










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkForma y Función
Print version ISSN 0120-338X
Forma funcion, Santaf, de Bogot, D.C. vol.29 no.2 Bogotá July/Dec. 2016
https://doi.org/10.1353/sls.2010.0008
Doi: http://dx.doi.org/10.1353/sls.2010.0008
HACIA UNA REPRESENTACIÓN FONÉTICA DE LAS SEÑAS: SECUENCIALIDAD Y CONTRASTE*
Robert E. Johnson
Scott K. Liddell
Cómo citar este artículo:
Johnson, R. E, & Liddell, S. K. (2016). Hacia una representación fonética de las señas: secuencialidad y contraste (M. A. Montañez & C. A. Robayo, Trads.). Forma y Función, 29(2), 247-279.
* Se agradece a los autores y a Ceil Lucas la autorización para traducir el original: Johnson, R. E., & Liddell, S. K. (2010). Toward a Phonetic Representation of Signs: Sequentiality and Contrast. Sign Language Studies, 11(2), 241-274. doi: 10.1353/sls.2010.0008. Fue traducido por Miguel Ángel Montáñez (mamontanezp@unal.edu.co) y Camilo Alberto Robayo (carobayor@unal.edu.co), Universidad Nacional de Colombia.
Este es el primero de varios artículos donde se describe el enfoque completo de los autores sobre la representación fonética de las lenguas de señas. Un artículo ha aparecido en números sucesivos de Sign Language Studies hasta completar la serie. Los próximos artículos se ocupan de los temas de segmentación, configuración manual, localización, orientación, representación del espacio analógico y de alteraciones fonológicas.
La idea de que las lenguas de señas existen como lenguas humanas reales y con un diseño estructural, tal como el que se encuentra en las lenguas producidas oralmente, es relativamente reciente. La propuesta de Stokoe (1960) de que la Lengua de Señas Estadounidense o American Sign Language (ASL) es una lengua real, fue considerada absurda por muchos lingüistas, por cuanto las lenguas de señas nunca habían sido tratadas como lenguas naturales plenamente constituidas. La gente estaba acostumbrada a pensar en ellas como un simple sistema de comunicación o como una representación de las lenguas orales. Además, el campo de la lingüística estaba obstinado con la idea de que todas las lenguas debían ser producidas oralmente. Desde esa perspectiva, como las lenguas de señas son producidas con las manos y el cuerpo, y percibidas visualmente, debían ser una cosa distinta a las lenguas.
No obstante, en el transcurso de las siguientes dos décadas, numerosos lingüistas llegaron a aceptar las ideas de Stokoe, y se involucraron en la descripción de la estructura de la Lengua de Señas Estadounidense, y otras lenguas de señas. La idea de que las lenguas de señas tienen gramáticas similares a aquellas de las lenguas producidas oralmente ganó gradualmente aceptación general a finales de 1970 y comienzos de 1980. Hoy en día, sería difícil encontrar a un profesional en lingüística que sostenga que las lenguas de señas no son lenguas reales.
La diferencia más obvia e inmediata entre las lenguas de señas y las lenguas habladas evidentemente se encuentra en la forma de su producción y percepción. Esta diferencia, a menudo descrita como una diferencia de modalidad (modality difference), se manifiesta en los movimientos físicos necesarios para crear y percibir la lengua de señas. Los hablantes de una lengua producida oralmente coordinan diferentes sistemas articulatorios dentro del tracto vocal para producir grupos de sonidos identificados como palabras. Los señantes coordinan movimientos de las manos, brazos, torso, cara y cabeza para producir grupos de gestos reconocibles como señas. De la misma manera, para comprender las señas se requieren conjuntos diferentes de receptores. Por un lado, las variaciones de las ondas sonoras deben ser identificadas por el sistema auditivo, mientras por el otro las variaciones en las ondas lumínicas deben ser identificadas por el sistema visual.
Por cuanto la señal en la lengua de señas es tan diferente de aquella producida en una lengua oral, simplemente no se puede imponer a las señas las estructuras fonéticas que se sabe que existen en las lenguas producidas oralmente. Más bien, los analistas deben intentar entender la estructura fonética de las señas en sus propios términos. Ha habido un sinnúmero de tales intentos. En este artículo, el primero de una serie, se propone una teoría fonética de la lengua de señas, se discute la propuesta original de Stokoe con respecto a la estructura física subyacente de las señas, así como algunos de los intentos posteriores que conciben que las señas están compuestas de segmentos secuenciales. Se llega a la conclusión de que, si bien las pruebas para la segmentación de las señas son convincentes, cada uno de los sistemas de segmentación propuestos tiene problemas significativos; y en posteriores artículos se discutirá una nueva forma de concebir las señas como segmentos organizados de manera secuencial.
La nueva propuesta difiere en el número y en los tipos de segmentos que componen las señas. También difiere en que nos concentramos en la representación fonética de los segmentos, en lugar de tratar de concebir la estructura de la seña a un nivel fonológico. Finalmente, estos artículos en su conjunto proponen un sistema de transcripción útil para representar las señas fonéticamente (un sistema que puede aplicarse a una amplia variedad de lenguas de señas y perfeccionarse o rechazarse con base en la descripción de eventos lingüísticos que ocurren de forma natural).
El sistema de Stokoe
Los queremas y las afirmaciones de simultaneidad
Stokoe (1960) fue el primero en proponer que las señas tienen una estructura interna equivalente al nivel fonológico de las lenguas producidas oralmente. Con el fin de marcar la diferencia de modalidad, él acuñó el término querema (chereme) como el equivalente del fonema en la lengua de señas, con lo cual modeló su sistema a partir del sistema fonético y fonémico de la Escuela Estructural Estadounidense (Sapir 1925, 1933; Bloomfield, 1933; Swadesh, 1934; Pike, 1947; Trager & Bloch, 1941)1. En el sistema de Stokoe, cada seña está dividida en tres partes o aspectos: el lugar de articulación (tabula o tab, comúnmente llamado localización), la mano activa (designador o dez, comúnmente denominada forma de la mano), y la acción de producir la seña (signación o sig, comúnmente llamada movimiento). Los queremas de la lengua de señas, como los fonemas en las lenguas producidas oralmente, se dice que tienen la propiedad de distinguir una palabra (señada) de otra.
En el sistema querémico de Stokoe, en la formación de señas, los queremas se combinan simultáneamente antes que secuencialmente. En su modelo, cada seña simple está compuesta de una localización (tab), una orientación de la forma de la mano (dez), y uno o más movimientos (sig). Esa estructura esquemática fue aplicada a todas las señas del Diccionario de la lengua de señas estadounidense (Stokoe, Casterline & Croneberg, 1965). Aunque el diccionario afirma que los tres aspectos de una seña se combinan simultáneamente para formar una seña, los movimientos pueden ser especificados secuencialmente. Por ejemplo, consideremos la seña CHICAGO ('Chicago'), ilustrada en la Figura 1. En la producción de esta seña, la mano primero realiza un movimiento hacia la derecha, luego un movimiento hacia abajo.

En el sistema querémico de Stokoe, CHICAGO se representa como «ØC>˅» (1965, p. 50), donde la ubicación en el espacio delante del cuerpo es representada por el símbolo «Ø», la forma de la mano es una «C» y los dos movimientos secuenciales son «>» (hacia la derecha) y posteriormente «˅» (hacia abajo)2,3,.
El hecho de que Stokoe apuntara hacia un nivel émico de representación es evidente en su uso de símbolos que representan el torso «[]» (tab). Aunque las señas GUILTY ('culpable'), PLEASE ('por favor'), ASSERTIVE ('asertivo'), DISGUSTING ('repugnante') y RUSSIA ('Rusia') son representadas como producidas en la localización del torso «[]», cada una debe ponerse en contacto con el torso en un lugar diferente. En GUILTY el contacto se realiza en la parte superior izquierda del torso, en please se hace contacto en la parte superior–central del torso, y para ASSERTIVE se realiza en la parte superior derecha y la parte superior izquierda. DISGUSTING se ejecuta en la parte central del torso; mientras en ASL, las dos manos, en la seña RUSSIA4, se realizan ambas en el torso a nivel de la cintura.
Es importante tener en cuenta que el intento de producir GUILTY a nivel de la cintura o RUSSIA a nivel del torso daría lugar a formas inexistentes que no transmiten el significado deseado. De este modo, aunque hay diferencias en la localización de estas señas, para Stokoe todas ellas hacen parte de una misma categoría émica, es decir, todas comparten el mismo querema «[]».
No está claro de qué manera Stokoe llegó a la conclusión de que cada una de estas señas compartía un querema para tab, pero parece que se basó en la noción de pares mínimos, con el fin de considerar que los diversos lugares del torso constituyen un mismo querema de localización. Es decir, si fuera posible encontrar alguna otra seña con una configuración manual y movimiento equivalente a la de GUILTY, pero producida en una localización diferente en el torso, esta seña hipotética y GUILTY constituirían, en el análisis de Stokoe, un par mínimo y podrían ser utilizadas para demostrar que hay queremas que contrastan en el torso para la localización. Dada la falta de pruebas de pares mínimos para distinguir una ubicación en el torso frente a otra, Stokoe propuso un querema de localización único «[]». Así, en el análisis de Stokoe, todas las localizaciones en el torso son aloqueres (término equivalente a los alófonos en las lenguas orales) y no son contrastivos.
El nivel abstracto (émico) de representación tiene consecuencias para los usuarios del sistema. Es muy significativo, por ejemplo, que este no contenga suficientes detalles como para ir de la transcripción a la producción. Si bien un lector que vea la transcripción «[]Cx>x» sabría que una configuración manual en C entra en contacto con el torso («x»), se mueve hacia la derecha («>») y vuelve a tocar el torso de nuevo («x»); esta notación no especifica qué parte del torso se tocó. Dado que el sistema no identifica las condiciones bajo las cuales podrían usarse lugares específicos del torso, una persona que no esté familiarizada con la seña congress ('congreso') sería incapaz de reproducirla únicamente sobre la base de la transcripción.
