










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353On-line version ISSN 2346-2183
Dyna rev.fac.nac.minas vol.79 no.171 Medellín Jan./Feb. 2012
TELEDETECCIÓN DE LA VEGETACIÓN DEL PÁRAMO DE BELMIRA CON IMÁGENES LANDSAT
REMOTE SENSING ANALYSIS OF BELMIRA'S PARAMO VEGEATATION WITH LANDSAT IMAGERY
JORGE ANDRÉS POLANCO LÓPEZ DE MESA
Profesor Facultad de Ciencias Económicas y Administrativas, Universidad de Medellín, japolanco@udem.edu.co
Recibido para revisar Junio 15 de 2011, aceptado Noviembre 28 de 2011, versión final Diciembre 21 de 2011
RESUMEN: El propósito de este trabajo es distinguir el bosque del páramo de Belmira de las otras coberturas del suelo. Se dispone para este fin de tres imágenes LANDSAT (1996, 2002 y 2003). La teledetección del bosque tiene en cuenta procesos de corrección, clasificación y validación. La corrección de las imágenes recurre al modelo COS(t) y a una función cuadrática de interpolación. La clasificación no supervisada se hace con la técnica de las medias móviles y la clasificación supervisada con la técnica de la máxima semejanza. La validación tiene en cuenta 70 observaciones de campo y se realiza tabulando los errores por acción o por omisión. El resultado consiste en un mapa para cada fecha con dos categorías de uso del suelo, bosque & no-bosque. La clasificación incurre en un error del 2% y la concordancia del mapa con las observaciones de campo es del 80%. Sin embargo, la presencia de nubes y sombras dificulta el proceso de teledetección del bosque.
PALABRAS CLAVE: Teledetección, LANDSAT, Vegetación, Clasificación, Páramo de Belmira
ABSTRACT: The purpose of this study is to distinguish the forest of Belmira's Páramo from other land cover classes. Three LANDSAT images are available (1996, 2002 and 2003). Remote sensing analysis of the vegetation coverage includes image correction and classification and validation process. The COS(t) model and the quadratic interpolation function were used for image correction. The iterative self-organizing cluster analysis is considered for image non supervised classification and the maximum likelihood classifier is taken into account for image supervised classification. 70 GPS land observations and the error matrix analysis, were used for validation process. The Result is a map for each image, with two land cover categories: forest & non-forest. Classification error is 2% and map-land observations correspondence is 80%. However, the presence of clouds and shadows affect the remote sensing accuracy.
KEYWORDS: Remote sensing analysis, LANDSAT, Vegetation, Classification, Belmira's Paramo
1. INTRODUCCIÓN
La información de los satélites LANDSAT es cada vez más utilizada para caracterizar la geografía a escala regional. Gracias a las resoluciones espacial y espectral de estos sensores pasivos, es posible captar diferentes coberturas del suelo, especialmente la vegetación. Es por eso que la teledetección de imágenes LANDSAT es comúnmente practicada para clasificar las coberturas vegetales [1, 2, 3].
Esta clasificación suele hacerse con procedimientos no supervisados y/o supervisados, dependiendo del objeto de estudio y de la disponibilidad de información de campo [1, 4, 5]. En el caso de la vegetación tropical andina, vale la pena tener en cuenta también el efecto de la topografía en las respuestas radiométricas, puesto que los pisos térmicos inciden considerablemente en los contenidos de humedad del suelo y de la vegetación. Por lo tanto, las clasificaciones deben realizarse en zonas con las mismas características edafoclimáticas, para facilitar la corrección por efecto de la topografía. La segmentación de la imagen a partir de un modelo digital de terreno es comúnmente realizada para este efecto [6].
Ahora bien, cualquier tipo de uso que se le dé a la información LANDSAT, debe ser precedido de un procedimiento de corrección radiométrica y geométrica de la imagen [1, 2]. La corrección radiométrica reduce las distorsiones de la respuesta electromagnética del suelo, debido a fenómenos atmosféricos. Y la corrección geométrica busca reducir las distorsiones espaciales, inherentes al proceso de georeferenciación de la imagen; es decir, reducir la diferencia de ubicación de un punto sobre la imagen respecto al mismo punto sobre el mapa de referencia.
Así pues, la teledetección de la vegetación a partir de imágenes LANDSAT es un proceso técnicamente complejo, pero provisto de un balance costo-beneficio positivo. Positivo, sobre todo, si se considera su alcance regional y si se tiene en cuenta que es poco intensivo en horas de investigación, con respecto a otras técnicas de mapeo derivadas de análisis bioclimáticos [3, 4, 6].
