










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353On-line version ISSN 2346-2183
Dyna rev.fac.nac.minas vol.77 no.164 Medellín Oct./Dec. 2010
DETECCIÓN DE BORDES UTILIZANDO LA MATRIZ DE CO-OCURRENCIA: APLICACIÓN A LA SEGMENTACIÓN DE IMÁGENES DE FRUTOS DE CAFÉ
EDGE DETECTION USING THE CO-OCCURRENCE MATRIX: AN APPLICATION TO THE SEGMENTATION OF COFFEE CHERRIES IMAGES
JULIÁN BETANCUR
Fundación Universidad del Norte, Colombia, Barranquilla julianb@uninorte.edu.co
JAISON MORA
Fundación Universidad del Norte, Colombia, Barranquilla. jmora@uninorte.edu.co
JORGE VIERA
Fundación Universidad del Norte, Colombia, Barranquilla. jviera@uninorte.edu.co
Recibido para revisar Marzo 7 de 2009, aceptado Junio 17 de 2009, versión final Julio 17 de 2009
RESUMEN: Se presenta un sistema de segmentación de imágenes de frutos de café basado en el análisis de las características de textura computadas de la matriz de co-ocurrencia. Se cuantifican 121 indicadores de los cuales se seleccionan aquellos con mayor discriminación entre dos clases posibles: "Centro de Fruto" y "Borde". La segmentación utiliza la imagen de bordes, buscando en esta sus regiones arco-conexas. El sistema detector de bordes consiste en un clasificador bayesiano con cinco indicadores como entrada extraídos de un elemento estructural, lo que resulta en la partición de la imagen. La salida del clasificador es la pertenencia hacia una de las dos clases para una región de 4x4 (elemento estructural). Para disminuir el costo computacional, se propone un método experimental utilizando un clasificador basado en umbrales, cuya entrada es un indicador de alta discriminación. Los sistemas alcanzan un nivel de detecciones correctas superior al 90% para un nivel de tolerancia de 50%.
PALABRAS CLAVE: Segmentación de imágenes, matriz de co-ocurrencia, clasificador Bayesiano, Análisis de Componentes Principales (PCA), Índice de Fisher (IDF).
ABSTRACT: A coffee-fruits image segmentation system based on the analysis of textural features computed from the co-occurrence matrix is presented. 121 indicators are measured and those with highest discrimination between two classes "Fruit Center" and "Edge", are selected. Segmentation is performed using the edge image, looking for their arc-connected regions. The edge detection system is a Bayesian classifier with five indicators as inputs computed using a structural element, resulting in the partition of the image. The classifier"s output indicates the belongingness to one of the two classes for a 4x4 region (structural element). In order to decrease computational burden, a thresholding-based edge detection system is proposed, using one indicator with high discrimination. Both systems reach a correct detection level higher than 90% at 50% of tolerance.
KEYWORDS: Image segmentation, co-occurrence matrix, Bayesian classifier, Principal Component Analysis (PCA), Fisher Index (IDF).
1. INTRODUCCIÓN
Colombia, como el productor de café de la más alta calidad del mundo, posee una fuerte infraestructura cafetera con 874.000 hectáreas cultivadas en 16 departamentos, generando con esto un millón de empleos directos e indirectos, haciendo un aporte del 12.4% del PIB agrícola nacional y con alrededor de 513.000 familias agricultoras. Esto muestra la tendencia de que cerca del 90% de los cafetales del país son propiedad de pequeños productores que poseen hasta 3 hectáreas por familia [1].
Según la Federación Nacional de Cafeteros de Colombia [1], el nuevo modelo de negocio de café en Colombia debe concentrar sus esfuerzos en transferir la mayor parte de los ingresos al caficultor, lo cual se genera dándole valor agregado al producto con nuevas estrategias de producción y comercialización, buscando la mejora continua en los procesos que apoyen el posicionamiento del café colombiano en el mundo. El actual sistema de recolección y selección de frutos se realiza de forma manual implicando esto un 30% al 40% del costo total de la producción [2]. Debido a la creciente competencia de mercados internacionales, la cada vez menor facilidad para conseguir cosechadores, a la automatización de procesos y con el fin de aumentar la calidad del café recolectado, se plantea la realización de un clasificador de estados de maduración para frutos de café en cereza, mediante técnicas de visión de máquina [3], el cual requiere una etapa de segmentación de los frutos. Estudios previos muestran que la característica de textura es discriminante para la distinción entre estados de maduración [3] [4], motivo por el cual se explora en este trabajo su utilización para el proceso de segmentación. Trabajos anteriores han sido realizados sobre la segmentación de imágenes de frutos de café [2] [5] [6] [7] [8]. Además, muchos textos y artículos mencionan la relevancia del uso de la textura al llevar a cabo procesos de segmentación en distintos tipos de objetos [9] [10] [11].
