










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkDYNA
versão impressa ISSN 0012-7353versão On-line ISSN 2346-2183
Dyna rev.fac.nac.minas v.79 n.173 Medellín maio/jun. 2012
MINERÍA DE DATOS BASADA EN LÓGICA DIFUSA PARA LA INTERPRETACIÓN DE CONSULTAS VAGAS DEPENDIENTES DEL CONTEXTO LINGÜÍSTICO
DATA MINING USING FUZZY LOGIC FOR THE TRANSLATION OF VAGUE QUERIES DEPENDING ON THE LINGUISTIC CONTEXT
CLAUDIA JIMENEZ RAMIREZ
Ph.D. Universidad Nacional de Colombia, Sede Medellín. csjimene@unal.edu.co
HERNÁN ALVAREZ ZAPATA
Ph.D. Universidad Nacional de Colombia, Sede Medellín. hdalvare@unal.edu.co
Recibido para revisar Febrero 3 de 2012, aceptado marzo 5 de 2012, versión final marzo 29 de 2012
RESUMEN: En este artículo se presenta un método propuesto para que un sistema flexible de consulta-respuesta a bases de datos pueda hallar, de manera autónoma y dinámicamente, la semántica de las condiciones vagas de las consultas, explorando los datos disponibles en la base de datos y usando lógica difusa. La máquina de inferencia del sistema, según el contexto lingüístico delimitado por cada consulta, elige un modelo de conjunto difuso entre los modelos predefinidos para diferentes patrones sintácticos con los que puede encajar el texto de una consulta vaga y considerando diferentes niveles de granularidad en la categorización de los objetos. Se estima el valor de los parámetros del conjunto difuso que representa una etiqueta lingüística, usando un método no supervisado y no paramétrico en el proceso de discriminación; evitando así, la intervención de expertos. Con esto se logra que los sistemas no sólo sean adaptables, sino confiables gracias a la validez de sus respuestas.
PALABRAS CLAVE: Sistemas flexible de consulta-respuesta, inferencia difusa, minería de datos
ABSTRACT: This paper presents a method in order to a flexible query-answering system can obtain, independently and dynamically, the semantics of imprecise words used as constraints in database queries by scanning the available data in the database and using fuzzy logic. The system's inference engine, according to the linguistic context defined by each query, chooses a fuzzy set model among the predefined theoretical models for different syntactic patterns with which can fit the text of a vague query and considering different levels of granularity in the fuzzy discrimination. It estimates the value of fuzzy set parameters by using a nonparametric method in the fuzzy discrimination, avoiding the intervention of experts. This achieves that the systems are not only adaptable, but reliable thanks to the validity of the responses.
KEYWORDS: flexible question answering systems, fuzzy inference, data mining
1. INTRODUCCIÓN
Puesto que en la interacción humano-máquina los términos vagos deben precisarse para obtener respuestas de esta última, en la presente propuesta se aborda el problema de la representación y manejo de la vaguedad dependiente del contexto lingüístico, como una estrategia clave para aproximar los lenguajes artificiales de los sistemas de consulta-respuesta al lenguaje natural.
Por la imprecisión de ciertas palabras, es corriente que la persona que consulta una base de datos no sepa si un objeto cualquiera se puede considerar "costoso", "reciente" o "pesado", entre muchas otras categorías no claramente diferenciables. Debido a esto, desde hace buen tiempo han surgido varias propuestas para flexibilizar el lenguaje estándar de consulta a bases de datos, el SQL (Structured Query Language) usando lógica difusa para admitir palabras vagas o imprecisas. Sin embargo, en esas propuestas, la forma y la ubicación espacial de los conjuntos difusos que representan las palabras vagas son definidas por expertos y proporcionadas, de antemano, a un sistema interactivo de consulta-respuesta. Esto hace que los modelos propuestos no puedan ser generales, ni objetivos y que además demanden mucho trabajo de actualización para preservar su validez; pues lo que hoy se puede considerar "costoso", por ejemplo, posiblemente no lo sea en un futuro cercano.
Además de la variabilidad del significado de los términos vagos por el paso del tiempo, en las propuestas previas no se considera que muchos de ellos sean relativos o dependientes del contexto que delimita cada consulta. Un vehículo, por ejemplo, puede ser muy costoso en ciertos lugares, mientras que en otros no. Debido a esto, un sistema que no considere el contexto, no podrá capturar adecuadamente el significado de los términos vagos para ofrecer al usuario respuestas confiables.
