteorológicos públicos, datos compartidos entre caficultores vecinos, información divulgada y proporcionada por la Federación Nacional de Cafeteros, información de los estudios del suelo y datos adquiridos por sensores de bajo costo que oportunamente se instalaron en la finca.
Vale la pena resaltar que este es un artículo de reflexión y se desea conducir el trabajo hacia la creación del “caficultor digital”, el cual tiene relación directa con el caficultor humano. No está de más profundizar en este concepto: el caficultor humano es el caficultor experto, que está representado por las personas que fueron entrevistadas en las fincas. Toda la información obtenida es la base de conocimiento para identificar las variables que el caficultor experto tiene en cuenta para tomar sus decisiones. Por otro lado, el “caficultor digital” deberá utilizar, al menos, las mismas variables, solamente que tendrá la posibilidad de estar procesando información incansablemente y podrá disponer de ella constantemente, gracias a los sensores instalados.
Luego de las entrevistas, se determina que las variables que el caficultor utiliza son temperatura y humedad ambiental; precipitaciones, y humedad del suelo. A partir de estas, se definen los siguientes dispositivos para conformar la red inalámbrica de sensores:
Propuesta: caficultor digital
En esta sección se describe la creación de un modelo de inteligencia artificial que replique la inteligencia del caficultor humano. Con este modelo es posible anticiparse a los sucesos y ejecutar las acciones de prevención y precaución para que ciertos eventos no deseados influyan negativamente sobre la producción del café, o minimizar su impacto. A partir de las entrevistas con el caficultor dueño de Las Acacias, sus colaboradores y trabajadores, se obtuvo información a partir de la cual ellos se basan para tomar sus decisiones, cuáles son sus métodos de medición, de qué manera corrigen anomalías, cómo hacen sus estimaciones, y, finalmente, cómo seleccionan y clasifican sus granos de café. En otras palabras, se obtuvo información que permitiera sintetizar la experiencia del caficultor para llevar adelante la producción de café. Ahora bien, se desea parametrizar la inteligencia del caficultor a través de un modelo de inteligencia artificial que emule, imite o reproduzca el comportamiento del caficultor humano.
Se pensó en que un caficultor experto tiene la información más valiosa y nadie mejor que él puede llevar adelante los procesos de cultivo en la finca. Las decisiones que él puede tomar son las más adecuadas y oportunas, con la limitación de que no dispone de grandes volúmenes de datos. Es decir, un caficultor que no posee suficientes sensores de medición automáticos y concentradores de datos realiza un muy buen análisis de la información para tomar las acciones durante el cultivo. La inteligencia humana de ese caficultor es sumamente valiosa. En esta propuesta, se quiere replicar esa inteligencia en un modelo que pueda imitar las acciones, pero a partir de grandes volúmenes de datos.
A la hora de construir un modelo, es necesario disponer de conjunto de datos (dataset), el cual está compuesto por las variables de entrada y los resultados obtenidos. Todo esto pensando en una red neuronal artificial. La salida en nuestra propuesta es la acción que el caficultor debe realizar en los cultivos de café.
El modelo
El diseño de la arquitectura de red está inspirado en el trabajo presentado por Bakthavatchalam et al. (2022), que es parte del estado del arte, en el cual se utiliza un método de aprendizaje automático para la predicción de cultivos. En ese trabajo se utilizan los siguientes parámetros: nitrógeno (N), fósforo (F), potasio (P), pH, temperatura ambiente, humedad del suelo y precipitaciones. Allí también se exponen las mediciones en la unidad de medida masa por volumen, generalmente en miligramos por kilogramo de suelo (mg/kg) o partes por millón (ppm). Estas unidades representan la cantidad de cada elemento presente en una muestra específica de suelo.
