











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCCIÓN
La investigación lingüística usando corpus computacional de aprendices ha revolucionado el estudio de la adquisición de lenguas extranjeras, ya que permite realizar análisis a gran escala que serían imposibles de llevar a cabo manualmente. Los avances en el campo de las tecnologías de la información (TIC) han convertido a la Linguística de Corpus (LC) en una metodología conveniente y moderna para recolectar textos auténticos representativos de una lengua o una variedad de ésta. Todos sus procedimientos exploran y describen un idioma de manera objetiva y no como una especulación subjetiva.
Aunque existe una gran cantidad de investigación en este campo, la mayor parte se ha producido en Europa. El Corpus Internacional de Aprendices de Inglés (ICLE) iniciado por Virtanen (1996) tiene una gran compilación de corpus de estudiantes de inglés con diferentes lenguas maternas que incluye hablantes nativos del español predominantemente de la península ibérica. Adicionalmente, la revista científica de la Asociación Española de Corpus Lingüístico (AELINCO), Research in Corpus Linguistics (RiCL), reporta principalmente investigaciones con corpus de aprendices en toda Europa y España (Berglind, 2017; Carrió y Mestre, 2013; Crespo, 2016; Hernández, 2013; Szabó, 2013, entre otros). Existen también los estudios realizados con el corpus CREA (Benavides, 2014). Sin embargo, análisis estadísticos de estudiantes de inglés como lengua extranjera (ILE) usando corpus de aprendices con el fin de establecer el desarrollo de la competencia comunicativa en esa lengua son escasos y con pocos informantes. Adicionalmente, es aún menor el número de estudios usando corpus de aprendices computacional. En Puerto Rico, Morales-Reyes y Gómez (2016) reportaron resultados con treinta informantes; en Argentina, Sánchez et al. (2016) reportaron resultados de veinticuatro informantes; en Colombia, Londoño (2008) reportó resultados de un informante.
La falta de análisis estadísticos en corpus computacionales de aprendices, que indaguen la incidencia de los errores escritos con el fin de entender las etapas en el aprendizaje del ILE en Colombia y en América Latina hacen que este estudio sea un acierto para la región. La presente investigación se llevó a cabo en una institución de formación universitaria. El objetivo de este artículo es presentar el análisis estadístico de los datos (realizado a través de SPSS, versión estadística 25) para establecer si existe una relación entre los errores escritos más recurrentes de estudiantes de ILE y dos factores sociodemográficos: el género y el estrato social. La presente investigación se ciñe a la definición de error lingüístico como una desviación de la norma del idioma de destino Corder (1981). El presente artículo se propone responder a la siguiente pregunta: ¿son el género y el estrato social factores determinantes en la cantidad y tipo de errores en la producción escrita del inglés como lengua extranjera a nivel universitario?
Sobre la base de esta pregunta de investigación, y una búsqueda exploratoria de diferentes teorías sobre género (Aliakbari y Mahjub, 2010; Babayiğit, 2015; Durán, 2006; Lakoff, 2003; Romaine, 2003) y teorías sobre estrato social (Arikan, 2011; Bernstein, 1971; Bourdieu, 1997; Morales, 2017; Vandrick, 1995), se formularon las siguientes hipótesis:
a. Los hombres y las mujeres presentan diferencias estadísticamente significativas en la mediana de errores de las composiciones escritas del inglés como lengua extranjera a nivel universitario.
b. Existen diferencias estadísticamente significativas en la mediana de errores de las composiciones escritas del inglés como lengua extranjera a nivel universitario en relación con el estrato socioeconómico de Colombia (Departamento Administrativo Nacional de Estadística [DANE], s.f.).
El presente artículo presenta un resumen de las principales teorías sobre corpus de aprendices y el análisis de errores. Seguidamente, se abordará la literatura relacionada con la incidencia de los factores sociodemográficos en la producción del inglés como lengua extranjera (ILE). Finalmente, se explica el proceso seguido en el análisis estadístico y se presenta una visión general del total de los errores. Los datos analizados en el presente artículo fueron recolectados durante el desarrollo de una tesis doctoral (Pardo, 2019).
MARCO TEÓRICO
Corpus de aprendices
Los corpus de aprendices son colecciones electrónicas de datos naturales o casi naturales producidos por estudiantes extranjeros o de un segundo idioma (L2) y reunidos de acuerdo con criterios de diseño explícitos (Granger et al., 2015). Los corpus de aprendices pueden contener producción escrita u oral en formato electrónico o multimodal para ser analizados. Todos los datos de los corpus de aprendices contienen colecciones auténticas de producción del lenguaje contextualizado de estudiantes de adquisición de una segunda lengua o de una lengua extranjera en formato electrónico. El auge de los corpus de aprendices a finales de los años 80 fue debido en parte a su potencial para investigar la producción propia de los estudiantes. Esta útil metodología permite a los investigadores el accceso a grandes cantidades de datos para investigar colocaciones, patrones de la lengua, hacer análisis de la interlengua de los estudiantes y obtener estadísticas del uso de la lengua.
De acuerdo a Gilquin (2015) un corpus de aprendices se puede diferenciar de otros tipos de corpus en que:
1. Los datos son el resultado de la producción oral o escrita de los aprendices.
2. Los datos provienen de textos escritos, transcripciones de discursos o material multimodal.
3. Puede incluir la combinación de varios géneros de texto (cartas, ensayos, etc.).
4. Es representativo de un idioma de destino (en este caso, inglés como idioma extranjero).
5. Establece la lengua materna de los alumnos y la fecha de compilación (una o varias muestras).
6. Tiene un propósito claro relacionado con el estudio de lenguas o pedagógico.
En la construcción de un corpus de aprendices es importante tener en cuenta las variables del alumno. Éstas se refieren a aspectos individuales del estudiante tales como la edad, el género, el país / zona de origen, la lengua materna. Otras variables que pueden tener incidencia y son específicas y relevantes para el entorno de los alumnos son el idioma materno de los padres, los idiomas que se hablan en el hogar, el nivel de competencia de los alumnos, la exposición al idioma de destino (cuánto tiempo ha estudiado el idioma de destino el alumno), el contacto con el idioma de destino en las actividades normales y la estancia en los países del idioma de destino (Gilquin, 2015).