En Colombia, se han hecho dos trabajos recientes en esta dirección que vale la pena resaltar. Se trata del Mapa de Ecosistemas Marinos y Costeros [7] y el Mapa de suelos del departamento de Antioquia [8]. Ambos trabajos partieron de imágenes LANDSAT fechadas en los primeros dos años del 2000. El primero, produjo mapas de coberturas del suelo a escala 1/500.000 y, el segundo, los hizo a escala 1/100.000. En estos trabajos se distinguieron diversas coberturas del suelo, como por ejemplo bosques plantados, bosques naturales, herbazales, etc.
El trabajo que se presenta en este texto es complementario a los anteriores, como consecuencia de su carácter específico. El objetivo es clasificar el bosque de un ecosistema estratégico. Es decir, se quiere distinguir el bosque del páramo de Belmira (SPANA), situado al norte de Medellín (Figura 1), de las demás coberturas del suelo en diferentes fechas. Esto con el ánimo de construir el insumo apropiado para conocer posteriormente su dinámica espacio-temporal.
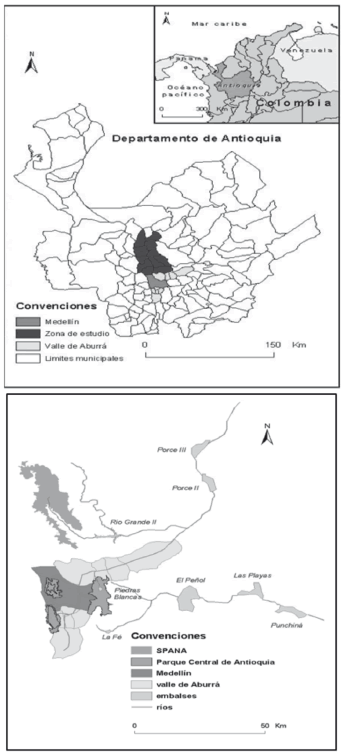
Figura 1. Localización del área de estudio
Esta teledetección del bosque se hace entonces con el propósito de producir información útil para la toma de decisiones ambientales, de cara a la perennidad del páramo [9]. En este documento sólo se presentará el proceso de clasificación del bosque a partir de imágenes LANDSAT de 1996, 2002 y 2003.
Para ello, se ha dividido el texto en tres partes. Primero, se presentarán las características de las imágenes y el método de corrección, clasificación y validación. Luego, se analizarán los resultados de las respuestas espectrales de las clases no supervisadas y supervisadas, estas últimas teniendo en cuenta observaciones de campo. Finalmente, se discutirá el alcance de la teledetección de la vegetación, en vista de un posible análisis diacrónico del bosque.
2. DATOS Y MÉTODO
Se dispone de tres imágenes de satélite y de un mapa digitalizado de coberturas del suelo. La primera imagen proviene del satélite Landsat 5, fechada el 2 de Agosto de 1996 (TM96), y las otras dos del satélite Landsat 7, fechadas el 14 de Octubre de 2002 (ETM02) y el 3 de Febrero de 2003 (ETM03). Las imágenes TM96 y ETM03 corresponden al verano, y la imagen ETM02 al invierno o periodo de lluvias, según el comportamiento bimodal de la pluviosidad media mensual en el Páramo de Belmira (Figura 2).
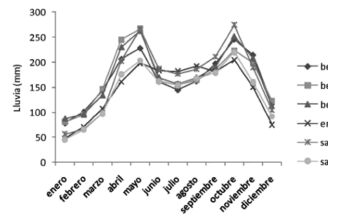
Figura 2. Pluviosidad media mensual en el páramo de Belmira (1968-1997)Fuente: cálculos propios a partir de [10]
El mapa ha sido digitalizado por la Corporación Autónoma Regional del Centro de Antioquia (Corantioquia), sobre la base de la información de coberturas del suelo, publicada por la Secretaría de Agricultura del Departamento de Antioquia en 1989, en escala 1/100.000. Este mapa ha sido adoptado por todos los municipios en sus Planes de Ordenamiento Territorial (POT) y su nomenclatura ha sido unificada [11]. El proceso de clasificación de las imágenes tiene en cuenta las siguientes categorías de coberturas del suelo del mapa: bosques, cultivos, pastos, arbustos, suelo desnudo y páramo.