En [1] se afirma que la principal dificultad para resolver en los sistemas de bases de datos basados en lógica difusa es la subjetividad en la representación de los conceptos vagos y su dependencia del contexto. Esta dificultad la motivación para abordar el problema de estimar, en forma dinámica y autónoma, la semántica de las condiciones vagas de una consulta en sistemas de bases de datos. Proponemos un método automático no supervisado que explora de los datos disponibles del contexto delimitado por la consulta, en la propia base de datos y realiza algunas mediciones para estimar los parámetros de los conjuntos difusos que representan las etiquetas lingüísticas detectadas. Se selecciona un modelo de conjunto difuso genérico aplicable en un caso, según el patrón sintáctico de la consulta y el número de categorías o clases que se deban considerar. Este modelo se particulariza o instancia gracias al proceso de minería de los datos realizada dinámica y automáticamente por el propio sistema. De esta forma, la máquina de inferencia emula a un experto calificado que puede descubrir nuevo conocimiento basándose en los datos disponibles. Por su autonomía y su capacidad de razonamiento puede considerarse un agente inteligente, como se le denomina en la ingeniería del conocimiento.
El resto del presente artículo está estructurado de la siguiente manera. En la segunda sección, se hará una breve descripción de los conceptos fundamentales en los que se basa la propuesta: la minería de datos y una de sus tareas: la discriminación de objetos, basada en la lógica difusa. En la sección 3, se presenta el método propuesto para abordar el problema de capturar el significado de los términos vagos simples especificados en las condiciones de filtrado de las consultas, considerando diferentes niveles de granularidad. En esta sección, se presentan ejemplos de consultas vagas usando la extensión propuesta en el lenguaje estándar de bases de datos SQL, para que se aprecie cómo sintácticamente se preserva su proximidad con el lenguaje natural. Luego, en la sección 4, se presentan los modelos teóricos para hallar la semántica de combinaciones lineales de expresiones vagas, para finalizar con las conclusiones.
2. CONCEPTOS BÁSICOS
2.1. Minería de datos
La minería de los datos para la concreción de la vaguedad es el proceso central en la interpretación de las palabras vagas o imprecisas. Es un proceso de razonamiento conocido también en la literatura como "precisiation" y considerado un prerrequisito básico para la representación y automatización del lenguaje natural puesto que permite la evolución de los Sistemas de Recuperación de Información a Sistemas Flexibles de Consulta-Respuesta [2].
La minería de datos es un proceso de exploración de los datos disponibles en las bases de datos, de forma automática o semiautomática, con el objetivo de encontrar patrones, tendencias o reglas que expliquen el comportamiento de cierto fenómeno en un determinado contexto. Encontrar patrones significa extraer información que permita establecer propiedades de o entre conjuntos de objetos [3].
Por su lado, la discriminación se considera el acto de separar o formar grupos, según algunos criterios o propiedades de los objetos con el objetivo de reconocer diferencias y similitudes entre los grupos y poder describirlas en forma gráfica o algebraica para lograr un mejor entendimiento de un determinado entorno [4]. Por esto, se puede decir que la discriminación y el reconocimiento de patrones son procesos equivalentes.
En el reconocimiento de patrones, algunas técnicas se consideran no supervisadas porque al sistema no se le ofrece una catalogación a priori de los patrones que se deben identificar para formar los grupos o clases pues no siempre se tiene un conjunto de ejemplares ya clasificados que permitan definir las clases, con base en sus propiedades. Una de las técnicas no supervisadas más conocida es la téncia c-medias (k-means, en inglés), con todas sus variaciones, basadas en una medida de distancia como la euclidiana. Infortunadamente, este tipo de técnicas, además de ser costosas en términos computacionales, se pueden quedar en mínimos locales en el proceso iterativo de optimización de los centroides o no llegan a una solución [5].
Existen otras técnicas estadísticas no supervisadas que se basan en la densidad de los datos, en lugar de las distancias, y que han sido empleadas en diferentes disciplinas. Como ejemplo, en sicología han servido para catalogar a una persona adulta como "subnormal", "normal" o "superdotada", con base en el cociente intelectual y bajo el supuesto de normalidad en la distribución del coeficiente. Una partición basada en la distribución normal tiene la ventaja de ofrecer un mecanismo de discriminación muy sencillo que depende sólo de dos parámetros: la media y la desviación estándar. Sin embargo, no siempre es el modelo apropiado para representar una colección de datos, pues pueden existir sesgos o asimetrías en la distribución y tratar de representarla únicamente con dos parámetros no sólo resulta insuficiente, sino inexacto porque los estimadores comunes de los parámetros, no son medidas robustas a los valores extremos.
Para superar la dificultad de representación con el modelo probabilístico normal, se han propuesto los modelos llamados no paramétricos. Este término no quiere decir que tales modelos carecen de parámetros, sino que el número y la naturaleza de los mismos pueden ser flexibles y no preestablecidos de antemano [6]. Esto porque los datos observados son los que determinan la forma y ubicación del modelo de distribución. Razón por la cual también se les denomina modelos libres o independientes de la distribución de los datos (distribution free models, en inglés). Dentro de esta categoría se encuentran los modelos basados en percentiles y los histogramas.