Análisis de Errores
El análisis de errores (AE) es una metodología usada para analizar los errores de los estudiantes. Es el proceso de determinar la incidencia, naturaleza, causas y consecuencias del lenguaje fallido (James, 1998). Se hace uso de etiquetas para identificar errores de acuerdo con varias categorías y tipos.
El análisis de errores (EA) apareció a principios de la década de 1970 como una alternativa al análisis contrastivo y se convirtió en la metodología preferida para analizar la producción de los estudiantes de lengua. Se convirtió en la respuesta para superar los vacíos dejados por el análisis contrastivo, que había dejado dudas sobre el origen de los errores. Los siguientes propuestos por Corder (1981) fueron los pasos seguidos en el análisis de errores del presente corpus.
a. Reconocimiento y reconstrucción de los errores.
b. Descripción de los errores (proceso de etiquetado).
c. Explicación de los errores (James, 1998).
Reconocimiento y reconstrucción de los errores
Esta primera etapa se refiere a dos procesos diferentes: primero, la identificación de errores, que es el reconocimiento de su existencia. Es dar cuenta de su presencia, en este caso, en un texto escrito. Después de detectar un error, el siguiente paso es identificar su ubicación exacta. Estas acciones deben realizarse por referencia al idioma de destino. El segundo proceso es la reconstrucción del error, que implica probar hipótesis sobre lo que el alumno trató de decir. En algunos casos, podría haber varias hipótesis, ya que algunos errores se superponen a categorías y tipos.
Descripción de los errores (proceso de etiquetado)
Se refiere a la caracterización de los errores como pertenecientes a una variedad de un tipo. Este procedimiento se realiza por medio de la anotación. La anotación del corpus es la práctica de agregar información interpretativa y lingüística a un corpus electrónico de datos de lenguaje hablado y / o escrito (Leech, 2005). El presente corpus tiene anotaciones de errores para obtener análisis estadísticos y cruce de variables por género y estrato socioeconómico. Por medio de este sistema de anotación se clasifican los errores describiéndolos por la categoría lingüística y tipo de error.
De acuerdo con James (1998), hay tres propósitos para describir errores, el primero es hacer explícito lo que podría ser tácito; en otras palabras, debemos justificar nuestras intuiciones sobre los errores que sólo toman forma cuando los etiquetamos como errores. El segundo es asegurarnos de contarlos, para que podamos obtener estadísticas de los tipos de error. El tercero es crear categorías que faciliten su estudio.
Explicación de los errores (James, 1998)
Finalmente, esta etapa se refiere a la interpretación de los sistemas que están detrás de esos errores. En esta etapa, los errores reciben una explicación teniendo en cuenta sus posibles fuentes. También se hace una explicación de los posibles procesos subyacentes a las etapas de aprendizaje.
Literatura sobre género y estrato social
Dado que el presente artículo informa las estadísticas de dos hipótesis relacionadas con la influencia del género y los estratos socioeconómicos en el aprendizaje del ILE, se presentará una breve reseña de la literatura sobre estas dos variables.
Es necesario definir el uso de los términos género y sexo. Por un lado, el género no es algo con lo que nacemos, y no es algo que tenemos, sino algo que hacemos (Eckert y McConnell-Ginet, 2003). Por otro lado, el sexo es una categorización biológica basada principalmente en el potencial reproductivo, mientras que el género es la elaboración social del sexo biológico (Eckert y McConnell-Ginet, 2003).
Varios estudios realizados para descubrir el impacto del género en la adquisición de una segunda lengua han señalado posibles diferencias de aprendizaje relacionadas con el género (Durán, 2006; Lakoff, 2003; Romaine, 2003). Se cree que existe una relación entre el género de un individuo y algunas características del lenguaje, por ejemplo los hombres usan más sustantivos que tienen que ver con ciertas actividades sociales y económicas relacionadas con un tema, mientras que las mujeres tienden a enfocarse en las personas involucradas en dichos temas (Ishikawa, 2015).
Por otra parte, Aliakbari y Mahjub (2010) investigaron las diferencias analíticas e intuitivas en los estudiantes de inglés como lengua extranjera basados en el efecto de género. Sus hallazgos dieron a conocer que los hombres adoptan un enfoque más analítico, mientras que las mujeres adoptan un enfoque más intuitivo. Saeed et al. (2011) aseguran que existe un mejor desempeño de las mujeres en el aprendizaje de idiomas. Los mencionados autores afirman que las mujeres cometieron menos errores de escritura en la segunda lengua en comparación con los estudiantes varones. Los autores concluyen que las mujeres pueden considerarse mejores estudiantes de idiomas que los hombres.
Finalmente, Babayiğit (2015) informa de un efecto significativo del género a favor de las niñas. Según el autor, las mujeres obtuvieron mejores resultados en todas las dimensiones de la expresión escrita, excepto en la organización. En resumen, los autores mencionados anteriormente encuentran diferencias que favorecen el rendimiento de las mujeres estudiantes de ILE. Éstos concluyen que las mujeres son mejores aprendices de lengua que los hombres.
