










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkDYNA
Print version ISSN 0012-7353
Dyna rev.fac.nac.minas vol.81 no.188 Medellín Nov./Dec. 2014
https://doi.org/10.15446/dyna.v81n188.40144
http://dx.doi.org/10.15446/dyna.v81n188.40144
Analysis of customer satisfaction using surveys with open questions
Análisis de la satisfacción de cliente mediante el uso de cuestionarios con preguntas abiertas
José Amelio Medina-Merodio a, Carmen de Pablos-Heredero b, María Lourdes Jiménez-Rodríguez c, Luis de Marcos-Ortega d, Roberto Barchino-Plata e, Daniel Rodríguez-García f & Daniel Gómez-Aguado g
a Escuela Politécnica Superior. Universidad de Alcalá. Alcalá, España, josea.medina@uah.es
b Facultad de Ciencias Jurídicas y Sociales. Universidad Rey Juan Carlos. Madrid, España, carmen.depablos@urjc.es
c Escuela Politécnica Superior. Universidad de Alcalá. Alcalá, España, lou.jimenez@uah.es
d Escuela Politécnica Superior. Universidad de Alcalá. Alcalá, España, luis.demarcos@uah.es
e Escuela Politécnica Superior. Universidad de Alcalá. Alcalá, España, roberto.barchino@uah.es
f Escuela Politécnica Superior. Universidad de Alcalá. Alcalá, España, daniel.rodriguezg@uah.es
g Escuela Politécnica. Universidad de Alcalá. Alcalá, España, daniel.gomeza@edu.uah.es
Received: October 7th, 2013. Received in revised form: March 3th, 2014. Accepted: October 27th, 2014.
Abstract
In this paper the use of open-ended questionnaires to improve the evaluation of customer satisfaction according to ISO 9001 in small and medium-sized enterprises is analyzed. By obtaining more information in comparison to the closed questions questionnaire some limitations coming from the second one are removed. The open-ended questionnaire is analyzed by applying a semantic study to obtain the root of each word and remove the word that is not relevant for the information needs of the organization. This way the positive or negative trend for each response is identified. This study proofs that the use of open-ended questionnaires facilitates the fulfilment of the ISO 9001 standard. It allows the comparison between the data coming from the Customer Relationship Management System (CRM) and the data obtained through the questionnaire. Furthermore it opens new areas of research based in the use of semantic analysis in quality systems and marketing.
Keywords: Customer's satisfaction, ISO 9001, semantic analysis, Lucene.
Resumen
En este trabajo se analiza, cómo el uso de cuestionarios de preguntas abiertas permite a las pequeñas y medianas empresas, mejorar la evaluación del grado de satisfacción de clientes según la norma ISO 9001. Al obtener mayor información que con los cuestionarios de preguntas cerradas, se eliminan las limitaciones de estos últimos. Para conseguir este objetivo, se han analizado las preguntas abiertas mediante su estudio semántico, obteniendo previamente la raíz de cada palabra y eliminando las que no aportan información, detectando la tendencia positiva y negativa de cada una de las respuestas. Este estudio prueba que el uso de cuestionarios de preguntas abiertas, facilita cumplir con la norma ISO 9001 y permite su comparación con los datos del sistema de gestión de las relaciones con los clientes (CRM - del ingles Customer Relationship Management). Además abre nuevas líneas de investigación de la semántica en los sistemas de calidad y de marketing.
Palabras clave: Satisfacción de cliente; ISO 9001; análisis semántico; Lucene.
1. Introducción
En un mundo cada vez más globalizado [1] conocer los gustos y las necesidades de los clientes genera una importante ventaja competitiva [2] al permitir descubrir nuevos clientes y fidelizarlos.
Con el fin de obtener la ventaja competitiva muchas empresas han optado por certificar sus organizaciones con la norma ISO 9001 [8] como se desprende de los últimos estudios presentados por ISO sobre la evolución de certificados de calidad [9].
El objetivo, de este trabajo se centra en analizar en qué medida el uso de cuestionarios de preguntas abiertas permite mejorar la evaluación del grado de satisfacción de cliente según la normativa ISO 9001 al obtener mayor información de los clientes.
Este análisis, se ha centrado en las pequeñas y medianas empresas, debido a que el tejido empresarial español está constituido básicamente por micro, pequeñas y medianas empresas, conocidas como Pyme (entre 0 y 249 asalariados) [6]. Según el directorio central de empresas (DIRCE), a 1 de enero del 2013 hay en España 3.195.210 empresas de las cuales 3.191.416 (99,88%) son Pyme [7].
Aunque este estudio es aplicable a todas las organizaciones independientemente de su tamaño y actividad.
Autores como Zaidi [3] y Prieto [4] indican que el 96 % de los clientes insatisfechos no se quejan, el 91% de los clientes insatisfechos no repiten y que cada cliente insatisfecho se lo dice a 10 personas. Además estadísticamente se ha calculado que cada reclamación significa aproximadamente 23 clientes perdidos y 250 informes negativos [5].