Formalmente, un percentil Pq es un punto del dominio de una variable, bajo el cual se encuentra un porcentaje q de los valores de una distribución de datos. Particularmente, se ha comprobado que una forma muy efectiva para la descripción de la distribución de los datos es la estadística de resumen de los cinco números compuesta por el valor mínimo P0, el valor máximo P100 y los tres cuartiles de la distribución. A partir de esta estadística se suele construir el diagrama de caja y bigotes (box and whisker plot o abreviadamente boxplot, en inglés), uno de los modelos gráficos más informativos [8]. En la Figura 1, se puede observar que este diagrama parte los datos en tres clases: la primera clase representada con el 25% de los datos con valores más bajos, la segunda clase con el 50% de los valores más comunes (la caja) y la tercera clase con los valores más altos. En esta figura, se compara con el histograma de frecuencias para que se aprecie la buena representación de una colección de datos, pero en una forma más condensada, sin necesidad de tantos parámetros.
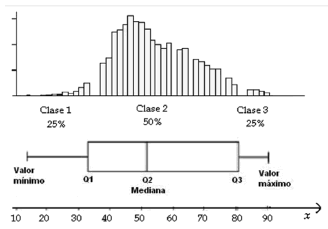
Figura 1. Diagrama de Caja y Bigotes
2.2. Discriminación y clasificación basada en lógica difusa
La discriminación basada en lógica difusa, como las demás técnicas basadas en esta lógica, se han propuesto para flexibilizar las técnicas de minería de datos tradicionales. En particular, las técnicas de agrupamiento (clustering, en inglés), al basarse en la lógica de Boole (cierto, falso), generan particiones matemáticas donde cada objeto pertenece a uno y sólo un grupo [9]. En cambio, en un modelo basado en lógica difusa, cada objeto puede pertenecer a varias clases rotuladas con una etiqueta lingüística, usando para ello, funciones de pertenencia. En la lógica difusa, cada clase o categoría 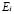 se representa mediante un conjunto difuso de pares ordenados:
se representa mediante un conjunto difuso de pares ordenados:
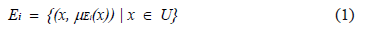
En (1), U es el universo del discurso o dominio de la variable x y la medida 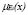 es el grado de pertenencia de x al conjunto con etiqueta Ei. Este conjunto usualmente se define por medio de funciones predefinidas, parecidas a las funciones densidad probabilísticas, llamadas la trapezoidal, la gamma o la campana generalizada, entre muchas otras [10]. Los modelos de las funciones de pertenencia suelen ser elegidas con la ayuda de expertos. Sin embargo, independientemente de los modelos de los conjuntos difusos elegidos, la discriminación obtenida, debe considerarse una partición difusa que cumple las propiedades siguientes:
es el grado de pertenencia de x al conjunto con etiqueta Ei. Este conjunto usualmente se define por medio de funciones predefinidas, parecidas a las funciones densidad probabilísticas, llamadas la trapezoidal, la gamma o la campana generalizada, entre muchas otras [10]. Los modelos de las funciones de pertenencia suelen ser elegidas con la ayuda de expertos. Sin embargo, independientemente de los modelos de los conjuntos difusos elegidos, la discriminación obtenida, debe considerarse una partición difusa que cumple las propiedades siguientes:

La primera propiedad especifica que no se pueden generar o definir conjuntos difusos vacíos en un marco de cognición y la segunda, demanda la cobertura total del dominio.
La computación granular, es llamada en lógica difusa, al paradigma de la representación y el manejo del concepto "gránulo de información", definido como aquel que surge de la derivación de conocimiento a partir de los datos [10]. Significa que un gránulo emerge de los datos como consecuencia de su resumen o condensación y el aspecto clave es la interpretación de los gránulos o grupos que se logra cuando se les puede fijar una etiqueta lingüística. Puesto que esto se quiere garantizar, una estrategia para asegurar que los gránulos o los conjuntos difusos sean interpretables, consiste en la definición de una sólida estructura lógica de razonamiento para realizar la discriminación difusa, utilizando una serie de restricciones que deben cumplirse.
Por limitaciones de espacio aquí no se presentan todas las restricciones que se consideraron en la presente investigación, pero es importante mencionar la convexidad de los conjuntos difusos para generar gránulos interpretables (que no siempre se obtienen con los métodos no supervisados basados en la distancia) y la restricción de complementariedad que demanda que la suma de los grados de pertenencia de cualquier elemento, a todas las clases, sea uno. Quiere decir que el grado de pertenencia total de cualquier elemento está repartido entre las clases y se considera importante pues garantiza que el grado de pertenencia de un elemento al conjunto universal sea uno [11]. Otra restricción considerada en este trabajo de investigación es que cualquier elemento ubicado en el área de solapamiento entre dos conjuntos tenga grados de pertenencia diferentes a los dos conjuntos; exceptuando el punto de cruce, cuyo grado de pertenencia a ambos conjuntos debe ser 0.5. Con ello, se busca la máxima especificidad en la discriminación de los objetos.
