










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería y Desarrollo
Print version ISSN 0122-3461On-line version ISSN 2145-9371
Ing. Desarro. no.23 Barranquilla June/Dec. 2008
Análisis multivariado aplicando componentes principales al caso de los desplazados
Multivariated analysis playing main components to homeless people case
Ángel León González1, Humberto Llinás Solano2, Jorge Tilano3
1 PhD. Gestión Industrial. Grupo de Investigaciones Productividad y Competitividad, Universidad del Norte. Profesor asociado de la Universidad del Norte. agonzale@uninorte.edu.co
2 Dr. rer. nat. Estadística. Grupo de Investigaciones en Estadística e Investigación Operativa (GEIO), Universidad del Norte. Profesor asociado de la Universidad del Norte. hllinas@uninorte.edu.co
3 Esp. Estadística. Grupo de Investigaciones en Estadística e Investigación Operativa (GEIO), Universidad del Norte. Profesor catedrático de la Universidad del Norte. jtilano@uninorte.edu.co
Dirección: Angel León González, Departamento de Ingeniería Industrial, Bloque B, segundo piso, Universidad del Norte Km 5, antigua vía a Puerto Colombia.
Fecha de recepción: 5 de febrero de 2008
Fecha de aceptación: 25 de abril de 2008
Resumen
La complejidad de los fenómenos de las ciencias en general hace que los investigadores se vean obligados a enfrentarse a problemas donde intervienen múltiples variables y grandes volúmenes de datos que requieren conceptos avanzados y herramientas para su tratamiento e interpretación integral. Por esta causa, desde hace mucho tiempo se han desarrollado las técnicas multivariadas, pero sólo con la evolución de los computadores y diversos paquetes de software que procesan amplios conjuntos de datos ha llegado a ser notoria la potencia de la estadística multivariada. Se ha tomado el problema del desplazamiento de personas del campo a la ciudad para consolidar el concepto y la aplicación de la técnica de componentes principales (ACP). En este artículo se presenta esta técnica dada su utilidad como paso previo a todos los análisis multivariados que se requiera aplicar. Para el estudio del ACP primero se desarrollan los conceptos fundamentales del álgebra matricial, para luego simular una situación problemática escogida como una forma de llevar a la práctica el marco teórico referente a la técnica objeto del artículo. Por otro lado, el desarrollo de la simulación mediante esta técnica conlleva el uso de otros conceptos relativos al ACP, los cuales se explican e interpretan a partir del análisis de los resultados obtenidos en los diferentes procesos. En el análisis de los resultados se ha concluido que, a pesar de que el gobierno está tomando medidas para mejorar el bienestar de los desplazados, que es la situación escogida, todavía faltan mayores esfuerzos que conlleven a una solución integral de esta problemática.
Palabras claves: Componentes principales, autovalores, autovectores, matriz de componentes, comunalidad.
Abstract
In general, the complexity of phenomena in sciences makes researchers feel obligated to face problems where multiple variables and big volumes of information are presented. Those problems require advanced in order to decipher the concepts and tools for its treatment. For this reason, multivariate techniques were developed long ago, but only the computer evolution and several software packages have caused the power of the multivariate statistics to become important. The problem of the displacement of people from the countryside to cities is a reason for consolidating the concepts and the principal component application technique (PCA). This article explains PCA technique while prefacing the applyed multivariate analysis. In order to study ACP, one first needs the fundamentals of matrix algebra concepts. When developed and then applied in a specific simulation, there is a way to carry and practice the theory related to the technique treated in this article. On the other hand, the simulation development using this technique needs to use other concepts associated with PCA which are explained and interpreted from the analysis of results obtained in the different processes. The analysis of this article points to one conclusion. In spite of the government taking a role for the displaced persons well-being, there is an absence of major efforts that leads to these problematic solutions.
Keywords: Principal components, eigenvalue, eigenvector, matriz components, comunality.
INTRODUCCIÓN
La humanidad en su evolución necesita conocer los fenómenos que están a su alrededor porque éstos afectan su desarrollo dentro de todos los ámbitos (fenómenos de tipo social, económico, tecnológico, físico, etc.). Este conocimiento se logra mediante la construcción de modelos que puedan reproducir y explicar dichos fenómenos. Por tal motivo, es necesario que los profesionales, directivos e investigadores en las distintas áreas del saber estén familiarizados con las herramientas necesarias para la construcción y adecuación de modelos. Una de las herramientas más importantes para llevar a cabo este objetivo es la estadística, y en particular, muy a menudo, la estadística multivariada.