Considerando la finca Las Acacias, la unidad de medida obtenida luego del análisis en laboratorio es Cmolc/kg (centimoles de carga por kilogramo), la cual expresa la capacidad de intercambio catiónico (CIC) del suelo, que es una propiedad fisicoquímica que describe la capacidad del suelo para retener y liberar cationes, que son iones cargados positivamente. La CIC se debe principalmente a la presencia de arcillas y materia orgánica en su composición, las cuales tienen superficies cargadas negativamente, denominadas sitios de intercambio catiónico, que pueden atraer y retener los cationes presentes en la solución del suelo. Cuando las plantas toman agua del suelo, los cationes presentes en los sitios de intercambio catiónico pueden ser liberados y absorbidos por las raíces de las plantas. La CIC es una medida de la fertilidad y de la capacidad de retención de nutrientes del suelo. Un suelo con una alta CIC puede retener una mayor cantidad de nutrientes, lo cual representa un beneficio para el crecimiento y desarrollo de las plantas, ya que disponen de un suministro constante de nutrientes. Por otro lado, un suelo con una baja CIC puede requerir una mayor frecuencia de fertilización para mantener niveles adecuados de nutrientes para las plantas. Como se observa en la tabla 1, se dispone de mediciones de: pH, materia orgánica, fósforo (P), potasio (K), magnesio (Mg) y calcio (Ca).
En Las Acacias, los datos aleatorios de fósforo, potasio, pH y humedad del suelo se generaron gracias a la utilización de rangos basados en estudios locales y en las condiciones agroecológicas del cultivo de café en suelos montañosos. El fósforo (5-15 mg/kg), esencial para el desarrollo radicular y la formación de flores, evidencia su disponibilidad limitada en suelos ácidos debido a la fijación con aluminio y hierro. El potasio (0,25-2,5 Cmolc/kg), vital para la osmorregulación, la resistencia al estrés hídrico y la calidad del grano, se basó en la capacidad de intercambio catiónico típica de los andisoles. El pH (5,0-5,5), que regula la disponibilidad de nutrientes como fósforo y calcio, corresponde a la acidez característica de suelos cafeteros. Para la humedad del suelo (60 %-90 % de capacidad de campo), se estimó la alta pluviosidad y retención hídrica del suelo durante épocas de lluvia. Estos elementos son cruciales para garantizar el crecimiento saludable de las plantas de café y optimizar su productividad. Los rangos, aplicados mediante distribuciones aleatorias ajustadas, simulan la variabilidad esperada en campo, lo cual facilita la creación de modelos predictivos realistas y útiles para el manejo del cultivo.
El modelo que se propone en este trabajo considera únicamente el pH, fósforo y potasio, con el objetivo de acercarse a lo propuesto por Bakthavatchalam et al. (2022), quienes utilizan mediciones de nitrógeno, fósforo, potasio y pH, además de la temperatura ambiente, humedad del suelo y precipitaciones. Basados en esta información, es posible elaborar el modelo de predicciones denominado “caficultor digital”.
De acuerdo con las entrevistas, el caficultor humano utiliza, principalmente, las mediciones de la temperatura ambiental, precipitaciones y la humedad del suelo, para tomar decisiones respecto a su cultivo. En segundo orden, recoge la información del estudio de suelo, pero para una planificación a mediano plazo. En este sentido, los parámetros de entrada al modelo de predicción propuesto en este trabajo son fósforo (F), potasio (P), pH, temperatura ambiente, humedad del suelo y precipitaciones.
Así, se dispone de un dataset de prueba construido con parámetros de entrada muy similares a los que se pretende utilizar para entrenar al caficultor digital. Este dataset está pensado para recomendar el tipo de cultivo que mejor rendiría en las condiciones definidas por los parámetros de entrada. El dataset se encuentra disponible en Atharva (2020).
