Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroducción
La relevancia política en las métricas de desarrollo de las economías ha venido pasando por un proceso de cambios, pues que el desarrollo sea multidimensional y no pueda ser medido a través de un solo indicador es aceptado y puesto en debate con mayor preponderancia por la comunidad internacional. Bajo esta premisa, es meritorio remontarse a mediados de la década de 1930, cuando salió a relucir una “nueva contabilidad nacional”, para medir el desarrollo de las economías. Ello, debido a que, tras la Gran Depresión (4 de enero de 1934), el producto interno bruto (PIB) fue el indicador con mayor presencia a la hora de tazar el ingreso —o creación de riqueza— de una economía. Formulado por el economista estadounidense Simon Kuznets (1973), el PIB es un indicador que mide la producción generada por un país, tomando en cuenta cierto periodo de tiempo y fronteras geográficas. En ese entonces, este indicador se convirtió en una medida ampliamente aceptada de la prosperidad de una nación.
En esta misma línea surgió el PIB per cápita (PIB pc), como el indicador más acuciante para la cuantificación del desarrollo, debido a que mide la producción entre el total de los habitantes de una nación; no obstante, a pesar de que ambos indicadores aún gozan, aunque menguadamente, de gran aceptación en la academia, en las últimas décadas diversos analistas les han puesto señalamientos críticos. Por ejemplo, como consecuencia de la crisis financiera de 2008, Stiglitz et al. (2010) presentaron su reporte “Malmidiendo nuestras vidas”, en el cual se ponen de manifiesto las limitaciones del PIB como indicador de bienestar y manifiestan que “si utilizamos las métricas equivocadas, tomaremos decisiones también equivocadas”. Así como ese trabajo, existen otras dos iniciativas que comparten la misma concepción, una llevada a cabo por la OCDE (Proyecto global para la medición del progreso de las sociedades) y otra liderada por la Comisión Europea a través de una comunicación de la Comisión al Consejo y el Parlamento Europeo, intitulada “Más allá del PIB”.
Esta concepción de desarrollo pone de manifiesto la gran importancia que tiene hoy la provisión de información estadística sobre el comportamiento de la sociedad en el ámbito económico, social, ambiental e institucional o, lo que es lo mismo, sobre el desarrollo sustentable. El que el desarrollo sea multidimensional y no puede —ni debe— estimarse mediante un único indicador, como el PIB, es aceptado por la comunidad internacional, en especial por las Naciones Unidas con la formulación de la Agenda 2030 para el Desarrollo Sostenible. La Agenda 2030, adjudicada por el Programa de las Naciones Unidas para el Desarrollo (PNUD, 2015, 2020), representa un logro importante, el cual, hasta el momento, ha conseguido forjar un consenso global acerca de las prioridades de desarrollo.
Sin embargo, el alcance y complejidad de los diecisiete objetivos de desarrollo sostenible (ODS) y las 169 metas junto a sus indicadores fijados en la Agenda pueden resultar bastante abrumadores para que los hacedores de políticas consigan orientarse. Es en esta línea que Stiglitz et al. (2018) en su acápite incluido en “For Good Measure” (la continuación de informe “Malmidiendo nuestras vidas” de Stiglitz et al. (2010) inciden en que, para alcanzar los ODS, es necesario seleccionar un delimitado panel de indicadores multidimensionales, con el fin de orientar la planificación y la elaboración de políticas en los países. Frente a ello, iniciativas de diversas organizaciones intentan medir este desarrollo a través de un “resumen” de indicadores relevantes. Por ejemplo, el índice de desarrollo humano (IDH) es un indicador sintético que, desde 1990, mide el desarrollo humano a través de tres variables: ingresos, salud y educación.
Asimismo, desde 2010 hasta 2014, cuatro indicadores compuestos internacionales salieron a relucir: (1) para medir la pobreza, el índice multidimensional de la pobreza; (2) para la desigualdad, el índice de desigualdad ajustado de desarrollo humano; (3) para el empoderamiento de género, el índice de desigualdad de género; y (4) para el desarrollo de género, el índice de desarrollo de género). Otro ejemplo es el índice de competitividad regional de la Unión Europea, elaborado por la Comisión Europea (2019), el cual evalúa el nivel de condiciones de 268 regiones europeas (a nivel de NUTS-2) de veintiocho Estados miembros de la Unión Europea, a través de 74 indicadores reflejados en once dimensiones de competitividad, las cuales, a su vez, se organizan en tres grandes categorías: factores básicos (instituciones, estabilidad macroeconómica, infraestructura, salud y educación básica), factores de eficiencia (educación avanzada, aprendizaje por resultados, eficiencia de la fuerza laboral y tamaño de mercado) y factores de innovación (preparación tecnológica, negocios sofisticados e innovación).
Evidentemente, estos índices son de corte nacional, es decir, su análisis oficial se basa en la comparación de países, por lo que se deja de lado la comparación interna (interdepartamental, interregional o intermunicipal). De ese modo, los nuevos retos de evaluación de desarrollo de forma interna en un país han venido constituyendo un nuevo ámbito de investigación. Así surgen estudios como el de Zaman y Goschin (2014), donde hicieron “una nueva clasificación de los condados rumanos basada en un índice compuesto de desarrollo económico”, el cual abarcó el desempeño del desarrollo regional de Rumania en el periodo 2001-2012. En ese estudio, con una metodología de normalización y ponderación de variables, se construyó un índice de desarrollo regional, tomando en cuenta dos factores influyentes de desarrollo, el primero obedecía a la adhesión de Rumanía a la Unión Europea y el segundo, a la crisis económica financiera de 2008.
Continuando con el análisis en Rumania, Goschin (2015) presentó el estudio “Divergencia regional en Rumania, basada en un nuevo índice de desarrollo económico y social”, en el cual, luego de reconocer el problema de disparidades espaciales, se planteó el objetivo de construir un índice multidimensional que capturara el aspecto económico y social de las 42 ciudades que conforman Rumania, para evaluar posteriormente la convergencia regional en el largo plazo de dicho país. Todo ello, a través de una normalización de datos y cálculos aritméticos concernientes a las variables propuestas, así como de la convergencia sigma (.), cuya metodología contempla pruebas de Dickey Fuller aumentado y de Phillips Perron.
Por su parte, en su tercera edición, Vial (2019) desarrolló el índice de desarrollo regional (Idere), para Chile. Concebido como una herramienta que mide el desarrollo en el nivel territorial, desde una perspectiva multidimensional, a través de una medida geométrica de índices normalizados entre 0 y 1 (donde 0 significa el desarrollo mínimo y 1, el máximo). Este índice considera 32 variables y siete dimensiones claves, que han sido necesarias para constatar las desigualdades territoriales y brechas existentes en Chile. Estas siete dimensiones son: educación, salud, bienestar socioeconómico, actividad económica, conectividad, seguridad y, sustentabilidad y medioambiente.
En esta misma línea, Aboal et al. (2018) elaboraron, para Uruguay, el estudio “Análisis de las inequidades territoriales a partir de indicadores sintéticos”, el cual también tuvo el objetivo de construir un indicador de desarrollo departamental (IDD) que evalúe las disparidades territoriales de ese país. La dimensionalidad del índice recayó en cuatro dimensiones: (1) seguridad ciudadana y sistema de derecho confiable; (2) sociedad influyente, preparada y sana;(3) mercados de factores eficientes y dinámicos, e (4) infraestructura física y tecnológica. A su vez, estas dimensiones fueron conformadas por dieciocho indicadores simples. Este índice sintético fue construido adoptando la metodología del Instituto Mexicano para la Competitividad (Imco), en la elaboración del índice de competitividad estatal (ICE), otro índice multidimensional, que comprende una ponderación de los indicadores simples por opinión de expertos y por un análisis multidimensional (ACP).
En cuanto a Perú, el Instituto Peruano de Economía (IPE, 2020) presenta, desde 2012, el índice de competitividad regional (Incore), único instrumento de medida de corte regional con el que actualmente cuenta el país; no obstante, esta propuesta tiene como principal debilidad no recabar información de la dimensión ambiental y, como se dijo en las líneas antecesoras, uno de los pilares fundamentales para el desarrollo sustentable es la conservación ambiental. Cabe resaltar que esta concepción ambiental es tomada en cuenta como ámbito prioritario, tanto por los ODS del PNUD como por el “Marco de Bienestar” propuesto por la Organización para la Cooperación y el Desarrollo Económico (Ocde), por lo que resulta meritorio estimar un índice sintético teniendo en consideración esta dimensión ambiental.
