











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkI. INTRODUCCIÓN.
Este trabajo aporta al tema de la innovación en tecnología a partir de los trabajos formales de eficiencia técnica, que inician formalmente a principios de los cincuenta, con los trabajos de Koopmans (1951), Debreu (1951) y Farell (1957) . Aunque recientemente los empresarios ven en la planificación de innovación tecnológica el tema de la eficiencia técnica (ET) e intentan incorporar estrategias relacionadas con la gestión de operaciones (GO) y ven a esta como sinónimo de rentabilidad, reducción de inventarios, aunque han incorporado el concepto de gestión de materiales para alcanzar el óptimo del servicio a partir de la minimización de costos, recurren muchas veces a mejorar los niveles de productividad a partir de estrategias logística como un modelo estratégico de eficiencia. Este trabajo va en esa dirección, intentando evaluar si la falta de talento humano especializado en actividades logísticas probablemente afecta el desempeño de la (GO) lo que conllevaría probablemente a la falta de innovación en el diseño de productos y procesos en las empresas de menor tamaño en América Latina (AL).
Sin embargo, una de las dificultades en América Latina (AL), está relacionado con la (ET) y específicamente en asuntos relacionados con bajos niveles de desempeño logístico que tienen que ver principalmente con una inadecuada infraestructura, falta de inversión, bajos desempeño de actores involucrados en la cadena de abastecimiento, restricciones relacionadas con legislación de cada país, bajos niveles de acumulación de capital humano en sentido estricto, muchos trabajadores que al no ser especialistas en actividades logísticas no contribuyen con la optimización de los costos de operación, o con la gestión de operaciones, ni mucho menos con el servicio a sus clientes (Kirby & Brosa, 2011).Esta situación, junto con otros factores como los costos logísticos como porcentaje del PIB evidencia que estos, los costos logísticos en América Latina, son altos en comparación con Singapur y países del OCDE Kogan & Guash (2006). En este sentido, se propuso responder la siguiente pregunta: ¿existiría alguna probabilidad de que el bajo desempeño en la (GO) en (AL) se estaría presentando por la falta de (TH) especializado en actividades logística en esta región?
II. REVISIÓN DE LA LITERATURA.
En cuanto a los aspectos conceptuales, es pertinente tomar en cuenta lo expresado por, Langley (1986) ; Carrasco (2000) ; García (2004) ; Trujillo (2005); Christopher (1994); Lambert et al (1998) ; Ballou (1999) ; Stock et al (2000); Sarache et al. (S/A) . A comienzo de los noventa, se comenta sobre el tema de la logística, hoy logística pasa a formar parte integral de la cadena de suministros, intentando integrar los procesos operativos y de capital humano.
En este sentido, (Cohen S. y Roussel J., 2005), Chopra y Meindl (2008) y Bowersox et al (1986) consideran que es la planeación, el abastecimiento y la producción, los factores determinantes de la cadena de suministro incluye no solamente al fabricante y al proveedor, sino también a los transportistas, almacenistas, vendedores al detalle e incluso a los mismos clientes. Según la literatura económica, el desempeño en las compras es considerado un importante elemento del desempeño corporativo, sin embargo, la medición de este desempeño y su comparación con otras áreas de compras y transporte, ha probado ser muy difícil. Desde la perspectiva de Harland et al (1999) los costos de producción, la calidad y la velocidad de respuesta al cliente, así como los costos de transporte, calidad y los tiempos de entrega; en esta misma ruta, Rojas (2014) establece que compras, integración de proveedores, las asociaciones de comprador-proveedor, la fuente de gestión de bases, alianzas estratégicas de proveedores, la sincronización de la cadena de suministro y, por último, simplemente Supply Chain Management son los factores determinantes de la gestión de operaciones, al respecto, Stock & Lambert (2000) señalan que es la integración organizacional, proveedores, minoristas y clientes, las estrategias corporativas, la red de la cadena de abastecimiento, incluyendo al cliente final seria los factores determinantes de la gestión de operaciones. Para (Simichi, et al, 2000) y Jiménez (2000) son los detallistas los quienes deben entregar las cantidades correctas, en los lugares correctos y en el tiempo preciso, buscando el menor costo, Beamon (1998) , considera que los proveedores, fabricantes, distribuidores y minoristas, quienes determinan el desempeño de la gestión.
