










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353On-line version ISSN 2346-2183
Dyna rev.fac.nac.minas vol.73 no.150 Medellín Nov. 2006
RECONSTRUCCIÓN DE OBJETOS DE TOPOLOGÍA ARBITRARIA MEDIANTE SELECCIÓN DE CENTROS PARA LA INTERPOLACIÓN CON FBR
RECONSTRUCTION OF ARBITRARY TOPOLOGY OBJECTS BY INTERPOLACIÓN WITH RBF WITH CENTERS SELECTION
GERMAN SANCHEZ TORRES
Universidad Nacional de Colombia, Facultad de Minas, Medellín, Colombia, gsanche@unalmed.edu.co
JOHN WILLIAN BRANCH BEDOYA
Universidad Nacional de Colombia, Facultad de Minas, Medellín, Colombia, jwbranch@unalmed.edu.co
PIERRE BOULANGER
University of Alberta, Edmonton, Canada, pierreb@ualberta.edu.ca
Recibido para revisar 14 de Agosto de 2006, aceptado 20 de Septiembre de 2006, versión final 9 de Octubre de 2006
RESUMEN: En este paper se presenta un procedimiento rápido para la selección automática de centros de interpolación de funciones de base radial. El procedimiento se basa en la clusterización de la superficie del objeto en regiones con características geométricas homogéneas tales como: la estimación de curvatura. Este enfoque de clusterización garantiza que la totalidad de las variaciones de la superficie serán representadas en la construcción del interpolante. Posteriormente, un conjunto de reglas es aplicado a cada uno de los cluster, para seleccionar finalmente los puntos del cluster que deberán ser utilizados como centros de interpolación. Las reglas fueron extraídas de soluciones óptimas obtenidas mediante una Estrategia Evolutiva. Excelentes resultados sobre datos de rango reales son mostrados.
PALABRAS CLAVE: Reconstrucción de superficies, Funciones de base radial, Selección de centros, Datos de rango, Estrategia evolutiva.
ABSTRACT: In this paper a fast procedure for the automatic selection of centres of interpolation of radial basis functions is showed. The procedure is based on the clusterization of the surface of the object in regions with homogenous geometric characteristics such as the curvature estimation. This approach of clusterization guarantees that the totality of the variations of the surface will be represented in the construction of the interpolant. Next, a set of rules is applied to each one of cluster, to finally select the points of cluster that they will have to be used like interpolation centre. The rules were extracted of obtained optimal solutions by means of an Evolutionary Strategy. Excellent results are showed on real data range.
KEYWORDS: Reconstruction, Radial basis functions, Centres selection, Range data, Evolutionary strategy.
1. INTRODUCCIÓN
Una gran cantidad de técnicas disponibles para interpolación 3D y métodos para aproximación mediante funciones de base radial (Radial Basis Functions) resultan ser muy atractivos para una gran cantidad de aplicaciones debido a la capacidad de reproducir forma de alta calidad, aún en presencia de datos irregularmente muestreados y con altos niveles de ruido.
La base del problema de ajuste de superficies mediante interpolación consiste en encontrar una superficie que interpole un número finito de N puntos en . Existen diferentes variantes del problema, el más simple de los casos ocurre cuando los datos están preescritos en una superficie en R2; en estos casos se mantiene una función bivariada F(x,y) la cual toma ciertos valores para cualquier pareja variante (xi, yi), esto es, F(xi, yi)=zi para todo i=1, .,N. Este problema es conocido como el problema de encontrar una función de reconstrucción. El caso más general de la interpolación de datos dispersos, es conocido como el problema de superficie-a-superficie en el cual los datos están preescritos en alguna superficie en R3; en este caso, el problema es encontrar una superficie S que interpole un conjunto finito de datos y otra superficie W que interpole unos valores wij estimados en cada punto de la superficie (x,y,z) en S. Este problema puede ser visto como el problema de interpolar datos dispersos (xi,yi,zi) en R, donde (xi,yi,zi) tiene la restricción de estar sobre la superficie en R3. Los casos más populares son aquellos en donde wij es un escalar y es generalmente una medida de distancia del punto a la superficie. La literatura en interpolación de datos dispersos es basta, trabajos como el de Powell [20], Arge [1] y Buhmann [7] describen métodos de interpolación con RBF.
En las pasadas décadas, las funciones de base radial fueron muy utilizadas para la construcción de funciones multivariadas desde datos dispersos. La selección de funciones radial más usadas incluyen, el kernel gaussiano, la multicuádrica robusta, la Multicuádrica Inversa y la Spline TPS. Cada una de estas funciones tiene buena aceptación debido a que el sistema asociado de ecuaciones resulta ser invertible, incluso si la distribución de los puntos no presenta regularidad.
