










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353
Dyna rev.fac.nac.minas vol.81 no.186 Medellín July/Aug. 2014
https://doi.org/10.15446/dyna.v81n186.45223
http://dx.doi.org/10.15446/dyna.v81n186.45223
New product forecasting demand by using neural networks and similar product analysis
Pronóstico de demanda de productos nuevos mediante el uso de redes neuronales y el análisis de productos similares
Alfonso T. Sarmiento a & Osman Camilo Soto b
a Programa de Ingeniería Industrial, Universidad de La Sabana, Colombia, alfonsosava@unisabana.edu.co
b Ing. LOGYCA / INVESTIGACIÓN, Colombia, osoto@logyca.org
Received: May 12th, 2014. Received in revised form: July 1th, 2014. Accepted: July 28th, 2014
Abstract
This research presents a new product forecasting methodology that combines the forecast of analogous products. The quantitative part of the method uses an artificial neural network to calculate the forecast of each analogous product. These individual forecasts are combined using a qualitative approach based on a factor that measures the similarity between the analogous products and the new product. A case study of two major multinational companies in the food sector is presented to illustrate the methodology. Results from this study showed more accurate forecasts using the proposed approach in 86 percent of the cases analyzed.
Keywords: demand forecasting; new products; neural networks; similar products.
Resumen
Esta investigación presenta una metodología para pronosticar productos nuevos que combina el pronóstico de productos similares. La parte cuantitativa del método usa una red neuronal artificial para calcular el pronóstico de cada producto similar. Estos pronósticos individuales son combinados usando una técnica cualitativa basada en un factor que mide la similaridad entre los productos análogos y el producto nuevo. Para ilustrar la metodología se presenta un caso de estudio de dos grandes compañías multinacionales en el sector de alimentos. Los resultados de este estudio mostraron en el 86 por ciento de los casos analizados pronósticos más exactos usando el método propuesto.
Palabras clave: pronóstico de demanda; productos nuevos; redes neuronales; productos similares.
1. Introducción
Actualmente las empresas tienen que estar en constante cambio para poder enfrentar mercados cada vez más competitivos en un mundo globalizado, donde los consumidores se han vuelto menos leales y los ciclos de vida de los productos son cada vez más cortos. Debido a ello, la continua introducción de productos nuevos debe ser un componente vital en el planeamiento estratégico de las compañías [1] para mantener una ventaja competitiva.
Un producto nuevo es aquel que posee características que los consumidores perciben como innovadoras con respecto a los productos ya existentes. Por ejemplo, el refinamiento de los productos existentes mediante una mejora o una nueva función o, por otro lado, productos con propiedades totalmente nuevas [2]. Justamente estas nuevas características hacen que el comportamiento de compra del consumidor no pueda ser pronosticado exactamente con las curvas de demanda de productos actuales. Esto implica alterar curvas de demanda de productos similares (por ejemplo, en productos nuevos que son una mejora del producto actual) o generar nuevas curvas de demanda sin apoyo de datos históricos (por ejemplo, en productos totalmente innovadores que no existían anteriormente).
Existe una gran variedad de métodos estadísticos desarrollados para generar pronósticos. El mayor inconveniente es que estos métodos están basados en supuestos sobre las tendencias de los datos, teniendo que utilizar generalmente un modelo distinto para diferentes comportamientos de demanda [3]. En el caso en que la demanda pueda ser expresada en función de otras variables (drivers) adicionales al tiempo, como el precio, canal, publicidad, etc., los métodos tradicionales de pronóstico se basan en modelos lineales de tipo causal como el de regresión o de series de tiempo multivariadas como el modelo VARMA [4].
Los métodos de predicción basados en redes neuronales artificiales (RNA) han contribuido a mejorar la precisión de los pronósticos en situaciones de negocios [5]. Son métodos que aprenden de los datos, es decir, no tienen ecuaciones predeterminadas basadas en suposiciones sobre el comportamiento de los datos [6]. Eso les permite capturar las tendencias lineales y no-lineales presentes en la demanda. Entre las aplicaciones de las RNA como herramientas de predicción tenemos el pronóstico de: precios de mercados financieros, demanda de energía eléctrica y agua, tráfico de pasajeros, índices macroeconómicos, niveles de temperatura, caudal de los ríos y niveles de producción agregada entre otros [7].