Al respecto, Servera, Gil y Fuentes (2009) , señalan que en la práctica empresarial y en el estudio académico de la logística, la incorporación de los conceptos “calidad” primero y “valor” después, Es a mediados de los años 90, cuando el estudio de la logística empieza a centrarse en su capacidad para entregar calidad y generar valor (Mentzer et al 2004), y hoy, en palabras de Ballou (2004:13), se acepta que “la logística gira en torno a la creación de valor: valor para los clientes, los proveedores y los accionistas de la empresa”.
Sin embargo, en la actualidad no existe suficiente claridad acerca de los factores que determinan la probabilidad de ocurrencia del bajo desempeño de la gestión de operaciones logística por la falta de talento humano especializado en algunas empresas de menor tamaño en América Latina, Arciniegas (1998) , Ariza (1997), Carrasco (2000) y Lambert et al (1998) ; no obstante, muchos estudios han encontrado que la (GO) está determinada por factores de gestión del conocimiento de orientación al cliente, capacidad del empleado y capacitación relacionada con el trabajo tuvieron una influencia variable en las dimensiones de calidad y eficiencia del rendimiento del sistema de servicio. Jayaram y Xu, (2016) .
De hecho, Henry, Patuwo y Hu, (1998) en un trabajo reciente respecto a "The human factor in advanced manufacturing technology adoption: An empirical analysis",examinan los factores de éxito críticos para la adopción e implementación de tecnología de fabricación avanzada.evalúan empíricamente la hipótesis de que las variables de gestión más asociadas con el factor humano en los proyectos de automatización por sí solas pueden diferenciar a las empresas que tienen éxito en la adopción de las tecnologías de aquellas que no tienen tanto éxito. Al respecto, Neumann, & Dul (2010) plantea que, son escasos los aportes empíricos que abordan la articulación entre la gestión humana y estrategia de operaciones, sin embargo, Ahmad & Schroeder (2003) . En The impact of human resource management practices on operational performance: recognizing country and industry differences. Journal of Operations Management, evaluaron en cuatro países el impacto que siete prácticas de gestión humana (seguridad en el empleo, contratación selectiva, uso de equipos de trabajo y descentralización, compensación asociada al desempeño, entrenamiento extensivo, diferencia de status e información compartida) tenían sobre el desempeño en las operaciones, medida globalmente a través del desempeño en seis prioridades con respecto a los competidores del mercado: costo unitario, calidad, entregas, flexibilidad y velocidad en la introducción de nuevos productos.
III. METODOLOGÍA.
TIPO DE INVESTIGACION.
Este trabajo es de tipo exploratorio con un enfoque cuantitativo y un alcance correlacional. Los datos provienen de algunas empresas del sector logístico en AL, que colaboraron con el estudio, para la toma de los datos se utilizaron empresas de menor tamaño por número de trabajadores del sector logístico en AL de acuerdo con la ficha técnica de la Tabla 1 y cuyas actividades logísticas, son homologas a CIIU 5229 (Revisión 4 adaptada para Colombia CIIU Rev. 4 A.C.) para las economías objetos de estudio.
En relación con el tamaño de la muestra para la realización del modelo logístico se utilizó el criterio Freeman (1987) el cual afirma “el tamaño de muestra ha de ser unas diez veces el número de variables independientes a estimar más uno,” p.50. formalmente [n = 10 * (k + 1)] donde, n representa tamaño de la muestra k, es el número de parámetros a estimar para efectos de este trabajo es uno (1). En este sentido un principio esencial en la determinación del tamaño de una muestra es que la aproximación utilizada se corresponda con los objetivos y el diseño de la investigación y con el tipo de análisis que se está planeando.