Según Peña [1] y Dallas [2] existen diversas definiciones acerca de las técnicas de análisis de datos multivariados, pero los dos coinciden en a conceptualizarla como "una herramienta que tiene como objetivo principal resumir grandes cantidades de datos por medio de pocos parámetros (simplificación), además busca encontrar relaciones entre:
Variables de respuesta
Unidades experimentales
Variables de respuesta y unidades experimentales 1
Según Peña [1], la mayoría de problemas que requieren la aplicación de la estadística exigen el tratamiento de muchos factores o variables y que por esto las técnicas del análisis de datos multivariados constituyen una herramienta poderosa para la toma de decisiones en las diferentes disciplinas, pues dan respuesta a necesidades palpables y plenamente identificables. Según Pérez [3], se puede observar que cuando existen muchas variables es posible que parte importante de la información sea redundante, en cuyo caso es necesario eliminar el exceso y dejar sólo variables que tengan representatividad dentro del conjunto. Esto se consigue con la aplicación de las técnicas multivariantes de reducción de la dimensión: análisis de componentes principales, factorial, correspondencias, escalamiento óptimo, homogeneidades, análisis conjunto.
Las técnicas multivariadas más utilizadas en el análisis de datos son: análisis de componentes principales; análisis factorial; análisis de clasificación entre los que se encuentran: discriminante, regresión logística y clúster; análisis multivariado de la varianza, y análisis de variables canónicas.
Con este artículo se desean integrar conocimientos teóricos y prácticos a través de la comprensión de las componentes principales, como una de las técnicas estadísticas que permiten estudiar la información que se dispone antes de entrar en el uso de los otros métodos que abordan el análisis de datos multivariados.
Por ser tan amplio el tema, este artículo sólo trata del análisis de componentes principales debido a su importancia dentro del desarrollo de las diversas técnicas de análisis de datos multivariados.
1. COMPONENTES PRINCIPALES
Siguiendo a autores como Peña [1] y Bramardi[4], el análisis de componentes principales (ACP) es una técnica estadística propuesta a principios del siglo XX por Hotelling (1933) quien se basó en los trabajos de Karl Pearson (1901) y en las investigaciones sobre ajustes ortogonales por mínimos cuadrados. Interpretando la definición de diversos autores, se puede decir que el ACP es una técnica estadística de análisis multivariado que permite seccionar la información contenida en un conjunto de p variables de interés en m nuevas variables independientes. Cada una explica una parte específica de la información y mediante combinación lineal de las variables originales otorgan la posibilidad de resumir la información, total en pocas componentes que reducen la dimensión del problema.
La mayor aplicación del ACP está centrada en la de reducción de la dimensión del espacio de los datos, en hacer descripciones sintéticas y en simplificar el problema que se estudia.
Para Peña [1], el ACP tiene una utilidad doble; por un lado, permite hacer representaciones de los datos originales en un espacio de dimensión pequeña y, por el otro, transformar las variables originales correladas en nuevas variables incorreladas que puedan ser interpretadas.
El ACP también se emplea con frecuencia cuando se desea dividir las unidades experimentales en subgrupos de acuerdo con la similaridad de los mismos. Igualmente, es útil para transformar un conjunto de variables respuesta correlacionadas en un conjunto de componentes no correlacionados, bajo el criterio de máxima variabilidad acumulada y, por tanto, de mínima pérdida de información.
Otra aplicación es el cribado, el cual permite el seguimiento sobre los componentes principales obtenidos para comprobar hipótesis establecidas en un estudio de análisis de datos multivariados y para identificar datos atípicos en el conjunto de datos.
De igual manera, García y Gil [5] afirman que el ACP es un criterio fundamental para hacer conjeturas sobre el numero de factores que se deben determinar en el análisis factorial y para probar si, en realidad, un grupo de variables p > 2 cae dentro de un espacio de dos o tres dimensiones que permita ser observado dentro del análisis de clúster.
Pérez [2] anota que el análisis de componentes principales es en muchas ocasiones un paso previo a otros análisis, en los que se sustituye el conjunto de variables originales por las componentes obtenidas. Éste siempre debe hacerse cuando se quiera obtener modelos en los que sea necesario el uso de las variables originales como explicativas para tratar con algunos problemas presentes, como la independencia.
Según Gil [6], en el análisis discriminante cuando se tienen menos observaciones que variables y es difícil encontrar nuevas observaciones, el ACP es útil para determinar un menor número de variables que resuma la máxima variabilidad de las originales y con las cuales se pueda construir la matriz de varianza-covarianza, de tal forma que sea invertible y permita elaborar una regla de discriminación necesaria para clasificar nuevas observaciones.
Finalmente, el ACP se usa como base para determinar si ocurre multicolinealidad entre variables predictoras en el análisis de regresión múltiple. Entendiéndose como multicolinealidad cuando en dos o más variables existe redundancia; esto es, la información de una o más variables ya está explicada en otra(s) variable(s) (véase por ejemplo, Peña [1], Dallas [2]).
2. NOTACIONES Y SÍMBOLOS
Siguiendo la simbología común de diversos autores, a continuación se presentan conceptos básicos del álgebra de matrices que son necesarios en el ACP.