En la sección 2 se discute el cálculo de las características de textura de los frutos de café a partir de la matriz de co-ocurrencia. En la sección 3 se presenta el sistema detector de bordes, cuyo núcleo central es un clasificador bi-clase. En la sección 4 se muestra el sistema de segmentación a partir de los bordes detectados y, en la sección 5 las pruebas y resultados obtenidos. Finalmente, la sección 6 presenta las conclusiones alcanzadas. El sistema fue desarrollado en el lenguaje C#® [12] y los análisis estadísticos PCA y Fisher así como los prototipos del aplicativo, se desarrollaron en MATLAB® [13].
2. CUANTIFICACIÓN DE LAS CARACTERÍSTICAS DE TEXTURA
Para realizar la segmentación se utiliza la imagen de bordes. Estas se obtienen analizando los indicadores derivados del análisis de la matriz de co-ocurrencia, cuantificados para las regiones que poseen píxeles dentro de un fruto. Las imágenes utilizadas corresponden a frutos de café en cereza tipo arábigo (Coffea Arabica), adquiridas bajo condiciones controladas de iluminación con un fondo azul de alto contraste, según se reporta en [7]. La figura 1 muestra un ejemplo de estas imágenes.

Figura 1. Imagen adquirida [7]
Figure 1. Acquired image [7]
Para discriminar el fondo de las imágenes de la información relevante, es decir, los frutos de café, se analizan los histogramas de las diferentes componentes de los espacios de color RGB, HSV, Colores Oponentes y OHTA.
El fruto se extrae del fondo para evitar que se realice el análisis de textura en esta última región, ya que las características de textura computadas usando la matriz de co-ocurrencia requieren de recursos computacionales altos, por lo que el tiempo aumentaría considerablemente.
De los histogramas analizados, el que ofrece mayor discriminación es de la componente de tono (H) en el espacio de color HSV. Es por esto que se decide utilizar dicho espacio de color para remover el fondo.
En la figura 2 puede observarse que los píxeles que corresponden a la clase "Fondo" se encuentran entre 150 y 200 aprox. Deben escogerse dos umbrales 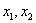 para asignar los píxeles a las clases "Fruto" o "Fondo". Un posible umbral es aquel que permita asignar un pixel a la clase a la que pertenece con mayor probabilidad, para lo cual se utiliza la regla de Bayes [14]. El umbral que separa las dos clases se encontrará en el
para asignar los píxeles a las clases "Fruto" o "Fondo". Un posible umbral es aquel que permita asignar un pixel a la clase a la que pertenece con mayor probabilidad, para lo cual se utiliza la regla de Bayes [14]. El umbral que separa las dos clases se encontrará en el 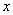 que produzca que la probabilidad de pertenencia a cada clase
que produzca que la probabilidad de pertenencia a cada clase 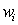 sea igual, es decir:
sea igual, es decir:
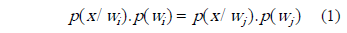
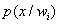 la probabilidad a priori por la cual pertenece a la clase
la probabilidad a priori por la cual pertenece a la clase 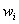 y,
y, 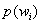 la función densidad de probabilidad de la clase para . Al modelar estas probabilidades con un comportamiento normal, puede obtenerse el umbral que divide las dos clases [14]. Los valores obtenidos para
la función densidad de probabilidad de la clase para . Al modelar estas probabilidades con un comportamiento normal, puede obtenerse el umbral que divide las dos clases [14]. Los valores obtenidos para 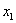 y
y 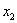 son 124.8 y 193.96, respectivamente, el cual corresponde a la realización alcanzada con el mejor desempeño. Esto, llevando a cabo 10 realizaciones de clasificadores utilizando una validación cruzada con un 70% de imágenes para entrenamiento y un 30% de imágenes para validación. La figura 3 muestra el error de validación para cada realización.
