











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
PermalinkINTRODUCCIÓN
Nos hemos acostumbrado a entender por «música» sólo el arte de los sonidos, e incluso hoy, simplemente el ejercicio de la música; sabemos que eso es una acepción arbitraria, puesto que el pueblo, que inventó la palabra «música», entendía con ella no sólo la Poesía y la Música, sino en general todas las manifestaciones artísticas del hombre íntimo, en la medida en la que este manifiesta, con el máximo de expresión, sus sentimientos y concepciones, con el órgano de la lengua de los sonidos, en una realización concreta suprema y definitiva. (Wagner, 2013, p. 77)
El interés que han despertado en los últimos años los análisis de las relaciones entre música y lingüística nos ha conducido a explorar estas dos vías, desde nuestra área de trabajo, la lingüística computacional y de corpus. La lingüística, por una parte, pretende estudiar el lenguaje y la forma en que los seres humanos nos relacionamos con él y a través de él. La música, por su parte, ha sido siempre una valiosa constante en la vida de los seres humanos en general, de forma «ontogenética» (individual) y «filogenética» (de la especie), según J. M. Igoa (2010, p. 97). Deseábamos, por lo tanto, ver de qué manera sería posible hacer un análisis en el que ambos campos estuviesen presentes. Es decir, poder analizar, en un primer momento, obras líricas utilizando para ello algunas de las herramientas que nos brinda la informática. Con el fin de lograr nuestro cometido recopilamos lo más representativo de la obra de Richard Wagner: catorce libretos traducidos al español, que se encuentran en un sitio en castellano dedicado a los compositores de óperas en general1.
Somos conscientes de que, aunque contamos con unas partituras que han sido traducidas de una forma muy depurada, no es lo mismo que si hubiésemos accedido a los textos originales en alemán. Nuestro impedimento en tal caso era más de orden lingüístico, ya que no somos hablantes de esta lengua germana y, por lo demás, este primer trabajo hace parte de un proyecto mayor de análisis de otros compositores de óperas2. Hemos decidido comenzar por Wagner, teniendo en cuenta que era un compositor muy polifacético que, además, escribía sus propios libretos, basándose en antiguas historias y leyendas germánicas o europeas.
El objetivo de este estudio de tipo exploratorio es obtener unos primeros datos a partir del análisis computacional de este primer corpus, lo que en un futuro nos permitirá realizar un trabajo más amplio en el que se puedan analizar los libretos de otros compositores de Europa, Asia y América. No obstante, consideramos importante, antes de realizar el estudio de las obras wagnerianas, dedicar un primer momento al análisis de la relación entre música y lingüística, ya que esta relación es de suma importancia para nuestro trabajo.
RELACIÓN ENTRE MÚSICA Y LINGÜÍSTICA
¿Existe una relación entre música y lingüística y, de existir dicha relación, en qué campos se daría? En realidad, si realizamos un análisis en el que ambos campos se entrelacen, podemos ver cómo varios autores se han interesado en explorar los vínculos existentes entre estas dos disciplinas del conocimiento humano. Para comenzar, tenemos los primeros trabajos de J.-J. Nattiez producidos en los años setenta, que abordan la semiología de la música. Seguido de esto, cabe destacar los recientes trabajos que exploran terrenos tan diversos como la relación entre música, fonología y sintaxis3 (McCarry & Zarnowski, 2007; Gallo, Reyzábal & Santiuste, 2008) y entre música y lingüística computacional (Fell & Sporleder, 2014; Eismont & Degtyareva, 2015). Aunque nuestro interés se encuentra focalizado en la relación música-lingüística computacional, dedicaremos, no obstante, algunos apartados del presente artículo a trazar la antes mencionada relación entre música-semiótica-fonología.
Un primer análisis semiótico de la música
Como lo mencionábamos con anterioridad, el primer autor en interesarse de una forma bastante clara en la relación entre estos dos campos del saber humano fue el musicólogo J.-J. Nattiez. En uno de sus primeros artículos, «Linguistics: a New Approach for Musical Analysis», este autor se dedica a explorar la idea de analizar la música de la misma forma que se hace con el lenguaje, es decir, utilizando métodos lingüísticos. Nattiez dice al respecto: «music is perhaps the non-linguistic field where linguistic models can most successfully be applied»4 (1973, p. 52). Todo el trabajo realizado por este autor recibirá el nombre de semiología de la música.