La segunda hipótesis se refiere a las diferencias estadísticamente significativas en la mediana de errores de las composiciones escritas de un idioma extranjero en relación con el estrato socioeconómico. El estrato socioeconómico se refiere a un sistema de clasificación de personas por categorías jerárquicas. En Colombia, la estratificación socioeconómica es una clasificación de los bienes raíces residenciales que reciben los servicios públicos. Se realiza principalmente para cobrar diferencialmente los servicios públicos domiciliarios y asignar subsidios para recaudar contribuciones. De esta manera, quienes tienen más capacidad económica pagan más por los servicios públicos y contribuyen para que los estratos más bajos puedan pagar sus facturas (DANE, s.f.) . Por lo tanto, cuanto mayor sea el estrato, mayor será el poder y la riqueza en comparación con otros grupos. Esta clasificación implica un examen de cómo las personas se ubican a sí mismas y a los demás en la estructura social de desigualdad.
Diferentes estudios aseguran que existe un impacto del estrato social en la educación. Arikan (2011), Bernstein (1971), Bourdieu (1997), Morales (2017) y Vandrick (1995) han examinado la relación entre la clase social, la familia y la reproducción de los diferentes significados. Bernstein (1971) elaboró códigos sobre los principios que regulan los sistemas de significados concluyendo que existen diferencias en los códigos de comunicación de la clase trabajadora y la clase media. Estas diferencias en los códigos de comunicación reflejan diferencias en las relaciones de poder. Además los autores muestran cómo las escuelas reproducen las diferencias de clase en tanto que los maestros ven a los estudiantes de acuerdo con esas clasificaciones que privilegian a los estudiantes de clase alta. En el aprendizaje de ILE, los estudiantes privilegiados de un estrato social más alto tienen más oportunidades de viajar al extranjero y practicar el idioma inglés aprendido en clase. Este hecho podría influir en sus resultados finales al aprender un idioma extranjero.
Vandrick (1995) sostiene que el estatus de clase social podría afectar las experiencias que viven los aprendices y, por lo tanto, los resultados de los educandos de una clase privilegiada serían más acordes con las reglas de producción de la lengua extranjera. Los alumnos internacionales privilegiados “retornarán a sus países y tomarán posiciones de poder riqueza e influencia. Éstos dan su privilegio por sentado como lo hace la gente privilegiada”1 Vandrick (1995, p. 375). De acuerdo con Lin (1999) es necesario persuadir a los educadores para que comprendan las consecuencias que conllevan las diferencias de clase social y que juegan un papel en las escuelas. El autor afirma que los estudiantes de clase media traen consigo el tipo de hábito correcto, es decir, el capital cultural (Bourdieu, 1997), tienen las "actitudes e intereses correctos y las habilidades lingüísticas correctas"2 (Lin, 1999, p. 407). Las reglas son "establecidas por las clases privilegiadas"3 (Lin, 1999, p. 410) y son percibidas como legítimas por toda la comunidad educativa profesores, estudiantes, diseñadores de currículo, etc. El aula de clase se transforma así en un sitio clave de producción cultural para tener éxito no sólo en la escuela sino también en la sociedad. En el escenario actual de esta investigación, los estudiantes que pueden permitirse viajar por diversión o tomar un curso corto en el extranjero probablemente aumentarán sus habilidades en el idioma extranjero. Si además tienen la posibilidad de estudiar en un colegio bilingue, donde tienen más intensidad horaria en los cursos de lengua extranjera, entonces, se esperaría que tengan más éxito en el aprendizaje del inglés.
Esta investigación se llevó a cabo con base en las teorías de género y estrato social en relación con el rendimiento escrito del ILE, además de lo anterior, se siguió la especulación intuitiva basada en la experiencia en el campo de la enseñanza de lenguas.
METODOLOGÍA
La presente investigación descriptiva, no experimental, es un estudio transversal con datos recopilados en el segundo semestre de 2015 en una institución educativa de nivel universitario. Para la caracterización de la población se diseñó un instrumento -encuesta- evaluado y aprobado por expertos con el fin de establecer el perfil de los aprendices siguiendo los lineamientos y las teorías sobre la elaboración de corpus de aprendices y con el fin de conocer los aspectos socioculturales relevantes que podrían afectar el desempeño de los estudiantes en la lengua extranjera. La encuesta estaba dividida en tres partes: parte uno: buscaba establecer el perfil de los estudiantes en aspectos como la edad, el estrato social, el género. La parte dos buscaba establecer el perfil académico de los estudiantes y la parte tres buscaba establecer los aspectos socioculturales y las creencias que pueden tener incidencia en la producción del inglés como lengua extranjera (para mayor información, se sugiere revisar el Anexo 1). Los siguientes pasos guiaron el proceso del desarrollo del corpus:
1. Recoleción de datos
2. Anotación del corpus
3. Descripción de los errores
4. Extracción de los errores
5. Verificación o prueba de las hipótesis
Recolección de datos
La recolección de los datos se llevó a cabo utilizando técnicas para sucitar respuestas por medio de instrumentos diseñados por la institución universitaria. En el caso del nivel B1 los estudiantes debían responder por escrito una pregunta de opinión sobre un tema de interés general. Para el caso de los estudiantes de nivel B2, los estudiantes debían escribir un ensayo de comparación y contraste (para mayor información, el Anexo 3 muestra los instrumentos que contienen los detalles y requerimientos del proceso de escritura).
Independientemente de la forma de compilación, los textos de un corpus de aprendices no se producen de forma estrictamente natural, porque se producen en el contexto del aula y son el resultado de actividades diseñadas para mejorar las habilidades de los alumnos en el idioma de destino. Los estudiantes participantes en ambos niveles, B1 y B2, pudieron elegir sus propias palabras y estructuras gramaticales para expresar las opiniones en sus composiciones. Teniendo en cuenta que la presente investigación se centra en un corpus escrito, a partir de un estudio transversal, la descripción se centrará en sus principales características.