Por todo ello, se considera que la evaluación de satisfacción del cliente propuesta por la norma ISO 9001 mediante herramientas como los cuestionarios, es fundamental para conocer el grado de satisfacción del cliente. Al mismo tiempo los cuestionarios con preguntas abiertas permiten conocer mejor las necesidades de los clientes al no quedar limitadas a opciones prefijadas.
La estructura de este artículo está compuesta por una breve introducción, un análisis del estado de la cuestión, la metodología y arquitectura empleadas en el estudio.
Por último se presentan los resultados, conclusiones y las futuras líneas de investigación.
2. Estado de la cuestión
Las organizaciones buscan adaptarse a un mercado cada vez mas global, competitivo, y cambiante. En este ambiente cada empresa busca diferenciarse de su competencia de distintas formas: una de ellas, mediante la certificación de la empresa a través de uno de los estándares existentes de gestión de la calidad, p. e. la ISO 9001 [8] o a través de la autoevaluación prevista por el modelo propuesto por la Fundación Europea para la Gestión de la Calidad (EFQM - del inglés European Foundation for Quality Management) [11].
Para estos sistemas de gestión de la calidad los clientes son las figuras más importantes a la hora de definir los procesos y los requisitos organizativos. Uno de estos procesos pone especial hincapié en que las empresas deben evaluar la satisfacción del cliente, ya que conocer lo que piensan los clientes sobre los productos, los procesos de venta, gestión de incidencia, etc., facilita que la organización cumpla con los requisitos del cliente.
La propia norma ISO 9001 en su apartado 8.2.1 indica que la empresa tiene que establecer medidas necesarias para "realizar el seguimiento de la información relativa a la percepción del cliente respecto al cumplimiento de sus requisitos por parte de la organización" [2]
Aunque son muchas las posibles opciones para medir la satisfacción de cliente, esta se ha centrado en los cuestionarios porque permiten una más amplia cobertura, ahorro de tiempo, ya que se pueden obtener respuestas a miles de cuestionarios en horas o días. Prueba de ello es el creciente número de páginas que permiten realizar y publicar estos cuestionarios [17].
Es habitual que estos cuestionarios o encuestas de satisfacción se realicen mediante preguntas cerradas [10,13,16] permitiendo al usuario seleccionar la respuesta entre un número finito de posibles respuestas. La cantidad de soluciones de cada pregunta va a estar en función del nivel de escala Likert que seleccionemos y esta puede ser de 5, 7 y 10 niveles [15]. Lo que significa que si tomamos escala de nivel 5 la pregunta tendrá 5 posibles respuestas.
Además el tratamiento de estos cuestionarios es mucho mas sencillo, no provoca complicaciones y el coste de la relación información/precio frente a otras herramientas similares es mucho mejor.
Por otro lado, el uso de este tipo de evaluaciones conlleva distintos problemas, los más conocidos son la contestación automática al cuestionario marcado todos 1 o todos 5 sin examinar a que equivale el valor de uno y de cinco, motivo por el cual se añaden preguntas de control [14]. Otro problema es la falta de personalización de los cuestionarios en función del cliente.
Al convertir los cuestionarios cerrados en preguntas abiertas se permite a la empresa llevar a cabo un seguimiento de la satisfacción de cliente de forma más eficiente. De este modo, al disponer de la información necesaria, se puede conocer de la fuente original lo que puede mejorar en sus procesos de una forma más real.
Los cuestionarios de preguntas abiertas son difíciles de implementar y controlar porque nunca se sabe lo que un encuestado puede contestar. Además, no debemos olvidar que independientemente de que el cuestionario esté confeccionado con preguntas abiertas o cerradas, debe validarse.
Cabe destacar que para sondear y conseguir información del mercado, se suele utilizar también como herramienta el cuestionario que permite obtener la información con un coste relativamente bajo [12].
3. Metodología
Para llevar a cabo la investigación se ha diseñado un cuestionario de satisfacción de cliente según la norma ISO 9001 en el que las preguntas que se plantean son abiertas, es decir el encuestado puede contestar sin limitarse a las respuestas que vienen preestablecidas en los cuestionarios cerrados.
Posteriormente se ha justificado y evaluado la hipótesis planteada, concluyendo que los cuestionarios de preguntas abiertas permiten mejorar la evaluación del grado de satisfacción de cliente según la norma ISO 9001.
Con el desarrollo de un cuestionario y el tratamiento semántico de las cuestiones planteadas, se determinará el grado de información obtenido y se dará solución a los problemas derivados del uso de cuestionarios de preguntas cerradas mediante la realización de un caso práctico que presentamos a continuación.
4. Arquitectura del sistema
El entorno de trabajo que se ha diseñado para analizar las respuestas a las preguntas abiertas y estudiar su tendencia positiva o negativa permitirá a la empresa evaluar el grado de satisfacción de cliente y al mismo tiempo realizar investigación de campo.