Para la selección de las variables de estudio, se tuvieron en cuenta los trabajos de Jayaram y Xu, (2016) ; Jayaram y Vickery (1999); Da Silveira & Sousa (2010) , Furlan. & Dal (2011) ; Goodridge (1986) ; Patrick y Dul, (2010) , quienes analizaron variables relacionadas con los determinantes de la calidad y el desempeño de la eficiencia en las operaciones de servicio, factores de gestión del conocimiento de orientación al cliente, capacidad del empleado y capacitación, capacidad del empleado, capacitación relacionada con el trabajo costo, calidad, flexibilidad, tiempo, gestión humana y su impacto en el desempeño del sistema productivo como un campo fértil para profundizar en la investigación, entre otros.
Con base en esta revisión, se elaboró un formato que fue aplicado a la muestra seleccionada, tal como se especifica en la tabla 1.
Para el procesamiento de datos se utilizaron dos métodos estadísticos:
El análisis factorial (afc): es una metodología descriptiva de carácter multivariante que permite la reducción de una gran cantidad de información a un pequeño número de modalidades de variables cualitativas asociadas, con la menor pérdida posible de información. Requiere que los datos representen las respuestas de un grupo de individuos a un conjunto de preguntas.
La regresión logística (rl): es una técnica de análisis inferencial utilizada para predecir el resultado de una variable dependiente categórica y dicotómica (solo acepta dos posibles respuestas), es decir, aquella cuyos elementos de variación tienen carácter cualitativo y adopta modalidades de variables explicativas en función de la variable dependiente. Esta técnica valora la contribución de diferentes factores en la ocurrencia de un evento simple (De la Fuente, 2011), cuyos resultados se obtienen comparando el resultado de las modalidades presentes en la tabla, con la casilla de referencia (no presente en la tabla) mediante el criterio de la razón de proporciones.
En el procesamiento de datos se utilizaron los programas estadísticos SPSS (versión 23) y Statgraphics Centurión (versión 16.1.15).
LAS VARIABLES Y EL MODELO UTILIZADO
Las variables objeto de estudio fueron:
Gestión de operaciones (GO), toma el valor de 1 si la empresa dispone de un operador logístico y 0 en otro caso. Para efectos de este trabajo se utilizó como variable proxy de la gestión de operaciones logística (GO), si la empresa dispone o no de un operador logístico la variable X 5
Talento Humano (TH) fue dicotomizada tomando el valor de 1 si el talento humano está especializado en asuntos logístico y 0 en otro caso;
Con base en los argumentos planteados en los ítems anteriores se intentó probar la hipótesis:
Ho La probabilidad de ocurrencia de la razón por la cual ocurre un bajo desempeño en la gestión de operaciones logística en América Latina no se puede predecir por la falta de talento humano especializado en logística.
Al respecto,
Variable independiente: talento humano especializado en asuntos logísticos (TH) se siguen los trabajos de Aguilar, J.A. (2001). Acero, M (2002) , Aguezzoul, A. (2014). Arciniegas H. (1998), Ariza,J.E.(1997).Avendaño, G. (2003), Ballou, R. (2004) . Bowersox, J.D; Cross J.D; Helferich O.K. (1986) , Burbano, E., Blanco, L. y Morales, R. (2009) , Burtman, J., Bargam, M. (2002) , Carrasco, J. (2000) , Carrión, A. (1998) , Cohen S. y Rousse J. L, (2005) , Cooke P. (1997). Correa, A. y Gómez, R. (2009) . Chopra, S.l y Meindl, P. (2008) , Díaz, García y N. Porcell (2008) , Fajardo, H. (2017) , García, J.G. (2004) , Gallardo, H. (2005) , González, J. (2015) , Giraldo, C.M., (2000) , Harland, C.M., Lamming, R.C., & Cousins P, D., (1999) , Jiménez, E. (2000) , Jiménez, J. y Hernández, S. (2002) , Kulmala, H.I. (2004). Kirby, C. & Brosa, N. (2011) .
