










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkUniversitas Psychologica
Print version ISSN 1657-9267
Univ. Psychol. vol.8 no.1 Bogotá Jan./Apr. 2009
La validez discriminante como criterio de evaluación de escalas: ¿teoría o estadística?*
Discriminant Validity as a Scale Evaluation Criterion Theory or Statistics?
JOSÉ ANTONIO MARTÍNEZ-GARCÍA** Universidad Politécnica de Cartagena, España
LAURA MARTÍNEZ-CARO Universidad Politécnica de Cartagena, España
* Artículo teórico en psicometría.
** Dirigir la correspondencia al Departamento de Economía de la Empresa. Area de Comercialización e Investigación de Mercados. Facultad de Ciencias de la Empresa. Universidad Politécnica de Cartagena. Paseo Alfonso XIII, 50 - 30203. Cartagena. Tlf. 96832 59 39. Fax. 968 32 57 74. Correo electrónico:josean.martinez@upct.es.
Recibido: julio 8 de 2008 | Revisado: noviembre 20 de 2008 | Aceptado: diciembre 10 de 2008
Resumen
La validez discriminante es uno de los criterios habituales para evaluar las escalas de medida de constructos latentes en ciencias sociales. Este artículo muestra como se pueden obtener resultados contradictorios si se aplican diferentes procedimientos estadísticos, por lo que se recomienda evaluar de forma teórica la divergencia entre escalas que representan conceptos. De este modo, la validez de contenido actúa como criterio robusto frente a determinados análisis estadísticos basados en covarianzas.
Palabras clave autores Validez discriminante, validez de contenido, escalas de medida.
Palabras clave descriptores Diseño experimental, escalas, análisis de varianza.
Abstract
Discriminant validity is one of the usual criteria for evaluating measurement scales that define latent constructs in social sciences. This article shows how different statistical procedures frequently used for accomplishing this aim can yield misleading results. Authors recommend a theoretical judgement about divergence among scales that are manifestation of latent concepts. Therefore, content validity represents a robust condition against certain covariance statistical based analysis.
Key words authors Discriminant Validity, Content Validity, Measurement Scales.
Key words plus Experimental Design, Scales, Analysis of Variance.
Introducción
La validez de las mediciones de los constructos o variables utilizados en Psicología, marketing y otras disciplinas afines, es una condición indispensable para el desarrollo y contraste de teorías científicas en estos campos de conocimiento. No es de extrañar, por tanto, la gran importancia que se le otorga a los métodos de validación en la literatura de las ciencias sociales, sobre todo a raíz de los trabajos de Cattel (1946), Cronbach y Meehl (1955), y Campbell y Fiske (1959).
Tradicionalmente, se afirma que la forma de medir un constructo es válida si las medidas implementadas miden realmente lo que pretenden medir (Cook & Campbell, 1979). A lo largo de la literatura se han propuesto diversos criterios para llevar a cabo ese proceso de validación (p.ej., Steenkamp & Trijp van, 1991), siendo la validez convergente y discriminante dos de los más utilizados, y que tal vez se han ligado más estrechamente a la idea de validez de constructo. De este modo, y a partir de los argumentos de Campbell & Fiske (1959), se afirma que, para que unas medidas sean válidas, las de un mismo constructo deben correlacionar altamente entre ellas (validez convergente), y que esa correlación debe ser mayor que la que exista con respecto a las medidas propuestas para otro constructo distinto (validez discriminante).
No obstante, existe un amplio debate en la literatura sobre el propio concepto de validez y las diferentes visiones acerca de la importancia de la red nomológica en la validación de mediciones, así como sobre la prevalencia de la perspectiva causal y las implicaciones que ello conlleva en la metodología utilizada por el investigador (p.ej., Bagozzi, Yi & Phillips., 1991; Markus, 1998; Hayduk & Glaser, 2000; Hancock & Mueller, 2001; Borsboom, Mellenbergh & Heerden van, 2004). El objetivo de nuestro artículo no es, sin embargo, participar de esa discusión ni deliberar acerca de las diferentes posturas, sino reflexionar sobre las diferentes formas que habitualmente se utilizan para estudiar la validez discriminante de las mediciones; es decir, una vez que el investigador se posiciona por una de las corrientes en disputa, establece una forma de actuar, y es precisamente esa forma de proceder la que ponemos bajo análisis, y no la filosofía subyacente.