La combinación de diversos métodos de pronóstico en un sólo modelo permite modelar diversos aspectos del negocio de las compañías y usar diferentes tipos de información. La integración de métodos estadísticos (cuantitativos) y métodos de juicio (cualitativos) pueden reducir la probabilidad de grandes errores de pronóstico [8]. La combinación de los métodos se realiza generalmente tomando una suma ponderada de los valores pronosticados por cada método en cada periodo de tiempo [9]. Existen varias formas de calcular las ponderaciones: usando pesos iguales, calculando los pesos mediante una regresión múltiple, usando pesos distintos basados en el conocimiento de expertos [10,11].
No existe una técnica de pronóstico que pueda ser aplicada con éxito a todos los tipos de productos nuevos. Este artículo se concentra en el análisis de productos nuevos cuyo pronóstico de demanda puede ser construido combinando los pronósticos de demanda de productos similares, los cuales son calculados usando RNA. Para combinar estos pronósticos se propone determinar el peso de los pronósticos de los productos similares a través de un factor de similaridad.
El resto de este artículo se organiza de la siguiente manera: en la segunda sección se presentan los tipos de productos nuevos y su clasificación de acuerdo al mercado objetivo y al tipo de tecnología requerida para fabricarlos; en la tercera sección se muestra el modelo de redes neuronales usado para generar los pronósticos; en la cuarta sección se muestra la metodología propuesta para pronosticar productos nuevos; en la quinta sección se presentan los resultados de los pronósticos aplicados a varios productos nuevos de dos empresas de consumo masivo en el sector alimentos; en la última sección se exponen las conclusiones y el trabajo futuro en esta línea de investigación.
2. Tipos de productos nuevos
Una forma de clasificar los productos nuevos es de acuerdo a las características que estos presentan con respecto al mercado objetivo al cual el producto está siendo lanzado y al nivel de tecnología usada para desarrollarlo [12]. De acuerdo a esta clasificación existen 7 tipos de
productos nuevos: 1) reducciones de costos (RC), 2) mejoramientos del producto (MP), 3) extensiones de línea (EL), 4) nuevos mercados (NM), 5) nuevos usos (NU), 6) nuevo para la compañía (NC) y nuevo para el mundo (NW). Estas decisiones son tomadas de acuerdo a la estrategia de crecimiento de la empresa: penetración de mercado, desarrollo de productos, desarrollo de mercado y diversificación, según se muestra en la Fig. 1.

3. Redes neuronales artificiales
Las neuronas son las unidades básicas de las RNA, y cada una de ellas se encarga de procesar una serie de entradas provenientes del exterior o de otras neuronas interconectadas y generan una única salida. Las redes neuronales multicapa se distinguen porque las neuronas están ubicadas en varias capas: una capa de entrada, en donde se recibe la información de fuentes externas a la red neuronal; una o varias capas ocultas (también llamadas intermedias), las cuales no tienen contacto directo con el entorno exterior a la red neuronal; y una capa de salida, que transfiere la información de la red hacia el exterior [13-15].
En general, el funcionamiento de una RNA es el siguiente: la información que va a ser analizada es alimentada a las neuronas de la capa de entrada, es procesada y luego propagada a las neuronas de la siguiente capa para un procesamiento adicional. El resultado de ese proceso es transmitido hacia la siguiente capa y así sucesivamente hasta la capa de salida. Cada unidad (neurona) de la red recibe información proveniente de otras neuronas o del mundo externo y procesa dichos datos, generando un valor de respuesta [16]. La Fig. 2 muestra la estructura funcional detallada de una neurona de una RNA.
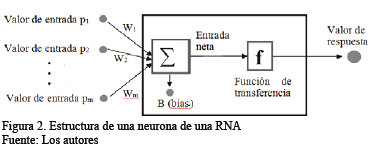
Como se aprecia en la Fig. 2, cada una de las neuronas artificiales (similar a como sucede con las neuronas biológicas) recibe unas entradas (pi) que pueden provenir del entorno externo o de las salidas de otras neuronas con las cuales se encuentre interconectada. A su vez, cada una de las entradas de las neuronas de una RNA tiene un peso asociado (Wi), conocido como peso sináptico, que proporcionan mayor o menor importancia a cada entrada y cuya función es emular el comportamiento existente entre las neuronas biológicas. Entre tanto, el parámetro B, se conoce como sesgo (bias) de la neurona.
