










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkCuadernos de Administración
Print version ISSN 0120-3592
Cuad. Adm. vol.19 no.32 Bogotá Jul./Dec. 2006
* Artículo de investigación científica y tecnológica. Es producto de la investigación realizada por el grupo de Finanzas Computacionales en el modelado y la predicción de series temporales usando técnicas basadas en inteligencia artificial. Fue auspiciado por la Escuela de Sistemas, Facultad de Minas, Universidad Nacional de Colombia. El artículo se recibió el 19-04-2005 y se aprobó el 05-12-2005.
** Candidato a doctor en Sistemas Energéticos, Universidad Nacional de Colombia. Magíster en Ingeniería de Sistemas, Universidad Nacional de Colombia, 1997. Ingeniero civil, Universidad Nacional de Colombia, 1994. Profesor asociado de la Facultad de Minas, Universidad Nacional de Colombia, sede Medellín. Director del Grupo de Finanzas Computacionales, Facultad de Minas, Universidad Nacional de Colombia. Correo electrónico: jdvelasq@unalmed.edu.co
*** Ingeniera de sistemas, Universidad Nacional de Colombia, 2006. Miembro del Grupo de Finanzas Computacionales, Facultad de Minas, Universidad Nacional de Colombia. Correo electrónico: lmgonzal@unalmed.edu.co
RESUMEN
El modelaje y la predicción de las tasas de cambio es un importante problema económico. En el artículo se usa un modelo de redes neuronales artificiales para representar la dinámica del índice del tipo de cambio real colombiano, porque describe mejor la dinámica de la serie que un modelo lineal autorregresivo, como lo muestra el resultado del contraste del radio de verosimilitud. El modelo fue aceptado después de aplicarle una serie de pruebas estándar y de contrastar sus resultados con los obtenidos usando un modelo lineal autorregresivo. Los resultados indican que el valor actual de la serie depende únicamente de su valor anterior.
Palabras clave: redes neuronales artificiales, tasa de cambio, series de tiempo, modelado.
ABSTRACT
Modeling and forecasting exchange rates is a big economic headache. This paper uses an artificial neuronal network model to represent the Colombian real exchange index dynamics because it describes the series dynamics better than a self-regressive linear model does, as may be appreciated in the result of the verosimilitud radius contrast. The model was accepted after applying a series of standard tests and contrasting the results against those obtained using a self-regressive linear model. The results indicated that the current value of a series solely depends on its previous value.
Key words: Artificial neuronal networks, exchange rate, time series, modeling.
Introducción
Durante las últimas décadas, la representación de relaciones económicas no lineales ha sido un problema de investigación muy importante (van Djck, 1999; Granger y Teräsvirta, 1993), de tal forma que la econometría empírica se ha nutrido de muchos modelos y técnicas, cuyos orígenes se encuentran en la estadística y la inteligencia artificial. Particularmente, el uso de las redes neuronales artificiales ha venido ganando terreno, debido a su capacidad para representar relaciones desconocidas a partir de los datos mismos, en aquellos casos donde la economía no brinda suficientes elementos para establecer la forma funcional de dicha relación. Más aún, se han dedicado importantes esfuerzos para desarrollar aproximaciones metodológicas que permitan formular y formalizar esta clase de modelos a partir de criterios estadísticos y, así, abandonar los métodos ad hoc tradicionales –véase, por ejemplo, a Anders y Korn (1999), Fukumizu (2003), entre otros–.
Igualmente, ha resultado importante la aplicación de estas metodologías en el modelado y predicción de series económicas y financieras reales con el fin de ganar una mayor experiencia en su uso, ya que, tal como lo señalan Granger y Teräsvirta (1993), no hay suficientes indicios que permitan determinar cuáles modelos podrían ser los más adecuados en la representación empírica de relaciones económicas.