En cuanto a las citas textuales encontradas en los ensayos de los estudiantes, se debe prestar atención porque no pertenecen a la producción de los alumnos. Se recomienda "eliminar las citas (que no representan el uso del lenguaje por parte del alumno y, por lo tanto, pueden tener que excluirse del análisis del corpus)"4 (Gilquin, 2015, p. 19). En el presente trabajo, las citas no se eliminaron para evitar errores en todo el contexto y porque en algunos casos, eliminar las citas significaría perder partes fundamentales del texto indispensables para comprender el contexto. Por lo contrario se mantuvieron, pero se prestó mucha atención para no analizar esas partes. Por otro lado, luego de la transcripción de los textos escritos a mano en formato MS Word, todos los archivos fueron transcritos en formato TXT para el etiquetado de errores.
La presente investigación centró su análisis en los niveles B1 a B2. La población la conformaban 2088 estudiantes universitarios de pregrado de los cuales, 515 estudiantes firmaron el consentimiento para participar en esta investigación. El proceso de escritura se desarrolló durante un curso de 64 horas impartidas en un semestre de 16 semanas. Todos los cursos se desarrollaron como clase-seminarios en los que los estudiantes pudieron entregar sus borradores preliminares para correcciones y luego recibieron comentarios. En los niveles B1, los estudiantes entregaron sus borradores y el trabajo final escrito a mano y posteriormente transcrito a formato MS Word para el correspondiente análisis. En el nivel B2, los borradores y el trabajo final se entregaron en archivos de MS Word, pero los estudiantes no contaban con la opción de correctores automáticos de procesador de textos, que fueron desactivados en el laboratorio de la universidad. Los estudiantes elaboraron los escritos finales analizados en esta investigación durante una clase de dos horas. El corpus compilado de estos estudiantes tenía 149 325 tokens, 12 164 tipos y 12 337 lemas. La Tabla 1 presenta la distribución de estudiantes de acuerdo con los niveles del MCER (Council of Europe, 2001).
Tabla 1 Distribución de los estudiantes de acuerdo a los niveles del MCER
| Nivel Intro | Nivel | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| U. Niveles | 1 | 2 | 3 | 4 | 5y6 | 7y8 | |||
| Pre-intermedio | Inter-medio | Intermedio II | Intermedio alto | ||||||
| Nivel MCER | 1.1 | 2.1 | 2.2 | B1 | B1 | B1 | B2 | B2 | B2 |
| #Alumnos | 10 | 496 | 439 | 409 | 325 | 356 | 377 | 335 | 286 |
En la Tabla 1, se observa desde el nivel 1 hasta el nivel 8 y su equivalente de acuerdo al Marco Común Europeo de Referencia (Council of Europe, 2001). Los niveles sombreados (3-8) son los niveles que participaron en este estudio y el número de estudiantes registrados en cada caso. Como se indicó anteriormente, en total 515 estudiantes de los niveles B1 a B2 participaron en este estudio. La Tabla 2 muestra la distribución de estudiantes por niveles de acuerdo al género.
Tabla 2 Distribución de los estudiantes por género y nivel
| Nivel B1 | # de estudiantes hombres | # de estudiantes mujeres |
|---|---|---|
| B1 (pre-intermedio) | 104 | 135 |
| B1 (intermedio) | 70 | 74 |
| B1 -B2 (Intermedio II) | 8 | 9 |
| Totales B1 | 182 | 218 |
| Total de hombres y mujeres en B1 | 400 | |
| NO REPORTARON GÉNERO B1 | 3 | |
| Nivel B2 | # número de hombres | # número de mujeres |
| B2 (Intermedio alto) | 56 | 56 |
| Total hombres y mujeres B2 | 112 | |
| Total en corpus B1 y B2 | 515 |
Los datos muestran un corpus equilibrado con una distribución balanceada de estudiantes por cada género en los niveles B1 y B2. La Tabla 3 muestra los detalles de distribución de acuerdo con el estrato socioeconómico. Se les solicitó a los estudiantes participantes que informaran sus estratos de forma voluntaria, pero la mayoría de los estudiantes de nivel B1 no lo hicieron.
Anotación del corpus
La anotación de errores se realizó de acuerdo con el Manual de etiquetado de errores de la Universidad de Lovaina versión 1.2 (Dagneaux et al., 2005). El manual distingue entre ocho categorías de error y éstas se dividen en subcategorías para un total de 56 etiquetas de error. En cada caso, la primera letra de la etiqueta muestra la categoría de error. La Tabla 4 presenta las categorías utilizadas en este estudio. Cada categoría de error representa varios tipos de error. Para más detalles se puede consultar el Anexo 2.
Tabla 4 Categorías de error con sus correspondientes etiquetas
| Categorías | Código. (Letra que representa la categoría de error) |
|---|---|
| 1. Errores de forma. | F |
| 2. Errores gramaticales (aquellos que rompen las reglas generales de la gramática inglesa). | G |
| 3. Errores léxico-gramaticales (aquellos en los que se han violado las propiedades morfosintácticas de una palabra). | X |
| 4. Errores de léxico (aquellos que involucran las propiedades semánticas de palabras simples y de frases). | L |
| 5. Errores en las palabras (Palabra redundante, Palabra faltante y orden de palabras). | W |
| 6. Errores de puntuación. | Q |
| 7. Errores de estilo. | S |
| 8. Infelicidades (es lenguaje no-erróneo, pero que suena extraño o inapropiado en el contexto en que es emitido). | Z |
Fuente: Extraído de (Dagneaux et al., 2005)
Descripción de los errores
La descripción de los errores se hizo según la categoría y de acuerdo con el Manual de Etiquetado de Errores de la Universidad de Lovaina, versión 1.2, que describe el nivel lingüístico y el tipo de error (Dagneaux et al., 2005). En la Tabla 5 se presentan algunos ejemplos del corpus5 CLEC.