son 124.8 y 193.96, respectivamente, el cual corresponde a la realización alcanzada con el mejor desempeño. Esto, llevando a cabo 10 realizaciones de clasificadores utilizando una validación cruzada con un 70% de imágenes para entrenamiento y un 30% de imágenes para validación. La figura 3 muestra el error de validación para cada realización. 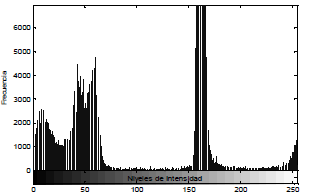
Figura 2. Ejemplo de histograma plano H
Figure 2. An example of histogram for the H component
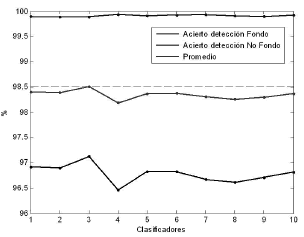
Figura 3. Indicadores de desempeño para los clasificadores
Figure 3. Performance of trained classifiers
La matriz de co-ocurrencia fue propuesta por Haralick [15] [16]. Esta se define como una matriz de frecuencias relativas
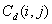 , en la cual dos píxeles, separados por un vector , ocurren en la imagen, el primero con una intensidad
, en la cual dos píxeles, separados por un vector , ocurren en la imagen, el primero con una intensidad 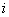 y el segundo con una intensidad
y el segundo con una intensidad 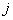 . Esto es, el valor de la matriz de co-ocurrencia
. Esto es, el valor de la matriz de co-ocurrencia 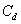 en la posición
en la posición 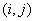 indica cuantas veces el valor coocurre con el valor en alguna relación espacial designada por el vector
indica cuantas veces el valor coocurre con el valor en alguna relación espacial designada por el vector 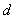 , el cual es un vector de desplazamiento
, el cual es un vector de desplazamiento 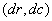 , donde
, donde 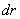 es un desplazamiento en filas (hacia abajo), y
es un desplazamiento en filas (hacia abajo), y 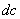 es un desplazamiento en columnas (hacia la derecha). Así, la matriz de co-ocurrencia de tipo asimétrico para una imagen en escala de grises I , está definida por [17]:
es un desplazamiento en columnas (hacia la derecha). Así, la matriz de co-ocurrencia de tipo asimétrico para una imagen en escala de grises I , está definida por [17]: 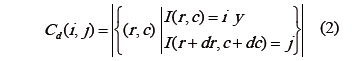
A partir de la matriz de co-ocurrencia se pueden extraer 11 características que describen la textura: energía, entropía, contraste, homogeneidad local, correlación, tendencia de clúster, directividad, momento de diferencia de orden k, momento inverso de diferencia de orden k, máxima probabilidad y varianza [18].
3. SISTEMA DETECTOR DE BORDES
Para el cómputo de las características derivadas de la matriz de co-ocurrencia, se toma un elemento estructurante cuadrado de 4x4, sobre las regiones de la imagen que no pertenecen a la clase Fondo (Sección 2.1).
3.1 Cuantificación y selección de las característicasPara el detector los bordes de la imagen, se supone que es posible asignar una región de fruto de 4x4 a una de dos clases: "Centro de Fruto" o "Borde". Esto, utilizando la información de las 11 características computadas de la matriz de co-ocurrencia, aplicada a cada uno de los planos de los espacios de color RGB, HSV, Colores Oponentes y OHTA (cada plano es considerado como una imagen en escala de grises), para un total de 121 indicadores. La figura 4 muestra 4 ejemplos de regiones de 4x4 sobre "Centro de Fruto" y "Borde".
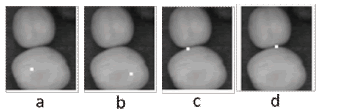
Figura 4. Ejemplos de elemento estructurante: a) y b) sobre "Centro de Fruto"; c) y d) sobre "Borde"
Figure 4. Structural element examples: a) and b) on " Fruit Center"; c) and d) on "Edge"
De la base de datos se toman 7 imágenes de frutos de café, cada una con 40 frutos en escena, aproximadamente. A estas se les extrae el fondo y se forman dos grupos de datos para la selección efectiva de las características discriminantes: grupo Centro de Fruto y grupo Borde de Fruto. El conjunto de 121 indicadores medidos para cada grupo es considerablemente grande, por lo que se utilizan los métodos de Índice de Discriminación de Fisher IDF y Análisis de Componentes Principales PCA, para determinar aquellos que permiten una mejor discriminación [19] [20].
