











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink
INTRODUCCIÓN
Conocimiento sobre el mundo y conocimiento lingüístico durante la comprensión de oraciones y textos
La comprensión de oraciones y textos involucra fenómenos complejos que suponen el procesamiento simultáneo tanto de información proveniente de los distintos niveles lingüísticos como de información no específicamente lingüística. La interacción de información léxica, sintáctica y textual -en términos de información específicamente lingüística- incide de modo decisivo, aunque suele no ser suficiente para lograr una comprensión global (Ferreira y Lowder, 2016; Graesser, 1981; Karimi y Ferreira, 2016; Kintsch, 1988; Townsend y Bever, 2001; Van Berkum, 2008; Van Dijk y Kintsch, 1983; Zunino, 2017; entre muchos otros). El conocimiento sobre el mundo y las expectativas del lector resultan factores determinantes, que, en las últimas décadas, se han transformado en el foco de estudio de diversas investigaciones (Dery y Koenig, 2015; Frank et al., 2007; Kintsch, 1988; Noordman y Vonk, 1998; Van der Meer et al., 2005; Zunino, 2014, 2017, 2020). Sin embargo, aún está en discusión de qué modo interviene esta información, cómo se articula con el conocimiento lingüístico (por ejemplo, información sintáctica y léxica) y cómo afecta al proceso la organización macroestructral de la información (Kendeou y Van den Broek, 2007; Van Dijk, 1992; Zunino, 2014).
Existen varias líneas de investigación que han abordado el problema de la articulación entre conocimiento de mundo, su organización conceptual y cómo la comprensión de oraciones y textos podría estar condicionada por ello.
Entre los modelos de procesamiento de oraciones, existen múltiples propuestas que analizan la interacción entre semántica -desde el nivel léxico hasta el pragmático- y la sintaxis durante la comprensión (De Long et al., 2005; Ferreira et al., 2002; Hagoort, 2003; Humphries et al., 2006; Jackendoff, 2010; Karimi y Ferreira, 2016; Metusalem et al., 2012; Pylkkänen y McElree, 2007; Pylkkänen et al., 2011; Sikos et al., 2016). Las propuestas sobre ilusiones semánticas y los modelos good-enough o los modelos de procesamiento predictivo que ponen el foco en la incidencia de las expectativas del hablante/lector son algunos ejemplos de estos abordajes (Ferreira et al., 2002; Karimi y Ferreira, 2016; Kuperberg y Jaeger, 2016; Metusalem et al., 2012; Pylkkänen et al., 2011; Sikos et al., 2016; Van Berkum et al., 2005; Wicha et al., 2004; Zunino, 2019b). Entre los modelos clásicos de procesamiento sintáctico existe un debate, también clásico, en torno a la posibilidad de involucrar información semántica y representaciones de alto orden y respecto del momento en que eso se produce durante el procesamiento de oraciones. Por supuesto, ese debate se enmarca en una discusión más amplia sobre arquitectura de la mente, que retoma consideraciones sobre modularidad, especificidad de dominio y flujo de la información top-down o bottom-up (Chomsky, 1986; Fodor, 1983; Huettig, 2015, Jackendoff, 2010, Lupyan y Clark, 2015). Los modelos interactivos y en paralelo son los que, en líneas generales, admiten flujo de información top-down y proponen que las representaciones de mayor grado de abstracción podrían condicionar o guiar el procesamiento sintáctico en instancias tempranas (MacDonald y Seidenberg, 2006; Stetie, 2021; Trueswell et al., 1994). Supuestos similares manejan las propuestas good-enough al plantear que, si bien existen casos en los que la información sintáctica y estructural es imprescindible e insoslayable, también hay ocasiones en las que la información semántica permite una interpretación plausible de la oración y se impone, incluso a riesgo de generar representaciones de estructuras sintácticamente anómalas o incompletas (Christianson et al., 2006; Ferreira et al., 2002; Karimi y Ferreira, 2016). Las propuestas de procesamiento predictivo en lenguaje, por su parte, también requieren admitir la intervención temprana de información contextual, semántica y pragmática sobre procesos de grano fino y de bajo orden como los morfosintácticos; es decir, una arquitectura cognitiva con posibilidad de flujo top-down. Y, por supuesto, suponen la interacción constante de todas estas fuentes de información a la hora de procesar lenguaje.
Entre los estudios del nivel textual, trabajos como los de Cozjin et al. (2011), Hagoort et al. (2004), Noordman et al. (2015), Ozuru et al. (2009), entre otros, abordaron el estudio del conocimiento sobre el mundo y su efecto durante la comprensión de lenguaje: ha podido mostrar que esa incidencia es decisiva (sobre todo en el nivel de representación más abstracto: el modelo de situación1). Por supuesto, este factor no opera de modo aislado sino que interacciona con las marcas lingüísticas presentadas en el texto y con las estrategias de procesamiento, que varían significativamente entre lectores expertos y no expertos.
Zunino et al. (2012), Zunino (2014, 2020), por su parte, han encontrado evidencias de que la ausencia de conocimiento previo durante el proceso de comprensión de relaciones causales y contracausales cambia el patrón de procesamiento de modo decisivo y proponen que la comprensión, en ausencia de marcas lingüísticas explícitas, estaría fuertemente restringida y guiada por el conocimiento previo y su particular modo de organización conceptual.
Como ya mencionamos, vale decir que nuestra comprensión de discursos no se basa únicamente sobre el conocimiento previo sobre el mundo; en cambio, nuestro conocimiento lingüístico en general y el adecuado manejo de la información semántica codificada en ciertas construcciones lingüísticas o lexemas clave como las partículas conectivas resultan fundamentales para la adecuada comprensión e, incluso, en ocasiones, pueden ser imprescindibles para el establecimiento de relaciones de significado (Asr y Demberg, 2012; Degand et al., 1999; Hoek et al., 2017; Murray, 1997; Zunino, 2014; Zunino et al., 2012).
Comprensión de relaciones semánticas: tipo de relación, marcación explícita y causalidad por defecto
Por supuesto, para abordar procesos complejos, es imprescindible acotar los objetos de análisis. Así, muchas investigaciones se han concentrado especialmente en el estudio del procesamiento (comprensión y producción) de relaciones semánticas específicas, entendidas como aquellas que posibilitan la construcción de una representación mental coherente a partir de un enunciado (Dery y Koenig, 2015; Goldman et al., 1999; Van der Meer et al., 2005; Zunino, 2017; Zwaan y Radwansky, 1998).
No son pocos los estudios que han analizado las diferencias de procesamiento entre relaciones de coherencia implícitas y explícitas. Antes de 1990 hubo algunos estudios aislados sobre comprensión de textos y el rol de las partículas conectivas (Caron et al., 1988; Haberlandt, 1982). Sin embargo, el grupo de estudios que marcó la línea de trabajo que llega hasta la actualidad comenzó luego, aunque se concentraron casi exclusivamente sobre el inglés (Millis y Just, 1994).