De hecho, para Nattiez el análisis realizado por F. de Saussure de los signos (bajo el nombre de semiología) puede muy bien ser aplicado a campos no lingüísticos como el de la música, y esto debido al «carácter lineal que posee esta última» (Nattiez, 1973, p. 53) y que tiene gran relación con los sistemas utilizados para describir el lenguaje natural y las herramientas utilizadas por los lingüistas para hacerlo. Así, los elementos, las notas musicales, pueden analizarse al igual que los fonemas, y el texto musical puede, a su vez, ser analizado sintáctica o semánticamente como el texto escrito, etc. Si bien es cierto que este autor no es el primero en interesarse en la relación entre música y lingüística, sí será el primero en teorizar acerca de esta relación desde una perspectiva semiológica-lingüística y a la vez musicológica.
Más tarde otros autores, como R. Monelle (1992; 2000) y N. Meeús (1993), harán una más explícita referencia al término «semiótica musical», diciéndonos que esta debería permitir la interpretación de signos semejantes a los que se encuentran en el lenguaje, pero esta vez en la música, pudiendo estos ser interpretados por el oyente o receptor del mensaje sonoro.
La música como vector de análisis de la fonología y la sintaxis
Si los autores antes mencionados realizaron unos primeros análisis desde la perspectiva semiótica, algunos otros van a ver la relación entre lingüística y música más centrada en un contexto fonológico (prosódico) y de la sintaxis musical, ligada a una de estas dos disciplinas o a ambas al mismo tiempo. Tal es el caso del trabajo desarrollado por las investigadoras N. McCarry y A. Zarnowski (2007), quienes nos proponen la posibilidad de analizar la música desde una perspectiva prosódico-lingüística y sintáctico-musical, a través de tres elementos suprasegmentales, que son: la entonación, la acentuación y el ritmo. Si, en efecto, según estas autoras, estos tres elementos poseen puntos comunes entre música y lingüística, dichos puntos comunes pueden analizarse utilizando «una estructura sintáctica de varios niveles jerárquicos que se manifiestan bajo el aspecto de una estructura arborescente y bajo el aspecto de una malla métrica» (2007, p. 66).
Para el análisis, las autoras parten de las categorías propuestas por Lerdahl y Jackendoff (1983) y Lerdahl (2003): la sílaba, el pie, la palabra fonológica, el grupo fonológico y el grupo de entonación. Otros autores, como Gallo, Reyzábal y Santiuste (2008), añadirán a estos tres elementos los siguientes: altura o tono, intensidad, duración y ritmo. Según estos autores, tanto un fonema como una nota musical (análoga o digital) comparten todos estos elementos.
En aras de observar hasta qué punto la música wagneriana puede ser analizada utilizando sistemas informáticos, como los que se emplean para analizar las cadenas habladas (PRAAT, por ejemplo), hemos empleado un software que nos ha permitido obtener un espectrograma de un fragmento de una obra wagneriana. Así pues, en la Figura 1 podemos ver un análisis de un fragmento de Tannhäuser de Richard Wagner, utilizando, para ello, el programa Sonic Visualiser (Cannam, Landone & Sandler, 2010).
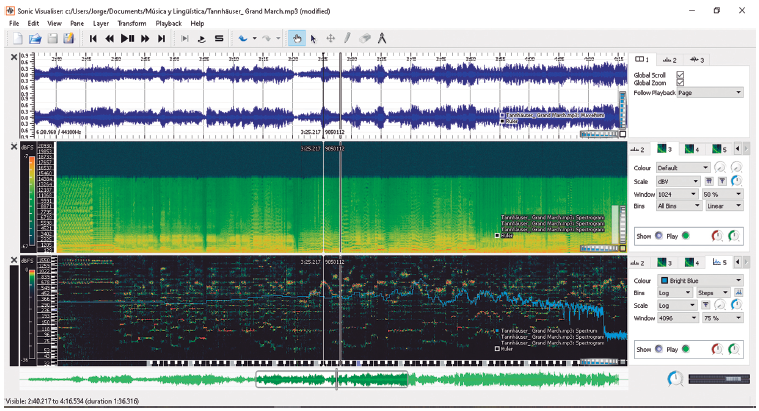
Figura 1 Análisis de un fragmento de Tannhäuser de Richard Wagner, utilizando Sonic Visualizer (Cannam, Landone & Sandler, 2010)
Podemos observar un espectrograma de un segmento en el cual canta el coro en esta ópera, acompañado por la orquesta (en esta sección se trata, en su mayor parte, de instrumentos de cuerda). En la parte izquierda podemos observar la parte correspondiente al coro masculino (voces graves) y, a partir del centro, lo que hace referencia al coro femenino (voces agudas). En la parte superior, puede verse la zona correspondiente a la forma de la onda (waveform); en el centro, en colores gris, verde y amarillo, se encuentra la zona relativa al espectrograma; y en la zona inferior, podemos observar la parte que representa tanto los picos de frecuencia (con los formantes) como el espectro (con la frecuencia fundamental F0).
