











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
Introducción
La comprensión del lenguaje depende de la integración que se hace de las diferentes formas de información mediante diversos procesos cognitivos. En particular, la representación léxica consiste de una serie de características asociadas a un concepto, es decir, no solo se considera la información básica asociada a la palabra (p. ej., auto), sino también los aspectos relacionados con la memoria episódica que evocan las interacciones asociadas a ese objeto o concepto (p. ej., el auto rojo que conducía ayer).1
Desde una perspectiva no descomposicional, las representaciones mentales de las unidades léxicas no pueden ser evocadas por sus constituyentes; sin embargo, desde el enfoque descomposicional se plantea que existen conexiones entre estas unidades (p. ej., hiperónimos) y el hecho que sus propiedades conceptuales generan bloques de representaciones semánticas.2 Así, un concepto puede ser representado como un nodo en una red de información que se asocia a otros conceptos con los que se intersectan sus propiedades.3
De hecho, de acuerdo con el modelo conexionista, la flexibilidad del reconocimiento léxico se da a partir de dos mecanismos complementarios entre sí: la excitación y la inhibición de las unidades léxicas, donde cada nodo léxico puede ser inhibido o activado dependiendo de la preactivación contextual lingüística, lo que produce un significado en particular.4 En este sentido, el reconocimiento léxico se genera por la activación de cada nodo léxico mediante el emparejamiento de la información acumulada y por la inhibición de las entradas léxicas que compiten por dicha activación.
Por otra parte, desde la fisiología, y a través de la medición de la respuesta neuronal unitaria, se ha observado la activación de unidades neuronales selectivas frente a estímulos provenientes de caras, animales, objetos o escenas,5 lo que sugiere que el procesamiento de los diversos estímulos es diferenciado y selectivo. Ahora bien, el procesamiento léxico se ha asociado generalmente con la activación en el hemisferio izquierdo del polo temporal del lóbulo temporal y del giro temporal anterior (zona ventral).6 Asimismo, teniendo en cuenta la relación entre procesamiento léxico y memoria episódica, se ha planteado que la porción posterior y medial del lóbulo temporal, junto con el hipocampo adyacente, juegan un papel importante en el procesamiento semántico.7,8 Igualmente, se ha reportado que existe una mayor actividad del giro angular cuando se reciben estímulos auditivos que consisten en frases semánticamente contrastivas 9 y frases altamente predecibles.10
Por otra parte, se ha reportado que cuando se realizan actividades de procesamiento preléxico (palabras que se rotaron acústicamente) y léxico, haciendo énfasis en el significado de las palabras, se produce la activación de una red neural en el hemisferio izquierdo que incluye el giro temporal inferior, la porción anterior del giro fusiforme, el hipocampo, el giro angular, el pars orbitalis, el giro frontal superior. el giro frontal medial y la porción derecha del cerebelo.11
Asimismo, se ha descrito que cuando se realizan tareas de decisión léxica en las que se utilizan palabras familiares, hay una activación bilateral del precúneo, la corteza temporal y la zona superior del lóbulo parietal, así como una activación en el hemisferio izquierdo del polo temporal, el córtex temporal posterior medial (visto desde el plano sagital), la porción anterior del giro fusiforme, el pars orbitalis, la corteza prefrontal, el cortex del cíngulo anterior y el putamen, además del giro precentral derecho.8 Por otra parte, en tareas de reconocimiento de palabras, se ha observado que el giro temporal superior se activa cuando las palabras escuchadas son diferentes a las esperadas.12
De acuerdo con el modelo neurocognitivo de Friederici et al.,13 en el procesamiento del lenguaje existe la siguiente secuencia lineal de aspectos segmentales: i) análisis fonológico, ii) procesamiento morfológico y léxico de las palabras, iii) procesamiento sintáctico e iv) integración semántica. Por su parte, el procesamiento semántico ha sido asociado a la corriente ventral, la cual conecta el área frontal anterior inferior del cerebro con el lóbulo temporal mediante el fascículo uncinado;13 además, este tipo de procesamiento ha sido ampliamente estudiado mediante el componente N400 de los potenciales relacionados a eventos (PRE).14