Murray (1994), uno de los autores que más ha trabajado estos temas, muestra que tanto en términos de recuerdo -medida offline- como en términos de tiempos de lectura -medida online-, solo los conectores adversativos poseían un rol verdaderamente facilitador. Este primer hallazgo pone en cuestión la hipótesis generalista de que cualquier conector, en cualquier contexto, muestra un efecto facilitador de la comprensión. De hecho, el mismo autor, algunos años después, planteó explícitamente su “Hipótesis de continuidad” (Murray, 1997), sobre la base de dos ejes: a) existe una tendencia a representar la información textual adoptando el orden sintagmático de las oraciones -se asume que los eventos se organizan secuencialmente en el orden en el que se presentan los sintagmas-; b) la continuidad -entendida en términos icónicos-2 se establece como la estrategia de organización textual y de procesamiento por defecto, por ende, un texto que respete esto se procesará con mayor velocidad y menor dificultad. A través de una serie de experimentos, logró probar que: 1) los conectores funcionan como instrucciones semánticas de procesamiento y son críticos durante el proceso de lectura; 2) la continuidad textual parece establecerse, efectivamente, por defecto; 3) los conectores que marcan ruptura de la continuidad tienen mayor efecto -facilitador- que aquellos que solo refuerzan una relación de continuidad.
En una línea similar pero enfocada específicamente en la centralidad de la dimensión causal, Sanders (2005) fue uno de los primeros en proponer una “Hipótesis de causalidad por defecto” y la planteó como respuesta a lo que denominó “Paradoja de la complejidad causal”. A pesar de que las estructuras causales pueden considerarse estructuras complejas -más que las aditivas o las temporales, por ejemplo-, la evidencia empírica muestra que su procesamiento es más sencillo: más veloz y más preciso (Hoek et al., 2017; Mak y Sanders, 2013; Noordman y Blijzer, 2000; Oudega, 2011; Zunino, 2014). Vale decir aquí que la propuesta de que existe una ventaja causal y un rol ubicuo de la causalidad excede al procesamiento de lenguaje y ha sido planteada también para el razonamiento, el aprendizaje e incluso para la percepción (Couper-Kuhlen y Kortman, 2000; Davidson, 1985; Kim, 2007; Sloman, 2005; Sperber et al., 1996).
En la misma línea trabajaron otros investigadores que respaldaron esta hipótesis y mostraron imprescindibles articulaciones entre el Principio de iconicidad, las Hipótesis de continuidad y la Hipótesis de causalidad por defecto (Asr y Demberg, 2012; Briner et al., 2012; Hoek et al., 2017; Meyer, 2009; Noordman y Blijzer, 2000; Oudega, 2011; Zunino, 2014). En este sentido, la propuesta plantea que la causalidad también puede considerarse un eje de organización conceptual fundante y generar un modo de procesamiento por defecto. Como consecuencia de ello, las relaciones causales se comprenderían incluso sin marca semántica explícita, en tanto constituirían una estrategia de procesamiento preferida. En cambio, cuando la relación involucra suspensión de expectativas causales, la marca semántica adquiere un rol decisivo. Sin embargo, también es posible articular la causalidad con la continuidad: así se distinguirían las relaciones causales en orden habitual e invertido. A partir de la dificultad de procesamiento esperada y el tipo de efecto provocado por la presencia/ausencia de conector, se constituye un continuum: las relaciones causales y continuas representan el extremo de menor dificultad y de menor necesidad de marca explícita, las causales discontinuas se encontrarían en posición intermedia y las contracausales -consideradas causales de polaridad negativa en algunos estudios (Abel y Hänze, 2019; Hoek et al., 2017)- serían las más complejas y aquellas que mostrarían mayor requerimiento de marca semántica, como instrucción de procesamiento que advierte sobre la necesidad de suspender una estrategia/expectativa causalista.
Distintos autores evalúan varias de las aristas involucradas en la Hipótesis de continuidad y la Hipótesis de causalidad por defecto. Analizan especialmente la complejidad cognitiva vinculada con el tipo de relación semántica y su marcación explícita. En el marco de esas dos hipótesis clásicas, Asr y Demberg (2012) proponen un análisis de corpus sobre el Penn Discourse Treebank, específicamente de las relaciones causales y temporales. Sus resultados respaldan las Hipótesis de continuidad y Causalidad por defecto. Por un lado, las causales presentan menos marcación, cosa que no sucede con todas las relaciones temporales; en segundo término, todas las relaciones con orden icónico se presentan con más frecuencia sin marcación explícita. Hoek et al. (2017), a su vez, toman la misma clasificación e introducen el análisis del potencial efecto de las expectativas generadas por los lectores. Se analizan relaciones aditivas, causales, condicionales y concesivas y se predice la siguiente asimetría: una tendencia a marcar explícitamente las dos primeras y a no marcar las dos últimas (patrón similar al que se propone en Zunino, 2014, 2017, 2020). La base para esta predicción se deriva de la hipótesis general que sostiene que las relaciones más esperadas no requerirían marcación explícita para ser comprendidas, mientras que aquellas menos esperadas necesitarían la presencia de una partícula conectiva para establecer la relación adecuada. Esta predicción está alienada con las Hipótesis de continuidad y casualidad por defecto. Sin embargo, los resultados de Hoek et al. (2017) no lograron mostrar una tendencia significativa que respalde estas propuestas.
Estudios como los de Mak y Sanders (2013), Briner et al. (2012) o Zunino (2020), por su parte, estudian el rol de las expectativas y la relación de la causalidad con la iconicidad durante la comprensión de relaciones semánticas. En todos los casos los resultados muestran que cuando el lector tiene expectativas causales sobre la relación por establecer o cuando la relación se presenta en orden icónico -es decir, en el orden sintagmático propuesto por la hipótesis de continuidad-, los tiempos de procesamiento son menores y hay una ventaja para la integración inter-clausal. De Ruiter et al. (2018), además, suman el estudio de la interacción de diversos factores durante la comprensión de oraciones con subordinadas adverbiales en niños: analizan oraciones temporales, causales y condicionales. El trabajo muestra que la iconicidad, como parámetro eminentemente semántico, tiene un efecto significativo durante la comprensión de oraciones en niños: un patrón similar al hallado por Clark (1971), aunque, en ese caso, solo para relaciones temporales. Sin embargo, un dato relevante para nuestros objetivos muestra que la comprensión de causalidad implicó un costo cognitivo mayor que la temporalidad durante procesamiento online -medido en tiempos de respuesta-, aunque no en términos de precisión de respuesta. Este podría ser un indicio respecto de que la ventaja causal, con fuerte respaldo en adultos, se fortalece quizá en edades posteriores a los 5 o 6 años y posiblemente a partir de una vinculación consistente con el desarrollo del conocimiento sobre el mundo y el conocimiento enciclopédico.