Por otro lado, en concordancia con los índices de nueva generación, los cuales reconocen la importancia de las cuatro dimensiones mencionadas, pero principalmente la relevancia de tener un índice en la web, a nivel internacional existen algunas plataformas donde se plasma este índice compuesto. Entre ellas, resalta la Plataforma de Análisis para el Desarrollo (PAD) y el Índice Estatal de Capacidades para el Desarrollo Social (Ides), ambos de México (Gesoc AC, 2019). En cuanto al ámbito nacional, Perú posee, dentro del corte regional, el Sistema de Información Regional para la Toma de Decisiones (Sirtod).
Bajo la tutela del Instituto Nacional de Estadística e Informática (2020), desde 2011, este sistema se consolidó como una herramienta para analizar y estudiar el comportamiento de indicadores de distinta índole, con corte regional, en el país (demografía, empleo, salud y educación, etc.). Asimismo, el sistema de monitoreo y seguimiento de los indicadores de los ODS, también elaborado por el Inei, es otro instrumento que estudia la evolución y comportamiento de los ODS en Perú (Inei, 2020). No obstante, a pesar del corte analítico regional, estas innovadoras plataformas solo se dedican a presentar indicadores simples, mas no indicadores sintéticos o compuestos de nueva generación.
Por lo dicho, esta investigación evalúa comparativamente el desarrollo regional en el Perú, a través de la elaboración multivariada de un indicador sintético, denominado índice de desarrollo regional (IDR), en torno a cuatro dimensiones: económica, social, ambiental e institucional. El periodo de referencia para la estimación del IDR captura datos de 2015-2019. Además, con el diseño y estimación del IDR, se realiza un análisis comparativo a nivel de regiones con énfasis en contrastes dimensionales, niveles de convergencia regional y validación metodológica. Asimismo, teniendo en cuenta lo anterior, en la investigación se propone involucrar el diseño de un prototipo de plataforma web iterativa, que sirva como herramienta didáctica para generar valuación valiosa, reflejada a través del IDR y sus dimensiones, principalmente, para los hacedores de política pública.
I. Materiales y métodos
La investigación tuvo un enfoque cuantitativo, con método deductivo, de tipo básica, longitudinal y retrospectiva. En cuanto al alcance, está comprendido por 25 unidades de análisis (24 regiones y la Provincia Constitucional del Callao).
A. Fuentes de información
La información recabada tuvo como principal institución proveedora de datos al Instituto Nacional de Estadística e Informática (INEI), organismo dedicado a efectuar el seguimiento de indicadores sobre las condiciones de vida en Perú. Así, para la descripción de algunos indicadores de población se usó el Censo Nacional de Población y Vivienda 2017, con una población censada de 29 381 884 personas y una población total de 31 237 385 (censada + omitida).
Para el análisis de componentes principales, las variables utilizadas (modificadas y calculadas) tuvieron como fuente de datos a la Encuesta Nacional de Hogares (Enaho) del periodo 2015-2019; con tamaño muestral de 33 430, 38 296, 36 996, 39 820 y 36 994 viviendas particulares para 2015, 2016, 2017, 2018 y 2019; respectivamente.
Asimismo, también se tuvo como fuentes de datos a la Encuesta Demográfica de Salud y Familia (2015-2019), el Registro Nacional de Municipalidades y el Anuario de Estadísticas Ambientales 2019-INEI. Cabe resaltar que las cinco encuestas (2015-2019) presentaron un nivel de confianza del 95 % en los resultados muestrales (el Anexo 1 presenta un resumen de las fuentes de información).
B. Selección de variables (indicadores simples)
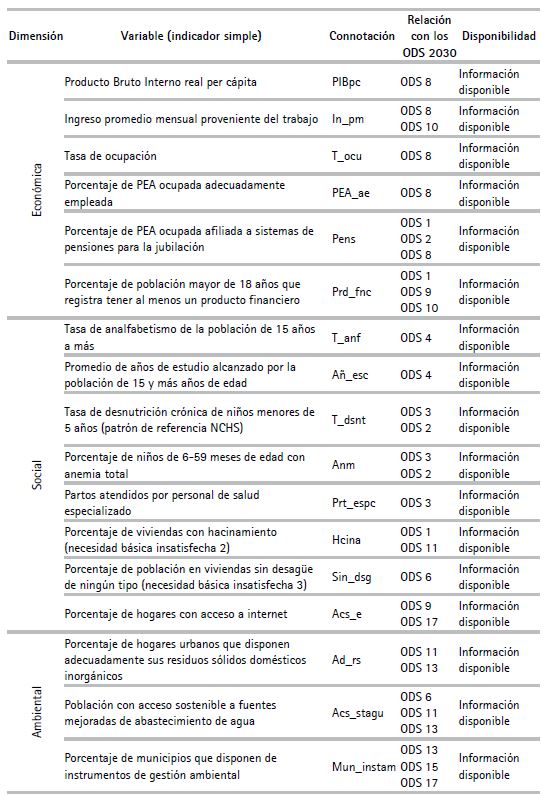
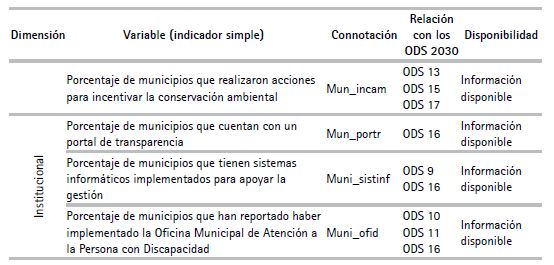
Tomando en cuenta el “Manual para la construcción de indicadores compuestos” de Nardo et al. (2008), publicado por la Ocde en el mismo año, y la “Guía metodológica: diseño de indicadores compuestos de desarrollo sostenible”, preparada por Schuschny y Soto (2009) y publicada por la Cepal en el mismo año, la selección de variables (21 indicadores simples) tuvo tres criterios en su delimitación:
Concomitancia con las dimensiones, es decir, cada dimensión debe contar con variables relevantes.
Relación con los objetivos y, consecuentemente, metas e indicadores de los objetivos de desarrollo sostenible 2030, pues dentro del marco de la investigación, la construcción del IDR es concomitante a la Agenda 2030.
Disponibilidad de información (periodo 2015-2019 y 25 unidades de análisis).
Cabe resaltar que el tercer criterio fue el principal para delimitar las variables utilizadas, pues por razones de exigencia metodológica, en la investigación no se contemplaron métodos de datos perdidos. Por ello, los indicadores de los ODS 5, 7, 12 y 14 —que si bien, son de suma importancia y como los demás ODS forman parte de una cadena de valor— no fueron contemplados, pues la información requerida para estos no presentó el tercer criterio en las fuentes revisadas (para algunos casos en cuanto a unidades de análisis y para otros en el espacio temporal analizado).
En esta línea, a continuación, el cuadro 1 presenta las veintiún variables seleccionadas, de acuerdo con la clasificación y respuesta de los criterios mencio nados.
C. Metodología para la elaboración del IDR
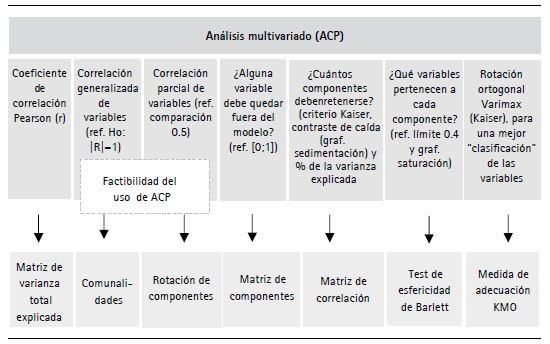
El método escogido para la construcción IDR corresponde al análisis multivariado, específicamente al análisis de componentes principales (ACP), el cual tiene el objetivo de capturar la mayor varianza posible en las variables (indicadores simples), con el menor número de componentes posible. Cabe resaltar que, así como el método ACP, existen otras técnicas cuyo propósito es sintetizar un indicador compuesto varias variables:
El análisis de factores comunes (AFC), el cual solo analiza la varianza común, mientras que el ACP analiza la varianza común y la no común.
El análisis clúster, el cual, de acuerdo con Nardo et al. (2008), sirve como un método puramente estadístico de agregación de indicadores y como una herramienta de diagnóstico de exploración del impacto de las elecciones metodológicas de la fase de construcción del indicador compuesto.