La Tabla 1 muestra los 6 indicadores con mayor discriminación según el criterio de Fisher, siendo el más discriminante el de Homogeneidad Local medido en el plano C3 de Báez [21]. De otro lado, la Tabla 2 muestra las cinco características más relevantes según PCA, siendo la primera la Varianza en el plano V del espacio HSV.
Tabla 1. Primeras 6 posiciones del ranking realizado usando IDF
Table 1. First 6 positions according to IDF analysis
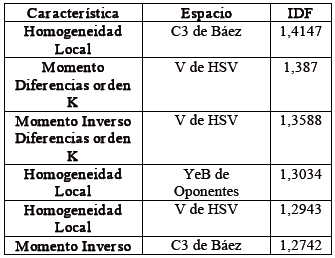
Tabla 2. Tabla de las primeras cinco características según PCA
Table 2. First five indicators given by PCA

3.2 Método de detección de regiones de borde
Una vez seleccionadas las características con mayor discriminación, se procede a clasificar las regiones de 4x4 hacia la clase "Centro de Fruto" o "Borde". Dos clasificadores fueron analizados: bayesiano y basado en umbrales.
3.2.1 Detección de bordes utilizando un clasificador bayesiano
Dada la gran cantidad de datos, es posible asumir que la probabilidad condicional 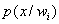 (probabilidad de que la observación x pertenezca a la clase ), presenta un comportamiento normal, permitiendo modelar dicha probabilidad como:
(probabilidad de que la observación x pertenezca a la clase ), presenta un comportamiento normal, permitiendo modelar dicha probabilidad como:
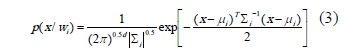
con un vector con d características computadas a un cuadro 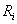 de 4x4,
de 4x4, 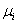 el vector de medias para la clase y
el vector de medias para la clase y 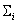 la matriz de covarianza para la misma clase. Utilizando la teoría de decisión bayesiana para distribuciones normales [14], se asigna una función discriminante
la matriz de covarianza para la misma clase. Utilizando la teoría de decisión bayesiana para distribuciones normales [14], se asigna una función discriminante 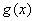 por clase , así:
por clase , así:
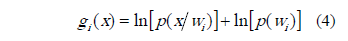
con 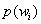 la probabilidad a priori para la clase. La observación x medida sobre es asignada a la clase cuya función discriminante sea mayor [14]:
la probabilidad a priori para la clase. La observación x medida sobre es asignada a la clase cuya función discriminante sea mayor [14]:
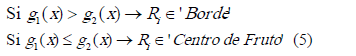
Así, se divide la imagen con el fondo extraído 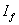 (sección 2.1), en segmentos cuadrados de 4x4 píxeles , tal que:
(sección 2.1), en segmentos cuadrados de 4x4 píxeles , tal que:
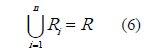
con 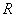 el conjunto de cuadros de 4x4 , los cuales se definen como:
el conjunto de cuadros de 4x4 , los cuales se definen como:
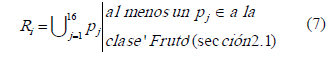
tal que 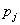 es un pixel dentro del cuadro . Así, es el conjunto de cuadros de 4x4 que contienen los píxeles que serán analizados para detectar los bordes. Cada es caracterizado utilizando los indicadores con mayor discriminación (sección 3.1), computados de su matriz de co-ocurrencia. Utilizando un clasificador bayesiano, la región es asignada a la clase "Centro de Fruto" o "Borde", utilizando para ello la ecuación (5). La figura 5 muestra un ejemplo de bordes obtenidos utilizando el clasificador bayesiano, con la imagen de la figura 1 como entrada. Nótese el ancho de los bordes es cual es de, al menos, 4 píxeles dado el tamaño de .
es un pixel dentro del cuadro . Así, es el conjunto de cuadros de 4x4 que contienen los píxeles que serán analizados para detectar los bordes. Cada es caracterizado utilizando los indicadores con mayor discriminación (sección 3.1), computados de su matriz de co-ocurrencia. Utilizando un clasificador bayesiano, la región es asignada a la clase "Centro de Fruto" o "Borde", utilizando para ello la ecuación (5). La figura 5 muestra un ejemplo de bordes obtenidos utilizando el clasificador bayesiano, con la imagen de la figura 1 como entrada. Nótese el ancho de los bordes es cual es de, al menos, 4 píxeles dado el tamaño de .