Matriz de variable respuesta
La base para la utilización del ACP es la estructura de correlación (interdependencia) entre las variables cuantitativas definidas en una población, en donde cada individuo queda definido en términos de las mismas. La matriz de variable respuesta de doble entrada X está compuesta por filas que representan las unidades experimentales Ir, r=1,2,....,n y las columnas, por las variables Xj, j= 1,2,...., p, como se muestra a continuación:

Vectores de datos
Con el fin de tener un lenguaje común en los procesos de ACP, en adelante, los vectores siempre serán columnas a o X, etc., y la transpuesta de un vector cualquiera, por ejemplo a, se simboliza por a'.
Vectores de medias y matrices de varianza covarianza
La media de un vector X de variables aleatorias se denota por µ, definido por:

La matriz de covarianza de X se denota por Σ, donde:
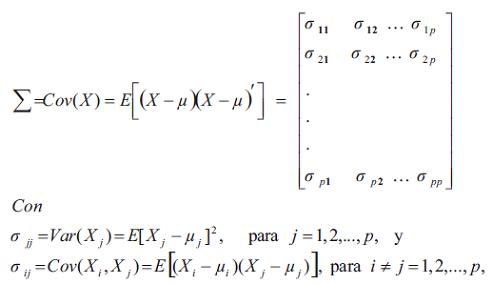
Correlación y matriz de correlación
El coeficiente de correlación entre Xi y Xj se denota por 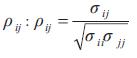
La matriz de correlación para un vector aleatorio X se denota por :
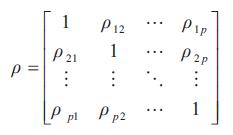
Matrices ortogonales unitarias
Dentro del álgebra de matrices las rotaciones de un espacio vectorial son transformaciones lineales del espacio vectorial sobre sí mismo y están asociadas con matrices cuadradas, unitarias y ortogonales. Una matriz de éstas, Q, tiene tantas filas y columnas como sea la dimensión del espacio. Sus columnas son vectores unitarios (es decir, de longitud igual a la unidad) y tiene la particularidad de que al ser multiplicada por su transpuesta produce la matriz unidad. En otras palabras, Q-1 = Q'. En cambio, las traslaciones no son transformaciones lineales pero tienen la propiedad de no modificar la variabilidad de la nube de puntos. Es decir, las varianzas y covarianzas en la nube son las mismas antes y después de una traslación. Lo expuesto anteriormente, junto con algunas propiedades de la matriz de varianzas covarianzas Σ, constituye las bases sobre las cuales descansa la técnica de componentes principales.
3. PLANTEAMIENTO Y SOLUCIÓN DEL PROBLEMA DE LOS COMPONENTES PRINCIPALES
El ACP es una técnica descriptiva; sin embargo, no niega la posibilidad de que también pueda ser utilizado con fines de inferencia. Por otra parte, las aplicaciones del ACP son numerosas y entre ellas se pueden citar la clasificación de individuos, la comparación de poblaciones, la estratificación multivariada, entre otras. En el ACP se maneja un número p (p ≥ 2) de variables numéricas. Si cada variable se representa sobre un eje, se necesitaría un sistema de coordenadas rectangulares con p ejes perpendiculares entre sí para ubicar las coordenadas de los puntos y poderlos dibujar. Cuando p ≥ 4, para el ser humano es imposible hacer la representación gráfica. En estos casos el ACP permite buscar un nuevo sistema de coordenadas con origen en el centro de gravedad de la nube de puntos, de tal manera que el primer eje del nuevo sistema F1 recoja la mayor cantidad posible de variación; el segundo eje F2, la mayor cantidad posible entre la variación restante; el tercer eje F3 la mayor cantidad posible entre la variación que queda después de las dos anteriores y así sucesivamente. Las Figuras 1 y 2 permiten ver la representación gráfica de dos componentes.

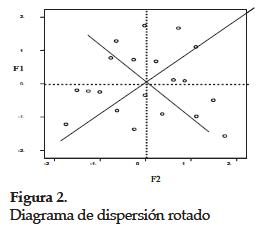
Observando las figuras anteriores se puede concluir que el sistema de coordenadas de la derecha se logra después de dos movimientos de la nube de puntos: el primer movimiento corresponde a una traslación que permite situar el nuevo origen en el centro de gravedad de la nube. El segundo movimiento que se hace sobre la nube centrada es una rotación, usando el centro de gravedad como punto pivote. La rotación permite ubicar los ejes en dirección horizontal y vertical como se observa en la Figura 2. Esto indica que se desea encontrar un nuevo sistema de coordenadas que represente lo mejor posible los datos sin causar distorsiones, cuya forma de problema es equivalente a encontrar las nuevas variables del espacio reducido con una mínima pérdida de la información, y también a buscar un elipsoide de concentración que permita encerrar los datos originales.