Escenario de análisis
Vamos a centrar el análisis en las situaciones en las que el investigador plantea varias mediciones por variable utilizando un método común. Asimismo suponemos un marco conceptual que requiere una interpretación realista sobre causalidad (Borsboom, Mellenbergh & Heerden van, 2003); es decir, que cambios en el valor de la variable de interés deben reflejarse en cambios en las mediciones implementadas y que, además, esas mediciones son agregadas para finalmente hallar el valor del constructo subyacente. Este escenario es el más común en los estudios en los que se recoge información del mercado (consumidores, empresas, etc.), aunque lógicamente no refleja todas las situaciones, quedando excluidos, por ejemplo, los estudios que utilizan matrices multirasgo-multimétodo o los que defienden una concepción formativa sobre la medición.
Para ilustrar nuestro razonamiento vamos a considerar un clásico ejemplo de Psicología del Consumo, donde el investigador está interesado en estudiar el efecto de la calidad percibida por el consumidor de un producto X sobre las intenciones futuras de mantener una relación comercial con la empresa Y (p.ej., Zeithaml, Parasuraman & Berry, 1996; Brady, Cronin & Brand, 2002). Para ello tomamos como referencia el estudio de Martínez, Flores y Martínez (2006) en el contexto de servicios financieros, donde se analiza una muestra de 207 consumidores. En este estudio se utilizan cuatro indicadores para el constructo "calidad" y tres para la variable "lealtad", medidos en una escala de intervalo (método común), siendo la media de esos indicadores el valor de referencia de ambas variables. De esta forma podemos plantear un enfoque sencillo de ecuaciones estructurales (Figura 1).
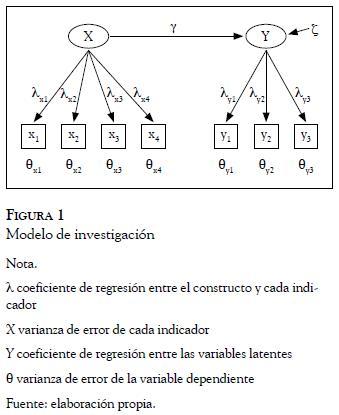
Formas de evaluar la validez discriminanteLlegados a este punto, y tras analizar la consistencia interna (validez convergente) de los indicadores de las dos variables, el investigador suele proceder al estudio de la validez discriminante a través de los siguientes métodos.
Comparación entre las correlaciones de los indicadores
Según las recomendaciones de Campbell & Fiske (1959), como las variables X y Y son indicadores de constructos distintos, existe validez discriminante si todas las correlaciones entre los indicadores de X (Rxx) y Y(Ryy) son significativas y cada una de esas correlaciones es mayor que todas las correlaciones entre indicadores de ambas variables (Rxy).
Para ver la precisión de las correlaciones construimos los intervalos de confianza al 95% usando el método de la transformada de Fisher (Rosnow & Rosenthal, 1996) tal como se muestra en la Tabla 1.
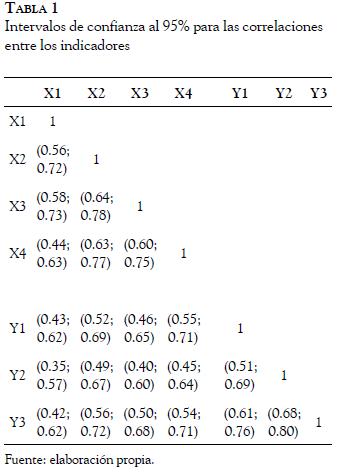
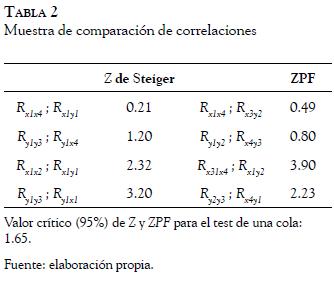
Rápidamente se constata que, aunque todas las correlaciones intravariables (Rxx;Ryy) son ampliamente diferentes de cero, los intervalos de confianza se solapan con los de las correlaciones intervariables ( Rxy) en un gran número de casos. Sin embargo, y dado que entran en juego comparaciones entre correlaciones dependientes, en este caso, deberían analizarse 72 comparaciones (6 x 12) entre Rxx y Rxy , y 36 comparaciones (3 x 12) entre Ryy y Rxy. Para ello, habría que calcular la significación de las comparaciones a través de la Z de Steiger (Steiger, 1980) para el caso de correlaciones superpuestas, o del estadístico ZPF (Steiger, 1980) para el caso de correlaciones no superpuestas. Dado el tedioso procedimiento de cálculo (108 comparaciones), nos limitamos a mostrar cuatro ocasiones en las que las correlaciones no pueden considerarse diferentes y cuatro en que sí lo son (Tabla 2).