4.1. Justificación del cuestionario según la norma ISO
El cuestionario esta compuesto por tres bloques: uno centrado en el producto, otro centrado en los servicios que proporciona la empresa y el último global. La justificación de la elección de estas preguntas y de estos grupos proviene de la norma ISO 9001:2008
Las primeras cuatro preguntas están relacionadas con el apartado 7.2 "Procesos relacionados con el cliente" y más concretamente con el punto 7.2.1. "Determinación de los requisitos relacionados con el producto". En él se indica que la organización debe determinar (i) los requisitos especificados por el cliente, incluyendo los requisitos para las actividades de entrega y las posteriores a la misma, (ii) los requisitos no establecidos por el cliente pero necesarios para el uso especificado o para el uso previsto, (iii) cuando sea conocido, los requisitos legales y reglamentarios aplicables al producto, y (iv) cualquier requisito adicional que la organización considere necesario.
Además se incluye una nota para las actividades posteriores a la entrega, por ejemplo, acciones cubiertas por la garantía, obligaciones contractuales como servicios de mantenimiento, y servicios suplementarios como el reciclaje o la disposición final.
Las siguientes cinco preguntas están vinculadas al apartado 7.2 Procesos relacionados con el cliente y más concretamente con el punto 7.2.3 Comunicación con el cliente, aunque cada pregunta hace referencia a algún apartado o punto de la norma.
En este apartado 7.2.3. se indica que la organización debe determinar e implementar disposiciones eficaces para la comunicación con los clientes, relativas a la información sobre el producto, las consultas, contratos o atención de pedidos, incluyendo las modificaciones, y la retroalimentación del cliente y sus quejas.
En la última pregunta del cuestionario propuesto: "¿Qué nos diferencia frente a la competencia?", se trata de obtener la percepción que los clientes tienen de la empresa con respecto a las demás empresas del sector y los matices que los diferencian de ellas, para lo cual se propone la posibilidad de responder mediante contestación múltiple a las características que más diferencien a la empresa.
4.2. Proceso de evaluación de la tendencia de las cuestiones
Si se analiza una pregunta y su contestación en un cuestionario con preguntas cerradas desarrollado en escala Likert 5, por ejemplo la pregunta "¿Los plazos de entrega son?", un cliente podría seleccionar entre cinco posibles respuestas "Muy bueno" "Bueno" "Regular" "Malo" y "Muy Malo".
Si por el contrario, las preguntas del cuestionario se transforman en preguntas abiertas evitamos que el cliente tienda a contestar automáticamente y necesitará escribir el texto de la respuesta, por ejemplo "Buenos".
En este caso y debido al idioma castellano el análisis de la respuesta tiene que ser capaz de tener en cuenta en cada palabra el genero, es decir, si se trata de masculino o femenino, y el número, plural o singular, a diferencia de otros idiomas como el inglés que no es necesario al no existir esta discriminación.
No hay que olvidar que el análisis morfológico es el estudio de la estructura de las palabras de un idioma y que a través del mismo se identifican sus respectivos morfemas. Por el contrario, el análisis semántico clasifica las palabras según su significado.
Si observamos una palabra de tendencia positiva como podría ser "bueno" y sacamos la raíz de dicha palabra, la cual seria "buen" vemos que seguiría siendo de tendencia positiva por lo que todas las palabras derivadas de la raíz "buen" también serán de tendencia positiva (bueno, buena, buenos, buenas, etc.).
De tal manera que si sabemos que la raíz "buen" y sus derivadas son de tendencia positiva, como se han sacado todas las raíces de las palabras, con buscar "buen" dentro de la contestación del cliente, estaríamos buscando implícitamente todas las palabras derivadas de buen, ahorrándonos así buscar el resto de palabras que tengan la raíz "buen".
Es por ello, que cada respuesta del cuestionario debe ser analizada, obteniendo cada una de las palabras que componen la oración.
Una vez realizado el proceso anterior se eliminan las palabras vacías (en inglés stopwords) [20] o que no aportan información, como son los determinantes, preposiciones y conjunciones que la componen, seguidamente se obtienen la raíces de las palabras y por último se analizan la tendencia positiva, negativa o neutra de cada una de ellas.
Se puede dar varios casos: el caso primero, que la respuesta a la pregunta del cuestionario tenga una única palabra y esta sea un adjetivo, por ejemplo "buenos" o "malos", en ese caso estos son reducidos a su raíz, "buen-" o "mal-", y se analizaría si tienen tendencia positiva o negativa.
Por otro lado, las respuestas pueden estar compuestas de varias palabras por ejemplo "son buenas" o "son buenas frente a la competencia". En estos casos, el sistema debe ser capaz de eliminar aquellas palabras que no tienen un valor sustancial con el fin de detectar si tiene una tendencia positiva o negativa
En el primer ejemplo "son buenas" al analizar se obtiene dos palabras "son" puede ser sustantivo o verbo y "buenas" que es adjetivo. En esta situación "son" es neutra, y "buen-" tiene tendencia positiva. En el segundo ejemplo "buenas frente a la competencia" al analizar se obtienen cinco palabras "buenas" "frente" "a", "la" "competencia", "a", "las", deben ser eliminadas al no aportar información, y las palabras restantes son reducidas a su raíz, por ejemplo "buenas" es reducida a "buen-", "frente" a "frent-" y "competencia" a "compet-" como apreciamos "buen-" tiene una clara tendencia positiva mientras que la raíz compet y frent son neutras.
