Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkDesarrollo y Sociedad
versão impressa ISSN 0120-3584
Desarro. soc. no.76 Bogotá jan./jun. 2016
https://doi.org/10.13043/DYS.76.7
DOI: 10.13043/DYS.76.7
Modelación de la asimetría y la curtosis condicionales en series financieras colombianas
Conditional Modeling of Skewness and Kurtosis on Colombian Financial Series
Andrés Eduardo Jiménez Gómez1
Luis Fernando Melo Velandia2
1 Estudiante de maestría de Ciencias Económicas de la Universidad Nacional de Colombia. Correo electrónico: anejimenezgo@unal.edu.co.
2 Econometrista principal del Banco de la República de Colombia. Correo electrónico: lmelovel@banrep.gov.co.
Este artículo fue recibido el 25 de agosto de 2014, revisado el 22 de mayo de 2015 y finalmente aceptado el 5 de noviembre de 2015.Resumen
Las metodologías tradicionales utilizadas para calcular el valor en riesgo y el valor en riesgo condicional usualmente modelan el primer y segundo momento de las series, suponiendo que el tercer y cuarto momento son constantes. En este artículo se utiliza la metodología de Hansen (1994) para modelar los primeros cuatro momentos de la serie y, en particular, se usan varias formas paramétricas para modelar la asimetría y la curtosis. Las medidas tradicionales de VaR y CVaR y las propuestas se calculan para la tasa representativa del mercado, los TES y el IGBC para el periodo comprendido entre enero de 2008 y febrero de 2014. En general, se encontró que las medidas de riesgo de mercado presentan mejor desempeño cuando se modelan la asimetría y la curtosis condicionales de la serie.
Palabras clave: valor en riesgo, valor en riesgo condicional, backtesting, asimetría, curtosis.
Clasificación JEL: C52, C51, G17.
Abstract
Traditional methodologies used to calculate the value at risk and conditional value at risk usually model the first and second moments of the series, assuming that the third and fourth moments are constant. This paper uses the methodology proposed by Hansen (1994) to model the first four moments of the series, in particular, several parametric shapes are used to model the skewness and kurtosis. The traditional measures of VaR, CVaR and proposals are calculated for the Representative Market Rate, TES, and the IGBC for the period between January 2008 and February 2014. Overall, it was found that measures of market risk have better performance when conditional skewness and kurtosis of the series is modeled.
Key words: VaR, conditional value at risk, backtesting, skewness, kurtosis.
JEL classification: C52, C51, G17.
Introducción
Para las instituciones financieras es importante contar con instrumentos adecuados de gestión del riesgo de mercado, dado que permiten cuantificar el riesgo al cual un activo o un portafolio están expuestos. En el caso colombiano, las instituciones financieras están obligadas a mantener un capital de reserva para cubrir los riesgos percibidos en el mercado. Usualmente se utiliza el valor en riesgo (VaRα) para cuantificar dicho riesgo.
Esta medida corresponde a la mínima pérdida esperada en el (1 - α) x 100% de los peores casos. Así, con una probabilidad a el administrador del riesgo esperaría que la pérdida de su inversión no sea mayor al VaR. En términos estadísticos, el VaRα es el cuantil α-ésimo de la distribución de pérdidas y ganancias del activo.
Algunas metodologías tradicionales usadas para calcular el VaR son: simulación histórica, normalidad, RiskMetrics y ARMA-GARCH. La simulación histórica obtiene directamente el VaR a partir del cuantil empírico de los retornos del activo, sin suponer que estos sigan alguna distribución paramétrica. Sin embargo, supone que todos los momentos de la serie son constantes. Por otra parte, la metodología de normalidad o de varianza-covarianza asume que los retornos siguen una distribución normal, a pesar de que su estimación es sencilla; este método también supone que todos los momentos son constantes. Por el contrario, RiskMetrics© modela la varianza de los retornos a partir de un modelo de suavizamiento exponencial, pero debido a su construcción no permite obtener volatilidad de largo plazo (varianza no condicional). Finalmente, la metodología ARMA-GARCH modela los primeros dos momentos condicionales de los retornos del activo.
Es importante notar que las últimas tres metodologías mencionadas suponen normalidad3, mientras que las series financieras con datos de alta frecuencia, en general, se asocian a distribuciones de colas pesadas y en algunos casos asimétricas.
Jondeau, Poon y Rockinger (2007) resaltan la necesidad de hacer una correcta especificación de la distribución de los retornos. Estos autores proponen que modelar la asimetría y la curtosis permite tener una descripción más adecuada de la distribución de los retornos. Esta información adicional es útil para modelar datos de frecuencia alta o cuando se tienen retornos con distribuciones de colas muy pesadas. Tal enfoque puede ser utilizado, por ejemplo, en las herramientas empleadas por inversionistas para la toma de decisiones, dado que ellos deben tener en cuenta la asimetría y la curtosis de los retornos de los activos. En general, se espera que los inversionistas prefieran asimetrías positivas y presenten un comportamiento adverso a la curtosis; por otra parte, la modelación de los dos momentos adicionales puede mejorar el desempeño de las medidas del riesgo de mercado.
Este documento sigue la metodología propuesta inicialmente por Hansen (1994) y ampliada después por Jondeau y Rockinger (2003). Según este método, los errores estandarizados de un modelo ARMA-GARCH siguen una distribución t de Student asimétrica. Además, los autores proponen modelar los grados de libertad y el parámetro de asimetría de la distribución, de tal forma que los momentos condicionales tres y cuatro puedan ser calculados analíticamente a partir de estos parámetros variantes.
El resto de este artículo se divide en seis secciones. La sección I define formalmente el valor en riesgo (VaR) y el valor en riesgo condicional (CVaR). En la sección II se presentan las metodologías más utilizadas para modelar el VaR y también se muestran las propuestas metodológicas de Hansen (1994) y Jondeau y Rockinger (2003). Luego, en la sección III se exponen algunas de las pruebas de backtesting de mayor uso en la literatura y se incluye la prueba que recientemente propusieron Leccadito, Boffelli y Urga (2014). En la sección IV se presentan los modelos y las series que se utilizarán en este documento. Los resultados de las estimaciones del VaR y CVaR se pueden apreciar en la sección V, junto con las pruebas de backtesting para cada modelo. Por último, en la sección VI se realizan comentarios sobre las metodologías y resultados encontrados.
I. Valor en riesgo y valor en riesgo condicional
A. Valor en riesgo
El VaR es una medida muy aceptada y difundida entre quienes manejan portafolios de activos financieros, lo cual se debe principalmente a que condensa gran cantidad de información en un número. El VaRαt|t−k de un portafolio es la máxima pérdida posible en el α×100% de los mejores escenarios o, en forma equivalente, la mínima pérdida en el (1−α)×100% de los peores casos, para el periodo t, con información disponible hasta t−k y con un horizonte de pronósticos k.
Por ejemplo, asumiendo que los retornos de un activo siguen una distribución normal estándar, la máxima pérdida en el 95% de los mejores escenarios será el 1,65% del valor del portafolio.
Para facilitar el manejo y notación de las expresiones utilizadas en este documento se supone que rt corresponde a los retornos negativos de un activo. Por lo tanto, valores positivos altos de rt corresponden a pérdidas grandes.
El VaRαt|t−k con horizonte de pronóstico k = 1 e información hasta t se define como:
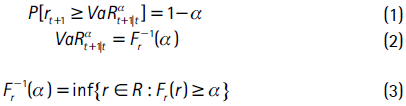
donde Fr−1(α) es la función inversa de la distribución acumulada de los retornos4.
A pesar de su gran aceptación, el VaR es objeto de numerosas críticas, principalmente la de no cumplir con la condición de subaditividad de Artzner, Delbaen, Eber y Heath (1999). Esta hace referencia al principio de diversificación, en el cual el riesgo de un portafolio debería ser menor o igual a la suma de los riesgos individuales de los activos que lo componen. Puesto que el VaR no siempre cumple con esta propiedad, podría llevar a resultados contradictorios para el administrador del riesgo.
B. Valor en riesgo condicional
Una medida del riesgo de mercado que efectivamente cumple con la condición de subaditividad es el valor en riesgo condicional (CVaR). Esta medida se define como el valor esperado de las pérdidas que exceden el VaR, formalmente:
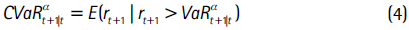
El CVaR se entiende como el promedio de los retornos en el (1−α)×100% de los peores casos y se obtiene a partir de:
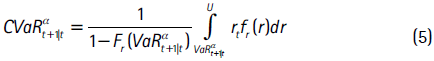
donde Fr(.) y fr(.) corresponden a la función de distribución y la de densidad de los retornos, respectivamente, y U es la pérdida máxima que puede sufrir el activo.
II. Metodología
En esta sección se presenta un resumen de los métodos tradicionales empleados para calcular el VaR y el CVaR y se expone la metodología propuesta para modelar la asimetría y la curtosis condicionales5.
A. Metodologías tradicionales
1. Simulación histórica
Este método obtiene el VaR a partir del cuantil empírico de los retornos del activo y se define como:
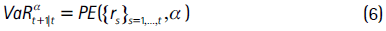
y el CVaR:
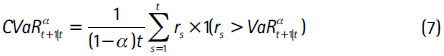
donde PE es el cuantil a-ésimo de la distribución empírica y 1(.) es la función indicadora, que toma el valor de 1 si la condición dentro del paréntesis se cumple.
Esta metodología no paramétrica es sensible al tamaño de la muestra utilizado y a la inclusión de nuevos datos. Además supone que todos los momentos de la distribución de los retornos son constantes.