Variable dependiente: Gestión de Operaciones (GO), se siguen los trabajos de Carman, J.M. (1990) , Crosby, P. (1991) , Guasch, J. (2011) , Handfield, R., & Nichols, E. L. (2002) . Mentzer, J.T., Myers, M.B. y Cheung, M-S. (2004), Millen, R. y Maggard, M. (1997)
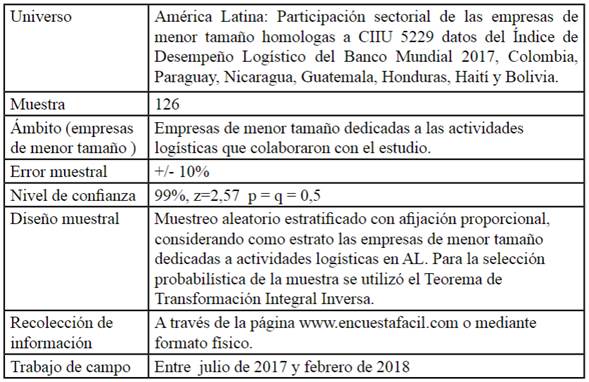
Los modelos de elección discreta predicen directamente la probabilidad de la ocurrencia de un suceso que viene definido por los valores de las variables independientes. Como los valores de una probabilidad están entre cero y uno. Las predicciones realizadas con los modelos de elección discreta deben estar acotadas para que caigan en el rango entre cero y uno. El modelo general que cumple esta condición es un caso particular del modelo de regresión múltiple que se denomina modelo de elección discreta, y tiene la forma funcional:
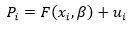
Se observa que si F es lineal tenemos el modelo lineal de probabilidad, pero si F es la función de distribución de una variable aleatoria, entonces P varía entre cero y uno de modo seguro.
En el caso particular en que la función F es la función logística estaremos ante el modelo Logit o Regresión Logística, cuya forma funcional será la siguiente:
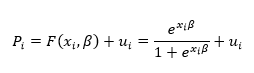
En el caso particular en que la función F es la función de distribución de una normal unitaria estaremos ante el modelo Probit, cuya forma funcional será la siguiente:
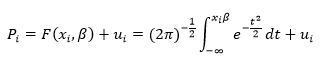
Sin embargo, si el tipo de modelo de regresión que se analiza opera con variable dependiente binomial (modelo logístico o modelo de regresión logística) será un modelo que permita estudiar si dicha variable discreta depende o no de otra u otras variables. Si una variable binomial de parámetro p es independiente de otra variable X, se cumple
(p\X=x)=p, para cualquier valor de x de la variable X. Por consiguiente, un modelo de regresión con variable dependiente binomial y una única variable independiente X se materializa en una función en la que p p aparece dependiendo de X y de unos coeficientes cuya investigación permite abordar la relación de dependencia.
Para una única variable independiente X el modelo de regresión logística toma la forma:
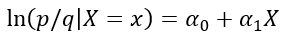
O de forma simplificada:
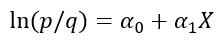
Donde ln significa logaritmo neperiano, αo y α1 son constantes y X una variable que puede ser aleatoria o no, continua o discreta. Este modelo se puede fácilmente generalizada para k variables independientes, dando lugar al modelo logístico múltiple, que expresa como sigue:
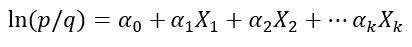
Hemos definido el modelo logístico como el logaritmo de odds para el suceso que representa la variable aleatoria binomial puntual dependiente del modelo.
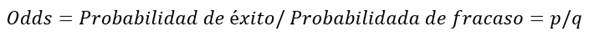
Hay varias razones para plantear el modelo con el logaritmo de odds, en lugar de plantearlo simplemente con la probabilidad de éxito o con el odds. En primer lugar, el campo de variación de ln (p1q) es todo el campo real (de -∞ a ∞), mientras que para p el campo es sólo de 0 a 1 y para p/q es de 0 a ∞. Por tanto, con el modelo definido en función del logaritmo de odds no hay que poner restricciones a los coeficientes que complicarían su estimación. Por otro lado, y más importante, en los modelos en función del logaritmo de odds los coeficientes son fácilmente interpretables en términos de independencia o asociación entre las variables, como se verá más adelante.
El modelo logístico se puede escribir de otras formas equivalentes que para ciertas aplicaciones son más cómodas de manejar. Tenemos:
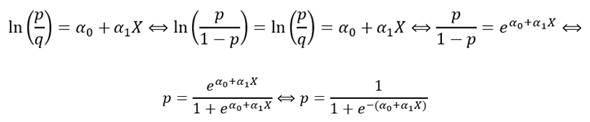
Estas dos últimas expresiones, si son conocidos los coeficientes αo y α1, permiten calcular directamente la probabilidad del proceso binomial para los distintos valores de la variable X.