3. MINERÍA DE DATOS PARA LA CONCRECIÓN DE LA CONDICIONES VAGAS SIMPLES
Como se dijo antes, en las propuestas previas para interpretar la vaguedad de las consultas a bases de datos, los conjuntos difusos para representar condiciones vagas deben predefinirse, con la ayuda expertos. Sin embargo, esto resulta inconveniente, por la falta de generalidad de los modelos construidos y por su falta de adaptación a los distintos contextos lingüísticos que puedan delimitarse en las consultas. Por eso, con el fin de superar dichas limitaciones, se propone que la máquina, en forma automática y dinámica, realice un proceso de ajuste de modelos de los conjuntos difusos, a los datos existentes en la base de datos.
En primer lugar, deberá realizar una exploración de la base de datos con el objeto de determinar el contexto, basándose en las condiciones concretas especificadas en la consulta. Luego, en la vista materializada obtenida, se realiza la minería de datos para la derivación de los modelos y las reglas de inferencia, válidas en ese contexto. Todo ello considerando diferentes niveles de granularidad para ofrecer mayor flexibilidad en la categorización de los objetos.
Se considera que un adjetivo calificativo como "alto" es simple porque su significado depende de un sólo atributo. Para el caso de la representación de las etiquetas lingüísticas correspondientes a estos adjetivos simples, nos basamos en una partición matemática convencional a la cual se le realizó, luego, un proceso de difuminado, acorde con la lógica difusa.
En el proceso de discriminación definido, se supone la forma de la función de pertenencia de cada uno de los conjuntos que representan una etiqueta, pero se desconocen los valores de los parámetros. Estas formas, para definir los conjuntos difusos, varían según el número de clases o categorías que se deban considerar y la posición de la categoría difusa en cuestión. Las formas son lineales, buscando simplicidad en los modelos: se eligió la función trapezoidal con parámetros (a, b, c, d) para definir un conjunto difuso, cuando la clase no sea una de los extremos, en el contexto considerado. Cuando sea una de éstas, se han elegido las formas semi-trapezoidales (conocidas también como hombro izquierdo y hombro derecho). Los parámetros de la función trapezoidal a y d, definen el soporte de la función de pertenencia (la base mayor del trapecio), y los parámetros b y c determinan núcleo de la misma.
Luego de seleccionar la forma de conjunto difuso apropiada para una etiqueta, se realiza la estimación de los parámetros del conjunto difuso que la representa. Aquí se propone una técnica basada en la densidad de los datos, usando estadísticas de posición relativas para lograr la adaptabilidad de la técnica a cada contexto e independencia sobre la distribución de los datos.
En el caso de una discriminación basada en dos categorías, se realizó una partición matemática usando la mediana para que cada clase contuviera el 50% de los datos. Se eligió esta medida en lugar de la media aritmética, por ser una medida robusta de la tendencia central [8]. Hecha esta partición convencional, se realizó un proceso de difuminado, basándonos en la estadística de resumen de los cinco números para definir su área de solapamiento como aquella, con el 25% de los datos centrales, delimitada por los valores máximos de la primera clase () y los valores más pequeños de la segunda (), como se ve en la Figura 2.
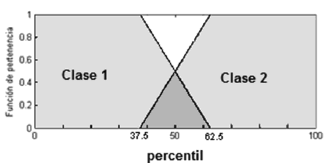
Figura 2. Partición difusa en dos clases
En el caso de una discriminación en tres clases, para determinar cuáles deberían ser los estimadores de los parámetros de las funciones que determinan los conjuntos difusos, se utilizó nuevamente la estadística de resumen de los cinco números sobre la clase intermedia. Por lo tanto, se consideró como núcleo de la función de pertenencia de esta clase, al 50% de sus datos centrales delimitados por sus dos cuartiles (QN1 y QN3) como se muestra en la Figura 3. Dado que la clase intermedia contiene el 50% de los datos originales, los nuevos cuartiles cubren el 25% de los datos centrales de todos los datos. A partir de estos valores, se define la zona de solapamiento con las clases de los extremos.
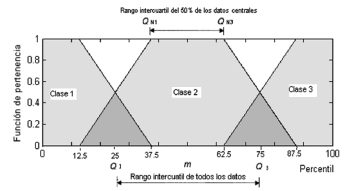
Figura 3. Partición difusa, en tres categorías
Además de discriminar considerando las anteriores categorías difusas, se consideraron otros niveles de granularidad más finos para mayor flexibilidad en la discriminación. Nuestra propuesta incluye hasta seis clases o categorías, como se muestra en la Tabla 1.
Tabla 1. Modelos teóricos de etiquetas vagas

3.1. Sintaxis de las condiciones vagas simples
La sintaxis de una consulta con condiciones vagas simples dependientes del contexto, demanda una extensión del lenguaje de consulta. Para ello, la presente propuesta, se basa en el lenguaje SQLf3 [12], entre otras extensiones, debido a su proximidad con el lenguaje natural. Por esto, la forma para la especificación de una condición vaga simple, en una consulta, es:
SELECT proyección
FROM relaciones
WHERE expresión IS E [j/k]
[WITH CALIBRATION {n| |n,
|n, }]
}]
En este tipo de sentencia, proyección es la lista de propiedades que el usuario quiere visualizar de una relación restringida a aquellos ejemplares que puedan ser calificados con la etiqueta lingüística E cuya posición en el marco es la j considerando k categorías difusas. El valor n es llamado el calibrador cuantitativo, que permite restringir a un número máximo "n" de las mejores respuestas y el umbral o calibrador cualitativo, permite visualizar sólo las tuplas cuyo grado de satisfacción a las condiciones especificadas sea mayor a un nivel mínimo de tolerancia 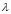 , en el encajamiento [13].
