











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCTION
Foundation models are powerful AI (Artificial Intelligence) models trained on vast amounts of text data, enabling them to perform a wide range of language tasks, from sentiment analysis and question answering to text summarization and creative writing. These models can be fine-tuned for specific applications, making them versatile tools for various AI tasks, such as powering chatbots and language translation services.
Their applications can optimize processes, enhance efficiency and precision in data analysis, generate innovative ideas, and accelerate the pace of scientific discovery. Furthermore, foundation models can democratize research, facilitate global collaboration, and contribute to the development of new products and services. Some tools using these models are:
Flux - it is an electronic design tool that utilizes foundation models to assist users in creating and assembling electronic circuits. By employing advanced AI algorithms, Flux can streamline design processes, allowing users to draw schematics, list components, simulate circuits, and layout printed circuit boards (PCBs) with greater efficiency and accuracy. [65]
Lalal - it is an AI-driven tool specifically designed for music separation and vocal removal. It harnesses foundation models to accurately extract individual tracks from audio files without compromising sound quality. This capability is particularly valuable for musicians and producers who seek to manipulate specific elements of a track, such as vocals or instruments, for creative purposes. [66]
PhotoRoom - it employs foundation models to enhance its design capabilities by intelligently identifying subjects in images and separating them from backgrounds. This functionality allows users to create professional-quality images for various applications, such as marketing and e-commerce, by simplifying editing and improving the overall aesthetic of their visuals. [67]
Gemini - it is a large, sophisticated language model developed by Google AI, which exemplifies the capabilities of foundation models to generate and process text. Trained on an extensive dataset comprising 341 GB of text filtered from public social media conversations, Gemini utilizes advanced AI techniques to perform a variety of language-related tasks. These include generating coherent text, translating languages, and producing creative conversational-style content. [64].
The tools mentioned above show how foundation models can streamline complex processes, making advanced technology accessible to diverse users and fostering collaboration across different fields.
Therefore, we consider it relevant to extend information on foundation model applications and trends. The primary objective of this systematic review is to delineate innovative foundation model applications and the results they yield. Additionally, the review aims to highlight prevailing trends within the research landscape surrounding these models. By articulating these goals explicitly from the outset, we intend to provide a focused framework that guides readers exploring how foundation models are being utilized creatively across various domains and the implications of these applications for future research and development.
To streamline a systematic review, we used free software tools. We utilized PRISMA guidelines for methodological rigor and CADIMA platform to facilitate implementation and documentation. Bibliometrix, an R library, was used to conduct a meta-analysis of the results. The following sections detail a complete methodology of this systematic review.
2. MATERIALS AND METHODS
2.1 PRISMA Methodology
PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) is a minimum set of evidence-based elements that should be included when reporting a systematic review or a meta-analysis. It is generally concerned with reporting reviews evaluating the impact of interventions, but it can also be used for systematic reviews with goals other than evaluating interventions, such as determining etiology, prevalence, diagnosis, or prognosis. PRISMA seeks to assist authors to improve the quality of published systematic reviews and meta-analyses.
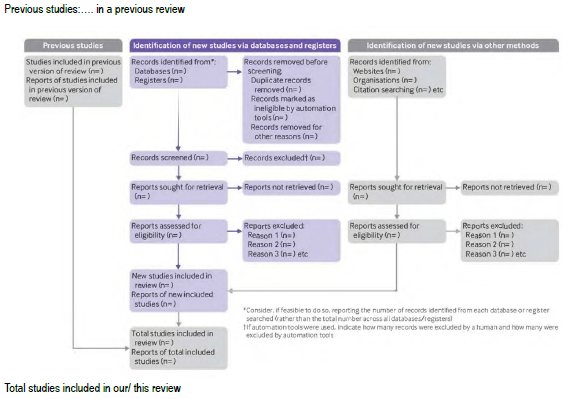
Figure 1 illustrates the three main phases of PRISMA approach. The first phase tracks studies found in earlier versions. In the second phase, we document new studies added from various databases, while also identifying and excluding any duplicates or studies that do not meet our eligibility criteria. The third phase typically allows adding recent studies from other sources. However, in this review, we only kept studies selected at the start , and did not add any new sources after applying eligibility criteria.
2.2 Data list
For this systematic review, this study identified and defined several variables related to included studies, and associated assumptions and simplifications. A list of these variables and their definitions are given below:
Population: The population of interest is Foundation Model-related studies, regardless of the application domain or specific methodology.
Intervention: This is not applicable, since this review does not focus on specific interventions, but rather on Foundation Model research topics and applications.
Comparison: Not applicable.