Por otra parte, el modelado y la predicción de las tasas de cambio han sido reconocidos como importantes problemas económicos, en especial por la dificultad para realizar predicciones tanto de corto como de largo plazo (Ince y Trafalis, 2006). En el modelado se pretende encontrar una descripción matemática (modelo) de la dinámica que sigue una tasa de cambio particular, tal que se cumplan los supuestos básicos en que se basa el modelo usado. Así, por ejemplo, los supuestos básicos en que se fundamentan los modelos autorregresivos son los siguientes: (a) el valor actual de la serie se obtiene como una combinación lineal de sus valores pasados; los residuales del modelo son (b) incorrelacionados, (c) homocedásticos y (d) idénticamente distribuidos (siguiendo una distribución normal). El proceso de modelado busca que el modelo finalmente obtenido cumpla con las condiciones estipuladas, de tal forma que cualquier violación de ellas sería considerada una causal del rechazo del modelo, lo que obligaría a reformularlo (eliminando o adicionando valores rezagados de la serie, etc.) o a postular otro tipo de modelo (una red neuronal u otra técnica no lineal en media, o un modelo GARCH para los residuales, etc.).
El modelo finalmente obtenido durante el proceso de modelado es una teoría del funcionamiento de la dinámica de la serie estudiada que permite esclarecer sus propiedades. El proceso de formulación del modelo es, en sí mis-mo, un proceso de aprendizaje en que el modelador, mediante un proceso de ensayo y error, depura su conocimiento sobre la serie estudiada. En la predicción se pretende encontrar aquel o aquellos modelos que permitan pronosticar con mayor precisión el valor futuro de las tasas de cambio, uno o más períodos adelante. Este proceso es distinto al del modelado, ya que en este último (el modelado) prima el cumplimiento de los supuestos de la serie, mientras que en la predicción prima la precisión de los pronósticos.
Los estudios recientes indican que la dificultad del modelado y la predicción de las tasas de cambio radica en que ellas siguen, en general, una dinámica inherentemente no lineal (Kilian y Taylor, 2003). No resulta sorprendente, entonces, que haya un número apreciable de aproximaciones metodológicas novedosas a este problema –véase, por ejemplo, a Ince y Trafalis (2006); De Gooijer, Ray y Krager (1998); Tseng, Tzeng, Yu y Yuan (2001); entre otros–, así como estudios basados en la comparación entre diferentes clases de modelos que buscan encontrar el mejor predictor para cada tasa de cambio particular –como trabajos recientes en este campo se encuentran a Clements y Smith (2001), El Shazly y El Shazly (1999), Cao y Soofi (1999), entre otros–.
La modelación econométrica de las tasas nominales de cambio del peso colombiano respecto al dólar americano es un tema que recientemente ha despertado el interés de los investigadores nacionales. Revéiz (2002) presenta un análisis descriptivo del comportamiento de la tasa de cambio nominal diaria entre enero de 1994 y septiembre de 1999, que corresponde al período de vigencia de la banda cambiaria. Gómez (1999) desarrolla un modelo empírico en que relaciona las tasas de cambio real y nominal a partir la técnica de cointegración de Johansen. Patiño y Alonso (2005) analizan la capacidad de predicción de la tasa de cambio nominal para Colombia en el período 1984:I-2004:I, usando los enfoques monetarios de precios rígidos y el modelo de Balassa-Samuelson, en contra de un modelo de paseo aleatorio. Milas y Otero (2002) analizan las relaciones de largo plazo entre las tasas de cambio oficial y paralela bajo los regímenes de banda cambiaria y tasa de cambio flexible. Igualmente, se han desarrollado estudios sobre la tasa de cambio real para el caso colombiano, con el fin de explicar sus determinantes (Echavarría y Gaviria, 1992; Langebaek, 1993; Calderón, 1995; Meisel, 1994).
Sin embargo, no se encontraron hallazgos sobre la realización de estudios en el modelado del índice del tipo de cambio real (ITCR), aunque este es un importante indicador económico que permite comparar la evolución relativa de la tasa de cambio colombiana en relación con las monedas de una canasta específica de países y las variaciones de los precios relativos. En este artículo se contribuye en esa dirección, al desarrollar un modelo univariado basado en redes neuronales artificiales del ITCR del peso colombiano frente a 18 países miembros del Fondo Monetario Internacional (FMI)1. Este reporte se encuentra organizado de la siguiente manera: la descripción de la información utilizada y la metodología de modelado son presentadas en la Sección 1. El modelo obtenido, los resultados de laspruebas estadísticas de especificación y su discusión son presentados en la Sección 2. Finalmente, las principales conclusiones son esbozadas en la Sección 3.
