











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink
INTRODUCCIÓN
Los procesos de debilitamiento y elisión de /d̪/ intervocálica han sido registrados, comentados y estudiados a lo largo de la historia de la lengua española. Por consiguiente, respecto a esta variación fonológica, hay amplios y conocidos trabajos en relación con su dialectología, su dispersión social y su relación con factores estilísticos (Alba, 2000; Malaver y Samper, 2016; Molina y Paredes, 2014). Estos estudios han mostrado que el contexto -ado es uno de los entornos más propicios para la aparición de las variantes aproximantes y de la elisión. De igual forma, las investigaciones revelan un proceso de elisión avanzado, tanto en España como en América, lo que indica su relevancia sociolingüística.
Además, dichos estudios han determinado tres variantes para el fonema consonántico obstruyente oclusivo oral /d̪/ en posición intervocálica: aproximante plena, relajada y elidida. La identificación de estas variantes se ha realizado, en la mayoría de investigaciones, de manera impresionística o espectrográfica (Gómez y Gómez, 2010; Scrivner y Díaz-Campos, 2016). Generalmente, los procedimientos son de parametrización subjetiva y realizada por distintas personas, lo que puede inducir a errores en los resultados.
Por otra parte, el fenómeno de las aproximantes ha estado en discusión, tanto por su naturaleza y caracterización acústica, como por el estatus fonológico (Figueroa, 2012). Desde el punto de vista fonético, el sonido aproximante ha sido descrito como categoría intermedia entre vocales y consonantes. En consecuencia, los métodos de caracterización de las variantes acústicas, específicamente para el caso de la consonante /d̪/, requieren de sendos análisis y gran gasto de recursos personales y de tiempo, pues se debe tener en cuenta que las medidas acústicas para las aproximantes no son en su mayoría de veces absolutas sino relativas y que para la producción de una /d̪/ se requiere, principalmente, la extracción de datos de duración, frecuencia fundamental5, intensidad6 y frecuencias formánticas7.
El objetivo de este estudio es describir la naturaleza fónica de la variable /d̪/ en el entorno -ado a partir de una prueba experimental con una muestra del habla de Medellín. Se diseñó un corpus para la recolección de datos, que fueron segmentados y llevados a medición automática de 9 parámetros acústicos de cada segmento8 y su proyección sobre una técnica de representación gráfica bidimensional de agrupamiento de rasgos de similitud.
En este artículo se presentan los resultados de dicho experimento. El procedimiento realizado y su correspondiente análisis buscan mejorar la homogeneización y eficiencia de recursos en estudios de variación fónica. Por ello, al final del trabajo se aplicó el protocolo en una muestra amplia de corpus oral robusto, el Preseea-Medellín (González-Rátiva, 2008).
Sobre la noción de aproximante
Uno de los primeros lingüistas en utilizar la denominación aproximante, para referirse a aquellos sonidos con estructura formántica similar a la de las vocales, fue Ladefoged (1975). Describe Ladefoged estos sonidos como el resultado de la proximidad de articuladores sin que se produzca corriente de aire turbulenta. En este sentido, Ladefoged acercó varios sonidos fonemáticos a la categoría de vocoides, especialmente por su caracterización formántica. Martínez Celdrán (1984), entre otros, recoge esta propuesta para la descripción fonética desde una perspectiva hispánica, específica a sonidos en los cuales los órganos articuladores se aproximan, sin roce y sin producción de ruido turbulento. Para Martínez Celdrán (1996) son sonidos más abiertos que las consonantes nasales, laterales y semiconsonantes, y más cerrados que los vocálicos. De esta manera, especialmente en el ámbito hispánico, Martínez Celdrán (1996) atribuye el término aproximante, entre otras, a las consonantes obstruyentes no fricativas, alófonos de las oclusivas orales, y propone la transcripción [ β̞ ð̞ ɣ̞ ] tomando como base el Alfabeto Fonético Internacional9.
También Martínez Celdrán (1998) establece las propiedades acústicas de los sonidos aproximantes: carecen de ruido, tienen las estrías típicas de los sonidos armónicos, muestran un descenso de intensidad en relación con las vocales adyacentes, y presentan un menor ennegrecimiento de la estructura transicional formántica.
La percepción de los sonidos aproximantes ha sido importante en sus diferentes clasificaciones; así, el ruido turbulento las alejó de la categoría de fricativas y, para Fernández (2005), las aproximantes muestran características espectrográficas vocálicas, pero son percibidas con menos claridad.