Outcomes: Various results are considered, like addressed research topics, proposed applications, methodologies used, and results obtained, among others.
2.3 Eligibility criteria
To ensure the quality of the studies included in our systematic review, rigorous inclusion and exclusion criteria were applied based on PRISMA methodology. Each study was evaluated based on its relevance, methodological rigor, and contribution to the field of foundation models. Additionally, CADIMA was a tool utilized to facilitate a review and allow reviewers to document their quality assessments. Although a formal quality scale was not used, studies that presented clear applicable results, and studies published in peer-reviewed journals, were prioritized. This approach ensures that selected studies not only meet relevance criteria but also adhere to acceptable research quality standards.
This review includes only studies published in English and focuses on applications across various fields of human society. By “different fields of human society,” we refer to a broad range of fields where foundation models are applied to benefit or interact with human activities. They include healthcare where models aid in diagnostics and personalized medicine, education, where they support tutoring and content generation, and business, where they enhance customer service and streamline operations. Additionally, foundation models impact entertainment, environmental science, finance, and government services, driving improvements in automation, decision-making, and personalized experiences. By examining these diverse fields, the review aims to capture a wider social and economic impact of foundation models. The full list of criteria that we used is shown in Tables 1 and 2.
Table 1 Inclusion criteria
| Criteria | Reasons to choose criteria |
|---|---|
| Publications from 2021 to 2024 | To have information regarding recent applications. |
| Papers including applications | To identify the main fields in which these models are being used. |
| Documents including the terms: GPT, BERT and GAI | Most of the applications of foundation models are related to Conversational Artificial Intelligence. |
| Papers with free PDF file access | To have access to all the research if necessary. |
| Journal articles and patents | To have relevant sources of information about academic and industrial fields. |
Source: own elaboration.
Table 2 Exclusion criterio
| Criteria | Reasons to choose criteria |
|---|---|
| Systematic Reviews | These papers do not provide information on patents or specific applications of these models. |
| Articles focused only on research | These papers generally report relevant advances in theory related to the development of new foundation models, but they do not directly impact the systematic review as they do not present applications. |
| Documents in pre-print status | These types of papers do not have a scientific review that can be considered relevant information. |
Source: own elaboration.
2.4 Information sources
In selecting the databases for our systematic review, we opted for Dimensions, The Lens, and SciSpace due to their unique features and advantages over more traditional databases like Scopus and Web of Science.
Dimensions offers a comprehensive collection of research outputs, including articles, patents, and funding information, which allows for a more holistic view of the research landscape. Its advanced search capabilities and integration of diverse data types facilitate a thorough exploration of foundation model applications. .
The Lens serves as a metadata aggregator that combines multiple content sets, providing equitable access to a wide range of scholarly publications and enabling researchers to discover and analyze knowledge efficiently. Its open-access model aligns with our goal of democratizing research and ensuring that our findings are accessible to a broader audience.
SciSpace, on the other hand, is a collaborative writing and research tool that streamlines research papers and theses managing. Its built-in tools for research-related tasks enhance the efficiency of our review process, making it easier to organize and analyze selected studies.
In contrast, while Scopus and Web of Science are well-established databases with extensive bibliometric data, they may not offer the same level of integration and accessibility for diverse research outputs. By choosing Dimensions, The Lens, and SciSpace, we aimed to leverage innovative tools that support our systematic review’s objectives and enhance the overall quality of our analysis.
2.5 Research
A comprehensive digital search strategy was designed to identify relevant studies in the mentioned databases. The search strategy was based on a combination of search terms related to foundation models, machine learning, and natural language processing. The search string used is shown below:
(foundation AND models) OR (large AND models) AND applications AND (education OR academic OR research)
To further ensure the reliability of our results, we implemented filters and limits tailored to our research criteria. Additionally, we utilized CADIMA to centralize and manage imported documents, which included a script to identify and eliminate duplicate entries.
While our primary focus was on an automated search process, we also conducted manual checks on the titles and abstracts of selected documents to confirm their relevance and adherence to our inclusion criteria. This combination of automated manual approaches helped mitigate search bias and enhance our systematic review’s overall accuracy.
3. RESULTS
In this systematic review, we focused on identifying and analyzing the diverse applications and methodologies associated with foundation models across various fields. We systematically gathered relevant studies from multiple databases, including Dimensions, SciSpace, and The Lens, resulting in a total of 1,161 manuscripts.
For data analysis, we used CADIMA to centralize and manage collected studies, allowing for the identification of duplicates and the application of eligibility criteria. Each selected study was then reviewed for its relevance to the foundation model applications , focusing on the methodologies used and reported outcomes. This approach enabled us to categorize our findings into key themes, highlighting the most significant applications in fields such as healthcare, education, and business.