La reducción de la complejidad computacional es una nueva directriz en los trabajos que investigadores en el área están realizando. La complejidad computacional de las RBF depende directamente de la cantidad de centros utilizados en el cálculo del interpolante y de la técnica utilizada para su solución. Adicionalmente, costos significativos asociados a este proceso, dependen de la etapa de evaluación, la cual permite la generación del modelo. La correcta selección del conjunto de centros para la interpolación es aún un problema. En trabajos recientes, la selección de centros es realizada principalmente en procedimientos iterativos y de naturaleza aleatoria como en [10]; tradicionalmente, nuevos centros son añadidos al interpolante en cada iteración hasta alcanzar un nivel de precisión estipulado.
Este trabajo se centra en el problema de la selección de centros de acuerdo a las características geométricas de la superficie, disminuyendo el costo computacional sin perdida considerable en la precisión de la representación del objeto.
Este trabajo está organizado de la siguiente manera: en la sección 2, se presenta la teoría de la interpolación con rbf. en la sección 3, se hace una descripción de los trabajos previos. en la sección 4, se explica el problema de la selección de centros y el método propuesto. en la sección 5, se presentan resultados de los experimentos y en la sección 6, conclusiones y directrices para los trabajos futuros.
2. INTERPOLACIÓN CON FUNCIONES DE BASE RADIAL
Los métodos de funciones de base radial usados para la aproximación multivariada constituyen uno de los más recientes y frecuentes procedimientos aplicados en la teoría de aproximación moderna cuando el objetivo es aproximar datos dispersos en varias dimensiones [8]. El problema de interpolar funciones de d variables reales (d>1), ocurre naturalmente en muchas áreas de matemática aplicada y de las ciencias. Los métodos de función de base radial pueden proporcionar interpolantes para valores de funciones dados en puntos irregularmente posicionados para cualquier valor de d. Estos interpolantes son a menudo excelentes aproximaciones a la función real, incluso cuando el número de puntos de la interpolación es pequeño.
El problema de la interpolación multivariable puede ser descrito como sigue: Dado un conjunto de puntos distintos x1, x2, ....,xN Rd y un conjunto de escalares f1,f2,...,fn deseamos construir una función continua S: Rd–>R para la cual:
![]()
El procedimiento basado en funciones de base radial consiste en seleccionar una función 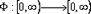 y una norma ||.|| en Rd ; por lo tanto s toma la forma:
y una norma ||.|| en Rd ; por lo tanto s toma la forma:
![]()
Así s es seleccionada para ser un elemento del espacio de vectores definido por las funciones ![]() , para i= 1,....,n. Las condiciones de interpolación entonces definen un sistema lineal de ecuaciones Al=f, donde A->Rnxn y es dado por:
, para i= 1,....,n. Las condiciones de interpolación entonces definen un sistema lineal de ecuaciones Al=f, donde A->Rnxn y es dado por:
![]() , para 1= i , j = n
, para 1= i , j = n
y donde l=(l1,...,ln) y f=(f1,...,fn).
Usualmente para la norma ||.|| es seleccionada la distancia euclídea; para este caso en particular, la matriz A o matriz de distancias generada por los distintos puntos es invertible para muchas selecciones de F no siendo sin embargo la única norma útil en la interpolación.
3. TRABAJOS PREVIOS
Barrow et al. [2] y Blicher [5] se constituyen los primeros, en introducir el problema de la reconstrucción de superficies en el área de la visión. Ellos implementaron una solución basada en la interpolación de superficies curvadas uniformemente. La solución aplica un algoritmo, que se desarrolla con el uso de un arreglo de procesos paralelos simples que realizan variaciones locales iterativamente. Esta técnica es muy simple y presenta varios problemas, como por ejemplo, el problema de las discontinuidades de la superficie.
Grimson [15] presenta la teoría de interpolación de superficies visual, en donde los datos de rango son obtenidos a partir de un par de imágenes estéreo. Esta teoría enfrenta el problema de encontrar el mejor ajuste a una superficie a partir de un conjunto de valores de profundidad obtenidos mediante el algoritmo de adquisición en estéreo presentado por Marr [17].
Boult y Kender [6] presentan un procedimiento de reconstrucción visual de superficies que está basado en la semi-reproducción de un kernel spline de Duchon [12]. El proceso de semi-reproducción del kernel spline está definido en términos de reproducir el kernel en un espacio de semi-Hilbert. La mayor componente computacional del método es la solución del denso sistema lineal de ecuaciones.