La revisión de trabajos y textos sobre el fenómeno en cuestión condujo el trabajo aquí presentado a tomar como base la caracterización de los sonidos aproximantes dada por Martínez Celdrán (2013), como la clase de
segmentos que, poseyendo cierto grado de constricción, carecen de la precisión articulatoria requerida para producir una corriente turbulenta de aire, bien sea por la falta de suficiente tensión en los órganos articuladores, bien sea porque el tracto vocal no está suficientemente constreñido o ambas cosas conjuntamente. (p. 15).
De esta manera, se presenta una clasificación acústica de tres variantes a partir de los siguientes parámetros:
aproximantes cerradas: pulsos glotales opcionales sobre la barra de sonoridad y sin explosión.
aproximantes abiertas: transiciones en las vocales adyacentes, pulsos glotales débiles, duración relativa breve e intensidad relativa menor.
aproximantes vocálicas: poca diferencia de intensidad con las vocales adyacentes. Aunque bien percibida, es de difícil segmentación.
ANTECEDENTES
La caracterización acústica de las aproximantes del español, especialmente para la variación de /d̪/, ha sido el propósito de diversos trabajos que han estimado distintos tipos de mediciones acústicas y aplicado diversas técnicas de extracción de datos.
Pérez (2007), para el español de Chile, analizó la serie /b d̪ g/ intervocálica en un corpus de habla de noticieros, con el fin de determinar la incidencia del estilo en la variación sociolingüística. A partir de un procedimiento perceptual y espectrográfico se determinó el reconocimiento de tres variantes: aproximante cerrada, aproximante y elidida. La aproximante cerrada se relacionó con una barra de sonoridad sin formantes; en la aproximante hay presencia de formantes disminuidos en intensidad y trayectorias variables; y la elisión se asoció con la ausencia de variaciones en los formantes de las vocales del entorno.
Sola (2011) hizo un estudio en español peninsular a partir de 90 enunciados de habla espontánea de 37 informantes, tomados de grabaciones de programas de TV, con el fin de verificar la presencia de aproximantes tensas y laxas (Martínez Celdrán, 1984) de /b d̪ g/ y caracterizarlas acústicamente. Con una metodología detallada para la identificación de parámetros acústicos sobre espectrogramas realizados en Praat10 (Boersma y Weenink, 2009) -que incluyen duración, energía, formantes, barra de sonoridad, ruido, entre otros-, mostró la dificultad del análisis del habla espontánea. Para la presentación de los resultados, Sola (2011) categorizó las realizaciones esperables como aproximantes en: aproximante, obstruyente, fundida, elidida, fricativa y asimilada. La autora refirió la realización aproximante como el sonido que presenta barra de sonoridad y estructura formántica y concluyó, a partir de la investigación, que
las aproximantes son sonidos que comparten rasgos consonánticos y vocálicos, esto es: hay obstrucción aunque menor que en las consonantes y por lo tanto más que en las vocales; y existe armonicidad (estructura de formantes), pero de menor intensidad que en las vocales. (p. 138).
Hualde, Shosted, y Scarpace (2011) presentaron datos experimentales, acústicos y electropalatográficos para la alofonía de /d̪/ en un corpus de grabaciones a tres hablantes hispanos, nativos de la península ibérica. Segmentaron en Praat (Boersma y Weenink, 2009) el sonido [d̪] y la vocal adyacente y tomaron dos medidas de la curva de intensidad: la diferencia de intensidad y el cálculo de velocidad MaxVel.
Martínez Celdrán (2013), con el fin de estudiar las aproximantes espirantes del español, [β̞ ð̞ ɣ̞], y determinar y limitar una clasificación medible, analizó los datos de tres hablantes femeninos de la península ibérica. Las mediciones fueron tomadas en Praat (Boersma y Weenink, 2009) para la duración e intensidad, absolutas y relativas, y realizó estadística descriptiva e inferencial sobre los resultados.
Figueroa (2012) propuso una metodología para automatizar la selección de variantes de las aproximantes [β̞ ð̞ ɣ̞] y determinar la naturaleza acústica de estos segmentos, con especial atención al español de Chile. Comenzó con la descripción de procedimientos detallados para la obtención de datos y el tratamiento del registro sonoro y la segmentación en Praat (Boersma y Weenink, 2009). Figueroa propuso tomar mediciones de duración, intensidad, pitch, frecuencias de F1 y F2 y de transiciones de vocales adyacentes a través del establecimiento de scripts. En total describió 62 procedimientos y realizó un pilotaje de esta metodología.