Por supuesto, también existen numerosos trabajos que se concentran sobre las relaciones temporales y muestran la centralidad de la temporalidad, que usualmente es difícil de escindir de la causalidad. Estudios clásicos sobre este punto son los de Gennari (2004) y Van der Meer et al. (2002, 2005). Se parte de una premisa clave: el tiempo constituye un eje central de nuestras representaciones mentales y la computación de temporalidad resulta un modo básico de ordenamiento de los eventos en la memoria. Los elementos temporales por computar son muchos y con distinto grado de granularidad: ubicación temporal general, dirección temporal de la narración, contigüidad temporal entre eventos, etc. No obstante, una pregunta que cruza todos los estudios es la posibilidad de desvincular la información temporal de la información causal a la hora de procesar relaciones entre eventos y dentro de los mismos eventos. En ese sentido, algunos estudios indagan sobre diferencias en la codificación temporal de estados y eventos: solo en los segundos la temporalidad estaría subsumida en y condicionada por la estructura causal, mientras los estados no tendrían estructura causal interna. Los resultados reportados respaldan esta diferencia y muestran que, al procesar eventos, se recupera de modo inmediato la información causal asociada, además de la temporal. Ambas integradas rápidamente con el conocimiento previo sobre el mundo para generar una interpretación global adecuada. Van der Meer et al. (2002, 2005), por su parte, encontraron evidencia para afirmar que la distancia cronológica entre los eventos tiene efecto sobre la comprensión (eventos más cercanos entre sí serían más sencillos de computar), además de exhibir que existe una facilitación cuando los eventos son presentados verbalmente en orden icónico. Sin embargo, también sostienen que la ventaja del orden temporal prospectivo puede estar, sobre todo, vinculado con las expectativas generadas por el lector a partir de su conocimiento previo, es decir que sería un efecto modulado por procesos estratégicos que guían las expectativas puntuales sobre el despliegue temporal del texto en cada caso.
Por último, otro de los elementos que se han estudiado versa sobre los mecanismos de actualización temporal durante la comprensión de discurso, específicamente en textos narrativos (Dery y Koenig, 2015). También en línea con los modelos que se enfocan sobre las expectativas del lector, se sostiene que la generación de expectativas sobre los marcos temporales de los eventos y la relación entre ellos es ubicua, un mecanismo por defecto durante la comprensión. Sin embargo, estos parámetros generales no serían suficientes para explicar los efectos hallados y sería necesario considerar información de grano más fino para analizar la construcción de expectativas temporales que pueden revestir una precisión muy aguda sobre la estructura temporal de los eventos (enfoques similares se discuten en relación con el procesamiento predictivo en Zunino, 2019b).
A partir de todos los antecedentes comentados, y antes de involucrarnos en el presente experimento, debemos decir que todos los estudios suelen evaluar sus hipótesis con información conocida y potencialmente cotidiana para el lector; es decir, información sobre la que el lector ya tiene representaciones mentales almacenadas. A partir de la evidencia aquí sintetizada, se ve que el tipo de proceso implicado en los casos en que la comprensión implica relaciones semánticas previamente almacenadas como parte del conocimiento sobre el mundo es distinto del que puede esperarse en casos en los que no es posible involucrar esas representaciones previas. Zunino (2014), Zunino et al., (2016), entre otros trabajos, se han encargado de mostrar que, en este último caso, el sujeto requiere “construir” relaciones nuevas, no ya “comprender”, en el sentido de corroborar información entrante con información previamente almacenada. Esto, indefectiblemente, modifica el patrón de procesamiento. En ese marco, proponemos el estudio experimental descrito en el próximo apartado.
Experimento
En este experimento proponemos analizar de qué modo incide la ausencia de conocimiento previo sobre el mundo durante la comprensión de oraciones y, específicamente, si este factor modula el proceso en función del tipo de relación semántica en cuestión. En ese sentido, además de sumar evidencia a los trabajos que evalúan la incidencia del conocimiento previo sobre el mundo y las expectativas del lector durante la comprensión de discurso, nuestro estudio intenta revisitar la Hipótesis de causalidad por defecto y la paradoja de la complejidad causal (Sanders, 2005; Zunino, 2014) para analizarla en virtud del tipo de información en proceso. Este experimento, además, nos permite analizar comparativamente dos relaciones semánticas tan estrechamente ligadas como las temporales y las causales, para continuar indagando sobre sus posibles asociaciones, en la línea de Gennari (2004) y Van der Meer et al. (2005). Asimismo, sumamos una relación semántica que se asume como línea de base y que es simétrica en términos de iconicidad, por lo que el orden de presentación de las cláusulas no debería tener efectos sobre el procesamiento: las relaciones aditivas (Asr y Demberg, 2012; Hoek et al., 2017). Si bien la evidencia a favor del establecimiento de causalidad por defecto es robusta en casos en los que la información es familiar para el lector -es decir, en aquellas situaciones en las que los lectores pueden hacer intervenir sus conocimientos previos para establecer expectativas-, nos preguntamos si los marcos causales también mantienen esta ventaja en casos de información desconocida. Esto implica, además, evaluar en qué medida las representaciones mentales que forman parte de nuestro conocimiento sobre el mundo afectan la comprensión de oraciones y textos, y de qué modo podría representarse nueva información a partir de su comprensión lingüística.
En ese marco, trabajaremos solo con relaciones semánticas explícitas -con partículas conectivas presentes-, controlaremos la estructura sintáctica de las oraciones y el orden icónico de las cláusulas, para concentrar el análisis sobre dos factores: tipo de información y tipo de relación semántica. Proponemos un diseño experimental factorial 2 x 3: Tipo de información (cotidiana vs. técnica) y Tipo de relación semántica (aditiva vs. temporal vs. causal).
Nuestras hipótesis centrales son: 1. el efecto del tipo de información será transversal a todas las relaciones semánticas y se exhibirá tanto en menor precisión en la comprensión como en la velocidad de lectura de la oración; 2. la ventaja de las relaciones causales predicha por la Hipótesis de causalidad por defecto se verá respaldada para los ítems con información conocida por el lector, pero no se proyectará a los ítems en los que no sea posible recurrir al conocimiento previo sobre el mundo.
METODOLOGÍA
Participantes
Dado que el experimento involucraba la consideración del conocimiento previo sobre el mundo de los participantes, dentro de las preguntas demográficas se incluyó una que indagaba sobre la formación profesional o académica en virtud de considerar válidos para la muestra solo a aquellos sujetos que no tuvieran alguna formación vinculada con las áreas del conocimiento involucradas en los ítems técnicos (ver Materiales). Una vez realizada esta selección, la muestra se conformó con datos de 155 participantes. Del total, se descartaron 2 participantes por no haber realizado la tarea completa. El análisis definitivo se hizo con 153 participantes: 44 varones3 (edad M= 38, DE= 13,3), 105 mujeres (edad M=36,2, DE=13,5) y 4 personas que se identificaron como no binarias (edad M=27,5, DE=0,5). Todos los participantes eran hablantes de español rioplatense, mayores de 18 años, con un nivel de educación formal de secundario completo o mayor.
Materiales
Como mencionamos, el experimento supuso un diseño factorial 2 x 3: el primer factor Tipo de información con dos niveles (información cotidiana vs. información técnica) y el segundo factor Tipo de relación semántica con tres niveles (aditiva, temporal y causal). Se diseñaron 24 ítems en cada una de las seis condiciones generadas por este diseño.
Todos los ítems se conformaban por dos cláusulas simples que podían tener una relación causal, temporal o aditiva entre sí, siempre con marca semántica explícita a través de partícula conectiva. Presentaban una estructura sintáctica coordinada y orden icónico para las relaciones temporales y causales. Esto es, “causa, efecto” para las causales y “evento 1, evento 2” para las temporales.
Algunas restricciones fueron consideradas como centrales para la construcción de materiales: 1) todas las oraciones presentan estructura S-V-O; 2) los verbos se presentan en modo indicativo -presente, pretérito simple o compuesto-; 3) ninguna oración presenta estructuras hendidas, proposiciones incluidas adjetivas -ni especificativas ni explicativas- o proposiciones incluidas sustantivas; 4) se evitan las negaciones explícitas: hay pocas negaciones léxicas cuando resultaba estrictamente necesario.