Trabajos más recientes constituyen los acercamientos más completos e importantes al problema del ajuste de superficies; entre ellos existe una variedad muy amplia de técnicas utilizadas incluyendo también combinaciones de éstas. Los acercamientos mediante mallas triangulares y funciones splines han sido tema de una amplia gama de trabajos realizados en el área recientemente. Esta tendencia es en gran medida incentivada debido a que soluciones como las basadas en interpolación suelen ser muy costosas computacionalmente. Estas limitaciones actualmente están siendo menguadas con el gran desarrollo de las capacidades de cómputo de las arquitecturas modernas, el aumento significativo en la capacidad de los dispositivos de almacenamiento y el desarrollo de técnicas más rápidas para la solución de grandes sistemas de ecuaciones.
La interpolación mediante RBF desde el punto de vista teórico, ha sido ampliamente utilizado en diferentes trabajos: Baxter [3] en su trabajo "The Interpolation Theory of Radial Basis Functions", investigó la sensibilidad de la interpolación de las RBF a los cambios en la valores de la función, utilizando descripciones de los trabajos de Ball, Narcowich y Ward, para estudiar las matrices generadas por un conjunto de puntos dispuestos en grid regulares; adicionalmente, se analizaron los resultados de la interpolación de una amplia gama de familias de RBF.
Wendland [23] describe ampliamente los aspectos computacionales de la interpolación multivariada y la aproximación mediante RBF. Aunque describe algunas características y restricciones que los datos deben cumplir para evitar problemas de matrices no invertibles no relaciona los aspectos o características para la selección de centros de interpolación.
En el campo de las aplicaciones realizadas para reconstrucción 3D mediante la interpolación de RBF, se pueden encontrar trabajos muy recientes que se direccionan en diversos enfoques. Floater et al. [13] presentan un esquema jerárquico para la interpolación con RBF de soporte compacto. La jerarquía está relacionada con un grupo de subconjuntos de los datos obtenidos mediante triangulaciones sucesivas de Delaunay. El problema de los enfoques de múltiples escalas, es la interpolación de más de un conjunto de puntos para un solo objeto.
Carr [9] describe una aplicación de rango restringido de suavidad para reconstruir superficies; esta técnica consiste en reducir la energía de una función cuádrica sobre todas las funciones de un espacio de Hilbert, satisfaciendo un conjunto dado de restricciones tomados de la topología de la superficie, que es inferida de los puntos. Posteriormente, Carr et al. [10] mostraron que puntos desordenados podían ser interpolados mediante RBF produciendo superficies suaves y continuas mediante la aplicación de un kernel pasa baja para reducir la cantidad de puntos, proponiendo un procedimiento en el cual se reduce el costo computacional del proceso de interpolación con RBF; sin embargo, el costo computacional alcanzado es alto debido a que el procedimiento de reducción de puntos es costoso computacionalmente.
Los trabajos teóricos y de aplicación realizados desde la última década clarifican una problemática relacionada con la interpolación de datos para reconstruir superficies, desde que la teoría de la interpolación con RBF está bien definida y sustentada, el problema que emerge del costo computacional anexo a este tipo de procedimientos, comparados otras técnicas de interpolación de datos como los splines ampliamente estudiado en los últimos años.
En el 2005, Beatson [4] construye un método para la rápida evaluación de interpolantes con funciones de base radial. El algoritmo propuesto está basado en una propiedad fundamental de funciones definidas condicionalmente negativas (o positivas); este procedimiento emplea un FGT para computar una suma de kernel Gaussiano mediante una regla de cuadratura; éste método mostró un alto rendimiento sobre arquitecturas de clúster de estaciones de trabajo.
Otros trabajos, proponen una técnica de ajuste adaptativo mediante RBF, como en Ohtake [19], el cual propone una método de selección de parámetros mediante el cual se garantiza la suavidad del modelo final; aquí el número de centros seleccionados para evaluar la función de base radial, tiene influencia sobre la calidad del error.
Kojekine [16] utiliza la evaluación de una función de base radial de soporte compacto; este tipo de funciones necesitan una menor complejidad computacional que otros modelos de RBF, ya que la utilización de estructuras de datos como los árboles Octales, ayudan a reducir la complejidad de la búsqueda y clasificación de centros sobre los cuales una RBF es evaluada.
El costo computacional que poseen los enfoques basados en RBF está presente en todos los trabajos realizados, el costo computacional de esta técnica está relacionado con el hecho de que ningún método presenta un criterio de selección y reducción de puntos así como el criterio para la correcta selección de los radios, en el caso de las funciones de base radial de soporte compacto, que permitan obtener interpolaciones con una precisión adecuada y un menor costo computacional.