Cuando ya se ha definido el problema es factible abordarlo. Según Peña [1], páginas 73-74, la matriz de varianza covarianza Σ es definida positiva, es decir, la forma cuadrática asociada a ella tiene todas sus raíces positivas. Lo anterior hace que esta matriz tenga p valores propios reales y diferentes, lo cual garantiza que sea diagonalizable. En términos matemáticos significa que existe una matriz A ortogonal, tal que Σ = ADA-1 donde D es la matriz diagonal formada por los valores propios de Σ, denotados por λ1, λ2,..., λp. Es posible reordenar de acuerdo con su magnitud los valores propios de Σ de tal manera que λ1 > λ2 >...> λp. Esto simplemente se traduce en un reordenamiento de las columnas de la matriz A de manera que la primera sea el vector propio o componente asociado con λ1, la segunda sea un vector propio asociado con λ2 y así sucesivamente. En particular, dichas columnas pueden estar formadas por vectores propios normalizados, es decir, perpendiculares entre sí y de longitud igual a la unidad. De esta manera se construye una matriz que produce la rotación deseada ya que, como puede probarse, el primer vector propio 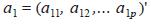 apunta en la dirección de máxima variabilidad de la nube centrada. Esta dirección se llama primera dirección principal. El segundo vector propio
apunta en la dirección de máxima variabilidad de la nube centrada. Esta dirección se llama primera dirección principal. El segundo vector propio 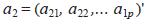 apunta en la siguiente dirección de máxima variabilidad de la nube centrada, llamada segunda dirección principal y así sucesivamente.
apunta en la siguiente dirección de máxima variabilidad de la nube centrada, llamada segunda dirección principal y así sucesivamente.
Una vez resuelto el problema de la rotación, bastará multiplicar la vac c c riable centrada Xc = X - µ = ( X1 , X2 ,..., Xp ) por la matriz de rotación A para obtener la nueva variable, Y = (Y1, Y2 ,... Yp ) llamada variable de componentes principales. Cada componente Yi del vector aleatorio Y se llama una componente principal. Evidentemente se cumple que Yj = aj1 Xc + aj2 Xc2 ,..., + ajp Xcp , es decir, cada componente principal es 1 una combinación lineal de las variables originales centradas. Para hacer el análisis de los autovalores se necesita desarrollar los conceptos y las propiedades que se verifican. La traza de Σ, por ser la suma de las varianzas de las variables originales Yi recibe el nombre de varianza total, resulta claro que traza(Σ) = traza (ADA-1) = Σ λi. Se puede probar además que V(Yi ) = λi para i = 1,2..., p y que Cov(Yi , Yj) = 0, con i â j. Esto implica varios aspectos, a saber: La varianza total es igual a la suma de los valores propios de λi e igual a la suma de las varianzas de las componentes principales. Es decir, la varianza total es la misma con las variables originales que con las variables transformadas Yi. Las componentes principales son variables aleatorias no correlacionadas entre sí, obtenidas mediante la transformación lineal del vector de las variables originales centradas por la matriz de autovectores. Esto es:
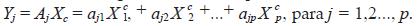
Resulta claro que E(Yj) = 0 para j = 1,2..., p. Si todas las variables originales Xi son normales, entonces todas las componentes principales son normales. Como puede deducirse de lo anterior, la varianza total se descompone en un número finito de partes disjuntas λj de tamaños cada vez menores, lo que en la práctica proporciona un mecanismo para estudiar la posibilidad de reducir la dimensionalidad de representación de las p variables originales a m. En efecto, si despreciamos las últimas p - m componentes principales, las primeras m tendrán una tasa de representatividad igual a  originales. Muchas veces este porcentaje es bastante alto con un pequeño valor de m lo que se traduce en una alta representatividad en un espacio de pocas dimensiones.
originales. Muchas veces este porcentaje es bastante alto con un pequeño valor de m lo que se traduce en una alta representatividad en un espacio de pocas dimensiones.
En la práctica resulta importante el caso m = 2 ya que si, se obtuviera una tasa de representatividad alta, se habría logrado describir el problema sobre un plano con una pequeña pérdida de información. Por supuesto que si la reducción a un espacio de dos dimensiones conlleva una alta pérdida de representatividad no se habrá logrado un éxito y las técnicas que aquí se propondrán para visualización de individuos y variables no serán muy buenas.
La ecuación Y = AXc implica Xc = A-1Y = AtY lo que permite obtener las variables centradas originales como combinaciones lineales de las componentes principales. Esto en particular va a permitir representar gráficamente las variables originales centradas dentro del espacio de componentes principales, llamado espacio factorial, como puntos cuyas coordenadas son los coeficientes de Xi en la combinación lineal correspondiente.