El análisis factorial (AF), el cual se relaciona mucho con el ACP, pero se diferencia en que el primero se basa en sostener los factores que expliquen la mayor parte de la varianza común, mientras que en el segundo se hallan primero los componentes principales (factores), los cuales expliquen la mayor parte de la varianza común (Schuschny y Soto, 2009).
Desde este sustento, el ACP fue elegido para método de análisis, pues, además, es uno de los métodos más estándares representativos en la síntesis de información en distintos campos investigativos (biología, medicina y economía, etc.). Así también, puesto que esta es una de las técnicas con mayor detalle en las fases de estimación, los resultados del ACP tienden a ser más exactos, algunos índices compuestos de nivel internacional que sustentan esto son el business climate indicator, el general indicator of science and technology yel relative intensity of regional problems in the community.
En esta línea, el proceso presentado a continuación (figura 1), se refiere al ACP, mostrando así la transformación del conjunto de las variables seleccionadas en un conjunto reducido de “nuevas” variables sintéticas (denominadas factores o componentes principales).
D. Metodología para el análisis comparativo: natural breaks y convergencia sigma
1. Método de optimización Jenks natural breaks
Para facilitar la comparación de las unidades de análisis en torno a sus IDR, se establecen tres niveles de desarrollo relativo: alto, medio y bajo. Estos niveles, así como el rango comprendido por cada uno, son utilizados tanto para la comparación del IDR global como para las subdimensiones. Para delimitar la extensión de los rangos (intervalos) se utilizó el método Jenks natural breaks (cortes o umbrales naturales), el cual posibilita una mejor disposición de datos en diferentes clases, de esta manera, se asegura que la clasificación de los datos dependa de su naturaleza y distribución.
Entonces, se persigue el doble propósito de extraer clases con gran homogeneidad interna y con máximas diferencias entre clases para el número de intervalos especificado previamente (Jenks, 1967). Es decir, estadísticamente, el método busca reducir la varianza dentro de categorías y maximizar la varianza entre clases. Dicho de otra manera, este método calcula las diferencias de los valores para, posteriormente, poner un límite en forma de separación de clases, donde existan grandes diferencias.
2. Convergencia sigma
Para capturar la tendencia de disparidades regionales de las unidades de análisis y, de este modo, determinar las fluctuaciones del comportamiento de las brechas regionales, se utilizó el método de convergencia sigma (σ), formulado por Barro y Sala-i-Martin (1995). Este método tiene el objetivo capturar la tendencia de las disparidades regionales basadas en la dispersión territorial de indicadores significativos de desarrollo. De acuerdo con León (2013), la convergencia sigma indica que la dispersión de la distribución de ingresos tiende a reducirse en el tiempo y, por ende, se espera que las diferencias o disparidades entre distintas economías también disminuyan.
3. Metodología del coeficiente alfa (σ) de Cronbach
El coeficiente alfa (σ) de Cronbach (1951) trasluce un valor que mide la consistencia interna, es decir que indica cuan bien está representada la información de diversas variables en un solo indicador compuesto. El coeficiente, que toma valores comprendidos en el intervalo [0,1], sirve para comprobar si un índice recopila información defectuosa de las variables que lo componen, o si es fiable y mide lo que se desea medir (Schuschny y Soto, 2009). El coeficiente alfa de Cronbach se calcula como se muestra en la ecuación 1:
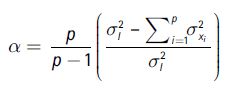 (1)
(1)
Donde:
α corresponde al coeficiente alfa de Cronbach.
l es un indicador compuesto.
p constituye las variables.
σl es la varianza del indicador l.
σxi es la varianza de cada una de las p variables.
De esta forma, el estimador mide la fracción de variabilidad total de la muestra de variables a raíz de su correlación. En caso de que no haya correlación y las variables presenten independencia entre sí, el valor del coeficiente alfa será nulo (α = 0). Por tanto, cuanto más el estimador alfa se acerque a 1 (α → 1), mejor es la fiabilidad de la selección de variables propuestas. Por el contrario, si este estimador se acerca a cero (α → 0), menor es esa fiabilidad. Cabe resaltar que se considera una fiabilidad aceptable cuando α ≥ 0.70.
II. Resultados
Los resultados del análisis se presentan de la siguiente manera: primero, se dan a conocer los resultados del IDR, enseguida, los del análisis comparativo entre regiones; finalmente, se reportan algunos resultados relativos a la fiabilidad metodológica del estudio.
A. Índice de Desarrollo Regional (IDR)
1. Análisis multivariado (ACP)
Matriz de correlación. De acuerdo con las matrices de correlación estimadas con el coeficiente de Pearson para el periodo 20152019, en promedio, las variables presentan correlaciones fuertes entre sí, con niveles de significancia de 0.01 y 0.05 (99 % de confianza y 95 % de confianza, respectivamente). Dentro de las correlaciones lineales más fuertes y significativas, destacan las variables: PIB per cápita (PIB pc), ingreso promedio mensual proveniente del trabajo (In_pm), tasa de ocupación (T_ocu), PEA ocupada adecuadamente empleada (PEA_ae), PEA ocupada con sistema de pensión (Pens) y población con al menos un producto financiero (Prd_fnc). Las correlaciones entre estas variables concuerdan con la clasificación dimensional que comparten entre sí (económica). De manera análoga es el comportamiento de las correlaciones de los indicadores de las demás dimensiones.
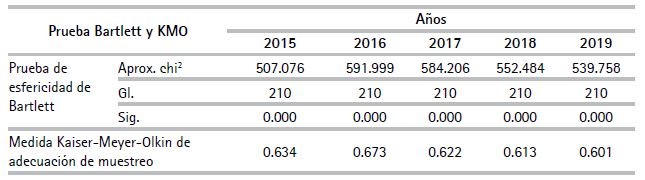
Contraste de esfericidad de Barlett y medida de adecuación muestral KMO. Con respecto a la prueba de esfericidad de Barlett (cuadro 2), se observa que el valor de χ2 (chi cuadrado) es alto y la significancia (parámetro p) es menor a 0.05, por lo que se rechaza la hipótesis nula (H0) y se acepta la hipótesis alterna (H1), razón por la cual se factibiliza el uso de ACP.
En cuanto a la medida de adecuación muestral KMO, el coeficiente analizado toma valores mayores a 0.60, que supera la valla estadística de 0.50 e indica que las correlaciones parciales entre las variables son suficientemente pequeñas. Por esta razón, se considera adecuada la aplicación de ACP.
2. Comunalidades
Con el objetivo de comprobar la relevancia de las variables seleccionadas, se estimaron las comunalidades asociadas a cada variable, para todos los años. Las comunalidades extraídas (cuadro 3), poseen en su mayoría valores superiores a 0.75, por lo que se infiere la existencia de factores comunes que explican las variabilidades de las variables. Ello significa que el modelo reproduce en promedio más del 75 % de la variabilidad original de todas las variables.