Primero, se realiza un procesamiento preliminar de las imágenes satelitales, a fin de eliminar los errores introducidos por la atmósfera, la topografía y la georeferenciación. A continuación, se hace una clasificación de las coberturas del suelo con el propósito de obtener el mismo número y tipo de clases para todas las imágenes. Finalmente, se efectúa una última clasificación teniendo en cuenta los resultados preliminares y las observaciones de campo (Figura 3). La teledetección de esta información satelital se ha realizado con la ayuda del programa IDRISI Kilimanjaro.
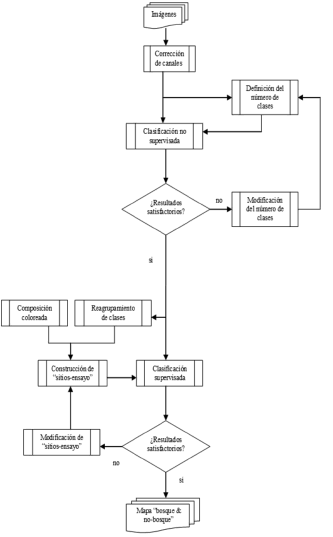
Figura 3. Diagrama de flujo de la clasificación
Procesamiento preliminar de las imágenes
El procesamiento preliminar consiste en corregir las imágenes de las perturbaciones atmosféricas y topográficas y de las deformaciones geométricas, que se generan en el proceso de georeferenciación. Se trata de una corrección dirigida a reducir el error de medida producido por estas perturbaciones y deformaciones.
La corrección de las perturbaciones atmosféricas hace parte de la corrección radiométrica y es necesaria como consecuencia de una reducción de la radiación solar reflejada por la tierra, en razón de fenómenos de difusión y absorción. Esta radiación solar que da cuenta de los objetos sobre el suelo, está modificada y puede dar pie a falsas interpretaciones sobre las características de la vegetación. Estos efectos se han corregido aquí con la ayuda del modelo COS(t) (Chavez, 1996, citado en [12]), puesto que se adapta a la poca información disponible sobre las imágenes. Luego de esta corrección atmosférica, se obtienen “nuevas” imágenes en modo radiancia (Watt*m-2*sr-1), las cuales pueden ser comparadas.
Los canales corregidos radiométricamente son luego traídos a la misma proyección geográfica (Universal Transverse Mercator UTM 18N, basada en el sistema geográfico mundial WGS 1984). Las cabeceras municipales se han escogido como puntos de referencia en el terreno, puesto que son fácilmente identificables sobre las imágenes y el mapa. Estos puntos de referencia se marcan sobre una composición de colores (RGB: canales 7, 3, y 1, respectivamente). El nuevo marco de la imagen está dado en coordenadas geográficas UTM.
Esta georeferenciación es necesaria para comparar las imágenes con el mapa y se realiza siguiendo el procedimiento RESAMPLE [12]. Este procedimiento utiliza una función cuadrática de interpolación según el vecino más próximo. El error (RMS) aceptable no debe pasar de 0.5 veces la unidad del pixel (en promedio unos 15m en el terreno), respetando un mínimo de seis puntos de referencia.
El cálculo del RMS óptimo o admisible, es función de la escala del mapa de referencia y del error aceptable sobre el terreno [12]. El RMS óptimo varía según la escala y la precisión del mapa de referencia. Por ejemplo, para un mapa en escala 1/100.000, en el cual el error aceptable es de 50.8m, el RMS óptimo sería de 30m en promedio, es decir 1 pixel del satélite Landsat. Para un mapa en escala 1/50.000, el RMS óptimo sería de 0.5 pixeles en promedio [13, 14].
El efecto topográfico respecto al cambio en altitud existente, se refleja en el cambio de humedad del suelo. Este efecto se ha reducido gracias a la partición de la imagen, teniendo en cuenta un modelo numérico del terreno. Todos los canales de las imágenes estudiadas se han partido con la ayuda de un filtro topográfico, que está definido en función de las zonas de vida propuestas por Holdridge [15, 16]. El filtro topográfico parte el espacio en dos zonas: la primera de 275 m a 2000 m y la segunda de 2001 m a 3300 m de altitud sobre el nivel del mar. Una altitud de 2000 m.s.n.m constituye la curva de nivel de articulación entre los climas tropicales seco y temperado y los climas tropicales fríos, donde la humedad del suelo implica un cambio perceptible por la imagen. En la zona de estudio, los climas tropicales seco y temperado tienen una precipitación media anual inferior a 2000 mm y una temperatura media anual superior a 20 oC. Por el contrario, los climas tropicales fríos tienen una precipitación media anual superior a 2000 mm y una temperatura media inferior a 20 oC [15, 16].
