










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkForma y Función
Print version ISSN 0120-338X
Forma funcion, Santaf, de Bogot, D.C. vol.25 no.1 Bogotá Jan./June 2012
INTERFERENCIA SINTÁCTICA ESPAÑOL-ALEMÁN: UNA APROXIMACIÓN DESDE LA TEORÍA DE REDES RELACIONALES*
SPANISH-GERMAN SYNTACTIC INTERFERENCE. AN APPROACH FROM THE RELATIONAL NETWORK THEORY
Matías Guzmán Naranjo
Universidad Nacional de Colombia
mguzmann@unal.edu.co
Artículo de investigación. Recibido 06-12-2012, aceptado 03-05-2012
Resumen
En el presente trabajo se compara la capacidad para explicar los fenómenos de interferencia sintáctica del Programa Minimalista y la teoría de redes relacionales-gramática de construcciones, teniendo en cuenta tanto los aspectos teóricos y formales, así como datos empíricos. Los resultados muestran que, en términos generales, el programa minimalista tiene falencias notables en el campo de la adquisición de la sintaxis de una segunda lengua y no puede explicar los fenómenos de interferencia sintáctica. Por otro lado, la integración de la teoría de redes relacionales y la gramática de construcciones ofrece una alternativa plausible para explicar la interferencia sintáctica.
Palabras clave: minimalismo, biolingüística, interferencia.
Abstract
This paper looks at the explanatory adequacy concerning interference phenomena in second language acquisition of the Minimalist Program and the Relational Network Theory-Construction Grammar. Both, formal and theoretical aspects of these theories, as well as empirical data were taken in account. Results show that the Minimalist Program can’t fully explain how the acquisition of a second language syntax works, nor the Interference Phenomena present in the process. On the other hand, the joint use of Relational Network Theory and CG offers a good and plausible alternative for explaining Interference Phenomena.
Key words: minimalism, biolinguistics, interference.
Introducción
La interferencia lingüística, y en especial los fenómenos de interferencia sintáctica (FIS), son un fenómeno ampliamente conocido y estudiado desde diferentes perspectivas y tradiciones lingüísticas. Las aproximaciones que se han hecho hasta el momento han sido de dos tipos: por un lado, los trabajos meramente descriptivos, y, por otro lado, las aproximaciones explicativas, que intentan dar cuenta de los procesos mentales que desencadenan los distintos tipos de interferencia.
La razón de estudiar la interferencia lingüística desde teorías cognitivas es que estas buscan entender los procesos cerebrales precisos que dan origen a la facultad lingüística de los hablantes y a los actos de habla producidos por aquellos. Más allá de preguntarnos "¿cuáles son las distintas formas de interferencia, su distribución y frecuencia?" nos preguntamos "¿cómo funciona exactamente la interferencia a nivel microscópico?" Dar respuesta a esta pregunta tiene importantes implicaciones teóricas y prácticas, y es el centro de trabajo de no pocos lingüistas contemporáneos (Ahukanna, Lund & Gentile, 1981; Azevedo, 1978; Gabryś, 2008; Grümpel, 2002; Martínez, 2004; Müller, 1998; Pienemann, 2005).
La gramática generativa transformacional (Chomsky, 1994, 1995; Dürscheid, s.f.; Grewendorf, 2002; Hornstein, 2009; Hornstein, Nuñes & Grohmann, 2005; Radford, 2009; Stepanov, Fanselow & Vogel, 2004) constituye, probablemente, el principal paradigma de investigación en la lingüística teórica, en especial en los campos relacionados con la neurociencia, la psicolingüística y las investigaciones sobre adquisición de lengua. El estudio del aprendizaje de una segunda lengua (L2)1 que ha surgido de esta corriente ha dado como resultado propuestas supremamente interesantes y con directas aplicaciones en la enseñanza de la L2.
El generativismo se ha construido con evidencia exclusivamente lingüística y, en los últimos años, neurolingüistas han buscado evidencia neurológica que lo soporte (Friederici, 2002; Grodzinsky & Friederici, 2006). No obstante, la gramática generativa (GG) no es universalmente aceptada, e incluso se ha llegado a sugerir que los principios fundamentales de la GG son errores perpetuados por la enorme popularidad de Chomsky (Gil, 2009). En los últimos años ha salido a la luz una enorme cantidad de literatura que pone en duda las ideas de Chomsky (Evans & Levinson, 2009; Hudson, 2010; Lamb, 1999; Lamb & Webster, 2004), por lo que resulta prudente considerar las objeciones y alternativas. La popularidad de la que goza la GG tiene, entonces, varias posibles explicaciones; entre ellas, se menciona la mala comunicación de los lingüistas funcionales y de corrientes no generativas con los neurolingüistas (Croft, 2009; Evans & Levinson, 2009).
Una teoría no muy conocida que fuertemente se opone al generativismo, y en particular al minimalismo, es la teoría de redes relacionales (TRR) de Sydney Lamb (Lockwood, Fries & Copeland, 2000; Gil, 2009; Lamb, 1999, 2000; Lamb & Webster, 2004; Pulju, 2000). La TRR es una propuesta neurocognitiva que, a diferencia de la lingüística sistémico funcional, sí cuenta con adecuación explicativa, porque ofrece un modelo de cómo podría organizarse la corteza cerebral para dar cuenta de todos los fenómenos del lenguaje. A diferencia de la teoría generativa, su motivación no es exclusivamente lingüística, sino que busca consistencia con lo que se conoce de neurología desde los acercamientos conexionistas.
Resulta entonces evidente la importancia de comparar ambas propuestas, desde un punto de vista teórico, y en su capacidad para explicar los FIS directamente observados. Un mejor entendimiento de las fortalezas y debilidades de estas teorías será de gran utilidad para comprender un poco más cómo funciona la adquisición de la L2 y qué métodos pueden utilizarse para facilitar el aprendizaje.
1. Gramática generativa
En el presente trabajo entenderé la gramática generativa (GG) en su sentido estrecho, considerando tan solo las corrientes transformacionales y dejando por fuera otras propuestas funcionalistas, como la word grammar (Hudson, 1984, 2007; Sugayama, Hudson & Shinkokai, 2006) y la gramática de papel y referencia (van Valin, 2005). La gramática generativa transformacional no es una sola e incluye diversos marcos teóricos, como la teoría estándar, la teoría estándar extendida, los principios y parámetros, la gramática léxico funcional y el programa minimalista, entre otros. La GG ha sido considerada como una aproximación cognitiva al estudio del lenguaje, pues intenta entender cómo este funciona internamente, y no solo su taxonomía externa (Radford, 2009).
1.1. Programa minimalista
De las muchas vertientes de la GG, adopto para el presente trabajo el programa minimalista (PM) (Boeckx, 2008; Hornstein, Nuñes & Grohmann, 2005; Radford, 2009); pero no trabajaré con algunos de los mecanismos y aspectos más especulativos, sino que me concentraré solo sobre los elementos que sean necesarios y que formen parte del consenso general.