Por tanto, según este criterio, los indicadores de ambas variables no cumplen de manera plena con uno de los criterios de validez discriminante exigidos.
Comparación entre la varianza compartida y la varianza extraída
Fornell y Larcker (1981) proponen que existe validez discriminante entre dos variables latentes, si la varianza compartida ( R2XY) entre pares de constructos es menor que la varianza extraída (pvc) para cada constructo individual. Este último indicador hace referencia a la cantidad de varianza capturada por el constructo en relación a la cantidad de varianza debida al error de medida:
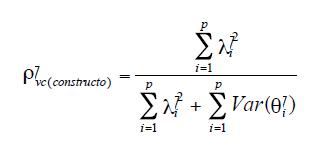
siendo λi el coeficiente de regresión estandarizado entre el constructo y cada indicador y, θi los errores de medida de cada indicador. En nuestro ejemplo, analizamos el modelo factorial confirmatorio(S-BX2: 25.60; gl: 13; p: 0.019) y, tras calcular el intervalo de confianza para el coeficiente de correlación múltiple usando el software R2 (Steiger & Fouladi, 1992), obtenemos que R2XY no puede considerarse diferente a pv(x) y Pvc(y) (Tabla 3), por lo que de nuevo no se cumple el criterio propuesto sobre la validez discriminante de las medidas.

Anderson & Gerbing (1988) proponen que si el intervalo de confianza al 95% para las correlaciones entre constructos no incluye el 1, se puede afirmar que existe validez discriminante. Este criterio es, por supuesto, mucho menos restrictivo que los anteriores y de muy fácil cumplimiento, ya que es bastante improbable que dos medidas correlacionen perfectamente, sobre todo cuando el tamaño de la muestra es grande. En el caso de nuestro ejemplo, la correlación entre las dos variables latentes es de 0.82, con un intervalo de confianza aproximado al 95% de (0.77; 0.86) Sin embargo, bajo nuestra perspectiva, este criterio no debe evaluarse teniendo en cuenta la "distancia estadística", sino la "distancia práctica"; es decir, considerar el tamaño del efecto frente a la significación estadística (Cohen, 1994). Podríamos considerar, de esta forma, dos alternativas de evaluación. La primera de ellas es tomar como referencia las convenciones de Cohen sobre la importancia de los tamaños de efecto. Para el caso de la correlación, Cohen (1988) propone que tamaños de efecto superiores a 0.5 se pueden considerar de gran relevancia. Por tanto, niveles tan altos de correlación indicarían una elevada semejanza de la variabilidad conjunta. La segunda opción es convertir la distribución asimétrica del coeficiente de correlación en simétrica, a través de la transformada de Fisher y calcular el percentil de la distribución que se corresponde con el límite superior del intervalo de confianza de la correlación. Esa operación da un percentil del 90,5%, lo que indica la pequeña distancia (menos de 10 puntos porcentuales) entre la perfecta correlación y la obtenida en la muestra y, por tanto, cuestiona la divergencia de las medidas.
Correlaciones en presencia de método común
Las covarianzas entre las medidas de las dos variables podrían ser explicadas por un efecto sistemático no deseado provocado por el método de recogida de información (Podsakoff, MacKenzie, Lee & Podsaoff, 2003); de este modo la correlación entre las variables latentes podría verse afectada una vez controlado el efecto método (Figura 2).