Este sistema nos permite analizar, al igual que con PRAAT, no solamente la realización de los instrumentos, sino además la producción de los elementos suprasegmentales antes mencionados. A diferencia de PRAAT, Sonic Visualiser permite el análisis de segmentos mucho más extensos, ya que el primero se encuentra limitado a análisis no superiores a diez segundos, mientras que el segundo no tiene límite de tiempo, pues fue diseñado para archivos mucho más grandes. En el caso que analizamos arriba, tenemos un fragmento de Tannhäuser que dura 6'38" y que es leído sin problema, y además hemos podido constatar que el sistema soporta grabaciones aún mucho más extensas.
La Figura 1, a título de ejemplo, da cuenta de una posibilidad de análisis, entre las diferentes que se pueden realizar desde una perspectiva fonológica. Por nuestra parte, en el marco del presente trabajo, nuestro interés se centrará en el análisis textual (lexical y fraseológico), a nivel computacional, de los libretos que contienen las obras de Wagner. Es así como se realiza el análisis de la música fundado en la lingüística computacional que presentamos a continuación.
La música desde el punto de vista de la lingüística computacional
Según J. Libovicky (2013), para compositores como L. Meyer (1956) el sentido musical viene de la confrontación entre la expectación del oyente y los diferentes niveles de percepción, niveles particulares que, según el compositor estadounidense, pueden ser modelados como cadenas de Markov5. Otros autores interesados en el campo del tratamiento del lenguaje y la música fueron Witten, Manzara y Conklin (1992), y el propio trabajo de Libovicky puede tomarse como ejemplo, al diseñar este autor un sistema de extracción de melodías en audio.
Según algunos autores (Fell & Sporleder, 2014), la música lírica, por su parte, y al igual que las lenguas naturales, puede ser analizada gracias a la lingüística informática. En su trabajo, estos autores se interesan en la extracción, análisis y clasificación de letras de canciones en inglés según los diferentes géneros musicales a los que corresponden. Para estos autores, «cuando un compositor escribe la letra de una canción, este despliega unos mecanismos particulares de estilo que le permiten redactar dicha letra» (p. 620). Fell y Sporleder indican, además, que dichos mecanismos pueden medirse automáticamente y que pueden, por lo tanto, ser lo suficientemente distintivos como para permitir la identificación en una canción de su género musical, de su calidad y del tiempo en que fue publicada. Tenemos pues un interés marcado en el análisis de textos ligados a la música y que pueden ser estudiados a partir de herramientas informáticas.
Respecto de la lingüística computacional y su relación con la música, hay que señalar como un hito el encuentro académico adelantado en 2015, en San Petersburgo, Rusia. En dicho evento se estudió esta relación desde diversos puntos de vista: 1) música y lenguaje en la educación; 2) estudios de corpus de lenguaje y música; 3) problemas de notación; 4) estudios lingüísticos de la música. Una obra que recoge estas cuatro temáticas fue publicada luego del evento: Language, Music and Computing(Eismont y Konstantinova, 2015). Vale la pena destacar, de todos los artículos publicados, el referente a la «búsqueda del sentido como un estudio para observar la relación entre lenguaje y música», de Eismont y Degtyareva (2015). En este artículo, se analizan obras de autores rusos y occidentales, entre ellas La walkyria de R. Wagner. La idea de estas autoras es analizar la percepción del sentido que se tiene con obras orquestadas y ver cómo dicho sentido puede ser analizado desde el punto de vista emocional. En efecto, para estas autoras es importante poder constatar la relación semántica entre lenguaje y música a partir de datos experimentales que tienen que ver con la relación que el oyente tiene con la música y cómo esta relación puede reflejarse de forma emocional.