1. Datos y metodología
1.1 Información utilizada
1.1.1 Formación de la tasa de cambio
La tasa de cambio representativa del mercado (TRM) del peso colombiano respecto al dólar americano es el valor calculado y certificado por la Superintendencia Financiera (conocida anteriormente como la Superintendencia Bancaria), que corresponde al promedio ponderado de pesos colombia-nos pagados por cada dólar americano de las operaciones de compra y venta de dólares del día hábil inmediatamente anterior. No incluye las operaciones de ventanilla y de derivados sobre divisas que llevan a cabo los establecimientos de crédito en las ciudades de Bogotá, Medellín, Cali y Barranquilla. La TRM para el día siguiente a un día que es hábil en Colombia y festivo en Estados Unidos es la misma TRM vigente el día festivo. Es un indicador de las operaciones de compra y venta de dólares en el mercado cambiario, y sus fluctuaciones dependen de la relación entre la oferta y la demanda.
El mercado cambiario colombiano está compuesto por un mercado regulado y por un mercado libre. El primero está conformado por las transacciones que se realizan mediante los intermediarios cambiarios autorizados (como las entidades financieras); mientras que el mercado libre comprende las demás transacciones de cambio entre el dólar y el peso colombiano realizadas por el público en general.
Igualmente, el mercado cambiario está conformado por los intermediarios y el público en general. Los intermediarios comprenden los establecimientos de crédito, las sociedades comisionistas de bolsa y las casas de cambio; entre tanto, el mercado libre está compuesto por los compradores profesionales, que son agentes especializados, registrados en las cámaras de comercio, y que negocian con el público en general. El Estatuto Cambiario indica que las siguientes operaciones deben realizarse a través del mercado cambiario regulado:
1.1.2 Efectos en la economía nacional
Adicionalmente a la importancia del cambio de divisas entre los agentes del mercado, la TRM es la base para la proyección de los ingresos de los exportadores y los egresos de los importadores, de tal forma que se realizan constantemente esfuerzos para pronosticar su evolución con la mayor precisión posible. Las tendencias marcadas hacia la devaluación o revaluación del dólar americano afectan las ventas externas y hacen menos o más competitivos los productos nacionales, vía precio, con los consiguientes efectos económicos.
De igual forma, aparte de que la TRM se usa como la base para el cálculo de la tasa de interés efectiva de algunos activos, influye directamente en el monto en pesos de la deuda del gobierno pactada en dólares y en la consiguiente estrategia gubernamental para su pago, pues la devaluación o revaluación del peso en relación con el dólar americano ejerce un efecto indirecto sobre los índices de precios al productor y al consumidor. La TRM se considera uno de los indicadores de la situación económica y política del país, ya que refleja indirectamente la confianza que tienen los inversionistas, tanto nacionales como extranjeros, en que se den condiciones favorables para la traída o permanencia de capitales.
1.1.3 Regulación histórica del mercado cambiario
La regulación del mercado cambiario Colombiano ha pasado por un proceso evolutivo: en el modelo anterior, la tasa de cambio era fijada por decreto una o dos veces por semana (Milas y Otero, 2002); el modelo actual, vigente desde septiembre de 1999, está caracterizado por un régimen de flotación sucia. En este último, la tasa de cambio flota sobre una banda amplia sin ningún sistema de piso o techo, y su valor es determinado por la interacción de las fuerzas del mercado. No obstante, el Banco de la República se reserva el derecho de actuar sobre el mercado cambiario para estabilizarlo, ya sea mediante la subasta de opciones tipo put y call, con los fines de acumular reservas o aumentar su liquidez, o mediante la intervención directa, cuando la TRM se encuentra cuatro puntos por encima o por debajo de su promedio móvil de los últimos veinte días con el fin de disminuir su volatilidad.