3.1 CADIMA-assisted Semi-automated systematic review
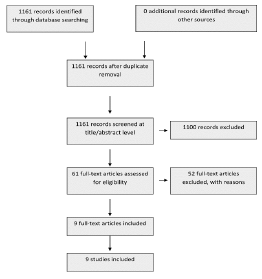
CADIMA provided us collected study organization and analysis. . The steps followed by CADIMA to generate the flow diagram shown in Figure 2 are as follows:
Data Importation: After selecting relevant databases and applying a defined search string, the search results are imported into CADIMA. This includes downloading the data in .ris format from each database. With the search string defined, 500 publications were found in Dimensions, 10 in SciSpace, and 651 documents in The Lens, of which 514 were mostly academic articles and the remaining 137 were patents.
Duplicate Identification: CADIMA automatically identifies duplicate documents across uploaded datasets. This step ensures that each study is only counted once, maintaining review process integrity. .
Eligibility Assessment: Reviewers assess the titles and abstracts of imported studies based on predefined eligibility criteria. CADIMA allows reviewers to mark documents as approved or rejected, providing an option to include comments for rejected studies.
Flow Diagram Generation: Once the review process is complete, CADIMA generates a flow diagram that visually summarizes the systematic review process. This diagram reflects key information, including the total number of studies initially loaded, the number of identified duplicates , and the final count of studies included in the review.
1161 records identified through database search
Source: own elaboration
Figure 2 Flow diagram generated by CADIMA from our systematic review process.
In Figure 2, the 1161 articles loaded into CADIMA from different data sources are displayed at the top, with this number preserved, as no duplicate documents were found. Following reviewers’ selection, 1100 documents were excluded for not meeting the initial selection criteria defined for this review. Subsequently, the diagram indicates that 52 studies were rejected because of unclear eligibility criteria display, absence of an uploaded abstract, or insufficient content in the abstract to include in the review. Reviewers assessed both eligibility criteria and the title and abstract of their assigned documents. Finally, the diagram at the bottom shows 9 studies included in this review.
The criteria taken into account to eliminate the 52 documents were firstly the abstract or summary. If any article did not contain it, CADIMA highlights it so that the reviewer can keep it or eliminate it manually. Secondly, keywords were considered, including LLMs, artificial intelligence, BERT, or GPT. If very few or no keywords appear in a document loaded in CADIMA, , reviewers may discard such works. All this was carried out in strict consideration of the eligibility criteria mentioned in Tables 1 and 2.
3.2 Semi-automated meta-analysis
Our meta-analysis offers several advantages, including increased precision, broader coverage, and resolution of conflicting findings. To conduct the meta-analysis, we employed the Bibliometrix R library, a powerful tool for bibliometric analysis. Bibliometrix enables researchers to analyze large datasets from various sources, such as Scopus, Web of Science, and PubMed. It provides functionalities for co-authorship, citation, and keyword analysis, aiding in the identification of research trends, key players, and emerging fields.
We utilized Bibliometrix to analyze search results, assess study relevance, map collaboration networks, and generate a word cloud. Figure 3 presents the word cloud, highlighting the most frequent terms, including “artificial intelligence,” “deep learning,” “machine learning,” and “neural network computing.”
An interesting observation from the Dimensions repository is the frequent occurrence of the word “human” in uploaded works. This is likely due to Bibliometrix’s analysis of titles, abstracts, and keywords, and the prevalence of discussions about AI replacing human tasks in reviewed articles.

Source: own elaboration
Figure 3 Word cloud generated by Bibliometrix from the Dimensions repository.
Figure 4 presents the word cloud generated from 651 papers sourced from The Lens. The similarity to the Dimensions word cloud can be attributed to a comparable number of documents and consistent filtering criteria. This suggests that during 2021-2023, a prevailing trend was a perception of AI as a potential human labor replacement in various tasks.

Figure 5 illustrates the co-authorship network derived from a Bibliometrix analysis. The network reveals a predominance of Asian and Anglo-Saxon surnames, along with six distinct international collaboration groups. The significant involvement of prestigious universities, government agencies, and research centers suggests that the primary focus of foundation model research lies in academic, engineering, and technological domains.
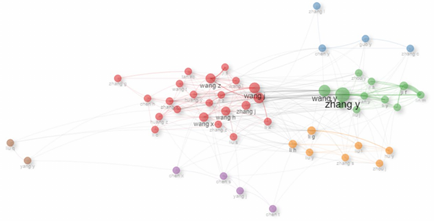
The meta-analysis reveals significant trends and collaborations within the foundation model field. These findings are crucial to understand a current research landscape and its implications for future advancements.