3. Matriz de varianza total explicada
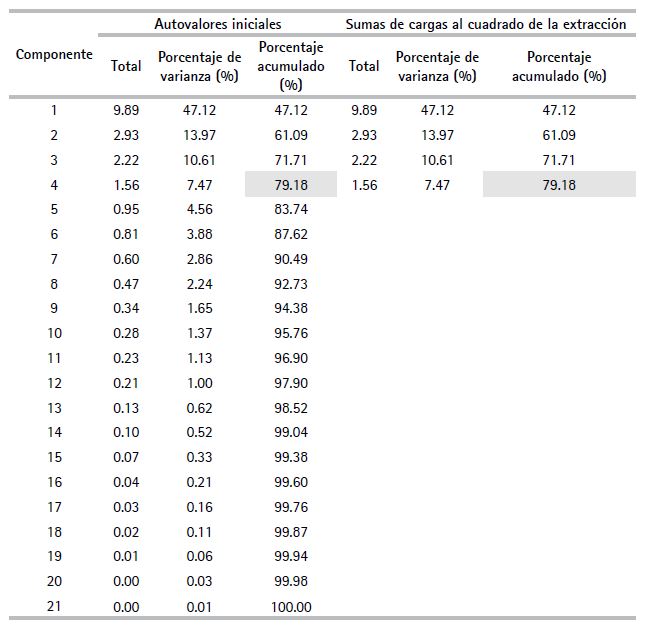
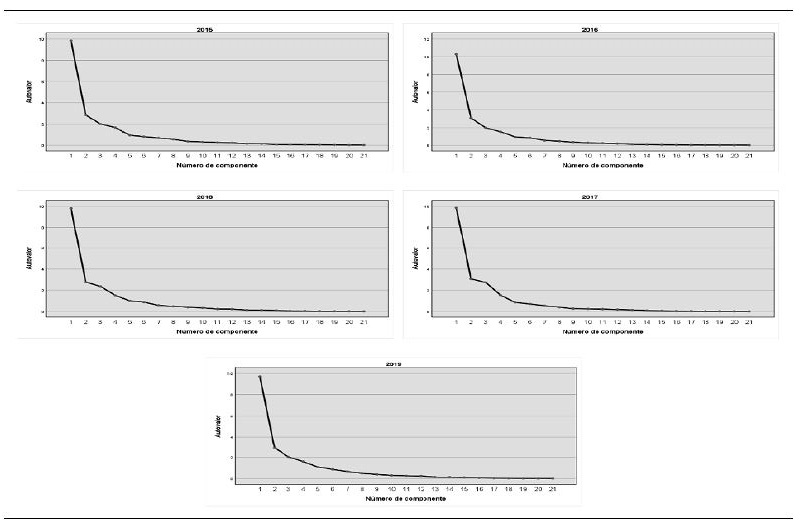
Esta fase se basa en determinar el número de factores que deben retenerse en el estudio. Para ello, se construyó la matriz de varianza explicada de los com ponentes (promedio de los cinco años). Para determinar el número de componentes retenidos, se consideró conjuntamente el criterio de Kaiser (raíz latente), el contraste de caída (codo de Castell) y el porcentaje de la varianza explicada.
Cuadro 3. Comunalidades extraídas
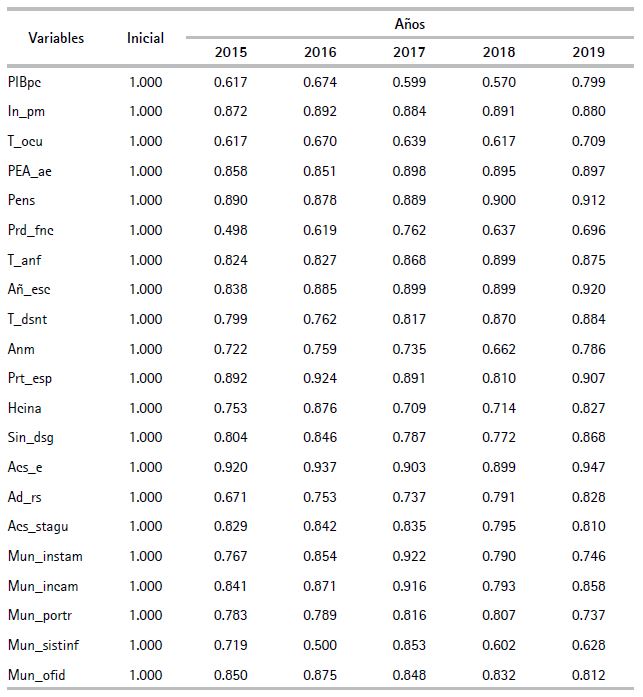
Nota:el método de extracción fue un análisis de componentes principales.
Fuente: elaboración propia
Según el primer criterio, se retuvieron cuatro componentes con autovalores que superan la unidad. Conviene mencionar que la retención de componentes que expliquen más varianza que la que una sola variable puede contener tiene más sentido.
Con respecto al segundo criterio, los gráficos de sedimentación muestran, para todos los años, puntos de inflexión después de consignar el cuarto componente (figura 2). Ello ratifica la selección del primer criterio.
De acuerdo con el tercer criterio (cuadro 4), se observa que el porcentaje acumulado promedio de la varianza al considerar cuatro componentes es 79.18 % (> 60 %, porcentaje referencial en investigaciones de carácter social). Por ello, una vez más, se ratifica la selección de cuatro componentes. Cabe resaltar que los componentes seleccionados hacen referencia a cuatro combinaciones lineales de las variables originales, independientes entre sí, pues no se presencia correlación alguna entre los componentes, producto de la aplicación del ACP.
4. Matriz de componentes
La siguiente fase corresponde a la construcción de la matriz de componentes principales. Esta revela la correlación entre los componentes seleccionados y las variables originales, con el fin de asignar un componente a cada una. La clasificación y la interpretación de los componentes puede hacerse a partir de la matriz de componentes, tomando en cuenta los mayores valores correlativos (umbral mínimo de 0.40). No obstante, a través de las estimaciones, se observó que la mayoría de las cargas factoriales de las variables originales tiene correlación con el primer componente, lo que deja de lado a los otros tres componentes y no permite tener una interpretación clara de estos. Por esta razón, se estimó la matriz de componentes con rotación para cada año.
5. Rotación de factores
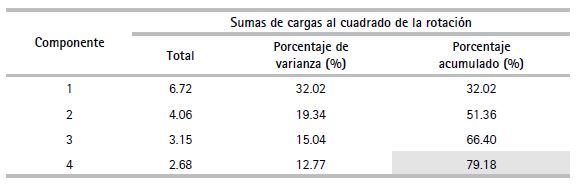
A raíz de la transformación, la varianza acumulada global por los componentes seleccionados se mantuvo invariable con el valor de 79.18 %. Sin embargo, lo que sí cambia es la distribución de la varianza entre los componentes, pues primero desciende de 9.89 (47.13 %) a 6.73 (32.02 %); y luego asciende de 2.93 (13.97 %) a 4.06 (19.34 %), de 2.23 (10.62 %) a 3.16 (15.04 %) y de 1.57 (7.47 %) a 2.68 (12.77 %), para el primer, segundo, tercer y cuarto componente, respectivamente.
6. Gráficos de saturación en espacios rotados
Los gráficos de saturación (figura 3) consideran que los componentes son los ejes de los cuales se proyectan los valores de carga para cada variable, en relación con uno de los componentes. Con respecto a los gráficos que relacionan componente 1 y componente 2, se observa que, en uno de los extremos del eje (horizontal) del componente uno, aparecen las variables PIB_pc, In_pm, PEA_ ae, Pens, Añ_Esc y Acs_e. Mientras tanto, en el otro extremo se encuentran T_anf, T_dsnt y T_ocu. Ello da, entre las nueve variables, contenido a un componente que muestra la contraposición entre no desarrollar el capital humano y sus “efectos” en el aspecto económico de la población (estructura económica, empleo y sistema de pensiones). De ese modo, se ratifica la dimensión social y económica expuesta en la interpretación de la matriz de componentes rotados. De manera análoga es la interpretación con los gráficos restantes.
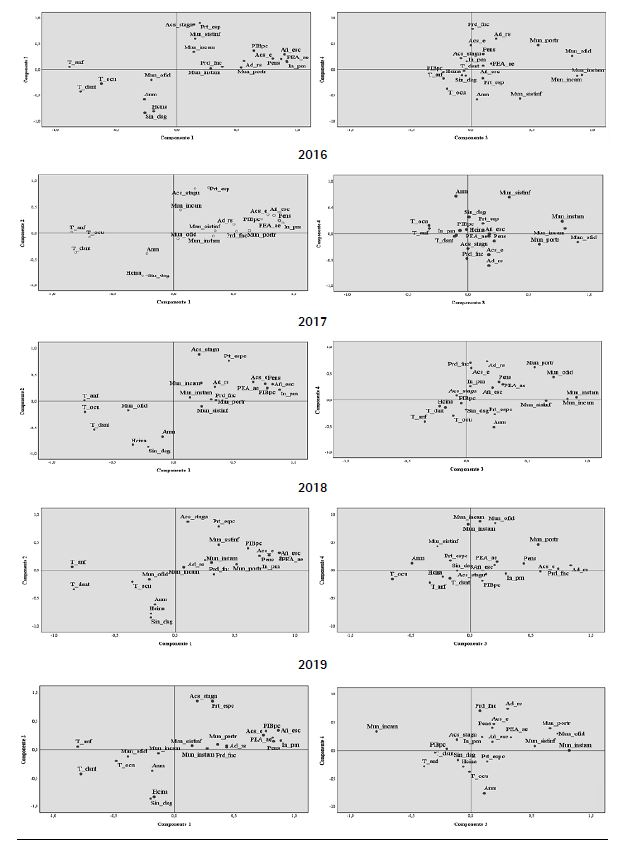
Fuente: elaboración propia.