El segundo aspecto de las señas que identificó Stokoe y colaboradores fue lo que actúa, es decir, el designador, o dez, comúnmente expresado como forma de la mano, para el cual Stokoe propuso diecinueve símbolos. Así como los símbolos de localización no identifican fonéticamente lugares precisos de articulación para la mano, el símbolo dez no identifica fonéticamente configuraciones manuales precisas. Por ejemplo, las configuraciones manuales contrastivas A, S y T son todas representadas como instancias (aloqueres) del querema A. De la misma manera, las configuraciones manuales contrastivas G, 1 y D son todas representadas como instancias del querema G.
Por cuanto Stokoe no especificó la distribución complementaria de estos aloqueres, no hay manera sustentada para saber cuál variante usar con cuál seña. Por tanto, una vez más, una persona que LEA la transcripción para una seña desconocida con un querema A, será incapaz de reproducir la configuración manual de la seña solo a partir de esta transcripción5.
Hay otro aspecto significativo de la representación de los símbolos dez que necesita ser mencionado aquí. Los diecinueve símbolos que constituyen el sistema dez son presentados sin ninguna referencia a cómo están orientadas las manos. En la práctica real, Stokoe frecuentemente añade subíndices u otro tipo de diacríticos que describen ciertos detalles perceptibles de orientación manual. Esto es evidente en la comparación de las transcripciones de Stokoe para BLACK ('negro') y THINK ('pensar'), ilustradas en el ejemplo 1 (Stokoe, Casterline, & Croneberg, 1965, pp. 126, 128). BLACK (1a) se inicia con la punta del dedo orientada a la izquierda («G<»), mientras que para THINK (1b), está orientada hacia el señante («Gt»)6.
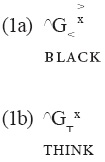
De este modo, aunque el Diccionario de lengua de señas estadounidense incluye solo diecinueve símbolos dez, si llega a tener en cuenta la orientación, entonces el número de posibles símbolos dez se eleva a varios cientos. Esto incide para argumentar en pro de la separación de la orientación y de la configuración manual, con el fin de reducir el inventario de los primitivos a partir de los cuales las señas pueden ser compuestas. Siguiendo a Battison (1974), Frishberg (1975), Woodward (1973) y otros, ahora es común citar cuatro aspectos manuales independientes en la formación de las señas: configuración manual, localización, movimiento y orientación7.
El tercer y último aspecto de la estructura de la seña propuesta por Stokoe es la señación (sig), entendida como la acción de producir una seña, lo que es comúnmente denominado como movimiento. Mientras que los rasgos de localización y configuración manual se limitan a uno por seña, Stokoe permite múltiples movimientos, que pueden ser simultáneos, secuenciales, o ambos.
Por ejemplo, la seña BOARD–OF–TRUSTEES ('junta directiva') es producida con la misma secuencia de movimientos direccionales que CONGRESS (contacto, movimiento a la derecha, contacto). Inicialmente, la mano se pone en contacto con el lado más alejado de la parte superior del torso, con una configuración manual en B; y la cara próxima al torso, con una configuración manual en T. El movimiento hacia la derecha y el movimiento de cierre para la configuración manual de T necesitarían ser representados como dos movimientos simultáneos, entre los movimientos de contacto inicial y final.
Stokoe también representa algunas de las señas sin cambios de configuración manual, con movimientos simultáneos entre otros movimientos secuenciales, como en king ('rey'), que se muestra en el ejemplo 2. La seña es producida por un primer contacto («x») en el lado superior izquierdo del torso, con el lado radial de la configuración manual de K. Luego la mano se mueve hacia abajo («˅») y simultáneamente a la derecha («>»), seguido de otro contacto («x») en el lado inferior derecho del torso.

El sistema de Stokoe para representar la acción de una seña consta de veinticuatro símbolos sig. Diez de los símbolos representan movimientos de la mano a lo largo de un recorrido («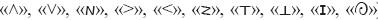 »). Por ejemplo, ;THANK–YOU ('gracias') (
»). Por ejemplo, ;THANK–YOU ('gracias') ( ) tiene el símbolo sig «┴», que es descrito como «un movimiento de alejamiento del señante». El tab inicial es especificado como la boca o la barbilla del señante «υ», y esta se toma como la única posición de la seña, aunque la mano, de hecho, se mueve hacia una segunda localización durante la producción de la seña. No hay información sobre qué tan lejos se debe mover la mano o qué se debe hacer con ella cuando esta llegue a su destino.
) tiene el símbolo sig «┴», que es descrito como «un movimiento de alejamiento del señante». El tab inicial es especificado como la boca o la barbilla del señante «υ», y esta se toma como la única posición de la seña, aunque la mano, de hecho, se mueve hacia una segunda localización durante la producción de la seña. No hay información sobre qué tan lejos se debe mover la mano o qué se debe hacer con ella cuando esta llegue a su destino.
Cuatro símbolos sig (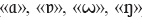 ) involucran movimiento de la muñeca en lugar de movimientos a lo largo de una trayectoria. Los dos primeros rotan la muñeca en una dirección u otra, el tercero representa una rotación oscilante continua de la muñeca, y el cuarto causa una flexión de la muñeca.
) involucran movimiento de la muñeca en lugar de movimientos a lo largo de una trayectoria. Los dos primeros rotan la muñeca en una dirección u otra, el tercero representa una rotación oscilante continua de la muñeca, y el cuarto causa una flexión de la muñeca.
Los tres símbolos sig, «℻» (acción de apertura), «#» (acción de cierre), y «ℓ» (acción de serpenteo) producen cambios en la configuración manual. En el sistema de Stokoe, cada una de las tres señas del ejemplo 3 es considerada como una seña producida con forma única de la mano A. Cada una de ellas es representada con un movimiento de «apertura», que produce la configuración manual final que se especifica en los corchetes que siguen al símbolo «℻», puesto que cada una de las señas termina con una configuración manual diferente. De este modo, Stokoe usa transcripciones de movimiento para dar cuenta de los detalles secuenciales de la configuración manual.

La necesidad de especificar la segunda configuración manual en estas señas representa un desperfecto en el sistema querémico. Si los movimientos de apertura y cierre realmente pudieran dar cuenta de los cambios en la configuración manual, entonces no sería necesario añadir símbolos de configuración manual adicionales a la representación querémica. El hecho de que se necesiten tales símbolos pone en cuestión el concepto de restringir las señas a un único símbolo dez y el de representar los cambios de la configuración manual con símbolos de movimiento.
El símbolo «ℓ» indica una acción de serpenteo de los dedos, que puede o no co–ocurrir con el movimiento de trayectoria. Por último, los siete símbolos sig —«)», «X», « », «
», « », «
», « », «÷», «
», «÷», « »— representan la interacción entre la mano y una localización, o entre las dos manos. Estos indican aproximación, contacto, conexión, cruce, entrada, separación e intercambio de dominancia, respectivamente.
»— representan la interacción entre la mano y una localización, o entre las dos manos. Estos indican aproximación, contacto, conexión, cruce, entrada, separación e intercambio de dominancia, respectivamente.
El resultado de concebir la estructura de las señas de esta manera es que Stokoe y lingüistas posteriores aplicaron conceptualmente el conjunto simultáneo de tres aspectos para representar secuencias de eventos articulatorios. Desde esa perspectiva, el sistema usa símbolos de movimiento para representar secuencias de movimientos, de localizaciones, de formas de la mano y de orientaciones (aunque la orientación no fuera vista como un aspecto fundamental de la estructura de las señas). Eso hace que sea posible afirmar que las señas con más de una forma fonética de la mano, orientación o localización, solo tienen una única forma de la mano, orientación o localización; porque tales secuencias son caracterizadas mediante símbolos especiales para el movimiento.
De esa manera, Stokoe (y por extensión, todos aquellos que adoptaron los supuestos centrales de ese sistema) perpetúa la noción de que todas las señas tienen una única forma de la mano, localización, y orientación. El resultado de esa práctica es que las secuencias de forma de la mano, localización y orientación quedan encubiertas, puesto que son constantemente interpretadas como movimientos. Más adelante se va a demostrar que esa práctica es en gran parte responsable de la noción errónea de que las señas no están organizadas como secuencias de segmentos fonéticos o de segmentos fonológicos.
Problemas con el sistema querémico
Problemas con el concepto de par mínimo
El concepto de pares mínimos es utilizado frecuentemente para asignar fonos a categorías fonémicas distintas. Los pares mínimos son pares de palabras que comparten fonos idénticos en todas las posiciones secuenciales, excepto en una. El conjunto de palabras que incluye [tes] tez, [pes] pez, [kes] ques, [les] les, [mes] mes y [res] res, pueden ser emparejadas entre sí, una con otra, para demostrar la noción de par mínimo, como se ve en la Figura 2. El hecho de que [pes] pez y [res] res sean palabras distintas con significados diferentes demuestra el potencial contrastivo de los segmentos fonéticos [p] y [t], que están situados en diferentes categorías fonémicas, en virtud del hecho de que ocurren en secuencias dentro de palabras con diferente significado, que de otra manera serían idénticas.

Esto lo mencionamos para demostrar el papel potencialmente contrastivo de los segmentos en una secuencia, y porqué es considerado como la prueba definitiva de la dualidad de ordenamiento en una lengua, dado que ilumina tanto el potencial de oposición de los rasgos (para distinguir el fono [p] del fono [t]), como el papel contrastivo de los segmentos [p] y [t] para distinguir dos palabras. Como tal, se ha convertido en una parte crucial del proceso de aislar las unidades elementales fonéticas y fonológicas de lenguas sin estudios previos. Empleando esta lógica, los contrastes que se muestran en la Figura 2 demuestran que los fonos [p], [t], [k], [l], [r] y [m] deben ser situados en categorías fonémicas distintas8.