Scrivner y Díaz-Campos (2016), en un trabajo diacrónico sobre el habla caraqueña, asumieron el fenómeno de la aproximante como una variable dependiente continua. Por medio de scripts de Praat tomaron los datos de medidas acústicas del radio de intensidad relativa para ser analizados en un novedoso software, Language Variation Suite, basado en el programa estadístico R, que les permitió automatizar, hacer análisis cuantitativo y establecer análisis macro y multifactorial sobre el fenómeno.
METODOLOGÍA
Se describe a continuación el procedimiento para el estudio experimental de la automatización de la identificación de variantes y el rendimiento de las características acústicas de /d̪/ en el entorno -ado. El diseño del corpus, el protocolo de grabación y la segmentación de los audios fueron hechos por el grupo de trabajo del Laboratorio de Fonética y Filología de la Facultad de Comunicaciones de la Universidad de Antioquia, con el apoyo del Grupo de Estudios Sociolingüísticos; la extracción de parámetros acústicos, la programación y el procedimiento de automatización fueron realizados por el Grupo de ingeniería de señales (GITA)11, así como la selección de la técnica para la representación de los resultados.
Prueba experimental
El experimento consistió en el diseño de una prueba para la posterior automatización de datos fonéticos extraídos de audios. En consonancia con el objetivo de la investigación, se buscó determinar la naturaleza acústica de la variante intervocálica aproximante de /d̪/. En relación con la variante elidida, es evidente que no hay que determinar la naturaleza acústica sino la ausencia de características acústicas distintas a las vocálicas en el segmento.
Para hacer esta prueba experimental efectiva, se construyó un corpus de 3 enunciados con 3 de las palabras terminadas en -ado: lado, pasado y demasiado12. Además, se escogieron estas por pertenecer a categorías léxicas distintas (N. V. Adv.), y por tener distinta longitud silábica. Se escribieron los enunciados para ser leídos en tres versiones por los informantes: los dos primeros con retención de /d̪/, articulación plena y articulación relajada; y la tercera versión con elisión de la /d̪/, pronunciación elidida.
Los enunciados fueron:
[ˈmĩˑɾepoɾlos̬ˈlaˑð̞os̬̪delˈpaˑɾke], versión con retención plena
[ˈmĩˑɾepoɾlos̬ˈlaˑð̞os̬̪delˈpaˑɾke], versión con retención relajada
[ˈmĩˑɾepoɾlos̬ˈlɑˑos̬̪delˈpaˑɾke], versión con elisión
[ˈmũˑt͡ʃas̬ˈbeˑseˈseˑpaˈsaˑð̞opoɾaˈʝiˑ], versión con retención plena
[ˈmũˑt͡ʃas̬ˈbeˑseˈseˑpaˈsaˑð̞opoɾaˈʝiˑ], versión con retención relajada
[ˈmũˑt͡ʃas̬ˈbeˑseˈseˑpaˈsaˑopoɾaˈʝiˑ], versión con elisión
[lɑˈhẽˑn̪teˈeˑs̬̪dẽmãˈsjaˑð̞otɾãŋˈkiˑla], versión con retención plena
[lɑˈhẽˑn̪teˈeˑs̬̪dẽmãˈsjaˑð̞otɾãŋˈkiˑla], versión con retención relajada
[lɑˈhẽˑn̪teˈeˑs̬̪dẽmãˈsjaˑotɾãŋˈkiˑla], versión con elisión
Se seleccionaron 3 hombres y 3 mujeres jóvenes de la ciudad de Medellín, estudiantes de la Universidad de Antioquia, dado que no se trataba de seleccionar mayores variables de análisis para la señal acústica, a quienes se les hizo registro mediante lectura. Los 6 informantes realizaron 3 repeticiones de cada una de las oraciones mediante instrucción que permitiera elicitar las tres variantes de /d̪/; primero una lectura cuidada, luego una lectura relajada y finalmente una pronunciación con /d̪/ elidida.
Las grabaciones fueron hechas en la cabina insonorizada del Laboratorio de Fonética y Filología de la Facultad de Comunicaciones de la Universidad de Antioquia. Se utilizó un micrófono Sennheiser e835. Los audios fueron sistematizados en un Imac, con el programa Adobe audition, en formato .wav, con una frecuencia de muestreo de 44100 Hz.