En este sentido, a pesar de que el N400 no es un componente exclusivo del lenguaje, sí ha permitido analizar con una alta precisión temporal el procesamiento léxico en contextos oracionales.15 De hecho, se ha descrito que otras violaciones de las reglas lingüísticas están relacionadas con otros componentes de los PRE16 (p. ej., las violaciones morfológicas se asocian con la negatividad anterior temprana izquierda). Teniendo en cuenta lo anterior, es posible decir que, si bien el N400 no es un componente específico del lenguaje, sí se asocia exclusivamente con el procesamiento semántico, pues se ha reportado un aumento de la amplitud de este componente cuando se utilizan palabras poco frecuentes, así como diferencias en su amplitud cuando se procesan estímulos concretos y abstractos.17
De igual forma, se ha planteado que la amplitud del componente N400 disminuye si hay una preactivación contextual lingüística o aumenta si hay una alteración a nivel semántico.18 De hecho, Molinaro et al.,19 al usar un paradigma de oraciones con pares mínimos en una estructura sustantivo-adjetivo con condiciones redundantes (lluvia mojada), anómalas (lluvia ciega) y contrastivas (lluvia seca), reportaron diferencias en la amplitud de este componente para cada una de estas condiciones.
Como se indicó arriba, se han identificado diferencias de amplitud del componente N400 cuando se procesan diversos paradigmas oracionales, mas no se han observado diferencias en su latencia de aparición. Al respecto, se ha propuesto que la diferencia en su latencia de aparición está relacionada con la composición semántica de los estímulos debido a la interacción entre la información contextual activada y las entradas semánticas, lo que tiene sentido si se considera la evidencia que existe sobre los modelos de predicción semántica.20
Por otra parte, se ha señalado que la amplitud de onda de este componente es menor cuando se procesan estímulos predictivos,16,21 por lo que podría afirmarse que los estímulos incongruentes que se encuentren en el campo léxico del estímulo esperado (p. ej., ha ladrado el perro vs. ha ladrado el caballo) generan una menor amplitud de onda que aquellos léxicamente lejanos al estímulo esperado (p. ej., ha ladrado el neumático); sin embargo, aún no existe evidencia de que esto suceda en el español. Además, el español es un idioma con procesos de lexicalización diferentes a los de otras lenguas, por lo que hay un especial interés en el estudio de su semántica.22
Teniendo en cuenta todo lo anterior, el objetivo del presente estudio fue determinar las diferencias temporales y espaciales de procesamiento entre las incongruencias léxicas semánticamente relacionadas a un contexto lingüístico oracional y las no relacionadas a través de mediciones electrofisiológicas de PRE, ya que, debido a su excelente resolución temporal, se consideran la herramienta más idónea para este fin.
Materiales y métodos
Participantes
Se realizó un estudio descriptivo, observacional, transversal con una muestra seleccionada por conveniencia. En el experimento participaron 10 estudiantes universitarios (4 mujeres y 6 hombres) con edad promedio de 25.8 años (desviación estándar (σ)=3.7), quienes fueron invitados mediante una convocatoria abierta a toda la comunidad universitaria. De los interesados, fueron seleccionados aquellos que reportaron, por una parte, no tener antecedentes de enfermedades neurológicas, psiquiátricas o trastornos lenguaje y, por otra, tener lateralidad diestra.
Corpus
Se construyó un corpus de 240 oraciones en español con la misma estructura sintáctica y agrupadas bajo tres condiciones: 80 oraciones congruentes (OC), 80 con in-congruencia dentro del campo léxico (IDCL) y 80 con incongruencia fuera del campo léxico (IFCL). La incongruencia léxica estuvo presente en el sustantivo de la cláusula y el contexto lingüístico fue provisto mediante el sujeto y el verbo, tal como se ilustra en la Tabla 1. Los sustantivos y verbos empleados en las oraciones fueron tomados de la lista de frecuencia de palabras del castellano de Chile23. En este sentido, las medias de longitud de los verbos utilizados en los tres grupos fueron: 6.2 (σ=1.6) para IDCL, 6.7 (σ=1.7) para IFCL, y 6.5 (σ=1.9) para OC.