Stokoe afirma que las señas tienen una estructura paralela a la de las lenguas orales, principalmente en cuanto ambas tienen un pequeño número de elementos carentes de significado que, al combinarse, crean los elementos con significado de la lengua. Desde que Stokoe realizó esta afirmación, numerosos lingüistas de las lenguas de señas la han reiterado, refinándola para incluir la noción de pares mínimos (Battison, 1978; Klima & Bellugi, 1979; Baker & Cokely, 1980). La siguiente afirmación realizada hace poco por Meir y colaboradores es bastante afín a la tradición que decía que pares como APPLE ('manzana') y ONION ('cebolla') de ASL eran pares mínimos, diferenciados únicamente por el lugar de realización:
Desde una perspectiva fonológica, las señas están compuestas por tres categorías formativas mayores: configuración manual, localización y movimiento [...] La lengua de señas Israelí (o en sus siglas en inglés, ISL) [...] Ejemplifica el hecho de que cada una de estas categorías está compuesta de una lista de caracteres contrastivos, tal como sucede con las consonantes y las vocales de las lenguas orales, y cada una cuenta con rasgos fonológicos contrastivos. En ISL, las señas MOTHER ('madre') y noon ('medio día') [...] se distinguen por las características de [...] dos formas de la mano [...] Este es un par mínimo, puesto que la localización y los movimientos son los mismos en ambas señas, y solo las distingue la forma de la mano. Las señas HEALTH ('salud') y CURIOSITY ('curiosidad') de ISL [...] se distinguen mínimamente por las características de localización (torso vs. nariz, respectivamente), mientras que escape ('escape') y BETRAY ('traición') solamente se distinguen por el movimiento, recto para escape y arqueado para BETRAY. (Meir et al., 2007, pp. 537-39)
La noción de que los rasgos contrastivos que constituyen estas señas están formados en el mismo modo que las vocales y las consonantes de las lenguas habladas, es de alguna manera correcta. Sin embargo, la idea de que dos señas que difieren por un solo querema constituyen un par mínimo, no lo es. Paralelamente a los ejemplos de MOTHER y NOON de ISL, citados anteriormente, las señas de APPLE y ONION de la ASL son citados con frecuencia como ejemplo de par mínimo. Ambas señas se realizan con una forma de la mano en X y un movimiento zigzagueante, pero APPLE es producida en la mejilla, mientras que ONION se produce al lado del ojo.
En ese enfoque, el potencial de oposición de los rasgos simultáneos se equipara al potencial contrastivo de las secuencias de fonos. La Figura 3 demuestra que los dos tipos de pares mínimos no son equivalentes. En las lenguas producidas oralmente (Figura 3a) los elementos contrastivos son segmentos; mientras que en las representaciones de Stokoe, los elementos contrastivos son rasgos descriptivos de un único paquete simultáneo, que es estructuralmente equivalente a un solo segmento en las lenguas habladas.

La Figura 3 ilustra las diferencias geométricas esquemáticas entre pares mínimos en el habla y un par mínimo putativo de señas. Los pares mínimos en el habla se descubren cuando las secuencias de fonos difieren por un solo elemento secuencial, como en la Figura 3a. Por lo tanto, [pes] pez y [tes] tez constituyen pares mínimos en español. En la Figura 3b, donde el concepto se aplica a APPLE y ONION, el concepto de secuencialidad se omite, debido al supuesto de simultaneidad del sistema de representación de Stokoe. El análisis simplemente aplica el concepto de sustituibilidad de manera simultánea sobre los tres queremas. Dado que las dos señas difieren solo en la localización (mejilla y lado del ojo), son utilizadas para afirmar que constituyen un par mínimo. El problema aquí es que la sustituibilidad (la oposición paradigmática de Saussure) no es suficiente para demostrar el contraste (el contraste sintagmático de Saussure).
Es más problemático si se intenta aplicar el concepto de par mínimo a una seña como BRAVE ('valiente'), que en el ejemplo 4 se representa con la transcripción de Stokoe. Debido a que el concepto de secuencia de segmentos es parte integral de la definición de pares mínimos en el habla, y como este concepto no se tiene en cuenta en su aplicación a las señas, un analista tendría dificultades en la aplicación del concepto para BRAVE.
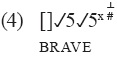
En BRAVE, los símbolos de tab, dez y sig («[]» —torso—, «j5j5» —dos configuraciones manuales en 5 con la participación del antebrazo [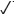 ]—, y «x» —contacto—) efectivamente representan la articulación simultánea, porque la seña comienza con dos configuraciones manuales en 5, en contacto por la punta de los dedos con el torso. Sin embargo, luego de este comienzo simultáneo, ocurre un segundo evento simultáneo que implica las formas originales de la mano y el torso, y dos movimientos diferentes y ulteriores: «˄» (movimiento de alejamiento de) y «#» (acción de cierre).
]—, y «x» —contacto—) efectivamente representan la articulación simultánea, porque la seña comienza con dos configuraciones manuales en 5, en contacto por la punta de los dedos con el torso. Sin embargo, luego de este comienzo simultáneo, ocurre un segundo evento simultáneo que implica las formas originales de la mano y el torso, y dos movimientos diferentes y ulteriores: «˄» (movimiento de alejamiento de) y «#» (acción de cierre).
Dados los supuestos del sistema, es ineludible que la propia representación de Stokoe de BRAVE implique una secuencia de dos eventos articulatorios simultáneos. En cuanto a cómo el concepto de pares mínimos podría aplicarse a BRAVE y a una seña hipotética que solo difiera de BRAVE en cuanto a la configuración manual, la respuesta directa es que el concepto es imposible de aplicar. Por ejemplo, la sustitución de algún otro tipo de configuración para la configuración de la mano en 5 de BRAVE, significaría que la nueva configuración de la mano se produjo en dos haces simultáneos: primero con «[]» y «x», y enseguida con «[]», «┴» y «#».
Recordemos que los pares mínimos en el habla pueden ser identificados solo cuando hay un par de palabras en las que solo difiere un segmento dentro de una secuencia de segmentos. Utilizando el ejemplo de sustitución de forma de la mano en BRAVE, la forma de la mano se produce como parte de una secuencia. Por lo tanto, usar la posibilidad de sustitución dentro del sistema de Stokoe implicaría sustituir no solo dentro de un único conjunto simultáneo de queremas, sino también dentro de una secuencia de queremas simultáneos. Esto choca con la forma en que se definen los pares mínimos.
Afirmar que, en ASL, ONION y APPLE conforman un par mínimo, requiere cambiar la definición para eliminar el concepto de contraste secuencial. Sin embargo, una vez que el concepto de pares mínimos es definido de forma distinta para el habla y para las señas, este ya no es el mismo concepto. De este modo, afirmar que APPLE y ONION constituyen un par mínimo es equivalente a afirmar que son equivalentes al par [pes] pez y [tes] tez. Pero esto solo resulta así, porque la definición fundamental de par mínimo ha sido alterada con el fin de que se ajuste a la concepción de estructura de APPLE y ONION, según Stokoe. Entonces, desde esta perspectiva, APPLE y ONION no constituyen un par mínimo en el mismo sentido que el término ha sido tradicionalmente usado en la descripción de las lenguas producidas oralmente.
Sin embargo, las dificultades para aplicar el concepto de pares mínimos a las señas, tal como las representa el sistema de Stokoe, no terminan con esta observación. La función de los pares mínimos es guiar al analista en la asignación de fonos (es decir, los elementos de representación a nivel fonético) a distintas categorías fonémicas. Pero se sostiene que el sistema de Stokoe es en esencia un sistema émico. Es decir, los símbolos como «[]», «┴» y «#» son descritos como queremas (equivalentes a fonemas del habla, no como queres, que serían los equivalentes a los fonos en el habla). Por lo tanto, la afirmación de que APPLE y ONION son un par mínimo contradice por completo la noción de pares mínimos.
El par mínimo [pes] y [tes] permite al analista clasificar los fonos [p] y [t] en categorías fonémicas distintas, pero el sistema de Stokoe afirma que ya está representando las señas en un nivel querémico, equivalente al nivel fonémico en el habla. De hecho, esto sugiere que no hay ningún otro interés lingüístico que se pueda obtener de observar pares como APPLE y ONION, que no sea documentar la oposición.
Meir y colaboradores afirman también, en concordancia con las afirmaciones de Stokoe, que las configuraciones manuales, las localizaciones y los movimientos que componen la estructura interna de una seña, funcionan como bloques de construcción carentes de significado, al igual que los fonemas en las lenguas producidas oralmente. También sostienen que esto verifica la noción de que las lenguas de señas, efectivamente, muestran dualidad de estructuración, equivalente al rasgo universal de las lenguas humanas, ya que ambas poseen un nivel de estructuración fonológico y uno gramatical.
La observación importante aquí es que en el léxico de la lengua de señas Israelí las diferentes formas de la mano, la localización y los movimientos funcionan como bloques de construcción sin sentido, de la misma manera que fonemas como [t], [k] y [a]9 en las lenguas orales [...] En pocas palabras, las lenguas de señas consolidadas que han sido investigadas tienen una estructura en el nivel fonológico. Esta característica da dualidad de estructuración a la lengua de señas (Hockett, 1960), la característica universal de diseño de las lenguas humanas que hace posible crear un vasto vocabulario de formas significativas a partir de un número relativamente pequeño de unidades que forman un sistema sin referencia al significado. (Meir et al., 2007, pp. 537-539)
Si uno toma esa afirmación sobre la dualidad de estructuración solo para entender que todas las lenguas combinan elementos sin sentido para formar morfemas y palabras, y que las palabras significativas se combinan para formar un número ilimitado de enunciados posibles, entonces su afirmación es válida, puesto que, efectivamente, los dos tipos de lenguas la tienen. Sin embargo, esto requiere cambiar la definición de la dualidad de estructuración, para eliminar la noción de contraste sintagmático a nivel fonológico. Es decir, a nivel fonológico la definición de la dualidad de estructuración involucra secuencias de segmentos sin significado que componen morfemas o palabras. El modelo de Stokoe, tal como fue descrito más arriba, no tiene segmentos y, por lo tanto, no tiene secuencias de segmentos. Por el contrario, si se llega a demostrar que las señas consisten en secuencias de segmentos, entonces el concepto de pares mínimos se podría utilizar sin la necesidad de redefinirlo. Una demostración semejante propondría que las señas descritas anteriormente como pares mínimos no cumplirían con la definición aplicada generalmente.