Una vez realizadas las grabaciones, se procedió a la segmentación del audio [ˈað̞o] y se obtuvo un total de 108 fragmentos de audio, repartidos en 3 grupos: plenas (lectura cuidada con atención a la realización de aproximante cerrada); relajadas (lectura menos cuidada con atención a la producción de una aproximante abierta); y elididas (repetición del enunciado con atención a la elisión de la /d̪/). Este corpus, sistematizado y etiquetado, se envió al Grupo GITA para el análisis automatizado.
Parámetros acústicos para la automatización
Es necesario aclarar que el trabajo del equipo del Laboratorio de Fonética y Filología llega en este trabajo hasta la preparación de las grabaciones, la segmentación, la extracción y percepción de cada fragmento de audio, y la correspondiente codificación, etiquetación y organización de tales archivos de audio para su envío al trabajo de automatización por parte de los ingenieros. Para el proceso de automatización de la señal acústica, el ingeniero de señales realiza una programación en la cual se toma por ventanas de observación una serie de parámetros de magnitudes variables que convierten el dato por ventana en un dato de alta dimensionalidad. Los parámetros acústicos que se tuvieron en cuenta para la programación de la señal acústica en cada ventana de observación fueron: Formante 1, F1; Formante 2, F2; la energía logarítmica, sus primeras y segundas derivadas para medir las transiciones en energía y aceleración. También se midieron los coeficientes cepstrales en las frecuencias de Mel (MFCC)13, y sus primeras y segundas derivadas14.
El procedimiento para la extracción computarizada de dichas características consistió en considerar periodos de observación en segmentos de tiempo corto, segmentos de 10 ms y solapamiento del 50 % en cada uno de los audios segmentados.
Con estos datos se programan dos tipos de análisis: un análisis estático y un análisis dinámico. En el análisis estático la automatización hace cálculos estadísticos (media, desviación estándar, asimetría y curtosis) de cada señal. En el análisis dinámico se hace la extracción de datos sin cálculos estadísticos. Cada uno de estos análisis lleva en los segmentos etiquetas de cada informante, en este caso, las variables sexo y tipo de registro o lectura.
Representación bidimensional de los datos
Los resultados de los cálculos se llevaron a la técnica t-SNE15 (Van der Maaten, 2019), que es un algoritmo para reducir dimensiones de los datos con el fin de permitir una visualización en información bidimensional. La técnica busca la agrupación entre puntos cercanos; es decir, la probabilidad de que dos puntos sean vecinos el uno del otro y tratar de igualar o proyectar esa probabilidad en un espacio bidimensional, tal como se ejemplifica en la Figura 1. Teniendo en cuenta que cada punto tendrá la información de múltiples variables, es importante mencionar que esta técnica no es la única que da la posibilidad de reducción bidimensional de datos, existen otras siete técnicas, algunas de ellas aplicadas por el grupo de ingeniería de señales, aunque sin mejores resultados que la t-SNE.
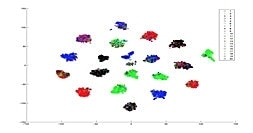
Para una aproximación inicial a los resultados de los datos en el experimento, se buscó agrupamiento de datos por características iniciales (40 %), mediales (20 %) y finales (40 %) en la secuencia [ˈað̞o]. Lo anterior porque se asume que la realización de la consonante es de corta duración en relación con las vocales adyacentes.
Las gráficas generadas a partir de los datos experimentales grabados y la aplicación de los parámetros de automatización llevados a gráficas bidimensionales mediante la técnica t-SNE, nos podría arrojar las siguientes agrupaciones visuales: grupos de [ˈa] vocal central, grupos de [ð̞] aproximante cerrada, de [ð̞] aproximante abierta, de [ð̞] aproximante vocálica, y de [o] vocal posterior.
Lo anterior teniendo en cuenta que la cadena -ado está constituida por tres segmentos fonémicamente distintos: [ˈa], [d̪] y [o], y el contexto fonémico de /d̪/ permite la aparición de tres variantes aproximantes en español (Martínez Celdrán, 2013): abierta, cerrada y vocalizada.
RESULTADOS
De los cálculos realizados y llevados a gráficas, los que mejor agrupación reflejaron son los análisis dinámicos, los datos sin cálculos estadísticos y los de coeficientes cepstrales, que relacionan potencia y energía de contenido perceptual relevante.