Tabla 1 Ejemplos de los tres tipos de oraciones empleadas en el corpus.
| Tipo de oración | Oración |
| Oraciones congruentes | La profesora que observa las plantas está aburrida por el mal clima. El hámster que come las semillas es pequeño y siempre se pierde. El pato que agita las alas es interesante por su llamativo color. |
| Oraciones con incongruencias dentro del campo léxico | El chef que hierve los helados es brillante y tiene mucho éxito. El pirata que navega las montañas es malvado y todos le temen. El zapatero que arregla los pies está arrugado y parece un anciano. |
| Oraciones con incongruencias fuera del campo léxico | El cocinero que fríe los estantes es distinguido y lo quieren premiar. El jefe que contrata a las lentejas está ocupado y necesita un reemplazo. El cartero que reparte los volcanes está insatisfecho y quiere un aumento. |
Fuente: Elaboración propia.
Validación del corpus
La comprensión de las oraciones del corpus se validó mediante la precisión de acierto, es decir, la cantidad de respuestas correctas, de 9 estudiantes universitarios diferentes a los 10 que participaron en el experimento. Para la validación del corpus, 400 oraciones fueron presentadas visualmente a estos 9 individuos mediante el programa E-prime 3.0, e inmediatamente después de la exposición a cada oración, se les realizó una pregunta comprensiva, cuya respuesta fue registrada con una teclera. De esta forma, las 240 oraciones con mayor comprensibilidad fueron incluidas en el paradigma experimental.
Paradigma experimental
El paradigma fue programado en E-prime 3.0 para que las oraciones (estímulos visuales) fueran presentadas de forma automática, aleatorizada y sin repetirse y, de esta forma dificultar la estimación de aparición. Tal como se observa en la Figura 1, las oraciones se presentaron en una pantalla con fondo negro palabra a palabra, con un tiempo de exposición de 450ms para cada palabra, un intervalo interestímulo (ISI, por su sigla en inglés) de 200ms y un tiempo inter-ensayo (ITI, por su sigla en inglés) de 8250ms. Una vez finalizada la exposición a cada oración, se presentó una pregunta comprensiva dicotómica sin límite de tiempo para confirmar la atención de los sujetos, por ejemplo, para la oración "El zapatero que arregla los pies está arrugado y parece un anciano" se preguntó ¿El zapatero parece anciano? Además, cada palabra presentada se sincronizó a una etiqueta.
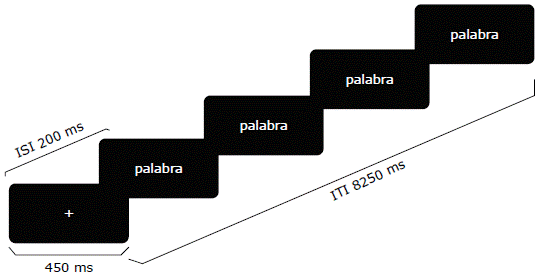
Experimento
El experimento se realizó en forma individual durante 50 minutos aproximadamente, con 5 sesiones de 7 a 10 minutos, dependiendo de la velocidad de respuesta de los participantes (n=10), a quienes se les solicitó leer las oraciones y contestar cada pregunta de acuerdo con la información recibida. Las mediciones electrofisiológicas se realizaron con un electroencefalograma Biosemi Active Two de 64 canales con frecuencia de muestreo de 1024Hz.