Teniendo en cuenta que sólo las componentes principales iniciales llevan la mayor parte de la representatividad se podrá reducir el espacio factorial a dos o tres dimensiones, lo que lleva a una representación de las variables originales como vectores sobre un plano (plano factorial) o sobre un espacio tridimensional. La representación sobre el plano factorial Y1Y2 es particularmente útil pues permite visualizar relaciones de correlación entre las variables originales y de éstas con los ejes factoriales, lo que rápidamente da una idea de cómo y en cuánto contribuye cada variable a la conformación de los primeros componentes y qué tan fuertes son las dependencias entre las diferentes variables y los componentes. La ausencia de correlación se traduce en vectores que tienden a formar ángulos rectos. Esto sugiere que la correlación entre dos variables se mida a través del coseno del ángulo que ellas forman. Igualmente es factible realizar una represtación de individuos, es decir, una proyección de la nube de individuos sobre el plano factorial Y1Y2, el cual reúne la mayor representatividad de VT. Las correlaciones entre las variables originales y los factores se conocen comúnmente como cargas factoriales, dadas en una matriz de carga C de orden pxm. Los elementos de la matriz C están dados por:
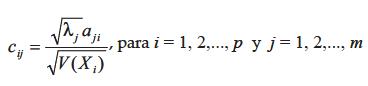
Criterios para determinación del número de componentes principales
Es importante saber el mecanismo para determinar el número de componentes principales (CP) que recojan la mayor variabilidad de las variables originales estandarizadas. Hay varios criterios para la selección de CP, los dos más extendidos son el criterio SCREEN y el de los porcentajes acumulados de varianza.
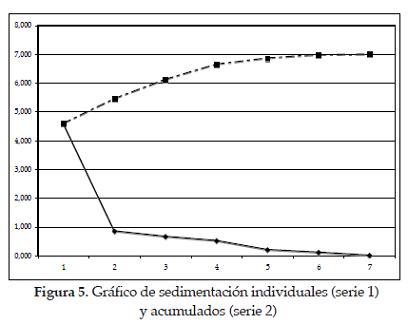
Criterio 1: Según Dallas [3], en este criterio se utiliza la gráfica screen de los eigenvalores, la cual se construye tomando como eje X el número de eigenvalor y en el eje Y los valores propios, como se muestra en la figura siguiente.
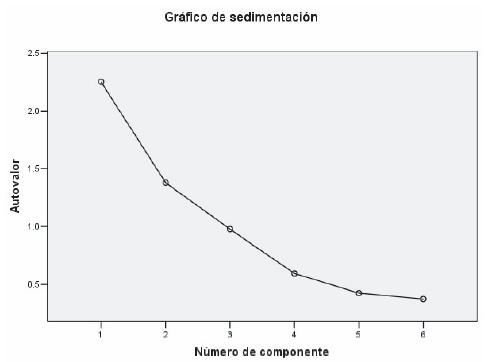
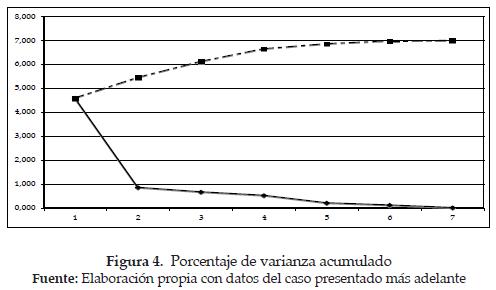
Criterio 2. Otro criterio, quizás más natural, consiste en retener tantos factores como sean necesarios para lograr un alto porcentaje de explicación de la varianza total. Para ello se usan los porcentajes acumulados de los valores propios con base en la varianza total del problema, junto con un criterio personal acerca de qué se considera un buen porcentaje de explicación. Los diversos investigadores sugieren que para datos tipo de laboratorio puede ser fácil explicar más del 95% de la variabilidad total con sólo dos o tres componentes principales y, que para datos de tipos de personas, negocios, estudios de mercados, etc., puede ser entre el 70% y el 75% de la variación total.
ACP normado Hay varios criterios. Tal vez los dos más extendidos son el criterio de Kaiser, según el cual se deben retener tantos factores como valores propios de la matriz Σ estén por encima del promedio VT/p y los diagramas de CATTELL [7]. Siendo VT : variabilidad total y p el número de variables originales. Todo lo mencionado anteriormente tiene un sentido geométrico y matemático muy claro pero en la práctica tiene un problema de interpretación. Por un lado, no tiene significado la combinación de variables cuyas naturalezas son diferente; por ejemplo las variables que representan la edad, ingreso, peso, etc., para la creación de un único factor. Por otra parte, el peso de cada variable original, traducido fundamentalmente en variabilidad, puede ser muy diferente para cada variable. Una variable muy dispersa puede contribuir enormemente a la varianza total mientras que una variable más homogénea contribuye menos. Esto finalmente determina la participación de cada variable en la conformación de un factor. Las inquietudes anteriores tienen una solución: Realizar ACP con variables originales estandarizadas. Esto resuelve los dos problemas: De una parte, los valores de las variables estandarizadas son adimensionales, son simplemente números sin unidades en los cuales expresan las mediciones. De otra parte, la estandarización lleva todas las escalas de medida a una escala común de media 0 y varianza 1, con lo cual se elimina el problema de medición y variabilidad diferente de las variables originales. El ACP realizado con variables originales estandarizadas se llama ACP normado. Más adelante, en el ejemplo se puede ver que el ACP normado equivale al ACP corriente pero partiendo de la matriz de correlaciones R en vez de la matriz de varianzas covarianzas Σ.