En el caso de los verbos, se realiza un análisis morfológico de verbo, de manera automática, Consiste en encontrar la flexión de un verbo en infinitivo en cualquier tiempo y conseguir lematizarlo a su forma de infinitivo. Existen diversos lematizadores que usan como idioma base el inglés [27-30], pero en el caso del español es más complicado [31,32]. Una de esas características o limitaciones es la gran cantidad de conjugaciones que puede poseer un verbo en castellano, lo cual dificulta enormemente la generación automática de dichas conjugaciones.
Si la contestación fuera del tipo "no es bueno" el sistema lo detectaría como negativa debido al uso de un adverbio de negación antes de la raíz "buen", convirtiendo esta raíz positiva a negativa.
Es importante destacar, que no hay la misma complejidad cuando se analiza morfológicamente una palabra en ingles, que una palabra en castellano. El análisis morfológico de verbos en castellano no es una tarea fácil, aunque hay autores que lo han analizado [24,25] debido a sus peculiaridades características.
4.3. Integración y conexión entre sistemas
La búsqueda de la ventaja competitiva ha facilitado el desarrollo de aplicaciones CRM (Customer Relationship Management). Esta filosofía de negocio busca entender las necesidades de los clientes, por lo que la obtención de información a través de los cuestionarios nos permitirá cotejar que la información recibida por este sistema está en la línea correcta.
El sistema presentado en la Fig. 1 permite que el cuestionario se introduzca por un usuario de forma online mediante una Web o por el contrario se introduzca en el sistema después de recibirse en la empresa por fax o por correo electrónico proporcionando gran versatilidad para los usuarios.
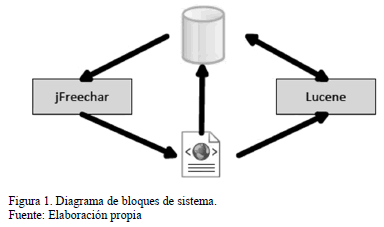
Los resultados de los cuestionarios obtenidos se almacenan en una base de datos MySQL.
Una vez introducidos los datos a través del formulario, mediante una aplicación en Java se capturarán todos los datos de las contestaciones de los clientes para saber si dichas contestaciones tienen una tendencia positiva o negativa, para esto se verá si las palabras que forman la contestación son como se ha comentado anteriormente positivas o negativas.
Cuando se realiza el procesamiento y análisis de las respuestas, si el programa detecta alguna palabra nueva que no está en la base de datos, será añadida previa consulta, en cuanto a si se trata de una palabra de tendencia positiva, negativa o neutra, una vez confirmada, se almacenará en la base de datos en su lugar correspondiente.
Para la representación gráfica [18] se ha optado por un sistema de indicadores mostrado por un cuadro de mando [22]. Esta herramienta nos permitirá facilitar la toma de decisiones en función de los resultados obtenidos.
Todo el desarrollo de la aplicación se ha basado en software libre. Por un lado, el desarrollo de la página web se ha realizado en PHP, ya que puede ser utilizado en los principales sistemas operativos, y se soporta en la mayoría de servidores Web.
El núcleo del sistema se ha desarrollado utilizando Lucene [19] por su potencia y posibilidad de modificación, facilita la búsqueda por campos y rangos.
4.4. Ensayo del sistema
Como se ha comentado antes, una de las funciones principales de la aplicación es el tratamiento de datos para que posteriormente sean utilizados por los demás programas. En la Fig. 2 se muestra las fases más importantes del proceso en la cual una de las funciones de esta aplicación es leer las respuestas de los cuestionarios que han sido contestados vía Web y tratadas de la manera adecuada, transformando esta información en información válida o necesaria para el uso en las aplicaciones .
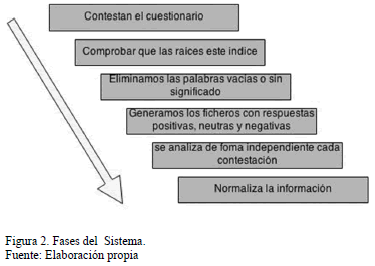
Lo que se realiza es una lectura completa de todas y cada una de las contestaciones de los clientes que están almacenadas en una tabla de una base de datos. Pero de estas contestaciones, no todo aporta información ya que hay partes que lo único que hacen es difuminar la información existente, consumir espacio de manera inútil o ralentizar el propósito de nuestro sistema.
Por ello, como se ha comentado anteriormente, una vez almacenadas las cadenas de texto contestadas en el cuestionario, son extraídas por el programa y se eliminarán las palabras que no aportan información significativa.
Estas palabras llamadas comúnmente palabras vacías o en ingles, stopwords [20], son aquellas palabras sin significado como artículos, pronombres, preposiciones, etc.