Un segundo artículo importante en esta obra viene de la mano de O. Mitrofanova (2015), titulado «Probabilistic Topic Modeling of the Russian Text Corpus on Musicolo-gy». Este artículo es importante por cuanto la autora propone un análisis probabilístico de textos musicales en los que se analizan las relaciones paradigmáticas y sintagmáticas entre los lemas y los tópicos. Resulta interesante ver cómo, en este trabajo, la autora se interesa en la elaboración de un sistema de análisis que permite distinguir entre tópicos generales o especiales. Esto es similar a lo que sucede en el trabajo realizado por Fell y Sporleder (2014), con la diferencia de que Mitrofonova se especializa en textos musicológicos, esto es, en textos escritos por críticos musicales de origen ruso.
Finalmente, reseñamos el proyecto que desde 2016 adelanta la Universidad Pompeu Fabra de Barcelona, llamado «Music Meets Natural Language Processing», que gira en torno a la extracción de información musical que se encuentra en la red.
LA MÚSICA DE WAGNER VISTA POR LA LINGÜÍSTICA
[...] el canto es el órgano a través del cual un ser humano puede expresarse dentro de la música, y si dicho órgano no ha alcanzado un perfecto desarrollo, [pues] se echa en falta de inmediato un lenguaje auténtico. (Wagner, 2011, p. 162)
La obra wagneriana puede parecer, a la vez, compleja y simple. Según algunos analistas, es de una grandeza inconmensurable, y para otros no pasa de ser una especie de moda6. Lo interesante, sin lugar a dudas, de la obra del maestro de Bayreuth es la posibilidad de poner en escena textos poéticos muy depurados, con imponentes arreglos musicales (gran cantidad de instrumentos en escena) y una caracterización teatral. Es lo que se llama obra de arte total (Gesamtkunstwerk, por su nombre en alemán).
Lo más importante es que el mismo Wagner era el autor de los textos que servían a su obra, para los que luego componía la música7. Serán justamente estos libretos los que analizaremos más adelante en nuestro artículo. En las Figuras 2 y 3 podemos observar dos extractos de obras escritas por Wagner. En el primer caso, se trata del preámbulo al primer acto de Tristón e Isolda (parte orquestada); y en el segundo caso, podemos apreciar un fragmento de la partitura para el coro de los peregrinos, correspondiente a la ópera Tannhüuser (parte a capela).


En los trabajos de Meeüs (1993), Raffman (1993), Spark (2013) se analiza la obra wagneriana y su relación con la lingüística. Para N. Meeüs, por ejemplo, los Leitmotive (temas conductores) wagnerianos pueden, en algunos casos, ser portadores de sentido y ser interpretados por los «iniciados» en la obra del compositor alemán. Por su parte, D. Raffman también aborda los Leitmotive wagnerianos y señala que para que estos sean realmente interpretados, el oyente debe contar con una suerte de glosario que los contenga y que, no obstante, puede o no acertar con respecto a algunas obras.
La autora también hace una aclaración entre lo que para ella son los sentidos musicales (musical meanings) y los sentimientos musicales (musicalfeelings). Para ello, toma dos autores: Wagner y Stravinsky, frente a los cuales el oyente experimentado podrá desarrollar unos sentimientos relevantes dependiendo del tipo de música (Raffman, 1993, p. 53). Finalmente, E. Spark traza un paralelo entre la obra de R. Wagner y la de F. de Saussure, con respecto a la significación (en términos saussureanos) en Wagner. Para Spark «la obra de Wagner puede servir como un campo útil en el que se puede comprobar que la teoría saussureana depende simplemente de la arbitrariedad totalmente determinada antes que de la arbitrariedad socialmente determinada» (2013, p. 26). En este sentido, el autor analiza la arbitrariedad del signo en Saussure y lo va comparando con la obra wagneriana.
Con el fin de analizar los textos escritos por Wagner, hemos empleado algunos sistemas informáticos que permiten analizar corpus escritos, arrojando resultados en cuanto a las coocurrencias o colocaciones que estos textos puedan tener.
SISTEMAS INFORMÁTICOS PARA EL ANÁLISIS DE COOCURRENCIAS Y COLOCACIONES
Existen muchos sistemas informáticos para el análisis del lenguaje y en particular para el estudio de temas como las coocurrencias y las colocaciones. En nuestro caso, utilizamos tres sistemas de uso libre: uno en línea: Wordle (Feinberg, 2014) y dos que pueden ser descargados en Internet: AntConc (Anthony, 2014) y GraphColl (Brezina, McEnery & Wattam, 2015). Debemos recordar que el análisis de coocurrencias, así como el de las colocaciones, puede ayudarnos en terrenos tan importantes como la lexicología y la fraseología, entre otros.