2. Normalidad
Es el caso más sencillo en el que se hace algún supuesto sobre la distribución de los retornos. En esta metodología se asume que los errores son independiente e idénticamente distribuidos con media y varianza finitas. A partir de la ecuación (1) el VaR se deduce como:
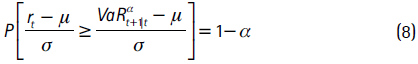

donde Zα  Φ-1(α) y Φ-1(α) es la función inversa de la distribución normal estándar acumulada.
Φ-1(α) y Φ-1(α) es la función inversa de la distribución normal estándar acumulada.
Y el CVaR:
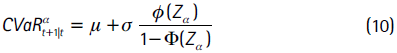
Al igual que en la simulación histórica, el VaR por normalidad es ampliamente usado por su facilidad de estimación. Sin embargo, un hecho estilizado en las series financieras de alta frecuencia, es que presentan distribuciones con colas pesadas y asimetría. Estas series, en general, no siguen una distribución normal. Igualmente, esta metodología asume que todos los momentos de los retornos son constantes en el tiempo.
3. RiskMetrics
Este método propuesto por Morgan (1996) consiste en utilizar la técnica de suavizamiento exponencial, en la cual la varianza se determina como un promedio ponderado de los retornos cuadráticos pasados, es decir:

suponiendo que las ponderaciones decaen exponencialmente de forma constante: αi+1/αi = λ con λ  (0,1), y si n es grande, se puede demostrar que el componente de volatilidad de la serie se obtiene a partir de:
(0,1), y si n es grande, se puede demostrar que el componente de volatilidad de la serie se obtiene a partir de:

RiskMetrics supone que los errores se distribuyen de forma normal estándar y, por consiguiente, el VaR y el CVaR se obtienen a partir de las ecuaciones (1) y (12) como:

y
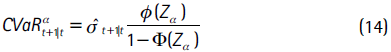
donde 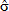 t+1|t es el pronóstico de la volatilidad calculado a través de la ecuación (12). Usualmente el parámetro l toma valores entre 0,94 y 0,99. A medida que l es mayor, la varianza condicional tendrá un comportamiento más suave. Sin embargo, la varianza no condicional (volatilidad de largo plazo) para este método no está definida.
t+1|t es el pronóstico de la volatilidad calculado a través de la ecuación (12). Usualmente el parámetro l toma valores entre 0,94 y 0,99. A medida que l es mayor, la varianza condicional tendrá un comportamiento más suave. Sin embargo, la varianza no condicional (volatilidad de largo plazo) para este método no está definida.
4. ARMA-GARCH
Esta metodología modela el primer y segundo momento condicional de la serie a partir de un proceso ARMA y uno GARCH, respectivamente. De manera formal:
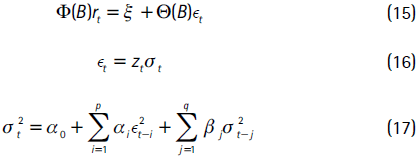
donde las ecuaciones (15) y (17) modelan la media y la varianza condicional de los retornos. Además, con el fin de garantizar la no negatividad de σ se imponen las siguientes restricciones: αo > 0; αi ≥ 0 para i =1,...,p; βj ≥ 0 para j =1,...,q.
Si se definen 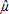 t+1|t y t+1|t como el pronóstico de la media y la volatilidad condicional obtenidos por medio de las ecuaciones (15) y (17) y se supone que zt
t+1|t y t+1|t como el pronóstico de la media y la volatilidad condicional obtenidos por medio de las ecuaciones (15) y (17) y se supone que zt  N(0,1), el VaR y el CVaR se calculan como:
N(0,1), el VaR y el CVaR se calculan como:
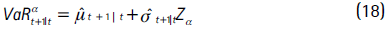
y
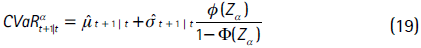
B. Modelación de la asimetría y la curtosis
En general, para países en vías de desarrollo son escasos los trabajos que modelan momentos de orden superior al de la varianza y entre ellos se encuentra el de Durán, Lorenzo y Ruiz (2012), quienes utilizan un enfoque similar al de Hansen (1994). Los autores proponen un modelo GARCH con asimetría condicional autorregresiva y concluyen que el pronóstico del índice de precios al consumidor (IPC) para México mejora considerablemente al tener en cuenta momentos de orden superior al de la varianza. Lai (2012) analiza la dependencia de la asimetría condicional de los mercados de valores internacionales y encuentra que la asimetría en la volatilidad es notablemente mayor en los mercados desarrollados que en los emergentes.
Para ampliar la literatura enfocada en los países en vías de desarrollo que modelen el tercer y cuarto momento, se parte de un modelo ARMA-GARCH asumiendo que Zt sigue una distribución que incorpora colas pesadas y asimetría, con el fin de tener un mayor acercamiento a la evidencia empírica para datos de alta frecuencia.
En la siguiente sección se define la distribución t de Student asimétrica propuesta por Hansen (1994), la cual se utiliza como función de distribución de Zt, y posteriormente se presenta el concepto de densidad condicional autorregresiva para modelar la asimetría y la curtosis condicionales.
1. Distribución t de Student asimétrica
La función de densidad de una variable aleatoria distribuida t de Student asimétrica con ν grados de libertad y con parámetro de asimetría λ es:
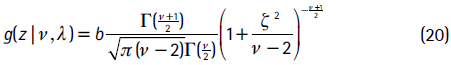
donde
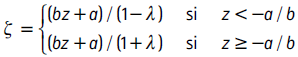
y la función de distribución (CDF) es:
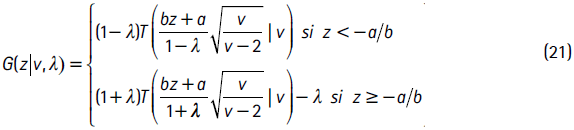
donde T(x|ν) es la CDF de la distribución estándar t con v grados de libertad y los términos a y b son:
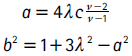
donde
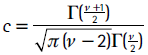
Jondeau et al. (2007) muestran que g(z|ν,λ) está definida si el dominio de los parámetros es (ν,λ) ]2, + 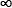 [×]−1,1. En la figura 1 se encuentra la comparación de una variable aleatoria distribuida t estándar con una distribuida t asimétrica para distintos grados de libertad y parámetros de asimetría.
[×]−1,1. En la figura 1 se encuentra la comparación de una variable aleatoria distribuida t estándar con una distribuida t asimétrica para distintos grados de libertad y parámetros de asimetría.
El concepto de densidad condicional autorregresiva se aplica cuando los parámetros de grados de libertad y asimetría varían en el tiempo. Básicamente, la idea detrás de este enfoque es especificar una dinámica para los parámetros νt y λt. Siguiendo a Hansen (1994), Lambert y Laurent (2002), Jondeau y Rockinger (2003) y Jondeau et al. (2007), en este documento se consideran las siguientes especificaciones para los dos parámetros:
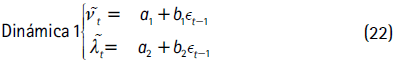
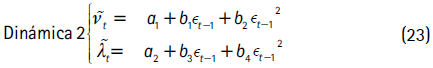
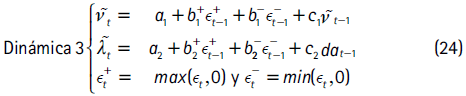
con νt = I]2,30[(νt) y λt = I]-1,1[(λt), tal que I]L,U[ es la transformación logística.
Esto permite asegurar que los parámetros estén en el dominio para el cual la densidad está definida6. A partir de las series λt y νt, la asimetría y la curtosis condicionales de la distribución se obtienen de forma analítica usando las ecuaciones (25) y (26), respectivamente:
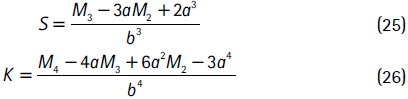
donde
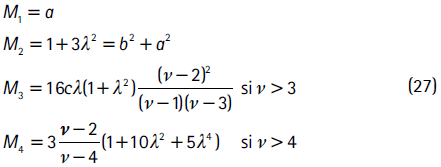
Existen varios aspectos por resaltar de la distribución t de Student asimétrica. Por ejemplo, si λ = 0, la función de densidad presentada en (20) toma la forma de una t de Student tradicional y, además, si ν → , esta se reduce a una distribución normal estándar.
2. VaR y CVaR
Para capturar la presencia de colas pesadas y asimetría, se asume que zt sigue una distribución t asimétrica, en donde el tercer y cuarto momento son modelados a partir de diferentes especificaciones para los parámetros de grados de libertad y asimetría. Esto permite que la distribución varíe en el tiempo y sea más flexible. Así, según esta metodología, el VaR y el CVaR son:
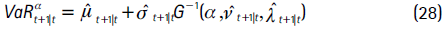
y
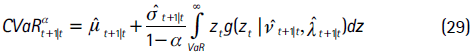
donde G−1(α, 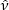 t,
t, 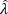 t) es la función inversa de la distribución t asimétrica7.
t) es la función inversa de la distribución t asimétrica7.
En este documento, además de incorporar la función de distribución t asimétrica para zt, se incluyeron algunas especificaciones adicionales de la volatilidad, con el objetivo de modelar mejor las asimetrías de los retornos sobre la volatilidad de las series.
Es de esperar que el mercado reaccione de forma distinta ante un retorno negativo y uno positivo (leverage effect). En el primer caso puede que la reacción del mercado sea más fuerte, dado que los retornos negativos no son deseados por los inversionistas. Específicamente, las definiciones de volatilidad utilizadas para capturar dichas asimetrías son:
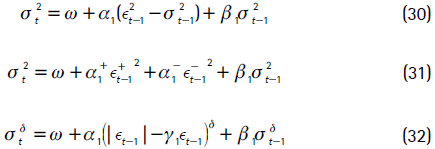
Las especificaciones de volatilidad de las ecuaciones (30), (31) y (32) fueron propuestas por Hansen (1994), Jondeau et al. (2007) y Ding, Granger y Engle (1993), respectivamente.