Una vez eliminadas las palabras vacías, para que la eficiencia de la aplicación sea aun mayor, realizaremos un barrido de stemming. El stemming es el método que permitirá reducir una palabra a su raíz.
Esto facilitará el procesado de la aplicación, ya que se buscan palabras positivas y negativas, pero si de dichas palabras se obtiene solo la raíz se disminuirá considerablemente el número de palabras con las que trabajar, ya que si ponemos como ejemplo una palabra positiva que podría ser bueno, su raíz seria buen y buscando esta raíz "buen" nos evitaríamos buscar el resto de palabras con dicha raíz como podrían ser buen, bueno, buenos, buenas. En vez de buscar entre todas esas palabras buscaríamos sólo sobre una, la cual es la raíz "buen".
En este caso se utilizará el algoritmo de steamming Snowball junto a Lucene, que es una API (del inglés Application Programming Interface) de código abierto para recuperación de información implementada en Java [21,23].
La eliminación de estas palabras hace que sea más ligero el algoritmo de procesamiento de palabras, ya que elimina palabras que para nuestro fin, no son relevantes en ningún caso y tendremos que tratar con menos palabras y esto provocará que el sistema sea bastante más rápido y eficiente.
4.4.1. Motor de búsqueda
El núcleo principal de esta aplicación, que procesa la mayor parte de información, se ha desarrollado con el fin de interactuar con Lucene.
Lucene no es un motor de búsqueda, pero se puede utilizar para implementar un motor de búsqueda, ya que es una herramienta de indexado y búsqueda de texto completo que posee funciones muy variadas e increíblemente útiles para este fin.
Lucene es una herramienta que permite tanto la indexación cómo la búsqueda de documentos y está implementada completamente en Java. Como se comentó anteriormente, Lucene no es un programa, sino una API, a través de la cual se añaden capacidades de indexación y búsqueda.
Se va a utilizar Lucene para las siguientes funcionalidades: (i) Eliminación de las palabras vacías, (ii) transformación de palabras a sus raíces, (iii) inserción de dichas palabras dentro de un índice de Lucene y (iv) poder buscar dentro de ese índice.
Lucene posee funciones por defecto para eliminar las palabras vacías, pero esta función se realiza para filtrar sólo palabras en inglés, en nuestro caso, ha sido necesario modificarlo creando una lista con todas o las máximas palabras vacías que hay en el castellano (se puede encontrar listas de palabras vacías fácilmente por internet).
Esto se puede realizar con la herramienta Lucene creando un array de tipo string que contenga todas las palabras vacías y pasar ese array a una función predefinida de Lucene junto con el texto o frase a la que se le quieren eliminar las palabras vacías, devolviendo esta función a un texto en el que se han eliminado todas esas palabras
Seguidamente se procedió a leer todas las palabras restantes y se pasará a extraer las raíces de cada una.
Para sacar las raíces de las palabras, se utiliza un lematizador (stemmer o algoritmo de stemming en inglés) que permite reducir una palabra a su raíz o (en inglés) a un stem o lema.
Cabe destacar que hay muchos para la lengua inglesa, pero por el contrario es difícil encontrar alguno para el idioma castellano.
La lematización de palabras se ha usado en un proyecto llamado Snowball que posee una librería aplicable a la programación en Java y se integra de forma perfecta con la herramienta de indexación y búsqueda Lucene.
En este caso la utilizarnos junto al algoritmo de Snowball para eliminar las palabras vacías y obtener de manera menos compleja y eficiente las raíces de las palabras e indexar las raíces de estas palabras obtenidas.
Snowball es un pequeño lenguaje para el manejo de strings que permite implementar algoritmos de normalización del lenguaje (stemming algorithms) mediante sencillos scripts. Posteriormente mediante un compilador se genera una salida en C o en Java.
Una vez indexadas las palabras en un índice, Lucene permite buscar las palabras dentro de dicho índice, mostrando la cantidad de palabras que ha encontrado dentro y que son iguales a la que se le ha indicado buscar.
Esto es muy útil en este caso, que queremos saber la cantidad de palabras positivas y negativas para obtener la tendencia de la contestación.
Todos estos algoritmos de lematización están basados en un algoritmo que se usaba inicialmente para la lematización de las palabras inglesas, y este es el algoritmo de Porter [26].
Una vez obtenidas las raíces de todas las palabras, sólo tendríamos que buscar entre ellas cuales son positivas y cuales negativas. Dependiendo de la cantidad de palabras positivas y negativas que haya en una contestación de una pregunta, se podrá obtener si dicha respuesta es de tendencia positiva o negativa
5. Resultados
Todo el proceso para analizar cada contestación de cada cliente no tendría ningún valor si no pudiéramos convertir esos datos en información.
Con ese fin se ha generado un cuadro de mando como herramienta que permita la toma de decisiones y se han implementado gráficas que facilitan su compresión de una manera rápida. Para ello nos hemos basado en la norma UNE 66175 [33].
En la Fig. 3 se puede ver cómo a partir de la contestación de los cuestionarios recibidos y su análisis, se muestran las preguntas positivas y negativas así como su porcentaje.