La imagen corregida consta entonces de una radiometría medida en radiancia, de una georeferenciación cuyo error geométrico es aceptable y de un filtro topográfico que facilita el análisis de las coberturas del suelo por encima de 2000 m, reduciendo el efecto de la humedad del suelo sobre el proceso de clasificación de estas coberturas.
Clasificación de la cobertura del suelo sobre las imágenes
Una vez que las imágenes han sido corregidas, se efectúa una primera identificación de las coberturas del suelo mediante un proceso de clasificación no supervisada. Durante la clasificación no supervisada, los pixeles se agrupan de manera iterativa en un número predefinido de clases sin significado temático. La clasificación no supervisada se realiza según el método ISOCLUST [12, 17, 18], que es una variante del método ISODATA. Se trata de un método iterativo de clasificación, según la técnica de las medias móviles. De manera general, la idea es afectar (o ligar) los pixeles a un número de clases predeterminado, tendiente a reducir la distancia espectral entre dichos pixeles y la media de las clases en el espacio radiométrico.
En el caso en que esta distancia sea euclidiana, el proceso iterativo de afectación se detiene cuando la suma del cuadrado del error no excede una cantidad definida a priori (Ballet y Hall, 1965, citado por [1]). El proceso ISOCLUST se realiza en dos etapas:
- Identificación del número de clases según el histograma de frecuencias de pixeles por clases, surgido de una clasificación según el vecino más próximo;
- Afectación de los pixeles de las clases por el criterio de aceptación de máxima verosimilitud, considerando la hipótesis de la ley normal. Lo que implica que el número de pixeles por clase, sea diez veces superior al número de canales que intervienen en la clasificación [1, 6].
Posteriormente, las clases no supervisadas se reagrupan con la ayuda del algoritmo SEPSIG [12], con el fin de mejorar su diferenciación radiométrica. Este reagrupamiento se hace teniendo en cuenta la “distancia” entre las marcas espectrales de las clases. Para la distancia utilizada (transformed divergence), se ha demostrado empíricamente que dos clases se distinguen bien en términos radiométricos, si esta distancia es aproximadamente 2000 (valor adimensional). Por el contrario, si la distancia entre las clases es en promedio de 1600 o inferior, se supone que las dos clases no son lo suficientemente distintas y se pueden reagrupar [1].
La clasificación no supervisada es un insumo para aquella supervisada. Esta última, se realiza con el fin de distinguir el bosque de las otras categorías de coberturas del suelo, reduciendo el efecto de las nubes y las sombras. El procedimiento de clasificación supervisada consiste, primero, en la construcción de “sitios-ensayo” (sites test) y, luego, en la construcción de dos temas o categorías de coberturas: bosque y no-bosque.
Se han construido los sitios-ensayo para todas las imágenes, sobre la base de una composición de colores de tipo RGB 453 y de las clases no supervisadas. Se han considerado cinco clases: Vegetación 1 (V1), Vegetación 2 (V2), Agua, Sombra de nubes y Nubes. Los sitios-ensayo de las clases Agua, Sombra de nubes y Nubes, han sido construidos sobre la base de la composición de colores, mientras que aquellos correspondientes a las otras dos clases (V1 y V2), han sido construidos teniendo en cuenta las clases preliminares.
Se han determinado los temas del mapa por medio de una clasificación supervisada, que ha sido realizada con la ayuda de los sitios-ensayo para todas las imágenes, según el algoritmo MAXLIKE [12, 17, 19]. Todos los pixeles son agrupados en las clases definidas por los sitios-ensayo, según la máxima semejanza y considerando la misma probabilidad de afectación para todas las clases. Los temas son determinados con la ayuda de las marcas espectrales de las clases y de las observaciones de campo, y el error de las clasificaciones es estimado según el algoritmo ERRMAT [12, 20].
3. RESULTADOS
Durante la corrección geométrica se tiene en cuenta que, los planos de referencia en escala 1/100.000, son el resultado de un mosaico de mapas en escala 1/25.000, obtenidos por fotointerpretación en los años 1960. El cambio de escala y la digitalización de los planos, puede ser una primera fuente de error en esta cartografía de referencia. Además, la georeferenciación engendra un segundo error que se minimiza adoptando un RMS inferior a 0.5 pixeles, es decir 15 m sobre el terreno.