Problemas con la supuesta simultaneidad en el sistema de Stokoe
Repasemos la propuesta de Stokoe en cuanto que un haz simultáneo de queremas se adhiere al significado como una sola unidad. Stokoe representa algunas señas como constituidas por tres queremas simultáneos. Este hecho es representado en la Figura 4 como grupos de rasgos organizados verticalmente. Esto se encuentra en consonancia con la práctica común de representar fenómenos simultáneos dentro de un evento lingüístico. Por ejemplo, THINK ('pensar') (Figura 4a) es representado con los siguientes tres queremas simultáneos: frente, forma de la mano en G, y movimiento de contacto.

GUESS ('adivinar') (Figura 4b) ilustra otro tipo de simultaneidad. Es representada por la frente, la forma de la mano en C, y dos movimientos simultáneos: un movimiento hacia la izquierda y un movimiento de cierre. Por lo tanto, aunque la seña utiliza dos movimientos, todos sus aspectos se conciben como simultáneos.
El concepto de un haz simultáneo de símbolos ya no es posible cuando consideramos señas como la de CHICAGO (Figura 4c), que, como se mencionó anteriormente, tiene dos movimientos (hacia la derecha y hacia abajo), a pesar de que son secuenciales antes que simultáneos. Al producir CHICAGO, primero la mano se mueve hacia la derecha y luego hacia abajo. La existencia de estas señas es un argumento en contra de la noción central del sistema de Stokoe, que afirma que los rasgos de una seña constituyen un único paquete simultáneo; porque la seña, en realidad, contiene secuencias de tales rasgos.
Si CHICAGO fuera la única excepción a la noción de representar señas con un haz simultáneo de símbolos, sería posible preservar los fundamentos de un sistema simultáneo y tratarla como una seña que requiere una representación secuencial excepcional. Pero CHICAGO no es excepcional. Más bien, representa a un gran número de señas producidas con dos movimientos secuenciales.
Además, Stokoe representa las señas como congress (Figura 4d) con una secuencia de tres movimientos secuenciales: contacto, movimiento hacia la derecha y contacto. Otras señas, como BRAVE (Figura 4e), también son representadas con tres símbolos de movimiento: contacto, movimiento hacia afuera y movimiento de cierre. Sin embargo, a diferencia de congress, ocurre primero el contacto y luego es seguido por dos movimientos simultáneos: movimiento de alejamiento del cuerpo y movimiento de cierre. Es decir, con posterioridad al contacto, a medida que las manos se alejan del contacto con el cuerpo, las formas de las manos se cierran simultáneamente. Las clases de señas representadas en las Figuras 4c, 4d y 4e demuestran claramente que el concepto de que las señas consisten solo en un único haz simultáneo sin secuencia alguna, es solo una ficción conveniente que se inició con la propuesta original de Stokoe en 1960 (un concepto al que él mismo no se adhirió en la práctica).
Problemas planteados por las señas compuestas
Desde 1970, el sistema de transcripción de Stokoe solo ha sido utilizado nominalmente en el análisis de las estructuras fonológicas y morfológicas de ASL. Esto constituye un enigma, porque su modelo querémico y su conjetura de la simultaneidad han sido ampliamente aceptados. Por ejemplo, Klima y Bellugi (1979, capítulo 9) adoptan los supuestos del modelo de Stokoe y los usan para presentar el primer análisis del proceso de composición que tiene tan alta productividad en ASL. Los ejemplos presentados por ellos se basan en la idea de que cualquier seña es una unidad simultánea.
Ellos recogieron y analizaron un gran número de señas compuestas, con lo que demostraron que los compuestos adquieren sus propios significados y que sus formas se diferencian de las secuencias simples de dos señas. Por ejemplo, consideremos la seña que significa algo como just barely adequate ('apenas mínimamente adecuado'), formada de GOOD ('bueno') y ENOUGH ('suficiente'), en ese orden. La Figura 5 repite las ilustraciones de Bellugi y Klima sobre la manera en la cual un individuo zurdo señó GOOD y ENOUGH, y cómo esa misma persona hizo la seña del compuesto GOOD^ENOUGH just barely adequate ('apenas mínimamente adecuado').
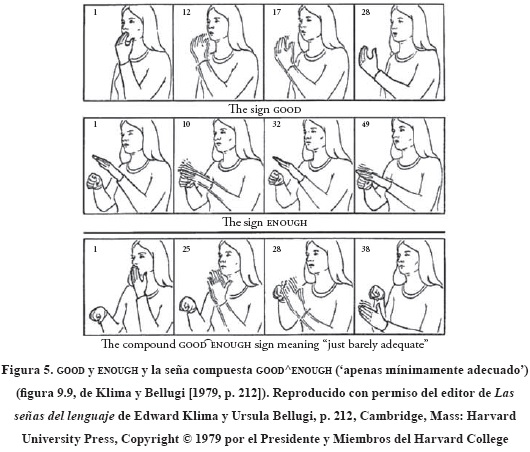
Klima y Bellugi demuestran que la seña compuesta es un ítem léxico independiente con su propio significado y con una forma que es diferente de aquella que se encuentra en la secuencia de las dos señas independientes. Es evidente, por sus ilustraciones, que aunque la seña compuesta comienza con la mano izquierda ubicada y orientada como al comienzo de GOOD, no se produce la seña GOOD de manera completa. En su lugar, después de dejar el contacto con la barbilla, la mano izquierda rápidamente se reorienta y se relocaliza, de tal manera que la palma roza la superficie radial de la forma de mano en S, sobre la mano derecha. En ENOUGH la repetición también está ausente. Además, la mano derecha ya está en posición durante el fragmento de la seña compuesta asociada con GOOD en una sola mano, y la orientación de la forma en S de la mano derecha es diferente de su orientación cuando se produce ENOUGH por fuera de la seña compuesta.
Debido a que el sistema de Stokoe no proporciona un modo de explicar estas diferencias como cambios en la estructura de una o ambas señas, Klima y Bellugi se ven obligados a hablar de manera impresionista de un movimiento «reducido y debilitado» de la seña inicial (1979, p. 216), y de una «transición suavizada entre señas» (1979, p. 218). También describen el ritmo del compuesto como algo diferente al de una frase. En los compuestos, las señas «parecen más estrechamente juntas» (1979, p. 211) que las mismas dos señas en una frase. Ellos describen la seña inicial como una seña que pierde fuerza y repetición, y mencionan que las señas de una mano «tienden a reducirse a un único contacto breve o detención (una duración de unos pocos milisegundos), como si apenas se representara el inicio de la seña» (1979, p. 216).
El problema que este análisis plantea proviene de la concepción de Stokoe de las señas, en la que ninguna parte de la estructura querémica es identificable como el inicio de la seña. Todos los aspectos son vistos como si fueran simultáneos, por lo que es imposible hablar de un inicio o un final en términos querémicos. Como resultado, la descripción de Klima y de Bellugi de la formación de compuestos se basa en términos impresionistas como «fuerza», «reducido» y «debilitado», así como la noción de «pareciendo más estrechamente juntas». Por lo tanto, aunque el sistema querémico de transcripción pareció adecuado para la representación de las señas en un diccionario, su falta de utilidad para la solución de problemas fonológicos o morfológicos demuestra que el modelo de estructura de las señas como «queremas simultáneos» tiene problemas significativos10.
Argumentos anteriores para la segmentación de señas
Secuencialidad vs. Segmentabilidad
En los tratamientos lingüísticos tradicionales, la fonética ha hecho una distinción entre eventos secuenciales articulatorios y segmentos fonéticos o fonológicos. Por ejemplo, consideremos la africada [č] en la palabra inglesa chat / čæt /. Para producir [č], la lengua debe detener primero el flujo de aire haciendo contacto con la cresta alveolar, como si se produjera una [t]. Luego, la lengua debe moverse hacia una posición cercana de la cresta alveolar para producir el sonido [š] de «sh». Por lo tanto, aunque producir [č] requiere una secuencia de eventos articulatorios para la producción del segmento fonético [č], se lo trata comúnmente como un segmento articulatorio único. Del mismo modo, una oclusiva aspirada tal como [t ͪ] también requiere una secuencia de eventos articulatorios. Durante el inicio, la lengua contacta la cresta alveolar y corta el flujo de aire. Después, durante el cierre, el sistema pulmonar aumenta la presión de aire en la boca, y por último la lengua se separa de ese contacto de una manera tal que provoca la aspiración, conocida como liberación. Pese a la secuencia de eventos necesarios para producir [t h], este también se trata como un único segmento consonántico.
Stokoe reconoce en su propuesta original la necesidad de describir las actividades secuenciales como parte de la articulación de las señas, pero solo dentro de la unidad «simultánea» única que constituye una seña completa. Él ve la secuencia dentro del movimiento. Sin embargo, trata los queremas dentro de la seña como simultáneos.