La entrada neta de una neurona corresponde a la sumatoria de los "m" valores de entrada que recibe, modificados por sus pesos sinápticos correspondientes más el bias de la neurona. En términos matemáticos esto es:
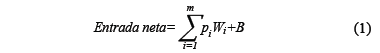
La entrada neta es luego transformada por la función de transferencia (también conocida como función de activación), cuya objetivo es limitar la amplitud de los valores de respuesta de la neurona. Existen funciones de transferencia lineales y no lineales, entre las que se encuentran: la función paso o escalafón, la función lineal o identidad, la función rampa o a tramos, la función sigmoidal o logística y la función tangente hiperbólica. La función sigmoidal es la función de activación más utilizada en redes neuronales y es recomendada para problemas de predicción [17].
Según Abdi et al. [16] el objetivo de la RNA es aprender o descubrir alguna asociación entre los patrones de entrada y de salida. Dicho proceso de aprendizaje se logra mediante la modificación iterativa de los pesos sinápticos que conectan las neuronas. Este proceso se lleva a cabo de acuerdo a un algoritmo de aprendizaje seleccionado [17].
Una de las estructuras de RNA más utilizada en el pronóstico de series de tiempo es la "perceptrón multicapa" [16], que cuenta con las siguientes características: a) no existen bucles ni conexiones entre las neuronas de una misma capa, b) las funciones de activación son iguales para cada neurona de una misma capa [18].
4. Metodología
El presente trabajo propone una metodología que involucra el uso de una técnica cuantitativa (RNA) para el cálculo de pronósticos de demanda a partir de la información histórica de productos de línea similares al nuevo producto que va a ser introducido al mercado, y su posterior ajuste mediante la aplicación de un factor que califica la similaridad entre el nuevo producto y el producto de referencia escogido.
La selección de la técnica de redes neuronales se debe a que ésta permite descifrar patrones de comportamiento de una serie de datos, determinando la influencia de diversas variables de entrada (drivers de la demanda) sobre una variable de salida (demanda); en contraste con las series de tiempo tradicionales, que sólo consideran la demanda histórica [19].
Los pasos que constituyen la metodología propuesta se visualizan en la Fig. 3 y se detallan a continuación:
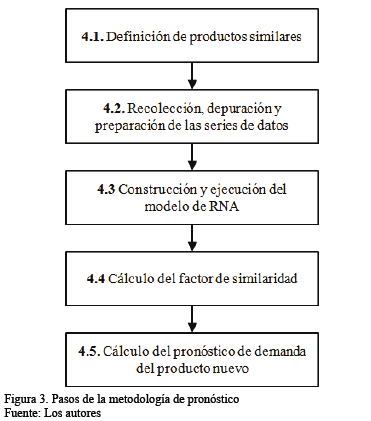
4.1. Definición de productos similares
La definición del producto similar depende en gran medida del tipo de producto nuevo a pronosticar. Por ejemplo, para los casos de un producto nuevo del tipo RC o MP, se cuenta con los datos históricos de demanda del producto original, antes de la modificación del precio o alguna característica. En el caso de las EL se cuenta bien sea con información del mismo producto en una presentación de mayor o menor tamaño o con información de productos pertenecientes a la misma familia o línea, pero que tienen una característica diferente, por ejemplo, el sabor. Para el caso de un producto tipo NM se recomienda utilizar la información del comportamiento del mismo producto en otro mercado donde ya haya sido introducido. Para el caso de productos NC se sugiere escoger un producto similar de la competencia, si se dispone de información de éste, en caso contrario se deberá buscar dentro del portafolio de la compañía el producto que más se aproxime al nuevo lanzamiento en cuanto a características como precio, mercado objetivo, etc. Para los productos NW, se sugiere dar más relevancia a otras técnicas cualitativas como el método Delphi [20], para estimar la aceptación potencial del producto nuevo.