En el presente trabajo no tendré en cuenta las propuestas de las DP (determinant phrase) porque son irrelevantes para los análisis de los fenómenos sintácticos considerados; en su lugar usaré la forma tradicional con NP (noun phrase). Asumo la existencia de una CP (complementizer phrase) para todas las oraciones completas, con un C (explícito o NULL [ausente]) que especifica la fuerza ilocutiva de la oración, y que asigna el caso nominativo del sujeto; también asumo la existencia de TP (time phrase), con un T con un afijo de carácter fuerte ʈ que tiene los rasgos de inflexión; y la de VP (verb phrase), en la que se generan el verbo y los argumentos internos y externos. Cada una de estas YP (y phrase) cuenta con un SpecY, que se representará siempre, así no haya ítems lexicales ocupándolo, y se asumirá que poseen un SpecNULL. Asumo, asimismo, que CP domina a TP, que a su vez domina a VP. Se asumirá la teoría del cotejo (checking theory) de rasgos no interpretables, que dice que las oraciones deben ser legibles para el sistema computacional, por lo que todos los rasgos no interpretables (ϕ) deben ser eliminados por medio del cotejo entre elementos del mismo dominio. Acepto también la propuesta de que el sujeto de la oración es generado en VP (VP-internal subject hypothesis), y que, seguidamente, sube a SpecT para cotejar los rasgos ϕ y para que C le asigne el caso nominativo. También asumo que los rasgos en T del alemán y del español son fuertes, por lo que V es arrastrado a T para eliminar aquellos rasgos ϕ y unirse a ʈ y así recibir tiempo, modo y número. La estructura básica de las oraciones en español sería, entonces, la siguiente:
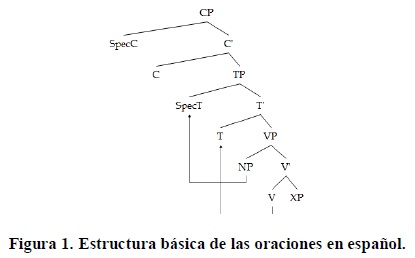
En cuanto a las oraciones negativas, no acepto la propuesta de que las NegP (negation phrase) se encuentran dominadas por TP y que dominan a VP (véase, por ejemplo, Radford, 2009), y asumo provisionalmente que tanto en español como en alemán las oraciones negativas se construyen por inserción léxica con la operación adjoin. La razón para esto es que en alemán y en español la posición de la partícula negativa (nicht y no, respectivamente) es difícilmente analizable haciendo uso de la hipótesis de que la NegP se une a la oración directamente con merge; y la derivación de algunas oraciones resulta innecesariamente compleja y, en ciertos casos, imposible.
1.2. Oraciones subordinadas en alemán
El alemán ya ha sido clasificado como un idioma SOV (orden subject-object-verb) (Müller, 1998; Sapp, 2006) y SVO (orden subject-verb-object) (Grümpel, 2002; Martínez, 2004). Grümpel y Martínez asumen un orden SVO y la existencia de proyecciones AgrS y AgrO. Por su lado, Müller y Sapp prefieren un orden SOV y no hacen uso de las AgrY. Para facilitar un poco la discusión, no tendré en cuenta las propuestas de Split VP, Split CP ni la existencia de las DP. Tampoco consideraré las discusiones sobre el momento en que los roles theta son asignados en las lenguas que presentan alto nivel de scramble, y acepto la propuesta de que, en alemán, tanto adverbios como partículas son insertadas en las oraciones por medio de la operación adjoin (Frey & Gärtner, 2002).
Trabajaré únicamente con la propuesta de Müller y Sapp, y no tendré en cuenta la propuesta de Martínez.
(1) Ich esse den Apfel
(2) Dass ich den Apfel esse
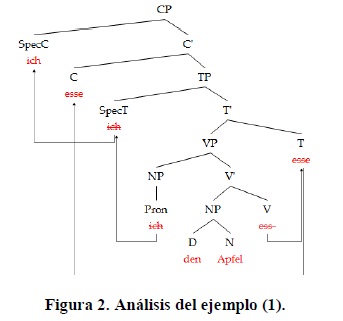
Hay algunos aspectos importantes en este análisis. Lo primero que hay que notar es que el movimiento hacia la derecha es posible y necesario porque se asume que tanto V' como T' se ramifican hacia la izquierda y que tienen su categoría lexical a la derecha. Lo segundo es que tanto SpecC como C poseen rasgos F y LC que activan el movimiento de último recurso de ich y de esse hacia estos, generando así la estructura superficial de las oraciones predicativas simples.
El análisis de (2) sería el siguiente:
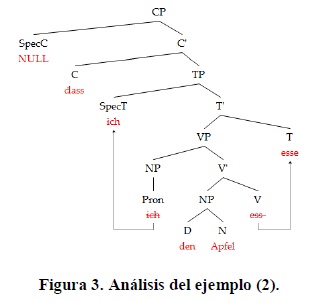
En (2) tenemos que C está ocupado por el complementizador dass, que bloquea el movimiento de esse desde T, y se encuentra acompañado por un determinante sin representación fonológica, NULL, que bloquea el movimiento de ich desde SpecT.
Si bien dentro del minimalismo hay diferentes formas de explicar las estructuras sintácticas del alemán, todos los modelos guardan algunas similitudes. Se asume que hay un orden subyacente en las oraciones y que, por medio de movimientos de los elementos, se crea el orden aparente de estas; también se asume que los movimientos, tanto del verbo como de los demás componentes, se dan por la necesidad del cotejo de rasgos funcionales y léxico-categoriales en CP y T.
2. La teoría de redes relacionales como una propuesta neurocognitiva
Como alternativa a la GG y al PM abordaré el problema de la interferencia desde la teoría de redes relacionales (TRR), de Sydney Lamb (Lockwood, Fries & Copeland, 2000; Gil, 2009; Lamb, 1999; Lamb & Webster, 2004). Dentro de la discusión también tomaré algunos elementos de la gramática de construcciones (GC), incluyendo aspectos de la versión radical (GCR) de Croft (Croft, 2001; Goldberg, 1995; Tomasello, 2003). Si bien es cierto que estas teorías son diferentes, con objetivos y métodos distintos, ambas son compatibles y pueden beneficiarse la una de la otra. Podría inclusive decirse que la GC da cuenta de los procesos cognitivos que se deben llevar a cabo para el manejo de las secuencias, mientras que la TRR es una herramienta para explicar el funcionamiento a nivel neurocognitvo de cada uno de estos procesos.
En la TRR se adopta la perspectiva de que el cerebro es una red de conexiones y no, como proponen algunos neurocientíficos (Pinker, 2007, 2008), un órgano capaz de manejar y almacenar símbolos. En general, la lingüística neurocognitiva critica los métodos de la lingüística analítica, en cuanto esta se fía de buscar patrones en los datos lingüísticos y asumir que tales patrones reflejan la realidad interna del lenguaje. Esta aproximación al lenguaje, a pesar de tener utilidad en la lingüística descriptiva, no necesariamente refleja la realidad cognitiva de los hablantes.
La importancia de la TRR radica en que es una de las pocas propuestas que intenta solucionar lo que Poeppel y Embick llaman el problema de contacto (Poeppel & Embick, 2005, 2-4); esto es: integrar las unidades discretas neuronales (neuronas, columnas corticales, sinapsis, etc.) con las unidades lingüísticas (morfemas, fonemas, sílabas, etc.). Los mismos autores agregan al respecto que: "[...] it is conceivable that the conceptual architecture of linguistics and neurobiology as presently conceived will never yield to any type of reduction, requiring instead substantive conceptual change in one or both of the disciplines"; y es precisamente esto lo que la TRR propone: repensar la lingüística para poder dar una explicación neurológicamente plausible de los fenómenos del lenguaje.