La noción de que las señas pueden tener estructuras secuenciales internas no es reciente. Ya para 1978, los problemas con la falta de segmentación en el modelo querémico de Stokoe eran evidentes. Supalla y Newport (1978) investigaron las diferencias de formación en cien pares de sustantivos y verbos parecidos en su formación, y descubrieron que los sustantivos y los verbos difieren en aspectos secuenciales de sus movimientos. Identificaron tres modos de movimiento: continuos, de detención y restringidos. Con esto, demostraron que la forma del movimiento al comienzo de una seña puede diferir de la que está en el medio o al final.
Por ejemplo, aunque el Diccionario de la lengua de señas estadounidense describe que SIT ('sentarse') y CHAIR ('silla') tienen los mismos tres aspectos, Supalla y Newport encontraron diferencias en su producción. Ellos describieron SIT como una seña que inicia con un movimiento unidireccional y termina con un movimiento de detención. En contraste, propusieron que CHAIR también comienza con un movimiento unidireccional, pero termina con un movimiento con forma restringida (es decir, un «rebote» en la dirección opuesta al movimiento original). Basándose en las pruebas secuenciales que reunieron, ellos sugieren que «las señas pueden tener segmentos internos secuenciales, contrariamente a la opinión predominante de que las señas son haces simultáneos de rasgos» (1978, p. 96).
Evidencia adicional de la necesidad de segmentar el movimiento aparece en el análisis de las formas verbales aspectuales en ASL (Newkirk, 1980, 1981). Newkirk reconoce la importancia de ambos, movimientos y detenciones, en el análisis de estas formas verbales aspectuales. También argumenta que el parámetro de movimiento necesita ser segmentado:
En algún nivel de abstracción, existe evidencia de que al menos uno de estos parámetros, el movimiento, presenta una organización secuencial–segmental, y que la información relacionada con uno de los otros parámetros, la configuración manual, de alguna manera debe realizase en la forma superficial de una seña en coordinación temporal con la estructura de movimiento. (1981, p. 65)
Aunque Newkirk presenta evidencia considerable en favor de la segmentación del movimiento en las formas verbales aspectuales, y argumenta que la configuración manual debe estar coordinada con los movimientos, falla en el intento de proponer que las señas, en general, se componen de secuencias de segmentos; en tanto encuentra que «no hay razones convincentes para analizar sintácticamente la seña en segmentos separados» (1981, p. 17).
Movimientos y detenciones como segmentos
Liddell (1982, 1984) ofrece los primeros argumentos sobre los conjuntos de funciones simultáneas que componen los segmentos fonológicos, y sobre las secuencias de tales segmentos que componen las señas. Resumimos los argumentos en las siguientes secciones.
Medir movimientos y detenciones
Liddell utiliza datos sincronizados para demostrar que las señas comunes son divisibles en secuencias de lo que él llama movimientos (M) (es decir, períodos de tiempo durante los cuales la mano se mueve), y detenciones (o holds —H—) (es decir, periodos de tiempo en los que la mano no se está moviendo). Él midió los períodos de M y H en señas, tanto en narraciones como para una lista, cuando eran señadas de forma individual. Además, observó que, en ambas condiciones, la mano pasa tanto tiempo sin moverse como moviéndose, y que en ambas condiciones emerge un patrón consistente de secuencias M y H. Liddell argumenta que estos datos de sincronización demuestran que (si se producen rápidamente como parte de una narración o más lentamente en la medida que las señas están en una lista) las señas tienen una estructura secuencial fundamental y coherente.
Señas de contacto sin contacto
Muchas señas tienden a ser producidas con el contacto entre la mano activa y el cuerpo, cuando son articuladas en forma aislada o discurso cuidadoso. Las mismas señas, cuando se producen en un discurso más rápido, frecuentemente se aproximan al punto en el que normalmente entran en contacto, pero en realidad no hacen contacto. Liddell llamó a estas señas de contacto sin contacto (noncontacting contact signs), cuyo comportamiento era un misterio en el sistema querémico.
Por ejemplo, Stokoe representó KNOW ('saber') como «∩BΤx» (localización en la frente, configuración manual en B orientada al señante, y un movimiento de contacto). En la producción de la forma con contacto de esta seña, la mano se mueve hacia arriba, hacia la frente. Mientras se aproxima a la frente, adquiere la configuración manual plana de B, con los cuatro dedos doblados sobre la primera articulación y las puntas de los dedos orientadas hacia la frente. La mano continúa su movimiento hacia la frente hasta que las puntas de los dedos hacen contacto. Este contacto es así sostenido durante un período apreciable de tiempo (es decir, en términos de Liddell, la seña termina con una detención).
Representar la seña en el sistema de Stokoe con el querema de movimiento «X» (contacto) implica que este contacto con la frente es lo importante, mas no el movimiento para conseguir que la mano entre en contacto con la frente. Además, la transcripción no lleva ninguna implicación que indique que el contacto es una parte de la estructura de la seña. Stokoe observa que KNOW puede ser producida también sin el contacto con la frente (1978, p. 29), aunque todavía se mueva hacia la frente. Él describe esta forma de la seña como producida en el espacio delante del señante, con un movimiento hacia arriba («ØBτ˄»).
Esto constituye un acertijo, porque según Stokoe, al producir la forma con contacto de KNOW, la mano se mueve hacia la frente con el propósito de hacer contacto. Si el querema de contacto se elimina, no parece existir ninguna razón para que la mano se mueva, puesto que ya no hay ninguna instrucción para ponerse en contacto con algo. Stokoe reemplaza «X» (acción de contacto) con «∧» (movimiento hacia arriba) y reemplaza la localización «∩» (frente) con «Ø» (espacio delante del señante). Ahí la seña es descrita, simplemente, como un movimiento hacia arriba en el espacio, sin ninguna meta distinta que un movimiento general ascendente, y constituye la afirmación de que la forma sin contacto de KNOW tiene una estructura totalmente diferente, que no está asociada a la frente.
Esto no refleja el comportamiento real de la mano en la forma sin contacto de KNOW. Simplemente mover la mano verticalmente hacia arriba no producirá una seña reconocible como KNOW. En realidad, el movimiento de la mano se dirige, de todas maneras, hacia una meta específica (la frente). Sin embargo, a pesar de que las puntas de los dedos no hacen contacto con la frente, se mueven a una posición cerca de ella, y acaban en una pausa, manteniendo esta posición durante un período apreciable de tiempo. Por lo tanto, el movimiento hacia la frente y la detención posterior son propiedades comunes tanto de la forma con contacto, como de la forma sin contacto de KNOW.
Sobre la base de esta observación, Liddell argumenta que ambas formas tienen la estructura MH y, en ambos casos, el movimiento es hacia la frente. La diferencia entre las dos es dónde está la mano cuando detiene su movimiento hacia la frente. En uno de los casos, la mano está en contacto con la frente y, en el otro, no lo está. Visto en estos términos, la forma sin contacto no pierde a la frente como lugar que guía el movimiento de la mano, es decir, que no pierde su movimiento hacia la frente. Más bien, la diferencia entre las dos resulta solo de la prosa que describe las dos formas de KNOW. En un caso, la mano se mueve hacia la frente y hace contacto, y, en el otro, la mano se mueve hacia la frente y se detiene sin realizar contacto.
Semejante punto de vista es imposible en un modelo estrictamente simultáneo de la estructura de las señas. De hecho, Liddell argumenta que si las dos versiones de la seña comparten los dos primeros aspectos de la actividad (donde inicia la mano, y su movimiento hacia la frente) y solo la última parte es diferente (si la mano se pone en contacto o no con la frente), entonces debe haber un orden secuencial significativo.
Compuestos
Utilizando estas mismas observaciones sobre las señas compuestas, Liddell demuestra que la primera seña en compuestos como BELIEVE ('creer'), seña compuesta formada históricamente a partir de THINK («∩Gτx») y marry ('casarse') («ØCC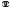 »), se reduce a un segmento H. Específicamente, propone que si la primera seña tiene un segmento de contacto H, ese segmento será retenido y el resto de la seña no será producido. Liddell propone que estos hechos relacionados con THINK en una seña compuesta no pueden ser explicados usando un modelo en donde todos los aspectos de la estructura de la seña son representados por un haz simultáneo.
»), se reduce a un segmento H. Específicamente, propone que si la primera seña tiene un segmento de contacto H, ese segmento será retenido y el resto de la seña no será producido. Liddell propone que estos hechos relacionados con THINK en una seña compuesta no pueden ser explicados usando un modelo en donde todos los aspectos de la estructura de la seña son representados por un haz simultáneo.
El primer elemento de THINK^marry ('pensar en casarse') tiene una estructura diferente a la de THINK a la hora de ser producida de forma individual, porque el movimiento inicial hacia la frente no se encuentra presente en la forma de la seña compuesta. No hay movimiento inicial hacia la frente cuando la estructura de THINK se entiende como «uGτx». Esto se debe a que el movimiento de contacto «X» es el único movimiento en la seña. Más aún, no hay ninguna parte final a ser conservada en el compuesto. Liddell argumenta claramente que, con el fin de mantener solo una parte secuencial de una seña, la seña debe tener partes secuenciales.
Secuencias de segmentos
Liddell propone que las señas compuestas de una sola acción circular constan de un solo segmento m. Concluye que otras señas como STARE ('mirar fijamente') y BE–SITTING ('estar sentado'), que se producen sin ningún otro movimiento de la mano que el movimiento transicional necesario para poner las manos en la posición, consisten de solo un segmento H. Él argumenta que, por simple lógica, se deriva que un movimiento seguido de una detención debería consistir en dos segmentos:
Parece razonable sostener la siguiente idea: si una seña M se compone de haces de unidades primarias, y así ocurre con una seña H, entonces una seña que se mueve y se detiene consta de dos haces de unidades primarias. Uno especifica las características de la seña durante el movimiento M, y el segundo especifica las características de la seña durante la detención H. (1984, p. 382)
La evidencia no manual
Liddell (1984) observó que la producción de algunas señas también involucra secuencias articulatorias no manuales que están estrechamente coordinadas con secuencias articulatorias manuales. Por ejemplo, GIVE–IN ('ceder') comienza con una mano en B que mantiene la palma en contacto con el pecho, y las puntas de los dedos apuntando a través del cuerpo. La mano se desplaza ligeramente hacia abajo y lejos del pecho y llega a detenerse. En el tiempo en que la mano alcanza esa posición, la muñeca ha rotado lo suficiente para que, desde su posición más inferior, la palma todavía esté de cara al pecho. Esto hace de GIVE–IN una seña con la estructura HMH.