1.1.4 Información utilizada
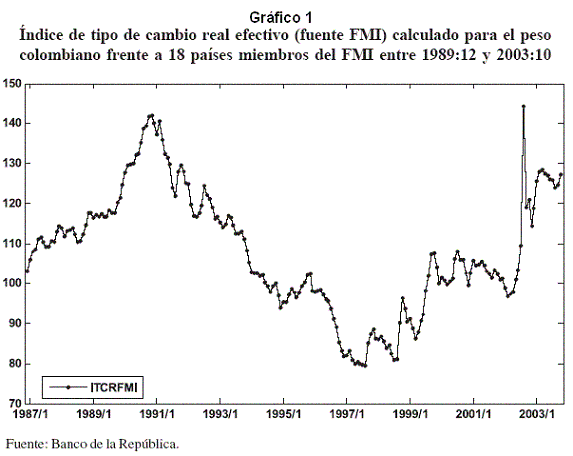
Tal como lo indica el Banco de la República (2002), internacionalmente se prefiere el uso de índices sobre la medición de la tasa de cambio real, debido a las dificultades metodológicas y a los grandes costos que implica su cálculo. La información utilizada en esta investigación corresponde al índice de tipo de cambio real efectivo calculado por el FMI (ITCRFMI) para el peso colombia-no frente a 18 países de entre sus miembros, para el período comprendido entre 1989:12 y 2003:10, el cual es publicado por el Banco de la República (Gráfico 1).
1.2 Metodología de modelado
1.2.1 El modelo de redes neuronales
Un perceptrón multicapa (MLP, por su sigla en inglés) es un modelo matemático que imita la estructura masivamente paralela de las neuronas del cerebro, cuya representación se presenta en el Gráfico 2 –véase a Masters (1993 y 1995) para una revisión general–. Este modelo puede aproximar cualquier función continua definida en un dominio compacto, con una precisión arbitraria previa-El MLP presentado en el Gráfico 2 se define mente establecida (Hornik, Stinchcombe y matemáticamente como: White, 1989; Cybenko, 1989; Funahashi 1989). En la práctica se ha caracterizado por ser muy tolerantes a información incompleta, inexacta o contaminada con ruido (Masters, 1993), por lo que han sido usados en la modelación empírica de series temporales no lineales. Zhang, Patuwo y Hu (1998) presentan una revisión general sobre el estado del arte, mientras que aplicaciones específicas son presentadas por Heravi, Osborn y Birchenhall (2004); Swanson y White (1997a y 1997b); Faraway y Chatfield (1998); Darbellay y Slama (2000); Kuan y Liu (1995), entre muchos otros.
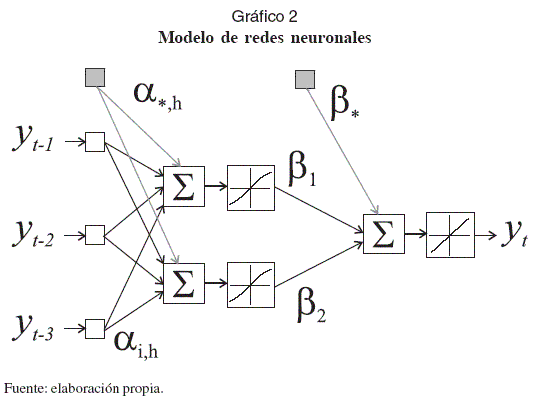
El MLP presentado en el gráfico 2 se define matemáticamente como:
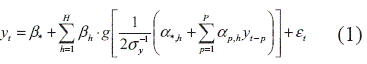
Los parámetros Ω = [β*, βh, α*,h, α p,h], h =1…H, p = 1…P son estimados usando el principio de máxima verosimilitud de los residuales. La ecuación definida por (1) equivale a un modelo estadístico no paramétrico de regresión no lineal (Sarle, 1994). En (1) se asume que ε t sigue una distribución normal con media cero y varianza desconocida σ2. H representa el número de neuronas en la capa oculta. P es el número de rezagos de la variable dependiente. Y g(·) es la función de activación de las neuronas de la capa oculta. En el contexto de las series temporales, el modelo puede ser entendido como una combinación lineal ponderada de la transformación no lineal de varios modelos autorregresivos.