A la función
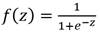 se le denomina función logística. El modelo de regresión logística modeliza la probabilidad de un proceso binomial como la función logística de una combinación lineal de la variable dependiente.
se le denomina función logística. El modelo de regresión logística modeliza la probabilidad de un proceso binomial como la función logística de una combinación lineal de la variable dependiente.
El modelo de regresión logística múltiple tendrá la expresión:
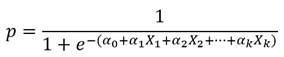
Finalmente, para abordar el tema de la estimación de los coeficientes, el método de los mínimos cuadrados, clásico en la estimación de los coeficientes de los modelos de regresión, no es aplicable al modelo logístico, dado que, dicho método se basa en la normalidad de la variable dependiente, que en este caso no se cumple. Por otra parte, cuando q=0, es imposible calcular ln (p1q). Se tratará entonces de utilizar el método de máxima verosimilitud.Se consideró ando el caso más simple con una sola variable independiente X. tomamos una muestra de n observaciones (y i , x i ) para la variable puntual binomial dependiente Y y para la variable independiente X. La variable Y toma valores y i que sólo pueden ser 1 con probabilidad p i o 0 con probabilidad. 1-p i . Como x i depende de p i a través del modelo logístico tenemos:
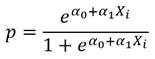
La función de verosimilitud para una variable binomial puntual es:
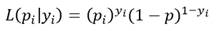
Y para n observaciones independientes la función de verosimilitud de la muestra será:
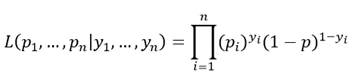
y al representar p i por el modelo logístico tendremos ya la expresión de la función de verosimilitud para la muestra como función de los parámetros a estimar:
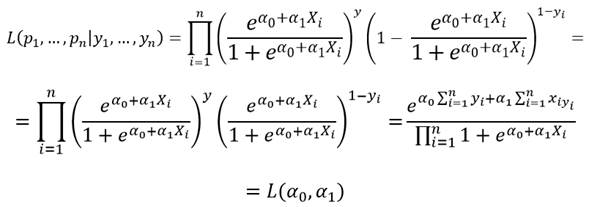
y como suele ser usual en máxima verosimilitud, maximizaremos el logaritmo de la función L(αo,α1) en vez de la función misma. Los parámetros estimados del modelo serán los valores de αo y α1 que maximicen la función Ln L(αo,α1).
En este sentido, para la estimación por intervalos y contrastes de hipótesis sobre los coeficientes, partimos del teorema central del límite, los estimadores por máxima verosimilitud de los parámetros del modelo logístico son asintóticamente normales y su matriz de varianzas covarianzas es calculable a partir del algoritmo de maximización de la función de verosimilitud (Método de Newton Rhampson).
De esta forma, un intervalo de confianza al (1- α) % para el estimador del coeficiente αi del modelo será:
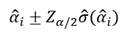
Hay que tener presente que los estimadores habituales que miden asociación entre variables son los odds ratio, por tanto, interesa dar los intervalos de confianza para los odds ratio, que evidentemente serán:
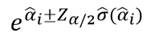
El estadístico para el contraste será:
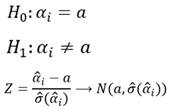
y con región crítica |Z| > Z α/2
También suele utilizarse para el contraste el estadístico de Wald definido como W=Z 2 y cuya distribución es una chi-cuadrado con 1 grado de libertad. La región crítica de este contraste es W=X 2 α.
En el modelo logístico es muy interesante contrastar la hipótesis α i =0 para, i=1,…, k, porque, no rechazar esta hipótesis para un valor de i, implica que la variable Y no depende X i , y por lo tanto esta última no debería figurar en el modelo.