, en el encajamiento [13].
Los valores j y k sólo se especificarían si se usa una etiqueta lingüística genérica como "alto" o "bajo" que no haya sido guardada como parte del conjunto de términos lingüísticos asociados a una variable cuantitativa en los metadatos. Como ejemplo, en la sentencia siguiente se pide el nombre y la dirección de los hoteles en Madrid cuyo valor noche pueda considerarse "medio", considerando tres categorías:
SELECT nombre, dir FROM hoteles
WHERE precio IS "medio" 2/3
AND ciudad = "Madrid"
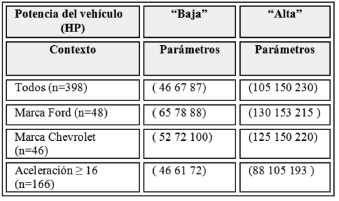
Para visualizar el método de concreción propuesto, se realizaron pruebas experimentales usando una base de datos de referencia sobre 398 autos, utilizada ampliamente en Minería de Datos y Aprendizaje de Máquinas [14]. En una de las pruebas, se hallaron los modelos de los conjuntos difusos de la potencia de los autos, medida en caballos de fuerza, considerando diferentes contextos y tres categorías en la discriminación. En Tabla 2 se puede observar cómo cambian los modelos de los autos cuando se restringen a los autos de ciertas marcas o a aquellos que se demoran 16 o más segundos para pasar de cero a 60 millas/hora. Esta variabilidad en los parámetros de los conjuntos difusos que representan cada etiqueta ratifica que el significado de los términos vagos depende, generalmente, del contexto considerado.
Tabla 2. Parámetros de las funciones de pertenencia en distintos contextos
Con el ánimo de mostrar cómo la máquina puede ser adaptable, no sólo a los cambios en el tiempo o en el espacio, en la Figura 4 se presentan dos marcos de cognición diferentes, a los cuales se podría ajustar autónomamente. Allí se puede ver que cuando se consideren dos clases, un auto se es de potencia "baja", si se tiene entre 50 y 100 caballos de fuerza (hp). En cambio, esta categoría deja de cubrir los autos con una potencia entre 80 y 100 hp, cuando se consideran tres clases.
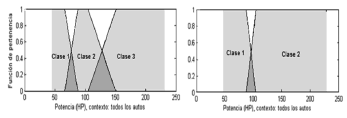
Figura 4. Marcos con distinto número de clases
3.2 Modificadores lingüísticos en las condiciones vagas simples
Un modificador lingüístico cambia los valores de verdad de una sentencia. Por ejemplo, un término como "joven" origina otros como "no muy joven" o "muy joven", gracias a la negación o al uso de adverbios de cantidad.
Convencionalmente, la compatibilidad de un objeto con una etiqueta lingüística modificada por un adverbio de cantidad o por la negación, se infiere, de manera deductiva, de la función de pertenencia definida para la etiqueta lingüística que le da origen.
La negación representa el complemento de una etiqueta lingüística.. A pesar de que existen varias propuestas para hallar el valor de pertenencia al complemento de un conjunto difuso como la de Yaguer o la de Sugeno, se ve conveniente emplear la definición clásica. Dicha definición es una negación fuerte que cumple con la ley de involución definida para el álgebra de Boole [15]. Por esto, si se desea encontrar el grado de pertenencia de una persona al grupo de los "no jóvenes", por ejemplo, se obtendría la respuesta, así:
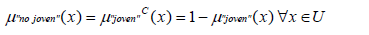
Por otro lado, un adverbio de cantidad como "muy" o "algo", se considera un operador que acentúa o relaja el significado de un adjetivo calificativo. Si la etiqueta Ei se caracteriza por una función de pertenencia , entonces la función = se interpreta como una versión modificada del valor lingüístico original. Usando esta función exponencial se obtienen corrientemente las representaciones para los adverbios de cantidad vagos que dependiendo del exponente k se denomina función de dilatación o de concentración [15].
En la Figura 5 se muestra un ejemplo de aplicación de la función de concentración Ei 2 y la función de dilatación Ei 1/2, para la potencia de los autos de la base de datos de referencia. A simple vista, se puede observar que las densidades de los subconjuntos enfatizados con el adverbio "muy" superan el 75% de la densidad del conjunto del cual fueron derivados, mostrando un efecto pobre del operador sobre las clases originales. De forma análoga, el operador de dilatación no genera cambios significativos sobre el conjunto difuso del cual se origina. Los cambios serían aún más pequeños para las formas trapezoidales, pues el núcleo permanece inalterado [7].