Para entrenar un modelo de inteligencia artificial es necesario disponer de los datos de salida; es decir, aquellos datos que el modelo podrá predecir. Estos datos de salida en el modelo “caficultor digital” son las acciones que el caficultor humano debe tomar para alcanzar el rendimiento deseado del cultivo. Para el caficultor digital se determinan las siguientes acciones:
Aplicar agroquímicos. Se realiza debido a diversos factores, como las condiciones climáticas, el estado de las plantas y problemas específicos que se están tratando. Los agroquímicos, que incluyen pesticidas, herbicidas y fertilizantes químicos, se utilizan en el cultivo de café para controlar plagas, enfermedades y mejorar la salud de las plantas.
Acción método integral de prevención de enfermedades MIPE. Implica la implementación de múltiples prácticas y estrategias para prevenir la aparición y propagación de enfermedades en las plantas.
Poda de plantas de café. Es una práctica importante para mantener la salud y el rendimiento de los cafetales. Depende de múltiples factores y momentos, entre los cuales se pueden mencionar la variedad del café; las condiciones climáticas; algunas prácticas MIPE, en momentos de cosecha; eliminación de brotes débiles; poda intensa para para rejuvenecer la planta; eliminación de ramas viejas o dañadas; entre otros.
Ninguna acción por realizar. Puede deberse a que no es momento de trabajar con algún agroquímico, o realizar prácticas de prevención de enfermedades. Alguno de los motivos para no realizar acciones sobre la finca es la probabilidad de condiciones climáticas; por ejemplo, si se pronostican lluvias, no es recomendable aplicar agroquímicos, ya que podrían lavarse.
En el momento en que se presenta este artículo de reflexión, no se dispone de cantidades significativas de datos como para lograr un modelo robusto, ya que aún no se encuentra desplegada la red IoT ni los sensores. Sin embargo, de la recopilación de información de trabajos que forman el estado de arte y con la particularización en una región muy importante de Colombia respecto al cultivo del café, es oportuno avanzar en la definición del modelo de predicciones que, oportunamente, tendrá interesantes mejorías cuando las cantidades de datos adquiridas a través de las redes de sensores se incrementen cosecha tras cosecha.
El dataset para crear la primera versión del modelo son datos de la temperatura ambiental y precipitaciones obtenidos desde el sitio Weather Spark1 en mediciones del mes en el que se visitó la finca. Respecto a la humedad del suelo, esta se estimó con base en las precipitaciones, aunque la relación entre ambas variables puede ser compleja y depende de varios factores adicionales. La precipitación es una de las principales fuentes de humedad del suelo. Sin embargo, la cantidad de humedad que el suelo retiene depende de varios factores: tipo de suelo, textura, permeabilidad, cobertura vegetal, evapotranspiración y condiciones climáticas adicionales. Si bien la precipitación puede aumentar la humedad del suelo, también es posible que esta disminuya debido a la evaporación y la transpiración de las plantas (evapotranspiración) y otros procesos de pérdida de agua. Por tanto, la estimación precisa de la humedad del suelo en función de las precipitaciones requeriría tener en cuenta estos factores; además, es posible utilizar el modelo de balance hídrico, que considera las entradas y salidas de agua en el suelo a lo largo del tiempo y en diferentes momentos. El modelo de balance hídrico se basa en la siguiente ecuación general:
Balance de agua en el suelo = Precipitación + Agua de riego - Evapotranspiración - Escurrimiento − Drenaje ± Cambio en la humedad del suelo
Donde:
Precipitación: cantidad de agua que cae al suelo en forma de lluvia.
Agua de riego: cantidad de agua agregada al suelo mediante riego artificial.
Evapotranspiración: pérdida de agua del suelo debido a la combinación de la evaporación desde la superficie del suelo y la transpiración de las plantas.
Escurrimiento: cantidad de agua que fluye superficialmente sobre la superficie del suelo y no se infiltra.
Drenaje: cantidad de agua que se mueve a través del suelo y se elimina del perfil del suelo.
Cambio en la humedad del suelo: variación neta de la humedad del suelo durante el periodo de tiempo considerado.