También suele utilizarse el contraste de la razón de verosimilitudes, basado en el estadístico -2Log(L 0 /L 1 ) donde L 0 es el máximo de la función de la verosimilitud bajo la hipótesis nula y L 1 es el máximo de la función de verosimilitud bajo la hipótesis alternativa. Este estadístico tiene una distribución chi-cuadrado con grados de libertad igual al número de parámetros bajo la hipótesis nula. Si se elige la función F como la función de distribución de una Normal (0,1), el modelo lineal general:
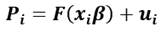
se denomina modelo Probit, cuyos parámetros β admiten estimación por máxima verosimilitud dado por :
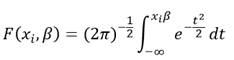
En el caso de que
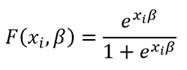
Estaríamos ante el modelo Logit dado que el logaritmo de la razón de probabilidades es lineal, tanto en las variables como en los parámetros. La estimación de estos puede realizarse mediante el método de máxima verosimilitud (Green 2001) quedando el modelo logita así:
IV. RESULTADOS
Los resultados se pueden resumir en siete (7) puntos así:
Se probó la hipótesis que predice que la probabilidad de ocurrencia de la razón por la cual ocurre un bajo desempeño en la gestión de operaciones logística en América Latina no se puede predecir por la falta de talento humano especializado en logística.
Los test la prueba de ómnibus, el resumen del modelo y el modelo de elección discreta en cada una de las tablas de referencia 1,2,3 y finalmente la Prueba de Hosmer y Lemeshow para validar el modelo. Tabla 1
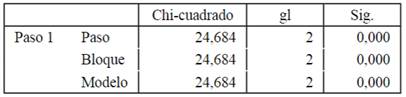
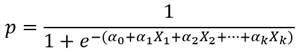
Obteniéndose el modelo X´ β=1,511-2,185X5
El modelo se validó con los siguientes procesos tabla 2 y 3
Tabla 2 Resumen del modelo

a) La estimación ha terminado en el número de iteración 5 porque las estimaciones de parámetro han cambiado en menos de 0 ,001.
b) Fuente: autor salida spss v23.
Para analizar cuáles son las variables que mayor influencia tienen en el TH se realizó un análisis de RL, en el que la variable respuesta es GO, que se transformó en una variable dicotómica en la que solo se tomaron dos opciones: uno (1), sí TH es especializado, y cero (0), en caso contrario no tiene intención de crear empresa.
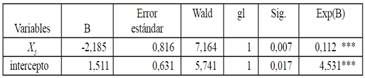
Se pudo observar que el valor del coeficiente -2.185 significa que, dejando todas las demás variables constantes, la falta de talento humano especializado en logística disminuiría la probabilidad del desempeño de la gestión de operaciones logística en 2.18 veces en las empresas de AL.
Para validar el modelo utilizamos el test de Hosmer y Lemesshow (2000) , con Chi-cuadrado 0,041y un valor p-valor de 0,041, confirma que el valor R cuadrado de Nagelkerke explica el 53,4% de la varianza del desempeño de la gestión de operaciones logística tabla 4.
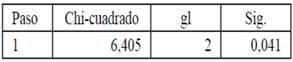
El valor EXP (B) de 0,112 con punto de corte 1, para este caso, la puntuación de EXP (B) es menor a uno, esto indica que, la falta de talento humano especializado en asuntos logísticos, disminuye el desempeño en la gestión de operaciones logística. Esto se confirma además por la puntuación de Wald que para este modelo fue de 7,164 gl 1 y un p-valor de 0,007 menor al 0. 001.Con esto comprobamos la hipótesis de que la falta talento humano especializado permite predecir en un 86% la probabilidad de concurrencia de la razón por la cual hay un bajo desempeño en la gestión de operaciones logística en la pequeña empresa en AL.
V. CONCLUSIONES.
El talento humano es un factor clave en el desempeño de la gestión de operaciones (GO) para la trazabilidad de los procesos, en la logística de abastecimiento, en producción, programación de producción y logística distribución, para la muestra analizada. En segundo lugar, los resultados sugieren que TH genera un efecto significativo en la GO para AL lo que posiblemente indicaría que las firmas de menor tamaño deberían poner mayor énfasis en mantener capacitados a los empleados en procesos y asuntos logísticos.