En este proceso de georeferenciación, el número de puntos de referencia se maximiza y el error RMS se minimiza. Es un proceso iterativo en donde los puntos que contribuyen más en el error se omiten, respetando el número mínimo demandado por el procedimiento de calibración cuadrático (Tabla 1).
Tabla 1. Error de georeferenciación

Al salir del proceso ISOCLUST, se han escogido seis clases. Luego, estas clases se han reagrupado dos veces, escogiendo, en primer lugar, cinco y, después, cuatro. La distancia media entre las marcas espectrales de las clases ha sido maximizada, siempre respetando el mismo número de clases por imagen y la distancia mínima entre clases igual a 1600. El reagrupamiento de las clases ha aumentado la distancia espectral media entre ellas, así:
- De 1935.7 a 1964.3: TM 96;
- De 1884.7 a 1933.5: ETM 02;
- De 1880.1 a 1936.7: ETM 03.
Como consecuencia de este reagrupamiento, se observa que la presencia de vegetación es dominante y las nubes se distinguen bien. Se observan distintos tipos de vegetación, pero se encuentra alguna confusión con la presencia de agua (principalmente de la represa Río Grande II) y de sombra de las nubes. En el caso de la imagen TM 96, por ejemplo (Figura 4), las clases 1, 2 y 3, representan tres tipos de vegetación, mientras que la clase 4 representa las nubes. Los tipos de vegetación de las clases 1 y 2, son bien distintos y no parecen confundirse con otros modos de ocupación del suelo, en razón de sus marcas espectrales.
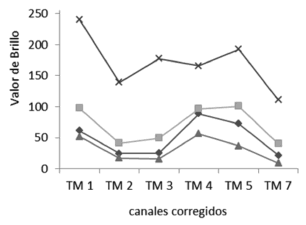
Figura 4. Marcas espectrales medias de las clases no supervisadas de la imagen TM96
El tipo de vegetación de la clase 3, se confunde con el agua y la sombra de las nubes, dada su ubicación en el espacio geográfico y dados los débiles valores radiométricos en todo el espectro electromagnético, respecto a los otros tipos de vegetación.
Los valores radiométricos de las marcas espectrales (ordenada de la Figura 4), están representados por un valor adimensional o valor de brillo (DN), calibrado entre 0 y 255, según la radiancia (L) del pixel (1).
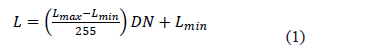
Así pues, los tipos de vegetación han sido determinados y la confusión entre la vegetación, la sombra de las nubes y el agua, ha sido reducida con la ayuda de una clasificación supervisada.
El número de sitios-ensayo construidos por clase depende esencialmente del error acumulado durante la clasificación supervisada. Es decir que, con el objetivo de minimizar el número de pixeles mal clasificados, ha sido necesario aumentar el número de sitios-ensayo (o el número de pixeles) en algunas clases. En el caso de la imagen ETM03, por ejemplo (Tabla 2), el número de sitios-ensayo ha sido duplicado en la mayor parte de las clases supervisadas, respecto a las otras imágenes. Esto se hace porque existe une confusión entre la vegetación, la sombra de nubes y el agua, que se acentúa en esta imagen a raíz de la presencia de nubes. Estos sitios-ensayo han contribuido, de esta manera, a la distinción de las clases dentro del proceso de clasificación supervisada.
Tabla 2. Número de sitios-ensayo

Los resultados de las clasificaciones supervisadas, se traducen en un mapa con dos categorías de cobertura del suelo: bosque y no-bosque. Las coberturas del suelo bosque y arbustos, identificados gracias a las observaciones de campo y según la nomenclatura unificada [11], han sido atribuidos al tema bosque, y las otras (suelo desnudo, pastos, páramo y cultivos) lo han sido a la categoría no-bosque. El agua, las sombras y las nubes se distinguen bien en las imágenes, en la medida en que la confusión entre el agua, las sombras y la vegetación, ha sido corregida.
En efecto, el comportamiento radiométrico muestra una clara distinción de las clases supervisadas sobre todas las imágenes (Figura 5). Las clases bosque y no-bosque se diferencian entre ellas, por ejemplo, en el rojo y el infrarrojo: la clorofila de la vegetación bosque absorbe más el rojo y esta vegetación es más húmeda que la vegetación no-bosque. La clase nubes, tiene la respuesta espectral más elevada en todos los canales. La respuesta espectral de la clase agua es débil en el infrarrojo, pero la presencia de sedimentos sobresalta un poco este valor radiométrico.