Figura 3. Gráfico de saturación bidimensional de componentes (2015-2019)
Habiendo analizado los componentes y las cargas factoriales de las variables en función a las matrices de componentes rotados, las variables que componen cada componente principal son las siguientes:
7. Normalización de los datos
La normalización de los datos fue realizada a través del método de re-escalamiento, el cual consistió en transformar los niveles de las variables en el intervalo [0,1]. Dada la naturaleza de los datos, se consideraron las dos funciones de normalización Min-Max y Max-Min.
8. Ponderación de información
Se tomó como base la matriz de varianza total explicada (después de la rotación), la cual presentó cada componente con su porcentaje de aporte de variabilidad al modelo. A raíz de ello, se retuvieron cuatro componentes, que se muestran en el cuadro 5.
De acuerdo con la varianza total promedio estimada, el aporte de variabilidad de cada componente constituyó los principales referentes para la nueva asig nación de pesos. De ese modo, se logró un porcentaje acumulado del 100 %, manteniendo la proporcionalidad. De esta manera, la distribución de porcentajes por componentes y variables es como muestra el cuadro 6.
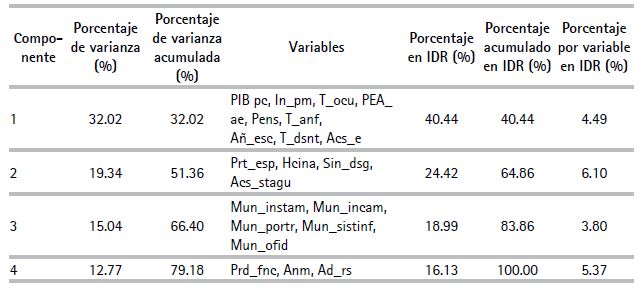
Con base en la asignación de pesos para cada una de las variables, el siguiente procedimiento fue un ordenamiento según las dimensiones conceptuales del IDR. El cuadro 7 muestra a las variables clasificadas por dimensión con sus respectivos pesos.
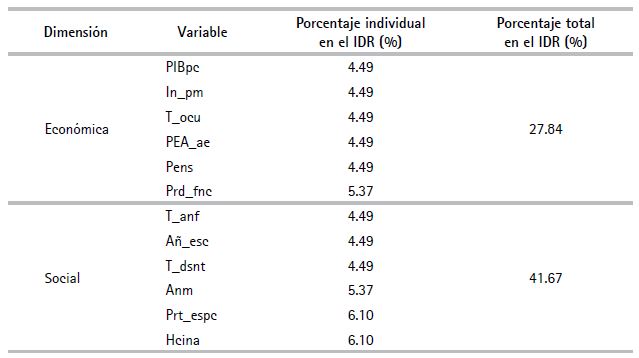
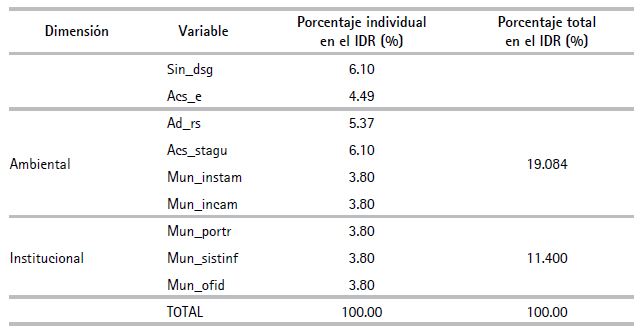
9. Agregación de información
La última etapa en la construcción del IDR fue la agregación de información de las variables ponderadas para cada unidad de análisis (regiones de Perú), para cada año (2015-2019). Con ese propósito, la técnica utilizada fue de tipo lineal, en específico, la media aritmética ponderada.
B. Análisis comparativo regional
1. Comparación global del IDR
En el cuadro 8, de acuerdo con los IDR estimados, se observa que la provincia constitucional del Callao junto a Ica, Moquegua y Lima fueron las unidades de análisis que se posicionaron en los primeros cuatro puestos en todo el periodo 2015-2019. Ello demuestra un mejor nivel de desarrollo regional en comparación al resto de regiones. Asimismo, tomando en cuenta el promedio, los IDR de estas cuatro regiones oscilan entre 0.745 y 0.886, muy por encima de la media nacional. En contraste, regiones como Loreto, Puno, Huancavelica y Cajamarca, obtuvieron los menores IDR. Por lo que comparten los cuatro últimos puestos en materia de desarrollo regional (tomando en cuenta el promedio, sus valores oscilan entre 0.251 y 0.339). Por otro lado, realizando una comparación entre estos dos grupos bastante diferenciados, se observa una brecha promedio de 0.593. Es decir, la brecha equivale a más de la mitad de lo que podría equivaler un IDR máximo (una unidad).
En cuanto al desempeño interanual de Perú en los cinco años analizados (0.542), se encuentra que el desarrollo a nivel no fue muy alentador. Ello podría deberse a que el periodo estudiado fue uno con particularidades políticas, como el cambio, la renuncia y las denuncias a expresidentes, específicamente en 2018, año en el que tuvo lugar la renuncia de un expresidente, y en 2019, cuando empezó la contienda de los poderes del Estado peruano.
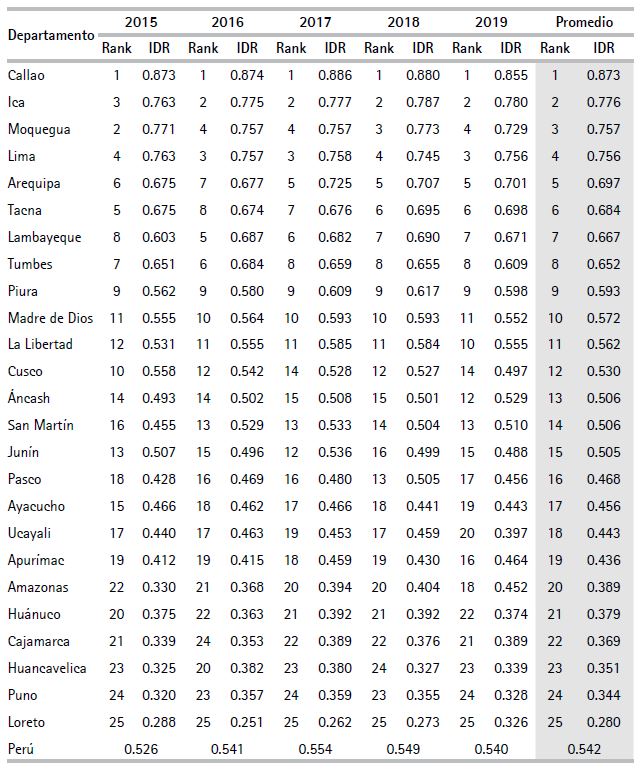
En cuanto a la clasificación per se del nivel de desarrollo regional, a saber, bajo, medio y alto, el cuadro 9 muestra estos tres niveles, junto a sus intervalos de IDR, estimados a través del método Jenks natural breaks.

Desde el punto de vista de distribución espacial del IDR, la figura 4 muestra un mapa coroplético1, que categoriza estos tres niveles de desarrollo. En este contexto, se aprecia que la mayor concentración de desarrollo se sitúa en la costa sur y centro del país, mientras que la selva y algunas regiones de la sierra son las áreas que despliegan las peores posiciones de desarrollo regional. Esta clasificación, evidentemente, puede ser contrastada con los promedios estimados en el cuadro 8.
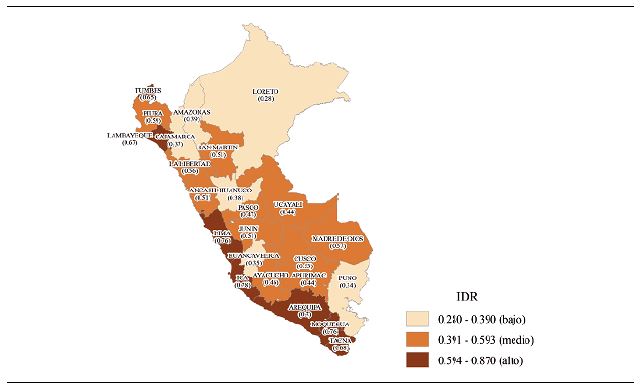
Desde el punto de vista de evolución del IDR, el análisis está sujeto a los intervalos definidos anteriormente. De esta forma, se realiza una interpretación objetivamente comparable dentro de cada nivel (alto, medio, bajo).