Tabla 5 Ejemplos del corpus
| (1). 4464 | the problems associated with (GA) the $0$ chemotherapy are |
| (2). 4465 | iversities, etc. According to (GA) 0 $the$ Universal Declara |
| (3). 4466 | auty is biased; the status of (GA)0 $an$ artist offers many |
| (4). 4467 | ything reason$0$, because all (GA) the $0$ people (GVAUX) ca |
| (5). 4468 | re chance to be welcomed than (GA) 0 $the$ artist that works |
| (6). 4469 | and our city is (LS) no $not$ (GA) 0 $an$ exception. So, if t |
Fuente: Pardo et al. (2018)
Los ejemplos anteriores muestran cómo se identifican los errores con la etiqueta entre paréntesis que, en estos ejemplos, se refieren a errores en el uso del artículo en inglés (GA). La corrección se produce después del error entre dos signos de dólar. Todos los errores se anotaron manualmente y luego, utilizando el software de extracción, se colocaron en listas por tipo de error para obtener las estadísticas. Se contabilizó un total de 14 631 errores distribuidos en las ocho categorías.
Extracción de los errores
La extracción es un proceso de recuperación de datos específicos, en este caso, etiquetas de error con un contexto que permite un análisis adecuado. La extracción se realizó con WordSmith Scott (2005). Este software permite la búsqueda de patrones de lengua y proporciona estadísticas de todo el corpus. Para la extracción de datos parciales se utilizó LancsBox (Brezina et al, 2015). Este sofware permite la búsqueda de patrones de lengua y permite obtener gráficas y estadísticas parciales.
Verificación o prueba de las hipótesis
El propósito de esta investigación es establecer la posible relación entre los principales errores encontrados en las composiciones escritas de estudiantes universitarios de inglés como lengua extranjera (ILE) y los factores socioeconómicos género y estrato que podrían tener incidencia en los resultados. El análisis estadístico se realizó enfocándose en las siguientes hipótesis:
a. Existe incidencia estadísticamente significativa entre hombres y mujeres en la mediana de los errores de la producción escrita del inglés como lengua extranjera (ILE) a nivel universitario.
b. Existen diferencias estadísticamente significativas en la mediana de los errores de la producción escrita de estudiantes universitarios de ILE en relación con el estrato socioeconómico de los estudiantes.
RESULTADOS Y DISCUSIÓN
Se analizó si la variable cuantitativa de errores sigue una distribución de probabilidad normal para determinar qué tipo de prueba debía usarse para aceptar o rechazar la hipótesis nula de cada situación previa. La Tabla 6 presenta los resultados de dos pruebas de normalidad para la variable errores, Kolmogorov-Smirnov y Shapiro-Wilk.
Tabla 6 Prueba de normalidad
| Prueba de normalidad | ||||||
|---|---|---|---|---|---|---|
| Kolmogorov-Smirnova | Shapiro-Wilk | |||||
| Estadística | Gl | Sig. | Estadística | gl | Sig. | |
| Errores | 0,112 | 515 | 0,000 | 0,894 | 515 | 0,000 |
| a. Corrección de significancia de Lilliefors | ||||||
Fuente: Pardo et al. (2018)
De acuerdo con los resultados, el nivel de significancia es inferior a 0.05 (valor p <0.05), en ambas pruebas de normalidad (Kolmogorov-Smirnov y Shapiro-Wilk); esto muestra que la variable errores no sigue un patrón de distribución normal.
Nota aclaratoria: Dado que las pruebas paramétricas son más confiables que las no paramétricas, la investigadora intentó lograr la normalidad en los datos aplicando una transformación logarítmica de los errores variables, pero no fue posible lograr la normalidad. Por esta razón, fue necesario utilizar una prueba no paramétrica para aceptar o rechazar la hipótesis nula en cada caso. La Figura 1 muestra la desviación estándar de errores en el corpus total.

Fuente: Pardo et al. (2018)
Figura 1 Histograma de la desviación estándar de los errores de 515 archivos
Como la situación 1 se refiere a muestras independientes de una variable dicotómica (1-hombre -2-mujer), se aplicó la prueba U Mann Whitney. Las Tablas 7 y 8 contienen la prueba y sus resultados.
Tabla 7 Prueba no paramétrica - U de Mann Whitney
| Género | Número | Rango promedio | Adición rango | |
|---|---|---|---|---|
| Errores | 1 | 238 | 252.21 | 60026.50 |
| 2 | 274 | 260.22 | 71301.50 | |
| Total | 512 |
Fuente: Pardo et al. (2018)
Tabla 8 Prueba estadística
| Errores | |
|---|---|
| U de Mann-Whitney | 31585.500 |
| W de Wilcoxon | 60026.500 |
| Z | -0,611 |
| Sig. asymptotic (bilateral) | 0.541 |
| a. Variable de género. | |
Fuente: Pardo et al. (2018)
Inferencia: Como la significancia obtenida es 0.541, (valor p> 0.05) se acepta la hipótesis nula (H0). Este estudio afirma que no existen diferencias estadísticamente significativas en la mediana de los errores escritos de los hombres y mujeres estudiantes universitarios de ILE.
Dado que la situación 2 se refiere a muestras independientes de seis estratos sociales, una variable politómica cualitativa y errores escritos, una variable cuantitativa, se aplicó la prueba de K-Kruskal-Wallis. Las Tablas 9 y 10 contienen los resultados de la prueba.
Tabla 9 Prueba no paramétrica - K Kruskal-Wallis
| Rangos | |||
|---|---|---|---|
| Estrato | Número | Rango promedio | |
| Errores | 0 | 324 | 240.78 |
| 1 | 18 | 211.47 | |
| 2 | 31 | 275.02 | |
| 3 | 47 | 261.36 | |
| 4 | 51 | 310.48 | |
| 5 | 33 | 331.33 | |
| 6 | 11 | 315.73 | |
| Total | 515 | ||
Fuente: Pardo et al. (2018)
Tabla 10 Tests a,b estadística 1
| Errores | |
|---|---|
| H de Kruskal-Wallis | 22,553 |
| gl | 6 |
| Sig. asymptotic | 0.001 |
| a. Prueba K Kruskal Wallis b. Variable de agrupación: Estrato |
Fuente: Pardo et al. (2018)
Inferencia: De acuerdo con los resultados de la situación 2, en la que la significancia es 0.001 (valor p <0.05), la hipótesis nula se rechaza y se acepta la hipótesis alternativa. Por lo tanto, se afirma que existen diferencias estadísticamente significativas en la mediana de los errores de la producción escrita de estudiantes universitarios ILE en relación con el sistema de estratificación socioeconómica.
