










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353On-line version ISSN 2346-2183
Dyna rev.fac.nac.minas vol.79 no.171 Medellín Jan./Feb. 2012
PARAMETER SELECTION IN LEAST SQUARES-SUPPORT VECTOR MACHINES REGRESSION ORIENTED, USING GENERALIZED CROSS-VALIDATION
SELECCIÓN DE PARÁMETROS EN MÍNIMOS CUADRADOS-MÁQUINAS DE VECTORES DE SOPORTE ORIENTADAS A REGRESIÓN, UTILIZANDO VALIDACIÓN CRUZADA GENERALIZADA
ANDRÉS M. ÁLVAREZ MEZA
Eng., Signal Processing and Recognition Group, Universidad Nacional de Colombia, Sede Manizales, amalvarezme@unal.edu.co
GENARO DAZA SANTACOLOMA
PhD., Universidad Antonio Nariño, Sede Bogotá, ensamblegl@gmail.com
CARLOS D. ACOSTA MEDINA
PhD., Scientific Computing and Mathematical Modeling Group, Universidad Nacional de Colombia, Sede Manizales, cdacostam@unal.edu.co
GERMÁN CASTELLANOS DOMÍNGUEZ
PhD., Signal Processing and Recognition Group, Universidad Nacional de Colombia, Sede Manizales, cgcastellanosd@unal.edu.co
Received for review November 5th, 2010, accepted October 31th, 2011, final version November, 21th, 2011
ABSTRACT: In this work, a new methodology for automatic selection of the free parameters in the least squares-support vector machines (LS-SVM) regression oriented algorithm is proposed. We employ a multidimensional generalized cross-validation analysis in the linear equation system of LS-SVM. Our approach does not require prior knowledge about the influence of the LS-SVM free parameters in the results. The methodology is tested on two artificial and two real-world data sets. According to the results, our methodology computes suitable regressions with competitive relative errors.
KEYWORDS: parameter selection, least squares-support vector machines, multidimensional generalized cross validation, regression
RESUMEN: En este trabajo, se propone una metodología para la selección automática de los parámetros libres de la técnica de regresión basada en mínimos cuadrados máquinas de vectores de soporte (LS-SVM), a partir de un análisis de validación cruzada generalizada multidimensional sobre el conjunto de ecuaciones lineales de LS-SVM. La técnica desarrollada no requiere de un conocimiento a priori por parte del usuario acerca de la influencia de los parámetros libres en los resultados. Se realizan experimentos sobre dos bases de datos artificiales y dos bases de datos reales. De acuerdo a los resultados obtenidos, se concluye que el algoritmo desarrollado calcula regresiones apropiadas con errores relativos competentes.
PALABRAS CLAVE: selección de parámetros, mínimos cuadrados-máquinas de vectores de soporte, validación cruzada generalizada multidimensional, regresión
1. INTRODUCTION
Solving machine learning problems requires for one to suitably fix the needed free parameters of the system in order to obtain reliable results according to the given application such as: data preprocessing, feature extraction, classification, and regression [6,17,18]. Particularly, in order to solve a regression problem, it is necessary to generate a methodology that analyzes, interprets, and discerns patterns, finding the relationships between the outputs and inputs of the system. In this sense, some algorithms have been developed based on statistical models and artificial neural networks (ANNs) [1,2]. Nonetheless, in most cases these techniques overfit the regression system due to the large number of parameters to fix, and the little prior user knowledge about the relevance of the inputs in the analyzed problem [3].
This is why support vector machines (SVMs) have been developed as an alternative that avoids such limitations. Their practical successes can be attributed to solid theoretical foundations based on VC-theory [4]. The SVM computes globally optimal solutions, unlike those obtained with ANNs, which tend to fall into local minima. However, many SVM application studies are performed by expert users having a good understanding of the SMV methodology [5]. Therefore, the quality of SMV models depends on a proper setting of a considerable number of parameters. Moreover, the SVM algorithm demands a high-computational load due to the form of its optimization problem.