En primer lugar, se destaca que las diferencias entre las grabaciones asumidas como plenas (aproximante cerrada) y como relajadas (aproximante abierta o aproximante vocálica) no obtuvieron diferenciación en los cálculos realizados, probablemente por la poca diferencia de características acústicas con las vocales adyacentes. Esta indiferenciación ya estaba dando un indicio del tipo de aproximante encontrada: una aproximante vocálica. Se procedió a realizar cálculos que buscaran 3 agrupaciones: vocal central, aproximantes (plenas que incluyen la relajada), y vocal posterior. Las Figuras 2 y 3 muestran el análisis para las muestras de mujeres y de hombres.
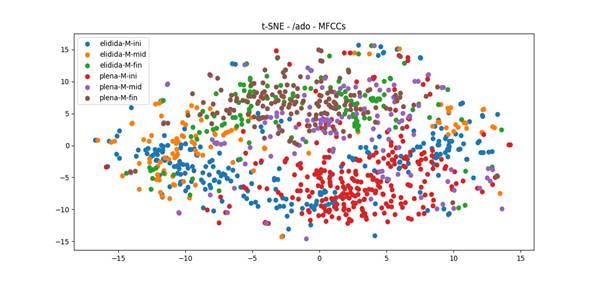
En relación con los coeficientes cepstrales, la técnica mostró en el caso de las mujeres, Figura 2, que las características acústicas de la [ˈa] (inicio del segmento, 40 %) tienden a agruparse (rojo y azul en la parte baja de la figura). También, las características acústicas de [o] (segmento final, 40 %) muestran un mayor agrupamiento (verde y café en la parte superior de la figura). En relación con las características acústicas de la aproximante (mitad del segmento, 20 %) debería haberse manifestado una agrupación diferencial (puntos morados). Sin embargo, las características del segmento tienden a agruparse con las de [o] (verde y café). En este sentido, podríamos advertir, para el caso de las voces femeninas, que la aproximante comparte más características acústicas con la vocal adyacente posterior átona [o]. En cuanto a la elidida (segmento medial del grupo de las elididas, en naranja), se acerca más a la producción de [ˈa]; es decir, en ese 20 % medial del segmento [-ˈao], se producen más las características acústicas del inicio del segmento, [ˈa] (azul a la izquierda de la Figura 2). Este resultado fue esperable, dada la acentuación de la vocal central, que probablemente le imprime más cantidad o tiempo al segmento silábico.
En el caso de las voces masculinas, Figura 3, los resultados fueron diferentes. La única tendencia de agrupación está en los segmentos finales (café y verde en la parte baja de la figura); es decir, los segmentos manifiestan compartir características acústicas de [o].
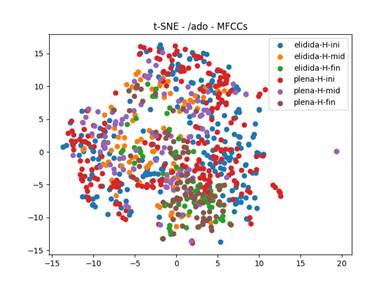
Sin embargo, la Figura 3 también determinó que no hubo diferencia, o no se halló una tendencia de agrupamiento de características acústicas entre los segmentos iniciales y mediales de [ˈað̞o] y [ˈao] en los enunciados masculinos. La casi total indiferenciación del segmento medial del grupo de realizaciones cuidadas, con atención a la pronunciación de aproximantes, establece que lo más probable es que se trató de una realización aproximante vocálica.
En términos de representación gráfica más cercana a esta tradición lingüística, se recurrió a la espectrografía de las muestras a través de Praat (Boersma y Weenink, 2009). La aproximación espectrográfica a las 108 muestras de la secuencia [ˈado] de la prueba experimental evidenció la dificultad de la segmentación, especialmente para las muestras que se grabaron y clasificaron como aproximantes. La Figura 4 es un ejemplo de la realización del enunciado de la prueba por un hablante masculino.
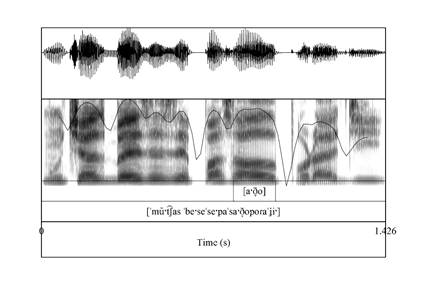
Se puede observar que para la pronunciación percibida y realizada como [ˈað̞o] es muy difícil mostrar una segmentación definida o relacionar la aproximante con diferencias de intensidad relativa, pues no hay un descenso marcado de la línea de intensidad, ni hay diferencias en la estructura formántica y en variabilidad transicional. Esto llevó a considerar que la aproximante, en contexto [ˈað̞o] del habla de Medellín, se puede determinar fonéticamente como un proceso de vocalización o en términos de una variable aproximante vocálica.