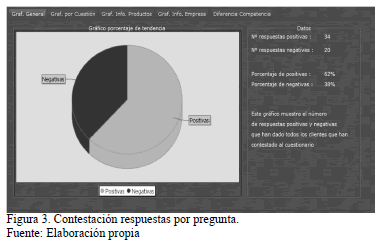
Durante la exposición del cuestionario propuesto se han desarrollado dos grandes grupos de cuestiones (i) uno referente a producto y (ii) otro referente a la información. En la Fig. 4 se observa el valor de tendencias positivas y negativas por pregunta referente al grupo de cuestiones de producto.
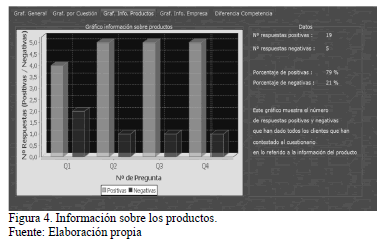
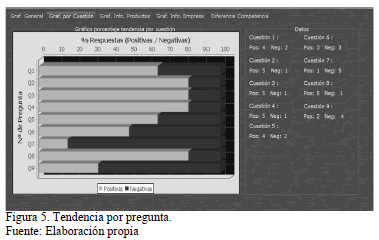
En la Fig. 5 se puede observar el valor de tendencias positivas y negativas por pregunta.
Finalmente, en la Fig. 6 se representa la información mediante un diagrama radial en el que se compara lo que se opina de la empresa frente a la competencia.

6. Conclusiones y futuros trabajos
En este artículo se ha descrito una aplicación que ayuda a las organizaciones que la usan a cumplir con la norma ISO 9001, facilitando la comparación entre los datos de CRM y los obtenidos a través del cuestionario.
El uso de cuestionarios Web facilita a la empresa obtener mayor número de cuestionarios a un coste relativamente bajo. Ya que este tipo cuestionario siempre tiene unas respuestas predefinidas para que el cliente conteste con una de ellas, al mismo tiempo, se obtienen las ventajas de las entrevistas.
Los cuestionarios tal y como se han implementado en este proyecto no son comunes, por la complejidad de los algoritmos usados para poder sacar las tendencias de las palabras.
Estos algoritmos de lematización son más comunes en idiomas como el inglés, pero en el caso de buscarlos con el idioma español son casi inexistentes por el gran incremento de complejidad que sufre el algoritmo debido a las formas verbales del español.
Este sistema permitirá a las empresas conocer más y mejor la opinión de sus clientes, no solo la respuesta sino que también cualquier matización de ella.
Además elimina errores cometidos en los cuestionarios de preguntas cerradas como son la contestación automática al cuestionario marcado todos 1 o todos 5 sin examinar a que equivale el valor de uno y de cinco y la eliminación de preguntas de control.
Dentro de las futuras líneas de investigación merece la pena analizar el grado de tendencia de las contestaciones a las cuestiones planteadas, así como relacionar este sistema con los CRM con el fin de realizar un análisis semántico de los informes de cada cliente y su verificación con los datos obtenidos de los cuestionarios de evaluación.
Aunque los cuestionarios son específicos como hemos indicado anteriormente, uno de los campos donde su aplicación puede ser importante a partir de los datos obtenidos en nuestro estudio es la investigación de mercados, donde los cuestionarios son una herramienta indispensable para desarrollar estudios de mercado.
Por otro lado como futura línea de trabajo se analizará el grado de positivismo y negatividad de la respuesta, ya que no es lo mismo bueno que excelente, pasando de un valor bivaluado por palabra, a un valor multivaluado en cada una.