Para los ítems causales se utilizó la partícula conectiva “entonces” como marca explícita de la relación, para los temporales se utilizó “después” y para los ítems aditivos se optó por “y”.
Se consideraron cotidianos aquellos ítems que expresan situaciones previamente conocidas para el lector, es decir que en esos casos el lector podía involucrar su conocimiento previo sobre el mundo durante la comprensión (Noordman et al., 2015). Un ejemplo podría ser información del tipo “el agua apaga el fuego”. Por su parte, los que llamamos estímulos técnicos son ítems que expresan situaciones desconocidas para la mayoría de los sujetos4 por ser parte de dominios de conocimiento muy específicos de ciertas disciplinas científicas. Se usaron oraciones adaptadas de textos naturales especializados de las siguientes disciplinas: astrofísica, física cuántica, geología, astronomía, genética, inmunología, química inorgánica, cardiología y endocrinología. En estos casos, se pone en juego información del tipo “la enzima calmodulina genera el proceso de fosforilación de la sinapsina I”.
Se controló la extensión de los estímulos por cantidad de palabras. Para todas las condiciones las oraciones tenían entre 16 y 17 palabras, con las siguientes medias por condición: temporales cotidianas: M=16,58; temporales técnicas: M= 16,62; aditivas cotidianas: M=16,50; aditivas técnicas: M=16,70; causales cotidianas: M=16,62; causales técnicas: M=16,67.
Para los estímulos técnicos, además, se establecieron restricciones sobre la cantidad de lexemas o frases técnicas: en todos hay entre dos y cuatro palabras o frases técnicas, en un promedio de 3 por estímulo.
Cada ensayo constaba de una oración y una pregunta de comprensión cerrada que buscaba verificar el establecimiento de la relación semántica. Las opciones de respuesta siempre eran “Sí/No/ No se sabe”. Si bien la estructura de las preguntas también fue controlada, el equilibrio por cantidad de palabras requirió un rango amplio en función de poder respetar la naturalidad de la pregunta adecuada para cada relación semántica. En ese sentido, no se desarrollarán comparaciones respecto del tiempo de respuesta. Todas las preguntas comenzaban con la misma introducción: “Según el texto anterior…” y siempre suponía la misma estructura para cada tipo de relación semántica. Además, se equilibró la cantidad de respuestas “Sí” y “No”. Los fillers se diseñaron a partir de oraciones con las mismas relaciones semánticas pero con otros tipos de estructuras sintácticas y órdenes interclausales. Las preguntas tenían la misma estructura que las de ítems experimentales y también lograban equilibrio en las repuestas por Sí/No. La Tabla 1 muestra ejemplos de ítems en cada una de las condiciones.
Dado el diseño mencionado, los ítems fueron organizados en 8 listas contrabalanceadas de 18 ítems experimentales y 18 fillers cada una.
Tabla 1 Ejemplos de ítems experimentales en cada condición
| Tipo de información | Relación semántica | Ítem |
|---|---|---|
| Cotidiana | Temporal | Julieta se puso las zapatillas deportivas, después se fue a correr al parque cercano a la casa. Según el texto anterior, ¿lo primero que pasó fue que Julieta se puso las zapatillas? |
| Aditiva | Agustín da clases de inglés los lunes en un instituto y trabaja en un hospital los martes. Según el texto anterior, ¿Agustín trabaja en varios lugares distintos? | |
| Causal | Camila sufrió una fuerte caída por la escalera del edificio, entonces se fracturó dos huesos del brazo. Según el texto anterior, ¿la caída provocó que Camila se fracturara? | |
| Técnica | Temporal | Las secciones remanentes de materia orgánica siempre generan geopolímeros, después sufren una conversión diagenética a querógeno. Según el texto anterior, ¿lo primero que pasa es la conversión diagenética a querógeno? |
| Aditiva | El diagrama de Penrose permite la identificación de horizontes y ofrece gráficos de la prolongación de geodésicas. Según el texto anterior, ¿el diagrama de Penrose brinda información sobre distintos elementos? | |
| Causal | La enzima calmodulina se activó con el calcio, entonces disparó el proceso de fosforilación de sinapsina. Según el texto anterior, ¿el proceso de fosforilación provocó la activación de la enzima calmodulina? |
Procedimiento
La tarea fue diseñada y tomada mediante el software PCIbex (Zehr y Schwarz, 2018), que asignaba aleatoriamente una lista diferente a cada participante. En todos los casos, se presentó primero un consentimiento informado que debía ser aceptado para acceder a las preguntas sobre datos demográficos y al experimento. Se les pidió a los participantes que indicaran identidad de género, máximo nivel de estudios alcanzado, edad y profesión. Luego se presentó la consigna: se les indicó que primero leyeran las oraciones a ritmo propio y que luego respondieran la pregunta. La oración se presentaba completa en una primera pantalla en letras negras sobre fondo blanco. La siguiente pantalla mostraba la pregunta y las opciones de respuesta: “Sí”, “No”, “No se sabe”. El participante debía responder seleccionando la opción con el mouse. Entre los ensayos, siempre se presentaba una pantalla en blanco con una cruz en el centro para fijar la mirada y descansar entre ítems, si lo necesitaban. Se aclaró que tendrían cuatro oraciones de práctica al inicio y luego se los invitaba a comenzar con la tarea cuando estuvieran listos. Se incluyeron, al inicio de cada lista, dos oraciones más de práctica que luego fueron descartadas: para el conocimiento de los participantes estos ítems ya eran parte de la tarea experimental.
El experimento se difundió por redes sociales entre hablantes de español rioplatense. La participación fue voluntaria y los participantes no recibieron ninguna remuneración a cambio.
RESULTADOS
Los datos fueron procesados mediante el programa R versión 4.1.1 en la interfaz R Studio (R CORE TEAM, 2021) y se utilizaron los paquetes lme4 (Bates et al., 2015), lmerTest (Kuznetsova, et al., 2017) y MuMIn (Barton, 2020) para realizar los análisis estadísticos.