In this sense, the least squares-support vector machines (LS-SVM) method is proposed in [6], which is a reformulation of the traditional SVM algorithm. The LS-SVM uses a regularized least squares function with equality constraints, leading to a linear system which meets the Karush-Kuhn-Tucker (KKT) conditions for obtaining an optimal solution. Consequently, the regression problem can be solved by a linear equation system rather than quadratic programming, as in SVM.
Although LS-SVM simplifies the SVM procedure, the regularization parameter and the kernel parameters play an important role in the regression system. Therefore, it is necessary to establish a methodology for properly selecting the LS-SVM free parameters, in such a way that the regression obtained by LS-SVM must be robust against noisy conditions, and it does not need priori user knowledge about the influence of the free parameters values in the problem studied.
Cherkassky et al. [5] present a methodology to choose the regularization value in SVM from an analytic analysis over the regression function, which is similar to the LS-SVM one. Moreover, they employ a Gaussian kernel to train the system. However, this approach does not consider the direct possible influence of the band-width kernel parameter, which is manually fixed. In this sense, the user must infer the kernel parameter value according to his/her prior knowledge about the problem, over-fitting the regression system. Again, in Zhou et al. [7] a multi-parameter selection in LS-SVM is proposed. Even though this technique computes a competitive regression, it requires the assumption of some parameter values for the quantum-behaved particle swarm optimization (QPSO) algorithm, which can be unsuitable. Besides, they just test the proposed multi-parameter selection technique using a single database, which is perturbed with Gaussian noise. As a result, it is not possible to ensure reliable performance over different data sets.
In this paper, a new methodology for choosing the regularization and Gaussian kernel band-width parameters in LS-SVM is proposed. We analyze the LS-SVM linear system using the generalized cross-validation (GCV) technique [8,9] in order to simultaneously infer the free parameters. Our approach does not require a prior knowledge about the influence of the LS-SVM parameters in the regression results.
The proposed algorithm is experimentally verified on two artificial and two real-world data sets. The regression quality is measured using the relative error between the target and the predicted sample.
This paper is organized as follows: Section 2 gives a brief introduction to the LS-SVM algorithm and the GCV methodology. Section 3 describes the algorithm proposed to simultaneously select the LS-SVM free parameters (regularization parameter and Gaussian kernel band-width). Section 4 presents the experimental conditions and shows the regression results obtained. Finally, the discussion and conclusions are given in Sections 5 and 6.
2. BACKGROUND
2.1 Least squares-support vector machines LS-SVM
Let 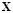 be the
be the 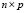 input data matrix, and
input data matrix, and 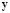 the
the 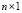 output vector. Given the
output vector. Given the 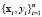 training data set, with
training data set, with 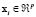 , and
, and 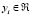 , the LS-SVM goal is to construct the function
, the LS-SVM goal is to construct the function 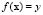 , which represents the dependence of the output
, which represents the dependence of the output 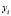 on the input
on the input 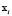 . This function is formulated as
. This function is formulated as
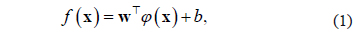
where 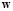 and
and 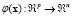 are
are 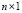 column vectors, and
column vectors, and 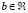 . The LS-SVM algorithm [6] computes the function (1) from a similar minimization problem found in the SVM method [4]. However, the main difference is that LS-SVM involves equality constraints instead of inequalities, and it is based on a least square cost function. Furthermore, the LS-SVM method solves a linear problem while conventional SVM solves a quadratic one. More precisely, the optimization problem and the equality constraints of LS-SVM are defined as follows:
. The LS-SVM algorithm [6] computes the function (1) from a similar minimization problem found in the SVM method [4]. However, the main difference is that LS-SVM involves equality constraints instead of inequalities, and it is based on a least square cost function. Furthermore, the LS-SVM method solves a linear problem while conventional SVM solves a quadratic one. More precisely, the optimization problem and the equality constraints of LS-SVM are defined as follows:
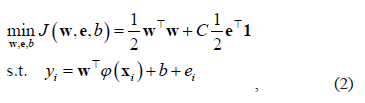
where 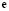 is the
is the 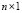 error vector,
error vector, 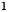 is an
is an 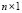 vector with all entries 1, and
vector with all entries 1, and 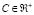 is the tradeoff parameter between the solution size and training errors. From (2) a Lagrangian is formed, and differentiating with respect to
is the tradeoff parameter between the solution size and training errors. From (2) a Lagrangian is formed, and differentiating with respect to 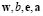 (
( : Lagrangian multipliers), we obtain
: Lagrangian multipliers), we obtain
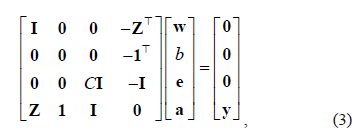
where 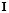 represents the identity matrix and
represents the identity matrix and 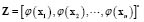 .