Consideraciones éticas
Una vez explicados los procedimientos a realizar y el objetivo del estudio, se obtuvo el consentimiento informado por parte de los participantes. Igualmente, el estudio fue aprobado por el Comité de Ética de la Universidad Santo Tomás según acta No. 171.16 del 11 de noviembre de 2016, y se siguieron los principios éticos de investigación biomédica en seres humanos establecidos en la Declaración de Helsinki.24
Análisis de datos
Para la medición conductual se realizó un análisis de la frecuencia de acierto de los participantes en las oraciones de cada grupo (OC, IDCL e IFCL), así como un análisis estadístico inferencial de su tiempo de respuesta en cada una. La precisión de respuesta fue analizada mediante una prueba de chi-cuadrado (X2), y se realizó un análisis de varianza (ANOVA) para determinar la varianza de las variables discretas (tiempo de respuesta y señales electrofisiológicas). Igualmente, se realizaron análisis post-hoc entre las tres condiciones y finalmente para estimar el tamaño del efecto se utilizó la d de Cohen mediante el programa estadístico JASP0.9.1.0. Para el análisis de las señales electrofisiológicas cerebrales se utilizó el programa Brain Vision Analyzer 2. Las señales electrofisiológicas fueron re-referenciadas con una transformada del promedio de los 64 canales, luego se aplicó un filtro pasa alto de 0.1Hz y un filtro pasa bajo de 30Hz. Posteriormente se realizó un muestreo de las señales a 256Hz y se realizó un análisis de sus componentes independientes para eliminar los artefactos visuales.
Por otra parte, la segmentación de las señales electrofisiológicas se realizó con base en la sincronización de las etiquetas de los sustantivos incongruentes, estableciendo una ventana temporal con un rango de -200ms a 1 000 ms. Luego se promediaron los 64 canales y se hizo una corrección de la línea de base; además, mediante la transformada de pooling de los canales de interés para el presente estudio (canal izquierdo: C1-FC1; derecho: C2-FC2, y central : Cz-FCz), se crearon tres regiones de interés. Finalmente, se promediaron las señales de todos los participantes y se obtuvieron los PRE.
Por otra parte, para la detección de fuentes cerebrales se exportaron los promedios de las señales electrofisiológicas de los 10 participantes al programa LORETA (Low Resolution Brain Electromagnetic Tomography). Se estableció un rango de latencia de 20ms del componente N400 antes y después de su pico para realizarei análisis estadístico independiente de los resultados obtenidos en cada grupo de oraciones y estimar las fuentes cerebrales. Finalmente, se generaron las soluciones inversas estableciendo un contraste en los grupos OC e IDCL, OC e IFCL, e IDCL e IFCL, lo que permitió establecer las zonas cerebrales con mayor activación en el procesamiento de los tres tipos de oraciones.
Resultados
Prueba conductual
El porcentaje de aciertos fue mayor en las OC (Figura 2). Las condiciones que presentaron dependencia de variables en la precisión de respuesta fueron OC con IDCL con un X2=4.69, (p=0.03) y OC con IFCL con un X2=4.69 (p=0.03). Por su parte, las condiciones IDCL e IFCL presentaron independencia de variables en la precisión de respuesta con un X2=0.388 (p=0.53).
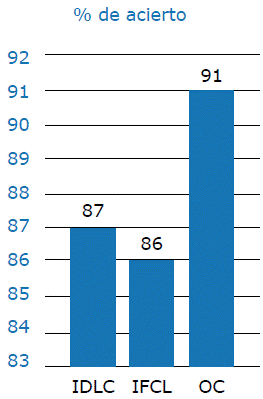
IDLC: oraciones con incongruencia dentro del campo léxico; IFCL: oraciones con incongruencia fuera del campo léxico; OC: oraciones congruentes. Fuente: Elaboración propia.
Figura 2 Porcentaje de aciertos de los participantes en los tres grupos de oraciones.