Para calcular la evapotranspiración para un día se recurre al método de Penman-Monteith, el cual asume las temperaturas máxima y mínima del día, humedad relativa promedio, velocidad del viento promedio y radiación solar promedio. Con estos datos, y siguiendo una serie de pasos del método, se obtiene la evapotranspiración estimada para ese día específico. Se estima que la evapotranspiración se encuentra en el rango de 4 mm/día y 12 mm/día para el mes de la visita a la finca.
Con el objetivo de probar el modelo y disponer de un dataset con variantes en sus datos, aquí se propone generar aleatoriamente los datos de fósforo, potasio, pH y humedad del suelo. En cuanto a las precipitaciones y temperatura, se dispone de los datos reales durante los meses de mayo y junio, desde el sitio Weather Spark. Según los estudios del suelo en Las Acacias, en distintas oportunidades, se tienen los siguientes rangos en las variaciones de los parámetros:
Fósforo: el rango para los niveles de fósforo en el suelo en la zona de montaña en la finca Las Acacias puede variar entre 5 a 15 mg/kg.
Potasio: los niveles de potasio pueden variar entre 0,25 a 2,5 Cmolc/kg.
pH: los niveles de pH pueden oscilar entre 5 y 5,5.
Humedad del suelo: la humedad del suelo puede oscilar entre el 60 % y el 90 % de capacidad de campo en las épocas de lluvia, como en los meses de mayo y junio.
De esta manera queda completo un primer dataset de entrada, como muestra, para ese par de meses en el que se visitó la finca. Para completar el dataset con una salida etiquetada, se solicita al caficultor experto que indique con una salida o clase específica, según su experiencia. En la tabla 2 se pueden visualizar algunas líneas de un archivo CSV con las columnas del dataset.
Tabla 2 Dataset propio
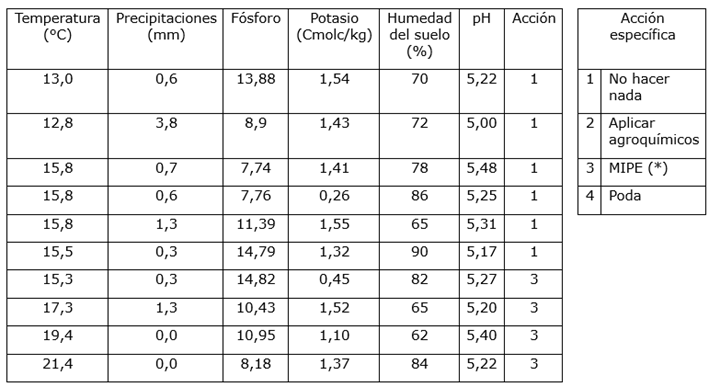
* MIPE: manejo integrado de plagas y enfermedades, estrategia agrícola que combina distintos métodos de control para reducir el daño de plagas y enfermedades en los cultivos
Con estos datos etiquetados con acciones, es posible entrenar el modelo. Luego, se podrán automatizar la toma de decisiones sobre las acciones oportunas para lograr el rendimiento deseado del cultivo.
En situaciones como estas, en donde se tiene una necesidad y se dispone de datos estructurados y etiquetados, se debe decidir sobre la técnica que se utilizará para confeccionar un modelo de predicción. Existe una limitación importante en este momento del proyecto y es la escasez de datos, que genera incertidumbre en cuanto a la precisión del modelo. Es importante establecer expectativas realistas y disponerse a mejorar el modelo a medida que se recopilen datos cuando se disponga de los sensores instalados.
Una red neuronal perceptrón multicapa (multilayer perceptron (MLP)) es una opción prometedora para problemas de predicción en este tipo de situaciones. Una MLP es una red neuronal artificial que consta de múltiples capas de neuronas conectadas entre sí. Cada capa se compone de neuronas que realizan operaciones matemáticas para propagar la información y ajustar la red durante el proceso de entrenamiento. En el artículo de Al-Adhaileh et al. (2022) se propone una red MLP para la predicción del rendimiento de los cultivos, según factores ambientales.