III. Backtesting
Las pruebas de backtesting permiten verificar si el desempeño del VaR es adecuado. Para esto se construye la serie de excepciones o fallas It+1|t que se define como:
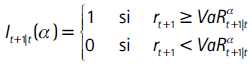
de forma tal que It+1|t se distribuye Bernoulli(p) con p = 1−α = E(It+1|t(α)). Si el VaR está bien especificado, esta serie cumple con dos propiedades:
- Cubrimiento incondicional: esta propiedad hace referencia a que la probabilidad con la que se generan pérdidas superiores al VaR (excepciones) debe ser exactamente 1−α; si esta probabilidad es mayor (menor), el riesgo se está subestimando (sobrestimando).
- Independencia: es la propiedad de que cualquier par de observaciones (It+j|t+j-1, It+k|t+k+1)
 j ≠ k deben ser independientes.
j ≠ k deben ser independientes.
A continuación se describen las pruebas de backtesting utilizadas en este documento.
A. Kupiec
Esta prueba verifica el cumplimiento de la propiedad de cubrimiento incondicional utilizando la hipótesis nula Ho : p = 1−α, la cual se puede contrastar usando una prueba de razón de verosimilitud, definida como:
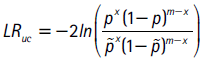
donde x es el número de excepciones, m el número de observaciones incluidas en el backtesting y % 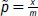 . Según la hipótesis nula, la distribución asintótica de esta prueba es X2 con un grado de libertad.
. Según la hipótesis nula, la distribución asintótica de esta prueba es X2 con un grado de libertad.
B. Pruebas de Christoffersen
Estas pruebas verifican las dos propiedades comentadas anteriormente. Para tal efecto, Christoffersen, Diebold y Santomero (2003) suponen que las realizaciones de la sucesión de variables aleatorias  siguen una cadena de Markov de orden uno, de modo que la matriz de transición de la serie es:
siguen una cadena de Markov de orden uno, de modo que la matriz de transición de la serie es:
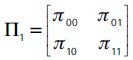
donde πij = P(It+1|t(α) = j | It|t-1(α) = i) con i, j = {0,1} son las probabilidades de transmisión de la cadena de Markov, tales que πi0 + πi1 = 1, con lo cual la matriz de transición se puede reescribir como:
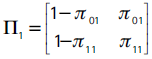
y cuya función de verosimilitud es:
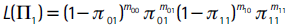
mij es el número de observaciones en las cuales It+1|t(α) = j e It|t-1(α) = i, con m00 + m01 + m10 + m11 = m, siendo m el número total de observaciones usadas en el backtesting, donde el estimador de máxima verosimilitud de Π1 es:
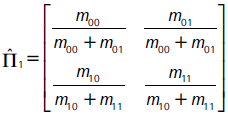
Con el supuesto de independencia π01 = π11 = π, la matriz de transición toma la forma:
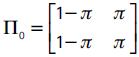
Christoffersen et al. (2003) prueban la hipótesis nula H0 : π01 = π11 con una prueba de razón de verosimilitud que se distribuye asintóticamente χ2 con un grado de libertad:
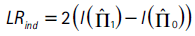
donde l(.) = log(L(.)) y 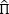 0 es la matriz de transición Π0 evaluada en
0 es la matriz de transición Π0 evaluada en 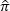 , y
, y 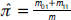 .
.
La propiedad de cubrimiento incondicional que anteriormente se verificó mediante la prueba de Kupiec, también puede ser calculada en el contexto de Christoffersen. En esta prueba la hipótesis nula es Ho : p = 1−α y su estadístico se basa en una prueba de razón de verosimilitud:
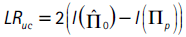
donde Πp corresponde a la matriz de transición Π0 evaluada en π = p = (1−α). Si se desea probar simultáneamente las propiedades de cubrimiento incondicional e independencia, se debe cumplir que H0 : π01 = π11 = p, hipótesis que se puede probar utilizando la siguiente prueba de razón de verosimilitud:
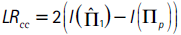
Según la hipótesis nula, el estadístico LRcc se distribuye asintóticamente χ2 con dos grados de libertad. Christoffersen et al. (2003) demuestran que este estadístico también se puede calcular como:
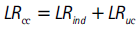
C. Backtesting sobre el CVaR
En Becerra y Melo (2008) se menciona una prueba para evaluar el CVaR, la cual parte del hecho de que la diferencia entre el promedio de las pérdidas mayores al VaR y el CVaR debería ser cero. Para esto se construye la serie de excesos Ht|t−1(pha) definida como:
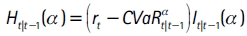
Si el CVaR está bien especificado, Ht|t-1(α) no debería ser significativamente diferente de cero. La hipótesis nula Ht|t-1(α) = 0 se evalúa como lo advierten McNeil, Frey y Embrechts (2010), a partir de un estadístico t calculado con técnicas bootstrap. Estos autores recomiendan ponderar a Ht|t-1(α) por 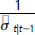 , dado que en general este proceso tiene una varianza que no es constante en el tiempo.
, dado que en general este proceso tiene una varianza que no es constante en el tiempo.
D. Backtesting multinivel
Las estimaciones VaR usualmente se realizan para diferentes valores α. En este contexto, Leccadito et al. (2014) proponen dos pruebas para realizar backtesting multinivel. Es decir, en lugar de realizar pruebas de backtesting para cada nivel α por separado, ellos prueban de forma conjunta si el VaR está bien especificado para distintos valores α. A continuación se describe la metodología propuesta.
Suponiendo que se tienen K diferentes niveles de confianza para estimar el VaR: α1 > α2 > ... > αK, tales que 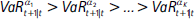 , se construye la siguiente serie de fallas:
, se construye la siguiente serie de fallas:
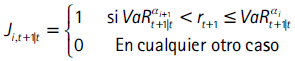
para i =1,...,K, con α0 = 1, αK+1 = 0, 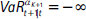 y
y 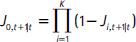 .
.
Adicionalmente, es necesario construir la serie Nt, tal que Nt = i cuando Ji,t+1|t = 1 para i = 1,...,K.
La primera prueba que Leccadito et al. (2014) plantean es una generalización del test de Christoffersen (1998). En el caso multinivel se considera la siguiente matriz de transición:
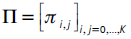
donde πi,j = P(Jj,t+1|t = 1 | Ji,t|t−1 = 1). Con la hipótesis de independencia, todas las filas en la matrix Π son iguales: Ho,ind : π0,j = π1,j = ... = πk,j para j = 0,...,K−1. La función log de verosimilitud asociada a esta prueba es:
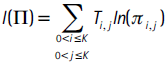
por lo cual, el estadístico de razón de verosimilitud es:
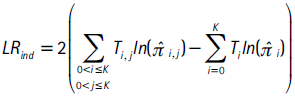
con i,j = Ti,j/Ti y i = Ti/T, donde Ti,j denota el número de observaciones en la muestra de Nt en las cuales las fallas pasan del caso i al caso j, con i, j = 0,...,K, y Ti es el número total de fallas de tipo i . Esta prueba se distribuye asintóticamente χ2 con K2 grados de libertad.
En este contexto, la propiedad de cubrimiento incondicional se evalúa usando la siguiente prueba de razón de verosimilitud:
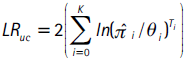
donde θi = αi − αi+1 para i = 0,1,...,K. Si K = 1 se obtiene el test de Kupiec ya descrito. Esta prueba se distribuye asintóticamente χ2 con K grados de libertad.
Por último, en la prueba de cubrimiento condicional donde simultáneamente se prueban las propiedades de independencia y cubrimiento incondicional, la hipótesis nula es: Ho,cc : π0,j = π1,j = ... = πk,j = θj para j = 0,...,K−1. En este caso, la prueba de razón de verosimilitud es:
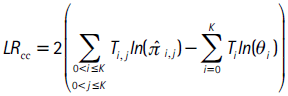
Esta prueba se distribuye asintóticamente χ2 con K2 + K grados de libertad.
La segunda prueba propuesta por Leccadito et al. (2014) es la multinivel de Pearson, en la cual se considera la siguiente distribución bivariada:
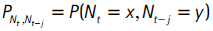
Según la hipótesis nula de cubrimiento condicional, se tiene que:
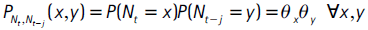
El estadístico para esta prueba es:
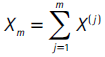
con
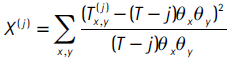
donde 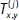 es el número de observaciones en la muestra para las cuales Nt = x, Nt−j = y.
es el número de observaciones en la muestra para las cuales Nt = x, Nt−j = y.
El estadístico Xm corresponde a la suma de variables aleatorias dependientes χ2. Su distribución no es estándar, incluso para muestras grandes. Leccadito et al. (2014) plantean utilizar un procedimiento de Montecarlo para calcular los valores críticos asociados a esta prueba.