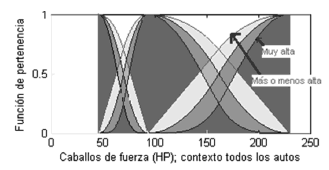
Figura 5. Modificadores de un conjunto difuso
Como lo señalan De Cock y Kerre [16], las funciones exponenciales que se han propuesto para la definición de los modificadores lingüísticos son sólo herramientas técnicas que conservan la propiedad de inclusión entre los subconjuntos difusos obtenidos, con el conjunto original etiquetado E, pero que carecen de significado como propiedad inherente. Por esto, hemos optado por otra estrategia que consiste en volver a realizar un proceso de discriminación sobre el conjunto que representa la etiqueta de interés.
Si la clase que necesita modificarse con el adverbio "muy" corresponde a la clase de los valores más pequeños y dado que el límite superior es el percentil P37.5, entonces el soporte del subconjunto difuso "muy bajo(a)" o "muy pequeño(a)" debe ser menor o igual al percentil P37.5 de ese conjunto, que equivale al percentil P14 de la distribución de todos los datos. Adicionalmente, el núcleo de la nueva función de pertenencia contiene al 12.5% de los datos menores del 37.5% de la clase con etiqueta "baja" o "pequeña". Por esto, el núcleo de la clase acentuada equivale al 4.7% de los valores más pequeños en todos los datos. Un razonamiento similar se aplica a la clase intermedia y a la clase de los valores "mayores" o "altos". En la Figura 6 se muestra la partición difusa propuesta para representar los conjuntos acentuados con el adverbio "muy.
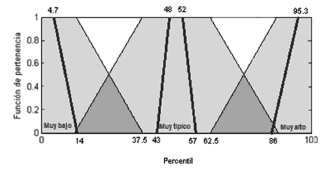
Figura 6. Clases acentuadas con el adverbio "muy"
Por su lado, el adverbio "extremadamente E", se puede interpretar como la acentuación del término "muy E". Entonces, se divide nuevamente el conjunto ya acentuado, en tres subconjuntos difusos, y se realiza un procedimiento similar al recientemente descrito.
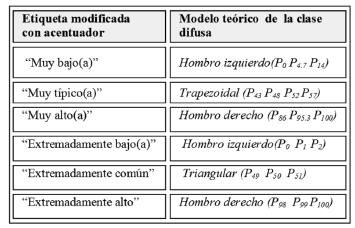
De acuerdo con lo anterior, los conjuntos difusos para encontrar la semántica de "muy" y "extremadamente", se pueden derivar de los datos del contexto (ver Tabla 3).
Tabla 3. Modelos teóricos para clases acentuadas
El adverbio "más o menos E", considerado sinónimo de "algo E", indica una interpretación más relajada del concepto vago que modifica. Es por esto que para definir el soporte del conjunto modificado se opta por incluir los elementos que superen a la mediana de la clase adyacente, cuando ésta sea menor o incluir los elementos que sean menores que la mediana de la clase adyacente cuando sea mayor a la considerada. Además, el núcleo de la función se amplía hasta cubrir los elementos que pertenezcan a la intersección con la clase vecina. Por esto, el conjunto que representa la relajación de un conjunto debido a la aplicación del modificador vago "más o menos" será hombro izquierdo, si se trata de la primera clase en el marco de cognición, una función trapezoidal si es intermedia y será hombro derecho si se trata de la clase con los valores más altos.
4. INTERPRETACIÓN DE COMPOSICIONES VAGAS
Un término vago complejo se deduce de una composición formada con el uso de las conectivas lógicas de la disyunción y la conjunción. El sistema de inferencia propuesto, en la interpretación de estos términos, usa el modelo FITA (acrónimo de First Infer Then Aggregate), que consiste en primero inferir los grados de pertenencia marginales o individuales a cada etiqueta lingüística especificada y luego agregarlos [18].
En lógica difusa, las operaciones de unión e intersección se determinan mediante las funciones de pertenencia.
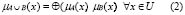
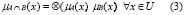
En (2) y (3), los símbolos 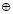 y
y 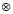 representan los operadores de la disyunción y la conjunción, respectivamente. Se han propuesto varias alternativas para representar la semántica de los operadores de la conjunción y la disyunción que cumplen con las restricciones para las s-normas y t-conormas [18]. Los operadores más comúnmente usados para representar las conectivas en la lógica difusa son el valor mínimo y el máximo de los grados de pertenencia, respectivamente, pues son duales con respecto a la negación fuerte. Esto quiere decir que, en su álgebra son válidas las leyes de De Morgan por eso un operador de estos puede derivarse o deducirse del otro. Sin embargo, el uso del máximo para representar el grado de pertenencia a la disyunción de conjuntos difusos, hace que se incumpla la ley del medio excluido, dado que
representan los operadores de la disyunción y la conjunción, respectivamente. Se han propuesto varias alternativas para representar la semántica de los operadores de la conjunción y la disyunción que cumplen con las restricciones para las s-normas y t-conormas [18]. Los operadores más comúnmente usados para representar las conectivas en la lógica difusa son el valor mínimo y el máximo de los grados de pertenencia, respectivamente, pues son duales con respecto a la negación fuerte. Esto quiere decir que, en su álgebra son válidas las leyes de De Morgan por eso un operador de estos puede derivarse o deducirse del otro. Sin embargo, el uso del máximo para representar el grado de pertenencia a la disyunción de conjuntos difusos, hace que se incumpla la ley del medio excluido, dado que 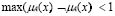 cuando el objeto x se encuentre en un área de solapamiento entre dos conjuntos difusos. Esto significa que se podría inferir que el grado de pertenencia de ciertos valores x al conjunto universal no sea 1, como se esperaría por la definición de este conjunto. Esto ocurre por no generar un conjunto convexo, como se aprecia en la Figura 7.