.
From rows one and three in (3) 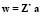 and
and 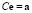 . Then, by defining the kernel matrix
. Then, by defining the kernel matrix 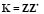 , and the parameter
, and the parameter 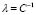 , the conditions for optimality lead to the following overall solution:
, the conditions for optimality lead to the following overall solution:
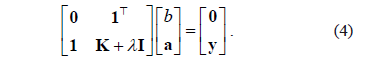
In this work, we consider the Gaussian Kernel, which is defined as
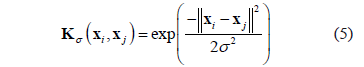
We can obtain the solution of the linear equation system presented in (4) as
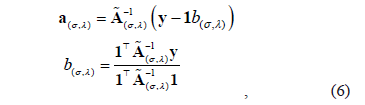
with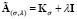 . Hence, Eq. (1) can be rewritten as a function of the Lagrangian multipliers
. Hence, Eq. (1) can be rewritten as a function of the Lagrangian multipliers
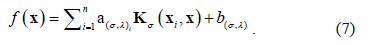
Taking into account Eq. (7), the LS-SVM performance depends of two free parameters: 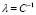 and
and 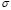 . In this sense, it is necessary to develop a methodology for finding suitable values of the LS-SVM free parameters.
. In this sense, it is necessary to develop a methodology for finding suitable values of the LS-SVM free parameters.
We use the generalized cross-validation (GCV) method for analyzing the linear equation system (4) to fix the free parameters of LS-SVM. Next, a brief description of GCV is presented.
2.2 Generalized Cross-Validation (GCV)
For dealing with ill-conditioned matrices 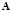 , the regularization techniques are based on approximations of the form
, the regularization techniques are based on approximations of the form 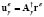 , where
, where 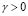 is the regularization parameter,
is the regularization parameter, 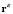 is a column vector with the estimated measures,
is a column vector with the estimated measures, 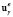 is a column vector containing the calculated solutions, and
is a column vector containing the calculated solutions, and 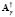 is a stable, easy to compute approximation of the generalized inverse of
is a stable, easy to compute approximation of the generalized inverse of 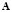 .
.
The GCV algorithm [8,9] looks for a 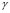 value that allows for one to obtain a suitable balance between the regularization error and the perturbation in the solution. In this sense, the GCV method calculates the
value that allows for one to obtain a suitable balance between the regularization error and the perturbation in the solution. In this sense, the GCV method calculates the 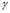 value that minimizes
value that minimizes
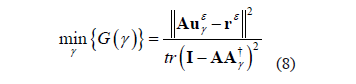
3. LS-SVM FREE PARAMETER SELECTION
In this work, we relate the linear equation system (4) with a problem of the form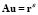 , in order to fix the free parameters of LS-SVM (
, in order to fix the free parameters of LS-SVM (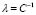 ,
,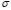 ) using the GCV method. Nevertheless, it should be noted that the original GCV algorithm method (8) was designed for the selection of a single parameter. For this reason, it is necessary to formulate the inverse problem of LS-SVM, in order to select its two free parameters simultaneously. Other similar approaches of the GCV method for choosing multiple parameters can be found in [10,11]. Based on the linear system presented in (4), we propose to set the relationships between LS-SVM and GCV as
) using the GCV method. Nevertheless, it should be noted that the original GCV algorithm method (8) was designed for the selection of a single parameter. For this reason, it is necessary to formulate the inverse problem of LS-SVM, in order to select its two free parameters simultaneously. Other similar approaches of the GCV method for choosing multiple parameters can be found in [10,11]. Based on the linear system presented in (4), we propose to set the relationships between LS-SVM and GCV as
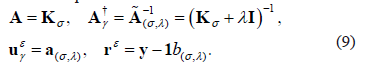
Note that 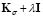 is positive definite. Hence, the GCV function to be considered is
is positive definite. Hence, the GCV function to be considered is
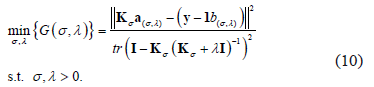
The above optimization problem is generally referred to as a constrained nonlinear optimization. It can be solved using the active-set optimization algorithm, which uses a sequential quadratic programming (SQP) method [12,13]. We will use its implementation in the fmincon Matlab routine.