4. SELECCIÓN DE CENTROS DE INTERPOLACIÓN DE FUNCIONES DE BASE RADIAL
En este trabajo la selección de centros se considera solamente en el caso de que los centros para el interpolante estén situados en los puntos de referencias. Hay una razón teórica que indica que la interpolación es óptima si los centros están situados en los puntos del objeto [22]. Los experimentos con la localización de centros se han centrado sobre todo en los métodos de aproximación [18]. Aunque la función típica de minimización la constituye los mínimos cuadrados, otras funciones objetivas también se han considerado para la minimización [21][14]. El objetivo, es obtener una buena aproximación del objeto representado por el conjunto de puntos con un subconjunto de este. Esto reduce el tiempo de cómputo empleado en la construcción y la evaluación del interpolante que aproxime la geometría del objeto. Los resultados indican que los ahorros significativos en costo computacional pueden resultar en el costo de introducir errores muy pequeños [11].
El problema de la selección de centros surge tras la incorporación de la técnica de interpolación al campo de la reconstrucción de superficies. Esto es, desde el punto de vista matemático, la teoría de interpolación con RBF garantiza que la función obtenida contiene los puntos dados como referencia. Pero al trabajar con superficies reales, se hace necesario minimizar costos computacionales en interpolar grandes cantidades de puntos, entonces, se plantea el problema de la reducción del conjunto de puntos de referencia o centros sin causar una perdida considerable de la calidad del ajuste en el modelo final.
Los métodos tradicionales de interpolación con RBF etiquetan todos los puntos como centros y realizan la denominada interpolación directa. La interpolación directa suele ser la manera más precisa de ajustar una superficie debido a que se utiliza toda la información posible que describe dicha superficie. En el campo de la reconstrucción de superficies, la interpolación directa no suele ser conveniente por sus altos costos computacionales, debido a que los medios de adquisición modernos generan densas nubes de puntos. Adicionalmente, interpolar todos los puntos obtenidos, sugiere que el modelo final contendrá el ruido contenido en los puntos; este nivel de ruido es introducido a los puntos desde el proceso de adquisición y durante etapas intermedias como la de registro y la de integración.
La manera más comúnmente utilizada para la reducción de centros [19][10], está basada en selección aleatoria. El enfoque tradicional podría describirse así:
Selección inicial de centros (Aleatoria).
Error = alguna medida de error ();
While( Error < l)
Adhiera nuevos puntos (aleatoria)
Error = alguna medida de error ();
Endwhile
Donde es algún umbral deseado de suavidad establecido por el usuario. En este enfoque, no existe una manera directa de selección de los centros, por el contrario, en cada iteración y tras la adhesión de nuevos puntos, es realizado un proceso de interpolación completo. Esto suele ser computacionalmente costoso.
Adicionalmente, cualquier solución de selección de centros planteada debe estar limitada en el costo computacional. Esto debido a que, ningún método propuesto de selección deberá ser más costoso que la interpolación directa, porque de lo contrario, sería mejor la interpolación de todos los puntos. Específicamente un método de selección deberá cumplir que:
![]()
Donde, Cs es el costo computacional que acarrea el proceso de selección, Cik es el costo de la interpolación con k puntos y CiN es el costo total de la interpolación con todo el conjunto de centros N (interpolación directa).
El procedimiento propuesto para la selección de los centros, es descrito en dos etapas. Primero, se describe las características de las regiones en donde deben estar centros de interpolación para minimizar el error de ajuste; este conjunto de reglas, fueron obtenidas experimentalmente de soluciones óptimas generadas mediante una Estrategia Evolutiva (EE); la descripción de la EE y las reglas son descritos en la sección 4.1. En la segunda parte, un método rápido y directo de selección de centros es detallado.
4.1 Selección de Centros Mediante Estrategia Evolutiva
El uso de las estrategias evolutivas en este contexto se centra en la obtención del comportamiento que utiliza la EE para seleccionar dentro de un conjunto general un conjunto reducido de puntos que servirán como centros de interpolación. Durante la evolución de la EE, los centros seleccionados se ubican en zonas en las cuales se minimiza el error de ajuste de las superficies, es decir el error que la interpolación genera frente al conjunto restante de puntos que no es utilizado para el proceso de interpolación. La idea principal es encontrar los patrones de ubicación que minimizan el error dentro de un conjunto de muestra de superficies matemáticas.
La descripción de la EE utilizada consiste de:
4.1.1 Esquema de Representación
El esquema de representación consiste en un cromosoma de tamaño N, donde N denota el número de centros con lo cuales se quiere ajustar la superficie. Cada uno de los genes contiene un índice que identifica un punto dentro de la nube de puntos (Ver Figura 1).
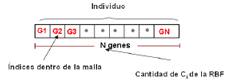
Figura 1. Representación de un individuo.
Figure 1. Representation of an individual
4.1.2 Función de aptitud
La función de aptitud para esta propuesta, consiste en medir el error promedio representado como la distancia entre los puntos generados con el interpolante y el conjunto de puntos inicial. (5)
Cada individuo, es considerado un conjunto de centros para la interpolación, de hecho cada individuo determina un interpolante que intenta describir una superficie con solo el conjunto N de puntos.