cuando el objeto x se encuentre en un área de solapamiento entre dos conjuntos difusos. Esto significa que se podría inferir que el grado de pertenencia de ciertos valores x al conjunto universal no sea 1, como se esperaría por la definición de este conjunto. Esto ocurre por no generar un conjunto convexo, como se aprecia en la Figura 7.
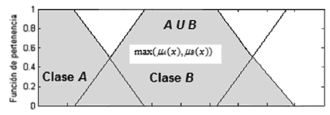
Figura 7. Conjunto difuso  convencional
convencional
Por lo anterior, el operador elegido para representar la disyunción, en un marco de cognición, es la suma convencional. Este operador es una s-conorma, bajo la restricción de Ruspini que se mencionó antes. Adicionalmente, la suma es una función continua que no produce grandes cambios en el conjunto derivado, cuando los cambios son pequeños en alguno de los dos conjuntos que actúan como operandos, tal como lo exige la teoría difusa estándar [19]. Por lo tanto, en esta propuesta, el conjunto derivado de la disyunción, queda determinado por la ecuación siguiente.
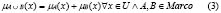 De acuerdo con (3), la representación gráfica de la unión de conjuntos es la que se presenta en la Figura 9, donde se ve claramente que el conjunto resultante es convexo, condición fundamental para que un conjunto difuso sea interpretable.
De acuerdo con (3), la representación gráfica de la unión de conjuntos es la que se presenta en la Figura 9, donde se ve claramente que el conjunto resultante es convexo, condición fundamental para que un conjunto difuso sea interpretable.
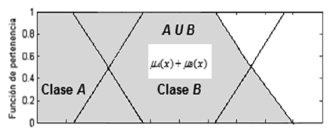
Figura 8. Unión de conjuntos usando la suma como operador
Infortunadamente, la suma deja de ser un buen operador para representar la unión de conjuntos cuando éstos sean de distintos marcos de referencia porque no se cumple la ley de la clausura. Debido a esto, en algunos casos, se podría concluir que el grado pertenencia global al conjunto difuso derivado por la conjunción de varias características sea mayor que 1. Por esto, han surgido propuestas distintas, que además consideran un peso diferente para cada etiqueta en la interpretación de las palabras vagas complejas. El operador LOWA (Linguistic Ordered Weighted Averaging) es un operador de este estilo que se basa en la operación OWA. Una operación OWA de la forma 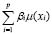 es una función con pesos
es una función con pesos 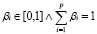 , que cumple ciertas propiedades como las condiciones de borde y la monotonía. El atributo de mayor peso, en la interpretación de la etiqueta vaga compleja, va primero y los demás van en orden decreciente. Por esto, el grado de pertenencia global de un objeto a la unión de p etiquetas vagas simples, se define mediante la ecuación siguiente.
, que cumple ciertas propiedades como las condiciones de borde y la monotonía. El atributo de mayor peso, en la interpretación de la etiqueta vaga compleja, va primero y los demás van en orden decreciente. Por esto, el grado de pertenencia global de un objeto a la unión de p etiquetas vagas simples, se define mediante la ecuación siguiente.
Por otro lado, para la representación del operador de la conjunción, se considera al mínimo de los grados de pertenencia de los operandos como la norma triangular más apropiada, puesto que usando este operador se cubre toda la zona de solapamiento entre dos conjuntos. El producto de los grado de pertenencia, que es otro operador propuesto, no la cubre en su totalidad, como se muestra en la Figura 11.
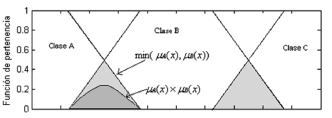
Figura 9. Operadores para representar la conjunción
El valor mínimo y la suma de los grados de pertenencia para representar las operaciones de la conjunción y de la disyunción, respectivamente, no cumplen la relación de dualidad con respecto al complemento. Sin embargo, la inexistencia de una relación de dualidad no es una limitación grave en la interpretación de una expresión vaga formada con conectivas lógicas en las condiciones de filtrado de una consulta.
CONCLUSIONES
Con la posibilidad de interpretar de las consultas vagas considerando su contexto lingüístico, como aquí se propone, se pueden construir no sólo sistemas de consulta-respuesta más flexibles, sino más confiables y amigables con el usuario final.