Aclaración: Es importante mencionar que 191 de 515 participantes (77 % del nivel B2 y 26 % del nivel B1) informaron voluntariamente sus estratos socioeconómicos. Por la razón anterior, a aquellas asignaciones que no entraron en los estratos se les dio un número cero. Esta situación dificulta el proceso de análisis y, de alguna manera, contribuye a la mala interpretación de los datos y a la comprobación de esta hipótesis, no por la prueba en sí, sino porque el estrato cero no existe y, por tanto, no corresponde con la realidad. Considerando que 191 de 515 estudiantes reportaron sus estratos sociales y que 77 % de estos estudiantes pertenecen a nivel B2, se vuelven a aplicar las pruebas estadísticas en la muestra de 191 estudiantes. La Figura 2 es la muestra de 191 participantes. Hay evidencia de que todos los niveles de estratos están representados.
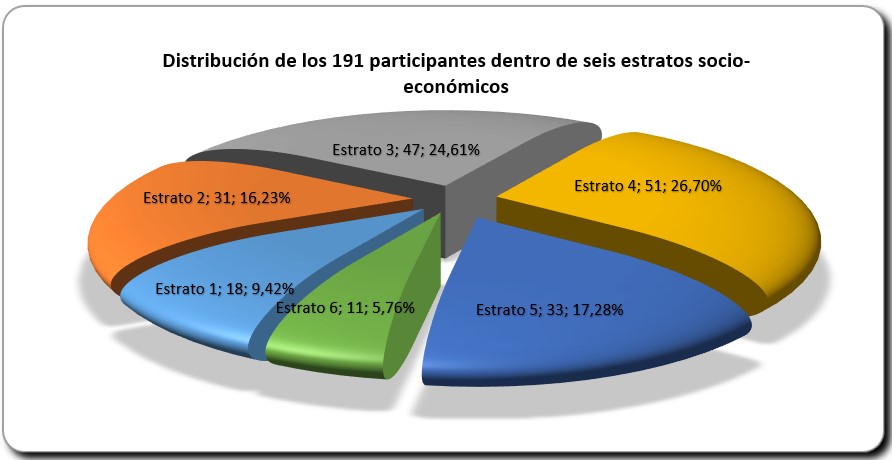
Cuando se aplica la prueba de normalidad de Kolmogorov-Smirnov a la nueva variable de errores con 191 participantes, el resultado es un nuevo valor p <0.05˃, por lo tanto, el resultado de la prueba no alcanza el supuesto de normalidad; por esta razón, se aplica a la muestra la prueba no -paramétrica K-Kruskal-Wallis.
La Tabla 11 muestra los resultados de la prueba no paramétrica de K-Kruskal-Wallis con sólo las 191 personas que informaron sus estratos socioeconómicos.
Tabla 11 Prueba K Krustal-Wallis aplicada a 191 individuos
| Estrato | Número | Rango promedio | |
|---|---|---|---|
| Errores | 1 | 18 | 70.11 |
| 2 | 31 | 91.02 | |
| 3 | 47 | 87.18 | |
| 4 | 51 | 103.79 | |
| 5 | 33 | 111.38 | |
| 6 | 11 | 107.82 | |
| Total | 191 |
Fuente: Pardo et al. (2018)
Inferencia Dado que la significancia es 0.092 (valor p> 0.05), se acepta la hipótesis nula. Por lo tanto, se afirma que no existen diferencias estadísticamente significativas en la mediana de errores de producción escrita de estudiantes universitarios de inglés como lengua extranjera en relación con la clasificación de estrato dada en Colombia. Es importante recordar que esta conclusión es el resultado de una prueba en una submuestra de 191 participantes que confirmaron su estrato socioeconómico, pero no de la muestra total de 515 individuos que fueron considerados para el análisis realizado con la prueba U de Mann-Whitney para las dos muestras independientes.
Los 515 participantes de esta investigación están distribuidos en 238 hombres y 274 mujeres. Hubo tres archivos anónimos en los que no se pudo identificar el género, en estos casos los datos se mantuvieron por razones informativas, pero no se contaron en los resultados finales. La Tabla 12 muestra el número de estudiantes por género en cada nivel, la cantidad de tokens y la cantidad de errores en cada caso. El análisis de errores por género se hizo según los niveles del Marco Común Europeo de Referencia (MCER).
Tabla 12 Vista general de los errores por género en cada nivel
| Código | Nivel | Número | Tokens | Género | % Token | # Errores | Errores /Tokens | |
|---|---|---|---|---|---|---|---|---|
| Hombre | 1 | B1.1 | 104 | 19,301 | 43 % | 41 % | 2,402 | 12.4 % |
| Mujer | 2 | B1.1 | 135 | 27,592 | 56 % | 59 % | 3,226 | 11.7 % |
| No género | 0 | B1.1 | 1 | 176 | 0.4 % | 0.4 % | 23 | 13.1 % |
| Hombre | 1 | B1.2 | 70 | 13,400 | 48 % | 46 % | 1,517 | 11.3 % |
| Mujer | 2 | B1.2 | 74 | 15,605 | 51 % | 53 % | 1,754 | 11.2 % |
| No Género | 0 | B1.2 | 2 | 437 | 1 % | 1 % | 44 | 10.1 % |
| Hombre | 1 | B1.3-B2.1 | 8 | 1,784 | 47% | 47 % | 279 | 15.6 % |
| Mujer | 2 | B1.3-B2.1 | 9 | 1,977 | 53 % | 53 % | 302 | 15.3 % |
| Hombre | 1 | B2.2-B2.3 | 56 | 33,725 | 50 % | 49 % | 2,526 | 7.5 % |
| Mujer | 2 | B2.2-B2.3 | 56 | 35,328 | 50 % | 51 % | 2,558 | 7.2 % |
En la Tabla 12 la columna errores / tokens describe el porcentaje de errores por cada 100 tokens. Los datos revelan que los hombres obtuvieron un mayor porcentaje de errores que las mujeres, aunque tienen menos producción escrita que éstas. Las Tablas 13 y 14 presentan la incidencia de errores en los niveles B1 y B2.