El problema de identificación o estimación de parámetros está relacionado con la multiplicidad de puntos de mínima local de la función de error usada para la estimación de los parámetros, debido a que:
El efecto nocivo de estas características del MLP puede ser mitigado al modificar la función de activación de las neuronas ocultas y al imponer algunas restricciones a los parámetros del modelo:
• Tal como es indicado por LeCun, Bottou, Orr y Muller (1998), algunos autores han sugerido, por su experiencia práctica, que las funciones tipo sigmoidea simétricas alrededor del origen, convergen más rápidamente que la función sigmoidea tradicional. Adicionalmente, la incorporación de un término lineal puede ayudar a la convergencia, ya que se evita la saturación de la neurona y garantiza un gradiente mínimo cuando la salida neta de la función sigmoidea es cercana a sus valores extremos. Consecuentemente con las razones expuestas, el modelo propuesto activa sus neuronas de la capa oculta usando la función:
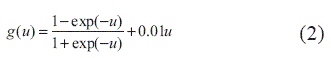
La división de la entrada neta a la neurona por 2σ y escala automáticamente las entradas al modelo, de tal forma que no es necesario realizar su preprocesamiento.
1.2.2 Selección del modelo
Por otra parte, el problema de selección del modelo (determinación de las variables relevantes y número de neuronas de la capa oculta) puede resolverse de una forma más adecuada a partir de pruebas de hipótesis, tal como es sugerido por Anders y Korn (1999). En este sentido, los contrastes de Wald, el multiplicador de Lagrange y el radio de verosimilitud aplican, ya que los parámetros tienen una distribución asintóticamente normal, siempre y cuando en su estimación se use el principio de máxima verosimilitud y el modelo no tenga neuronas ocultas redundantes.
Ello implica que en el proceso de selección se debe agregar una nueva neurona en la capa oculta, a fin de contrastar si la ganancia de su adición es significativa. Es bien sabido que estos resultados son válidos si el modelo no tiene neuronas ocultas redundantes, tal como es discutido por Fukumizu (2003), así como también que los tres contrastes anteriores son equivalentes asintóticamente; no obstante, poco es sabido cuando la muestra de datos es pequeña; usualmente, la elección del contraste usado para cada caso particular se realiza en función de la facilidad de su cálculo, aunque los resultados pueden ser significativamente diferentes para un mismo caso.
En este sentido, Anders y Korn (1999), así como muchos otros, argumentan que el proceso de selección del modelo debe ser realizado en forma constructiva: el primer modelo contiene una neurona en la capa oculta; el segundo, dos, y así sucesivamente. Por otra parte, en este estudio se considera que la prueba basada en el radio de verosimilitud es más apropiada, ya que tiene en cuenta el desempeño real del modelo aumentado con la nueva neurona, y no una aproximación, como ocurre en el contraste de multiplicadores de Lagrange. Consecuentemente, la metodología propuesta para la especificación del MLP es la siguiente:
1. Los regresores iniciales son determinados a partir de la especificación de un modelo AR de orden p usando un criterio de información como el de Akaike, Hannan y Quinn o Schwartz.
2. Se estima con el modelo con H = 1.
3. Se agrega una nueva neurona oculta y se estima el modelo.
4. Si la nueva neurona es aceptada usando la prueba del radio de verosimilitud se regresa al paso 3; de lo contrario se continúa con el paso 5.
5. Fin del algoritmo.
1.2.3 Evaluación del modelo
El modelo estimado se evalúa mediante la aplicación de dos grupos de pruebas para determinar sus bondades en la representación de la dinámica de la serie estudiada. Un primer grupo de pruebas está orientado a determinar si la secuencia de errores εt siguen una distribución normal. Las pruebas restantes se usan para determinar si los residuales son incorrelacionados o presentan algún tipo de heterocedasticidad. Una verificación final, obligatoria para cualquier modelo no lineal, es determinar sus propiedades dinámicas. Si el modelo es divergente, debería ser rechazado y, luego, realizar una nueva especificación o un nuevo proceso de estimación de sus parámetros. Las pruebas específicas llevadas a cabo y sus resultados son descritos en la próxima sección.