La técnica no supervisada propuesta para la minería de los datos, permite obtener los modelos de los conjuntos difusos, dinámicamente, sin la necesidad de expertos e independientemente de la distribución de los datos contextuales. Esto muestra la generalidad de la técnica.
Por otro lado, con la posibilidad que se le otorga al sistema de inferencia para discriminar en un número variable de clases o conjuntos difusos, se aprecia otra flexibilidad de nuestra propuesta, no sólo por la posibilidad de adaptarse a diferentes contextos, sino por admitir diferentes niveles de granularidad en la categorización difusa.
REFERENCIAS BIBILOGRÁFICAS
[1] Galindo, J., Introduction and Trends in Fuzzy Logic and Fuzzy Databases. En Handbook of Research on Fuzzy Information Processing in Databases. José Galindo. Idea Group Inc (IGI). 2008 [ Links ]
[2] Zadeh, L., Chapter 9. From Search Engines to Question Answering Systems– The Problems of World Knowledge, Relevance, Deduction and Precisiation. Capturing Intelligence, Vol 1, pp. 163-210. 2006. [ Links ]
[3] Carrasco, J., Reconocimiento de patrones. Instituto Nacional de Astrofísica Óptica y Electrónica. 2010. Disponible en: http://ccc.inaoep.mx/~ariel/recpat.pdf. [Citado en marzo de 2012]. [ Links ]
[4] Soto, C. y Jiménez, C., Aprendizaje Supervisado para la Discriminación y Clasificación Difusa. Revista Dyna. Vol 78 nro 169. 2011. [ Links ]
[5] Dyer, C., Machine Learning. Lecture Notes. Universidad de Wisconsin. Capítulos 18.1-18.3. Disponible en http://www.cs.wisc.edu/~dyer/cs540/notes/learning.html. [Citado en marzo de 2012]. [ Links ]
[6] Johnson, R. and Wichern, D., Applied Multivariate Statistical Analysis. Prentice Hall. 6ta ed. EEUU. 2007. [ Links ]
[7] Jiménez, C., Razonamiento Aproximado y Adaptable en el Procesamiento de Consultas Vagas. Tesis doctoral, Universidad Nacional de Colombia, Medellín. 2008. [ Links ]
[8] Borgelt, C., Combining Soft Computing and Statistical Methods in Data Analysis. Advances in Intelligent and Soft Computing, Vol 77, 611-618. 2010 [ Links ]
[9] Rokach, L., Using Fuzzy Logic in Data Mining. Data Mining and Knowledge Discovery Handbook. Springerlink. 2012. http://www.springerlink.com. [Citado en marzo de 2012]. [ Links ]
[10] Pedrycs, W., Granular Computing -The Emerging Paradigm. Journal of Uncertain Systems, pág.38-61. 2007. Disponible en: www.jus.org.uk. [Citado en marzo de 2012] [ Links ]
[11] Mencar, C., (2004). Theory of Fuzzy Information Granulation: Contributions to Interpretability Issues. Tesis doctoral. Universidad de Bari. Italia. Disponible en: www.di.uniba.it/~mencar/download/research/tesi_mencar.pdf. [citado en marzo de 2012]. [ Links ]
[12] Gonçalves, M. and Tineo, L., "A New Step towards Flexible XQuery". Avances en Sistemas e Informática. Vol 4(3). pp. 27-34. 2007 [ Links ]
[13] Gonçalves, M., Rodriguez, C. y Tineo, L., Incorporando Consultas Difusas en el Desarrollo de software. Avances en Sistemas e Informática. Vol 6(3). pp. 87-101. 2009 [ Links ]
[14] UCI. Machine Learning Repository. University of California, School of Information and Computer Science. Disponible en: http://archive.ics.uci.edu/ml/datasets/Iris. [citado en enero de 2012]: enero de 2012. [ Links ]
[15] Fodor, J., "Left-continuous t-norms in fuzzy logic: An overview". Acta Polytechnica Hungarica 1(2), ISSN 1785-8860. 2004 Disponible en: http://www.bmf.hu/journal/Fodor_2.pdf. [citado en enero de 2012]. [ Links ]
[16] De Cock, M. and Kerre, E., Fuzzy modifiers based on fuzzy relations. Information Sciences. Lecture Notes in Artificial Intelligence 3214, pp. 779-785. 2004 [ Links ]
[17] Cintula, P., Esteva, F., Gispert, J., Godo, L. and Noguera, C., Distinguished algebraic semantics for t-norm based fuzzy logics: methods and algebraic equivalencies, Annals of Pure and Applied Logic 160, pp. 53–81. 2009 [ Links ]
[18] Cox, E., The fuzzy systems handbook: a practitioner's guide to building, using and maintaining fuzzy systems. Academic Press. Estados Unidos.1994 [ Links ]
[19] Pradera, A., Trillas, E., Guadarrama, E. and Renedo., On Construction Imprecise Fuzzy Set Theories. European Centre for Soft Computing. 2006. [ Links ]