Resulta claro que el ACP normado debe ser la técnica a seguir en cualquier caso, a menos que se quieran explorar algunas otras posibilidades de tipo teórico o que se tengan variables muy similares tanto en su naturaleza como en su escala de medida.
ACP a partir de una muestra
Finalmente, la matriz Σ por ser desconocida no puede ser usada directamente en los cálculos. En la práctica, se usa la matriz de varianzascovarianzas S, estimada a partir de una muestra observada de n individuos. Esta matriz constituye una estimación de Σ y, por tanto, los resultados obtenidos con ella constituyen estimaciones de los correspondientes valores poblacionales. Se debe saber, sin embargo, que será necesaria una muestra aleatoria cuyo tamaño n sea mayor que el número p de variables consideradas.
De lo dicho anteriormente se obtienen algunas conclusiones:
- El ACP es una técnica que transforma ciertas variables correlacionadas en otras incorrelacionadas, de media cero, que pueden escribirse como combinaciones lineales de las primeras y que se llaman componentes principales, las cuales pueden ordenarse por la magnitud de su varianza, la cual está dada por un valor propio de la matriz.
- Las primeras y componentes principales bastan para describir en alto porcentaje la variabilidad total de las variables originales.
- Con frecuencia y vale 2 o 3, siendo el primero de ellos el caso más deseable.
- Cuando el porcentaje de variabilidad explicado por dos componentes principales es alto (70%) se puede realizar una representación gráfica de las variables originales y de los individuos de la muestra (mapas perceptuales) que muestran algunas relaciones de correlación o semejanza entre ellos.
4. UN CASO DE APLICACIÓN DEL ANÁLISIS DE COMPONENTES PRINCIPALES
Descripción del problema
Según la ley 387 de 1997, "Es desplazado toda persona que se ha visto forzada a migrar dentro del territorio nacional abandonando su localidad de residencia o actividades económicas habituales, porque su vida, su integridad física, su seguridad o libertad personales han sido vulneradas o se encuentran directamente amenazadas, con ocasión de cualquiera de las siguientes situaciones: Conflicto armado interno, disturbios y tensiones interiores, violencia generalizada, violaciones masivas de los Derechos Humanos, infracciones al Derecho Internacional Humanitario u otras circunstancias emanadas de las situaciones anteriores que puedan alterar o alteren drásticamente el orden público"2.
Nuestro problema está basado en la lectura de la situación de los desplazados en un municipio de Colombia, donde se concentran el mayor porcentaje de estas personas que huyen de la violencia y el temor que generan las fuerzas oscuras en los campos del país.
Mediante entrevistas a expertos, a los mismos desplazados y la observación directa, se ha podido determinar problemas de diferente índole, tales como: la ubicación desordenada de los desplazados que han incomodado hasta llegar a roces con el personal que habita en los diferentes barrios, hacinamiento, inseguridad, y otros problemas de orden público.
Para analizar más profundamente esta problemática, los investigadores han recopilado información de fuentes (como, por ejemplo, el ministerio de Protección Social, el Sistema de Información de Hogares Desplazados por Violencia en Colombia - SISDES; el boletín sobre "Niños desplazados" editado por Codhes el 25 de octubre de 1997, entre otros) relativa a la población desplazada, con el propósito de contribuir desde la academia a ver técnicamente el problema con la ayuda del análisis de componentes principales.
Los datos de la Tabla 1 corresponden a la investigación exploratoria y estimaciones realizadas por los autores con el fin de encontrar los niveles de incidencia de los factores que conforman el problema de los desplazados en la comunidad.
Lo anterior se consigue mediante ACP, con lo cual se obtienen resultados útiles para ver más claro la gravedad del problema (véase resultados finales en esta sección). Para este estudio se han definido las variables que a continuación se nombran en los 25 lugares donde se ubican los desplazados: HPM: Horas promedio de movilidad diaria; NPM: Número promedio de desplazados por mes; NHS: Número de horas semanales que los centros de alimentación están en funcionamiento; ATR: Área total de recreación de uso común (en metros cuadrados); NBC: Número de centros del lugar de posible concentración; CCD: Cantidad de camas disponibles; NTC: Número total de cuartos; HHM: Horas-hombre mensual requeridas para atenderlos.

Estos datos fueron procesados con SPSS y Statgraphics y se obtuvieron los resultados que aparecen a continuación, para sacar algunas conclusiones que sirven para consolidar el estudio sobre el ACP.