2. Resultados obtenidos y discusión
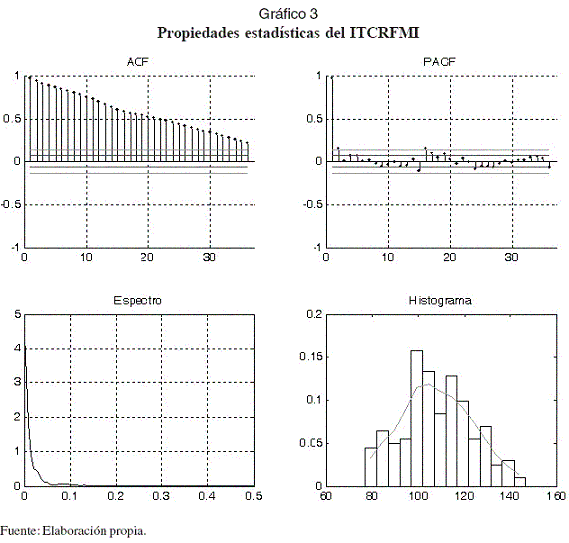
En esta sección se reportan los resultados de aplicar el proceso de especificación del MLP descrito en la sección anterior al ITCRFMI. La serie se encuentra disponible en la página web del Banco de la República de Colombia. Sus principales propiedades estadísticas son resumidas en el Gráfico 3. La inspección visual de la serie y de suautocorrelograma señalan indicios de que el ITCRFMI esté integrado; no obstante, los contrastes KPSS (con un estadístico de 2,109, p-crítico < 1%) y de Dickey-Fuller (con un estadístico de -1,3828, p-crítico > 10%) indican que la serie es estacionaria.
Siguiendo el primer paso del proceso de especificación, se estimaron modelos autorregresivos AR(p) para p = 1,…,12, y se calcularon para cada uno de ellos los criterios de información de Akaike, Hannan y Quinn y Schwartz. Los resultados son presentados en el Cuadro 1. Para complementar los resultados obtenidos en esta primera fase, se aplicaron las pruebas de no linealidad de Tsay, Kennan, White y RESET a cada uno de los modelos AR(p) estimados.
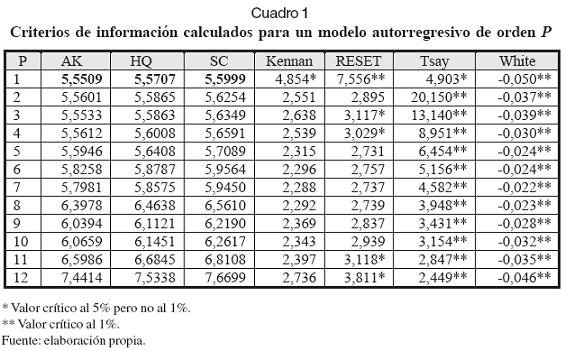
Las pruebas de White y Tsay indican que la serie es no lineal para todos los modelos estimados, usando un valor crítico del 5%. La prueba RESET indica no linealidad para los modelos AR(p) con p = 1, 3, 4, 11 y 12. La prueba de Kennan indica una evidencia moderada a favor de la no linealidad para el modelo AR(1). Los tres criterios de información considerados indican que el modelo óptimo es un AR(1), y para el cual las cuatro pruebas confirman la no linealidad de la serie estudiada.
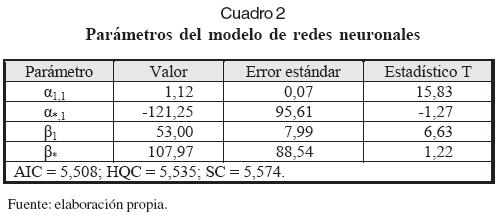
Como segundo paso del procedimiento se estimaron modelos MLP con H = 1 y 2. El estadístico para el contraste del radio de verosimilitud para los dos modelos es 2,923 (p = 0,404), por lo que se rechaza el modelo con H = 2. Los parámetros del modelo obtenido (H = 1) son reportados en el Cuadro 2, junto con los criterios de información calculados. En dicho cuadro, AIC es el criterio de información de Akaike; HQC, el criterio de información de Hannan-Quinn, y SC, el criterio de información de Schwartz.