E. Funciones de pérdida
Además de probar el cumplimiento de las propiedades de la serie It+1|t(α), es conveniente tener en cuenta las magnitudes de las pérdidas superiores al VaR. Por ejemplo, cuando se cuente con dos estimaciones del VaR apropiadas para un activo, se preferiría aquella que genere las menores pérdidas. En la literatura se encuentran diversas pruebas que evalúan las pérdidas del VaR, que en general asignan un puntaje a través de una función de pérdida. La idea en este enfoque es generar una función de la forma:
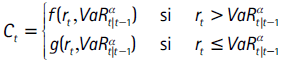
Esta función debe cumplir con la propiedad 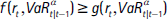 , de tal forma que implique mayores valores cuando existe una pérdida superior al VaR.
, de tal forma que implique mayores valores cuando existe una pérdida superior al VaR.
Posteriormente, se construye un índice de desempeño definido como:

En este contexto, el mejor modelo es aquel que minimiza el índice C. Algunas de las funciones propuestas para este índice son:
- La frecuencia de pérdidas en las colas ajustada por el tamaño (López II) es propuesta por López (1998). Según esta medida la función de Ct se define como:
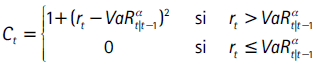
- Caporin (2003) argumenta que las funciones propuestas por López (1998) tienden a descartar modelos apropiados para la medición del riesgo, cuando estos presentan excepciones de gran tamaño. Por lo tanto, propone el uso de las siguientes funciones de pérdidas menos sensibles a valores atípicos, siendo g(.) = 0 y f(.) = Fi para i = 1,2,3, con:
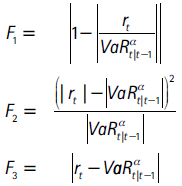
IV. Ejercicio empírico
En este documento se calculan el VaR y CVaR de las siguientes series: el índice general de la Bolsa de Valores de Colombia (IGBC) desde 02/01/2008 hasta 21/02/2014, la tasa de cambio representativa del mercado (TRM) desde 02/01/2008 hasta 21/02/2014 y los TES a veinte años desde 20/03/2009 hasta 21/02/2014. En total se consideraron doce métodos para modelar las medidas de riesgo, seis de los cuales incluyen la función de distribución t de Student asimétrica y, de estos, cuatro modelan la asimetría y la curtosis. Finalmente, los seis restantes corresponden a métodos tradicionales (simulación histórica, normalidad, RiskMetrics y ARMA-GARCH8) y dos de ellos consideran que los errores estandarizados siguen una función de distribución t de Student (ARMAGARCH y ARMA-APGARCH). Las seis metodologías alternativas son:
- Jondeau et al. (2007): esta metodología considera un ARMA(p,q) para modelar el primer momento de los retornos, mientras que para el segundo momento se utiliza la siguiente especificación:
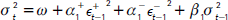 ; por otra parte, se asume que el error estandarizado Zt sigue una distribución t asimétrica con la dinámica 3 (ecuación 24) para los parámetros νt y λt.
; por otra parte, se asume que el error estandarizado Zt sigue una distribución t asimétrica con la dinámica 3 (ecuación 24) para los parámetros νt y λt. - Hansen (1994): en este caso se utiliza un ARMA(p,q) para el primer momento de los retornos, la varianza se modela usando:
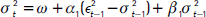 y los errores zt se distribuyen t asimétricos con la dinámica 2 (ecuación 23).
y los errores zt se distribuyen t asimétricos con la dinámica 2 (ecuación 23). - Jondeau et al. (2007) con ν y λ constantes: modela los primeros dos momentos de forma similar a la metodología 1 de Jondeau et al. (2007), aunque se asume que zt sigue una distribución t asimétrica con ν y λ constantes en el tiempo.
- Jondeau y Rockinger (2003): en este caso se utiliza un método ARMA(p,q) para el primer momento de rt, mientras que la varianza condicional está descrita por:
y zt se distribuye t asimétrica utilizando la dinámica 1 (ecuación 22) para los parámetros de la distribución. - ARMA-APGARCH: dada la posible existencia de un efecto de apalancamiento en las series, en este método se utiliza un APGARCH para la volatilidad:
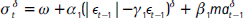 . Los demás componentes se modelan igual que la metodología 1 de Jondeau et al. (2007).
. Los demás componentes se modelan igual que la metodología 1 de Jondeau et al. (2007). - ARMA-APGARCH constante: modela el primer y segundo momento de forma análoga a la metodología 5 (ARMA-APGARCH), mientras que Zt sigue una distribución t asimétrica, con ν y λ constantes.
V. Resultados
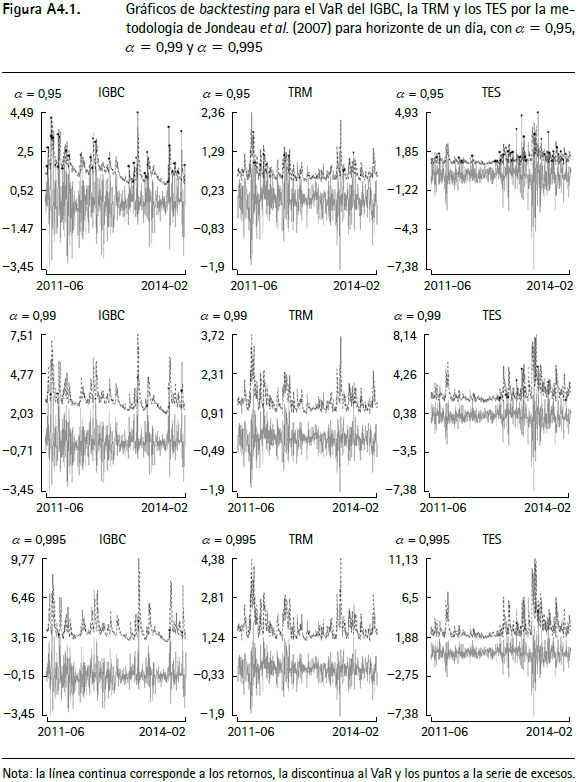
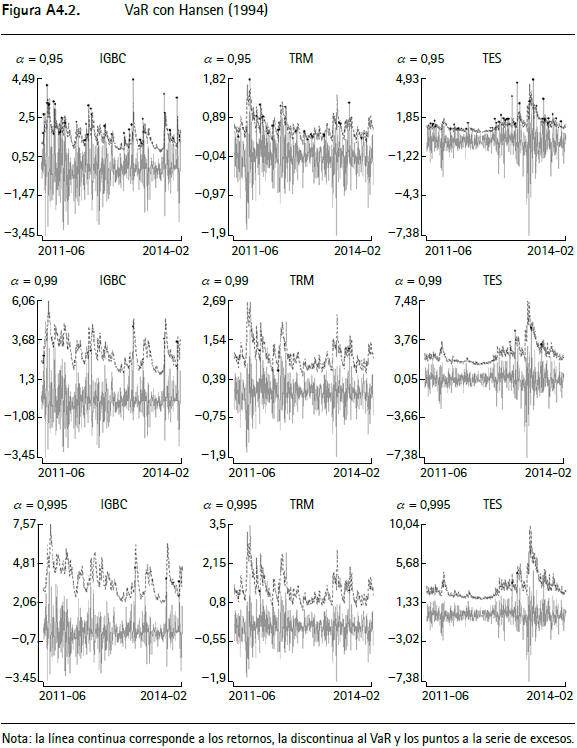
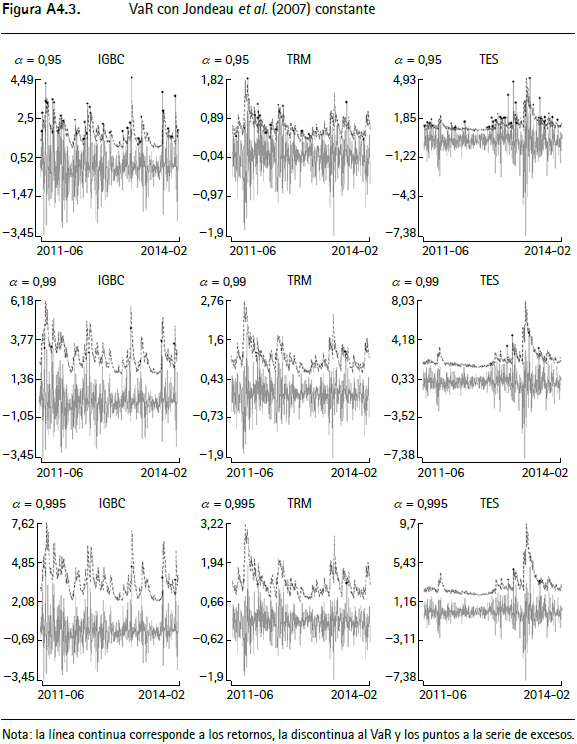
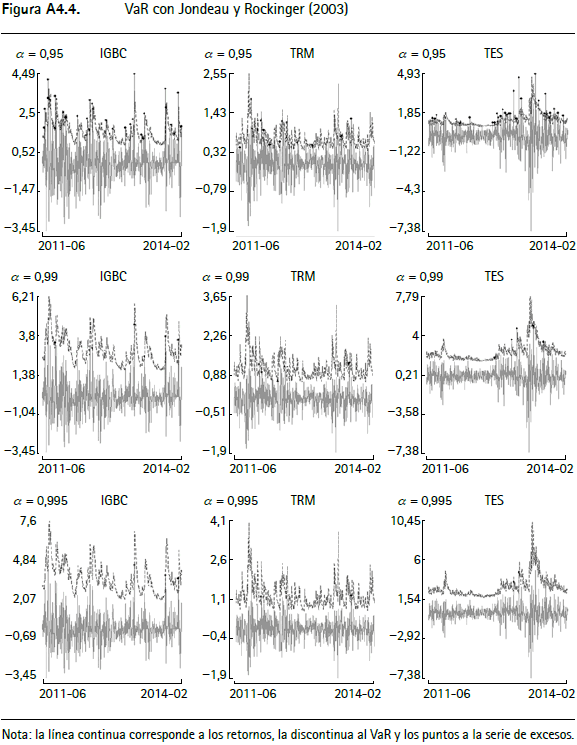
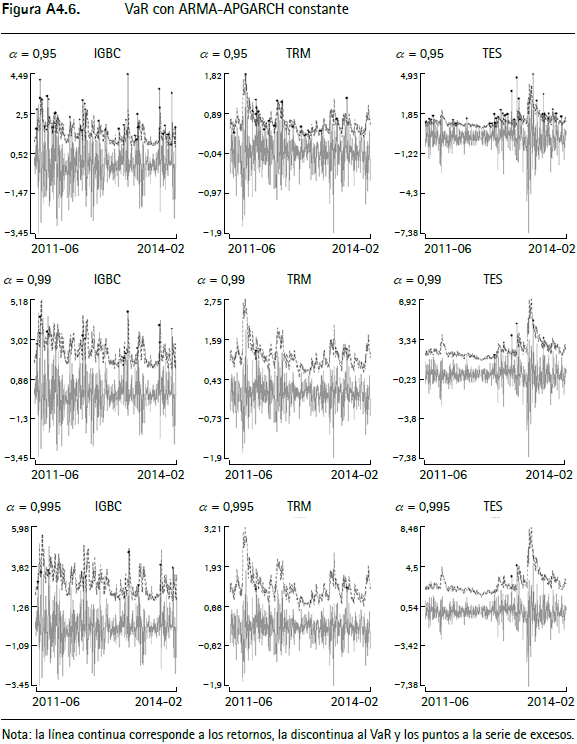
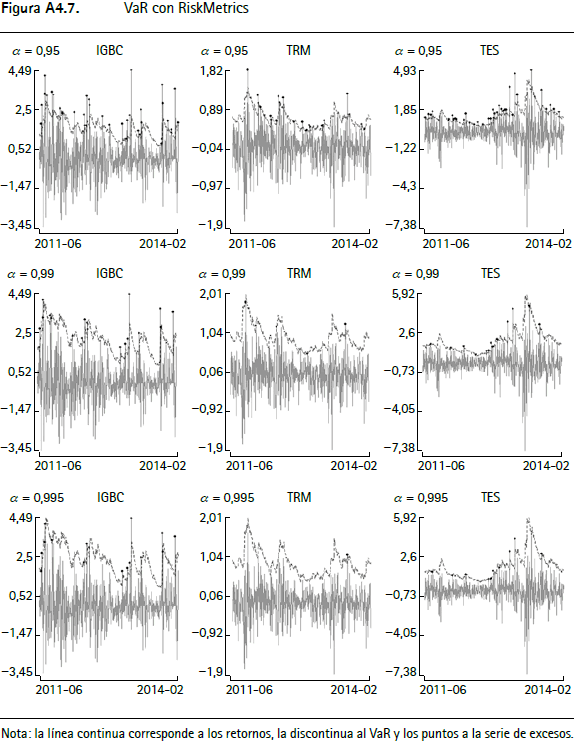
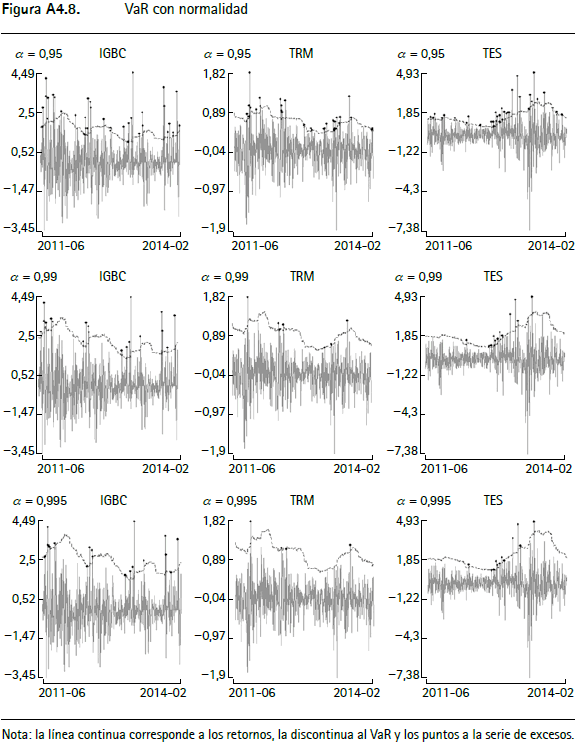
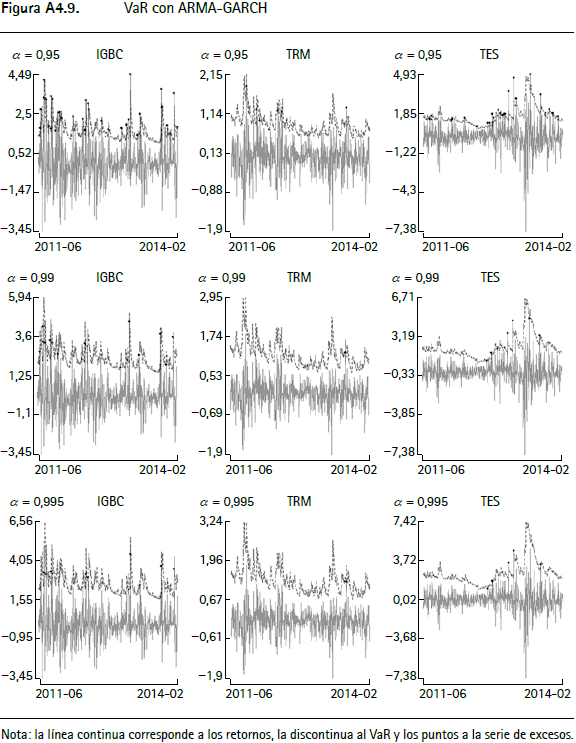
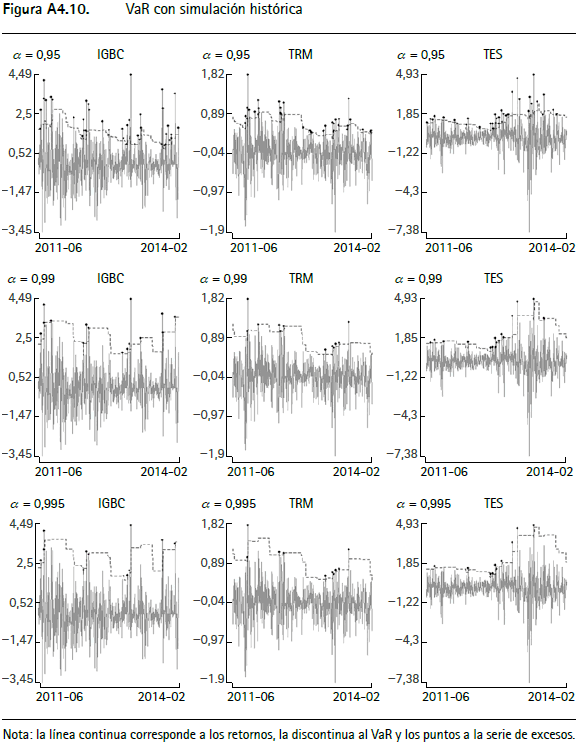
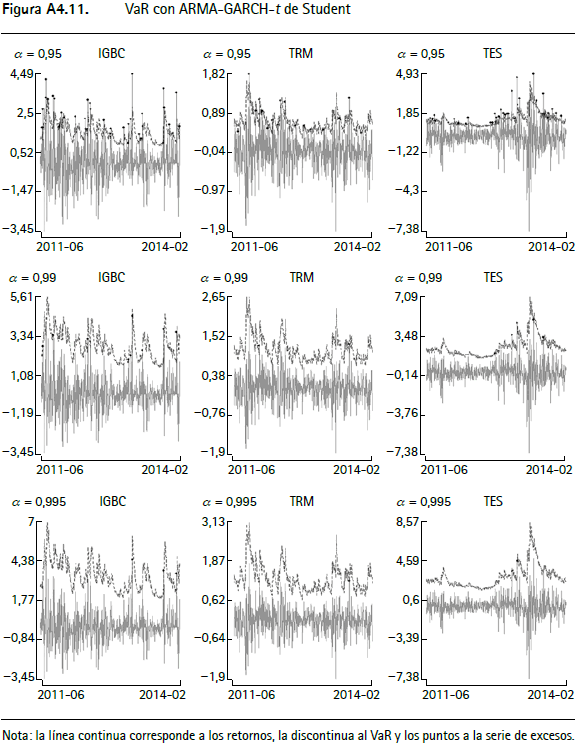
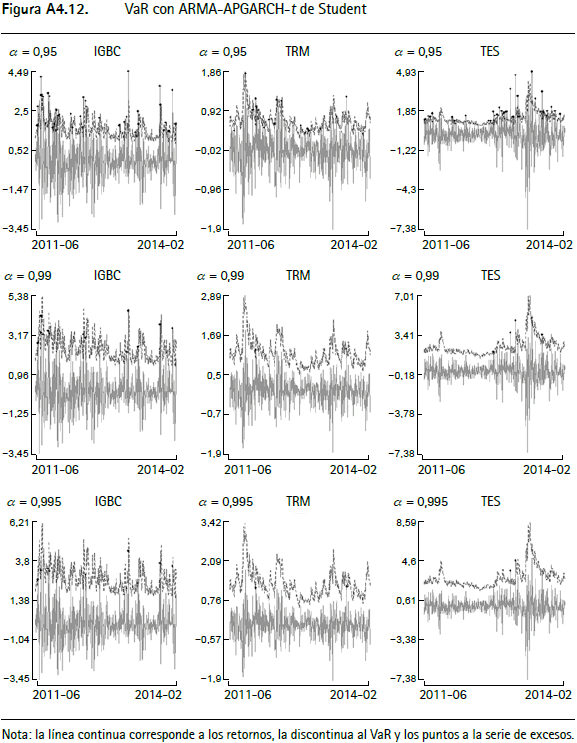
En las figuras A4.1 a A4.12 (anexo 4) se encuentran los gráficos de backtesting del VaR para el IGBC, la TRM y los TES para cada metodología empleada con un horizonte de pronóstico de un día y α = 0,95, α = 0,99 y α = 0,9959.