2.1. Redes relacionales y notación
La TRR hace uso de un amplio número de términos propios para distanciarse de otras tradiciones lingüísticas, que se evitarán, en lo posible, por motivos de simplicidad; así, se preferirán los conceptos clásicos de la lingüística analítica. También evitaré la notación fina y usaré exclusivamente la notación gruesa.
La TRR parte de la idea de que el sistema lingüístico funciona como una red de conexiones constituida por dos componentes: nodos y uniones entre los nodos. En la notación gruesa hay dos tipos de nodo: el O y el Y. La orientación de la activación de los nodos puede ser ascendente o descendente, y estos pueden ser ordenados o no ordenados. Cada nodo tiene un umbral de activación propio, que es el que determina cuándo la activación puede atravesar el nodo y seguir por las demás uniones conectadas a este. Los umbrales de activación no son homogéneos pues cada conexión puede tener un umbral distinto, y se asume que esta es una propiedad de los nodos (Lamb, 1999, p. 208).
Las líneas en la red unen nodos y llevan niveles de activación. Estas pueden tener más o menos fuerza y llevar distintos niveles de activación. Cada que una línea se activa, volver a activarla se hace más y más fácil. En la notación que se usará, las líneas representan uniones bidireccionales entre los dos nodos que conectan.
Describo a continuación el funcionamiento de los nodos:
• Y ascendente no ordenado
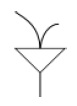
Debe recibir activación de todas las conexiones superiores para satisfacer su umbral y permitir que la activación continúe en dirección descendente. Si la activación es ascendente, el nodo enviará activación por todas sus uniones superiores.
• Y descendente no ordenado
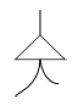
Debe recibir activación de todas las conexiones inferiores para satisfacer su umbral y permitir que la activación continúe en dirección ascendente. Si la activación es descendente, el nodo enviará activación por todas sus uniones inferiores.
• Y descendente ordenado

Se comporta igual que el Y descendente no ordenado cuando la activación es ascendente. Si la activación es descendente, el nodo enviará activación por todas sus uniones inferiores, pero una a una, de forma ordenada (por convención, la primera línea en activarse se ubica a la izquierda y las sucesivas a la derecha de esta).
• O ascendente no ordenado
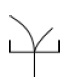
Cuando la activación es ascendente, el nodo se comporta igual que un nodo Y. Cuando la activación es descendente, el nodo solo necesita recibir activación de una de las líneas para satisfacer su umbral.
• O descendente ordenado
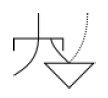
Este nodo tiene un comportamiento un poco distinto al de los anteriores. Si la activación es ascendente, se comporta igual que un Y descendente. Si la activación es descendente, el nodo solo activará una de las dos líneas, y preferirá activar la línea alternativa en caso de ser posible (esto es, si el nodo conectado a esta recibe suficiente activación para satisfacer su umbral). De lo contrario, activará la línea predeterminada (en la figura en la que se conecta directamente con la línea superior).
La 'nexión' se entiende como la unidad de organización modular básica de las redes relacionales; se delimitan porque tienen únicamente una unión que conecta inmediatamente un nodo de orientación ascendente con otro de orientación descendente. Todas las demás conexiones de estos nodos se consideran parte de la nexión.
Como ya mencioné, la TRR intenta explicar la totalidad del sistema lingüístico de las personas, y todos los estratos han recibido cierta atención en la literatura. No obstante, para el presente trabajo no tendré en cuenta el sistema fonológico y su interacción con el estrato morfosintáctico, no trabajaré el estrato morfológico del sistema sino que me limitaré a las formas fijas de los lexemas, ignorando conjugaciones y declinaciones. Tampoco tendré en cuenta las discusiones sobre el funcionamiento del estrato semántico y su conexión con los niveles conceptuales, ni sobre el funcionamiento del sistema sensorial y su interacción con el sistema lingüístico y cognitivo (para una discusión sobre estos niveles y estratos véase Lamb & Webster, 2004)
2.2. Sintaxis
2.2.1. Manejo de secuencias
El manejo de secuencias dentro de la TRR tiene otra alternativa. Sydney Lamb propone la posibilidad de que secuencias lexémicas podrían ser aprendidas como unidades completas, no analizadas sintácticamente por el hablante. Esta alternativa fue propuesta por primera vez por Adolf Noreen (Noreen, 2009), quien sugirió un análisis de la fonología del sueco en fonemas segmentales como unidades independientes. En español, las secuencias /ʈ∫/, /kr/ y /tr/ serían un solo fonema, según Noreen, y no la combinación de dos unidades separadas. Desde la lingüística analítica tradicional podría contestarse, ante esta propuesta, que es posible analizar estas unidades como la combinación de unidades menores, pero que la posibilidad de hacer este análisis no significa que así opere el cerebro. Esta idea la extiende Lamb a lo que él llama lexemas complejos, que serían aprendidos como unidades, y a los cuales el hablante no aplicaría ningún tipo de regla gramatical. Algunos ejemplos en español son "señal de alerta", "¿cómo amaneciste?" y "no te lo puedo creer". Así pues, cuando algo se experimenta muchas veces, se aprende como una unidad (Lamb, 1999, p. 164).
Esta alternativa parece, inicialmente, como un gasto innecesario de recursos que atenta directamente contra la economía propuesta por el minimalismo. Ciertamente, la propuesta de la TRR no es "minimalista" y posee redundancias. Desde el punto de vista de Lamb, la lingüística analítica, y en especial la chomskiana, subestiman la capacidad de memoria de las personas y buscan, por tanto, favorecer sistemas computacionales altamente complicados en vez de usar simplemente modelos y patrones previamente aprendidos (Lamb, 1999, p. 169).
El aprendizaje de estos lexemas mutables se da, inicialmente, por un proceso de lexicalización. Esto sucede cuando una combinación de unidades se repite numerosas veces, de tal forma que se convierten en una unidad en la red. Los lexemas más familiares son más fáciles de usar que aquellos poco usados o recientemente aprendidos (Lamb, 1999, p. 165). Esto es consistente con la idea de las conexiones fuertes propuesta por Lakoff (Lakoff, 2008): en cuanto una conexión se usa con mucha frecuencia, empieza a solidificarse y a recibir activación automática. Entre más se usa un sendero en la TRR, más fácil es volverlo a usar (Lamb, 1999, p. 179).
El siguiente paso a la lexicalización de oraciones es convertir el lexema fijo en un lexema mutable. El hablante puede, entonces, reemplazar elementos de este lexema por otros elementos semánticamente similares. Lamb propone que el hablante clasifica inconscientemente los distintos lexemas que conoce como pertenecientes a distintos grupos semánticos (Lamb, 1999, p. 267). Esta clasificación, podemos asumir, se da por la activación simultánea de otros nodos en niveles superiores (ejemplos de esto serían <comida> o <bebida>). Los lexemas de procesos (verbos) están también conectados a este nivel de categorías semánticas. Se tiene, entonces, que un verbo como comer está conectado a <aquel/aquello que come> y a <aquello comido>. La activación de comer activará también estos dos nodos. En caso de que falte alguno de los dos elementos, el oyente podrá asignar un "valor por defecto", como en la oración Yo como, en la que <aquello comido> se conecta con COMIDA en general y no con algo específico.
Los lexemas mutables son lexemas complejos ya cableados en el sistema lingüístico del hablante, en los que este puede reemplazar alguno de sus elementos para construir un nuevo lexema mutable.