En la parte que sigue explicaremos en qué consisten estas tres herramientas y abordaremos la manera en que fueron utilizadas para el análisis de los textos wagnerianos.
Wordle8
Se trata de una herramienta que permite generar, de manera automática, nubes de palabras (word clouds) a partir de textos (Feinberg, 2014), uno a la vez. Utilizando algunos filtros que Wordle posee, es posible configurar nubes de palabras que extraigan las más pertinentes y que obvien los términos más comunes (determinantes, conjunciones, etc.). En el formato de salida, podemos observar que el tamaño de las palabras es mayor, en función de una mayor utilización dentro del texto. Esto tiene dos inconvenientes: primero, que las palabras compuestas pueden ser tomadas como dos términos aparte (sin embargo = sin + embargo, etc.); segundo, que la variación del tamaño es bastante relativa; por ejemplo, la diferencia entre un tamaño 14 y 15 es poco visible a simple vista.
No obstante haber encontrado estos problemas, este programa nos permite un primer acercamiento a determinados textos y a un corpus en especial. Consideramos que, mientras más extenso sea un texto, mejor se verán los elementos resaltados. En el caso de los libretos de Wagner, existe una fuerte tendencia a que los nombres propios o los de los personajes principales sean bastante nombrados y que esto nos dé unas nubes de palabras en las que predominen este tipo de elementos.
AntConc9
Dentro de la panoplia de herramientas para el análisis del lenguaje que nos proporciona Lawrence Anthony en su sitio, tenemos una herramienta llamada AntConc. Se trata de un programa informático que permite analizar un corpus textual (varios textos a la vez) y encontrar concordancias u ocurrencias de un mismo término o de un conjunto de términos (Anthony, 2014). Para tal fin, AntConc permite utilizar expresiones regulares, lo que ayuda a afinar las búsquedas y a obtener un mayor número de resultados. Gracias a este programa, pudimos obtener la lista general de términos de una forma rápida y fácil, así como observar las posibles colocaciones que se pueden dar dentro del corpus analizado.
GraphColl10
Se trata de una sofisticada herramienta que, además de proporcionar las diferentes ocurrencias de un término, ofreciendo su contexto derecho e izquierdo por listas de palabras, también permite hacer grafos de las palabras encontradas en el corpus (Brezina, McEnery & Wattam, 2015). Al igual que AntConc, este sistema ayuda a analizar grandes corpus, pero no permite el empleo de expresiones regulares. Aparte de las listas, este sistema calcula el peso estadístico de los types analizados. Permite, además, crear nuevos grafos a partir de las ramas de un determinado type.
En el caso del corpus wagneriano, este sistema nos permitió crear grafos a partir de palabras que habíamos hallado con AntConc, para corroborar la información hallada y ver si los types se correspondían entre ellos. Con esto, pretendíamos observar los términos más relevantes y en qué proporción se relacionan con los Leitmotive del autor alemán.
ANÁLISIS DE LAS OBRAS WAGNERIANAS
Descripción del corpus
Con el fin de realizar este trabajo se tomaron las partituras, en castellano, de catorce de las obras más representativas de Richard Wagner. Se tuvieron en consideración las siguientes obras, en orden alfabético: 1) El holandés errante; 2) El ocaso de los Dioses; 3) El oro del Rin; 4) La prohibición de amar; 5) La walkyria; 6) Las hadas; 7) Lohengrin; 8) Los maestros cantores de Núremberg; 9) Parsifal; 10) Rienzi; 11) Sigfrido; 12) Tannhauser; 13) Tristón e Isolda; 14) WesendonkLieder. Como habíamos señalado, todas estas obras se obtuvieron del sitio Kareol y se procedió a su conversión en formato de texto (.txt) y a su codificación en ÜTF-8. Esto nos permitió usar la mayoría de sistemas de análisis que veremos en la parte siguiente.