La línea continua corresponde a los retornos, la punteada al VaR y los círculos negros a la serie de excesos. En general, aquellas series que modelan la varianza condicional presentan un mejor comportamiento y las que modelan el tercer y cuarto momento de los retornos incorporan comportamientos asociados a distribuciones de colas más pesadas que las metodologías tradicionales10.
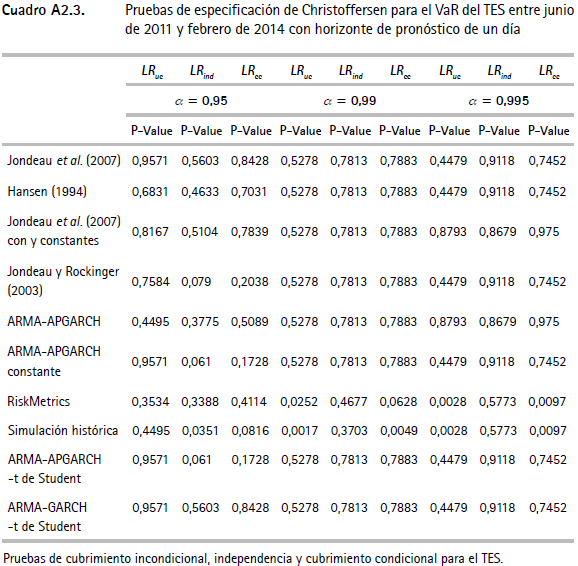
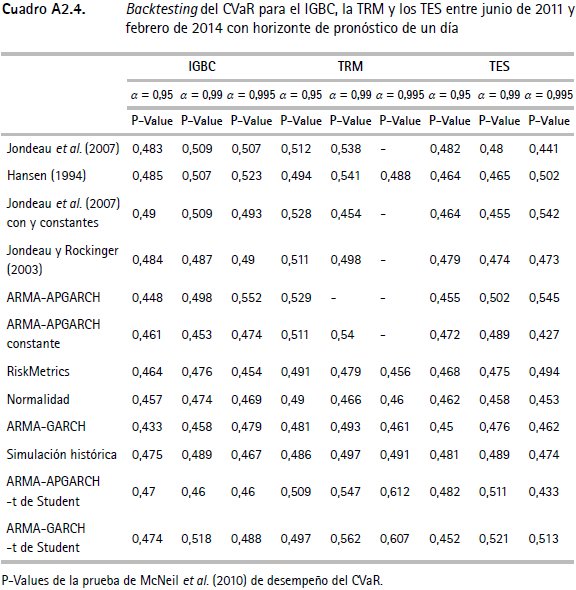
Los cuadros A2.1, A2.2 y A2.3 (anexo 2) muestran las pruebas de backtesting propuestas por Christoffersen et al. (2003) para el VaR del IGBC, la TRM y los TES. En estos cuadros se presentan los valores p para los estadísticos de razón de verosimilitud LRuc, LRind, LRcc. En el cuadro A2.4 se presentan los resultados del test empleado para verificar el desempeño del CVaR de cada serie. Tanto en los cuadros de especificación de Christoffersen como en los del CVaR, se encuentran los resultados para los tres niveles de confianza utilizados en el ejercicio (α1 = 0,95, α2 = 0,99 y α3 = 0,995).
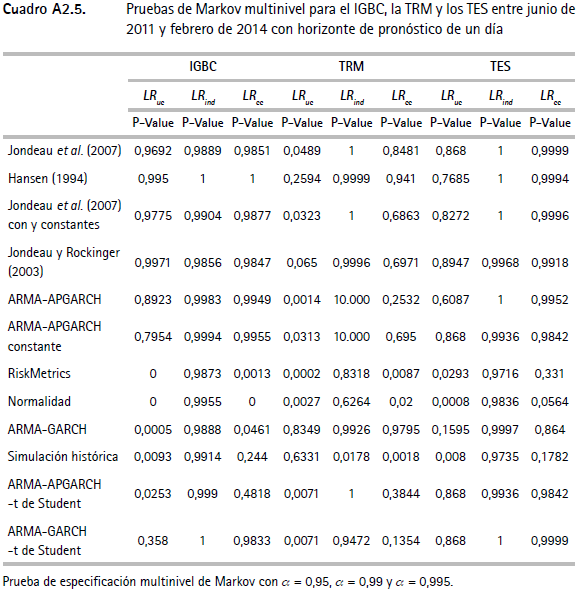
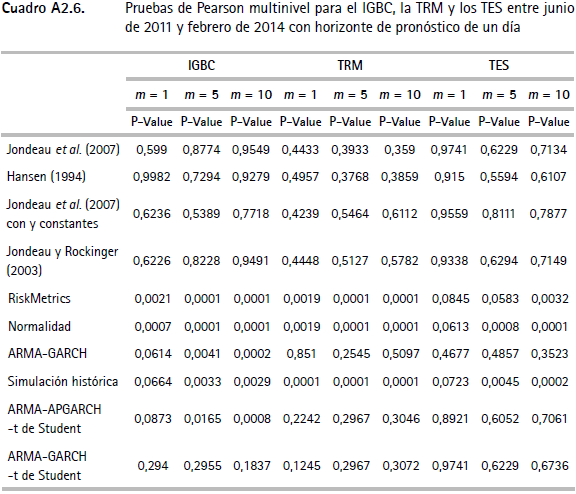
Las pruebas de backtesting del VaR para el IGBC (cuadro A2.1) no muestran indicios de una mala especificación para siete de las doce metodologías, específicamente para Jondeau et al. (2007), Hansen (1994), Jondeau et al. (2007) constante, Jondeau y Rockinger (2003), ARMA-APGARCH, ARMA-APGARCH constante y ARMA-GARCH-t de Student. Este hecho se verifica por el test de Markov multinivel (cuadro A2.5), ya que al evaluar la especificación del valor en riesgo para los tres niveles de confianza en forma conjunta, no muestra evidencia de no cumplimiento del supuesto de cubrimiento incondicional o del de independencia. Contrariamente, este test señala que las metodologías restantes (RiskMetrics, normalidad, ARMA-GARCH, simulación histórica y ARMAAPGARCH-t de Student) no cumplen el supuesto de cubrimiento incondicional, un resultado que se repite con la prueba de Pearson (cuadro A2.6).
Por otra parte, para el VaR de la TRM (cuadro A2.2), únicamente las metodologías de Hansen (1994) y ARMA-GARCH no muestran evidencia de mala especificación según los test presentados. En este caso se encuentra evidencia para rechazar la hipótesis de cubrimiento incondicional para la mayoría de los modelos. En cuanto al VaR de los TES (cuadro A2.3), se encuentra que nueve de las doce metodologías (Jondeau, et al., 2007; Hansen, 1994; Jondeau et al., 2007 constante; Jondeau y Rockinger, 2003; ARMA-APGARCH, ARMA-APGARCH constante, ARMA-GARCH, ARMA-APGARCH-t de Student y ARMA-GARCH-t de Student) no presentan evidencia de mala especificación de acuerdo con las pruebas empleadas, mientras que las metodologías RiskMetrics, de normalidad y de simulación histórica rechazan la hipótesis nula de cubrimiento condicional.
Respecto al desempeño del CVaR, los resultados presentados en los cuadros A2.4 a A2.6 indican que no existe evidencia de una mala especificación para todas las metodologías consideradas.
En los cuadros A2.5 y A2.6 se muestran los p-values asociados a las pruebas de especificación conjunta del VaR (Markov y Pearson multinivel) para los tres niveles de confianza empleados. Para el IGBC se encuentra que en las metodologías de RiskMetrics, normalidad, ARMA-GARCH y simulación histórica se rechaza la hipótesis nula de cubrimiento condicional del test de Pearson y de cubrimiento incondicional de la prueba de Markov, mientras que en el VaR de la TRM y de los TES por RiskMetrics, normalidad y simulación histórica hay evidencia de mala especificación de acuerdo con las dos pruebas multinivel.
En los cuadros A3.1, A3.2 y A3.3 (anexo 3) se presentan las funciones de pérdida de López II y las de Caporin (F1, F2 y F3). En general, se encuentra que las metodologías que utilizan la función de distribución t asimétrica presentan menores puntuaciones en las funciones de pérdida.
Ahora bien, tomando en cuenta únicamente las metodologías que tienen un desempeño adecuado según las pruebas de Christoffersen y las multinivel, se tiene que las metodologías con mejores resultados son: Jondeau et al. (2007) para las series IGBC y TES y Hansen (1994) para la TRM. Cabe señalar que en los casos del VaR de la TRM y de los TES, con α = 0,95, la mejor metodología es ARMA-GARCH; sin embargo, al incrementar el nivel de confianza del VaR (α = 0,99 y α = 0,995) los métodos de Hansen (1994) y de Jondeau et al. (2007), respectivamente, presentan los mejores resultados en cuanto al desempeño de las funciones de pérdida.