Figura 5. Imagen de bordes obtenida utilizando el clasificador bayesiano
Figure 5. Edge image computed using the Bayesian classifier
Para disminuir la necesidad del cómputo de las funciones discriminantes
, se diseñó un detector de bordes basado en un clasificador que utiliza umbrales. Los umbrales de decisión se hallaron de manera empírica, utilizando para ello el histograma del indicador de textura con mayor discriminación, según los criterios de IDF y PCA (Tablas 1, 2). El experimento para seleccionar el umbral evalúa el rendimiento del sistema para diversos valores de umbral en un solo indicador (clasificador unidimensional), escogiendo aquel clasificador con mejor rendimiento. En la sección 5 se reportan los resultados para cada caso.
4. SEGMENTACIÓN USANDO LA IMAGEN DE REGIONES DE BORDE
Luego de hallada una imagen de bordes como la mostrada en la figura 5, se procede a realizar la segmentación. Para ello, los bordes son adelgazados a un píxel de ancho, utilizando la operación morfológica de adelgazamiento, como lo muestra la figura 6 [22] [23]. Posteriormente, la imagen resultante es etiquetada, hallando así las regiones arco-conexas contenidas en la escena. La figura 7 muestra la imagen segmentada.
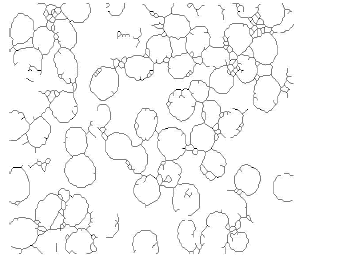
Figura 6. Imagen de bordes adelgazados
Figure 6. Image with thinned edges

Figura 7. Segmentación resultante
Figure 7. Resulting image segmentation
5. PRUEBAS Y RESULTADOS
Para cuantificar el rendimiento de la segmentación alcanzada con cada detector de bordes, se utilizaron las métricas de desempeño propuestas en [24]: detecciones correctas (CD), sobre-segmentación (OS), sub-segmentación (US), ruido (N) y regiones perdidas (M). Para ello se hace necesaria la realización de imágenes de Ground Truth (referencia), como la mostrada en la figura 8.

Figura 8. Imagen de referencia (Ground Truth)
Figure 8. Ground Truth image
Las figuras 9, 10 muestran el rendimiento del sistema de segmentación bayesiano cuya entrada es el vector de características resultante del análisis de componentes principales comparado con otros sistemas de segmentación. La combinación Bayes-PCA presenta mejor desempeño en los indicadores de rendimiento que el sistema Bayes-Fisher, como se muestra en las figuras 11 y 12.
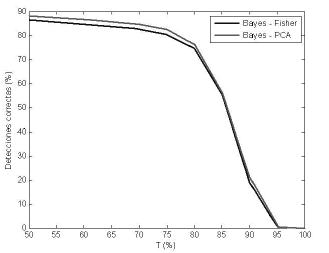
Figura 9. Detecciones correctas: Bayes-PCA Vs Bayes-Fisher
Figure 9. Correct detection: Bayes-PCA Vs Bayes-Fisher
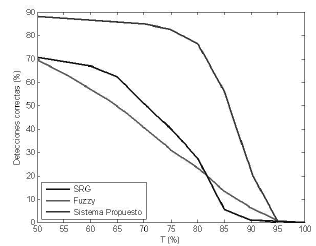
Figura 10. Detecciones correctas: comparación con otras investigaciones
Figure 10. Correct detection: comparison with other systems
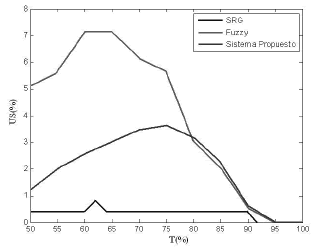
Figura 11. Sub-segmentación
Figure 11. Under-segmentation
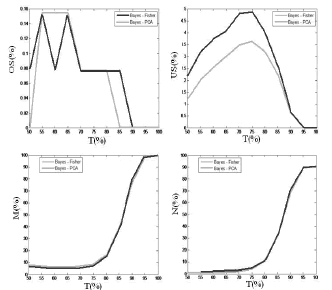
Figura 12. Indicadores de desempeño Bayes-PCA Vs Bayes-Fisher. a) OS, b) US, c) M, d) N
Figure 12. Performance indicators Bayes-PCA Vs Bayes-Fisher. a) OS, b) US, c) M, d) N
DISCUSIÓN
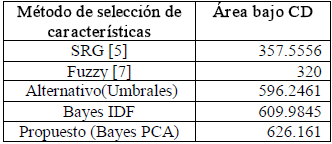