A notable trend is the increasing interdisciplinary collaboration among researchers from diverse fields, such as computer science, linguistics, and social sciences. This collaborative approach facilitates knowledge sharing, fosters innovation, and accelerates research progress.
Identified collaborations also highlight a growing network of researchers and institutions dedicated to advancing the field. These partnerships can enhance research quality by bringing together diverse expertise and perspectives.
The insights from this meta-analysis underscore the importance of interdisciplinary collaboration and network building in driving the development and application of foundation models. As the field continues to evolve, these factors will be crucial to maximize this technology’s societal impact.
3.3 Synthesis of results
Table 3 provides additional details on selected studies, including publication year and citation count. Notably, 70% of the studies were published in 2023, indicating a recent surge in foundation model research. Furthermore, the most highly cited studies often focus on medical applications, highlighting a significant healthcare potential of these models.
Table 3 Summary of citations.
| Title | Year | Citations |
|---|---|---|
| Decision Making Foundation Models : Problems, Methods, and Opportunities | 2023 | 77 |
| GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts | 2023 | 2 |
| Knowledge Acquired by Foundation Models | 2022 | 0 |
| Towards a geospatial artificial intelligence foundation model (vision paper) | 2022 | 24 |
| The Utility of Large Language Models and Generative AI for Education Research | 2023 | 2 |
| Revolutionizing Healthcare with Foundation AI Models | 2023 | 3 |
| Large-scale Foundation Model on Single-cell Transcriptomics | 2023 | 16 |
| Foundation models for generalist medical artificial intelligence | 2023 | 260 |
| Impending impacts of large medical education language models | 2023 | 23 |
Source: own elaboration.
Table 4 provides a relevant detailed overview of reviewed articles, including authors and a summary of key findings and applications.
Table 4 Review Outcomes
| Authors | Title | Application |
|---|---|---|
| Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans | Decision-Making Foundation Models: Problems, Methods, and Opportunities [60] | They explain the enhancing systems for dialogue, autonomous driving, healthcare, education, and robotics. |
| Dongbo Wang, Chang Liu, Si Shen, Liu Liu, Bin Li, Haotian Hu, Litao Lin, Xue Zhao, Xi-Yu Wang | GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts [54] | They developed GujiBERT and GujiGPT for ancient text processing and enhanced models with self-supervised classical text corpora training. |
| Gerhard Paaß and Sven Giesselbach | Knowledge Acquired by Foundation Models [17] | They mention that Foundation Models acquire syntactic, semantic, and logical knowledge through pretraining on vast text data, enabling them to excel in various benchmarks and tasks. |
| Gengchen Mai, Christine Cundy, Kristy Choi, Yingjie Hu, Ni Lao, Stefano Ermon | Towards a geospatial artificial intelligence foundation model (vision paper) [31] | They tested the performance of existing Large pre-trained Language Models (LLMs) on geospatial semantics tasks. |
| Andrew Katz, Umair Shakir, Benita Steinberg Chambers | The Utility of Large Language Models and Generative AI for Education Research [22] | They demonstrate the usefulness of NLP techniques and LLMs to automate an analysis of student engineering education research essays. |
| Hazrat Ali, Junaid Qadir, Tanvir Alam, Mowafa Househ, Zubair Shah | Revolutionizing Healthcare with Foundation AI Models [5] | Foundation AI models, such as ChatGPT, serve to interpret and complete reports. |
| Minsheng Hao et al | Large Scale Foundation Model on Single-cell Transcriptomics [19] | They developed a large-scale pre-trained model called scFoundation for single-cell transcriptomics. |
| Michael Moor et al | Generalist Medical Artificial Intelligence Foundation Models [36] | They propose a new paradigm for medical AI called generalist medical AI (GMAI). |
| Sangzin Ahn | Impending impacts of large language models on medical education [3] | It discusses the potential impacts of LLMs on medical education, including using them for prompt chaining and fact-checking methods, as well as creating of dynamic learning materials tailored to individual needs. |
Source: own elaboration.
As shown in Table 4, foundation models are closely related to other AI concepts, as Generative AI (GAI) and Large Language Models (LLMs). While GAI encompasses AI systems that generate new content, LLMs are specifically designed for language tasks. Foundation models, on the other hand, are versatile models trained on massive datasets that can be fine-tuned for various applications, including language tasks, image recognition, and more. In essence, foundation models serve as the foundational building blocks for many AI applications, including LLMs.