Estadísticos descriptivos
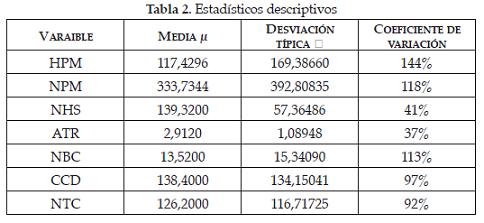
En la Tabla 2 se muestran la media, la desviación y el coeficiente de variación para cada una de las variables (análisis univariante). Estos valores permiten estimar la variable centrada tipificada Z (compárese con la Tabla 7). El objetivo de esta tipificación es homogenizar las unidades de medidas, buscando que todas pesen por igual en el análisis como se dijo anteriormente.
Matriz de correlaciones y prueba de independencia
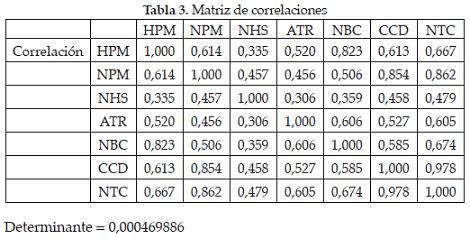
Determinante=0,000469886
El tener determinante bajo y coeficiente de correlaciones relativamente altas entre las variables originales es un buen indicador para utilizar la técnica de componentes principales que ayuda a resumir las variables en pocas dimensiones cuando se hace este tipo de análisis. Esto se debe a que las correlaciones altas implican dependencia lineal entre las variables, dando lugar a que se puedan explicar con un número menor de variables llamadas componentes principales Yi . Todo lo anterior, y suponiendo normalidad de los datos, se puede corroborar con la prueba de independencia que se muestra en la siguiente tabla (p-valor=0 es menor que 0,05 y KMO es próximo a 1):

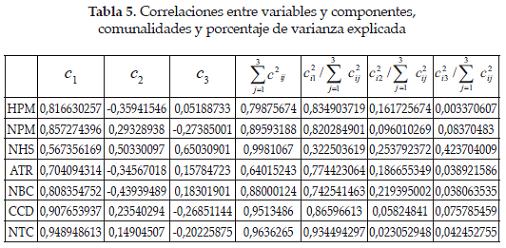
Comunalidades
En el análisis de componentes principales, las comunalidades son los elementos diagonales de la matriz analizada (la matriz de correlaciones o covarianza); en el análisis factorial, son las sumas de los cuadrados de las saturaciones para cada variable, utilizando todas las otras variables como predictores (ver Tabla 5). Esto indica, en el caso de la matriz de correlaciones, que la comunalidad es el porcentaje de varianza explicado por los componentes principales de la variable original determinada. Por ejemplo, para HPM, se observa que los tres componentes elegidos explican aproximadamente el 79,87% de la variabilidad; sin embargo, el porcentaje correspondiente al componente uno es de 83% frente al 16% y 0.3% en los componentes 2 y 3 respectivamente. Igual comportamiento se observa en las demás variables, excepto con NHS (número de horas semanales de los centros de alimentación en funcionamiento). Teniendo en cuenta estos porcentajes, podemos afirmar que todas las variables pueden resumirse con un solo componente principal, como se puede reconfirmar con los resultados mostrados en la Tabla 6. Para el caso en estudio, se podría pensar que el gobierno si está cumpliendo en parte con las necesidades de los desplazados, si se tiene en cuenta la alta correlación de las variables con el componente principal.
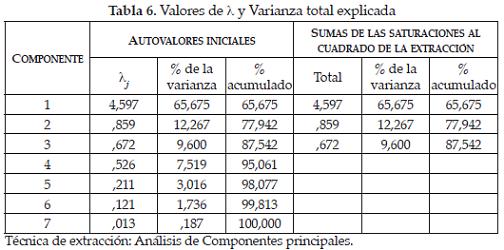
Autovalores y varianza explicada
Los autovalores se relacionan con la varianza explicada y permiten determinar el número de componentes principales adecuado (ver Tabla 6). En el caso de valores tipificados, el número de componentes principales está dado por aquellos autovalores mayores que uno. En este caso, solamente habría un solo componente principal correspondiente a lambda (λ1 = 4,597); sin embargo, para el caso se trabajará con tres componentes. Los valores de porcentaje de la varianza se estiman a partir del cociente entre λj y la traza de la matriz de R.
La Figura 5 permite ver con mayor claridad los datos estimados en la tabla anterior.
En la Tabla 7 se muestra la matriz de componentes C y la matriz de coeficientes de puntuaciones que permiten estimar los componentes principales.

Las Tablas 8, 9 y 10 muestran los procesos para determinar las coordenadas de los sitios en nuevo sistema de componentes principales mediante los datos estimados anteriormente y haciendo uso de las siguientes fórmulas o relaciones.
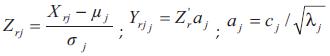
Donde r = 1,2,..., n ; j = 1,2,..., p.