Tabla 13 Incidencia y porcentaje de los cinco primeros errores en nivel B1
| Tipo de error | # Errores hombres B1 | % en corpus | # Errores mujeres B1 | % en corpus |
|---|---|---|---|---|
| FS (Forma, Deletreo) | 800 | 0.05 | 881 | 0.06 |
| GA (Gramática, Artículos) | 580 | 0.03 | 702 | 0.04 |
| LS (Léxico, Individual) | 317 | 0.021 | 353 | 0.024 |
| GPP (Gramática, Pronombre, Personal) | 156 | 0.010 | 208 | 0.014 |
| GVN (Gramática, Verbo, Número) | 183 | 0.012 | 251 | 0.017 |
Tabla 14 Incidencia y porcentaje de los cinco primeros errores en nivel B2
| Tipo de error | # Errores hombres B2 | % en corpus | # Errores mujeres B2 | % en corpus |
|---|---|---|---|---|
| LS (Léxico, Individual) | 283 | 0.019 | 301 | 0.020 |
| GA (Gramática, Artículos) | 225 | 0.015 | 199 | 0.013 |
| GVN (Gramática, Verbo, Número) | 109 | 0.007 | 115 | 0.0078 |
| FS (Forma, Deletreo) | 105 | 0.007 | 109 | 0.007 |
| GPP (Gramática, Pronombre, Personal) | 96 | 0.006 | 105 | 0.007 |
El tipo y la cantidad de errores escritos en el nivel B1 muestran varias diferencias en comparación con los del nivel B2. En el nivel B1, los cinco errores más frecuentes en hombres y mujeres fueron FS, GA, LS, GPP y GVN. En el nivel B2, el orden de incidencia cambia y LS (Léxico individual) se convierte en el error más frecuente para ambos géneros seguido de GA, GVN, FS y GPP. Este cambio probablemente se deba a que el nivel de interlengua de los alumnos está en la búsqueda de nuevo vocabulario. Además, los estudiantes están adquiriendo estructuras más avanzadas.
En el nivel B1, las mujeres tuvieron más cantidad de errores que los hombres, en parte porque las mujeres tuvieron más producción escrita que los hombres, un promedio de 207 tokens por cada mujer y 189 tokens por cada hombre. Sin embargo, esos errores son proporcionales al número de mujeres. El porcentaje de errores por cada 100 tokens fue del 12 % para los hombres y del 11 % para las mujeres.
El nivel B2 podría considerarse un nivel balanceado porque el número de estudiantes es el mismo para hombres y mujeres. Se registró un total de 56 hombres y 56 mujeres. El promedio de tokens fue de 630 por texto para las mujeres y 602 por texto para los hombres con un promedio de M = 45 errores por estudiante hombre y M = 45.6 errores por estudiante mujer. Nuevamente, en este nivel, las mujeres tenían un menor porcentaje de errores por cada 100 tokens, 7.2 % para las mujeres y 7.5 % para los hombres.
En la Tabla 15 se puede observar la incidencia de los errores escritos de los hombres de acuerdo con el estrato socioeconómico.
Tabla 15 Errores y estrato de estudiantes hombres en B2
| Strata | Male B2 | Tokens | # Of Errors | % Errors |
|---|---|---|---|---|
| 1 | 7 | 3.871 | 224 | 5.8 % |
| 2 | 4 | 2.522 | 158 | 6.3 % |
| 3 | 15 | 8.311 | 600 | 7.2 % |
| 4 | 7 | 4.998 | 352 | 7.0 % |
| 5 | 7 | 4.339 | 360 | 8.3 % |
| 6 | 3 | 2.095 | 151 | 7.2 % |
| 43 | 26.136 | 1.845 | ||
| 0 | 13 | 7.589 | 681 |
El porcentaje de errores por cada 100 tokens aumenta junto con algunos estratos. Mientras que en el estrato socioeconómico 1 los errores fueron del 5,8 % por cada 100 tokens, en el estrato 5 el porcentaje alcanzó el 8,3 %, y en el estrato social 6 disminuyó aproximadamente un punto. Se observa que en el nivel B2 el número de errores se incrementa en los estratos 3, 4, y 5 para los hombres. En cuanto al promedio de producción escrita en los diferentes estratos, el número de tokens aumentó junto con el estrato. La siguiente lista muestra cómo las medias de los tokens varían en los estudiantes varones en el nivel B2, alcanzando un máximo de 714 tokens en el estrato 4.
Estrato 1 M=553,
Estrato 2, M=630,
Estrato 3 M= 554,
Estrato 4 M= 714,
Estrato 5 M= 619,
Estrato 6 M= 698.
La Tabla 16 contiene los errores y el estrato de estudiantes féminas en nivel B2. Se puede observar el número de errores en relación con número de tokens producidos por los estudiantes.