La evolución de las unidades de análisis con altos niveles de desarrollo se presenta en la figura 5, donde la Provincia Constitucional del Callao se ubica en el primer lugar del índice a lo largo del periodo 2015-2019. Una razón de ello tiene que ver con que esta unidad de análisis se ubica enteramente en un área urbana.
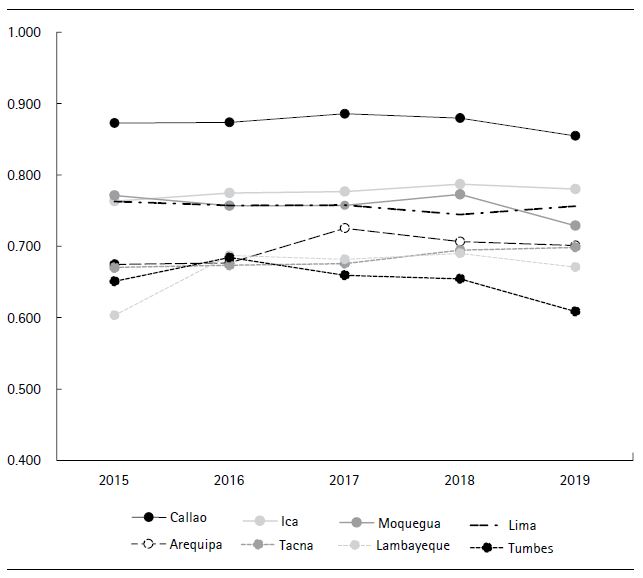
Fuente: elaboración propia.
Figura 5. Evolución del IDR (regiones con nivel alto de desarrollo regional)
Con respecto a la evolución de las regiones con desarrollo medio, en la figura 6 se observa que Piura fue la región que se perfiló como la primera en su bloque (con un crecimiento promedio del 6.503 %), mientras que Cusco tuvo un comportamiento de decaimiento, pues interanualmente para todos los casos presentó tasas negativas de crecimiento (–10.88 % para el caso interanual de 2015-2019).
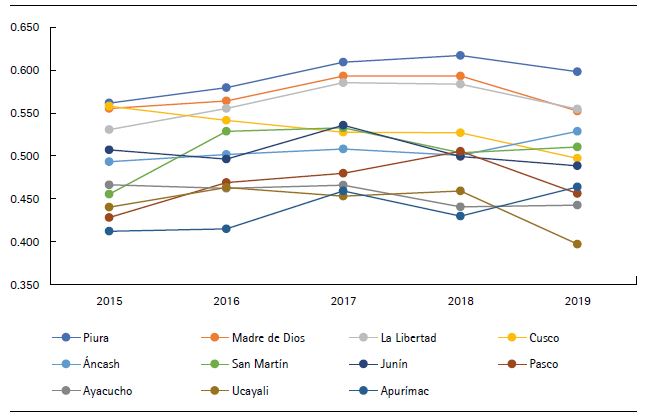
Fuente: elaboración propia.
Figura 6. Evolución del IDR (regiones con nivel medio de desarrollo regional)
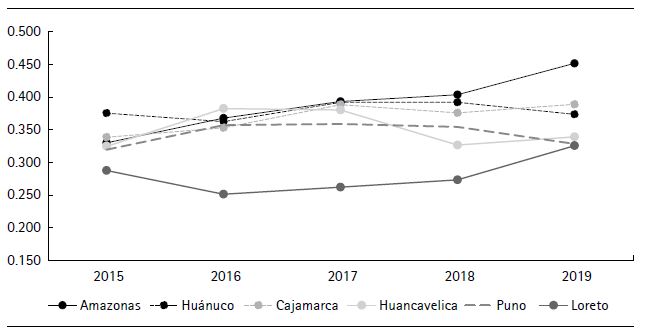
En referencia a la evolución de las regiones con niveles bajos de desarrollo (figura 7), todas, a excepción de Huánuco (–0.42 %) presentaron tasas de crecimiento positivas. En este bloque, se presentan las tasas de crecimiento más altas en comparación con los otros dos bloques (niveles alto y medio), pues resaltan las tasas de crecimiento de regiones como Amazonas (36.87 %), Cajamarca (14.91 %) y Loreto (13.12 %).
2. Comparación por dimensiones del IDR (económica, social, ambiental e institucional)
Habiendo incidido en el IDR promedio global, es meritorio analizar el comportamiento que tuvo el IDR en torno a sus dimensiones. La figura 8 muestra un gráfico radial que considera los IDR promedio (2015-2019) de los niveles de desarrollo (alto, medio y bajo), según las dimensiones que lo componen. Se observa que, en las dimensiones, el desempeño de los niveles guarda lógica con el IDR, es decir las regiones que se encuentran con niveles altos en el IDR, también muestran niveles altos en el aspecto económico, social, ambiental e institucional. Sucede lo mismo con los otros dos niveles. No obstante, también se aprecia que los índices de la dimensión institucional son más cercanos entre sí, mientras que los de la dimensión social son más lejanos. Estas dos premisas indican que en la dimensión institucional existe una menor brecha con respecto a las demás dimensiones, en especial a la dimensión social.
Fuente: elaboración propia.
Figura 7. Evolución del IDR (regiones con nivel bajo de desarrollo regional)
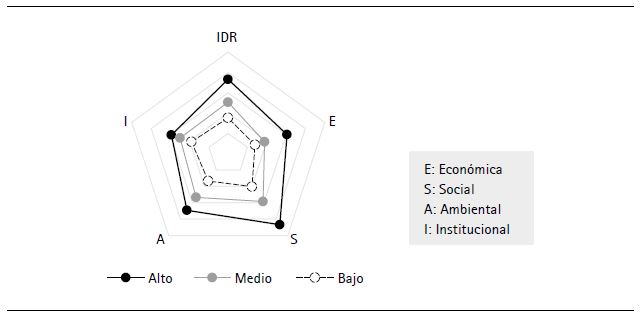
3. Análisis correlacional
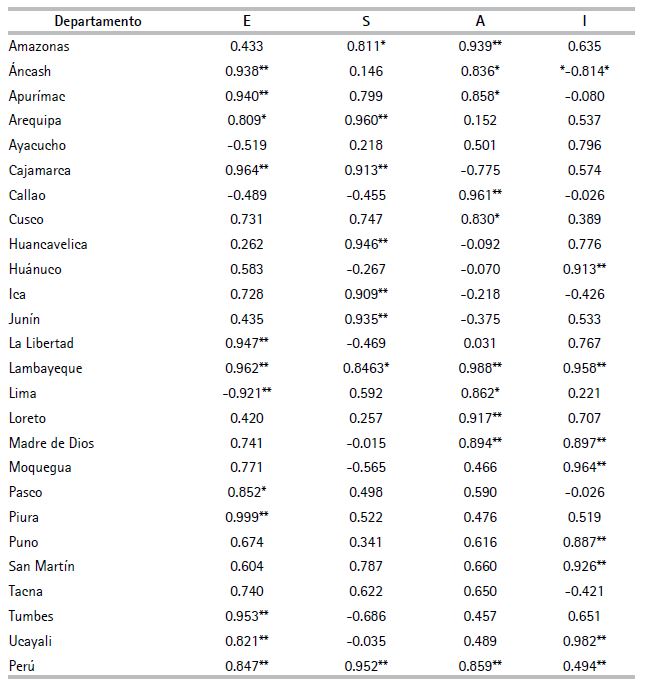
Con respecto al análisis correlacional, según muestra el cuadro 10, Lambayeque fue la región con mejores valores (altas correlaciones estadísticamente significativas), lo que es coherente con el análisis de la evolución del IDR, donde se indicó que esta región presentó la mayor tasa de crecimiento (11.277 %) respecto al grupo de regiones con IDR alto. Además resalta con el valor correlacional más alto en la dimensión ambiental (0.988), con respecto a las demás regiones, por lo que parte de su desarrollo se da, en gran medida, por la disposición de desechos (Ad_rs), hábitat humano (Acs_stagu) y gestión ambiental (Mun_instam, Mun_incam).
Piura, por su parte, posee el valor correlacional significativo más alto en el ámbito económico (0.999). Ello evidencia que su desarrollo fue acrecentado por la estructura económica (PIB pc), empleo (In_pm, T_ocu, PEA_ae), sistema de pensiones (Pens) y sistema financiero (Prd_fnc). En lo social, Arequipa fue la región con mayor predominio correlacional (0.961), lo que indica avance en educación (T_anf, Añ_esc), salud (T_dsnt, Anm, Prt_Espc) y vivienda (Hcina, Sin_dsg, Acs_e).