Además de estas producciones manuales, los aspectos no manuales de esta seña también son secuenciales. La seña comienza con los labios apretados uno con otro, seguido por una rápida separación de los labios mientras la mano se aleja del pecho. La boca es sostenida en una posición de apertura durante la H final. Independientemente de la duración que tiene la detención inicial en GIVE–IN, los labios apretados se mantienen durante toda esta detención. Del mismo modo, independientemente de la duración de la detención final, la boca se mantiene abierta durante este intervalo de tiempo.
Durante el movimiento entre las detenciones, se lleva a cabo una transición de labios apretados a boca abierta. Aunque, desde esta perspectiva, labios apretados se puede identificar como un rasgo de la producción de GIVE–IN, una representación a partir de Stokoe no tiene medios para hacer esta observación. Esto se debe a que labios apretados no es un rasgo de la seña como un todo, sino lo es solo de la detención inicial. De manera similar, boca abierta es un rasgo solo de la detención final. Las h inicial y final cumplen una función importante, en cuanto que los rasgos manuales y no manuales están alineados durante estos segmentos.
Señas ya conocidas por tener múltiples movimientos
En la obra original de Stokoe, se decía que una seña es un único haz simultáneo de localización, configuración manual y rasgos de movimiento, pero el aspecto de movimiento frecuentemente involucraba secuencias. Esto condujo a que señas como CHICAGO aparecieran casi como un haz de rasgos completamente simultáneos, y, por lo tanto, de cierta manera ilegítimas, de ser correcto el supuesto teórico de Stokoe. Sin embargo, si las señas se componen de segmentos secuenciales, cada uno con su propio conjunto de rasgos, entonces CHICAGO simplemente se convierte en una seña más, producida con una secuencia de segmentos.
Stokoe analizó CHICAGO («ØC>V») como si tuviese una secuencia de dos movimientos: «>» (hacia la derecha) y «V» (hacia abajo). En la propuesta de Liddell (1984) CHICAGO consta de una secuencia de tres segmentos: mmh. La mano se mueve hacia la derecha durante el primer movimiento, hacia abajo durante el segundo, y finalmente termina con una detención11.
El tratamiento que Stokoe da a tales señas asume que, a pesar de que la mano hace múltiples movimientos, los rasgos de localización y configuración manual permanecen constantes. Esto no es correcto. Además del hecho evidente de que la mano inicia en un lugar, se mueve hacia la derecha a un segundo lugar, luego se mueve hacia abajo a un tercero; también cambia la orientación de la palma de la mano. Durante el movimiento inicial, la palma está orientada hacia delante (alejada del señante), pero esto cambia durante el segundo movimiento, de tal manera que, para la conclusión de la seña (durante la h final), la palma es orientada hacia abajo. Este cambio de orientación debe ser coordinado exactamente con el cambio final de la localización, lo que sugiere que las secuencias son fundamentales en la estructura de las señas12.
Otras señas cambian la configuración manual durante múltiples movimientos. Por ejemplo, destroy comienza con las dos manos en forma 5. Para un señante diestro, la mano derecha se coloca por delante del lado derecho del pecho, la palma hacia abajo, mientras la otra mano está sobre el lado izquierdo del pecho, con la palma hacia arriba. Las manos se cruzan (mano fuerte sobre mano débil) sin ningún cambio en la configuración manual. Las dos manos regresan luego a sus localizaciones iniciales, pero, mientras lo hacen, cambian hacia configuraciones manuales en A. La propuesta de Liddell trata destroy como una seña mmh, con una configuración manual final diferente a la inicial y con un cambio en la configuración manual sincronizado para ocurrir durante el segundo cambio de lugar.
Los verbos de indicación
Liddell también observa que los verbos de indicación (indication verbs) (Liddell, 2003) deben ser especificados para más de una localización13. Por ejemplo, si givex→y ('dar') comienza su movimiento hacia x (el destinatario) y termina su movimiento dirigido hacia y (una mujer de pie junto al destinatario), la seña se traduce como 'usted le da (eso) a ella'. La localización inicial de la seña identifica el destinatario como el dador y la localización final identifica a la mujer como el receptor. No hay manera de describir el movimiento en esa seña mediante la identificación de solo una localización para ella.
Suponga que el destinatario fuera la localización de la seña ¿Qué movimiento posible podría asegurar que la seña finalice señalando a la mujer junto al destinatario? Del mismo modo, si se entendiera que la mujer es la receptora del dar, y una localización en su dirección fuera especificada como la única localización de la seña, ¿Qué opción posible habría para asegurar que la mano comienza dirigida hacia el destinatario? Esto llevó a Liddell a concluir que tales verbos implican una secuencia esencial e indispensable de los lugares que es distintiva, y con movimientos entre ellos.
Movimientos sin trayectoria y movimientos locales
Stokoe propuso dos tipos de movimiento: los que causan que la mano se mueva a lo largo de una trayectoria y los que no lo hacen. Por ejemplo, el movimiento «┴», según Stokoe, lleva la mano a lo largo de una trayectoria en una dirección de alejamiento del señante, mientras que el movimiento «▨» simplemente hace que la forma de la mano se cierre.
En WHITE ('blanco') (ejemplo 5) la forma manual en 5 comienza con el pulgar y las puntas de los dedos en contacto con el pecho. A medida de que la mano se aleja del pecho, se cierra en forma de O. En el ejemplo 6, la seña bimanual BRAVE ('valiente') comienza con el pulgar y las puntas de los dedos de una mano en 5, y en contacto con los frentes de sus respectivos hombros. Luego, las manos se dirigen hacia afuera y terminan sus movimientos en lo que el sistema de Stokoe identifica como una forma manual (querémica) en A, aunque las manos en realidad tengan una forma manual en S.

Estas dos señas ilustran cómo el símbolo acción de cierre es insuficiente por sí solo como mecanismo para producir la configuración manual final correcta. Es decir, hay más de una manera de cerrar la mano en 5. Stokoe añadió la segunda forma de la mano entre paréntesis cuadrados para representar este hecho. Sin embargo, la especificación de una segunda mano es inconsistente con un sistema que afirma que las señas tienen una sola configuración manual, y con denominarla un «movimiento de cierre» en vez de una «segunda configuración manual». Por lo tanto, Liddell argumenta que esas señas proporcionan evidencia de la necesidad de especificar las secuencias de configuración manual, un hecho fácilmente ubicado dentro de un sistema que admite secuencias de segmentos.
Un tercer tipo de movimiento (movimientos locales —a menudo llamados movimientos internos de la mano—) también argumenta en favor de la segmentación de las señas. Estos involucran un tipo de actividad secundaria repetida de las manos, que puede co–ocurrir con los movimientos de trayectoria. Uno de tales movimientos locales es el serpenteo, en el que los dedos repetidamente serpentean debido a las contracciones musculares en la articulación más cercana a la palma de la mano.
Consideremos VERY–LONG–AGO ('hace mucho tiempo'). En el tratamiento de Liddell VERY–LONG–AGO ('hace mucho tiempo') es una seña MH con el movimiento de inicio muy por delante del hombro, con una configuración manual 5 y con la palma orientada a través del cuerpo. Los dedos serpentean durante este movimiento. Cuando la mano se acerca al hombro, detiene su movimiento y los dedos también detienen su serpenteo. La mano que no serpentea mantiene brevemente una configuración inmóvil (H). El problema para una representación simultánea es que el serpenteo no se puede asignar como una propiedad de la seña. Más bien, el serpenteo es una propiedad solo del movimiento hacia el hombro, ya que no hay serpenteo durante h. Sin embargo, si M y H tienen sus propias propiedades, entonces esto lleva a asignar el serpenteo como una propiedad de una, pero no de la otra. En la medida de que cada segmento tiene sus propios rasgos, esto lleva a restringir el serpenteo al segmento en el cual efectivamente ocurre.
El modelo revisado MH
El modelo inicial MH (Liddell, 1984) fue considerablemente ampliado y revisado en Liddell y Johnson (1989). Mantuvo M y H como los dos tipos básicos de segmentos que componen las señas, pero los separó como unidades sincronizadas de los rasgos que no solo configuran la forma, la orientación y la localización de la mano, sino también las señas no manuales. Este modelo fue enseñado en el curso de fonología de ASL de Johnson en la Universidad de Gallaudet a mediados de 1980. Además, las versiones inéditas de las guías de clase, así como un manuscrito inédito de 1985, «ASL: The Phonological Base» que explica los detalles de cómo el sistema ha evolucionado, fueron también ampliamente distribuidos durante este tiempo. El artículo fue publicado finalmente por Liddell y Johnson (1989).
El modelo difiere significativamente del de Liddell (1984) en varios sentidos. En primer lugar, proporciona una descripción mucho más detallada de la forma de la mano, (denominada ahora como configuración manual), la ubicación y la orientación tanto de la mano activa como de la mano pasiva, y las relaciones entre la mano activa y la localización especificada de la seña. También se mostró que unas representaciones más detalladas de las señas ayudan a identificar las restricciones de estructura del morfema y los procesos fonológicos, y conduce a solucionar problemas morfológicos.