Por otra parte, las medias de los tiempos de respuesta observados en las OC, las IDCL y las IFCL fueron 2 026ms (σ = 1072), 2 200ms (σ = 1335) y 2 134ms (σ= 1229), respectivamente (Figura 3). Además, al realizar un análisis de varianza se observaron diferencias en los tiempos de respuesta entre las OC y las IDCL (df (grados de libertad)=1; F(Fisher)=4.981; p=0.026), entre las OC y las IFCL (df=979.0; F=2.157; p=0.142), y entre las IDCL y las IFCL (df=1; F=2.159; p=0.142).
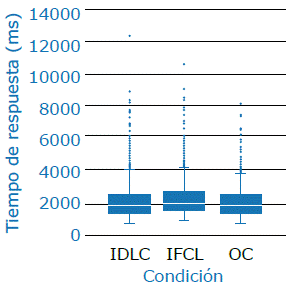
Potenciales relacionados a eventos
Mediante inspección visual de las señales registradas (Figura 4) se observó que los componentes exógenos tempranos, es decir, las respuestas sensoriales y perceptivas básicas, no presentaron diferencias entre los tres tipos de oración; sin embargo, se identificó una mayor negatividad de amplitud alrededor de los 400ms en las oraciones incongruentes. Esta negatividad se puede identificar como el componente N400, ampliamente estudiado en paradigmas léxicos.
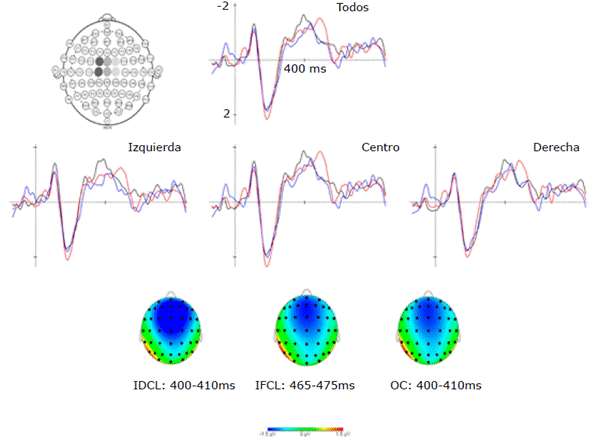
Todos: promedio de los 3 pooling, izquierda: pooling izquierdo, centro: pooling central; derecha: pooling derecho. OC: oración congruente (azul); IDCL: incongruencia dentro del campo léxico (negro); IFCL: incongruencia fuera del campo léxico (rojo). Fuente: Elaboración propia.
Figura 4 Potenciales relacionados a eventos.
Las diferencias de amplitud de este componente entre el procesamiento de las oraciones IDCL e IFCL no fueron estadísticamente significativas (F=0.279 (p=0.757)) considerando la ventana temporal del componente observado; no obstante, la diferencia en la latencia del componente entre estas oraciones sí fue estadísticamente significativa. En particular, al realizar un ANOVA se observó un F=71.12 (p=0.000) para la latencia del componente con la agrupación de las tres áreas de interés (Canal izquierdo; C1/FC1; derecho: C2/FC2, y Central Cz/FCz en las oraciones IDCL e IFCL. Además, en el análisis post-hoc entre las tres condiciones se observaron los siguientes valores: entre IDCL e IFCL: t=-12.055, Cohen's d = -2.301 / pTukey≤0.001; entre IDCL y OC: t=-6.385, Cohen's d = -1.226 / pTukey≤0.001, y entre IFCL y OC: t=-5.619, Cohen's d=-0.951 / pTukey≤0.001. Por otra parte, se observó un componente positivo sobre los 500ms que se podría asociar al componente tardío positivo; sin embargo, no se observaron diferencias estadísticamente significativas para este componente entre los tres tipos de oraciones.