Otro tanto sucede con las realizaciones que se grabaron a partir de la instrucción de elidir /d̪/ en el segmento [ˈað̞o]. En la Figura 5, realización femenina de la variante elidida, se percibe claramente la elisión de la aproximante a través de las transiciones frecuenciales de los formantes de [ˈa] y [o].
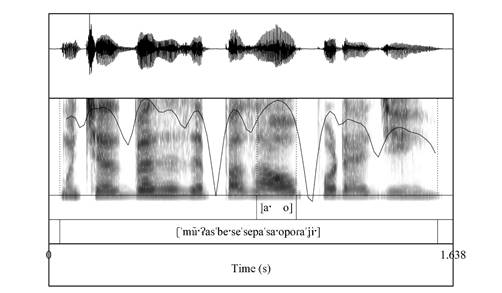
De esta manera, se evidencia cómo ni la disminución de intensidad relativa ni la estructura formántica, en este caso, puede considerarse un parámetro que permita distinguir aproximantes abiertas o cerradas. Por tanto, en este corpus -ado de jóvenes de Medellín se está ante una aproximante vocálica que, aunque se percibe, es difícil determinar sus límites de adyacencia con las vocales [ˈa] y [o].
APLICACIÓN DEL PROTOCOLO DE IDENTIFICACIÓN AL CORPUS PRESEEA-MEDELLÍN
Una vez establecido el protocolo de identificación automática, se emprendió la tarea de aplicar el protocolo al Corpus Preseea-Medellín (González-Rátiva, 2008), corpus oral por cuotas de afijación uniforme preestratificado16 y posestratificado17 de acuerdo con los parámetros del PRESEEA (Moreno-Fernández, 1996).
Se tomó una muestra del Corpus Preseea-Medellín compuesta por 36 informantes. Para la sistematización de variantes se identificaron cada una de las apariciones de [ˈað̞o] en las transliteraciones etiquetadas y se extrajeron, por medio del programa Audacity, 1644 segmentos de audio en contexto. Posteriormente se segmentaron, excluyendo del contexto, los 1644 segmentos [ˈað̞o] para ser clasificados perceptualmente en tres carpetas según la variante: aproximante abierta, aproximante vocálica, y variante elidida, de acuerdo con la percepción cualificada del grupo del Laboratorio.
Las entrevistas semidirigidas del Preseea-Medellín fueron hechas entre los años 2008 y 2010; la mayoría de ellas, bajo condiciones ambientales de calle, locaciones públicas y viviendas de los informantes. En la construcción de este Corpus hubo un amplio número de entrevistadores. Las grabaciones fueron hechas por medio de aparatos digitales (Sony icd px240). La mayoría de los audios se registraron en formato .wav, y algunas de ellas, quedaron como archivos en formato .mp3.
Debido a algunas o todas las razones expuestas, el subcorpus -ado, contiene una heterogeneidad de condiciones de grabación, además de la baja calidad de muchas de las grabaciones, que imposibilitan un estudio fonético-fonológico de buena fiabilidad. También es importante anotar que el habla espontánea de este Corpus Preseea-Medellín presenta enunciados con muy poca intensidad, sin muestra de sonoridad, rasgos de aspiración al final que, aunque inteligibles, son de extrema complejidad para la segmentación.
Todas esas características no aseguran condiciones acústicas homogéneas para el análisis automatizado, de acuerdo con los ingenieros del Grupo GITA. Los resultados mostraron una gran cantidad de diferencias, empezando por las condiciones acústicas de las grabaciones del corpus, por ejemplo, en la frecuencia del muestreo. Por ello, al encontrar audios en frecuencias de muestreo de 16000 Hz., 44100 y 48000 Hz, se decidió para el caso de esta investigación, y por las condiciones de las grabaciones, la estandarización a una frecuencia de 8000 Hz. Una vez se reagruparon los audios estandarizados, se procedió al protocolo de automatización.
Como un primer acercamiento a la automatización, se optó por realizar un análisis en dos informantes por separado (un hombre y una mujer) para determinar el rendimiento de los MFCCs en el habla espontánea. La Figura 6 corresponde a los segmentos -ado de una mujer de primera generación, con nivel alto de estudios.