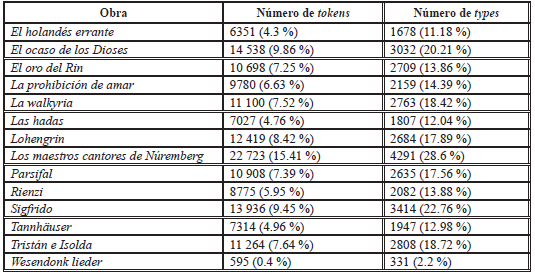
Según el análisis realizado con GraphColl (Brezina, McEnery & Wattam, 2015), el corpus total consta de 147 428 tokens (14 999 types), divididos de la siguiente forma (Tabla 1):
Metodología de trabajo
Basados en el trabajo realizado por Fell y Sporleder (2014), iniciamos nuestro análisis con la herramienta Wordle (Feinberg, 2014). En la Figura 4, referente a la obra El holandés errante, pudimos observar que los elementos que más se destacan son, a parte de los personajes principales (Senta, Erik, el Holandés, etc.), nociones como fidelidad, Dios, corazón, etc. Son términos muy ligados a esta primera obra wagneriana y son los que más se resaltan. En otras obras, como Lohengrin, tenemos los términos Dios, rey, mujeres, etc.

En otras obras posteriores, se podrá observar un cierto cambio y los términos irán variando. Por ejemplo, en las obras de la tetralogía El anillo de los nibelungos, los términos más empleados son amor, corazón, muerte. Esto puede deberse al giro que va tomando la obra de Wagner, que se desliza de obras que tienen que ver con tradiciones paganas de tipo germánico hacia obras de corte más cristiano.
La segunda herramienta empleada para nuestro análisis fue AntConc (Anthony, 2014). Como podemos observar en la Figura 5, para el término amor, pudimos obtener los siguientes resultados:
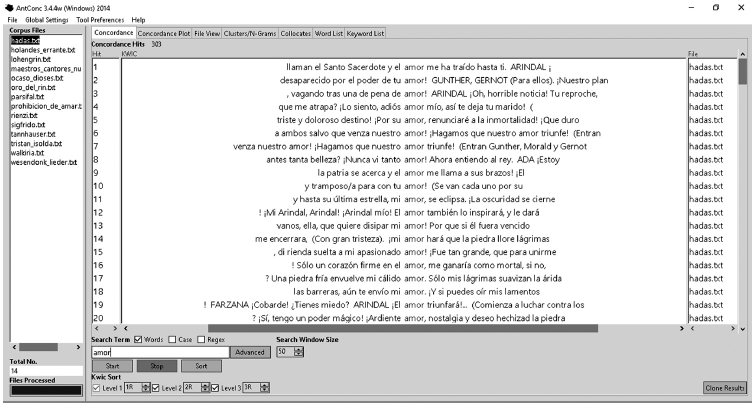
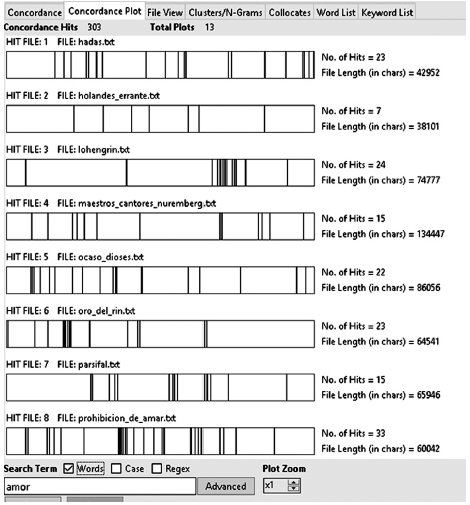
Obtuvimos 303 concordancias de la palabra amor, distribuidas de la siguiente manera en los 14 textos:
Pero si le agregamos a este término la expresión regular representada por el asterisco («amor*»), podemos obtener más resultados. Así se encontraron otras ocurrencias representadas por adjetivos como amorosa, amorosas, amorosos; adverbios como amorosamente, etc., con lo que en esta ocasión se obtuvieron 326 resultados. Si en vez de esto utilizamos «*amor*», entonces obtendremos también: enamorada, enamoraron, enamoró, enamoré, etc., con un aumento a 351 resultados. Esto es importante pues permite alargar la lista de términos relacionados con un type. Sin embargo, es posible que obtengamos algo de ruido y que resulten palabras como clamor y camorra que nada tienen que ver con la palabra amor.