Estimación de fuentes de actividad cerebral
Con el fin de comparar la distribución estimada de fuentes cerebrales mediante la técnica de análisis LORETA en el procesamiento del sustantivo de la cláusula, se consideró la ventana temporal de procesamiento léxico. De esta forma, se restó la activación cerebral de las condiciones OC-IDCL, OC-IFCL y ID-CL-IFCL y se analizaron las diferencias estadísticas con la solución inversa. De acuerdo con la Figura 5, en la estimación de fuentes de la condición OC menos la condición IDCL se observa una diferencia estadísticamente significativa al verse una mayor activación de la corteza frontopolar (valor mínimo del voxel = -9.060) y la corteza orbitofrontal (valor mínimo del voxel=-7.571).
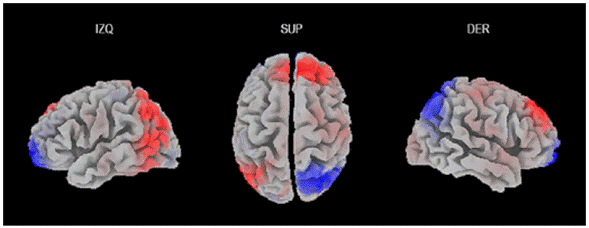
Fuente: Elaboración propia.
Figura 5 Solución inversa de oración congruente menos incongruencia dentro del campo léxico. IZQ: vista izquierda; SUP: vista superior; DER: vista derecha.
Por otra parte, tal como se observa en la Figura 6, en la estimación de fuentes de la condición OC menos la condición IFCL se observa que en el procesamiento de las oraciones IFCL hay una mayor activación en la corteza motora asociativa (valor mínimo del voxel=-9.492), la corteza prefrontal dorsolateral granular(valor mínimo del voxel=-9.527), la corteza frontopolar (valor mínimo del voxel=-9.934), la corteza orbitofrontal (valor mínimo del voxel=-9.859), el pars opercularis del giro frontal inferior (valor mínimo del voxel=-9.942), el pars triangularis del giro frontal inferior (valor mínimo del voxel=-9.310) y la corteza prefrontal dorsolateral (valor mínimo del voxel=-9.831).
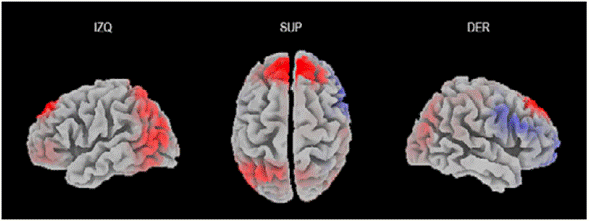
Fuente: Elaboración propia.
Figura 6 Solución inversa de oración congruente menos incongruencia fuera del campo léxico. IZQ: vista izquierda; SUP: vista superior; DER: vista derecha.
Por último, en cuanto al procesamiento de oraciones IDCL e IFCL, se observó una mayor activación (F=0.182 p=0.833) en el precúneo (valor mínimo del voxel=-9.834), la corteza orbitofrontal (valor mínimo del voxel=-9.840), la corteza frontopolar (valor mínimo del voxel=-9.784), el giro angular (valor mínimo del voxel=-9.863) y el giro supramarginal (valor mínimo del voxel=-9.965).