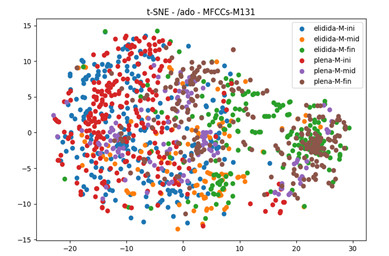
En la Figura 6 se observa un comportamiento de los MFCCs de toda la producción de segmentos [ˈado] de la informante MEDE_M13_1, en su caso, 38 segmentos. Al igual que en la Figura 2 (mujeres en la prueba experimental), se observa una leve tendencia de agrupación para [ˈa] (puntos azules y rojos). En relación con la aproximante (puntos anaranjados y morados) se percibe una ligera separación, más notoria hacia la parte final del segmento [o] (cafés y verdes) y una leve agrupación hacia la parte inicial del segmento [ˈa] (azul y rojo). Estas tendencias podrían seguir indicándonos la similitud de los parámetros acústicos relacionados con la energía que hay entre vocales y aproximantes en esta variedad de habla.
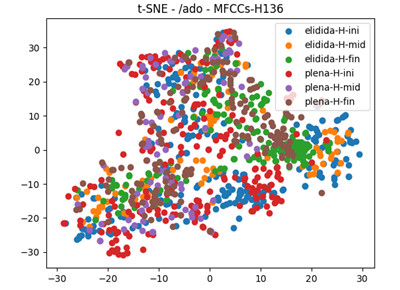
La Figura 7, para el caso de un hombre de primera generación y nivel alto de estudios (con 47 segmentos -ado, no permite una buena apreciación de agrupaciones salvo alguna parte final (cafes y verdes), correspondiente nuevamente con la finalización vocálica del segmento, [o]. Se puede decir, que en los dos casos graficados no se encontró en su análisis automatizado de parámetros acústicos de energía, indicios de separación o agrupación de características que reflejaran distancia acústica perceptible.
A pesar de que en la prueba experimental y en el análisis de los dos informantes del Preseea-Medellín no hubo rendimiento para una posible identificación de la variante aproximante [ð̞] diferencial de las vocales adyacentes en su energía, se realizó un análisis con todos los informantes (36) en sus 1644 realizaciones de segmentos [-ˈað̞o]. Se tomó como base la clasificación perceptual de los segmentos, divididos en las tres carpetas: aproximante plena, aproximante relajada y variante elidida. En esta ocasión, el análisis se centró en los Formantes 1 y 2 del segmento [-ˈað̞o], asumiendo la transicionalidad que debe presentarse, bien en la aproximante vocálica, bien en el caso de la elisión. El resultado del análisis se observa en la Figura 8.
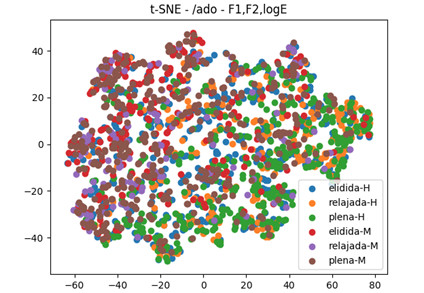
En la Figura 8 se observa un ligero agrupamiento entre la aproximante plena y la relajada femenina (café y morado) e igualmente plena y relajada masculina (verde y naranja). Este resultado permite en parte acercarse a la caracterización de una aproximante vocálica para las realizaciones perceptualmente audibles. En cuanto a la elisión de hombres (puntos azules) y la elisión de mujeres (puntos rojos) se presenta la mayor dispersión, por lo que no se encuentra una posible relación para este resultado.
DISCUSIÓN
Los resultados del experimento permiten realizar solo un contraste general con los antecedentes aquí expuestos, ya que se trata tanto de metodologías como de procedimientos de análisis diferentes. Hay aspectos que coincidieron en el desarrollo de las investigaciones. El procedimiento perceptual del fenómeno seguido por Pérez (2007) y la corroboración espectrográfica para cada segmento, si bien es un método impresionístico, se estableció, como en el caso presentado para el pilotaje, en un parámetro de gran importancia para la determinación de la naturaleza acústica de la aproximante. Incluso, el resultado de la automatización rindió mejores resultados a través de análisis de los MFCCs que son coeficientes basados en la percepción auditiva humana.