On the other hand, Figure 6 presents a conceptual map highlighting three key fields influenced by foundation models. These models excel at analyzing large datasets, enabling the extraction of valuable insights from various sources, including text, conversations, medical records, and environmental data.
A notable advancement in foundation models, such as GPT, is their ability to communicate effectively through Transformer-based architectures. These models, often categorized as Large Language Models (LLMs), can process and understand long-term context, leading to more coherent contextually relevant text generation. Other prominent LLM architectures include BERT (Bidirectional Encoder Representations from Transformers).
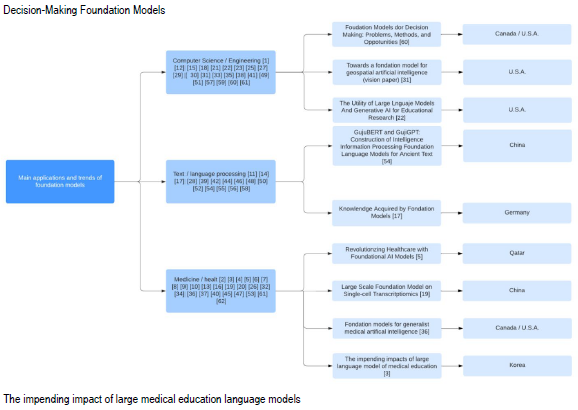
Foundation models have impacted various fields significantly, including education and healthcare. In education, these models can enhance learning through techniques like providing hints, generating responses, and learning from rewards. [14,15,22,57,62]. In healthcare, foundation models, such as ChatGPT, can assist with medical education, creating training material , and medical research by analyzing complex medical data. [7,10,16,19,26,32,34,45,47,53,63] Additionally, they can aid in clinical decisionmaking, diagnosis, and note-taking. [6,8,9,20,40] A promising concept in medical AI is Generalist Medical AI (GMAI), which leverages chatbots to analyze large datasets and provide timely medical insights. [4,5,13,36,37] Large Language Models (LLMs) are also transforming medical education by enhancing learning methods, aiding in clinical reasoning skill development, and revolutionizing evaluation methods. [2,3] While foundation models have made significant strides in various fields, their impact in certain fields, such as geospatial AI and ancient text processing, remains limited. Despite ongoing research, the application of foundation models in geospatial AI has not yet reached the level of integration seen in healthcare or education. For instance, it [31] received only 24 citations, suggesting limited engagement with this topic. Similarly, while specialized models like GujiBERT and GujiGPT have shown promise in ancient text processing [54], their overall impact is minimal, as indicated by the 2 citations received in 2023. These examples highlight that while foundation models are a powerful tool, their application in specific domains requires further exploration and development.
4. CONCLUSIONS
While foundation models have significant potential, their adoption varies across different fields. The medical and health sector, followed by computer science, leads in terms of research and development. Other fields, as geospatial science, engineering, and education, have shown slower adoption. While our findings indicated higher citation rates in the medical field, it is important to consider the broader context. The information presented in Figures 3 and 4 provides a more nuanced understanding of the varying impacts of foundation models across different research fields.
It is important to note that foundation models, generative AI, and large language models are interconnected, but they are distinct concepts. Foundation models are versatile AI models that can be fine-tuned for various tasks, including language generation. Generative AI focuses on creating new content, while large language models excel in understanding and generating text.
To streamline our systematic review process, we employed CADIMA to efficiently manage and filter a large number of publications. CADIMA’s flow diagrams visually represented our selection process, helping us narrow down to 9 relevant studies from an initial pool of 1,161. Bibliometrix was utilized to conduct a meta-analysis of the selected studies, providing insights into citation patterns, co-authorship networks, and keyword analysis. This analysis highlighted the strong global interest in foundation models, particularly in healthcare applications. We will explain in the revised document how these tools directly contributed to our conclusions, emphasizing the connection between our methodology and findings. However, the use of these powerful tools raises ethical concerns, including bias, misinformation, and potential loss of human control. Responsible development and usage are crucial to mitigate these risks.
Finally, derived from the findings of our systematic review, it is important to point out the need to take measures to mitigate potential risks, like generating biased or false information and overreliance on technology. It is essential to develop and manage foundation models responsibly. Ethical considerations must be prioritized to ensure that these models are used in a beneficial and equitable manner. On the other hand, industry and academia are actively addressing challenges like bias, misinformation, and human oversight in AI. To mitigate bias, Google has established AI principles emphasizing fairness and accountability, while Microsoft has developed a “Fairness Toolkit” for developers. In academia, frameworks to promote transparency in algorithmic decision-making have been proposed . Additionally, institutions like Stanford University are exploring ways to integrate human judgment into AI systems, especially in sensitive areas.