Las expresiones encerradas entre <> se consideran constituyentes variables de los lexemas mutables o construcciones.
Algunos datos empíricos que parecen corroborar la hipótesis de los lexemas mutables son presentados por Tomasello (2003, p. 115), quien demostró que los niños adquieren marcadores sintácticos para algunos tipos de verbos antes que para otros, y que la mayoría de producciones en niños de entre uno y tres años se estructuran con base en un elemento fijo que puede recibir "argumentos" variantes.
Si bien la propuesta de los lexemas mutables es suficiente para explicar algunos tipos de oraciones en una lengua, no es capaz de explicar estructuras sin elementos fijos o construcciones.
2.2.2. Gramática de construcciones
Como ya se mencionó, la propuesta de los lexemas mutables es coherente con la GC en sus distintas variedades, por lo cual algunos de sus postulados serán integrados al manejo de secuencias desde la TRR.
La GC es una teoría monoestrática, no transformacional y generativa (en el sentido amplio). Surgió, inicialmente, del estudio de las expresiones idiomáticas (idioms). Expresiones como all of a sudden, in point of fact, the ADJ-er I..., the ADJ-er, all hell broke loose presentan un problema para las gramáticas reduccionistas porque no son expresiones lo suficientemente libres como para postular que son producto de una derivación, pero son mucho más complejas semánticamente que los ítems del lexicón, y su interpretación semántica no sigue las reglas generales que aplican a las oraciones no idiomáticas derivadas. Además, las construcciones pueden ser complejas y componerse de más de un elemento sintáctico. Las construcciones se definen como aquellos elementos en una lengua cuyo significado, forma o comportamiento no se deriva estrictamente de sus elementos constituyentes o de otros elementos de la lengua (Goldberg, 1995).
La postura de la GC consiste en que todo -la morfología, la estructura semántica y hasta la estructura sintáctica de las oraciones de una lengua- son construcciones no derivadas de sus elementos internos. En palabras de Croft: "[...] construction grammar has generalized the notion of a construction to apply to any grammatical structure, including both its form and its meaning" (Croft, 2001, p. 17).
Acepto la propuesta de la GC de que no hay una distinción estricta entre el lexicón y la sintaxis, y de que las construcciones y lexemas mutables son parte del lexicón, tienen una estructura semántica asociada independiente de sus elementos constituyentes y su comportamiento sintáctico es interno y no dependiente. La diferencia entre construcciones y lexemas mutables es la propuesta por Lamb: en los lexemas mutables solo unos cuantos constituyentes pueden variar (la madre de todas las <batallas>), mientras que, en las construcciones, la mayoría o todos sus elementos constituyentes son variables (Lamb & Webster, 2004, capítulo 15). Asumo también que la estructura argumental de las oraciones no se deriva directamente del verbo sino de la construcción como tal (Goldberg, 1995). Esto permite que verbos típicamente intransitivos puedan aparecer en construcciones transitivas como Llovieron perros y gatos. De igual manera, tendré en cuenta la distinción entre participantes y argumentos: los primeros aplican a la estructura de los verbos, los segundos a las construcciones.
Acepto también, bajo la propuesta de Croft (2001), que las construcciones marcan y definen funciones gramaticales diferentes, así como categorías gramaticales diferentes. De este modo, las construcciones transitivas (CTr)2 marcan sujetos transitivos (SjTr), mientras que las construcciones intransitivas (CInTr) marcan sujetos intransitivos (SjInTr). No obstante, acepto también la hipótesis de que existe un nivel de generalización más abstracto, del tipo SBJ, que se extiende tanto a SjTr y SjInTr (igual para los demás elementos).
Una expresión es normalmente el resultado de varias construcciones que interactúan: [Sbj VrbTran Ojb] + [Sbj no Vrb] → [(Yo) no te vi]. Las construcciones más específicas son "hijas" de construcciones más generales, así [Sbj VrbDiTran Obj1 Obj2] → [Sbj buscar3 Obj1 Obj2] → [Buscarle cinco patas al gato].
Algunos ejemplos de construcciones con valores semánticos asociados, no derivados de sus componentes, son los de las construcciones con de, como los siguientes:
- Una hoja de papel
- Un vaso de agua
- Sentado de rodillas
Como se puede ver, el valor semántico de de es asignado por la construcción, no puede entenderse aisladamente, y se requiere la construcción completa para poder asignarle un valor.
La forma en la que la GC y la TRR se integran será analizada en 3.3. Por ahora, basta decir que ambas teorías son totalmente compatibles y que la TRR se beneficia enormemente de la implementación de la GC.
Podemos decir, entonces, que, desde la propuesta lambiana y de la GC, los hablantes no crean realmente nuevas construcciones sintácticas, tan solo reutilizan las aprendidas de los demás. Esto responde a la idea de la pobreza del estímulo, que sugiere que los niños no tienen suficientes datos lingüísticos para aprender la sintaxis de una lengua por métodos cognitivos solamente, sino que requieren ciertos elementos de la gramática universal (GU). Los niños usan las estructuras sintácticas que escuchan, y, al volverlas a escuchar, sus conexiones y nodos se van reforzando; en caso de crear estructuras sintácticas "erróneas", estas no recibirán refuerzo ascendente, pues nadie más las usará y sus conexiones se debilitarán rápidamente. Esta perspectiva está de acuerdo con propuestas como la de Bavin (2009). Igualmente, Christiansen y Charter afirman que los niños que aprenden la sintaxis de una lengua "[...] must extrapolate a language from the sample of language they encounter; but such extrapolation is likely to be correct, given that it is the result of prior extrapolations by previous generations of learners" (Christiansen & Charter, 2009, p. 453).
2.3. Construcciones en alemán y español
Debido a la falta de trabajos dentro de la TRR sobre otros idiomas, no es posible encontrar dentro de la literatura propuestas para explicar el manejo de secuencias en el alemán. Propongo, entonces, la siguiente alternativa de análisis:
Teniendo en cuenta lo mencionado en el apartado 1.2., asumo que las diferentes estructuras sintácticas en las oraciones del alemán son producto de estructuras fijas que interactúan en distintos niveles de abstracción, y que especifican los términos y argumentos, así como el orden (u órdenes) de estos. De igual forma, asumo que estas construcciones tienen una representación directa en términos de TRR, que refleja su función y sus particularidades sintácticas, que especifica su interacción con otras construcciones y que, en una representación detallada, muestra también su correspondencia semántica.
Considero así las siguientes construcciones dentro del alemán: construcción transitiva (CTr) de la forma [SjTr VrTr Obj X], que, según marcas y topicalización, puede tener los órdenes SVOX4, OVSX, y XVSO; construcción subordinada (CSo) de la forma [Sub CTR] con el orden asociado [SubO CTr VrTr]; construcción subordinante (CSt) de la forma [CTr CSo] con los órdenes asociados [CTr, Sub CTr VrTr], y [Sub CTr, VrTr,VrTr, CTr]. De forma análoga, se organizan las construcciones intransitivas (CInTr). A esto hay que agregar el concepto de herencia entre las construcciones. La 'herencia' implica que una construcción hija tendrá todas las propiedades de la construcción padre, siempre y cuando estas propiedades no interfieran con las propias (Goldberg, 1995). Se supone entonces que las CTr y CInTr son ambas hijas de una misma construcción más abstracta, lo que las hace tener ciertas propiedades en común (véase órdenes de los argumentos, sujeto, etc.).