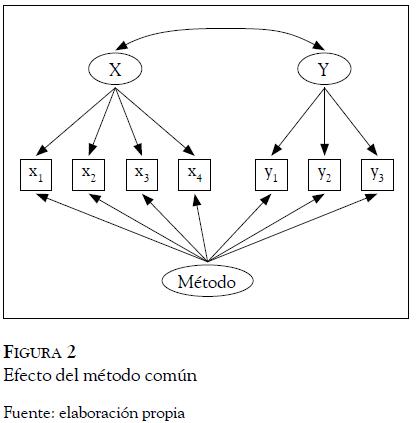
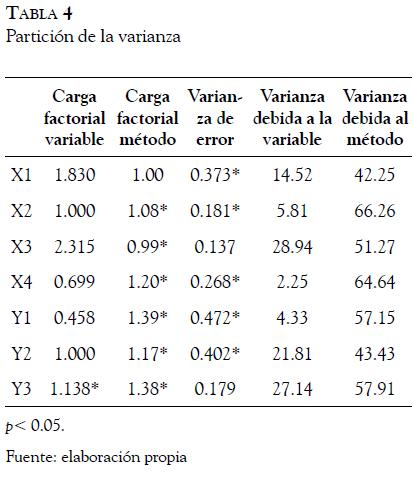
El análisis del modelo con la presencia de un efecto método latente mostró un ajuste adecuado: S-BX2: 7.088; gl: 6; p: 0.313. Como puede observarse en la Tabla 4, la mayor parte de la variación de los ítems se debe al efecto del método común, lo que hace cuestionar la validez de la información obtenida (sobre todo la fiabilidad de los indicadores). Es más, tras esta corrección por método, los resultados muestran que la correlación entre la calidad percibida y la lealtad es no significativa (0.07), por lo que ambas variables son completamente independientes, aunque el cálculo del valor contranulo de la correlación (Rosenthal & Rubin,1994) nos indica que la evidencia de que la correlación sea cero es la misma de que sea de 0.137, por lo cual podemos afirmar que a nivel de tamaño de efecto existe una pequeña asociación no explicada por el método común de medición. Por tanto, los resultados son totalmente contradictorios a los obtenidos en los epígrafes anteriores.
Diferencia entre valores medios
Por último, una fórmula simple es comparar los valores medios de las escalas de medida propuestas. Aunque dos variables estén muy relacionadas y medidas con el mismo método, pueden tener valores medios sustantivamente diferentes, lo que cuestionaría que las escalas de medida no fueran capaces de discriminar entre conceptos. Para ello se halló el tamaño de efecto d de Cohen (1977) usando las indicaciones metodológicas de Dunlap, Cortina, Vaslow y Burke (1996) para muestras relacionadas, y considerando el coeficiente de correlación proveniente del análisis factorial confirmatorio, con el fin de tener en cuenta el error de medida1. Los resultados (Tabla 5) muestran cómo se pueden darinterpretaciones muy diferentes de la similitud de las variables, atendiendo a si se considera o no los efectos del método de medición. Así, la alta correlación entre las variables latentes obtenida sin efectos del método produce un tamaño de efecto pequeño, mientras que esta magnitud es más que duplicada en caso contrario2. Evidentemente, esta disparidad de magnitudes puede llevar a interpretaciones bastante divergentes sobre la capacidad discriminante de las escalas.

1.Test del modelo causal
El análisis del modelo de investigación proporciona funciones de ajuste y parámetros estimados idénticos al modelo factorial confirmatorio (son modelos equivalentes) sin tener en cuenta el efecto método, por lo que se puede afirmar que la calidad ejerce una gran influencia sobre la lealtad (explica entre un 59 y un 74% de la variabilidad). Sin embargo, las dudas sobre la idoneidad de las escalas de medida propuestas son evidentes tras los análisis previos de validez, por lo que el investigador necesitaría una muy buena justificación para defender su propuesta.
2. La validez de contenido
La respuesta a los problemas derivados de los análisis estadísticos es la apropiada solidez teórica de las escalas propuestas. La validez de contenido hace referencia a la adecuada selección de las medidas de la variable de interés. Esa selección tiene que ser realizada en forma deductiva (Cronbach & Meehl, 1955) y requiere un profundo conocimiento de la materia en cuestión. Es decir, la definición de las variables del estudio condiciona la elección de sus indicadores en el cuestionario (Hayduk, 1996). Por tanto, si dos variables son conceptualmente diferentes y sus respectivas escalas de medición están justificadas suficientemente bien a nivel teórico, los análisis estadísticos basados en covarianzas o correlaciones no deben desembocar en conclusiones ambiguas. Si ambos conceptos son diferentes en su definición y las medidas propuestas son capaces de ser sensibles a las variaciones en esos conceptos, no importa la magnitud de la correlación entre ellos. Ésta es una de las aseveraciones que discuten perfectamente Borsboom et al. (2003), y que plantea un nuevo camino en la metodología sobre validación de escalas.