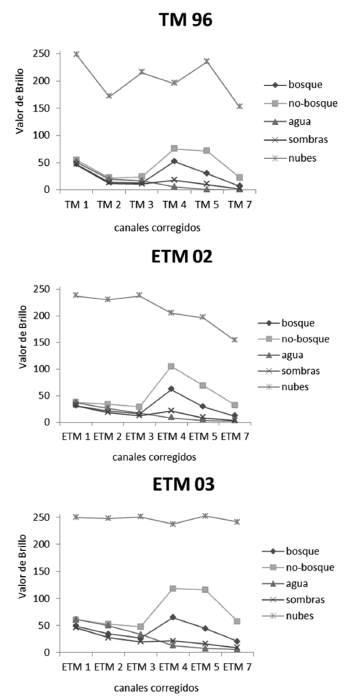
Figura 5. Marcas espectrales medias de las clases supervisadas
La clase sombras tiene una respuesta espectral débil y descendiente a lo largo del espectro electromagnético, a raíz de la difusión atmosférica. Es decir que, los objetos expuestos a la sombra, son aclarados por el fenómeno de difusión de Rayleigh, principalmente en la parte visible del espectro electromagnético. Las sombras aparecen aún más oscuras, en la media en que el espectro electromagnético se acerca al infrarrojo próximo, donde esta difusión es prescindible [2].
Teniendo en cuenta la nomenclatura de los POT homologada [11], se han distinguido cinco modos de ocupación del suelo en función de 70 puntos registrados en 2002 con un GPS: Suelo desnudo (15 observaciones), Cultivos (11 observaciones), Pastos (27 observaciones), Arbustos (17 observaciones) y Bosque (18 observaciones). La categoría Pastos incluye la de Páramo, y la categoría Suelo desnudo incluye la de Urbano. En lo que concierne a la zona por encima de los 2000 m.s.n.m de la imagen ETM02, la concordancia entre la clasificación supervisada y las observaciones de campo es aceptable (coeficiente de Cohen [21]: Kappa = 0.8), cuando las categorías Bosque y Arbustos se han atribuido a la clase supervisada bosque.
Esta concordancia también se acepta porque la imagen ETM02 y las observaciones de campo corresponden al mismo mes y año. En cuanto a las imágenes TM96 y ETM03, se supone que las clases supervisadas representan también los mismos modos de ocupación del suelo, teniendo en cuenta los canales corregidos y sus marcas espectrales.
La estimación del error de las clasificaciones supervisadas se realiza a partir de una matriz de confusión. Esta matriz establece la relación entre las clases supervisadas y los sitios-ensayo (Tabla 3). Las columnas de la matriz están asociadas a los sitios-ensayo y las filas a las clases supervisadas. Bajo la hipótesis en la cual las clases supervisadas están totalmente representadas por las clases de los sitios-ensayo, la matriz de confusión solo tendrá valores sobre la diagonal, siendo éstos equivalentes al número de pixeles bien clasificados. Si las clases supervisadas no corresponden completamente a los sitios-ensayo, algunos pixeles estarán mal clasificados. El número de pixeles mal clasificados es la suma de los valores situados por fuera de la diagonal de esta matriz.
Tabla 3. Matrices de confusión
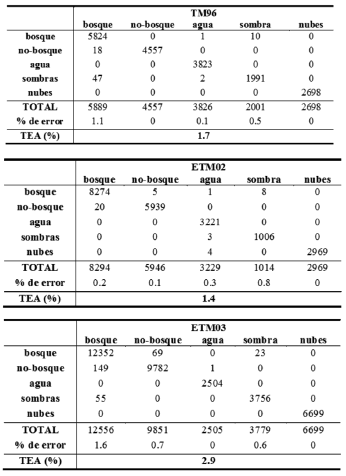
La calidad de la clasificación supervisada puede ser estimada por el método de validación cruzada [22]. De esta manera se calcula el porcentaje de pixeles mal clasificados por clase. Este porcentaje total de pixeles mal clasificados o Tasa de Error Aparente (TEA), ha sido reducido aumentando el número de sitios-ensayo. Entre las tres clasificaciones supervisadas, la tasa de error media obtenida es del 2%.
Ahora bien, a mayor número de clases supervisadas, mayor tiende a ser el error de clasificación. Es decir, si se hubiese desagregado la categoría bosque en, por ejemplo, bosque natural y plantado, el error esperado habría sido mayor. Pero esta desagregación demanda una información que esta por fuera del alcance de este trabajo.