Por su parte, Ucayali posee la correlación significativa más alta en la dimensión institucional (0.983), lo que es coherente con el ranking institucional visto anteriormente, en el que esta región ocupó su mejor posición individual (7°), con respecto a los otros rankings. Ello evidencia que su desarrollo fue potenciado por la capacidad de gestión (Mun_portr), infraestructura en TIC (Mun_ sistinf) e inclusión social (Mun_ofid).
Por otro lado, también se observan regiones con correlaciones con signos negativos, donde es meritorio realizar inferencias sobre el planteamiento de políticas públicas. Por ejemplo, para Áncash una limitante en su desarrollo es la dimensión institucional (–0.815), por lo que los decisores de política deben mejorar sus acciones en capacidad de gestión, infraestructura municipal en TIC e inclusión social en las atenciones municipales. De la misma forma, los decisores de política pública de las regiones que presentan signos negativos en valores significativamente estadísticos son los que deberían poner mayor atención en esas dimensiones, así como en los indicadores simples que las constituyen.
Cuadro 10. Correlaciones entre el IDR y sus dimensiones (promedio del periodo 2015-2019)
**La correlación es significativa al 95 % de confianza.
*La correlación es significativa al 90 % de confianza.
Fuente: elaboración propia.
En esta misma línea, de las correlaciones estimadas, se destaca que la dimensión social ha permitido mejorar los niveles de desarrollo en casi todas las regiones del país, pues, además de demostrar las correlaciones más elevadas y estadísticamente significativas regionales, desde el plano nacional, es la más alta (0.952). La siguiente dimensión que impulsa el desarrollo regional es la ambiental (0.859), seguida de la económica (0.848) y la institucional (0.494).
Asimismo, las cuatro dimensiones son estadísticamente significativas al 5 %. Con respecto a la dimensión institucional, esta ratifica lo encontrado en el ranking institucional estimado anteriormente, donde las regiones que ocupaban los últimos puestos en el IDR salieron a relucir con desarrollos medios en el aspecto institucional, de la misma forma, la correlación hallada (0.494) para la dimensión institucional es moderada y la más baja respecto a las otras tres dimensiones.
4. Convergencia sigma
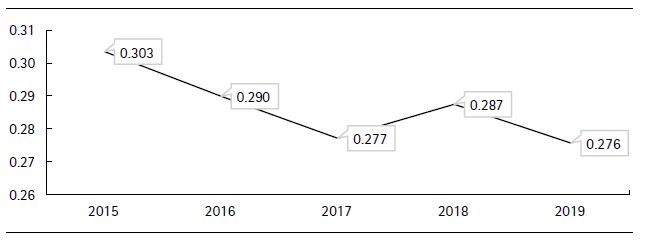
Con el fin de establecer el nivel de brechas regionales, la figura 9 muestra que el valor del valor sigma (σ) computado para las 25 unidades de análisis indica una tendencia general de decaimiento, demostrando así una convergencia sigma regional. Esto significa que las disparidades regionales disminuyeron en el periodo 2015-2019. No obstante, se aprecia una interrupción en 2018, año en el cual el valor de sigma (σ) se levanta para volver a caer en 2019 (valor más bajo).
A su vez, el valor revelado para el 2018 podría deberse a la inestabilidad política que se presenció en ese año, cuando la renuncia de un expresidente fue efectuada y un nuevo mandatario tomó la posta presidencial; encaminando así a que la dimensión institucional que, cabe destacar, es la que menos desarrollo involucra en el IDR, sea la más afectada.
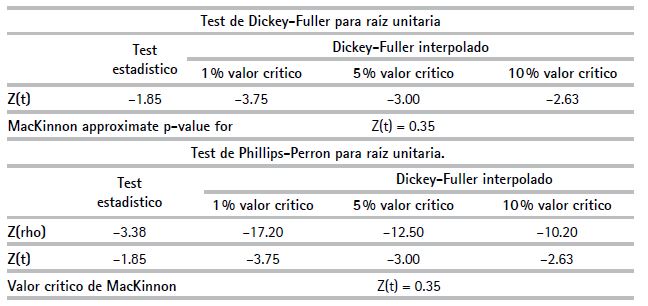
Por otro lado, para poder avalar estos resultados, así como su interpretación, se evaluó si el valor sigma calculado es coherente con la estacionariedad (cuadro 11). Para ello, se utilizaron los tests de Dickery-Fuller aumentado (DFA) y Phillips Perron (PP). Fue probada en ambos tests la hipótesis nula (H.), referida a la existencia de raíz unitaria y, consecuentemente, la no estacionariedad de la serie de tiempo, pero no se encontró raíz unitaria en razón al t-statistic, por lo que los resultados preliminares fueron validados estadísticamente. Es decir, la serie de tiempo es estacionaria y, por tanto, no existe divergencia sigma, sino, convergencia sigma regional.
E. Fiabilidad metodológica interna y prototipo de plataforma iterativa web
1. Análisis de fiabilidad interna
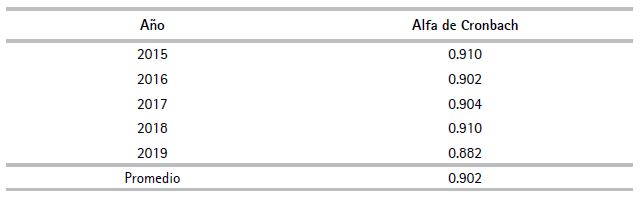
A través de la estimación del coeficiente alfa (α) de Cronbach, se reportó que los valores computados para cada año en análisis (2015-2019) mostraron ser próximos a la unidad (α > 0.700, mínimo para fiabilidad aceptable). El cuadro 12 muestra estos coeficientes, los cuales en promedio revelan el valor de 0.902, lo que indica que el IDR recopila información objetiva y, además de ser fiable, efectúa mediciones estables y consistentes.
2. Prototipo de plataforma iterativa web
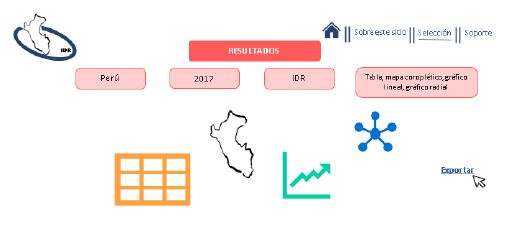
A continuación, se realiza una breve descripción del prototipo de la plataforma iterativa web, en específico, procesos, características y funciones que tendría en caso de que dicho prototipo sea construido en la web (el Anexo 2 ilustra ello con mayor detalle).
La plataforma tendrá dos elementos principales, el primero corresponde a la selección de características: (1) selección de ámbito geográfico (regiones, macrorregiones o Perú-general); (2) año de selección (2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, etc.); (3) estado situacional (IDR, dimensiones: económica, social, ambiental y institucional); y (4) presentación de resultados(tabla, mapa coroplético, gráfico lineal de evolución o gráfico radial). El segundo elemento, por su parte, se basa en la ilustración y presentación de los resultados de acuerdo con la selección realizada dentro del primer elemento.
En cuanto a la transformación de variables, una vez realizada la selección de características en el primer elemento, el diseño de la plataforma estará supeditado a la presente investigación, en específico a las ponderaciones estimadas de las variables, pues dado que a través del ACP fue posible calcular las ponderaciones (pesos) de las variables que componen el IDR, estas ponderaciones estimadas serán utilizadas para la estimación de los siguientes IDR y dimensiones en la plataforma.
Asimismo, respecto a la ilustración y presentación de resultados, a través de inteligencia analítica y artificial, se utilizarán algoritmos de actualización automática mediante un diseño web scraping con leguaje Python, de forma que la extracción de información sea obtenida directamente de las bases de datos del Inei (microdatos-módulos), recodificadas y transformadas. De este modo, la recopilación y actualización automática de los datos públicos posibilitará la construcción de reportes, mapas y gráficos que muestren tenden cias y comparaciones de las regiones del Perú en torno al IDR y sus variables, según año y región.