En el caso de nuestro ejemplo, la calidad es definida como la evaluación que realiza el consumidor sobre la excelencia o superioridad de un servicio (Zeithaml, 1988) y la lealtad es entendida como una actitud de favorabilidad hacia el servicio, que puede manifestarse en recomendar y hablar positivamente de él y tener la intención de mantenerse fiel a la compañía (Zeithaml et al., 1996). Ambos son conceptos claramente diferenciados, y las escalas propuestas reflejan teóricamente esa divergencia (Tabla 6). Además, los indicadores de la escala de lealtad hacen referencia a comportamientos futuros; es decir, en un tiempo t+i, en oposición a los indicadores de calidad donde la evaluación es realizada por el encuestado en un momento t y en cuyo juicio intervienen las experiencias en t-i. Esta condición es crucial a la hora del diseño de estudios causales con datos de corte transversal (Kline, 2005) y evita los problemas filosóficos y metodológicos derivados del planteamiento de relaciones no recursivas (Kaplan, Harik, & Hotchkiss, 2000; Kline, 2006).

3. Conclusión
Hemos tratado de mostrar con un ejemplo real, cómo los criterios más utilizados para analizar la validez discriminante de las escalas de medida propuestas para conceptos latentes, pueden llevar a conclusiones engañosas sobre la idoneidad de esas escalas. Operativamente los investigadores suelen realizar, muchas veces de forma mecánica, los análisis estadísticos para testar la validez discriminante una vez justificada la definición de los conceptas y elección de los indicadores. Además, resulta muy complicado encontrar (nosotros no lo hemos hecho) algún investigador que se replantee su estudio porque estadísticamente exista poca evidencia de divergencia entre escalas. Normalmente, se suele continuar la investigación reconociendo que las medidas tienen poca validez discriminante pero que otros criterios de validez y la propia definición de los conceptos justifican esa debilidad estadística. Pero entonces, ¿por qué se siguen realizando esos análisis estadísticos? Bajo nuestro punto de vista, no es necesario embarcarse en esos procedimientos estadísticos para defender la validez discriminante de las escalas, simplemente basta con la correcta delimitación de las variables.
Los problemas de sesgo por método común son una realidad en la investigación sobre comportamiento del consumidor, aunque se han propuesto diferentes procedimientos para paliar esa deficiencia (Podsakoff et al., 2003). Sin embargo, a nivel operativo el investigador no tiene muchas veces los recursos suficientes para implementar esos métodos y únicamente puede plantear diseños de investigación como el ilustrado en este artículo. A este respecto, tampoco los resultados estadísticos que devienen de tener en cuenta el método común deben interpretarse sin estar sujetos a crítica. En el ejemplo propuestoRxx ,Rxx, y Ryy y Rxy son muy similares.
Pero hay que plantearse en qué medida se debe ello al efecto del método común o a la propia relación real entre indicadores. No es muy lógico pensar que dos variables como la calidad y la lealtad, que teóricamente están en mayor o menor medida asociadas, no correlacionen casi nada cuando se tiene en cuenta los efectos del método común. De este modo, como argumentan Podsakoff et al. (2003), el investigador se enfrenta a un verdadero desafío metodológico a la hora de analizar si las asociaciones obtenidas entre las variables están contaminadas por el sesgo de método común. Procedimientos metodológicos avanzados basados en ecuaciones estructurales como las matrices multirasgo-multimétodo, el análisis factorial confirmatorio de segundo orden, el análisis factorial confirmatorio jerárquico, el modelo de primer orden múltiple informante múltiítem o el modelo de producto directo pueden ser herramientas que ayuden a tomar decisiones sobre la validez de constructo (Bagozzi et al., 1991), aunque están sujetos a diferentes limitaciones (Podsakoff et al., 2003).