A continuación expongo una representación simplificada de la construcción transitiva en alemán.
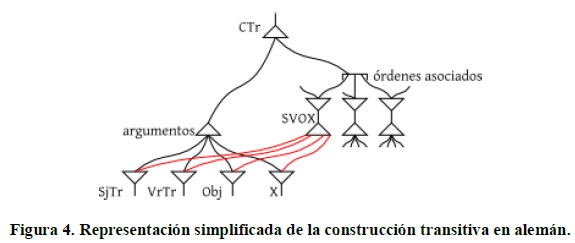
La red representa los elementos principales de la CTr: la construcción como unidad, su estructura argumental y los posibles órdenes que pueden tener estos argumentos. También muestra que el orden escogido depende de factores semántico-pragmáticos externos a la construcción y que la construcción aporta contenido semántico no derivado directamente de sus componentes. A diferencia de la CTr, la CSo solo tiene dos órdenes argumentales asociados: SOV y OSV. Las CInTr funcionan de forma similar, pero sin la presencia de Obj y con un SjInTr y un VrInTr.
El funcionamiento de las CSo y CSt es similar:
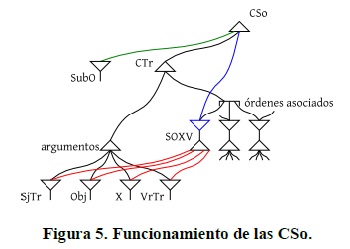
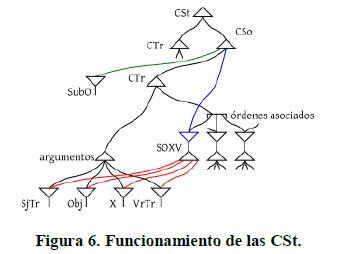
Las oraciones intransitivas tienen formas análogas. De nuevo, las construcciones están muy simplificadas, pero representan la forma en la que estarían organizadas las construcciones CSo y CSt en el alemán. Para no complicar innecesariamente la red, no representé algunos aspectos importantes de las CSt, como los posibles órdenes [CTr, CSo] y [CSo, VrTr, CTr], que son esenciales para explicar la interferencia desde la TRR.
En español, las oraciones subordinadas tienen un manejo similar, pero se diferencian radicalmente de las alemanas en el orden de sus argumentos. Igual que en alemán, el español contendría CSo y CSt en una jerarquía similar a la del alemán. Como en los casos anteriores, las CInTr se organizan de forma análoga.
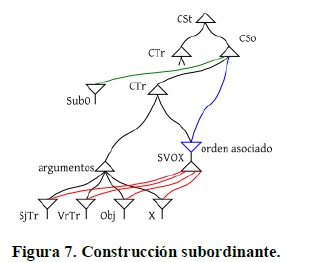
3. Estudio de caso
3.1. Recolección de datos y análisis
3.1.1. La población
Para el estudio se escogieron estudiantes de la Universidad Nacional de Colombia, pertenecientes a la carrera de Filología e Idiomas - Alemán, que se encontraban tomando los cursos de alemán Básico oral IV y Básico Oral VI (con 6 y 4 horas de clase a la semana, respectivamente) durante el segundo semestre del 2010. Todos los estudiantes se encontraban en un rango de edad de entre 18 y 22 años, con distribución proporcional entre mujeres y hombres. No se controló, sin embargo, ningún factor social porque ningún estudio realizado previamente sobre interferencia lingüística ha encontrado correlaciones significativas. Tampoco se han encontrado diferencias tangibles entre la capacidad de hombres y mujeres para aprender una segunda lengua (Martínez, 2004; Müller, 1998; Pienemann, 2005).
3.1.2. La encuesta
Para la recolección de los datos, se usaron pruebas orales de gramaticalidad. Las pruebas realizadas consistían en que los estudiantes escuchaban 25 oraciones leídas una sola vez por un hablante nativo de alemán, con intervalos de 1 segundo entre cada oración, y debían decidir si la oración era gramaticalmente correcta o no. Asumo que los datos así recogidos reflejan no solo la competencia de los hablantes al evaluar la gramaticalidad de las oraciones, sino también la distribución de errores producto de la interferencia al hablar.
Las oraciones usadas fueron las siguientes:
(1) *Ich trinke Bier, weil ich habe Durst.
(2) Es ist schade, dass ihr schon gehen müsst.
(3) Ich freue mich, dass ihr gekommen seid.
(4) *Er sagte, dass er hatte keine Lust.
(5) *Er will, dass sie kommt heute Abend.
(6) *Obwohl ich habe viel zu tun, kann ich spazieren gehen.
(7) Ich sah, dass jemand im Zimmer gewesen war.
(8) Mozart war ein Wunderkind, weil er schon mit fünf Jahren komponierte.
(9) *Obwohl ich bin krank, werde ich ins Kino gehen.
(10) *Dass er kommt noch nicht, ärgert mich sehr.
(11) *Weil Das achtjährige Kind aus der Schule kam zu früh nach Hause, konnte es seinen Vater treffen.
(12) *Ich gehe jetzt nach Hause, weil ich bin müde.
(13) *Der Film hat mir nicht gefallen, weil er war langweilig.
(14) Obwohl sie müde ist, geht sie fleißig in die Schule.
(15) Obwohl Sandra noch Probleme bei der Arbeit hat, ist der Chef mit ihr zufrieden.
(16) *Weil es gefällt mir, trage ich ein Kopftuch.
(17) *Wir sparen Geld, weil wir möchten ein grünes Auto für meinen Geburtstag kaufen.
(18) Obwohl alle gesagt haben ich könnte das nicht, habe ich es trotzdem hinbekommen.
(19) Weil ich Hunger habe, esse ich etwas.
(20) *Wir essen kein Fleisch, weil wir möchten sehr gern bald Vegetarier werden.
(21) *Ich spreche mit meiner Chefin, weil ich will mir morgen frei nehmen.
(22) Obwohl es heute regnet, gehe ich joggen.
(23) *Obwohl ich bin ziemlich schlau, kann ich das Fach nicht bestehen.
(24) Weil ich müde bin, gehe ich schlafen.
(25) Obwohl ich nicht müde bin, gehe ich schlafen.
3.1.3. Los datos
La figura 8 muestra el porcentaje de errores por pregunta.
Tenemos que la varianza es para el Básico VI (Bs6) de 1.805556 y para el Básico IV (Bs4) de 2.349630. El promedio de error en el Bs4 fue de .2977778, mientras que el promedio de error del Bs6 fue de .3666667. Vemos, entonces, que la capacidad para evaluar la gramaticalidad de las oraciones subordinadas en alemán no necesariamente mejoró en el Bs6 con respecto al Bs4. Puede decirse incluso que en promedio, hubo más errores entre los estudiantes de Bs6. Se observa no obstante que, en el Bs6, s fue menor; es decir, la cantidad de errores por pregunta fue ligeramente más homogénea.
A primera vista, la gráfica parece sugerir que algunas preguntas presentan una dificultad similar a todos los estudiantes que presentaron la prueba. Si tomamos la correlación (ρ) entre el Bs6 y el Bs4 según su desviación de los promedios μx, μy por pregunta, tenemos que ρBs4Bs6 = .6198216. Un ρBs4Bs6 de esta magnitud (entre .6 y .8 se considera una correlación regular) corrobora numéricamente que algunas preguntas presentan una dificultad mayor y otras, una dificultad menor de forma consistente. Volveré a esta observación más adelante.