4.2. Recolección, depuración y preparación de las series de datos
Esta actividad se centra en recopilar para cada uno de los productos similares, la información histórica de la demanda y de todas aquellas variables que también puedan influenciar el comportamiento de dicha demanda. Estas variables son conocidas como drivers de demanda, entre las que se encuentran el precio, el canal de ventas, la ciudad o región, la inversión en publicidad, la estacionalidad, entre otras.
Una vez recopilada la información, se deben eliminar los registros atípicos y preparar dichas series de datos para ser incluidas en el software de redes neuronales a utilizar. Por ejemplo, convertir una variable cualitativa como el canal de ventas en una variable numérica.
4.3. Construcción y ejecución del modelo de RNA
En este paso se debe definir la estructura de la RNA teniendo en cuenta la disponibilidad de información de los drivers de demanda.
Para cada producto similar (seleccionado en el paso 4.1) se debe desarrollar una red neuronal. El pronóstico resultante de la RNA dependerá del número de neuronas que se incluyan en la capa oculta, por tanto, se deben probar la inclusión de diferentes números de neuronas en dicha capa. Sin embargo, este número no debe exceder un máximo de neuronas (límite superior) dado por la Ec. 2, con el fin de evitar el sobre-entrenamiento de la RNA [21]:

Una vez definida la estructura de la red neuronal, se procede a entrenar la RNA. En el caso del cálculo del pronóstico de demanda esto equivale a resolver el siguiente problema de optimización:
Minimizar el error del pronóstico
Variando: los valores de los pesos sinópticos y el sesgo (bias) asociados con todas las neuronas de la RNA
La validación del proceso de entrenamiento se realiza generando un modelo de regresión, el cual muestra la relación entre los valores de los pronósticos generados por la red neuronal y los valores de la demanda que se busca predecir. Si el entrenamiento fue perfecto, dichos valores serían iguales (se ubicarían sobre una línea de 45 grados) y el coeficiente de determinación R2 sería igual a 1. Pero esa relación perfecta rara vez se da en la realidad. Para propósitos prácticos se tuvieron en cuenta sólo las opciones de configuración de redes neuronales que arrojaron R2≥ 0.5 (es decir, valores de R en valor absoluto mayores a 0.71) las cuales se consideran correlaciones fuertes [22] entre los pronósticos y los valores de la demanda.
Una vez que la red neuronal está entrenada, se encuentra en capacidad de generar los pronósticos. Para ello se debe definir un valor específico para cada una de las variables de entrada. La RNA toma dichos datos de entrada, los procesa y de acuerdo a los pesos que determinó para cada entrada y a las funciones de transferencia, genera un pronóstico de demanda.
Para cada producto similar se deben ejecutar varias "opciones" de configuración de RNA, variando el número de neuronas que contiene la capa interna y usando diferentes funciones de transferencia. Luego se selecciona la "opción" que genera un menor error de pronóstico para los datos de entrenamiento que se le suministren. Dicha opción de configuración será la utilizada para generar los pronósticos de demanda.
4.4. Cálculo del factor de similaridad
El factor de similaridad (FS) se usa para ajustar el pronóstico obtenido por la red neuronal. El pronóstico de cada producto análogo ó similar puede ser ajustado hacia arriba (incrementado) o hacia abajo (reducido) mediante la multiplicación de su valor por el FS, dependiendo de si se considera que las cifras de demanda del producto nuevo serán mayores o menores que las calculadas para el producto similar.
El método de cálculo propuesto para hallar el valor del FS se basa en determinar que "tan similar" es el producto nuevo respecto al producto análogo escogido. El FS se calcula con base en una combinación de los valores otorgados a ciertas características de los productos. Características típicas en el uso de este cálculo son: empaque (tipo de empaque), capacidad (tamaño), sabor y mercado objetivo. La evaluación de estas características se realiza entre el producto nuevo y cada uno de sus productos similares de forma independiente. A cada característica se le da un valor entre 1 y 10. El valor de 10 indica que ambos productos son 100% similares en esa característica, mientras que el valor de 1 indica que lo son sólo en el 10%, es decir muy poco similares.