El modelo MH y su desarrollo en el modelo presentado en Liddell y Johnson (1989) es el único intento que sabemos que existe, que crea un sistema de representación capaz de representar más detalles fonéticos de la actividad real de hacer señas. Tales detalles han sido especialmente útiles en el análisis de muchas construcciones morfológicas en ASL: los «marcos» aspectuales (Liddell, 1984; Johnson, 1996), los procesos de formación de compuestos en ASL (Liddell, 1985; Liddell & Johnson, 1986), la afijación y la incorporación numeral (Liddell, 1996), y la reduplicación (Liddell, 2003).
Liddell y Johnson (1989) también exploran procesos fonológicos como la epéntesis de movimiento, la eliminación de detención, metátesis, geminación, asimilación, reducción, la perseverancia y anticipación. Al lado de este trabajo, esa versión del sistema fonético también ha sido aplicada al análisis de otras lenguas de señas (Takkinen, 2002; Fridman-Mintz, 2006)
Sin embargo, los fonólogos de la ASL no han estado interesados especialmente en la representación fonética detallada de las señas. La fonología de la lengua de señas ha venido a orientarse principalmente por tipos más abstractos de representaciones:
Utilizar el comportamiento fonológico de la configuración manual como guía para su análisis implica que el detalle fonético se relegará a un componente diferente de la gramática. (Sandler, 1989, p. 45)
Mi hipótesis es que entre más cercano esté nuestro análisis de lo fonético, más visibles son las diferencias entre el lenguaje de señas y el lenguaje hablado, y que entre más cercanos estén nuestros análisis de la función gramatical, más visibles aparecerán las similitudes. (Brentari, 1998, p. 3)
La meta de la especificación mínima de los rasgos en un sistema de representación de nivel émico es también una característica del modelo silábico propuesto en Wilbur (1993):
El detalle fonético predecible y la especificación de rasgos redundantes no deben ser incluidos en una verdadera representación de nivel «fonémico». (Wilbur, 1993, p. 137)
El enfoque adecuado es, entonces, plantear la menor cantidad de estructura interna en las entradas léxicas hasta el momento en que se demuestre de manera concluyente que se les debe añadir estructura adicional. (Wilbur, 1993, p. 149)
Debido a que buscamos desarrollar un sistema que posibilite una descripción, y una solución a problemas fonológicos y morfológicos corrientes, y puesto que ninguna de estas propuestas trata con representaciones de nivel fonético, nosotros no las revisaremos acá. Sin embargo, queda por revisar aquí una propuesta con respecto a la segmentación. Esta sugiere que los movimientos no necesitan ser transcritos en la representación de las señas de ASL, y en esa medida es directamente pertinente para nuestro análisis.
Un modelo sin–movimiento
Sin presentar una contrapropuesta explícita, Hayes (1993) sostiene que en el análisis de las lenguas habladas los fonólogos se han ido alejando de los rasgos dinámicos. Antes de la aparición de la fonología autosegmental, la africada era considerada como una consonante única que incluía más de una sola configuración. Su configuración inicial, representada en la Figura 6 se parece a [t], y su configuración final se asemeja a [š]. Dadas estas correspondencias, los fonólogos llegaron a representar la africada como una secuencia unida de dos configuraciones estáticas distintas, y no como una sola consonante con el rasgo dinámico [+ liberación retardada].

Hayes plantea la hipótesis de que podría ser fructífero buscar rasgos dinámicos en ASL y reemplazarlos por unos estáticos. Él observa que tanto Liddell (1988) como Stack (1988) argumentan que las señas producidas con un movimiento de gancho se pueden describir en términos de sus puntos terminales. Por ejemplo, DREAM ('soñar') comienza con un dedo índice recto en contacto con el lado de la frente. A medida que la mano se aleja de la frente, comienza el «enganche», contrayendo repetidamente la segunda y tercera articulación del dedo índice. Cuando el movimiento llega a una parada, el dedo se queda inmóvil en la posición de gancho. Por lo tanto, la seña se puede describir como que comienza con un dedo índice recto, y concluye con un dedo índice en forma de gancho, y oscila rápidamente entre estas dos configuraciones durante el recorrido del movimiento.
Hayes observa que un m es probablemente el «elemento dinámico central de todos» (1993, p. 220). Si hubiera una manera de eliminar los m de las representaciones fonológicas de ASL, entonces se parecerían mucho a las representaciones fonológicas de las lenguas producidas oralmente. Él conjetura que si los m resultaran ser completamente predecibles, no aparecerían de ninguna manera en las formas subyacentes14.
En el próximo artículo de esta serie se demuestra que la eliminación de los m de las representaciones estructurales fonéticas o fonológicas de la ASL oscurece el hecho de que los medios para ir de una configuración a otra resultan ser significativos y no predecibles. Hayes mismo encuentra problemas para especificar la forma de la trayectoria del movimiento (por ejemplo: arco, recto), así como cuando el movimiento es o no es «acentuado». Él finaliza su propuesta sin soluciones para ninguno de estos problemas. Nosotros demostramos que cierto número de otras características para ir de una configuración a la siguiente también necesitan ser especificadas como parte de un movimiento.
Transcripciones fonéticas
Lenguas producidas oralmente
Una transcripción fonética de un enunciado hablado es una representación de los sonidos producidos por un hablante en una ocasión específica. Cómo una representación fonética representa exactamente un evento de habla, diferirá de acuerdo con las necesidades del analista que realiza la transcripción. Como mínimo, el sistema fonético debe capturar las distinciones de sonido necesarias para distinguir una palabra de otra. Es posible que las transcripciones fonéticas de varias instancias de la palabra play ('jugar') producidas por varios hablantes de diferentes sexos y edades puedan estar representadas todas ellas como [phleI]. Esto no quiere decir que todos los hablantes pronuncien la palabra exactamente de la misma manera. Más bien, significa que el analista reconoció la misma secuencia de unidades fonéticas cada vez que uno de los hablantes produjo la palabra. Las tres unidades son la consonante aspirada inicial [ph], la consonante [1], y el diptongo [eI].
Las producciones reales de estas instancias de play podrían haber diferido en la entonación de la voz, el tono del sonido, la longitud de la vocal, el grado de aspiración de la consonante inicial, y así sucesivamente. Es decir, a pesar de que la voz de un niño o de una mujer esté típicamente en un tono más alto que el del hombre, la representación fonética [phleI] no pretende representar ese hecho. Lo que el analista intenta hacer es identificar las unidades fonéticas lingüísticamente significativas dentro del grupo de sonidos, mientras ignora otros aspectos del grupo de sonidos que son resultado de fenómenos idiosincráticos, lingüísticamente no significativos.
Transcribir la palabra play fonéticamente requiere tomar una decisión acerca de si el sonido inicial cae en la categoría de los sonidos representados fonéticamente como [ph] o en la categoría de sonidos representada fonéticamente como [p]. La producción típica de play por parte de un hablante estadounidense estaría representada fonéticamente como [phleI]. Cualquiera que haya escuchado a un gran número de hablantes sabe que hay muchas diferencias individuales en la pronunciación. Sin embargo, estas diferencias no suelen ser lo suficientemente grandes como para cambiar las categorías fonéticas.
Es posible, sin embargo, encontrar a un hablante que pronuncie play de una manera que requiera una representación fonética diferente. Por ejemplo, hemos observado una celebridad de la televisión cuya producción de play tendría que ser representada fonéticamente como [pleI]. Es decir, no aspira la «p» inicial hasta el punto que garantice su categorización como aspirada.
Destacamos aquí que los símbolos fonéticos para transcribir son símbolos para categorías abstractas de sonidos, pero las categorías no son tan abstractas como las categorías fonémicas. La principal diferencia entre las categorías fonéticas y fonémicas es que las categorías fonémicas son abstracciones a través de las categorías fonéticas (abstractas). Es decir, para el inglés, las categorías fonéticas abstractas [ph] y [p] caen ambas dentro de la categoría fonémica aún más abstracta /p/. Para otras lenguas estas dos categorías fonéticas abstractas son potencialmente capaces de distinguir una palabra de otra, por lo que podrían caer en las diferentes categorías fonémicas.
Lenguas de señas
Idealmente, un sistema de representación fonética para las señas debe cumplir los mismos objetivos que uno para el habla. Debe proporcionar una representación categórica escrita de lo que un señante produce realmente. Tales representaciones podrían proporcionar una base para el análisis de varios tipos de procesos fonológicos, incluyendo la asimilación, la perseverancia, y así sucesivamente.
Sostenemos que una representación fonética adecuada para las señas necesariamente implica secuencias de segmentos fonéticos. La naturaleza y el tipo de los segmentos requeridos para esa representación son el tema del siguiente artículo de nuestra serie.
1 Stokoe, Casterline y Croneberg (1965, p. XXIX) describen la motivación para el término querema de la siguiente manera: «(CARE–eem, la primera sílaba de una palabra del griego homérico, que significa manual)». El origen del término es descrito de manera diferente en Maher (1996, p. 67), quien indica que se trata «de la palabra griega chirologia (término del siglo XVIII y el siglo XIX para dactilológico o señando)»
2 Por convención, Stokoe omite el símbolo para la localización en la parte frontal del cuerpo («Ø»). Su diccionario representa chicago como «C>V». Hemos añadido el símbolo tab «Ø» aquí para mayor claridad.
3 Aunque la orientación manual es fundamental, y aunque cambia durante el curso de la seña, no se describe como un aspecto independiente en la notación de Stokoe. Si se representa, tiende a ser mostrada como una parte de la forma manual (dez) o como un movimiento específico, tal como «υ» (movimiento de supinación).
4 La seña bimanual de ASL se opone a la seña de una sola mano RUSSIA, tomada de la Lengua de Señas Rusa.
5 El uso de tales categorías fue defendida a menudo, diciendo que Stokoe no estaba tratando de hacer fonética (que estaba interesado sólo en la representación émica) y, por lo tanto, tales detalles no son relevantes. Sin embargo, al representar los fonemas de una lengua oral no sucede que sea irrelevante la fonética de esa lengua hablada. De hecho, los fonemas son usados a la par que un conjunto de afirmaciones sobre la distribución que siempre hacen posible recuperar la representación fonética a partir de la representación fonémica. Por lo tanto, a falta de afirmaciones sobre la distribución de los aloqueres a partir de los queremas, las clasificaciones de Stokoe de las categorías émicas son injustificadas e inutilizables.