Observando las gráficas arriba expuestas, resultan especialmente llamativas las oraciones (4), (7), (8), (10), (18), (19), (21), (23) y (24). Las oraciones (4), (7), (8), (19) y (24) son interesantes porque fueron las que tuvieron el menor número de errores. Llamaré a estas oraciones Err1. Las oraciones (10), (18), y (23) fueron las que mayor porcentaje de errores generaron (en adelante, Err2). Los resultados de la oración (21) resultan complicados de interpretar.
3.2. Análisis minimalista
La primera dificultad de analizar los datos desde el minimalismo es que no hay unidad en la literatura sobre cómo funcionan las segundas lenguas. No hay un consenso aún sobre si las gramáticas de las segundas lenguas se ven afectadas por la GU, o si el aprendizaje de aquellas es independiente de esta, es decir, si todos los fenómenos y particularidades gramaticales se observan y se aprenden (Grümpel, 2002; Martínez, 2004; Müller, 1998; Pienemann, 2005).
La primera posibilidad de análisis dice que las oraciones en la L2 se derivan algebraicamente como se derivarían las oraciones en la L1 (según los principios discutidos en 1.), pero que los parámetros en la L2 no se adquieren automáticamente sino que se mantienen "difusos" durante el aprendizaje (Martínez, 2004, 2008, 2010). Los parámetros difusos solo determinarán la derivación de algunas oraciones, por lo que los parámetros de la L1 actuarán en los demás casos. Así, la interferencia sintáctica, entendida desde esta perspectiva, no es producto de las estructuras de la L1, que actúan sobre la producción de las estructuras de la L2, sino que se limita al efecto de algunos parámetros que se activan o no para derivar las oraciones. Para el caso particular de las oraciones subordinadas, los parámetros significativos son la T y V finales, así como los rasgos fuertes de SpecC y de C.
El principal problema que suponen estos datos para la alternativa generativa es que las oraciones que generaron más errores tienen un funcionamiento interno exactamente igual a las oraciones que generaron pocos o ningún error. No se entiende, pues, por qué en (23) los parámetros difusos sí se activaron, mientras que en (24) no.
Tomemos las oraciones (23) y (24):
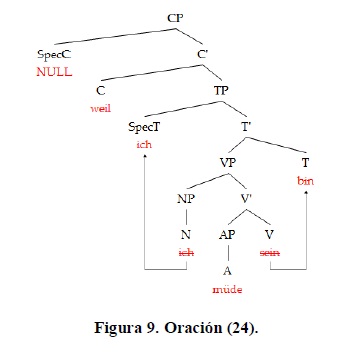
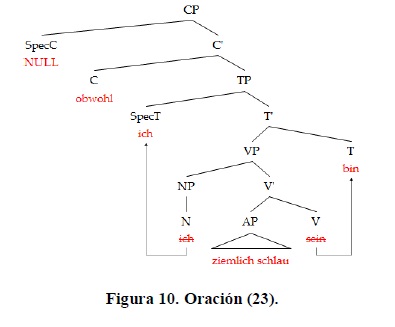
Se puede ver claramente que la derivación de ambas oraciones es virtualmente idéntica y que un proceso algebraico con parámetros difusos debería resultar en un porcentaje de error cercano para ambas oraciones.
Proponer que la diferencia en porcentajes de error radica en que obwohl es menos frecuente que weil falla en cuanto los rasgos T y V finales son independientes, y deberían manifestarse en igual proporción. De igual modo, (6), (9), (10) y (22) presentaron un porcentaje de error mucho menor que (23), y todas contienen obwohl. También puede verse que (21), formada por weil, tuvo un alto porcentaje de error entre los estudiantes de Bs6. De esta corta comparación, puede concluirse que el subordinante no es directamente responsable por los porcentajes de error y que es algo más lo que causa la diferencia en los porcentajes de error.
La otra posibilidad de análisis consiste en que la derivación inicial se da con los parámetros de la L2 y que, posteriormente, el hablante reorganiza los elementos en el orden de la L2 por medio de procesos cognitivos independientes (metalingüísticos); o que la organización se da, desde un principio, por medio de procesos cognitivos ajenos a merge, move y adjoin (Müller, 1998). El principal problema de esta propuesta es que, en realidad, no explica nada sino que deja más incógnitas. No es claro cuáles son los procesos cognitivos metalingüísticos, por qué juegan un papel en la construcción de oraciones en la L2, pero no en la L1, ni cómo interactúan con el sistema de la GU.
3.3. Acercamiento desde la TRR y la GC
Desde la TRR, el aprendizaje de una lengua extranjera está íntimamente unido al hecho de que la red es dinámica y tiene la capacidad de cambiar y modificar su propia estructura. La creación de nuevas nexiones se realiza por medio de nexiones ya establecidas, que pueden "reclutar" nexiones latentes sin una función asociada (Lamb, 1999, p. 204); el reclutamiento se da porque las nexiones ya establecidas envían activación a las latentes, fortaleciendo y estableciendo las conexiones requeridas por el sistema y aumentando sus umbrales de activación, hasta que estas se vuelven, a su vez, nexiones establecidas (Lamb, 1999, p. 204). Dentro de la TRR, incluso existe la posibilidad de que haya creación de nuevas nexiones si esto llegara a ser necesario5. Nuevas conexiones también pueden agregarse a las nexiones ya existentes para ampliarlas o complementarlas. Un caso en el que esto sucede es el del hablante que conoce una palabra con cierto significado, y que luego aprende que esta tiene, además, otros significados y se los asigna. De igual forma, es posible eliminar conexiones o nexiones completas en caso de que sean erróneas.
Para explicar la interferencia lingüística dentro del marco de la TRR y de la GC, propongo la siguiente hipótesis (H1): el aprendizaje de una lengua extranjera consiste en ir definiendo construcciones a partir de los ítems atómicos en el estímulo, y en asociarlas con significados. Según esto, los principiantes y hablantes con bajo dominio de una L2 tendrían solo algunas construcciones muy simples6 y un lexicón conformado por unidades sueltas, que se ordenan bien conscientemente o que se encuentran subordinadas a las construcciones de la L1. En la medida en que los aprendientes progresan, van adquiriendo y fijando más construcciones que pueden empezar a operar sobre los ítems lexicales ya conocidos. En la medida en que las construcciones de la L2 sean similares a las de la L1, el hablante asociará las redes ya disponibles con los elementos léxicos nuevos. Por el contrario, las construcciones de la L2 que difieran en cierta forma de las equivalentes en la L1 tendrán que construirse e integrarse al sistema. Con grandes cantidades de estímulo es posible que también las construcciones iguales en las dos lenguas lleguen a separarse en la red y que las conexiones entre las construcciones de la L1 y la L2 se debiliten hasta desaparecer eventualmente. De este modo, los hablantes en niveles muy avanzados de la L2 (C1 y C2, según el marco de referencia europeo) tendrían un mayor número de construcciones claramente diferenciadas que las que tendrían los hablantes con un nivel bajo.
En el caso del español y el alemán, las CTr y CInTr tienen un orden asociado común, que es el más frecuente en ambas. Esto hace que los aprendientes puedan, inicialmente, mantener la construcción del español también para el alemán y recibir retroalimentación positiva del estímulo. De este modo, los demás órdenes asociados posibles de las construcciones del alemán reciben muy poca activación, y el orden canónico del español no se debilita.