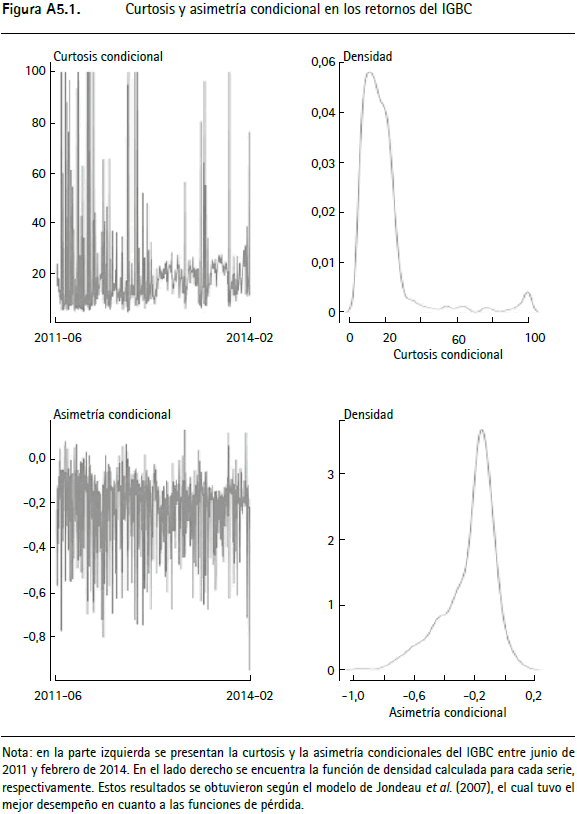
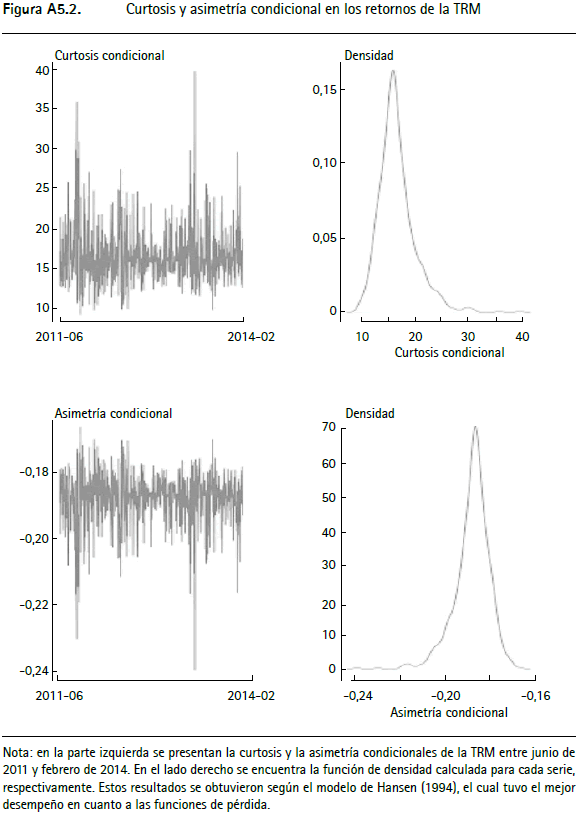
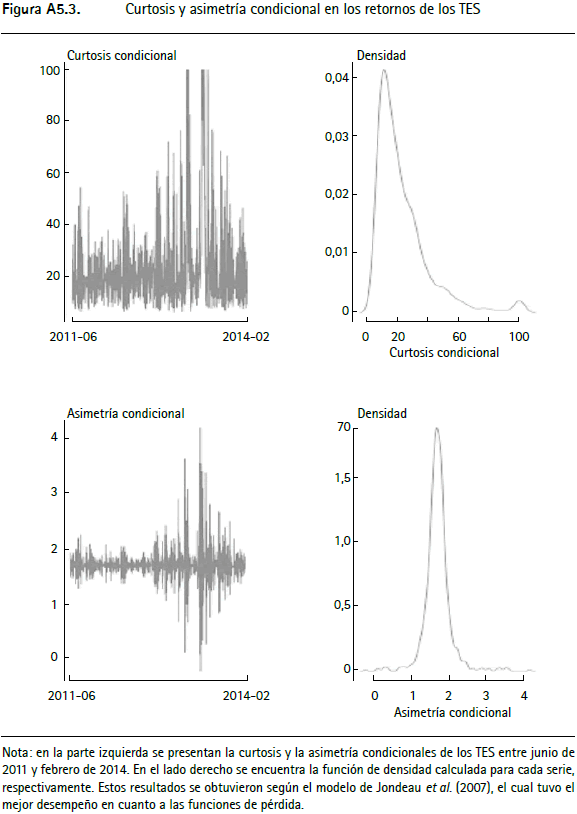
Partiendo de las metodologías que presentan el mejor desempeño en el VaR para el IGBC, la TRM y los TES, en las figuras A5.1 a A5.3 (anexo 5) se presentan la curtosis y la asimetría condicionales11, junto a su densidad empírica. En dichas figuras se observa que para las tres series empleadas, los momentos tres y cuatro presentan alta volatilidad a lo largo del tiempo. La curtosis llega a tomar valores muy altos, seguidos de periodos en los cuales tiene caídas repentinas. Este hecho no puede ser modelado con las metodologías tradicionales, dado que suponen que el tercer y cuarto momento son invariantes en el tiempo.
Por último, se realizó la extensión del pronóstico a diez días para las metodologías especificadas y se obtuvieron resultados similares a Melo y Becerra (2006). En general, ninguno de los modelos presenta una buena especificación ni un desempeño adecuado, debido al aumento de incertidumbre a medida que se incrementa el horizonte de pronóstico. Teniendo en cuenta esto, no se incluyeron en el documento tales resultados.
En resumen, es adecuado el desempeño de las medidas del riesgo que utilizan la distribución t de Student asimétrica. Asimismo, estas metodologías presentan mejores desempeños en cuanto a las funciones de pérdida. Específicamente, las técnicas con mejores resultados son las dos de Jondeau et al. (2007) y la de Hansen (1994), las cuales modelan la asimetría y la curtosis condicionales. Por otro lado, la mayoría de los ejercicios relacionados con las metodologías tradicionales para calcular el VaR (RiskMetrics, normalidad, ARMA-GARCH, simulación histórica) presentan evidencia de una mala especificación para niveles altos de confianza (α = 0,99512).
En el análisis del riesgo de mercado es importante realizar evaluaciones para eventos muy extremos (niveles de confianza muy altos). A este respecto, los anteriores resultados indican que cuando se presenta este tipo de eventos, las medidas VaR y CVaR deben considerar metodologías que modelen de forma apropiada las dinámicas de las series y las colas pesadas de las distribuciones en consideración. Los ejercicios realizados muestran que las metodologías que logran modelar estos comportamientos de forma adecuada, son las que utilizan la distribución t asimétrica y que modelan la asimetría y la curtosis condicionales.
VI. Comentarios finales
En este documento se calculó el VaR y el CVaR para tres series financieras colombianas, utilizando metodologías tradicionales y otras que incluyen la modelación de la asimetría y la curtosis condicionales y, además, se consideran las distribuciones asimétricas. Posteriormente se realizaron varias pruebas de especificación para cada medida del riesgo y se calcularon varias funciones de pérdida para evaluar el desempeño de cada método.
En síntesis, la mayoría de las metodologías utilizadas para calcular el VaR y el CVaR no presentaron evidencia de una mala especificación para el IGBC y los TES. En el caso de la TRM se debe tener más cuidado, ya que únicamente dos metodologías (Hansen, 1994, y ARMA-GARCH) logran modelar de forma adecuada las medidas del riesgo. Cabe señalar que para las tres series empleadas el desempeño de las metodologías que incorporan distribuciones asimétricas y que modelan la asimetría y la curtosis condicionales es, en general, superior al de las metodologías tradicionales. Este resultado es de especial utilidad, porque permite obtener una medida del riesgo con mejor desempeño, que tiene el potencial de modelar comportamientos asimétricos y de colas pesadas.
Reconocimientos
Los autores expresan sus profundos agradecimientos al Comité Editorial de la revista Desarrollo y Sociedad por sus oportunas sugerencias a esta investigación, así como a los evaluadores, cuyos comentarios permitieron fortalecer los resultados encontrados. La investigación desarrollada para escribir este artículo no tuvo ninguna financiación institucional.
_____________________________
Notas al pie
3 Los modelos ARMA-GARCH permiten definir otras funciones de distribución para los errores estandarizados y en su versión más sencilla se asume normalidad.
4 Dicha función no necesariamente tiene una solución analítica.
5 Unas definiciones más detalladas de estas metodologías se pueden encontrar en Dowd (2003), Tsay (2005), Melo y Becerra (2006), Jorion (2007) y Alexander (2009), entre otros.
6 Dicha acotación a los parámetros no asegura la existencia de la asimetría o la curtosis. Al igual que en Jondeau y Rockinger (2003), no se restringe el dominio de los parámetros a νt ≥ 4, con el fin de que sean los datos los que determinen la existencia del tercer y cuarto momento.
7 Esta función está definida en Jondeau et al. (2007).
8 En este modelo se asume que los errores estandarizados siguen una distribución normal.
9 El ejercicio de backtesting se realizó sobre las últimas 655 observaciones. En este procedimiento las estimaciones de los parámetros de los modelos no se mantienen constantes y se reestiman cada diez observaciones.
10 Los resultados de la prueba de Dickey y Fuller aumentada (ADF) y la de Kwiatkowsky, Phillips, Schmidt y Shin (KPSS), presentados en el cuadro A1.1 (anexo 1), indican que las series analizadas son estacionarias. Igualmente, los resultados del cuadro A1.2 sugieren que existe evidencia de efectos ARCH sobre las variables consideradas.