La arquitectura de la red MLP está formada de la siguiente manera:
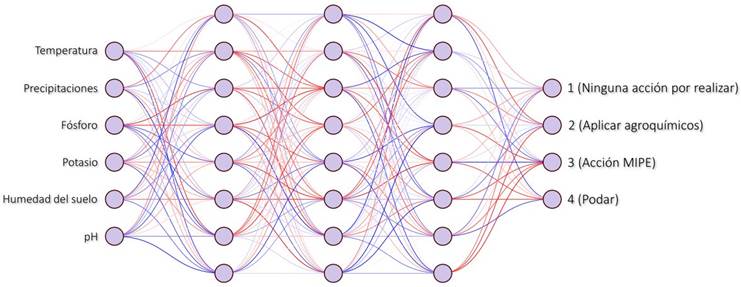
Capa de entrada: 6 neuronas, una por cada variable de entrada.
Capas ocultas: se realizará la experimentación con diferentes configuraciones de capas y número de neuronas en cada capa oculta para obtener el mejor rendimiento con el conjunto de datos disponible.
Capa de salida: 4 neuronas, una por cada acción que el caficultor debe realizar.
La función de activación en las capas ocultas será la función sigmoid y softmax en la capa de salida, ya que esta permite la clasificación con múltiples clases. La función softmax transforma las salidas en la capa de salida en una distribución de probabilidad sobre las diferentes clases.
La función de pérdida (también conocida como función de costo o función de error) mide la discrepancia entre las salidas predichas por el modelo y las etiquetas reales del conjunto de datos. El objetivo principal durante el entrenamiento de la MLP es minimizar esta función de pérdida para que el modelo pueda arrojar predicciones más precisas. En este problema de clasificación con múltiples clases, se puede utilizar la función de entropía cruzada categórica (categorical cross-entropy).
Con el objetivo de ajustar los parámetros de la red, que son los pesos de las conexiones entre las neuronas, durante el entrenamiento, se utiliza un algoritmo de optimización. En esta propuesta se selecciona el descenso de gradiente (gradient descent) con propagación hacia atrás de errores (backpropagation). Con este ajuste de los pesos se busca que el modelo aprenda a mapear las entradas hacia las salidas, de manera que las predicciones sean lo más cercanas posible a las etiquetas reales del conjunto de entrenamiento (estas salidas son las cuatro acciones de salida). Para hacer esto, la red pasa las entradas hacia adelante a través de las capas (proceso conocido como propagación hacia adelante), mediante el cálculo de las salidas predichas. Luego, se compara la diferencia entre las salidas predichas y las etiquetas reales mediante una función de pérdida. Una vez que se calcula la función de pérdida, el algoritmo de optimización entra en acción para ajustar los pesos en las neuronas para minimizar esa función de pérdida. El algoritmo de optimización utiliza la información proporcionada por la función de pérdida y sus gradientes para actualizar los parámetros de la red de manera iterativa. Existen diferentes variantes del algoritmo de descenso de gradiente, como el descenso de gradiente estocástico (stochastic gradient descent (SGD)), el descenso de gradiente con momento (momentum), el descenso de gradiente con RMSProp (root mean square propagation), el descenso de gradiente con adam (adaptive moment estimation), entre otros. El seleccionado para esta propuesta es adam.
Para implementar esta arquitectura de red se dispone de una herramienta denominada WEKA (Waikato Environment for Knowledge Analysis), y es frecuentemente utilizada en el ámbito de la investigación en minería de datos y aprendizaje automático. Cuenta con gran cantidad de algoritmos, además, permite un rápido prototipado y experimentación, facilidad de uso y diversas referencias en artículos científicos. También, su disponibilidad es de código abierto y gratuito.
Luego de distintas iteraciones en la experimentación con redes neuronales del tipo perceptrón multicapa, en la figura 3 se ilustra la arquitectura de red propuesta para el entrenamiento con el dataset de prueba.