La figura 9 muestra el desempeño para los sistemas bayesianos óptimos, utilizando las características efectivas calificadas según IDF y PCA. Se observa que el mejor desempeño es alcanzado con las características de PCA, con un nivel de detecciones correctas del 90% a un nivel de tolerancia del 50%. Además, esta segmentación, es comparada con [5] [6] [7] [8]. Para el caso de las regiones detectadas correctamente (figura 10), el índice es mejorado notoriamente respecto de los reportados en [6] y [7]. Para la mayor parte de niveles de tolerancia, la curva de los sistemas de segmentación supera en un 25% a [6] [7] [8]. En cuanto a [5], para niveles de tolerancia entre 50% y 80%, el porcentaje de regiones detectadas correctamente no es mayor que 68%, por lo cual se ve también superado por el sistema propuesto. La tabla 3 indica el área bajo la curva de Detecciones Correctas, para los sistemas evaluados. A mayor área, mejor desempeño del sistema, siendo el ideal un área de 1100.
Tabla 3. Área bajo la curva de Detecciones Correctas
Table 3. Area for CD curve
En la figura 12.b) se muestran las curvas del índice de sub-segmentación para los dos sistemas bayesianos diseñados. De la figura 11, se observa que el sistema Bayes-PCA presenta una mejora para este índice respecto del reportado en [8]; sin embargo, tiene un menor desempeño al reportado en [5]. Cabe destacar que el sistema SRG es uno de delineación, y que debe colocarse de manera anticipada las regiones semilla para cada región, lo que no ocurre con el sistema fuzzy [8] y en el propuesto en este artículo, que detectan automáticamente los frutos. No obstante, una posible causa de sub-segmentación es discutida en la sección 5.1.1.
En el caso del índice de sobresegmentación, en la mayor parte del tramo de tolerancias resulta ser menor la combinación Bayes-PCA, haciéndose nula para T>80%. La combinación Bayes-Fisher se hace nula en T>90%. En el caso de regiones fallidas y regiones ruido, las dos combinaciones analizadas presentan un comportamiento muy similar.
Las figuras 13 y 14 muestran los indicadores de desempeño para el enfoque alternativo de umbrales. Se nota que en el caso de detecciones correctas el indicador resultante de PCA presenta mejor desempeño que el respectivo indicador de Fisher, aunque en el caso de detecciones correctas las gráficas descienden más rápido comparadas con el caso bayesiano. El resto de indicadores presenta un comportamiento similar al que se tiene con el caso bayesiano, llevando a las mismas conclusiones.
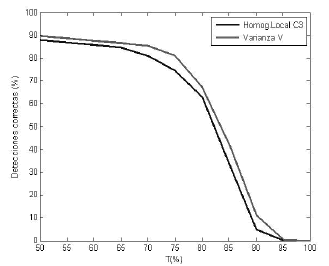
Figura 13. Detecciones correctas para el método alternativo de umbrales
Figure 13. Correct detection for alternative method using thresholding
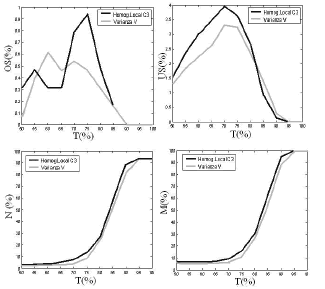
Figura 14. Indicadores de desempeño para Umbral-PCA Vs Umbral-Fisher a) OS, b) US, c) M, d) N
Figure 14. Performance indicators for Threshold-PCA Vs Threshold-Fisher a) OS, b) US, c) M, d) N
5.1.1 Hipótesis sobre granos que se encuentran en los bordes de la imagen o superpuestos (unos sobre otros)
Al observar las distintas imágenes después del proceso de segmentación, se aprecia un fenómeno que afecta directamente el desempeño del sistema. El sistema diseñado presenta dificultades en dos casos específicos:
- Frutos que se encuentran cortados por el marco de la imagen.