11 La curtosis y la asimetría condicionales se calculan a partir de las ecuaciones (26), (25) y (27), utilizando los parámetros modelados (_ , _ ) t, según la dinámica de cada metodología.
12 Este tipo de resultados también se obtienen para algunos casos cuando se utiliza un nivel de confianza de a = 0,99.
Referencias
1. Alexander, C. (2009). Market risk analysis, value at risk models (vol. 4). John Wiley & Sons. [ Links ]
2. Artzner, P., Delbaen, F., Eber, J.-M., & Heath, D. (1999). Coherent measures of risk. Mathematical finance, 9(3), 203-228. [ Links ]
3. Becerra, O., & Melo, L. (2008). Medidas de riesgo financiero usando cópulas: teoría y aplicaciones (Borradores de Economía 489). Banco de la República. [ Links ]
4. Caporin, M. (2003). Evaluating value-at-risk measures in presence of long memory conditional volatility. GRETA, 5. [ Links ]
5. Christoffersen, P. F. (1998). Evaluating interval forecasts. International Economic Review, 841-862. [ Links ]
6. Christoffersen, P. F., Diebold, F. X., & Santomero, A. M. (2003). Elements of financial risk management. CiteSeer. [ Links ]
7. Ding, Z., Granger, C. W., & Engle, R. F. (1993). A long memory property of stock market returns and a new model. Journal of Empirical Finance, 1(1), 83-106. [ Links ]
8. Dowd, K. (2003). An introduction to market risk measurement. John Wiley & Sons. [ Links ]
9. Durán, R., Lorenzo, A., & Ruiz, A. (2012). A GARCH model with autoregressive conditional asymmetry to model time-series: An application to the returns of the Mexican stock market index. Avances Recientes en Valuación de Activos y Administración de Riesgos, 4, 247-262. [ Links ]
10. Hansen, B. E. (1994). Autoregressive conditional density estimation. International Economic Review, 35(3), 705-730. [ Links ]
11. Jondeau, E., Poon, S.-H., & Rockinger, M. (2007). Financial modeling under non-Gaussian distributions. Springer. [ Links ]
12. Jondeau, E., & Rockinger, M. (2003). Conditional volatility, skewness, and kurtosis: Existence, persistence, and comovements. Journal of Economic Dynamics and Control, 27(10), 1699-1737. [ Links ]
13. Jorion, P. (2007). Value at risk: The new benchmark for managing financial risk (vol. 3). Nueva York: McGraw-Hill. [ Links ]
14. Lai, J.-Y. (2012). Shock-dependent conditional skewness in international aggregate stock markets. The Quarterly Review of Economics and Finance, 52(1), 72-83. [ Links ]
15. Lambert, P., & Laurent, S. (2002). Modelling skewness dynamics in series of financial data using skewed location-scale distributions (Discussion Paper 119). Louvain-la-Neuve: Institut de Statistique. [ Links ]
16. Leccadito, A., Boffelli, S., & Urga, G. (2014). Evaluating the accuracy of value-at-risk forecasts: New multilevel tests. International Journal of Forecasting, 30(2), 206-216. [ Links ]
17. López, J. A. (1998). Methods for evaluating value-at-risk estimates (Technical Report). Nueva York: Federal Reserve Bank. [ Links ]
18. McNeil, A. J., Frey, R., & Embrechts, P. (2010). Quantitative risk management: Concepts, techniques, and tools. Princeton: Princeton University Press. [ Links ]
19. Melo, L., & Becerra, O. (2006). Una aproximación a la dinámica de las tasas de interés de corto plazo en Colombia a través de modelos garch multivariados (Reporte Técnico). Banco de la República. [ Links ]
20. Morgan, J. (1996). Riskmetrics (Technical Document). Nueva York: Morgan Guaranty Trust Company. [ Links ]
21. Tsay, R. S. (2005). Analysis of financial time series (vol. 543). John Wiley & Sons. [ Links ]
Anexos
Anexo 1. Pruebas de raíz unitaria y de efectos ARCH
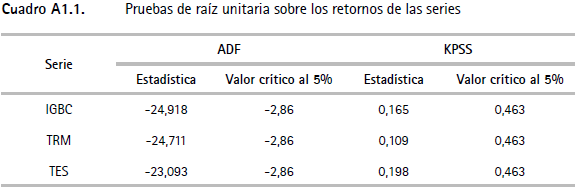
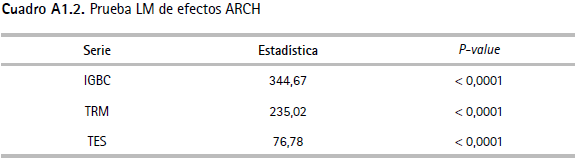
Anexo 2. Pruebas de backtesting
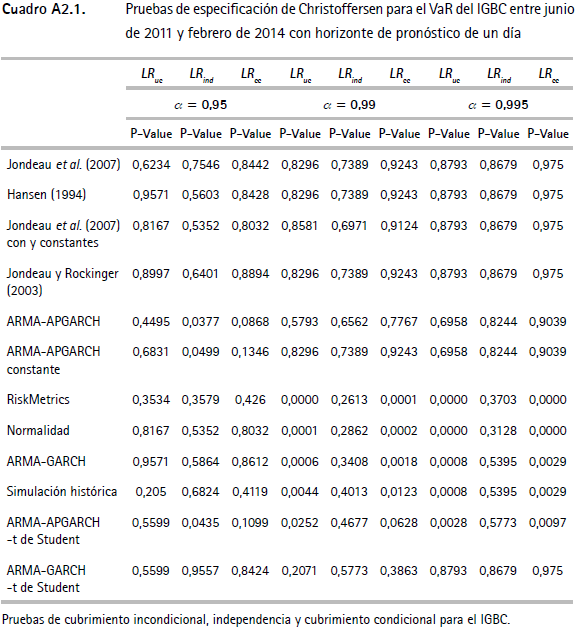
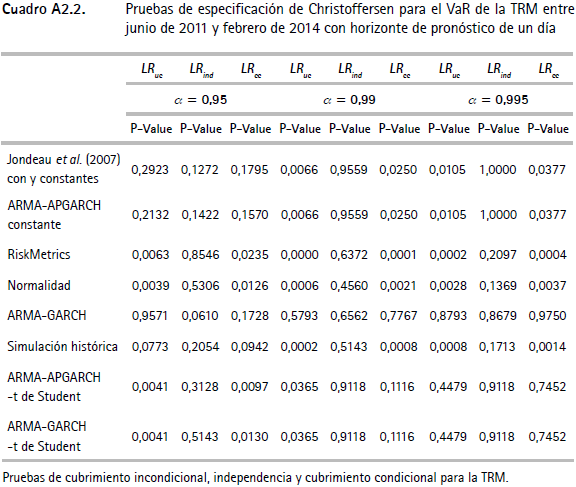
Anexo 3. Funciones de pérdida
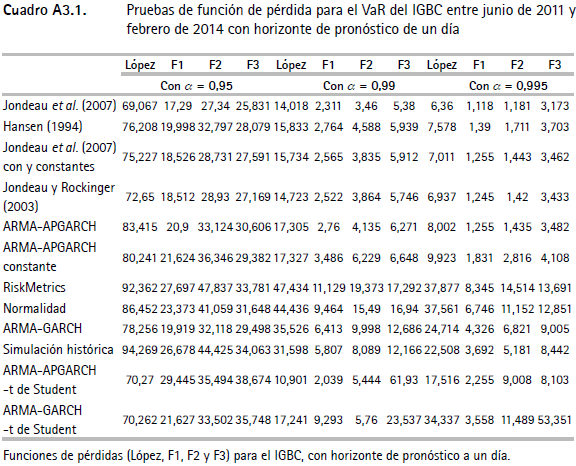
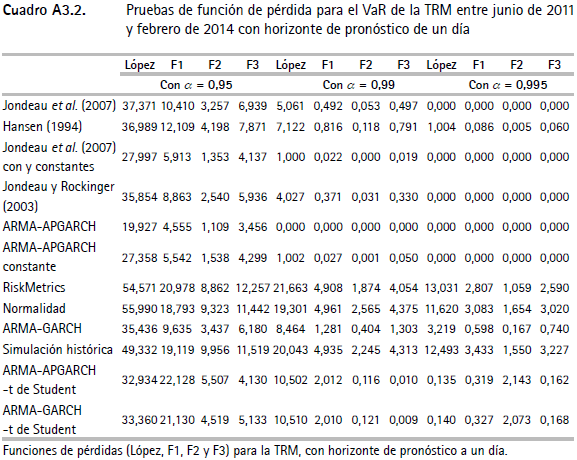
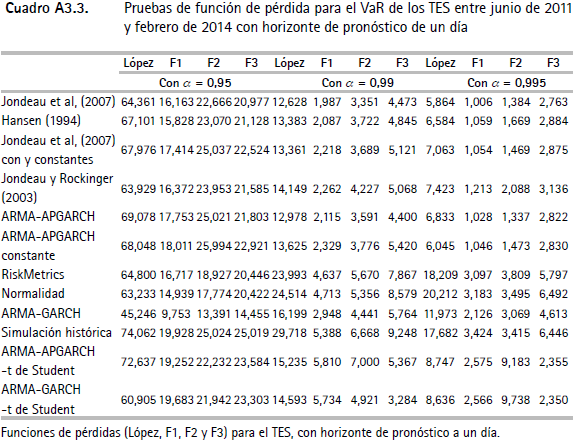
Anexo 4. Gráficos de backtesting para el VaR

Anexo 5. Curtosis y asimetría condicionales