En cuanto a los términos más empleados en toda la obra de Wagner, sacando de lado preposiciones, determinantes, conjunciones, etc., pudimos obtener en la word list de AntConc la Tabla 2:
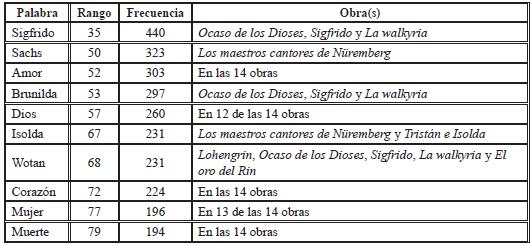
Como podemos observar, los personajes más importantes de toda la obra wagneriana son, en su orden, Sigfrido, que aparece en tres obras de la tetralogía de El anillo de los nibelungos; luego Sachs, de Los maestros cantores de Nüremberg, una de las obras más extensas de Wagner (Tabla 1); y Brunilda, que, al igual que Sigfrido, aparece en varias obras de la tetralogía. En cuanto a los nombres comunes, vemos que amor aparece en primer lugar, luego de corazón, seguido de muerte. Estos serían los términos y los personajes más ligados a los Leitmotive wagnerianos, según este análisis inicial. Intentaremos ver con otras herramientas que analizan colocaciones si dichas relaciones se mantienen o si, por el contrario, cambian.
Analizando el corpus con la herramienta GraphColl (Brezina, McEnery & Wattam, 2015), podemos observar en la Figura 7 la forma de extraer las ocurrencias de la palabra «amor». En la imagen, «amor» se ubica en el centro y al lado izquierdo y derecho, según el contexto en el que se halla en el corpus.
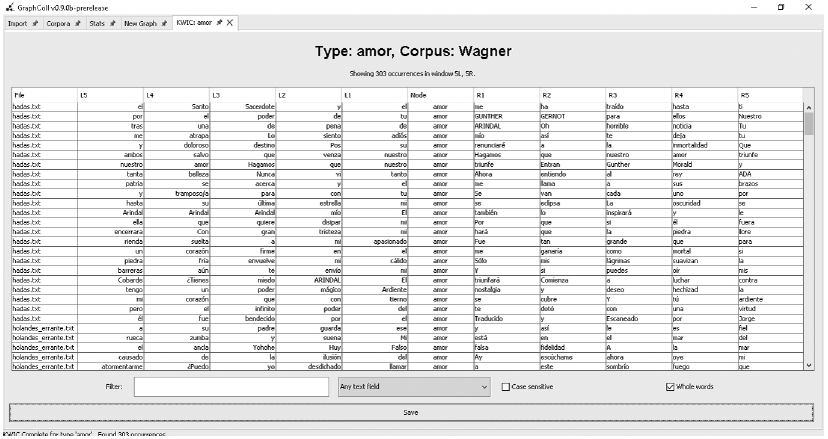
Figura 7 Análisis de ocurrencias de la palabra «amor», en GraphColl (Brezina, McEnery & Wattam, 2015)
Esta herramienta también nos permite crear grafos, como el que podemos ver en la Figura 8. En la parte izquierda, vienen las palabras que tienen mayor relación con el type «amor», así como su peso estadístico, su frecuencia respecto de su colocación y su frecuencia absoluta de aparición en el texto. El grafo que se despliega en la parte derecha, de acuerdo con el peso estadístico, traza la distancia entre el type y sus nudos.
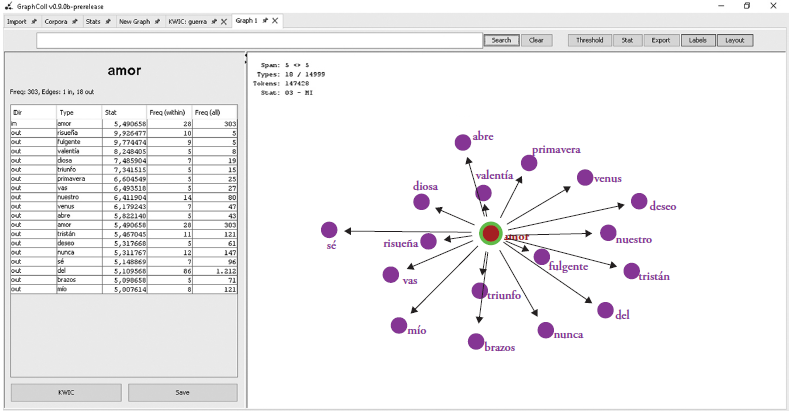
Figura 8 Extracción de un grafo a partir del type «amor», en GraphColl (Brezina, McEnery & Wattam, 2015)
En el grafo para el type «amor» (Figura 9) podemos observar términos como triunfo, fulgente, valentía, risueña, que son los types que mayor cercanía tienen con él; mientras que otros, como se, mío, del, etc., se hallan mucho más lejos.