La forma de combinar todos estos porcentajes en el número resultante del FS puede hacerse de dos formas: a) aditiva, mediante un promedio simple de los porcentajes) y b) multiplicativa, por la multiplicación de los porcentajes. El criterio multiplicativo es más estricto que el aditivo, en cuanto requiere que exista un mayor grado de similaridad en cada una de las características para que se consideren ambos productos altamente similares. La decisión para elegir una forma o la otra dependerá del impacto que el pronóstico del producto similar tendrá en el pronóstico del producto nuevo. Por ejemplo, el impacto en el cálculo de la demanda del producto nuevo por el ajuste (incremento/disminución) de la demanda de sus productos similares mediante el FS, es mayor si se usa el criterio multiplicativo.
A modo de ejemplo, la Tabla 1 muestra el cálculo de los posibles factores de similaridad que existen entre un producto nuevo denominado PN y su producto similar denominado PS. La parte izquierda de la tabla (Atributos) presenta los valores que se asignaron a cada uno de los atributos de similaridad evaluados al comparar que "tan parecidos" eran el producto nuevo y el producto usado como referencia; mientras que el lado derecho (Factores) muestra los valores resultantes al computar los puntajes de similaridad bajo el enfoque multiplicativo y bajo el método aditivo.

En el método multiplicativo, el valor de la columna "factor por debajo" es obtenido al multiplicar los porcentajes de similaridad de la parte izquierda de la Tabla 1. Es decir, factor por debajo = 0.5*0.9*0.7*0.5 = 0.16. Este resultado indica que las ventas del PN serán sólo el 16% de las ventas del PS. Entre tanto, la columna "factor de diferencia" muestra el resultado de la no similaridad entre los dos productos analizados, se obtiene como el complemento del factor por debajo. En otras palabras, factor de diferencia = (1- factor por debajo) = (1-0.16) = 0.84. Por último, en la columna "factor por arriba" se presenta el escenario de incremento de las ventas del PN en relación al PS como consecuencia de su no similaridad, o sea aplicando el factor por arriba = 1+factor de diferencia = 1+0.84 = 1.84. Lo cual se puede interpretar como que las ventas del nuevo producto serán 84% superiores o 1.84 veces las ventas del producto similar.
Por otra parte, en el método aditivo, el valor de la columna "factor por debajo" se estima como un promedio simple de los porcentajes de similaridad de cada característica, incluidos en la parte izquierda de la Tabla 1. Esto es, el factor por debajo = (0.5+0.9+0.7+0.5)/4 = 0.65. Lo cual significa que las ventas de PN serán el 65% de las ventas de PS. Los valores del "factor de diferencia" y el "factor por arriba" del método aditivo se obtienen mediante el mismo procedimiento descrito para el método multiplicativo.
En consecuencia, los factores de similaridad cercanos a 1 indican que la demanda del producto nuevo será muy cercana a la demanda pronosticada del producto similar. En consecuencia, que tanto el factor se aleje de 1 (por encima o por debajo) indica el grado de no similaridad.
4.5. Cálculo del pronóstico de demanda del producto nuevo
El pronóstico de demanda de un producto nuevo para un punto específico en el tiempo se obtiene al multiplicar el pronóstico del producto similar para ese periodo específico (calculado por la RNA escogida) por el factor de similaridad definido en el paso 4.4. Si se da el caso que para un producto nuevo se definan varios productos similares, su pronóstico de demanda se obtendrá como el promedio simple de los resultados de la multiplicación del pronóstico de cada producto similar por el factor de similaridad correspondiente. Entonces, el pronóstico para el periodo t de un producto nuevo que tiene "q" productos similares estará dado por la Ec. 3:

5. Caso de estudio y resultados
Con el propósito de evaluar la efectividad de la metodología propuesta para pronosticar la demanda de nuevos productos, se realizó una prueba de la misma en dos grandes compañías que tienen presencia en Colombia y Ecuador y que fabrican y comercializan principalmente productos alimenticios. Por la confidencialidad de la información, a estas compañías se les denominará A y B.