- Frutos que se encuentran superpuestos unos sobre otros.
En la figura 15 se muestran un ejemplo para cada caso mencionado. Se nota que las regiones que cumplen una de estas dos condiciones terminan siendo instancias de sub-segmentación. Este problema podría evitarse en la etapa de adquisición. En la figura 16 se muestra el índice de Detecciones Correctas para frutos que cumplen la hipótesis (figura 15). Se observa que el índice aumenta en un 10% a un nivel de tolerancia de 50. No obstante, este es un resultado preliminar que debe ser validado con imágenes adquiridas donde no haya oclusiones ni frutos truncados.
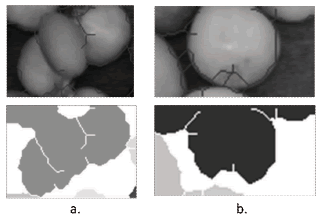
Figura 15. Casos donde el sistema incurre en US: a) Frutos superpuestos, b) Frutos cortados por el borde de la imagen
Figure 15. Instances that cause US: a) Overlapped cherries, b) Cherries truncated by the frame of the image
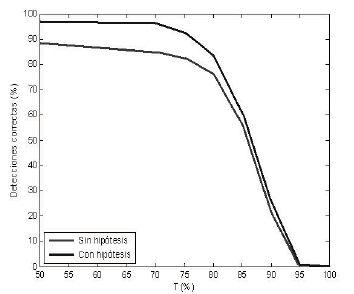
Figura 16. Detecciones Correctas con imágenes que cumplen hipótesis
Figure 16. Correct Detection computed on images that achieve the hypothesis
6. CONCLUSIONES
Se muestra un detector de regiones de borde utilizando la información de textura y un clasificador bi-clase. Dicho detector es validado en imágenes de frutos de café y se demuestra en este trabajo la importancia de la información de textura en la detección de sus bordes, donde el enfoque estadístico planteado a través de indicadores extraídos de la matriz de Haralick o de co-ocurrencia, muestra que algunos de estos permiten una alta discriminación entre las clases "Centro de Fruto" y "Borde". Las características discriminantes de textura se escogieron sobre una población total de 121 indicadores, cuyo nivel de discriminación es cuantificado utilizando el método de Fisher y el de PCA.
Dos clasificadores bi-clase fueron probados: un clasificador bayesiano y un clasificador alternativo (basado en umbrales). El método alternativo se diseña con el objetivo de obtener un clasificador sencillo, de menor complejidad computacional aunque presenta menor estabilidad en su rendimiento (detecciones correctas), al aumentar el nivel de tolerancia T(%) comparados con el enfoque de Bayesiano.
El rendimiento alcanzado por cada sistema oscila alrededor del 90% de regiones detectadas correctamente (para T=50%), con un grado de sub-segmentación máximo de 4%. Aunque este desempeño aún no es el deseado, mejora sustancialmente los desempeños de herramientas anteriores. Al eliminar del análisis de resultados aquellos frutos superpuestos o cortados por los límites de la imagen, se alcanza un rendimiento del 97% en regiones detectadas correctamente (para T= 50%), el cual es el desempeño mínimo requerido para el sistema de Visión Completo (adquisición + segmentación + reconocimiento).
Se menciona el método de umbralización, como experimental dejando como trabajo futuro darle una justificación teórica (detección automática del umbral óptimo), y el análisis de otros métodos de clasificación.
7. AGRADECIMIENTOS
Los autores agradecen la asesoría de la Ing. Zulma Liliana Sandoval Niño, docente de la Universidad Pedagógica y Tecnológica de Colombia Sede Sogamoso, y autora de [3] [4].