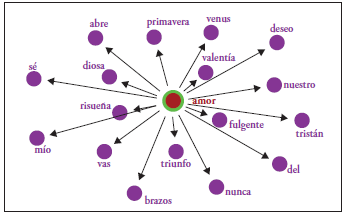
Podemos notar en la Figura 10 que, si buscamos types relacionados con la palabra «fulgente» (fulgente amor), dando clic en este nudo, de esta se desprende el type «muerte»; así podemos ver la relación entre amor + fulgente + muerte. El amor y la muerte hacen parte de los Leitmotive que más se hallan en la obra wagneriana. Es decir, siempre hay un amor (o un amor fulgente) y este conduce irremediablemente a la muerte.
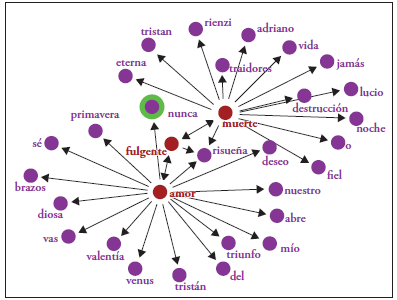
Figura 10 Grafo que se desprende del nudo «fulgente», en GraphColl (Brezina, McEnery & Wattam, 2015)
En la Figura 10, es posible constatar, además, en qué forma el sistema permite alargar los grafos y establecer relaciones entre los diferentes types que conforman el grafo principal. Es posible observar también cómo se encuentran relacionadas las palabras muerte y vida. Lo interesante es que palabras como guerra o dioses no se hallan presentes.
RESULTADOS Y CONCLUSIONES
Como pudimos ver a lo largo de este artículo, existe una relación bastante estrecha entre música y lingüística. Pudimos ver de qué manera se puede analizar tanto el sonido como las letras de las partituras de las obras de Richard Wagner. Algo importante que cabe señalar es el hecho de poder mirar la relación entre el lenguaje y las tendencias en la música, es decir, que a partir de herramientas de análisis de lenguas naturales se puede prever una tendencia o un Leitmotiv en una pieza musical o en un conjunto de obras. Así pues, en el caso de la obra wagneriana se pudo observar una cierta tendencia a una obra que habla principalmente del amor y de la muerte y que posee unos personajes que en general muestran esa tendencia. Esto no es del todo anodino, ya que Wagner fue un fiel representante del Romanticismo y en aquella época estos eran los temas recurrentes; por ejemplo, en los Leitmotive que aparecen en la obra de F. Schubert.
Fue interesante, por lo tanto, poder observar la importancia de la utilización de herramientas para el análisis de corpus, caso de AntConc y GraphColl, que nos permiten justamente ese análisis mucho más fino y que nos dejan entrever estas tendencias antes señaladas. Consideramos que sería bastante interesante contrastar la obra de este autor con la de otros autores que, como él, también escribían sus propios libretos. Esto podría darnos pistas importantes más adelante, y nos dejaría ver si estas tendencias se repiten con otros compositores y si hay diferencias entre épocas y autores. Este es un trabajo exploratorio, pero esperamos realizar otros más.
No obstante, somos conscientes de la existencia de otras posibilidades compu-tacionales, que podrían ayudarnos a mejorar el análisis de los datos obtenidos en el presente trabajo. En este sentido, podemos encontrar algunos métodos basados en el procesamiento del lenguaje natural, como es el caso del Latent Dirichlet Allocation (LDA) o del modelo Word2Vec. En el caso del LDA, se basa en herramientas informáticas estándar que permiten el análisis de datos textuales (Bell & Altosaar, 2016). Según estos autores, este tipo de sistemas representa la información a partir de lo que se llama un bag-of-words o modelo de «bolsa de palabras», que, según Bell y Altosaar, podría ser un poco limitado, por lo que prefieren el modelo Word2Vec.
En el caso del modelo Word2Vec, este tiene una metodología en la que se modeliza un sistema para analizar word embeddings. Algunos autores, como Shanahan & Albrecht (2013); White y Quinn (2014); Kusner et al. (2015) y Bell y Altosaar (2016), trabajan el análisis musical a partir de word embeddings en obras de música clásica. De estos modelos, el más importante constituye el propuesto por White y Quinn, que recibe el nombre de YCAO (Yale/Classical Archives Corpus)11, el cual puede ser fácilmente consultado en línea y posee una gran colección de obras tratadas con este modelo. En futuros trabajos, desearíamos poder aplicarlo, ya que da la posibilidad de realizar análisis mucho más finos que los que se logran con un análisis de coocurrencias y colocaciones.