En relación con los parámetros acústicos, fueron coincidentes de los trabajos revisados y este estudio, medidas acerca de la energía, F1 y F2, armonicidad, pitch, velocidad, transiciones de vocales adyacentes; no se mencionan en el trabajo de Figueroa (2012) los coeficientes cepstrales en las frecuencias de Mel (MFCC), pero es muy probable que entre 62 procedimientos se hubiera incluido esa magnitud de medida y otros cálculos matemáticos y estadísticos.
La caracterización acústica de la aproximante mostró diferencias entre las variables de habla analizadas: para el español de Chile, Pérez (2007) reportó una aproximante cerrada; Sola (2011) para el español ibérico no obtuvo rendimiento de la aproximante ‘fundida’, sino la presencia de una aproximante con formantes de menor intensidad, abierta. Los resultados de esta investigación establecen, para la variedad antioqueña, una aproximante vocálica percibida, pero de difícil segmentación, en habla controlada, aún más en habla espontánea.
CONCLUSIONES
A partir de la prueba experimental de la variación de la /d̪/ intervocálica en el habla de seis estudiantes de Medellín, y el acercamiento automatizado para la identificación de variantes, se pueden presentar, a modo de conclusión, algunas consideraciones al respecto.
En primer lugar, el fenómeno de variación de la /d̪/ intervocálica, especialmente en el contexto favorecedor -ado en el habla de Medellín, aunque perceptible, es un fenómeno que presenta escasa visibilidad espectrográfica y, por lo tanto, reviste de complejidad acústica para su medición. El acercamiento a través de la parametrización y automatización de las características acústicas de este fenómeno de espirantización, debilitamiento o aproximación es fundamental en la medida en que podría optimizar los recursos de investigación.
La propuesta de experimentación permitió tener un buen control sobre los datos de estudio, características de las que carecen algunos corpus orales. En consecuencia, el procedimiento seguido por el GITA, ingenieros de telecomunicaciones, consistente en la programación de tareas automatizadas para la extracción y tratamiento de datos es menos complejo para el lingüista, debido a la posibilidad de extraer datos variables y graficarlos en posibles patrones de comportamiento. Sin embargo, es necesario: a) actualizar constantemente los parámetros acústicos utilizados, b) cerciorarse de que los datos recogidos son homogéneos y comparables. El procedimiento es replicable, tal como aquí se hizo del pilotaje al Corpus Preseea-Medellín, pero las características de grabación, edición y manipulación de los datos no permitieron obtener buen rendimiento en el análisis.
El seguimiento del procedimiento de automatización aquí presentado, en cambio, permitió mostrar que en el habla de la ciudad de Medellín la variante aproximante de la /d̪/ en contexto -ado es la aproximante vocálica, en términos de Martínez Celdrán (2013). Los parámetros espectrográficos mostraron que la energía vocálica del segmento, su potencia, no se aleja de aquella de las vocales adyacentes. En este sentido, aunque hay unas ligeras y muy superficiales tendencias de agrupamiento, lo que se mostró en las figuras y en los espectrogramas es la presencia constante durante todo el segmento de la energía vocálica. Se presentó una aproximante vocálica con espectro formántico en transición de una vocal a otra, sin disminución notoria de su ennegrecimiento ni valles notorios en su curva de intensidad que posibilitara una segmentación precisa y diferencial con las vocales adyacentes. Todo ello permitió confirmar la presencia del fenómeno de vocalización de la /d̪/ en el segmento -ado y la poca distinción entre los segmentos medios de la aproximante y la elisión. Si bien hay una sola propuesta de transcripción para la variedad de posibilidades fonéticas que tiene una aproximante como [ð̞] en el ámbito hispánico, la caracterización como vocálica o su denominación como vocalizada no se corresponde con la simbología AFI utilizada. Queda abierta la discusión sobre una transcripción adecuada para esta variante.
Es importante concluir con una reflexión en torno a la planeación de corpus orales. Para poder realizar un proceso de automatización, posible y viable en términos de estudios actuales de la señal acústica, se requiere y es indispensable que se logren grabaciones de óptimas condiciones, especialmente en lo relacionado con la homogenización de parámetros y requerimientos de la grabación. Este paso metodológico reviste toda la importancia, más aún hoy en día que se cuenta con posibilidades amplias de etiquetado y automatización de corpus orales de gran robustez.
Se puede afirmar también que la automatización realizada, y la base de datos ya elaborada sobre el corpus Preseea-Medellín, posibilita seguir indagando y realizando pruebas que permitan acercarse cada vez más a la comprensión de un fenómeno tan complejo como el menor grado de constricción en la realización de las consonantes aproximantes del español.