To avoid over-fitting in the initialization of the unknown variables in (10), we propose the following procedure: First, we choose the initial value of 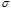 according to Sylverman's rule [14]:
according to Sylverman's rule [14]:
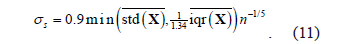
where 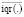 computes the average interquartil range and
computes the average interquartil range and 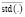 calculates the average standard deviation. Then, we select the initial value of
calculates the average standard deviation. Then, we select the initial value of 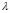 (
(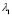 ), minimizing Eq. (10) with
), minimizing Eq. (10) with 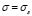 . We fix the bounds of
. We fix the bounds of 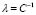 according to [8]:
according to [8]:
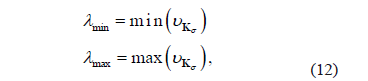
where 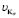 contains the eigenvalues of
contains the eigenvalues of 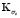 greater than zero.
greater than zero.
Later, we use 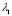 and
and 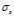 as initial values to minimize (10), setting the bounds of
as initial values to minimize (10), setting the bounds of 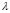 as in (12) and the bounds of
as in (12) and the bounds of 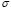 as
as
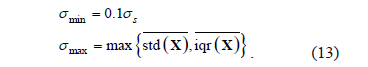
Finally, the optimal values 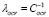 and
and 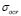 that minimize (10) are used for training the regression system base on the LS-SVM algorithm. The proposed methodology can be summarized as presented in Fig. 1.
that minimize (10) are used for training the regression system base on the LS-SVM algorithm. The proposed methodology can be summarized as presented in Fig. 1.
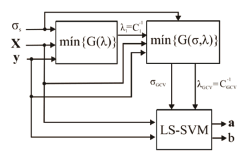
Figure 1. Proposed scheme for the LS-SVM parameter selection
4. EXPERIMENTS
Two artificial and two real-world data sets are tested. We employ a 10-fold cross validation analysis to determinate the experiment's generalization and robustness. For each fold we randomly select a training set, which is used to calculate the LS-SVM parameters according to the proposed approach, and it is also employed to train the LS-SVM regression algorithm. The remaining data is used as test set. We compute the relative error (RE) over the test set according to Eq. (14), and the performance of the system is calculated as the mean relative error (MRE) for the 10-folds.