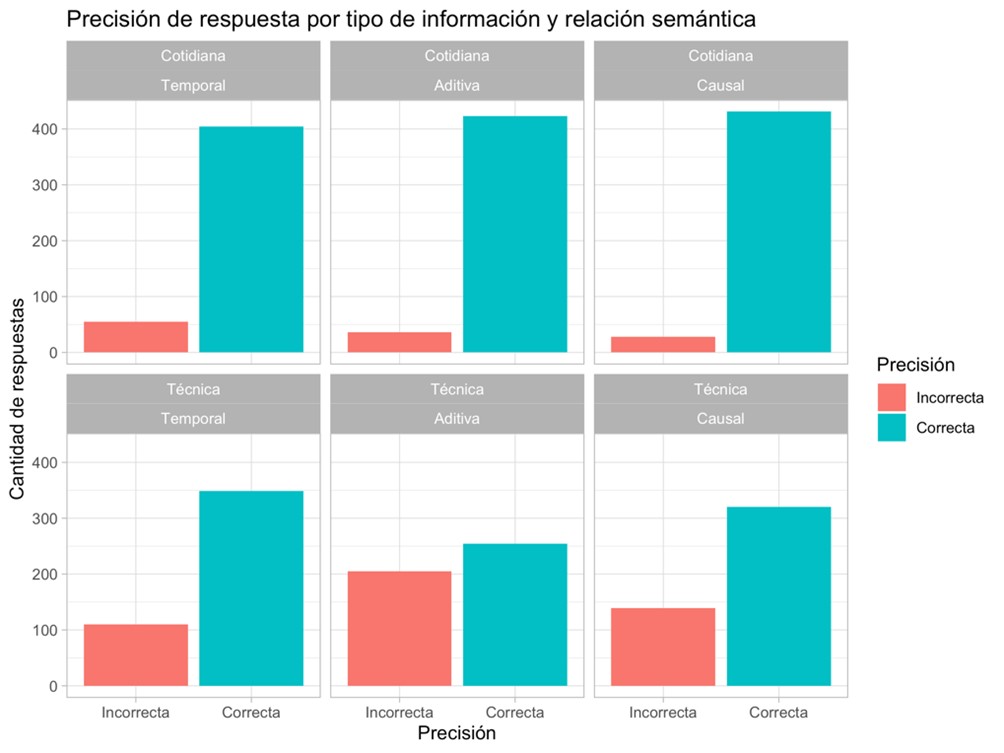
Para analizar la medida de precisión, se consideraron las repuestas correctas e incorrectas dadas a las preguntas de comprensión en cada condición. La Figura 1 presenta gráficamente la frecuencia de respuestas correctas e incorrectas para cada condición.
A partir de esta codificación de las respuestas utilizamos Modelo Mixtos Lineales Generalizados (GLMM) con distribución binomial. Todos los contrastes fueron codificados como contrastes repetidos (también denominado sliding differences:Schad et al., 2020), que en el caso de factores con dos niveles también corresponde a la codificación de suma escalada. En primera instancia, aplicamos un modelo máximo (Barr et al., 2013) con dos efectos fijos anidados -Relación semántica anidada a Tipo de información- y cálculo de Interceptos y Pendientes para Ítem y Participantes como efectos aleatorios. Dado que el modelo máximo no lograba convergencia, eliminamos, sucesivamente, el efecto aleatorio que menos varianza aportaba. Finalmente, a partir de la comparación por AIC de modelos convergentes, seleccionamos el modelo con la siguiente fórmula, que considera los mismos efectos fijos e Interceptos para Ítems y Participantes como efectos aleatorios: Precisión ~ Tipo de Información/Relación semántica + (1 | Participante) + (1 | Ítem).
La Tabla 2 presenta el resultado del modelo seleccionado. Como es posible ver, se halló un efecto principal del factor Tipo de información (p<0,001), en tanto todos los ítems técnicos muestran un menor rendimiento respecto de la precisión de respuesta. Además, se encontró un efecto de Relación semántica anidado al tipo de información técnica, entre relaciones aditivas y temporales (p=0,004). Los ítems técnicos con relación semántica aditiva mostraron el mayor nivel de error en las respuestas a la pregunta de comprensión, aunque solo se diferenciaron significativamente de los técnicos temporales.
Tabla 2 Modelo seleccionado para el análisis de la variable Precisión de respuesta.
| Precisión de respuesta | |||
|---|---|---|---|
| Predictores | Razón probabilidad | CI | p |
| Intercepto | 7.67 | 5.77 - 10.20 | <0.001 |
| Tipo de Información (TdF) | 0.11 | 0.06 - 0.19 | <0.001 |
| TdF Cotidiana -Temporal_Aditiva | 1.16 | 0.43 - 3.12 | 0.765 |
| TdF Técnica -Temporal_Aditiva | 0.30 | 0.13 - 0.68 | 0.004 |
| TdF Cotidiana -Causal_Aditiva | 1.14 | 0.43 - 3.04 | 0.792 |
| TdF Técnica Causal_Aditiva | 2.09 | 0.93 - 4.70 | 0.076 |
| Efectos aleatorios | 3.29 | ||
| σ2 | |||
| τ00 Participante | 0.19 | ||
| τ00 Ítem | 1.73 | ||
| ICC | 0.37 | ||
| N Participante | 153 | ||
| N Ítem | 144 | ||
| Observaciones | 2754 | ||
| R2 Marginal /R2 Condicional | 0.207 /0.499 | ||
CI = Intervalos de confianza; p = p valor.
Tiempos de lectura
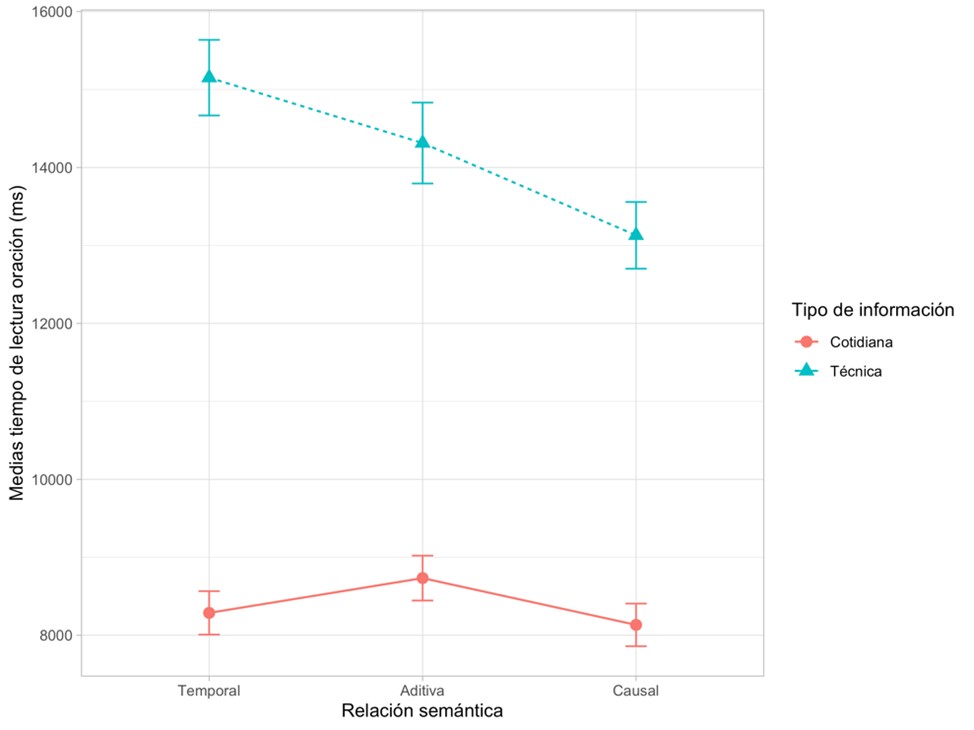
Para el análisis de los tiempos de lectura, se tomaron solo las respuestas correctas. Dado que la recolección online de los datos no permite llevar a cabo un control exhaustivo de las condiciones en las que cada participante hace la tarea, se hizo una búsqueda y limpieza de outliers o casos extremos en dos etapas. En primera instancia se consideraron valores mínimos y máximos de corte (300 ms y 45.000 ms) y se eliminaron los puntos de datos que se encontraran fuera de ese rango. Eso supuso eliminar 2,93 % de los datos. Luego se realizó un análisis de outliers considerando media y desvío estándar por condición por participante: no se hallaron casos extremos en este análisis (Baayen y Milin; 2010; Cousineau y Chartier, 2010; Ratcliff, 1993). En la Figura 2 se exhiben gráficamente las medias de la variable dependiente Tiempo de lectura de la oración (TLO) en milisegundos, por condición experimental.