Ahora se busca analizar los resultados del entrenamiento y pruebas de la red perceptrón multicapa con el software WEKA. El objetivo es evaluar el rendimiento en las predicciones de las acciones a realizar por el caficultor. Inicialmente, este modelo de red MLP fue probado con el dataset que está disponible en Atharva (2020), y permite predecir el tipo de cultivo que mejor rendiría en un suelo y datos climáticos particulares, y entrega resultados con exactitud (accuracy) elevada, superando el 95 %. Sin embargo, con el dataset de prueba, los resultados fueron inferiores al 60 % de exactitud, lo que es considerablemente negativo, debido a la aleatoriedad de los datos, lo cual será solucionado cuando los sensores se encuentren instalados. Es importante comparar el desempeño del modelo MLP con otros algoritmos del estado del arte para determinar si su uso es importante para el “caficultor digital”.
El estudio de Laddha (2023) presentó un sistema hidropónico automatizado basado en IoT que emplea árboles de decisión para monitorear y controlar parámetros como pH, intensidad lumínica y temperatura. Este enfoque se destacó por su interpretabilidad y eficiencia computacional, pues facilitó la adopción de tecnologías inteligentes en la agricultura. Aunque los árboles de decisión son más fáciles de interpretar, pueden ser propensos al sobreajuste, lo que podría limitar su precisión en escenarios con múltiples variables interdependientes.
Por otro lado, los bosques aleatorios, que combinan múltiples árboles de decisión, han mostrado mejoras en la precisión y robustez en comparación con los árboles individuales. El artículo de Singh y Sharma (2024) revisó aplicaciones de IoT en la agricultura de precisión, y destacó la efectividad de los bosques aleatorios en el manejo grandes volúmenes de datos y en la captura de interacciones complejas entre variables agroambientales. Sin embargo, aunque ofrecen un equilibrio entre interpretabilidad y rendimiento, su capacidad para modelar relaciones altamente no lineales puede ser limitada en comparación con una red MLP.
La regresión logística, conocida por su simplicidad y rapidez computacional, es adecuada para problemas de clasificación binaria o multiclase con relaciones lineales. No obstante, su incapacidad para capturar relaciones no lineales entre variables las hace menos adecuadas para problemas complejos como la predicción en cultivos con múltiples variables.
Reflexión final
En primer lugar, es importante destacar la escasa implementación de tecnología en la zona cafetera donde se llevaron a cabo las entrevistas. A pesar de ello, se obtiene café de alta calidad, bien recibido por los consumidores. Esto sugiere que los caficultores locales poseen una vasta experiencia y conocimiento gracias a los cuales obtienen resultados satisfactorios, sin depender en gran medida de la recolección automatizada de datos por medio de la tecnología. Sin embargo, es crucial reconocer que la utilización de datos recolectados y la generación de informes mediante su procesamiento continuo podrían permitir anticiparse a posibles eventos adversos en el cultivo.
Tras analizar el estado actual de la tecnología en el sector, se observa una tendencia hacia una mayor implementación de tecnología. Esto se puede leer en el informe de 2023 de la Federación Nacional de Cafeteros de Colombia (FNC, 2023), en el cual se destaca y se impulsa el desarrollo tecnológico para los siguientes proyectos:
IoT para monitoreo de variable en fincas. Solución digital para capturar información, dar trazabilidad y relacionar variables de producción en finca (recolección y beneficio, fermentación, secado) con variables de calidad del café (humedad, defectos en taza, perfil de taza, residuos químicos) para retroalimentar al productor, mejorando calidad.
Visión artificial. Detección de defectos físicos y tamaño de grano mediante análisis de imágenes.
Nariz electrónica. Uso de una nariz electrónica para análisis sensorial. Este desarrollo busca apoyar la evaluación de la calidad del café.
Inteligencia artificial. Clasificación de granos según su apariencia física y defectos.