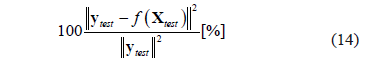
4.1 Artificial data sets
The first artificial data set is the univariate Sinc function, which has been studied in [6,7]. This function is defined as
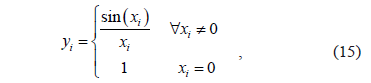
where 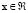 . We generate 300 observations. The vector
. We generate 300 observations. The vector is taken from a uniform grid in the
is taken from a uniform grid in the 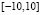 interval. We randomly select 150 samples as a training set and the remaining 150 conforms the test set. Moreover, the training output samples are perturbed with Gaussian noise (
interval. We randomly select 150 samples as a training set and the remaining 150 conforms the test set. Moreover, the training output samples are perturbed with Gaussian noise (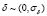 ). In Table 1 the MRE for the Sinc data set is shown for different noise conditions. Besides, the
). In Table 1 the MRE for the Sinc data set is shown for different noise conditions. Besides, the 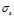 ,
, 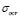 ,
, 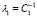 and
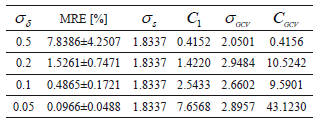
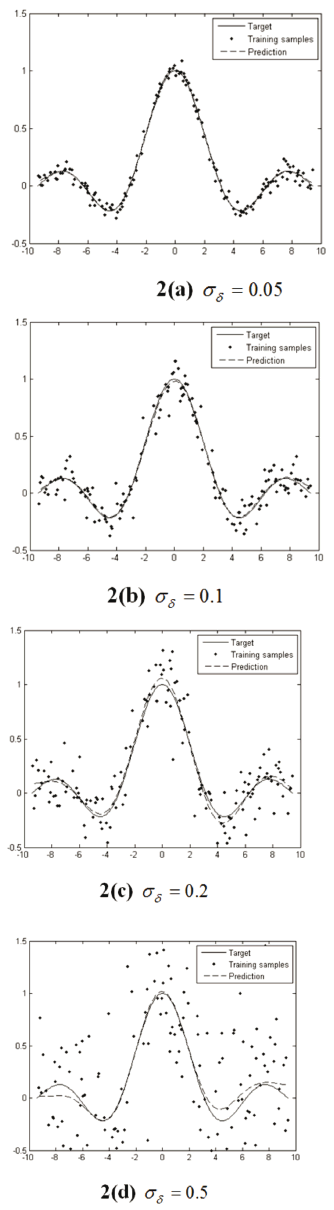
and 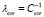 parameter values are presented for the lowest relative error. Additionally, in Fig. 2 some regression results for the Sinc data set are presented.
parameter values are presented for the lowest relative error. Additionally, in Fig. 2 some regression results for the Sinc data set are presented.
The second artificial data set corresponds to the function Sinc3D, which is also analyzed in [5] and can be calculated as
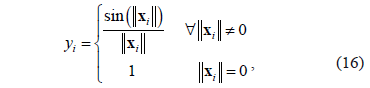
where 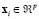 . We compute 845 observations. The
. We compute 845 observations. The  values are sampled on a uniform square lattice
values are sampled on a uniform square lattice 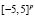 (p = 2). We randomly select 169 samples as training set and the remaining 676 as a test set. Besides, the training set is perturbed with Gaussian noise (
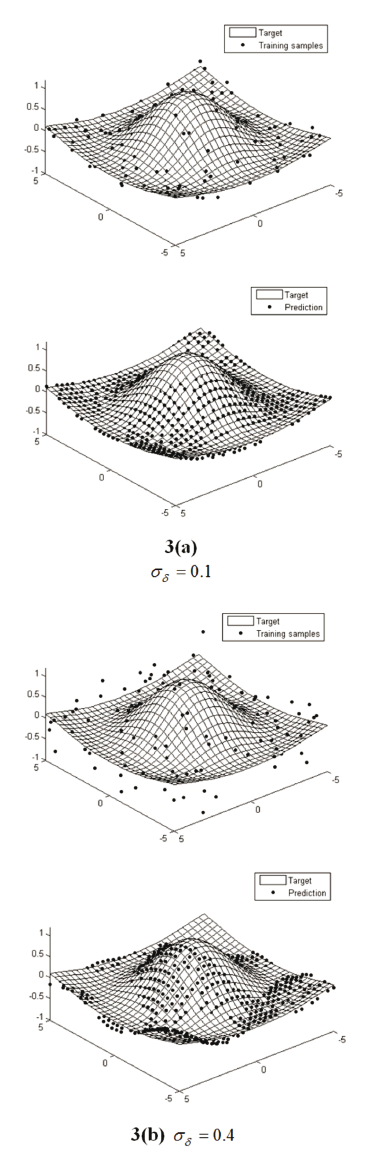
(p = 2). We randomly select 169 samples as training set and the remaining 676 as a test set. Besides, the training set is perturbed with Gaussian noise (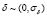 ). In Table 2 and Fig. 3, the Sinc3D results are shown.