Para probar la metodología en estas dos compañías, el primer paso seguido fue identificar la disponibilidad de información sobre los drivers de demanda de los productos similares. Se determinó la disponibilidad de sólo 5 drivers de demanda (año, mes, canal, ciudad y precio). En consecuencia, y adoptando el modelo perceptrón multicapa descrito en la sección 3, se definió la siguiente estructura para las RNA utilizadas en el caso de estudio desarrollado, como se muestra en la Fig. 4:
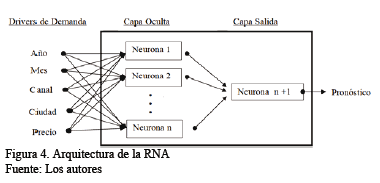
Para la selección de las funciones de transferencia, después de la realización de varias pruebas preliminares, se encontró que el uso de la función de transferencia sigmoidal en la capa oculta y la función de transferencia tangente hiperbólica en la capa de salida proveían los menores errores de pronóstico. Este resultado se corrobora con lo expuesto en la literatura sobre el uso de estas dos funciones de transferencia en RNA con estructuras no-lineales [23].
La prueba de la metodología se llevó a cabo para tres nuevos lanzamientos de la compañía A (denominados: 1A, 2A, 3A) y cuatro nuevos lanzamientos de la compañía B (denominados: 1B, 2B, 3B, 4B). Para los productos 1A y 4B, se determinaron 2 productos similares para cada uno; mientras que para los demás productos se eligió un producto
similar para cada uno. En dicha prueba se calcularon los pronósticos de demanda de cada producto para sus primeros tres o cuatro meses de vida en el mercado mediante la metodología propuesta y mediante la metodología actualmente utilizada por cada compañía. La metodología usada por la compañía A se basa en el análisis de los datos de productos similares y las sugerencias de las áreas de Mercadeo y Ventas. La metodología usada por la empresa B genera pronósticos con base principalmente en análisis de mercado realizados sólo por el área de Mercadeo.
Para analizar comparativamente la asertividad de los pronósticos generados por las dos metodologías, se decidió estimar como medida de desempeño el error medio absoluto porcentual (conocido como MAPE por sus siglas en inglés: mean absolute percentage error). El MAPE se obtiene usando la Ec. 4:
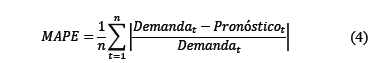
Donde "n" es el horizonte de tiempo para el cual se calculará indicador MAPE.
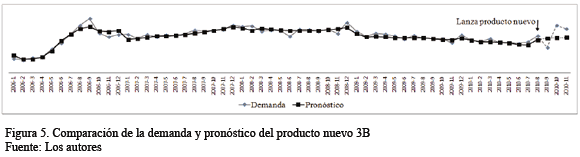
En la Fig. 5 se muestra el caso del producto nuevo 3B que fue lanzado en Agosto del 2010. Este era un producto nuevo tipo RC. Es decir, era el mismo producto que iba a ser lanzado con un menor precio de venta. Los últimos 4 valores en color gris (2010-8 al 2010-11) muestran los valores reales de la demanda (en unidades) para los meses de Agosto a Noviembre 2010; mientras que los últimos 4 valores en color negro muestran los valores pronosticados por la RNA. Al pronóstico calculado por la red neural mostrado en la Fig. 5 se le debía aplicar el factor de similaridad. Se usó un factor de similaridad de 1, ya que en esencia era el mismo producto pero con un precio menor. En consecuencia, para este caso, al aplicarle el factor de 1, el pronóstico final de la metodología coincidía con el generado por la red neuronal. Se obtuvo un MAPE 7.1% menor que el del pronóstico generado por la compañía B.
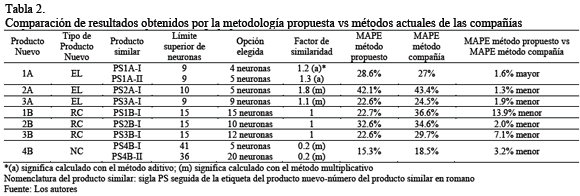
La Tabla 2 presenta los resultados obtenidos para cada una de las 7 pruebas (pronósticos de productos) realizadas con las dos compañías objeto de estudio. Dicha tabla indica para cada una de las pruebas el tipo de producto nuevo analizado, el número de productos similares considerados para la estimación del pronóstico con sus correspondientes factores de similaridad, el límite máximo de neuronas estimado mediante la fórmula descrita en la sección 4.3, la mejor configuración encontrada al analizar el desempeño de la RNA y finalmente la comparación de los errores de pronóstico (MAPE) de la metodología aquí propuesta y la metodología actualmente usada por las compañías estudiadas.