El informe también revela que los proyectos de innovación tecnológica son altamente valorados en el sector, y el “caficultor digital” podría impulsar mejoras de la producción de café.
Si bien los resultados durante el entrenamiento de la red MLP fueron poco satisfactorios, debido a la limitada disponibilidad de datos reales, la generación de datos aleatorios ocasionó la falta de patrones discernibles para agrupar propiedades a lo largo de las capas de la red MLP. Esta es una de las principales limitaciones del proyecto, que introduce incertidumbre en el desempeño del modelo bajo condiciones reales. Para superar este desafío, están planificadas las etapas de recolección de datos mediante sensores IoT, lo que permitirá ajustar y validar el modelo. Además, se evaluará el impacto del modelo en métricas clave como la calidad del grano y el rendimiento de las cosechas, lo que demostrará su influencia positiva en la producción cafetera. Con estas iniciativas, el modelo tiene el potencial de convertirse en otra herramienta para la agricultura de precisión en el sector cafetero.
También es importante definir una metodología para registrar las acciones realizadas por el caficultor humano en la finca. Esto implica que, una vez que los sensores estén instalados y en funcionamiento, y los datos comiencen a registrarse de forma continua, deben documentarse y organizarse todas las acciones del caficultor en su finca. En este sentido, el conjunto de datos estará etiquetado con la salida correspondiente, que representa la acción que el modelo “caficultor digital” entregará como predicción.
Entre las principales limitaciones del estudio se destaca la falta de datos agroambientales reales recopilados en campo, al momento de iniciar la investigación, lo cual afecta la precisión y relevancia del modelo “caficultor digital”. Actualmente, este se apoya en datos generados aleatoriamente que, si bien resultan útiles para las simulaciones preliminares, no representan con fidelidad la complejidad de las interacciones reales entre las variables ambientales y las prácticas del caficultor. Para superar esta limitación, se implementará una red experimental IoT en la finca Las Acacias, destinada a recolectar datos en tiempo real sobre variables como humedad del suelo, temperatura y pH. Esta red será complementada con una estrategia de monitoreo continuo a lo largo de varias cosechas, con el fin de capturar variaciones estacionales y espaciales. Además, se incorporarán registros manuales aportados por los caficultores locales para enriquecer el conjunto de datos disponibles.
Otra limitación significativa es la dependencia inicial de datos simulados, lo que restringe la capacidad del modelo para identificar patrones reales en las primeras etapas de su desarrollo. Esta situación afecta la calidad de las predicciones, ya que los datos aleatorios no incorporan toda la variabilidad presente en un entorno agrícola real. Para mitigar este problema, el modelo será entrenado de manera progresiva con los datos reales que se recopilen, y será ajustado para reflejar mejor las condiciones específicas del cultivo. Además, se planea una validación cruzada con caficultores expertos, cuyo conocimiento y experiencia serán fundamentales para afinar las predicciones y garantizar que las decisiones generadas sean aplicables y efectivas en la práctica.
Trabajo futuro
En el desarrollo del modelo “caficultor digital”, es crucial avanzar en su validación y mejora a través de varias iniciativas. En primer lugar, se plantea la recolección de datos reales a través de sensores IoT en la finca Las Acacias. Estos datos incluirán parámetros agroambientales reales como temperatura y humedad del suelo y del ambiente, con los cuales se entrenará y probará el modelo.
Asimismo, se sugiere la experimentación con diferentes modelos de predicción, como bosques aleatorios y modelos híbridos, para evaluar su desempeño en comparación con la red MLP. Estas comparaciones ayudarán a evaluar cada enfoque según la necesidad específica del caficultor de la finca.
Por último, es importante evaluar el impacto del modelo en la producción cafetera, además de considerar métricas como la calidad del grano, el rendimiento de las cosechas y la reducción en el uso de insumos agrícolas. Este análisis validará la utilidad del modelo y ayudará a identificar áreas de mejora y a expandir su alcance en el sector cafetero.