Antes de pasar al ajuste de modelos y luego de realizar el chequeo de homocedasticidad y normalidad, se realizó una transformación logarítmica de los datos (Vasishth et al., 2021; Winter, 2019).
Se utilizaron Modelos Lineales Mixtos (LMM). El mismo procedimiento para ajuste y selección de modelos que fue descripto en el análisis de precisión de respuestas fue utilizado aquí. Se corrió un modelo máximo y se llegó a ajustar un modelo convergente con la siguiente fórmula, en el que se evalúan dos factores fijos (Relación semántica anidada a Tipo de información) y el cálculo de Intercepto para Ítems e Intercepto y Pendiente para el Tipo de información entre Participantes como efectos aleatorios: log (TLO) ~ Tipo de información/Relación semántica + (1 + Tipo de información | Participante) + (1 | Ítem). La Tabla 3 exhibe los resultados del modelo seleccionado. Se halló un efecto principal del factor Tipo de información (p<0,001), en tanto los tiempos de lectura de los ítems técnicos son mayores para todas las relaciones semánticas. Sin embargo, también se halló un efecto de Relación semántica anidado al nivel de información técnica entre relaciones causales y las otras dos condiciones de relación semántica (p=0,047): los ítems causales técnicos son los que exhibieron menores tiempos de lectura.
Tabla 3 Modelo seleccionado para el análisis de la variable Tiempos de lectura de la oración (TLO)
| Tiempo de lectura oración | |||
|---|---|---|---|
| Predictores | Estimadores | CI | p |
| Intercepto | 9.14 | 9.07 - 9.21 | <0.001 |
| Tipo de Información (TdF) | 0.53 | 0.47 - 0.60 | <0.001 |
| TdF Cotidiana -Temporal_Aditiva | 0.05 | -0.05 - 0.14 | 0.324 |
| TdF Técnica -Temporal_Aditiva | -0.05 | -0.15 - 0.05 | 0.307 |
| TdF Cotidiana -Causal_Aditiva | -0.06 | -0.15 - 0.03 | 0.207 |
| TdF Técnica Causal_Aditiva | -0.10 | -0.20 - -0.00 | 0.047 |
| Efectos aleatorios | 0.14 | ||
| σ2 | |||
| τ00 Participante | 0.17 | ||
| τ00 Ítem | 0.02 | ||
| τ11 Part.TdFAdit-Temp | 0.04 | ||
| ρ01 Participante | 0.23 | ||
| ICC | 0.57 | ||
| N Participante | 153 | ||
| N Ítem | 141 | ||
| Observaciones | 2117 | ||
| R2 Marginal /R2 Condicional | 0.175 /0.649 | ||
CI = Intervalos de confianza; p = p valor.
DISCUSIÓN
Como comentamos en la Introducción del presente trabajo, las líneas de estudio que indagan sobre los efectos del conocimiento previo sobre el mundo -o la imposibilidad de hacer intervenir este conocimiento- durante la comprensión de lenguaje son variadas y se concentran sobre distintas dimensiones de este fenómeno general. Algunas de ellas hacen foco en el procesamiento de oraciones, otras en el procesamiento del nivel textual/discursivo, pero, en general, todas tienen dos puntos en común: 1. el análisis de la interacción entre información específicamente lingüística y extralingüística; 2. la naturaleza de los procesos de generación de expectativas por parte del lector, usualmente basadas en esa interacción (Christianson et al., 2006; Dery y Koenig, 2015, Metusalem et al., 2012; Van Berkum, 2008; Zunino, 2014, 2020).
Además, paralelamente, hemos mencionado que muchos de los estudios sobre comprensión de oraciones y textos han hecho un recorte del objeto y se han concentrado sobre el procesamiento de relaciones semánticas o relaciones de coherencia, como ejes clave para la comprensión, la representación de significados complejos, el recuerdo y el aprendizaje (Goldman et al., 1999; Kendeou y Van den Broek, 2007; Koornneef y Sanders 2012; León y Peñalba, 2002; Murray, 1997). En ese marco, además, se han desarrollado numerosos estudios acerca de los distintos factores -lingüísticos y extralingüísticos- que intervienen a la hora de comprender algunas relaciones semánticas en particular. Las relaciones causales han tenido un lugar privilegiado e incluso se han desarrollado propuestas denominadas “causalistas” que sostienen que la causalidad no sería solo un eje importante más sino el eje central para la comprensión de textos (Goldman et al., 1999; Noordman y Vonk, 1998). La temporalidad ha despertado gran interés, por su parte y, además, presenta un vínculo tan estrecho con la causalidad que se vuelve inevitable el solapamiento conceptual y empírico entre los estudios sobre una y otra dimensión (Gennari, 2004; Sloman, 2005). Han sido desarrolladas propuestas centrales en torno a tres principios e hipótesis: Principio de iconicidad, Hipótesis de continuidad, Hipótesis de causalidad por defecto. Todas ellas fueron consideradas para el diseño de este estudio experimental, ya que hacen predicciones convergentes en relación con la facilidad con la que las relaciones semánticas podrían comprenderse y derivan hipótesis complementarias sobre las expectativas que establecería el lector durante la comprensión de oraciones y textos. Las relaciones temporales y causales presentadas en orden cronológico y prospectivo (icónicas y continuas) serían coincidentes con las expectativas del lector -basadas sobre las representaciones propias de su conocimiento sobre el mundo- y por lo tanto esto se proyectaría en una facilitación del procesamiento y en una menor necesidad de marcación explícita a través de conector. Las aditivas, por su parte, al ser sintagmáticamente simétricas y presentar la relación semántica conceptualmente más genérica, no mostraría efecto alguno del orden sintagmático de presentación. A su vez, las relaciones causales, a partir de la Hipótesis de causalidad por defecto, mostraría una ventaja por sobre el resto de las relaciones de coherencia: la paradoja de la complejidad causal justamente propone que, a pesar de ser una relación conceptualmente más compleja y específica, tendría una ventaja significativa durante el procesamiento.