). In Table 2 and Fig. 3, the Sinc3D results are shown.

4.1 Real-world data sets
The first real-world data set corresponds to the concrete compressive strength (CCS) [15], which is a highly nonlinear function of the time and ingredients. Eight variables are measured: including cement, blast furnace slag, fly ash, water, super plasticizer, coarse aggregate, fine aggregate, and time. There are 1030 observations (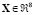 ), and the goal is to predict the CCS (
), and the goal is to predict the CCS (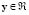 ) for different input conditions. In this case, we train the regression system with 309 random samples, and the MRE is calculated on the remaining 721 data. In Table 3 and Fig. 4, the CCS data set results are presented.
) for different input conditions. In this case, we train the regression system with 309 random samples, and the MRE is calculated on the remaining 721 data. In Table 3 and Fig. 4, the CCS data set results are presented.

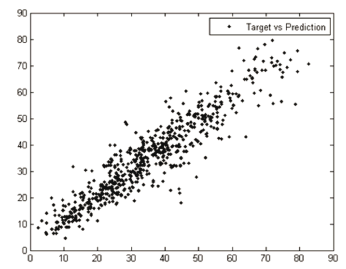
Figure 4. Target vs. prediction (CCS)
Finally, the European Climate Assessment (ECA) real-world data set [16] is tested. This database is a daily weather summary of Berlin, Germany from between 2001 to 2004. Nine variables are measured: cloud cover, mean relative humidity, mean barometric pressure, snow depth, precipitation amount, sunshine, amount of rain, minimum air temperature, maximum air temperature, and mean air temperature. In our experiments, we analyze the relationships between the mean air daily temperature and the remaining meteorological features. Therefore, we have 1465 observations, where 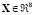 and
and 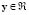 . We randomly choose 439 samples for the training set, and 1026 for the test set. In Table 5 the ECA data set results are presented. For illustration, see Fig. 5.
. We randomly choose 439 samples for the training set, and 1026 for the test set. In Table 5 the ECA data set results are presented. For illustration, see Fig. 5.

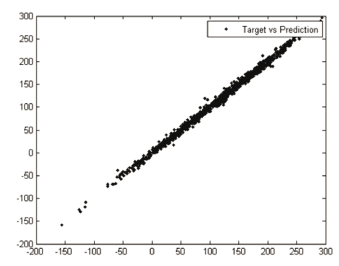
Figure 5. Target vs. prediction (ECA)
5. DISCUSSION
According to the obtained results shown in Table 1 and Fig. 2, it is possible to notice that the proposed methodology for choosing the values of 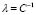 and
and 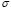 in the LS-SVM algorithm, allows for one to find suitable regression results for the Sinc database.
in the LS-SVM algorithm, allows for one to find suitable regression results for the Sinc database.
Our methodology improves the results presented in Zhou et al. [7], where a RE of 2.3141[%] is reported for a similar experiment (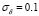 ). Even when this technique computes competitive regression, it requires the assumption of some free parameter values for the QPSO algorithm, which can be undesirable when the user does not have prior knowledge about the phenomenon. Besides, no more experiments with different noise conditions are presented; so only limited conclusions can be reached. On the other hand, our methodology shows a suitable performance, even for different noise conditions.
). Even when this technique computes competitive regression, it requires the assumption of some free parameter values for the QPSO algorithm, which can be undesirable when the user does not have prior knowledge about the phenomenon. Besides, no more experiments with different noise conditions are presented; so only limited conclusions can be reached. On the other hand, our methodology shows a suitable performance, even for different noise conditions.
Furthermore, it can be seen in Table 1 how our algorithm controls the LS-SVM free parameters in the Sinc dataset. If 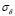 increases, the
increases, the 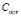 value is low, which prevents an over-fitting in the LS-SVM training.
value is low, which prevents an over-fitting in the LS-SVM training.