Para el caso colombiano, en materia logística en el ranking de la región, al pasar de la posición 10 a la 13 entre los años 2016 y 2017, del Índice de Desempeño Logístico del Banco Mundial 2017, y en relación con Latinoamérica, Colombia solo supera a Paraguay, Nicaragua, Guatemala, Honduras, Haití y Bolivia.
Al respecto, de esto, los parámetros internacionales, por ejemplo, del Banco Mundial, solo consideran el bajo desempeño logístico, explicado por cuatro factores: la eficiencia de las aduanas, baja capacidad de los envíos de llegar a su destino a tiempo, la falta de seguimiento y localización de las mercancías y la calidad de los servicios logísticos, pero, ¿del talento humano y sus efectos en el desempeño logística nada o casi nada se dice? Al respecto: Jayaram y Xu, (2016) evalúan los determinantes de la calidad y el desempeño de la eficiencia en las operaciones de servicio, estos autores proponen un modelo hipotético, utilizando una muestra de 249 empresas de servicios chinos, aplicando como metodología las ecuaciones estructurales y análisis de regresión jerárquica. Los resultados encontrados por ello indican que los factores de gestión del conocimiento de orientación al cliente, capacidad del empleado y capacitación relacionada con el trabajo tuvieron una influencia variable en las dimensiones de calidad y eficiencia del rendimiento del sistema de servicio. Además, las facetas de conocimiento interno de la capacidad del empleado y la capacitación relacionada con el trabajo tuvieron efectos complementarios al inducir un mejor desempeño.
Jayaram y Vickery (1999). En un estudio relacional respecto al “The impact of human resource management practices on manufacturing performance. Journal of Operations Management”estudian la relación entre diversas prácticas de gestión de recursos humanos (compromiso de la alta dirección, comunicación de objetivos, entrenamiento formal, equipos de trabajo multifuncionales, trabajos amplios, entrenamiento cruzado, autonomía, impacto del empleado, administración de relaciones laborales y organizaciones abiertas) y el desempeño en manufactura a través de cuatro prioridades competitivas (costo, calidad, flexibilidad y tiempo) los autores concluyen relaciones significativas entre estas variables.
Da Silveira & Sousa (2010) , evalúan el efecto sobre cuatro prioridades (costo, calidad, entregas, flexibilidad) y comprobó que estas prácticas tuvieron efecto significativo sobre el costo, pero no sobre las demás, a pesar que la literatura sugiere ampliamente un efecto positivo, por lo que estos autores sugirieron las posibles razones por la cual no encontraron relaciones. Al respecto, Furlan. & Dal (2011) encuentran relaciones significativas entre la gestión humana y su impacto en el desempeño del sistema productivo como un campo fértil para profundizar en la investigación.
Goodridge (1986) plantean que la administración de operaciones británica debería poner mayor énfasis en mantener las relaciones con los empleados, además consideran que la tecnología, impactan significativamente al empleo y estas interacciones generan efectos sobre la gestión de operaciones e indican que es necesario pasar de una orientación de control a una de compromiso en el lugar de trabajo.
Patrick y Dul, (2010) trabajaron en "Human factors: spanning the gap between OM and HRM", probaron la hipótesis, respecto a, la aplicación del conocimiento de los factores humanos (FC) puede mejorar el rendimiento del sistema de operaciones y el bienestar humano. Los autores realizan una revisión sistemática utilizando una base de datos general y dos especializadas para identificar estudios empíricos que abordan tanto los efectos humanos como los del sistema operativo al examinar los aspectos de diseño del sistema operativo de fabricación. El trabajo mostró una convergencia entre efectos humanos y efectos del sistema incluyeron calidad, productividad, rendimiento de implementación de nuevas tecnologías y también más efectos "intangibles" en términos de comunicación y cooperación mejoradas. Los efectos humanos incluyeron la salud de los empleados, las actitudes, la carga de trabajo física y la "calidad de la vida laboral"
En suma, los resultados de este trabajo deberían tomarse con prevención, dado algunos factores limitantes, como son, el uso de modelos estadísticos para aproximarnos en comprender realidades o fenómenos de las Ciencias Sociales.