REFERENCIAS
[1] FEDERACIÓN NACIONAL DE CAFETEROS. El comportamiento de la industria cafetera colombiana durante el 2007 [online]. P54. Chinchiná, Colombia . 2008. [ Links ]
[2] MONTES, N., PRIETO, F. AND OSORIO, G. Visual Segmentation of Fruits: An Application to Coffee Beans [Tesis de Maestría]. Manizales, Colombia: Universidad Nacional de Colombia Sede Manizales. 2003. [ Links ]
[3] SANDOVAL, Z. AND PRIETO, F. Descripción y clasificación de frutos de café en cereza usando vision artificial [Tesis de Maestría]. Manizales, Colombia: Universidad Nacional de Colombia Sede Manizales. 2005. [ Links ]
[4] SANDOVAL, Z. AND PRIETO, F. Caracterización de Café en Cereza empleando Técnicas de Visión Artificial. Rex.Fac.Nal.Agr.Medellín., 60, No.2, 4105-4127, 2007. [ Links ]
[5] MONTES, N. Desarrollo de algoritmo de segmentación de frutos maduros y verdes de café en imágenes tomadas en condiciones controladas, basados en la propiedad de color [Tesis de Pregrado]. Manizales, Colombia: Universidad Nacional de Colombia Sede Manizales. 2001. [ Links ]
[6] BETANCUR, J., PRIETO, F, AND OSORIO, G. Segmentación de frutos de café mediante métodos de crecimiento de regiones. Rev.Fac.Nal.Agr.Medellín, 59, No. 1, 3311-3333. 2006. [ Links ]
[7] BETANCUR, J. AND PRIETO, F. Active Contour-Based Segmentation of Coffee Cherries Images. Proceedings of the ICSP"08 (International Conference on Signal Processing). Beijing, China , Tomo III, Octubre de 2008. [ Links ]
[8] BETANCUR, J. AND PRIETO, F. Segmentación de imágenes mediante estrategias de lógica y conjuntos difusos [Tesis de Maestría]. Manizales, Colombia: Universidad Nacional de Colombia Sede Manizales. 2005. [ Links ]
[9] CASELLES VICENT, FRANGI ALEJANDRO. La Segmentación De Imágenes: El Método De Los Contornos Activos Geométricos, Departamento De Tecnología, Universitat Pompeu Fabra. [ Links ]
[10] CHI FOK Y BOUZERDOUM ABDESSELAM. A non linear extractor for texture segmentation. University of Wollongong, 2007. [ Links ]
[11] YOO TERRY. Insight into Images: Principles and practice for segmentation, registration and image analysis. Wesllesley, Massachusetts : A.K. Peters, 2004. [ Links ]
[12] KIMMEL PAUL. Advanced C# Programming. McGraw Hill, 2002 [ Links ]
[13] GONZALEZ, R; WOODS, R. AND EDDINS, S Digital Image Processing using MATLAB. Prentice Hall, Upper-Saddle River, New Jersey 07458, First edition, 2003. [ Links ]
[14] DUDA, R., HART, P. AND STORK, D. Pattern Classification. John Wiley and Sons, 2ed. 2001. [ Links ]
[15] HARALICK, R. AND SHANMUGAN, K. Textural Features For Image Classification. IEEE Transactions on Syst., Man., Cybern., Vol. Dmc-3, 610-621. 1973. [ Links ]
[16] HARALICK, R. Statistical and Structural Approaches to Texture. IEEE Transactions on SMC, 3, 610-621, 1979. [ Links ]
[17] SHAPIRO, L AND STOCKMAN, G. Computer Vision. Prentice Hall, United States of America . 2000. [ Links ]
[18] BEVK, M. AND KONONENKO, I. Statistical Approach to texture description of medical images: A preliminary study. Proceedings of the 15th IEEE Symposium on Computer-Based Medical Systems, 239-244. 2002. [ Links ]
[19] JOHNSON, R. AND WICHERN, D. Applied multivariate statistical analysis, Prentice Hall, fifth edition. 2002. [ Links ]
[20] HAIR, J., ANDERSON, R., TATHAM, R. AND BLACK, W. Multivariate analysis, Prentice Hall, fifth edition, 1999. [ Links ]
[21] BÁEZ, J., GUERRERO, M., CODE, J., PADILLA, A. AND UREID, D. Segmentación de imágenes de color. Revista Mexicana de Física, 2004. Vía Internet: http://redalyc.uaemex.mx/redalyc/src/inicio/ArtPdfRed.jsp?iCve=57050605. [ Links ]
[22] GONZALEZ, R AND WOODS, R. Digital Image Processing. Prentice Hall, Upper-Saddle River, New Jersey 07458, Third Edition, 2002. [ Links ]
[23] LAM L.; SEONG-WHAN LEE Y CHING Y. SUEN. Thinning Methodologies A Comprehensive Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol 14, No. 9, 1992. p 879 [ Links ]
[24] MIN, J., POWELL, M. AND BOWYER, K. Automated performance evaluation of range image segmentation. IEEE workshop on applications of computer vision. 2000. [ Links ]