Otherwise, if 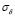 decreases, the
decreases, the 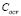 value is high, giving more weight to the training error of the LS-SVM optimization problem. Now, the lowest
value is high, giving more weight to the training error of the LS-SVM optimization problem. Now, the lowest 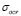 is calculated for the highest
is calculated for the highest 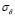 , which reveals that the proposed methodology analyzes the system with a low band-width when the output signal is highly perturbed.
, which reveals that the proposed methodology analyzes the system with a low band-width when the output signal is highly perturbed.
Again, in agreement with the results shown in Table 2 and Fig. 3, our approach computes suitable regression for the Sinc3D dataset. Moreover, the 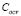 and
and 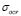 values decrease for high noise conditions, which allow for one to find a regression function that can deal with perturbed samples. The last statement can be especially corroborated by the regression results attained for
values decrease for high noise conditions, which allow for one to find a regression function that can deal with perturbed samples. The last statement can be especially corroborated by the regression results attained for 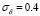 (Fig. 3 (b)) Note that our approach improves the Sinc3D results presented in [5], where an RE of 23.9393[%] and 2.0908[%] are reported for
(Fig. 3 (b)) Note that our approach improves the Sinc3D results presented in [5], where an RE of 23.9393[%] and 2.0908[%] are reported for 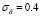 and
and 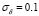 , respectively. It is important to note that the methodology presented in [5] analytically chooses the
, respectively. It is important to note that the methodology presented in [5] analytically chooses the 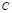 value, but it does not directly consider the influence of
value, but it does not directly consider the influence of 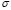 , which is manually fixed. This is why it is not possible to ensure suitable performance in several cases.
, which is manually fixed. This is why it is not possible to ensure suitable performance in several cases.
Regarding to the real-world experiments, our methodology calculates appropriate regressions with low ARE results (Tables 3 and 4, Fig. 4 and Fig. 5), which confirm its applicability in complex problems. According to the fixed 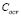 and
and 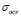 values, it can be seen how our method aims to analyze the data with a low band-width Gaussian kernel, while a considerably high value for the tradeoff parameter is selected. Indeed, our approach fixed the highest
values, it can be seen how our method aims to analyze the data with a low band-width Gaussian kernel, while a considerably high value for the tradeoff parameter is selected. Indeed, our approach fixed the highest 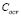 value for the ECA dataset (Table 4), which can be explained by the fact that ECA has a well defined dynamic that is suitably modeled by LS-SVM. On the other hand, CCS data contains more complex nonlinearities properties, which LS-SVM aim to compensate with low
value for the ECA dataset (Table 4), which can be explained by the fact that ECA has a well defined dynamic that is suitably modeled by LS-SVM. On the other hand, CCS data contains more complex nonlinearities properties, which LS-SVM aim to compensate with low 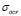 and
and  values.
values.
6. CONCLUSIONS
In this paper, a methodology for automatic parameters choice in the LS-SVM algorithm is proposed. It selects simultaneously suitable values for the parameters 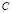 and
and 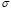 using the GCV method, formulating a scheme that relates the LS-SVM optimization to an inverse problem. According to the experiments, our technique computes suitable regression results even in several noise conditions.
using the GCV method, formulating a scheme that relates the LS-SVM optimization to an inverse problem. According to the experiments, our technique computes suitable regression results even in several noise conditions.
Besides, our algorithm does not need prior knowledge about the influence of the LS-SVM parameters in the phenomenon studied. The proposed method seems to be appropriated for real-world regression tasks. It is important to note that due to the nonconvex characteristic of the proposed optimization problem for the LS-SVM free parameter selection, our approach can not ensure the computation of the optimal values for 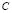 and
and 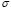 . However, our initialization procedure allows for one to work in a suitable domain for minimizing the proposed objective function, which can be confirmed by the results attained.
. However, our initialization procedure allows for one to work in a suitable domain for minimizing the proposed objective function, which can be confirmed by the results attained.
As future work, we are interested in testing more complex regression problems and forecasting procedures.