4.1.3 Operadores Genéticos
La EE empleada en esta propuesta, aplica un operador de cruce con dos puntos; este enfoque, de más de un punto de cruce intenta conservar en nuevas generaciones, segmentos pequeños de puntos correctamente ubicados. Por otra parte, el operador de mutación, simplemente varía la información de cada gen según la probabilidad de mutación, teniendo en cuenta los vecindarios definidos para cada punto representado. En el paradigma de las EE, el operador de mutación suele ser el más importante, esto debido entre otras razones, a que cada uno de los genes de los individuos posee su propio significado y no en conjunto como en los algoritmos genéticos.
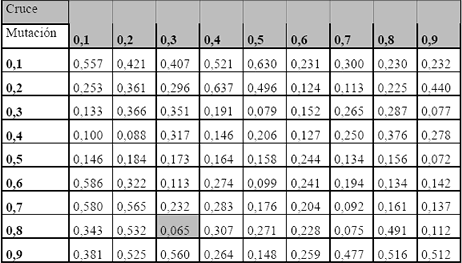
Con el objeto de estimar adecuadamente los valores para cada uno de los operadores genéticos, se realizaron un conjunto de pruebas con superficies matemáticas. Los mejores resultados en promedio de 10 pruebas para cada una de las combinaciones porcentuales de los operadores genéticos se obtuvieron con un valor del 80% para el operador de mutación y 30% para el operador de cruce como se muestra en la Tabla 1.
Tabla 1. Promedio de los resultados obtenidos para la parametrización de la EE.
Table 1. Average of the results obtained for the parametrization of the EE.
Una vez se ha parametrizado correctamente la EE, se optimizó un conjunto de 15 centros para diferentes superficies matemáticas que se muestran en la Figura 2. El conjunto de soluciones que se muestran fueron obtenidas como el resultado de la optimización de 10.000 generaciones, el tamaño tan reducido de centros se estableció así para que la localización de los centros fuera crítica y evitar que el error disminuyera por la cantidad de centros.
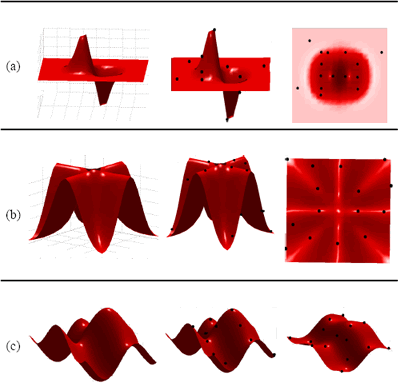
Figura 2. (a),(b) y (c) Funciones matemáticas y los correspondientes 15 centros que la EE seleccionó. Las funciones matemáticas fueron evaluadas en el intervalo (-4,4) con una densidad de muestreo de 0.1
Figure 2. (a), (b) and (c) Mathematical functions and the 15 centers that the EE selected. The mathematical functions were evaluated in the interval (- 4.4) with a sampling density of 0.1. 4.2 Selección de Centros Mediante Clusterización
En la sección (a) de la Figura 2 se puede ver que el algoritmo evolutivo concentró la mayor cantidad de centros en las regiones de alta variación geométrica, mientras que por el contrario la región plana se aproximó con solo tres puntos. Se nota la presencia de centros en los puntos extremos de la superficie; en esta Figura, en donde cada punto extremo forma un especie de conos, la anchura de esos fue modelada con algunos puntos. En la sección (b) y (c) la posición de los centros tiene una disposición simétrica, la selección de los centros fue realizada en su mayoría en regiones con altas variaciones de curvatura. Aunque una superficie como esta es muy difícil de aproximar con pocos centros, debido a sus altas variaciones geométricas, se nota que la EE cubrió casi de manera uniforme la superficie. Los resultados del ajuste de la interpolación obtenidos mediante la EE se listan en la Tabla 2.
Tabla 2. Resultados obtenidos con la evolución de la EE para cada superficie de la Figura 2.
Table 2. Results obtained with the evolution of the EE for each of the surfaces in the Figure 2.

Esta etapa implementa una técnica general de clusterización mediante crecimiento de regiones, dado que clusterizar la superficies no es costoso computacionalmente si se establecen las estructuras de datos eficientemente. El algoritmo consiste en previamente calcular la estimación de la curvatura de las superficies en cada punto P. La estimación de la curvatura es calculada, resolviendo una matriz de coovarianza formada utilizando un vecindario cercano y de tamaño fijo en cada uno de los puntos así (6):
![]()
Donde n es el número de vecinos a p y ![]() . La estimación de la curvatura en p es (7): , donde
. La estimación de la curvatura en p es (7): , donde
![]()
Una vez obtenida la aproximación de la curvatura, el siguiente paso consiste en calcular una clusterización de las superficies, de tal forma que la varianza de cada clúster no supere un umbral establecido por el usuario. La descripción general del algoritmo es:
- Inicie con un punto semilla aleatoria Pi, y cree un clúster Ci.