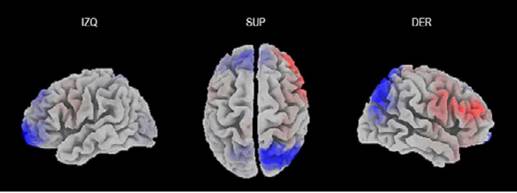
Discusión
En el presente estudio se observó una diferencia estadísticamente significativa en la latencia de aparición del componente N400 entre el procesamiento de oraciones IDCL (media de 402 ms en el pico de amplitud) e IFCL (media de 473 ms en el pico de amplitud). Estos resultados se pueden interpretar como parte de la modulación de la predicción de las representaciones léxicas debido a un desfase en la integración con la representación conceptual. En este sentido, se ha descrito una mayor latencia de aparición de este componente (con una extensión hasta los 750 ms) en experimentos de incongruencias léxicas con degradación acústica de los estímulos, lo que sugiere un retraso en el acceso léxico debido al aumento de carga cognitiva.25 Asimismo, se ha observado un retraso en la aparición de este componente en tareas de comprensión de oraciones con un intervalo inter-estímulo alargado entre la palabra objetivo y la palabra precedente, es decir, este retraso se asocia a la restricción contextual de la oración.26
Las hipótesis actuales para comprender el mecanismo subyacente del componente N400 disocian dos aspectos en particular: la pre-activación contextual lingüística y la integración con la representación conceptual. Por una parte, en la hipótesis de la pre-activación asume que la modulación del contexto lingüístico precedente induce el acceso léxico de la memoria de largo plazo. Por otra parte, la hipótesis de la integración propone que el N400 es un índice de incongruencia, ya que luego de acceder al significado de la palabra en la memoria de largo plazo, este se integra a la representación conceptual del contexto lingüístico precedente. En este escenario, la hipótesis factual asociada a la diferencia temporal del componente N400 observada entre el procesamiento de las oraciones IDCL y IFCL en el presente estudio responde al proceso anticipatorio de la comprensión del lenguaje, pues las unidades léxicas pre-activadas facilitan el acceso a las representaciones semánticamente relacionadas, aun cuando son incongruentes.
Por otra parte, las diferencias de activación entre el procesamiento de oraciones IDCL e IFCL observadas aquí, particularmente en el giro angular, se pueden explicar por la participación de esta área en la integración de la información compleja.27 Al respecto, el giro angular es considerado como un centro semántico heteromodal28 anatómicamente conectado con áreas de asociación secundaria, por lo que prácticamente no recibe información de las áreas sensoriales.29En este sentido, Benson et al.30 y Dronkers et al.31 señalan que las lesiones en esta zona producen diversos trastornos del lenguaje, tales como alexia, agrafia, anomia, acalculia, dificultades en la comprensión de oraciones, entre otros.
En esta línea, y considerando que se ha descrito una mayor activación del giro angular en el procesamiento de oraciones no relacionadas32 y de frases semántica y sintácticamente correctas,13 se ha sugerido que este es un centro de integración semántica que contribuye a la conceptualización de las palabras, lo cual se evidencia con el procesamiento en esta área de estímulos en conflicto con aquellos que se encuentran fuera del campo léxico.
Igualmente, se ha reportado que el precúneo es un área de activación asociada a procesos de reconocimiento visual ortográfico, específicamente de búsqueda visual, atención selectiva visual y análisis viso espacial de la vía dorsal (también llamada where pathway).33 Por otra parte, también se ha reportado que el giro supramarginal presenta una mayor activación cuando se procesan estímulos fonológicos, en particular en el área encargada de almacenamiento temporal de la memoria de trabajo,34 de ahí que esté involucrado en los procesos cognitivos asociados con la lectura.35 En este sentido, se cree que las diferencias de activación observadas entre el precúneo y el giro supramarginal, corresponden a procesos atencionales y de memoria de trabajo, lo cual es congruente con hallazgos del presente estudio, donde se observó una mayor activación de estas zonas en el procesamiento de oraciones con incongruencias fuera del campo léxico.
Por último, el córtex orbitofrontal, ampliamente estudiado por estar involucrado en procesos atencionales y de inhibición,34 también ha sido asociado a funciones relacionadas con la memoria de trabajo y la evocación de la memoria episódica.36 Teniendo en cuenta lo anterior, los resultados de este estudio sugieren que el compromiso de procesos atencionales y de memoria de trabajo es más elevado en el procesamiento de oraciones IFCL.
Conclusiones
El componente N400 presentó diferencias temporales entre el procesamiento de las incongruencias fuera del campo léxico y aquellas dentro del campo léxico, ya que la su latencia de aparición fue mayor en el primer caso debido a la dificultad de integración del significado de la palabra con la representación conceptual del contexto lingüístico precedente. Además, en el procesamiento de incongruencias fuera del campo léxico se observó una mayor activación del precúneo, el giro orbitofrontal, el giro angular y el giro supramarginal.