ACKNOWLEDGMENTS
This research was carried out under grants provided by the project 1115-470-22055 funded by the Research Center for Excellence ARTICA, Medellín, Colombia, and by projects 20201006599, 20201006570, and 20201006594 funded by the Universidad Nacional de Colombia Sede Manizales. Moreover, GDS was supported by project #20110108-PI/UAN-2011-510gb UAN.
REFERENCES
[1] Methaprayoon, K., Lee, W. J., Rasmiddatta, S., Liao, J. and Ross, R., Multi-stage arti?cial neural network short-term load forecasting engine with front-end weather forecast, IEEE Trans. Ind. Appl., pp. 1410-1416, 2007. [ Links ]
[2] Maier, H. and Dandy, G., Neural networks for the prediction and forecasting of water resources variables: a review of modeling issues and applications, Environmental Modeling and Software, vol. 15, pp. 101-124, 2000. [ Links ]
[3] Leng, X. and Miller, H.-G., Input dimension reduction for load forecasting based on support vector machines, IEEE International Conference on Electric Utility Deregulation, Restructuring and Power Technologies (DRPT2004), 2004. [ Links ]
[4] Vapnik, V., The nature of statistical learning, second edition, Springer, 1999. [ Links ]
[5] Cherkassky, V. and Ma, Y., Practical Selection of SVM Parameters and Noise Estimation for SVM regression. Neural Networks, vol., 17, pp. 113-126, 2004. [ Links ]
[6] Suykens, J. A. K., Gestel, V. T., Brabanter, J. D., Moor, B. D. and Vandewalle, J. Least squares support vector machines, World Scientific, 2002. [ Links ]
[7] Zhou, L., Yang, H. and Liu, C., QPSO-based hyper parameters selection for LS-SVM regression. Fourth International Conference on Natural Computation. Jinan, China, 2008. [ Links ]
[8] Hansen, C., Nagy, J. and Oleary, D., Deblurring Images: Matrices, Spectra, and Filtering. Philadelphia, PA, USA: Society for Industrial and Applied Mathematics, 2006. [ Links ]
[9] Golub, M. and Wahba, G., Generalized Cross Validation as a method for choosing a good ridge parameter, Technometrics, vol. 21, pp. 215-223, 1979. [ Links ]
[10] Nguyen, N., Milanfar, P., Member, S. and Golub, G., Efficient generalized cross validation with applications to parametric image restoration and resolution enhancement, IEEE Transactions on Image Processing, vol. 10, 2001. [ Links ]
[11] Peiliang, X., Iterative generalized cross-validation for fusing heteroscedastic data of inverse ill-posed problems, Geophys. J. Int, vol. 179, pp. 182-200, 2009. [ Links ]
[12] Boggs, P.T. and Tolle, J.W., Sequential quadratic programming for large-scale nonlinear optimization, Journal of Computational Application Mathematics, vol. 124, pp. 123-137, 2000. [ Links ]
[13] Powell, M.J.D., A Fast Algorithm for Nonlinearly Constrained Optimization Calculations, Numerical Analysis, Lecture Notes in Mathematics, Springer Verlag, Vol. 630, 1978. [ Links ]
[14] Sheather, S.J., Density Estimation, Statistical Sci. 19 (2004) 588-597. [ Links ]
[15] Cheng, Y., Modeling of strength of high performance concrete using artificial neural networks. Cement and Concrete Research, vol. 28, pp. 1797-1808, 1998. [ Links ]
[16] Tank, A. M., coauthors, Daily dataset of 20th-century surface air temperature and precipitation series for the European Climate Assessment, Journal of Climatology 22, pp. 1441-1453, 2002. [ Links ]
[17] Soto, C. and Jiménez, C., Supervised learning for fuzzy discrimination and classification, Revista DYNA, vol. 78, pp. 26-36, 2011. [ Links ]
[18] Pulgarín, J., Acosta, C. and Castellanos, G., Multiscale analysis by means of discrete mollification for ECG noise reduction, Revista DYNA, vol. 76, pp. 185-191, 2009. [ Links ]