Las figuras 11 y 12 representan dos momentos en la organización de una construcción subordinada. En la figura 11 las conexiones del español (en rojo) aún no se han debilitado, y el orden SOV (en azul) apenas se está configurando. Por el contrario, en la figura 12 las líneas del orden SOV ya están establecidas y el orden SVO del español empieza a debilitarse.
Tanto la figura 11 como la figura 12 son simples aproximaciones. Si aceptamos a H1, en el sistema de los aprendientes, no habría una sola CSo, sino que el hablante iría conformando diferentes CSo para diferentes construcciones. La distinción exacta entre estas construcciones y los niveles y rangos de generalización de las CSo no es claro, y no es fácil determinar si un hablante usa la misma o diferentes construcciones para un par de oraciones. De este modo, es perfectamente posible que la figura 12 represente el estado de la red para la construcción [CTr, dass CSo] y que la figura 11 sea el estado de la red para [dass CSo, VrTr, CTr]. Así, la primera tendría niveles de interferencia menores a la segunda.
Por depender directamente del estímulo, H1 tiene como consecuencia que la frecuencia de aparición de las diferentes construcciones es un factor importante en la velocidad con la que los hablantes las solidifican y aíslan de las construcciones equivalentes en la L1. Construcciones más frecuentes recibirán mayor activación en el sistema, y a los aprendientes les será más fácil debilitar y, eventualmente, eliminar las conexiones "viejas" que generan la interferencia con las construcciones en la L1. Si esto es así, las construcciones de las oraciones en Err1 tendrían que tener una frecuencia de aparición mucho menor a las de Err2 en el estímulo de los aprendientes. De igual forma, las construcciones (léxicas y gramaticales) nuevas aprendidas, por tener conexiones muy débiles, se debilitarán y olvidarán rápidamente si el aprendiente no las encuentra de nuevo en el estímulo o si no hay retroalimentación interna (e. g. repasarlas mentalmente).
Reviso a continuación la frecuencia en el alemán escrito de las construcciones en Err1 y Err2. Lamentablemente, aún no hay ningún corpus del alemán según nivel de aprendizaje, por lo que utilicé el buscador de Googlebooks.
Los datos de la tabla 1 sugieren que las oraciones Err2 son, en efecto, construcciones menos frecuentes que las de Err1 en el alemán escrito. También hay que notar que ambos corpus representan la totalidad de la lengua escrita y que los cursos de alemán siempre usan textos con estructuras gramaticales relativamente fáciles, evitándose el uso de oraciones complejas.
Esta forma de aproximación a la interferencia, que separa el manejo de varios tipos de construcciones, permite explicar por qué algunas oraciones tuvieron mayor porcentaje de error que otras. Se puede predecir, de igual forma, que otras construcciones poco frecuentes presentarán porcentajes de error similares a los de Err2, y que otras construcciones de alta frecuencia presentarán porcentajes de error similares a los de Err1.
H1 también predice que los hablantes irán reduciendo el porcentaje de errores por interferencia en conversaciones en alemán prolongadas con hablantes con competencia de nativos (o cercana). A medida que la conversación avanza, las conexiones que producen oraciones correctas recibirán activación y se irán haciendo más fáciles de reactivar, por lo que se usarán con más frecuencia. H1 podría falsarse si se encontrara que esta predicción está equivocada y que los porcentajes de error se mantienen homogéneos a lo largo de conversaciones prolongadas. También podría mostrarse que H1 está equivocada si se encontrara empíricamente que una construcción de alta frecuencia en una lengua dada presenta mayor dificultad, para hablantes aprendientes de una lengua, que alguna otra construcción de baja frecuencia que no contenga construcciones equivalentes ni similares.
Otra forma de confirmar o falsar H1 sería diseñar un experimento en el que se compararan dos grupos de aprendientes de alemán más o menos homogéneos, en más o menos el mismo nivel de aprendizaje, pero con métodos diferentes: uno con un método "tradicional" y otro con método sin gramática. Si H1 es correcto, los estudiantes del método de repetición constante sin gramática deberían presentar niveles de interferencia significativamente menores que los estudiantes del método tradicional.
4. Conclusiones
Se han revisado los aportes desde el minimalismo y desde la TRR al problema de la adquisición de segundas lenguas y la interferencia sintáctica, tomando el caso particular de la posición del verbo en las oraciones subordinadas en alemán.
El PM, si bien es capaz de proporcionar diferentes formas de análisis posibles de las estructuras sintácticas consideradas, gramaticales y agramaticales, y el proceso por medio del cual se produciría la interferencia sintáctica, este no es capaz de proponer un mecanismo que explique por qué la interferencia es intermitente en estadios avanzados del aprendizaje de la L2, ni tampoco logra explicar satisfactoriamente las diferencias en los porcentajes de error de algunas oraciones con respecto a otras.
Como alternativa se revisó la TRR y su posible aplicación para explicar los mismos casos de interferencia sintáctica. Desde esta teoría no se revisó ninguna posible explicación de por qué la interferencia es intermitente, pero sí se encontró que es posible dar cuenta de las diferencias en porcentajes de error entre las distintas oraciones. Según la TRR, las personas procesan la sintaxis de las lenguas por medio de construcciones, y el aprendizaje de estas está directamente determinado por su frecuencia de aparición en el estímulo.
Aun cuando la TRR y la GC estén lejos de haber alcanzado un desarrollo completo y tengan muchas falencias en diferentes campos, estas sí ofrecen alternativas plausibles para explicar algunos aspectos de la interferencia sintáctica que el PM no es capaz de abordar satisfactoriamente. Las propuestas funcionales revisadas, además, cuentan con la ventaja de que hacer predicciones falsables, lo que permite corroborar si son ciertas o erróneas. Por último, si se confirmaran empíricamente las conclusiones de que los hablantes organizan su sistema lingüístico en construcciones, y de que el aprendizaje de una gramática es aprendizaje de las construcciones de aquella, resultaría pertinente revisar algunos métodos de enseñanza de lengua extranjera para hacerlos más efectivos.
Abreviaturas
AgrS = agreement subject
AgrO = agreement object
CInTr = construcción intransitive
CP = complementizer phrase
CSo = construcción subordinada
CSt = construcción subordinante
CTr = construcción transitiva
DP = determinant phrase
GC = gramática de construcciones
GG = gramática generativa
GU = gramática universal
L1 = lengua materna
L2 = segunda lengua
NegP = negation phrase
NP = noun phrase
-NULL = un elemento ausente
PM = programa minimalista
Rasgo F = rasgo funcional
Rasgo LC = rasgo lexicocategorial
Spec = specifier
SOV = orden subject-object-verb
SVO = orden subject-verb-object
TP = time phrase
TRR = teoría de redes relacionales
VP = verb phrase
VrTr = verbo transitivo
YP = y phrase (generalización)
* Investigación realizada entre el 2010 y el 2011 con el apoyo de Néstor Alejandro Pardo, de la Universidad Nacional de Colombia.
1 Ver abreviaturas al final del documento.
2 La notación que sigo para la GC es mía, pero bien podría usarse otra sin que tenga realmente implicaciones teóricas.
3 'Buscar' adopta el carácter ditransitivo por encontrarse en una construcción ditransitiva.
4 El alemán permite mayor grado de libertad en los no términos (X) que el expuesto en este trabajo. No tendré en cuenta otras posibilidades en la secuencia, empero, porque son irrelevantes para la discusión.