En el caso de la compañía B, la determinación de los factores de similaridad fue hecha por el área de Mercadeo y la determinación del método a aplicar estos factores (aditivo o multiplicativo) recayó en el área de Planeación de Demanda. En el caso de la compañía A, tanto la determinación de los factores de similaridad como el método a aplicar fueron definidos por el área de Planeación de Demanda.
Como se puede observar en la Tabla 2, la metodología propuesta generó un pronóstico más acertado para 6 de las 7 pruebas realizadas, obteniendo un MAPE entre 1.3% y 13.9% más bajos que el MAPE obtenido por las compañías respectivas.
6. Conclusiones
La metodología propuesta en este artículo demostró ser efectiva en la generación de pronósticos de demanda de productos nuevos para los cuales existe un producto similar que pueda tomarse como referencia. Los resultados obtenidos fueron superiores en el 86 por ciento de los casos probados con respecto al método actual usado por las dos compañías participantes. En el peor escenario se obtuvo un MAPE 1.6% mayor que el de la compañía; y en el mejor escenario se obtuvo un MAPE 13.9% menor que el de la compañía.
El método tiene un componente cuantitativo, que es el cálculo de los pronósticos de los productos similares usando RNA. Los autores proponen un método cualitativo, basado en un factor de similaridad, para combinar los pronósticos de los productos similares y calcular el pronóstico del producto nuevo. La selección de los productos similares y la estimación de los factores de similaridad, deben ser el resultado del consenso entre las opiniones de un equipo multidepartamental, que involucre diversas áreas de la compañía. Permitir que sólo un área de la empresa determine los factores de similaridad y su impacto puede originar pronósticos demasiado optimistas o demasiado conservadores según sea el caso. Aunque no se puede justificar como la única razón, en cierta manera, esto quizás podría indicar el porqué se obtuvieron mejores resultados con la metodología propuesta en la compañía B que en la compañía A, donde en esta última sólo el área de Planeación de Demanda intervino en la determinación de los factores de similaridad. Se deberán hacer pruebas adicionales para verificar esta hipótesis.
Como trabajo futuro, se propone agregar a la metodología propuesta la estimación de un valor esperado del pronóstico de la demanda a partir de la generación de varios escenarios de pronósticos (optimistas, neutrales y pesimistas) y la definición de sus probabilidades de ocurrencia correspondientes en cada uno de los periodos a analizar. También se destaca la posibilidad de incluir otras variables que afectan la demanda como las inversiones en publicidad o las promociones, bien sea como datos de entradas de las redes neuronales o como factores de ajuste adicionales.
Referencias
[1] Kahn, K.B., The hard and soft sides of new product forecasting, The Journal of Business Forecasting, 28 (4), pp. 29-32, 2009. [ Links ]
[2] Jain, C.L., Benchmarking new product forecasting, The Journal of Business Forecasting, 26 (4), pp. 28-29, 2007. [ Links ]
[3] Thiesing, F.M. and Vornberger, O., Sales forecasting using neural networks, Proceedings of the 1997 IEEE International Conference on Neural Networks, Huston, Texas, 4, pp. 2125-2128, 1997. [ Links ]
[4] Lütkepohl, H., Forecasting with VARMA models, In G. Elliott, C.W.J. Granger and A. Timmermann (Eds.), Handbook of Economic Forecasting, Vol. 1, chapter 6, Netherland, Elsevier, pp. 287-325, 2006. [ Links ]
[5] Adya, M. and Collopy, F., How effective are neural networks at forecasting and prediction?: A review and evaluation, Journal of Forecasting, 17, pp. 481-495, 1998. [ Links ]
[6] Mittal, P., Chowdhury, S., Roy, S., Bhatia, N. and Srivastav, R., Dual artificial neural network for rainfall-runoff forecasting, Journal of Water Resource and Protection, 4, pp. 1024-1028, 2012. [ Links ]