La Tabla 8 se puede representar la matriz normalizada de los datos originales consignados en la Tabla 1 que se utiliza para el cálculo de las coordenadas de los sitios en el nuevo sistema de ejes (componentes principales). El cálculo de las coordenadas se hace a través de la matriz de autovectores que se presenta a continuación.

En la Tabla 10 se presentan los valores de los componentes principales en el nuevo espacio generado por los tres componentes principales. Básicamente, se muestra que los datos se han reducido de un espacio de siete dimensiones a tres, lo que facilita la interpretación del problema.


La Tabla 10 muestra los valores de coordenadas de los sitios en los componentes principales que fueron estimados. En dicha tabla aparecen en negrilla las coordenadas absolutas mayores de cada sitio asociadas con cada componente. Al asignar cada sitio a un componente siguiendo este criterio (véase Tabla 11), nuestro el modelo será como se muestra a continuación:
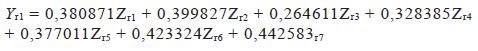
Siendo r= 1,....., 25. Las otras dos columnas se estiman de igual forma utilizando como coeficientes los valores de las columnas dos y tres de la matriz de autovectores.
5. CONCLUSIONES
La aplicación del análisis de datos multivariado, específicamente de la técnica de componentes principales, al caso de los desplazados de un municipio de Colombia permite sacar las siguientes conclusiones:
Las siete variables originales estudiadas en el caso de los desplazados quedan resumidas en tres índices (componentes principales), que están explicando el 87,542% de la variabilidad total (ver Tabla 7).
Según la matriz de autovectores, el primer componente principal asocia las variables NPM, CCD y NTC, explicando un 65,675% de la variabilidad total, equivalente al 75% del total explicado por los tres componentes (ver Tablas 7 y 10).
Al segundo componente principal le corresponden las variables HPM, ATR y NBC, explicando el 12,267% de la variabilidad total, equivalente al 14% del total explicado por los tres componentes, ver tablas 7 y 10.
Al tercer componente principal le corresponde la variable NHS, explicando el 9,6% de la variabilidad total, equivalente al 11% del total explicado por los tres componentes (ver Tablas 7 y 10).
Analizando las variables por componentes se pueden evidenciar los siguientes aspectos (recordar que por ser un caso, las conclusiones sólo hacen referencia a los datos seleccionados):
Según los resultados de la Tabla 10 de autovectores, el componente 1 al asociar con más peso las variables NPM, CCD y NTC se puede definir como el índice que mide la atención que el gobierno local ofrece a los desplazados. Sin embargo, creemos que no son suficientes las acciones realizadas por el gobierno local y nacional dado que para la movilidad de los desplazados hay poca disponibilidad de camas y cuartos. Hay que anotar que sólo en algunos sitios se percibe que el gobierno cumple a cabalidad el compromiso adquirido con la sociedad. Por ejemplo, los sitios 22, 23 y 24.
En el componente 2, las horas promedio de movilidad diaria (HPM), que al compararlo con las área total de recreación de uso común (ATR) y números centros de lugar de posible concentración (NBC), explica en gran parte el interés del gobierno por concentrar a los desplazados en lugares determinados proporcionándoles áreas de recreación común. Esto se puede evidenciar en los sitios 9, 22 y 23, donde las áreas recreacionales y/o de concentración responden a la movilidad de los desplazados más adecuadamente que los demás sitios.
El componente 3 se puede definir como el índice de atención alimenticia de los desplazados. El número de horas semanales en que los centros de alimentación están funcionando, parece no ser suficiente para atender al personal que se presenta en los diferentes sitios.
1 E. J. DALLAS. Métodos multivariados aplicados al análisis de datos. México: Thomson, 2000
2 http://www.derechoshumanos.gov.co/modules.php?name=informacion&file=article&sid=120
Referencias
[1] D. PEÑA. Análisis de datos multivariados. Madrid: Mac Graw Hill, 2002, pp. 133-158. [ Links ]
[2] E. J. DALLAS. Métodos multivariados aplicados al análisis de datos. México: Thomson, 2000, pp. 93-396. [ Links ]
[3] C. PÉREZ. Técnicas de análisis multivariante de datos. Aplicaciones con SPSS. Madrid; Pearson, 2004, pp. 121- 154. [ Links ]
[4] S. J. BRAMARDI. Estrategias para el análisis de datos en la caracterización de recursos fitogenéticos. Tesis doctoral, Universidad Politécnica de Valencia, Valecia, 2000, p 47-52. [ Links ]
[5] GARCÍA JIMÉNEZ y J. GIL FLORES. Análisis factorial. Cuadernos de estadística, Valencia, España: La Muralla, 2001. [ Links ]
[6] J. GIL FLORES. Análisis discriminante. Cuadernos de estadística, Valencia, España: La Muralla, 2000. [ Links ]
[7] R. CATTELL. The screen test for the number of factors. Multivariate Behavioral Research, 1, pág. 245-276, 1966. [ Links ]