En esta escena y considerando estos dos grandes bloques de estudio, sin embargo, debemos destacar que no existen tantos trabajos que indaguen sobre la comprensión de relaciones semánticas en textos sobre temáticas desconocidas para el lector. Si bien se han analizado los efectos de la experticia temática y de la pericia lectora sobre la comprensión de textos en general, los trabajos no se concentran sobre relaciones semánticas específicas ni cruzan factores como los efectos de iconicidad, continuidad y causalidad por defecto con el condicionamiento impuesto por el tipo de información. Este punto no es menor, ya que las predicciones producidas por las tres hipótesis suelen suponer representaciones mentales de relaciones semánticas entre eventos almacenadas previamente en la mente del hablante; es decir, representaciones propias del conocimiento previo sobre el mundo. Sin embargo, en numerosas ocasiones, por ejemplo, instancias de aprendizaje formal a partir de textos especializados, los lectores no cuentan con información previa alguna sobre los eventos por relacionar y solo pueden valerse de la adecuada computación de las marcas lingüísticas presentes en los textos, como información que funciona de guía transversal a cualquier dominio de conocimiento enciclopédico (Hoek et al., 2017; Koornneef y Sanders, 2012; Ozuru et al., 2009; Traxler et al., 1997; Zunino, 2014; Zunino et al., 2016). En ese sentido, nuestra propuesta intenta comenzar un camino de investigación que permita poner en interacción varios de estos elementos y busque obtener evidencia sobre cuáles son los factores que inciden y condicionan la comprensión de información previamente desconocida para el lector. Este proceso supone un mecanismo subyacente distinto al que estaría implicado en la comprensión de información conocida: para el segundo caso se requiere acceder, evaluar, comparar e integrar representaciones mentales preexistentes con aquellas representaciones surgidas del texto que se intenta comprender; para el primer caso, en cambio, la comprensión requiere la construcción de representaciones nuevas, no existe constatación ni integración con información preexistente (Zunino 2014, 2017, 2020). Esto tiene, además, consecuencias evidentes para las teorías que ponen el foco en las expectativas del lector y su rol activo durante el proceso de comprensión: no es posible construir expectativa alguna sobre lo que se desconoce por completo, no existe ancla posible para generar predicciones anticipatorias (Kuperberg y Jaeger, 2016; Zunino, 2019b). En este punto, parece imprescindible recordar que la comprensión de información previamente desconocida parece ser un primer paso para posibilitar el aprendizaje a partir de textos especializados: la adecuada representación de información nueva es una condición necesaria -aunque no suficiente- para generar una representación semántica estable de mayor abstracción que luego logre consolidarse como parte de la memoria semántica, como parte de nuestro conocimiento sobre el mundo o enciclopédico. Hay información a la que jamás accederemos a partir de la experiencia directa, a la que justamente solo podemos acceder a partir de discursos o textos (no eliminamos aquí ninguna de las modalidades: escrito u oral): ese es el tipo de información especializada, con alto nivel de abstracción conceptual, que suele ser el núcleo de la formación académica en espacios de educación formal, especialmente del nivel superior o universitario. En ese sentido, estudiar los procesos que subyacen a la comprensión de información desconocida y que pueden suponer el primer paso en la cadena de aprendizaje resulta fundamental no solo desde un punto de vista teórico sino práctico: ¿qué factores favorecen y cuáles dificultan la comprensión y, por ende, podrían obstaculizar el aprendizaje?
Para interpretar los resultados hallados en este estudio, en primera instancia, nos interesa discutir qué ocurre para cada una de las variables dependientes -precisión de respuesta y tiempos de lectura- en cada una de las condiciones evaluadas. Recordemos que el diseño experimental propuesto generaba seis condiciones a partir de dos factores: Tipo de información y Relación semántica. Por lo tanto, evaluamos ítems con información técnica -desconocida para los participantes- e ítems cotidianos -con información familiar para los participantes- que presentaban tres tipos de relación semántica: aditivas, temporales y causales.
Para la medida de precisión de respuesta hallamos un patrón claro que muestra una mayor complejidad para comprender los ítems técnicos: todos los ítems con información desconocida -para todas las relaciones semánticas- mostraron una tasa de error mayor, es decir, una complejidad significativamente mayor que obstaculiza su comprensión. Esto corresponde a una de las hipótesis generales planteadas al inicio: el rol del conocimiento previo sobre el mundo es determinante durante la comprensión. La imposibilidad de andamiar el proceso en representaciones semánticas previamente almacenadas plantea un obstáculo transversal. Sin embargo, si precisamos el análisis, es posible ver que dentro de los ítems técnicos también existe un efecto significativo que distingue a las relaciones aditivas de las temporales y causales, por lo que el efecto de la ausencia de conocimiento previo también está modulado por el tipo de relación semántica. No obstante, el patrón no respalda las predicciones iniciales: se esperaba que las relaciones aditivas, como aquellas conceptualmente más sencillas y genéricas, fueran las que mostraran una facilitación para la condición de ítems con información técnica. Las temporales, en cambio, son las que muestran mejor rendimiento, seguidas por las causales, que no exhiben diferencias significativas con ellas en términos de precisión de respuestas. En ese sentido, las dos relaciones semánticas conceptualmente más complejas -temporales y causales- muestran un mejor rendimiento cuando el lector debe procesar información previamente desconocida, conformando una escala de complejidad de menor a mayor: temporales, causales, aditivas. Dado que las relaciones temporales y causales se presentaron en orden icónico y continuo, este resultado podría estar respaldando las predicciones de continuidad e iconicidad para el caso de las temporales, aunque es difícil considerar cómo sería la construcción de una expectativa a partir de información desconocida. Por otro lado, la hipótesis de causalidad por defecto prediría que las relaciones causales deberían mostrar una ventaja por sobre el resto de las relaciones y no fue el caso: en este trabajo, para los ítems técnicos, los resultados no pueden ser explicados en esos términos. En cambio, surge el indicio de que construir relaciones temporales nuevas en orden cronológico prospectivo entre eventos desconocidos podría ser más sencillo que construir relaciones causales y aditivas, incluso cuando la iconicidad y continuidad se mantienen como variables controladas.
Por su parte, los ítems cotidianos no mostraron una diferencia estadísticamente significativa entre las tres relaciones semánticas, por lo que tampoco se ha podido evidenciar una ventaja causal para la medida de precisión de respuesta cuando el proceso se hace sobre información familiar. Es decir, no hallamos resultados alineados con trabajos anteriores (Asr y Demberg, 2012; Hoek et al., 2017; Mak y Sanders, 2013; Sanders, 2005; Zunino, 2019a).
Si analizamos los tiempos de lectura como medida online de procesamiento, también se evidencia una ventaja transversal de los ítems cotidianos. Recordemos que todas las condiciones estaban controladas en extensión por cantidad de palabras, sin embargo, la lectura de oraciones que presentaron información desconocida tomó consistentemente más tiempo y esa diferencia resultó estadísticamente significativa, es decir, constituyó un efecto principal del factor Tipo de información. En este caso, tampoco encontramos diferencias en los tiempos de lectura entre las distintas relaciones semánticas cuando la información procesada era conocida y familiar para el lector, por lo que la ventaja causal no fue respaldada tampoco para la medida online analizada. Sin embargo, sí se hallaron diferencias entre las tres relaciones semánticas para los ítems técnicos, es decir, aquellas oraciones que suponían procesar información desconocida. En este cuadro, un elemento especialmente interesante es el patrón de facilitación hallado en este caso, que no coincide con el exhibido para la precisión de respuesta. Las relaciones causales son las que se leyeron más rápido, seguidas por las aditivas y, por último, las temporales, que no muestra diferencias significativas con las últimas. Nuevamente, podemos decir que el tipo de relación semántica modula el efecto que surge de la ausencia de conocimiento previo sobre el mundo; o dicho de otro modo, la imposibilidad de involucrar conocimiento previo impacta de modo distinto según la relación de coherencia de la que se trate. Esto, en términos generales, es lo mismo que ocurre para la medida de precisión, sin embargo, la relación semántica facilitada no es la misma en los dos casos. En ese marco, conviene observar los resultados desde otra perspectiva: ¿qué ocurre para cada tipo de relación durante todo el proceso?