[7] Zhang, G., Patuwo, B.E. and Hu, M.Y.. Forecasting with artificial neural networks: The state of the art, International Journal of Forecasting, 14 (1), pp. 35-62, 1998. [ Links ]
[8] Sanders, N.R. and Ritzman, L.P., Judgmental adjustment of statistical forecasts, In J.S. Armstrong (Ed.), Principles of forecasting: A handbook for researchers and practitioners, Kluwer Academic Publishers, 2001, pp. 405-416. [ Links ]
[9] Yelland, P.M., Kim, S. and Stratulate, R., A bayesian model for sales forecasting at sun microsystems, Interfaces, 40 (2), pp. 118-129, 2010. [ Links ]
[10] Krishnamurti, T.N., Kishtawal, C.M., LaRow, T.E., Bachiochi, D.R., Zhang, Z., Williford, C.E., Gadgil, S. and Surendran, S., Improved weather and seasonal climate forecasts from multimodal ensemble, Science, 285, pp. 1548-1550, 1999. [ Links ]
[11] Armstrong, J.S., Combining forecasts, In J.S. Armstrong (Ed.), Principles of forecasting: a handbook for researchers and practitioners, Kluwer Academic Publishers, 2001, pp. 417-439. [ Links ]
[12] Kahn, K.B., New Product Forecasting: An applied approach, New York, M.E. Sharpe Inc., 2006. [ Links ]
[13] Ariza, A., Métodos utilizados para el pronóstico de demanda de energía eléctrica en sistemas de distribución, Tesis de grado en Ingeniería Electricista, Universidad Tecnológica de Pereira, Colombia, 2013. [ Links ]
[14] Flórez, R. y Fernández, J.M.F., Las redes neuronales artificiales: Fundamentos teóricos y aplicaciones prácticas. España, Netbiblo, 2008. [ Links ]
[15] Charytoniuk, W., Box, E.D., Lee, W.J., Chen, M.S., Kotas, P. and Van Olinda, P., Neural-network-based demand forecasting in a deregulated environment, IEEE Transactions on Industry Applications, 36 (3), pp. 893-898, 2000. [ Links ]
[16] Abdi, H., Valentin, D. and Edelman, B., Neural networks, California: SAGE Publications, 1999. [ Links ]
[17] Jiménez, J.M., Pronóstico de demanda de llamadas en los call center, utilizando redes neuronales artificiales,Tesis de grado en Ingeniería Industrial y de Sistemas, Universidad de Piura, Piura, Perú, 2013. [ Links ]
[18] Medina, S., Moreno, J. and Gallego, J.P., Pronóstico de la demanda de energía eléctrica horaria en Colombia mediante redes neuronales artificiales. Revista Facultad de Ingeniería, 59, pp. 98-107, 2011. [ Links ]
[19] Vaisla, K.S. and Bhatt, A.K., An analysis of the performance of artificial neural network technique for stock market forecasting, International Journal on Computer Science and Engineering, 2 (6), pp. 2104-2109, 2010. [ Links ]
[20] Fang-Mei, T., Ai-Chia, C. and Yi-Nung, P., Assessing market penetration combining scenario analysis, Delphi, and the technological substitution model: The case of the OLED TV market, Technological Forecasting & Social Change, 76, pp. 897-909, 2009. [ Links ]
[21] Ward Systems Group (WSG). Neuroshell 2, User's Guide, 2000. [ Links ]
[22] Taylor, R., Interpretation of the correlation coefficient: a basic review, Journal of Diagnostic Medical Sonography, 6, pp. 35-39, 1990. [ Links ]
[23] da S. Gomes, D.S., Ludemir, T.B. and Lima, L.M.M.R., Comparison of new activation functions in neural network for forecasting financial time series, Neural Computing and Applications, 20 (3), pp. 417-439. [ Links ]
A.T. Sarmiento, es PhD. en Ingeniería Industrial. Se ha desempeñado como investigador de CLI- Logyca y actualmente es investigador y profesor de planta de la Facultad de Ingeniería de la Universidad de La Sabana, Colombia. Además es miembro del grupo de investigación en Sistemas logísticos de dicha universidad. Sus líneas actuales de investigación incluyen la planeación de la demanda para productos nuevos, riesgo en la cadena de suministro, optimización de tamaños de empaques en productos de consumo masivo y modelos que combinan la optimización de la cadena logística, precios y beneficios (EPO-Enterprise Profit Optimization).
O.C. Soto, es MSc. en Ingeniería Industrial de la Universidad Nacional de Colombia - Sede Bogotá, Colombia. Se desempeñado como investigador Junior en Logyca / Investigación, Colombia.