Referencias
[1] Friedman, T. L. La tierra es plana: Breve Historia del Mundo Globalizado del Siglo XXI. Ciudad de edición, Ediciones Martínez Roca 2006. [ Links ]
[2] Soriano, C. L. La ventaja competitiva. Madrid, Ediciones Díaz de Santos S.A., 1997. [ Links ]
[3] Zaidi, A. QFD Despliegue de la función calidad, Madrid, Díaz Santos, 1993. [ Links ]
[4] Prieto, J., El servicio en acción: la única forma de ganar a todos, Bogotá, ECOE Ediciones, 2005. [ Links ]
[5] Plaza, A.S., Apuntes teóricos y ejercicios de aplicación de gestión del mantenimiento industrial- Integración con calidad y riesgos laborales, lulu.com, 2009. [ Links ]
[6] Moreno, M.E., Pyme Española: Características y Sectores. [en línea] [consulta: abril 8 de 2013] Disponible en: http://www.microsoft.com/business/es-es/content/paginas/article.aspx?cbcid=108. [ Links ]
[7] DIRCE (Directorio Central de Empresas), Retrato de las Pyme 2013, [en línea], [consulta: abril 23 de 2013]. Disponible en: http://www.ipyme.org/Publicaciones/Retrato_PYME_2013.pdf [ Links ]
[8] ISO 9001:2008, Sistema de gestión de la calidad. Requisitos, Madrid, Aenor, 2008, 42 P. [ Links ]
[9] ISO Survey 2011, World distribution of certificates in 2011 [online], [date of reference may 12th of 2013]. Available on: http://www.iso.org/iso/home/standards/certification/iso-survey.htm. [ Links ]
[10] UNE 66176, Guía para la medición, seguimiento y análisis de la satisfacción del cliente, Madrid, Aenor, 2005, 30 P. [ Links ]
[11] EFQM, EFQM MODEL [en línea] [consulta, mayo 22 de 2013]. Disponible en: http://www.efqm.org. [ Links ]
[12] Díaz-de Rada, V., Flavián, C. y Guinaliu M., Encuesta en Internet; Algo más que una versión mejorada de la tradicional encuesta autoadministrada, Investigación y Marketing, 82, pp. 45-56, 2004. [ Links ]
[13] García, T., El cuestionario como instrumento de investigación/evaluación [en línea] [consulta, mayo 15 de 2013] Disponible en: http://www.univsantana.com/sociologia/El_Cuestionario.pdf . [ Links ]
[14] del Castillo, A.M. Investigación de mercados, [en línea] [consulta, febrero 10 de 2013] Disponible en: http://openmultimedia.ie.edu/OpenProducts/usmc/usmc/pdf/USMC.pdf. [ Links ]
[15] DeVellis, R.F., Scale development: Theory and applications, Thousand Oaks Publicacions Inc., 2012. [ Links ]
[16] Dutka, A., Manual de la A.M.A. Para la satisfacción de cliente. Buenos Aires, Ediciones Granica, S.A., 1998. [ Links ]
[17] Google, Cómo crear un formulario de Google, [en línea] [consulta, marzo 13 de 2013] Disponible en: https://support.google.com/docs/answer/87809?hl=es [ Links ]
[18] Chart J., [en línea] [consulta, marzo 20 de 2013]. Disponible en: http://www.jfree.org/jfreechart/. [ Links ]
[19] Lucene, [en línea] [consulta, marzo 1 de 2013]. Disponible en http://lucene.apache.org/. [ Links ]
[20] Stop-words. [en línea] [consulta, marzo 12 de 2013] Disponible en: https://code.google.com/p/stop-words/ [citado 12 de marzo de 2013] [ Links ].
[21] Configure and manage stopwords and stoplists for full-text search, [en línea] [consulta, mayo 28 de 2013]. Disponible en: http://msdn.microsoft.com/en-us/library/ms142551.aspx [ Links ]
[22] Kaplan, R. and Norton, D., Cuadro de mando integral. Gestión 2.000. Barcelona. 2000. [ Links ]
[23] Cutting, D., Lucene, [en línea] [consulta, mayo 28 de 2013]. Disponible en: http://apachefoundation.wikispaces.com/Apache+Lucene. [ Links ]
[24] Zapata, C.M, and Mesa, J.E., Una propuesta para el análisis morfológico de verbos del español, DYNA, 76 (157), pp 27-36, 2009 [ Links ]
[25] Zapata, C. M and Mesa, J.E., Los modelos de diálogos y sus aplicaciones en sistemas de diálogo hombre-maquina: Revisión de la literatura, DYNA, 76 (160), pp. 305-315, 2009 [ Links ]
[26] The Porter stemming Algorithm, [onlíne], [date of reference, june 13th of 2013]. Available on: http://snowball.tartarus.org/algorithms/english/stemmer.html [ Links ]
[27] The English (Porter 2) stemming Algorithm, [onlíne], [date of reference june 10th of 2013]. Available on: http://snowball.tartarus.org/algorithms/english/stemmer.html [ Links ]
[28] Stemming early English, [onlíne], Available on: http://snowball.tartarus.org/texts/earlyenglish.html [ Links ]
[29] Muise, C., McIlraith, S., Baier, J.A. and Reimer, M., Exploiting N-gram analysis to predict operator sequences 2009. In 19th International Conference on Automated Planning and Scheduling (ICAPS09), Thessaloniki, Greece. A version of this paper also appeared in the ICAPS09 Workshop on Learning in Planning. [ Links ]
[30] Rojas-Galeano, S.A., Revealing non-alphabetical guises of spam-trigger vocables, DYNA, 80 (186), pp 50-57. 2013 [ Links ]
[31] Molino de Ideas, Lematizador, [en línea] [consultado junio 12 de 2013].Disponible en: http://www.molinolabs.com/lematizador.html [ Links ]
[32] Grampal, Lematizador para el español desarrollado en la Universidad Autónoma de Madrid, [en línea] [consultado junio 13 de 2013]. Disponible en: http://cartago.lllf.uam.es/grampal/grampal.cgi [ Links ]
[33] UNE 66175:2003. Sistema de gestión de la calidad. Guía para la implantación de sistemas de indicadores, Aenor, 2003, 30 P. [ Links ]