Si analizamos el patrón para las relaciones casuales, vemos que la lectura de oraciones causales sobre información desconocida resulta la más sencilla de todas. No obstante, esa velocidad de lectura pierde impacto a la hora de evaluar la precisión de la comprensión propiamente dicha. El rendimiento no es el mejor: de algún modo una lectura veloz no se proyecta sobre una adecuada comprensión. Este esquema no es nuevo y ha sido hallado en trabajos que analizan lo que suele denominarse comprensión activa y profunda vs. comprensión pasiva y superficial (Kendeou y Van den Broek, 2007; Linderholm et al., 2000; McNamara et al., 1996; O´Reilly y McNamara, 2007). Una comprensión superficial puede implicar una elevada velocidad de lectura que luego debe ser compensada por el tiempo de respuesta o no traducirse en una adecuada comprensión. Esto muestra, una vez más, que la sola evaluación de los tiempos de lectura como medida de comprensión es insuficiente. Más aún, en casos de información desconocida, lo que podemos arriesgar es que las estructuras causales -gracias a esa ventaja causal predicha por la Hipótesis de causalidad por defecto- podrían generar una ilusión de comprensión más que una comprensión adecuada de la relación.
El proceso que vemos para las relaciones temporales, en cambio, parece mostrar el patrón inverso: el mayor costo durante la lectura de la oración resulta compensado por una ventaja en la precisión de las respuestas, es decir, con una mejor comprensión de la relación semántica por construir. En ese sentido, el proceso subyacente que podemos inferir supone una comprensión activa durante la lectura que permite una adecuada integración de las cláusulas/eventos temporales y una construcción más precisa de la relación temporal global: eso posibilita un mayor rendimiento a la hora de responder. Es decir, algo que podría parecer una desventaja en primera instancia -una estructura que no presenta las ventajas que podrían mostrar las construcciones causales durante la lectura-, termina siendo una ventaja en términos del resultado final de la comprensión.
Sobre las relaciones aditivas, por último, podemos destacar que, a pesar de ser las que presentarían menor complejidad conceptual, ser simétricas en términos de iconicidad y resultar semánticamente más genéricas, no muestran ventaja respecto de las temporales y de las causales en ninguna condición ni para ninguna de las medidas. Para los ítems familiares no se hallaron ventajas en la precisión de respuesta e incluso muestran tiempos de lectura levemente mayores, aún sin ser diferencias significativas. En el caso de los ítems técnicos, por su parte, no sólo fueron los que mostraron menor rendimiento final, sino que los tiempos de lectura no se diferenciaron significativamente de los ítems técnicos temporales. Así, desde varias perspectivas, las relaciones aditivas fueron las que supusieron mayor dificultad. Este punto sí puede vincularse y respaldar parcialmente lo propuesto por la paradoja de la complejidad causal (Sanders, 2005): una relación más genérica y sencilla semánticamente no proyecta a priori esas características al proceso de comprensión. A partir de estos resultados, podría alegarse que una relación tan genérica, sin precisión semántica alguna, ni indicios de organización temporo-causal (considerando que estos dos ejes resultan centrales para la comprensión de discursos y conformación de modelos mentales) resultaría demasiado vaga y el lector requeriría mayor precisión para poder comprender esa oración, ya sea para integrarla y contrastarla con información previamente conocida, como para construir una relación semántica nueva, que sería, por tan genérica, poco informativa.
En síntesis, nuestra hipótesis sobre el efecto transversal que genera la imposibilidad de involucrar conocimientos previos sobre el mundo se vio respaldada; sin embargo, la modulación de ese efecto que produce cada tipo de relación semántica no responde a las predicciones iniciales. Nuestros datos no respaldan la Hipótesis de causalidad por defecto en su totalidad, aunque sí muestran una ventaja de las relaciones temporales y causales por sobre las aditivas. Estos resultados pueden estar exhibiendo la centralidad del eje temporo-causal para la comprensión de oraciones y textos, incluso en los casos en los que el proceso implica construir representaciones nuevas sobre información desconocida.
CONCLUSIONES
Presentamos aquí un primer trabajo de una línea de investigación más amplia que busca indagar qué factores influyen y subyacen al proceso de comprensión de oraciones y textos que presentan información previamente desconocida para el lector. En este estudio específico, nos concentramos sobre el procesamiento de ciertas relaciones semánticas particulares, consideradas clave para la conformación de modelos mentales y la construcción de coherencia durante la comprensión de oraciones y textos: aditivas, temporales y causales. Asimismo, intentamos revisitar y poner a consideración los potenciales límites de las predicciones hechas por tres hipótesis clásicas en los estudios sobre comprensión de oraciones y textos: Principio de iconicidad, Hipótesis de continuidad e Hipótesis de causalidad por defecto.
Creemos que el estudio de los procesos y factores que subyacen e intervienen durante la comprensión de información nueva o desconocida para el lector -es decir, aquellos procesos en los que no es posible hacer intervenir conocimientos previos para generar expectativas que aporten a la construcción de coherencia global y faciliten la comprensión- no es solo de interés teórico sino que también muestra numerosas proyecciones de aplicación y transferencia, especialmente para comprender y mejorar los procesos de enseñanza-aprendizaje.
En este marco, los resultados reportados en este trabajo muestran la complejidad del fenómeno por analizar: los patrones y predicciones que pueden hacerse en casos en los que la información resulta familiar para el lector, sobre la que se tienen representaciones mentales previamente almacenadas y en los que este conocimiento se pone en juego de modo sistemático y consistente durante la comprensión, son modificados ostensiblemente cuando la información involucrada es desconocida, nueva para ese lector. No es posible, entonces, usar los mismos modelos para comprender los procesos implicados en cada una de esas situaciones; es preciso revisar nuestra hipótesis y repensar las diferencias respecto de los procesos subyacentes que se despliegan en cada caso. Construir representaciones mentales nuevas no puede suponer los mismos procesos psicolingüísticos que aquellos implicados en integrar y actualizar vínculos sobre información previamente conocida. Y en este sentido, es esperable que el rol de la marcación lingüística en ambos casos sea ostensiblemente distinto. Vale destacar, además, que lejos de ser un fenómeno infrecuente, la necesidad de comprender y construir representaciones nuevas, sobre dominios de conocimiento desconocidos, a partir de textos es la situación habitual en un proceso de enseñanza-aprendizaje en espacios de educación formal, por lo que parece clave comprender cabalmente los mecanismos implicados.
De modo preliminar, nuestros datos indican que, si bien la iconicidad, continuidad y causalidad por defecto tienen algún rol durante la comprensión de información desconocida, ese rol puede no tener la misma naturaleza que el que se halló para la comprensión de oraciones y textos con información familiar. En principio, la ventaja causal hallada en estudios anteriores no logra replicarse claramente y requiere ser reconsiderada en articulación con otros factores. Asimismo, se hace indispensable profundizar en el análisis y la consideración de otras variables lingüísticas que pueden influir durante el proceso, por ejemplo, estructura sintáctica de las construcciones y no solo ausencia o presencia de marca semántica explícita, sino también tipo de conector utilizado. En esta línea, nos encontramos trabajando en un estudio que considere los efectos de la complejidad sintáctica, para continuar aportando evidencia que permita construir un panorama cada vez más preciso sobre este fenómeno complejo.