Tabla 16 Errores y estrato de mujeres estudiantes en B2
| Strata | Male B2 | Tokens | # Of Errors | % Errors |
|---|---|---|---|---|
| 1 | 1 | 821 | 51 | 6.2 % |
| 2 | 8 | 4,785 | 319 | 6.7 % |
| 3 | 19 | 5,889 | 362 | 6.1 % |
| 4 | 13 | 7,909 | 594 | 7.5 % |
| 5 | 8 | 4,789 | 374 | 7.8 % |
| 6 | 4 | 2,842 | 130 | 4.6 % |
| 43 | 27,035 | 1,830 | ||
| 0 | 13 | 8,293 | 728 |
Para el caso de las mujeres se observa en la Tabla 16 cómo los errores aumentaron gradualmente en los estratos 3, 4, y 5. Las mujeres del nivel B2 presentaron un porcentaje de 6,2 % de errores por cada 100 tokens en el estrato 1 y aumentaron hasta alcanzar el 7,8 % de errores en el estrato 5. En el estrato 6, el porcentaje de errores por cada 100 tokens disminuyó a 4,6 %, lo que es un indicador de un mejor rendimiento en la producción escrita respecto a los estratos inferiores. El promedio de tokens varió en los diferentes estratos. La siguiente lista muestra cómo la media de los tokens varía en las alumnas en el nivel B2. El pico de éstos se alcanza en el estrato 1 con 821 tokens. Sin embargo, el siguiente pico se logra en el estrato 6 con 710 tokens.
Medias de tokens para estudiantes mujeres en el nivel B2:
Estrato 1 M=821,
Estrato 2 M=598,
Estrato 3 M=654,
Estrato 4 M=608,
Estrato 5 M=598,
Estrato 6 M=710.
Los estratos 1 y 6 de las mujeres tienen más producción escrita que los demás estratos. La tendencia es bastante diferente de la de los homólogos masculinos. La Tabla 17 muestra la distribución de los cinco errores principales en el nivel B2 según los estratos.
Tabla 17 Estadísticas de los cinco errores principales en el nivel B2
| Estrato | Error | # | Error | # | Error | # | Error | # | Error | # |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | LS | 22 | GA | 22 | WRS | 20 | LP | 17 | GWC | 16 |
| 2 | LS | 46 | GA | 47 | WRS | 27 | LP | 31 | GWC | 19 |
| 3 | LS | 126 | GA | 84 | WRS | 72 | LP | 57 | GWC | 64 |
| 4 | LS | 104 | GA | 76 | WRS | 67 | LP | 67 | GWC | 72 |
| 5 | LS | 94 | GA | 56 | WRS | 48 | LP | 51 | GWC | 48 |
| 6 | LS | 31 | GA | 25 | WRS | 19 | LP | 18 | GWC | 20 |
Cuando se analizan los cinco errores principales por estrato en el nivel B2, la tendencia es encontrar menos errores en los estratos 1 y 2, luego en los estratos 3 a 5 éstos aumentan y de nuevo disminuyen en el estrato 6.
CONCLUSIONES
Sobre los hallazgos de los errores por género
Las pruebas estadísticas revelaron que no hay diferencias estadísticamente significativas en la mediana de los errores escritos de acuerdo con el género (hombres y mujeres estudiantes universitarios de ILE). En el nivel B1, los tres errores más frecuentes de hombres y mujeres fueron los mismos, FS (Forma Ortografía), GA (Gramática Artículo) y LS (Léxico Individual)). En todos los subniveles de B1, las mujeres presentaron un mayor número de errores que los hombres, en parte porque las mujeres tuvieron más producción escrita. Sin embargo, la media de errores por cada 100 tokens reveló que las mujeres tenían un porcentaje de errores menor que los hombres en todos los niveles. En el nivel B2, la cantidad de errores en las mujeres disminuyó. Una vez más, en este nivel, las mujeres en comparación con los hombres, cometieron un menor porcentaje de errores por cada 100 tokens. El error más frecuente en el nivel B1 para hombres y mujeres fue FS (Forma Ortografía), pero esta tendencia cambió en el nivel B2 donde el error más frecuente fue LS (Léxico Individual) para hombres y mujeres.
Los resultados muestran que las mujeres tienen más producción escrita con menos incidencia de errores por cada 100 tokens. Es decir, a pesar de que las diferencias de errores no son estadísticamente significativas, existen diferencias que confirman un mejor rendimiento de las mujeres en el aprendizaje del ILE. Estos resultados confirman estudios previos de Babayiğit (2015) con respecto a un mejor rendimiento en el aprendizaje de ILE de las mujeres y además el trabajo de Saeed et al. (2011), quienes afirman que las mujeres aprenden mejor el idioma que los hombres.
Sobre los hallazgos de los errores por estrato
Se estableció por medio de pruebas estadísticas que la muestra de 191 estudiantes universitarios de ILE, no presenta diferencias estadísticamente significativas en la mediana de los errores según los estratos. La media de errores por cada 100 tokens en el nivel B2 aumentó progresivamente con el incremento de estrato, especialmente en los estratos 3-5. La producción escrita en nivel B2 fue mayor en los estratos más altos y alcanza un pico en el estrato 6. Cuanto mayor es el estrato, mayor es el número de errores. Estos hallazgos contradicen las teorías de Lin (1999) con respecto a las afirmaciones de algunos autores sobre los privilegios de algunas clases sociales que tienen acceso a viajar al extranjero y, por lo tanto, mejorar su nivel de inglés. Por el contrario, este estudio reveló que los estudiantes más exitosos estaban en los estratos más bajos. En este caso particular, los estudiantes privilegiados que pertenecen a estratos altos no muestran una ventaja lingüística en la producción escrita del ILE en comparación con los estudiantes de estratos bajos.
La presente investigación es un estudio transversal con datos recopilados en un semestre. Quizá si se realiza un estudio longitudinal se podría hacer más comprobación de las hipótesis.
El presente estudio no busca un fin didáctico. Posiblemente tenga incidencia en elaboraciones didácticas futuras, pero, ese no es el fin actual.
Por otra parte, el corpus del presente estudio es solamente escrito resultado de la producción de los estudiantes.