Finalmente, los mapas bosque y no-bosque (Figura 6), obtenidos por medio de las clasificaciones supervisadas, han sido filtrados a fin de reagrupar los pixeles aislados y consolidar las fronteras. Esta filtración se hace con el algoritmo MODE, que modifica el pixel situado en el centro de una malla de 3x3 pixeles, afectándolo a la clase más frecuente [1, 12]. Es una generalización del mapa que conviene al análisis espacial, puesto que las clases son más homogéneas (Tabla 4).
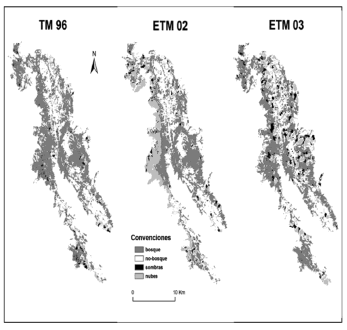
Figura 6. Mapa de la clasificación supervisada considerando el filtro MODE
Tabla 4. Resultados de las clasificaciones supervisadas y filtradas (hectáreas)

4. CONCLUSIÓN
Este trabajo se propuso distinguir el bosque de las demás coberturas de suelo, construyendo un mapa bosque & no-bosque a partir de información LANDSAT. Aunque se recurrió a procedimientos convencionales de teledetección, la innovación científica de este trabajo se centra sobre todo en la producción de conocimiento nuevo para la zona de estudio.
Este conocimiento fue producido a partir de imágenes corregidas radiométrica y geométricamente. La corrección radiométrica permitió obtener valores en radiancia, que pueden ser comparados entre las imágenes, haciendo posible un análisis diacrónico de la vegetación. Por su parte, la corrección geométrica redujo de manera satisfactoria las deformaciones, con un error promedio de 0.43 pixeles, es decir aproximadamente de 13 m sobre el terreno. Una vez corregidas las imágenes, el resultado del proceso de clasificación se benefició de observaciones de campo para su validación, alcanzando una concordancia de éstas con el mapa del 80%. Además, en este proceso de clasificación del bosque, se incurrió en un error pequeño, según la matriz de confusión. Es decir, sólo un promedio del 2% de los pixeles quedó mal clasificado.
Sin embargo, la calidad de la información disponible se vio afectada por la presencia de nubes y sombras, especialmente en la imagen ETM03. Esto indujo errores de clasificación en el proceso no supervisado y dificultó la afectación de la cobertura Arbustos a las clases supervisadas bosque & no-bosque.
En vista de un análisis diacrónico del bosque, se sugiere la construcción de un mosaico de imágenes para evitar esta presencia de nubes. Es decir, se podría considerar simultáneamente la información de las imágenes ETM02 y ETM03. Puesto que estas imágenes fueron tomadas más o menos en la misma época, puede suponerse que el paisaje no cambió lo suficiente para ser percibido por medio de la teledetección. Aceptando esta hipótesis, las zonas cubiertas de nubes en ETM03 podrían reemplazarse por las mismas zonas despejadas de ETM02, construyendo así un mosaico ETM02/03 que pueda compararse con TM96, para conocer la dinámica espacio-temporal del bosque; es decir, para saber dónde hay deforestación y reforestación, o dónde el bosque no ha sido intervenido. Este análisis diacrónico podría experimentar cadenas de Markov con el fin de modelar la deforestación [23].
Finalmente, el resultado de este trabajo debe interpretarse a escala regional, teniendo en cuenta que las categorías de coberturas clasificadas son de carácter agregado. Si se quisiera caracterizar, por ejemplo, diferentes tipos de bosque (bosque plantado, bosque natural, etc.), sería necesario no solamente contar con un trabajo de campo más exhaustivo, sino también con el cálculo índices de vegetación como el NDVI.