III. Conclusiones
La elaboración del IDR, construido a través del análisis por componentes principales (ACP), permitió estimar, con enfoque multidimensional (económico, social, ambiental e institucional), el nivel de desarrollo alcanzado por las 24 regiones del país y la Provincia Constitucional del Callao, en el periodo 20152019. Se concluye, a partir de ello, que las regiones con mayor desarrollo regional en dichos años fueron la Provincia Constitucional del Callao (0.873), junto a Ica (0.776), Moquegua (0.757) y Lima (0.756). Entretanto, las regiones con menor desarrollo fueron Cajamarca (0.369), Huancavelica (0.351), Puno (0.344) y Loreto (0.280).
Asimismo, tomando en cuenta el último año de análisis (2019), se encontró que las regiones que ocuparon los primeros puestos fueron la Provincia Constitucional del Callao (0.86), Ica (0.78), Lima (0.76), Moquegua (0.73) y Arequipa (0.70). Este resultado es muy similar al presentado por el Instituto Peruano de Economía (2020), pues en una escala del 0 a 10, se presentó que las mismas regiones fueron las que tuvieron mayores niveles de desarrollo en el Incore 2019: Lima (7.7, incluyendo a la Provincia Constitucional del Callao), Moquegua (6.8), Tacna (6.7) y Arequipa (6.6). De igual forma sucede con las regiones con bajos niveles de desarrollo: Cajamarca (0.39), Huánuco (0.37), Huancavelica (0.34), Puno (0.33) y Loreto (0.33), mismas regiones reportadas por el IPE: Huánuco (3.6), Loreto (3.6), Cajamarca (3.5), Puno (3.4) y Huancavelica (2.9). Además, los resultados de las dimensiones estimadas (específicamente: económica, social e institucional) siguen el mismo orden que los resultados de los pilares reportados por el IPE en su Incore.
En cuanto al análisis por dimensiones, se encontró que, en la dimensión institucional, existió una menor brecha regional con respecto a las restantes dimensiones, en especial, la social. Además, por orden jerárquico, las dimensiones que más aportaron al desarrollo sustentable analizado fueron: social (95.20 %), ambiental (85.98 %), económica (84.78 %) e institucional (49.42 %). Este resultado se alinea con el estudio de Correa y Morocho (2012) para el periodo 2004-2010 en el que, a pesar de que solo se contemplaron como dimensiones a la actividad económica, capital físico, capital humano y gestión de recursos financieros, se encontró que el ámbito social, así como la dimensión social (95.2 %), es el que mayor asociación tiene con el IDR estimado en la presente investigación; el capital físico (97.6 %) fue el componente de mayor asociación con el índice compuesto elaborado por los autores.
Además, en el ámbito institucional, así como la dimensión institucional (49.42 %) tuvo la menor y hasta negativa relación con el IDR, la gestión de recursos financieros (–0.001) también tuvo una relación inversa con el índice compuesto elaborado por los autores. En este contexto, teniendo en consideración el distinto periodo de análisis en ambos estudios (2004-2010 para Correa y Morocho, 2012; y 2015-2019 para la presente investigación), se colige que con el pasar de los años, en Perú aún se tiene como un aspecto crítico al marco institucional, pues el que esta dimensión tenga bajo o negativo grado de asociación con el desarrollo (reflejado en el IDR) orienta a que los decisores de política pongan mayor énfasis y atención en dicha dimensión.
Por otro lado, el análisis de convergencia sigma reportó una tendencia general de decaimiento, lo que evidenció una convergencia sigma regional; es decir, las disparidades regionales del Perú disminuyeron en el periodo 2015-2019. Ello tiene una relación mixta con otras investigaciones de análisis de brechas regionales para este país. Por ejemplo, con la misma metodología utilizada en la presente investigación (convergencia sigma), Alcántara (2001) reporta que la desigualdad de ingresos en el Perú en 1961-1972 disminuyó, pero aumentó en el periodo 1972-1993, para cambiar de tendencia (disminución de brechas) en el periodo 1993-1995.
Por su parte, Sutton et al. (2006) también concluyen, para el periodo 19702001, la existencia de convergencia. Del mismo modo, considerando la metodología de convergencia sigma para el periodo 1979-2008, Delgado y del Pozo (2011) encontraron que las disparidades (PIB pc) regionales disminuyeron. En contraste con ellos, el estudio de Delgado y Rodríguez (2015) no encontró convergencia sigma para el periodo 1970-2010.
Asimismo, un interesante estudio de Tello (2021) reveló que, en el periodo 2000-2020, no existió convergencia en el crecimiento regional, por lo que las brechas entre las regiones no disminuyeron. No obstante, de acuerdo con sus resultados, se observa que desde 2009 hasta 2020 existió un cambio en los coeficientes que reportan el grado de cierre de brechas regionales, induciendo a una convergencia. En este contexto, se infiere que la evidencia empírica del análisis de convergencia regional en el país es mixta, pues unos estudios plantean una disminución de brechas regionales, mientras otros revelan un aumento de estas. A pesar de ello, es necesario mencionar que las conclusiones de los autores se ciñen a periodos estudiados.
En cuanto a la fiabilidad metodológica del IDR, dado que a través del coeficiente alfa de Cronbach se reportó que los valores computados para cada año analizado (2015-2019) mostraron ser próximos a la unidad y, en promedio, revelaron un coeficiente de 0.902, superior a 0.700. Se concluye la existencia de fiabilidad interna metodológica en el IDR. Además, con respecto a la plataforma web iterativa, se espera que con el diseño planteado pueda ser implementada a través de algoritmos genéticos e inteligencia artificial en la web, pues, de esta forma, en Perú se contaría con una herramienta pionera connotada dentro de los índices de nueva generación.
En general, se concluye que la creación de índices compuestos ha constituido un campo de investigación variado en el desarrollo económico; no obstante, existe el consenso de que el fin primordial de estos es diagnosticar la realidad en los territorios para que, a partir de ellos, se propongan nuevos mecanismos de desarrollo.
IV. Recomendaciones
En primera instancia, en línea con el desarrollo multidimensional planteado, se recomienda incentivar el acceso a productos financieros, dado que esta variable representó una debilidad para las regiones con niveles medios y bajos en la dimensión económica. Asimismo, para las regiones con niveles altos en esta dimensión, se recomienda que se tomen medidas para incrementar el porcentaje de la PEA adecuadamente empleada.
Por otro lado, en el aspecto social, dado que la tasa de anemia representa la principal debilidad para las regiones con desarrollo social medio, se recomienda ejecutar iniciativas políticas de salubridad, en torno a dicha variable, con gran énfasis en este grupo de regiones. Asimismo, se recomienda tomar acciones para incrementar la cantidad de años de escolaridad y disminuir la tasa de desnutrición en las regiones con desarrollo medio social.
En cuanto a la dimensión ambiental, se recomienda a las municipalidades pertenecientes a las regiones con niveles altos y medios, tomar acciones para incentivar la conservación ambiental, pues esta variable fue la principal debilidad presentada.
Con respecto a la dimensión institucional, dado que durante el periodo 20152019, la tendencia de los tres niveles de regiones compartió la característica de retroceder en el porcentaje de municipalidades con sistemas informáticos implementados para el apoyo de la gestión (Mun_sistinf), por lo que se convirtió en una debilidad para todas las regiones. En esa medida, se recomienda implementar TIC, así como brindar capacitación en el manejo y desarrollo de estas hacia los trabajadores de las distintas municipalidades peruanas. Además, en un plano comparativo, se ratifica poner mayor énfasis en el desarrollo institucional, puesto que la correlación hallada (0.494) para la dimensión institucional es moderada y la más baja respecto a las otras tres dimensiones.
En línea con el análisis correlacional estimado, dado que se observaron correlaciones de regiones con signos negativos, se recomienda a los tomadores de decisiones de políticas implementar planes para la mejoría de estos valores. Por ejemplo, se aprecia que, para Áncash, una limitante en su desarrollo es la dimensión institucional (-0.815), por lo que los decisores de política de esta región deben mejorar sus acciones en capacidad de gestión, infraestructura municipal en TIC e inclusión social en las atenciones municipales. De manera análoga, las demás regiones con correlaciones negativas y significativas deberían mejorar sus acciones de acuerdo con la dimensión del valor correspondiente.
Finalmente, con respecto a la plataforma web iterativa del IDR, se hace un llamado a la academia y a los investigadores de futuro estudios a que se implemente esta plataforma, a través de algoritmos genéticos e inteligencia artificial en la web, de acuerdo con el prototipo diseñado, pues, de esta forma, en Perú se contaría con una herramienta pionera, connotada dentro de los índices de nueva generación.