- Adhiera un vértice
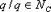 sucesivamente a Ci hasta que Vc<l donde Nc es un vecindario circular (Ver Figura 3) alrededor del centroide de Ci y Vc es la varianza dentro del clúster Ci.
sucesivamente a Ci hasta que Vc<l donde Nc es un vecindario circular (Ver Figura 3) alrededor del centroide de Ci y Vc es la varianza dentro del clúster Ci. - Retorne a 1 hasta clusterizar todos los puntos de M
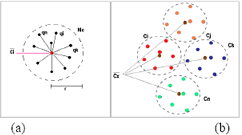
Figura 3. (a) Definición de vecindario de cada centroide, (b) Centroides de los clúster que no pertenecen al conjunto de datos.
Figure 3. (a) Definition of neighborhood of each centroid (b) Centroid of the cluster does not belong to the data set.
Resultados de esta técnica se muestran en la Figura 4, variando el umbral de la varianza. La cantidad de clúster obtenidos se comparten inversamente al valor de la varianza, a medida que la varianza es mayor, menor número de clúster son obtenidos. La varianza tendrá una incidencia directa sobre la suavidad y la calidad de la superficie interpolada, porque ésta determina la cantidad de centros con las cuales se aproximará la superficie.

Figura 4. Variación del umbral de la varianza; (a)l = 1, con 16643 centros seleccionados; (b) l= 0.1, con 27.402 centros seleccionados; (c) l=0.01, con 42.033 centros seleccionados; y (d) sin reducción , 172.930 centros (figura original).
Figure 4. Variation of the threshold of the variance; (a) l= 1, with 16643 selected centers; (b) l= 0,1, with 27,402 centers selected; (c) l=0.01, with 42,033 selected centers; and (d) without reduction, 172,930 centers (original figure).
La técnica de clusterización, tiene la propiedad de representar completamente las variaciones de la superficie, característica que no se presenta en técnicas de selección aleatoria, en la cual puede presentarse ausencia de centros en regiones pequeñas que generan altos errores y causan la interpolación iterativa del interpolante. Adicionalmente, regiones curvadas altamente tendrán mayor número de clúster, frente a regiones poco curvadas; esto es importante debido a que la mayor proporción de error de la superficie interpolada y la superficie real se da en regiones con altas variaciones.
Finalmente la selección de los puntos que se tomarán como centros serán seleccionados de cada uno de los clúster así:
- Inicie en clúster Ci.
- Seleccione el puntos más alejados de la media del clúster.
Los dos pasos anteriores garantizan que si la varianza del clúster fue aumentada por valores extremos, esos puntos serán seleccionados garantizando que las máximas variaciones geométricas serán tomadas como referentes de interpolación.
5. EXPERIMENTOS Y RESULTADOS
En esta sección se muestran los resultados obtenidos al aplicar el método propuesto en diferentes conjuntos de datos analizando el tiempo empleado en la selección y los porcentajes de reducción de puntos, así como el error de ajuste del modelo final obtenido.
5.1 Hadware y librerías
Todas las pruebas fueron realizadas utilizando una computador con procesador de 3.0GHz y memoria RAM de 1.0GB corriendo bajo el sistema operativo Microsoft XP. Las implementaciones de los modelos fueron realizadas en C++ y MATLAB; además se programó un motor gráfico en OpenGL, para obtener la representación gráfica de las imágenes.
5.2 Umbral de suavidad
El algoritmo necesita un único parámetro , para realizar la selección de centros. El valor de determina el nivel de suavidad de cada uno de los parches, así como directamente la cantidad de centros seleccionados y el error de ajuste también es afectado. Experimentalmente se ha establecido el valor de l menor o igual a 0.01 para los cuales se obtuvieron modelos con altos niveles de precisión. En la Figura 4, se muestra un segmento de superficie; en este segmento se pueden observar altas variaciones geométricas y su interpolación con conjuntos diferentes de centros obtenidos de la variación del valor de l. Note que a mayor valor de l los detalles de la superficie se van perdiendo y con un valor de l=0.01 se alcanza un nivel de detalle significativamente igual a la imagen original con una reducción aproximada al 73%.
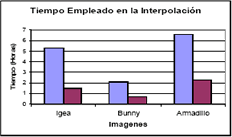
Figura 5. Comparación de los tiempos empleados en la interpolación. (Azul) Interpolación Directa y (Rojo) Interpolación con centros seleccionados.
Figure 5. Comparison of the times used in the interpolation. (Blue) Direct Interpolation and (Red) Interpolation with selected centers.