6 Obsérvese que Stokoe describe todas las señas como si fueran producidas por un señante diestro. Por lo tanto, la orientación hacia la izquierda de BLACK ('negro') significa aquí la orientación hacia la izquierda de la mano derecha. Su sistema de notación no atiende al hecho de que hay señantes zurdos, ni a la práctica común de los señantes diestros de señar como si fueran zurdos. Esta es una dificultad que nuestra propuesta resuelve.
7 A pesar de la amplia aceptación de esta idea, Stokoe nunca separó la configuración y la orientación manual. Por lo tanto, para el sistema de Stokoe esta contradicción interna de la teoría (diecinueve símbolos dez, pero cientos de posibles configuraciones dez) nunca fue resuelta. Además, la expresión facial y otros detalles de gestos no manuales también necesitan ser representados por razones léxicas, morfológicas y sintácticas (ver entre otros Liddell, 1977, 2003; Baker & Padden, 1978; Baker-Shenk & Cokely, 1980).
8 Una revisión útil de estos conceptos aparece en Mannheim (1991).
9 Meir y colaboradores utilizan paréntesis cuadrados para representar fonemas, mientras nosotros seguimos la práctica tradicional de representar fonemas entre paréntesis angulares y los fonos entre paréntesis cuadrados.
10 Véase Liddell (1984) y Liddell y Johnson (1986) para una discusión más completa de la composición y de otras dificultades inherentes de la visión simultánea de la estructura de la seña.
11 Nuestro análisis de CHICAGO en un artículo posterior se diferencia del de Liddell (1984), en que el sistema fonético que proponemos contiene cinco segmentos.
12 Puesto que Stokoe representó una secuencia de dos movimientos, y porque todas las demás secuencias también eran representadas como movimientos, su sistema fue capaz de representar la sincronización del cambio de orientación y los cambios de localización. Él logró eso mediante el etiquetado de cambios de orientación como movimientos unitarios. En ese caso, el movimiento sería etiquetado con el símbolo ŋ, que es descrito como «asentir con la cabeza». Sin embargo, este no es una clase de movimiento, sino más bien un cambio único de orientación que necesita estar coordinado con el cambio final de lugar.
13 A pesar de que estas señas son referidas comúnmente como verbos de concordancia, Liddell (2000) sostiene que no aparecen en construcciones en las que se aplica el concepto de concordancia gramatical.
14 Uyechi (1995, p. 97) también propone un modelo en el cual el «movimiento en sí no emerge como un constructo fonológico del modelo». Más bien, ella propone una «unidad de transición» que pretende dar razón de los cambios en la forma de la mano, localización y orientación, mientras que la mano se mueve de una configuración a la siguiente.
Referencias
Baker, C., & Padden, C. (1978). American Sign Language: A Look at Its Story, Structure, and Community. Silver Spring: tj Publishers. [ Links ]
Baker, C., & Cokely, D. (1980). American Sign Language: A Teacher's Resource Text on Grammar and Culture. Washington D.C.: Clerc Books. [ Links ]
Battison, R. (1974). Phonological Deletion in American Sign Language. Sign Language Studies, 5, 1-19. [ Links ]
Battison, R. (1978). Lexical Borrowing in American Sign Language. Silver Spring: Linstok. [ Links ]
Bloomfield, L. (1933). Language. New York: Holt. [ Links ]
Brentari, D. (1998). A Prosodic Model of Sign Language Phonology. Cambridge: MIT Press. [ Links ]
Fridman-Mintz, B. (2006). Tense and Aspect Inflections in Mexican Sign Language Verbs. Tesis doctoral, Georgetown University. [ Links ]
Friedman, L. A. (1975). Space, Time, and Person Reference in American Sign Language. Language, 51, 940-961. [ Links ]
Frishberg, N. (1975). Arbitrariness and Iconicity. Language, 51, 696-719. [ Links ]
Hayes, B. (1993). Against Movement: Comments on Liddell's Article. En G. R. Coulter (Ed.), Current Issues in ASL Phonology. San Diego: Academic Press. [ Links ]
Hockett, C. (1960). A Course in Modern Linguistics. New York: Macmillan. [ Links ]
Johnson, R. E. (1996). The Continuative Aspect Inflection in ASL: Evidence for Variable Phonological Feature Values. Documento presentado a Theoretical Issues in Sign Language Linguistics Conference, Montreal, Quebec, Canada. [ Links ]
Klima, E., & Bellugi, U. (1979). The Signs of Language. Cambridge: Harvard University Press. [ Links ]
Liddell, S. K. (1977). An Investigation into the Syntactic Structure of American Sign Language. Tesis doctoral, University of California-San Diego. [ Links ]
Liddell, S. K. (1982). THINK and BELIEVE: Sequentiality in American Sign Language Signs. Linguistic Society of America, University of Maryland, Summer Session. [ Links ]
Liddell, S. K. (1984). THINK and BELIEVE: Sequentiality in American Sign Language. Language, 60, 372-399. [ Links ]
Liddell, S. K. (1985). Compound Formation Rules in American Sign Language. En SLR '83, Proceedings of the III. International Symposium on Sign Language Research. Silver Spring: Linstok Press. [ Links ]
Liddell, S. K. (1988). Structures for Representing Handshape and Local Movement at the Phonemic Level. Manuscrito inédito, Gallaudet University, Washington, D.C. [ Links ]
Liddell, S. K. (1989). American Sign Language: The Phonological Base. Sign Language Studies, 64, 195-277. [ Links ]
Liddell, S. K. (1996). Numeral Incorporating Roots and Non-incorporating Prefixes in American Sign Language. Sign Language Studies, 92, 201-226. [ Links ]
Liddell, S. K. (2000). Indicating Verbs and Pronouns: Pointing Away from Agreement. En K. Emmorey & H. Lane (Eds.), The Signs of Language Revisited: An Anthology to Honor Ursula Bellugi and Edward Klima (pp. 303-320). Mahwah: LEA. [ Links ]
Liddell, S. K. (2003). Grammar, Gesture, and Meaning in American Sign Language. New York: Cambridge University Press. [ Links ]
Liddell, S. K., & Johnson, R. E. (1986). American Sign Language Compound Formation Processes, Lexicalization, and Phonological Remnants. Natural Language and Linguistic Theory, 4, 445-513. [ Links ]
Maher, J. (1996). Seeing Language in Sign: The Work of William C. Stokoe. Washington D.C.: Gallaudet University Press. [ Links ]
Mannheim, B. (1991). The Language of the Inka since the European Invasion. Austin: University of Texas Press. [ Links ]
Meir, I., Padden, C., Aronoff, M., & Sandler, W. (2007). Body as Subject. Journal of Linguistics, 43, 531-563. [ Links ]
Newkirk, D. (1980). Rhythmic Features of Inflections in American Sign Language. Manuscrito. La Jolla, California: Salk Institute. [ Links ]
Newkirk, D. (1981). On the Temporal Segmentation of Movement in American Sign Language. Manuscrito. La Jolla, California: Salk Institute. [ Links ]
Pike, K. (1947). Phonemics: A Technique for Reducing Languages to Writing. Ann Arbor: University of Michigan Press. [ Links ]
Sandler, W. (1989). Phonological Representation of the Sign. Dordrecht: Foris. [ Links ]
Sapir, E. (1925). Sound Patterns in Language. Language, 1, 37-51. [ Links ]
Sapir, E. (1933). La réalité psychologique des phonèmes [The Psychological Reality of Phonemes]. Journal de Psychologie Normale et Pathologique, 30, 247-265. [ Links ]
Stack, K. (1988). Tiers and Syllable Structure in American Sign Language: Evidence from Phonotactics. Tesis de maestría, University of California-Los Angeles. [ Links ]
Stokoe, W. C., Jr. (1960). Sign Language Structure: An Outline of the Visual Communication System of the American Deaf. Studies in Linguistics occasional papers, no. 8, Buffalo: Department of Anthropology and Linguistics, University of Buffalo. [ Links ]
Stokoe, W. C., Jr., Casterline, D., & Croneberg K. (1965). Dictionary of American Sign Language. Washington D.C.: Gallaudet College Press. [ Links ]
Supalla, T., & Newport, E. (1978). How Many Seats in a Chair? The Derivation of Nouns and Verbs in American Sign Language. En P. Siple (Ed.), Understanding Language through Sign Language Research (pp. 91-132). New York: Academic Press. [ Links ]
Swadesh, M. (1934). The Phonemic Principle. Language, 10, 117-129. [ Links ]
Takkinen, R. (2002). Käsimuotojen salat: Viittomakielisten lasten käsimuotojen omaksuminen 2-7 vuoden iässä. (Väitöskirja) [The Secrets of Handshapes: The Acquisition of Handshapes by Native Signers at the Age of Two to Seven Years]. Tesis doctoral, Kuurojen Liitto ry, Helsinki. [ Links ]
Trager, G. L., & Bloch, B. (1941). The Syllabic Phonemes of English. Language, 17, 223-246. [ Links ]
Uyechi, L. A. N. (1995). The Geometry of Visual Phonology. Tesis doctoral, Stanford University, Stanford, California (Publicado en 1996 por CSLI Publications, Stanford). [ Links ]
Wilbur, R. (1993). Syllables and Segments: Hold the Movement and Move the Holds! En G. R. Coulter (Ed.), Current Issues in ASL Phonology (pp. 135-168). San Diego: Academic Press. [ Links ]
Woodward, J. A., Jr. (1973). Implicational Lects on the Deaf Diglossic Continuum. Tesis doctoral, Georgetown University. [ Links ]