Muchos de los inconvenientes estadísticos derivados de los procesos de validación de las escalas multiítem podrían en parte subsanarse, reduciendo el número de indicadores a uno o dos por concepto (Hayduk, 1996). Nuestra recomendación es que si el investigador está interesado en analizar relaciones causales, se plantee entonces la reducción de indicadores, y de esta forma se evitarían coeficientes de fiabilidad artificialmente engordados y disminuirían los problemas de presencia de efectos halo y el sesgo de método común. Además, habría muchas menos restricciones de covarianza por explicar y en consecuencia sería más fácil obtener modelos con buen ajuste.
Determinar la validez de las medidas propuestas sigue siendo un debate candente, en la literatura de las ciencias sociales. Como se indicó al comienzo, el investigador debe posicionarse por una de las diferentes corrientes metodológicas. Pero sea cual sea su decisión, creemos más oportuno justificar de forma teórica la divergencia entre escalas que representan conceptos y no apoyarse en procedimientos estadísticos, que, tal y como hemos mostrado, pueden desembocar en resultados contradictorios. Finalmente, las asunciones de linealidad y simetría entre las relaciones de este tipo de conceptos es muchas veces cuestionable (Mittal, Ross & Baldasare, 1998), lo que refuerza aún más la defensa de la justificación teórica frente a la estadística.
1 d=tc[2(1-r)/n]1/2donde tc es el valor t para la diferencia de medias pareadas y r el coeficiente de correlación
2 En este caso, el cálculo del valor medio de la escala como representativo del concepto latente quedaría bastante cuestionado, ya que la mayor parte de la varianza de esos indicadores es explicada por el efecto método y no por la variable latente, por lo que se podría afirmar que esos indicadores no son lo suficientemente adecuados.
Referencias
Anderson, J. C. & Gerbing, D. W. (1988). Structural Equation Modeling in Practice: A review and recommended two step approach. Psychological Bulletin, 103, 411-423. [ Links ]
Bagozzi, R. P, Yi, Y. & Phillips, L. W. (1991). Assessing construct validity in organizational research. Administrative Science Quarterly, 36, 421-458. [ Links ]
Borsboom, D., Mellenbergh, G. J. & Heerden van, J. (2003). The theoretical status of latent variables. Psychological Review, 110(2), 203-219. [ Links ]
Borsboom, D., Mellenbergh, G. J. & Heerden van, J. (2004). The concept of validity. Psychological Review, 111 (4), 1061-1071. [ Links ]
Brady, M. K. & Cronin, J. J. Jr. (2001). Some new thoughts on conceptualizing perceived service quality: A hierarchical approach. Journal of Marketing, 65, 34-49. [ Links ]
Brady, M. K., Cronin, J. J. & Brand, R. R. (2002). Performance only measurement of service quality: A replication and extension. Journal of Business Research, 55, 17-31. [ Links ]
Campbell, D. T & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait-multime-thod matrix. Psychological Bulletin, 56, 81-105. [ Links ]
Cattel, R. B. (1946). Description and measurement of personality. New York: World Book Company. [ Links ]
Cohen, J. (1977). Statistical power analysis for the behavioral sciences. New York: Academic Press. [ Links ]
Cohen, J. (1988). Statistical power analysis for the behavioural sciences (2nd ed.). Hillsdale, NJ: Lawrence Elbaum. [ Links ]
Cohen, J. (1994). The earth is round (p < .05). American Psychologist, 49(12), 997-1003. [ Links ]
Cook, T & Campbell, D. (1979). Quasiexperimentation: Design and analysis issues for field settings. Boston: Houghton Mifflin. [ Links ]
Cronbach, L. J. & Meehl, P E. (1955). Construct validity in psychological test. Psychological Bulletin, 52, 218-302. [ Links ]
Cronin, J. J., Brady, M. K. & Hult, G. T. M. (2000). Assessing the effects of quality, value, and customer satisfaction on consumer behavioral intentions in service environments. Journal of Retailing, 76(2), 193-218. [ Links ]
Dunlap, W. P., Cortina, J. M., Vaslow, J. B. & Burke, M. J. (1996). Meta analysis of experiments with matched groups or repeated measures designs. Psychological Methods, 1, 170-177. [ Links ]