5.3 Reconstrucción de superficies
Adicionalmente, la reducción obtenida y los errores de interpolación obtenidos para un conjunto mayor de imágenes son reportados en la Tabla 3. Los porcentajes de reducción obtenidos son significativamente altos, cercanos al 70% del total de las imágenes originales. Las imágenes resultantes fueron obtenidas solo con la interpolación de no más del 30% de los datos originales, obteniendo modelos de alta precisión y con costos computacionales significativamente bajos en comparación al resultado de interpolar el conjunto original de datos, los modelos finales obtenidos son mostrados en la Figura 6.
Tabla 3. Objetos y los porcentajes de reducción obtenidos.
Table 3. Objects and the obtained percentage of reduction.
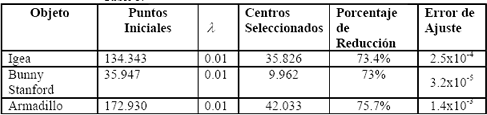

Figura 6. (a),(b) y (c) Imagen completa de la Igea, la clusterización y la imagen final obtenida mediante interpolación, (d),(e) y (f) Conejo de Stanford, su clusterización y la imagen final obtenida y (g), (h) y (i) Armadillo, su clusterización y el modelo final obtenido con la interpolación de los puntos seleccionados.
Figure 6. (a), (b) and (c) Complete image of the Igea, the cluster and the obtained final image by interpolation, (d), (e) and (f) Rabbit of Stanford, its cluster and the final image obtained and (g), (h) and (i) Armadillo, its cluster and the obtained final model with the interpolation of the selected points.
Existen diferentes formas de medir el error de interpolación entre la representación original y la imagen obtenida, el problema radica en que la cantidad de puntos no es igual entre los dos modelos y tampoco es posible comparar puntos con el interpolante. En este trabajo, el procedimiento para medir el error de ajuste consiste en medir la distancia de los puntos de la imagen generada a la superficie descrita por la triangulación de la imagen original. Para cada punto del modelo generado se encuentra el triángulo contenedor en la imagen original; la distancia de la proyección del punto sobre el plano descrito por el triangulo contenedor, es el error de ajuste en ese punto específico; la media de esta distribución es el error reportado.
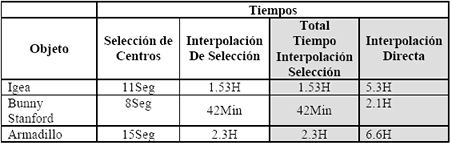
La reducción de centros de interpolación tiene como consecuencia directa el ahorro de tiempo y cómputo en el cálculo del interpolante ver Figura 5; sin embargo, a este tiempo se debería adicionar el tiempo empleado en realizar la selección de los centros. Los tiempos para el conjunto de imágenes de la Figura 6, se muestran en la Tabla 4. En general, el tiempo para realizar la selección no es significativamente grande frente a los tiempos empleados en realizar la interpolación; esto es debido a que el procedimiento tiene un orden de magnitud lineal y solo depende del número de puntos de la imagen.
Tabla 4. Tiempos empleados para obtener los porcentajes de reducción.
Table 4. Used times to obtain the percentage of reduction.
6. CONCLUSIONES Y TRABAJOS FUTUROS
Se ha propuesto un método eficiente para la selección de centros de interpolación mediante funciones de base radial, el cual posibilita la reducción del costo computacional que genera la interpolación directa de la nube total de puntos que describen los objetos, generando modelos de alta precisión en un menor tiempo.
El método está basado en el análisis del comportamiento de las soluciones óptimas generadas mediante una EE e incorporado en un algoritmo rápido de selección. El comportamiento general que utiliza la EE para obtener soluciones óptimas consiste en la concentración de centros en regiones con altas variaciones geométricas y por el contrario, regiones con bajas variaciones geométricas son descritas con pocos centros; es decir, la mayor parte de la reducción de centros se centra en regiones planas.
El algoritmo propuesto se basa en la clusterización de la superficie garantizando que la superficie es dividida en regiones geométricamente homogéneas permitiendo la concentración de centros en regiones altamente curvadas, esto debido a que las altas variaciones geométricas producen clúster muy pequeños y regiones pocos curvadas generan clúster de mayor tamaño. Adicionalmente, la clusterización garantiza que toda las variaciones de la superficie es incorporada en el interpolante, de cada clúster es seleccionado un punto cuya varianza con respecto a la media sea la mayor; esto garantiza, que el punto de mayor variación dentro de los clúster es el utilizado para realizar la interpolación. Es claro que obtener el punto de mayor varianza podría introducir ruido seleccionando outliers por tal razón es necesario que a la imagen se le aplique inicialmente un filtro de reducción de ruido.