5 La descripción completa de los procesos neurológicos implicados en este aspecto no está dentro del rango de este trabajo.
6 Un ejemplo de estas construcciones serían 'mir ist kalt' o 'ich bin 20 Jahre alt'. Ambas son construcciones que inicialmente se memorizan y que no tienen un equivalente directo en español.
Referencias
Ahukanna, J. G. W., Lund, N. J., & Gentile, J. R. (1981). Inter-and intra-Lingual Interference Effects in Learning a Third Language. The Modern Language Journal, 65(3), 281-287.
Azevedo, M. M. (1978). Identifying Spanish Interference in the Speech of Learners of Portuguese. The Modern Language Journal, 62(1, 2), 18-23.
Bavin, E. L. (Ed.). (2009). The Cambridge Handbook of Child Language. New York: Cambridge University Press.
Boeckx, C. (2008). Bare syntax. Oxford, New York: Oxford University Press.
Chomsky, N. (1994). El conocimiento del lenguaje. Barcelona: Altaya.
Chomsky, N. (1995). The Minimalist Program. Cambridge, Mass.: The MIT Press.
Christiansen, M. H., & Charter, N. (2009). The Myth of Language Universals and the Myth of Universal Grammar. Behavioral and Brain Sciences, 32(5), 452-453.
Croft, W. (2001). Radical Construction Grammar: Syntactic Theory in Typological Perspective. Oxford; New York: Oxford University Press.
Croft, W. (2009). Syntax is More Diverse, and Evolutionary Linguistics is already Here. Behavioral and Brain Sciences, 32(5), 453-554.
Lockwood, D. G., Fries, P. H., & Copeland, J. E. (2000). Functional Approaches to Language, Culture, and Cognition: Papers in Honor of Sydney M. Lamb. Amsterdam: John Benjamins Publishing Company.
Dürscheid, C. (s.f.). Syntax: Grundlagen und Theorien. Göttingen: Vandenhoeck & Ruprecht.
Evans, N., & Levinson, S. C. (2009). The Myth of Language Universals: Language Diversity and its Importance for Cognitive Science. Behavioral and Brain Sciences, 32(5), 429-492.
Frey, W., & Gärtner, H. M. (2002). On the Treatment of Scrambling and Adjunction in Minimalist Grammars. En G. Jäger, P. Monachesi, G. Penn & S. Wintner (Eds.), Proceedings of Formal Grammar 2002 (pp. 41-52).
Friederici, A. D. (2002). From the Cover: Brain Signatures of Artificial Language Processing: Evidence Challenging the Critical Period Hypothesis. Proceedings of the National Academy of Sciences, 99(1), 529-534.
Gabryś, D. (Ed.) (2008). Morphosyntactic Issues in Second Language Acquisition. Clevedon, UK; Buffalo, NY: Multilingual Matters.
Gil, J. M. (2009). Neurología y lingüística: la "teoría de redes relacionales" como una alternativa ante Chomsky. Revista de Investigación Lingüística, 12, 343-374.
Goldberg, A. E. (1995). Constructions: a Construction Grammar Approach to Argument Structure. Chicago: University of Chicago Press.
Grewendorf, G. (2002). Minimalistische Syntax. Tübingen: UTB/Francke.
Grodzinsky, Y., & Friederici, A. D. (2006). Neuroimaging of Syntax and Syntactic Processing. Current Opinion in Neurobiology, 16, 240-246.
Grümpel, C. (2002, Noviembre 11). The Acquisition of German Syntax by Spanish-Speaking Advanced Learners Based on an Underlying Subject Verb Object Order. Recuperado de http://www.ucm.es/info/circulo/no11/gruempel.htm.
Hornstein, N. (2009). A Theory of Syntax. Cambridge: Cambridge University Press.
Hornstein, N., Nuñes, J., & Grohmann, K. K. (2005). Understanding Minimalism. Cambridge: Cambridge University Press.
Hudson, R. (1984). Word Grammar. Oxford; New York: B. Blackwell.
Hudson, R. (2007). Language Networks: the New Word Grammar. Oxford; New York: Oxford University Press.
Hudson, R. (2010). Reaction to: "The Myth of Language Universals and Cognitive Science" - On the Choice between Phrase Structure and Dependency Structure. Lingua, 120(12), 2651-2758.
Lakoff, G. (2008, Junio 13). Authors@Google: George Lakoff [Video]. Recuperado de http://www.youtube.com/watch?v=saDHFomGW3A.
Lamb, S. M. (1999). Pathways of the Brain: the Neurocognitive Basis of Language. Amsterdam; Philadelphia: J. Benjamins.
Lamb, S. M. (2000). Learning Syntax: A Neurocognitive Approach. Recuperado de http://www.ruf.rice.edu/~lngbrain/syntax.doc.
Lamb, S. M., & Webster, J. (2004). Language and Reality. Continuum International Publishing Group.
Martínez, M. (2004). La hipótesis de la transferencia de la L2 y la adquisición del orden de las palabras. RESLA, 17(18), 1987-208.
Martínez, M. (2008). La adquisición del parámetro de ascenso verbal en el alemán comon tercera lengua. Magazin, 18, 28-36.
Martínez, M. (2010). On L2 English Transfer Effects in L3 Syntax. Vigo International Journal of Applied Linguistics, 7, 75-98.
Müller, N. (1998). Die Abfolge OV/VO und Nebensätze im Zweit- und Erstspracherwerb. En S. W. Felix, J. M. Meisel & H. Wode (Eds.), Eine zweite Sprache lernen (pp. 89-116). Tubingen: Gunter Narr Verlag.
Noreen, A. (2009). Altschwedisches lesebuch. [S.l.]: Richardson.
Pienemann, M. (2005). Cross-Linguistic Aspects of Processability Theory. John Benjamins Publishing Company.
Pinker, S. (2007). The Language Instinct: How the Mind Creates Language. Harper Perennial Modern Classics.
Pinker, S. (2008). The Stuff of Thought: Language as a Window Into Human Nature. Penguin Books.
Poeppel, D., & Embick, D. (2005). Defining the Relation between Linguistics and Neuroscience. Recuperado de http://www.ling.upenn.edu/~embick/lingneuro.pdf.
Pulju, T. (2000). Neurological Evidence for the Existence of an Autonomous Lexicon. En D. G. Lockwood, P. H. Fries & J. E. Copeland (Eds.), Functional Approaches to Language, Culture, and Cognition: Papers in Honor of Sydney M. Lamb (pp. 49-58). Amsterdam: John Benjamins Publishing Company.
Radford, A. (2009). Analysing English Sentences. Cambridge: Cambridge University Press.
Sapp, C. D. (2006). Verb Order in Subordinate Clauses from Early New High German to Modern German (Tesis doctoral). Indiana University. Recuperado de http://home.olemiss.edu/~csapp/Sapp-Dissertation.pdf.
Stepanov, A., Fanselow, G., & Vogel, R. (Eds.). (2004). Minimality Effects in Syntax. Berlin: Walter de Gruyter GmbH & Co. KG.
Sugayama, K., Hudson, R., & Shinkokai, N. G. (2006). Word Grammar: New Perspectives on a Theory of Language Structure. London; New York: Continuum.
Tomasello, M. (2003). Constructing a Language: A Usage-Based Theory of Language Acquisition. Cambridge, Mass.: Harvard University Press.
Van Valin, R. D. (2005). Exploring the Syntax-Semantics Interface. Cambridge; New York: Cambridge University Press.