Fornell, C. & Larcker, D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 27, 39-50. [ Links ]
Hancock, G. R. & Mueller, R. (2001). Rethinking construct reliability within latent variable systems. En R. Cudeck, S. du Toit & D. Sõrbom (Eds.), Structural equation modeling: Present and future A Festschrift in honor of Karl Jòreskog (pp. 195-216). Lincolnwood, IL: Scientific Software International. [ Links ]
Hayduk, L. A. (1996). LISREL Issues, Debates and Strategies. Baltimore: Johns Hopkins University Press. [ Links ]
Hayduk, L. A. & Glaser, D. N. (2000). Jiving the four-step, waltzing around factor analysis, and other serious fun. Structural Equation Modeling, 7, 1-35. [ Links ]
Kaplan, D., Harik, P. & Hotchkiss, L. (2000). Crosssectional estimation of dynamic structural equation models in disequilibrium. En R. Cudeck, S. du Toit & D. Sõrbom (Eds.), Structural equation modeling: Present and future-A Festschrift in honor of Karl Jòreskog (pp. 315-340). Lincolnwood, IL: Scientific Software International. [ Links ]
Kline, R. B. (2005). Principles and practice of structural equation modeling (2nd ed.). New York: Guildford Press. [ Links ]
Kline, R. B. (2006). Reverse arrow dynamics. En G. R. Hancock & R. O. Mueller (Eds.), A second course in structural equation modelling (pp. 43-68). Greenwich, CT: Information Age Publishing. [ Links ]
Markus, K. A. (1998). Science, measurement, and validity: Is completion of Samuel Messick's synthesis possible? Social Indicators Research, 45, 7-34. [ Links ]
Martínez, J. A., Flores, E. & Martínez, L. (2006, septiembre). La relación causal entre la calidad percibida, satisfacción e imagen corporativa en la determinación de la lealtad. XVIII Encuentro de Profesores Universitarios de Marketing, Almería, España. [ Links ]
Mittal, V., Ross Jr., W. T. & Baldasare, P M. (1998). The asymmetric impact of negative and positive attribute level performance on overall satisfaction and repurchase intentions. Journal of Marketing, 62, 33-47. [ Links ]
Nguyen N. & Leblanc G. (1998). The mediating role of corporate image on customers' retention decisions: An investigation in financial services. International Journal of Bank Marketing, 16(2), 52-65. [ Links ]
Olsen, S. O. (2002). Comparative Evaluation and the Relationship between Quality, Satisfaction, and Repurchase Loyalty. Journal of the Academy of Marketing Science, 30(3), 240-249. [ Links ]
Podsakoff, P M., MacKenzie, S. B., Lee, J. Y. & Podsakoff, N. P (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88, 879-903. [ Links ]
Rodríguez, S., Camarero C. & Gutiérrez J. (2002, septiembre). Lealtad y valor en la relación del consumidor. Una aplicación al caso de los servicios financieros. XIV Encuentro de Profesores Universitarios de Marketing. Granada, España. [ Links ]
Rosenthal, R. & Rubin, D. B. (1994). The counternull value of an effect size: A new statistic. Psychological Science, 5, 329-334. [ Links ]
Rosnow, R. L. & Rosenthal, R. (1996). Computing contrasts, effect sizes, and counternulls on other people's published data: General procedures for research consumers. Psychological Methods, 1, 331-340. [ Links ]
Steenkamp, J. B. E. M. & Trijp van, H. C. M. (1991).The Use of LISREL in Validating Marketing Constructs. International Journal of Research in Marketing, 8, 283-99. [ Links ]
Steiger, J. H. (1980). Test for Comparing Elements of a Correlation Matrix. Psychological Bulletin, 87, 245-281. [ Links ]
Steiger, J. H. & Fouladi, R. T. (1992). R2: A Computer program for interval estimation, power calculation, and hypothesis testing for the squared multiple correlation. Behavior Research Methods, Instruments, and Computers, 4, 581-582. [ Links ]
Teas, R. (1993). Expectations, performance evaluation, and consumer's perceptions of quality. Journal of Marketing, 57, 18-31. [ Links ]
Zeithaml, V. A. (1988). Consumer perceptions of price, quality, and value: A means end model and synthesis of evidence. Journal of Marketing, 52, 2-22. [ Links ]
Zeithaml, V., Berry, L. & Parasuraman, A. (1996). The behavioral consequences of service quality. Journal of Marketing, 60, 31-46. [ Links ]