Como trabajo futuro, es interesante realizar la selección de centros guiada por la densidad de puntos, es decir por características de muestreo de los datos sobre la superficie y no por características geométricas directamente, sin embargo, regiones en las cuales se presenta altas densidades generalmente están situadas en zonas de alta variación geométrica. Pretendemos hacer una extensión de la técnica de Mean-Shift para selección de centros.
REFERENCIAS
[1] ARGE, A. Approximation of scattered data using smoth grid functions. Technical Report STF33 A94003, SINTEF. 1994. [ Links ]
[2] BARROW, H. G. AND TANENBAUM, J. M. Interpreting line drawings as three-dimensional surfaces. In Proc. of AAAI-80, pages 1114, Stanford, CA. 1980. [ Links ]
[3] BAXTER, B. The Interpolation Theory of Radil Basis Functions. PhD thesis, Trinity College. 1992. [ Links ]
[4] BEATSON, R. K. Fast solution of the radial basis function interpolation equations: Domain decomposition methods, Proceedings of ACM SIGGRAPH, 2005. [ Links ]
[5] BLICHER, P. From images to surfaces: A computational study of the human early visual system; Mit press, 1982. SIGART Bull., (82):12-14. [ Links ]
[6] BOULT, T. AND KENDER, J. Visual surface reconstruction using sparse depth data. In CVPR86, pages 68-76. 1986. [ Links ]
[7] BUHMANN, M. Multivariate interpolation in odd-dimensional Euclidean spaces using multiquadrics, Const. Approx; 6; 21-34. 1990. [ Links ]
[8] BUHMANN, M. Radial Basis Functions: Theory and Implementations. Cambridge University Press. 2003. [ Links ]
[9] CARR, J. Reconstruction and representation of °ud objects with radial basis function. 2001 [ Links ]
[10] CARR, J., BEATSON, R., MCCALLUM, B., FRIGHT, W., MCLENNAN, T., AND MITCHELL, T. Smooth surface reconstruction from noisy range data. In GRAPHITE 03: Proceedings of the 1st international conference on Computer graphics and interactive techniques in Australasia and South East Asia, pages 119ff, New York, NY, USA. ACM Press. 2003 [ Links ]
[11] CARLSON, R., AND NATARAJAN, B. Sparse approximate multiquadric interpolation. Computers and Mathematics with Applications, 26:99–108. 1994. [ Links ]
[12] DUCHON, J. Spline minimizing rotation-invariant seminorms in sobolev spaces. Constructive Theory of Functions of several Variables, Vol. 571, 85-100. 1997 [ Links ]
[13]FLOATER, M. AND ISKE, A. Multistep scattered data interpolation using compactly supported radial basis functions. Journal of Comp. Appl. Math., 73:65–78. 1996. [ Links ]
[14] GIROSI, F. Some extensions of radial basis functions and their applications in artificial intelligence. Computers and Mathematics with Applications, 24(12):61–80. 1992. [ Links ]
[15] GRIMSON, W. From Images to Surfaces: A Computational Study of the Human Early Visual System. MIT Press, Cambridge, MA. 1981. [ Links ]
[16] KOJEKINE, N AND SAVCHENKO, V. Surface reconstruction based on compactly supported radial basis functions, Geometric modeling: techniques, applications, systems and tools, pp 218231, Kluwer Academic Publishers. 2004. [ Links ]
[17] MARR, D. AND POGGIO, T. A theory of human stereo vision. Technical report, Cambridge, MA, USA. 1997. [ Links ]
[18] MCMAHON AND FRANKE, R. Knot selection for least squares thin plate splines. SIAM Journal on Scientific and Statistical Computing, 13(2):484–498. 1992. [ Links ]
[19] OHTAKE, Y. 3d scattered data approximation with adaptive compactly supported radial basis functions. In SMI 04: Proceedings of the Shape Modeling International 2004 (SMI04), pages 3139, Washington, DC, USA. IEEE Computer Society. 2004. [ Links ]
[20] POWELL, M. The theory of radial basis function approximation, in Advances in Numerical Analysis II, W.A. Light, ed., Claredon Press, Oxford, pp. 105. 1990. [ Links ]
[21] SALKAUSKAS, K. Moving least squares interpolation with thin-plate splines and radial basis functions. Computers and Mathematics with Applications, 24(12):177–185. 1992. [ Links ]
[22] SCHABACK, R. Creating surfaces from scattered data using radial basis functions. In M. Daehlen, T. Lyche, and L. L. Schumaker, editors, Mathematical Methods in AGD III. Vanderbilt Press, 1995. [ Links ]
[23] WENDLAND, H. Piecewise polynomial, positive definite and compactly supported radial functions of minimal degree. Advances in computational Mathematics 4, 389-396. 1995. [ Links ]