REFERENCIAS
[1] Richards, J. A., Jia, X., Remote Sensing Digital Image Analysis. An Introduction, Springer-Verlag, 4 edition, Berlin, P. 291, 2006. [ Links ]
[2] Robin, M., La Télédétection, Coll. Géographie, Nathan, Paris, P. 318, 1998. [ Links ]
[3] Running, S. W., Loveland, T. R., Pierce, L. L., Nemani, R. R., Hunt, E. R., A remote sensing based vegetation classification logic for global land cover analysis, Remote Sensing Environment, Vol. 51, pp. 39-48, 1995. [ Links ]
[4] Al-Tamimi, S., Al-Bakri, J. T., Comparison between supervised and unsupervised classification for mapping land use/cover in Ajloun area. Jordan Journal of Agriculture Science, Vol. 1, No. 1, pp. 73-83, 2005. [ Links ]
[5] Fisher, Ch., Gustafson, W., Redmond, R., Mapping sagebrush/grasslands from Landsat TM-7 Imagery: a comparison of methods, USDI, Montana, P. 21, 2002. [ Links ]
[6] Kokalj, Z., Ostir, K., Land cover mapping using Landsat satellite image classification in the classical Karst-Kras region, Acta Carsologica, Vol. 36 (3), pp. 433-440, 2007. [ Links ]
[7] IGAC, IDEAM, IAvH, INVEMAR, SINCHI, IIAP. Ecosistemas continentales, costeros y marinos de Colombia, Bogotá, 276 p. + 37 hojas cartográficas, 2007. [ Links ]
[8] Instituto Geográfico Agustín Codazzi, Gobernación de Antioquia, Levantamiento semidetallado de las coberturas terrestres del departamento de Antioquia, Medellín, 2007. [ Links ]
[9] Polanco López De Mesa, J.A., Formulación de un análisis multiobjetivo para la toma de decisiones ambientales en Andes colombianos. DYNA, Universidad Nacional, Medellín, 76 (157) pp. 49-60, 2009. [ Links ]
[10] CORANTIOQUIA. Diagnóstico (tomo 1) y Plan de manejo ambiental (tomo2) del sistema de páramos y bosques alto-andinos del noroccidente medio antioqueño, Universidad de Antioquia, Medellín, 1999. [ Links ]
[11] Buriticá Mira, I. C., Memoria explicativa del mapa de coberturas y usos del suelo en la jurisdicción de Corantioquia. Homologación de los POTM, Corantioquia, Medellín, 2002. [ Links ]
[12] Eastman, J. R., IDRISI Kilimanjaro. Guide to GIS and Image processing, Clark Labs, Clark University, MA, 2003. [ Links ]
[13] Southworth, J., An assessment of landsat TM band 6 thermal data for analysing land cover in tropical dry forest regions, International Journal of Remote Sensing, Vol. 20, pp. 689-706, 2004. [ Links ]
[14] Tottrup, C., Improving tropical forest mapping using multi-date Landsat TM data and pre-classification image smoothing, International Journal of Remote Sensing, Vol. 25 (4), pp. 717-730, 2004. [ Links ]
[15] Holdridge, L. R., Curso de ecología vegetal, Instituto interamericano de Ciencias Agrícolas, Costa Rica, Turrialba, P. 47, 1953. [ Links ]
[16] Holdridge, L. R., Determination of world plant formation for simple climatic data, Science, Vol. 105, pp. 367-368, 1947. [ Links ]
[17] Eastman, J. R., Crema, S., Zhu, H., Toledano, J., Jiang, H., In-Process Classification Assessment of Remotely Sensed Imagery, Geocarto International, Vol. 20, No. 4, pp. 33-43, 2005. [ Links ]
[18] Ferreira, M. A., Andrade, F., Cardoso, P., Paula, J., Coastal Habitat Mapping Along the Tanzania/Mozambique Transboundary Area Using Landsat 5 TM Imagery, WIOMSA, Vol. 8, No. 1, pp. 1-13, 2009. [ Links ]
[19] Kong, N., Fei, S., Rieske-Kinney, L., Obrichy, J., Mapping Hemlock Forest in Harlan County, Kentucky, En: Proceedings of the 6th Southern Forestry and Natural Resources GIS Conference, (Eds. P. Bettinger, K. Merry, S. Fei, J. Drake, N. Nibbelink, J. Hepinstall), Athens, pp. 107- 117, 2008. [ Links ]
[20] Ojigi, L. M. Analysis of Spatial Variations of Abuja Land Use and Land Cover from Image Classification Algorithms, Symposium Remote Sensing: From Pixel to Processes, Enschede, Netherlands, p. 6, 2006. [ Links ]
[21] Cohen, J., A coefficient of agreement for nominal scales, Educational and Psychological Measurement, Vol. 20 (1), pp. 37-46, 1960. [ Links ]
[22] Lebart, L., Morineau, A., Piron, M., Statistique exploratoire et multidimensionnelle, DUNOD, Paris, P. 434, 2006. [ Links ]
[23] CABRAL, P., ZAMYATIN, A., Procesos de Markov en la modelización de alteraciones del uso y ocupación del suelo en Sintra-Cascais, Portugal, DYNA, Universidad Nacional de Colombia, Medellin, 76 (158), pp. 191-198, 2009. [ Links ]