J. A. Medina-Merodio, Ingeniero Técnico en Telecomunicaciones en 2001 e Ingeniero Técnico Industrial en 2010 por la Universidad de Alcalá, Licenciado en Investigación y Técnicas de Mercado en 2007 y Doctor en Dirección de Empresas por la Universidad Rey Juan Carlos de Madrid en 2010. En la actualidad es Profesor Ayudante Doctor en el Departamento de Ciencias de la Computación en la Universidad de Alcalá. Anteriormente desempeñó funciones de Técnico de Gestión (Sistemas y Tecnologías de la Información) en el Servicio de Salud de Castilla la Mancha, Técnico Informático en ADAC- Asociación para el Desarrollo de la Alcarria y la Campiña y trabajó como Responsable de Calidad, Medioambiente y Servicios Informáticos en Tecnivial, S.A. ORCID ID: http://orcid.org/0000-0003-3359-4952
C. de Pablos-Heredero, Doctora en Ciencias Económicas y Empresariales es profesora en el área de Organización de Empresas en la Universidad Rey Juan Carlos de Madrid desde 1994. Responsable del programa de Doctorado en Organización de Empresas. Está especializada en el impacto de las tecnologías de información y comunicación en los sistemas organizativos donde desarrolla sus investigaciones principalmente. Ha dirigido tesis doctorales y proyectos en esta temática y publicado 78 artículos en revistas especializadas con índices de impacto y escrito 8 libros. Ha trabajado como consultora en Primma Consulting y es la Directora Académica del Master Oficial en Organización de Empresas y co-directora del Master en Emprendimiento y el Master en gestión de proyectos logísticos SAP ERP en la Universidad Rey Juan Carlos. ORCID ID: http://orcid.org/0000-0003-0457-3730
M. L. Jiménez-Rodríguez, es Licenciada en Ciencias Matemáticas por la Universidad Complutense de Madrid, en 2002 y Doctora por la Universidad de Alcalá, en 2006. En la actualidad es Profesora Titular en el área de Lenguajes y Sistemas Informáticos adscrito al Departamento de Ciencias de la Computación de la Universidad de Alcalá y profesora-tutora de la Universidad Nacional de Educación a Distancia (UNED) en los estudios de Grado en Ingeniería Informática y Grado en Administración y Dirección de Empresas. ORCID ID: http://orcid.org/0000-0003-4398-5404
L. de Marcos-Ortega, Ingeniero Informática en 2005 y Doctor en Informática en 2009 por la Universidad de Alcalá donde actualmente ocupa plaza de profesor ayudante doctor en el Departamento de CC. de la Computación. Cuenta con más de 90 publicaciones en revistas y congresos. Entre sus áreas de interés destacan los sistemas educativos y la formación en el ámbito de la informática (objetos docentes, competencias, sistemas adaptativos, movilidad y estandarización en las TIC aplicadas al aprendizaje); junto con distintos aspectos del ámbito de la computación evolutiva (algoritmos genéticos, enjambres partículas y optimización combinatoria). Ha participado en numerosos proyectos de investigación y cuenta con amplia experiencia en tareas de gestión y administración de estos proyectos. Ha completado estancias en las universidades de Lund (Suecia) y Reading (Reino Unido), y en el Instituto Tecnológico de Monterrey (México) donde ha realizado diversas actividades relacionadas con la docencia y la investigación. ORCID ID: http://orcid.org/0000-0003-0718-8774
R. Barchino-Plata, es Ingeniero en Informática por la Universidad Politécnica de Madrid en 2003 y Doctor por la Universidad de Alcalá en 2007. En la actualidad es Profesor Titular del Área de Lenguajes y Sistemas Informáticos adscrito al Departamento de Ciencias de la Computación de la Universidad de Alcalá además de ser Profesor Tutor de la Universidad Nacional de Educación a Distancia - UNED. Ocupa el puesto de Coordinador de Estudios Virtuales dentro del Instituto de Ciencias de la Educación de la Universidad de Alcalá. Es miembro, en calidad de vocal, del comité técnico de normalización 71, Subcomité 36: Tecnologías de la Información para el Aprendizaje de AENOR - Asociación Española de Normalización y Certificación. ORCID ID: http://orcid.org/0000-0002-5657-5191
D. Rodríguez-García, es licenciado en informática por la Universidad del País Vasco (EHU/UPV) en 1995 y doctorado en informática por la Universidad de Reading, Reino Unido, en 2003, donde ha sido profesor desde octubre del 2001 hasta septiembre 2006. Daniel obtuvo el certificado en educación universitaria por la Universidad de Reading en julio del 2005. Desde octubre 2006, es profesor en el departamento de Ciencias de la Computación de la Universidad de Alcalá, Madrid, consultor on-line en la UOC colabora habitualmente con Oxford Brookes Reino Unido. Además, Daniel tiene 2 años de experiencia en la empresa privada como ingeniero de software y consultor.
Sus intereses en la investigación se centran en la ingeniería del software, y la aplicación de distintas técnicas de la minería de datos y computación a la ingeniería del software. Daniel es miembro de las asociaciones profesionales ACM e IEEE. ORCID ID: http://orcid.org/0000-0002-2887-0185