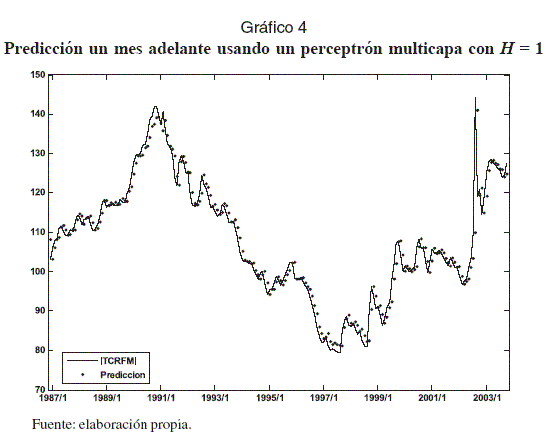
La predicción un mes adelante puede ser observada en el Gráfico 4.
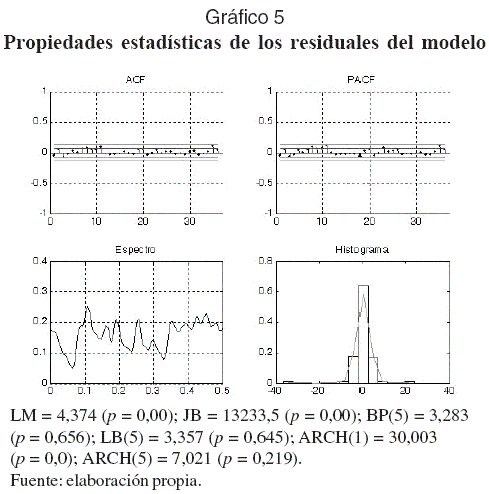
En el Gráfico 5 se resumen las principales propiedades estadísticas de los residuales: LM y JB son las pruebas de normalidad de Lin-Muldhokar y Jarque-Bera, respectivamente; BP y LB son las pruebas de correlación serial de Box-Pierce y Ljung-Box, respectivamente; ARCH es la prueba de heterocedasticidad de Engle (1982). Los residuales del modelo son incorrelacionados y no siguen una distribución normal. La prueba ARCH indica la presencia de heterocedasticidad en los residuales, pero se piensa que esto es un efecto, debido a que no se han incluido variables explicativas, más que una propiedad intrínseca de la serie misma.
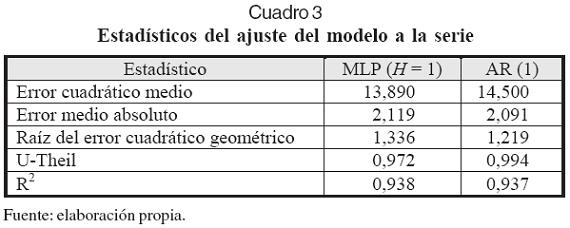
En el Cuadro 3 se reportan varias medidas de ajuste entre la serie y el modelo; particularmente, el estadístico U de Theil muestra la ganancia en la predicción un paso adelante en relación con la predicción asumiendo la hipótesis de que la serie sigue un paseo aleatorio.
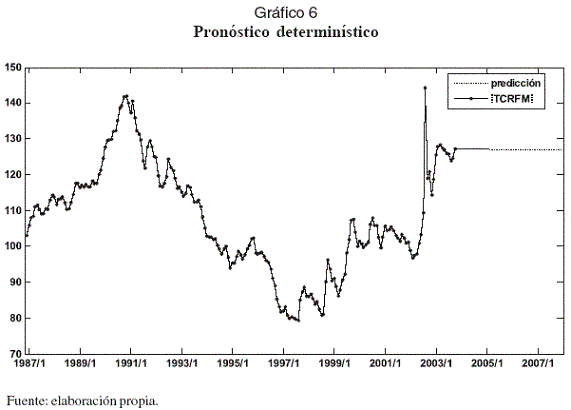
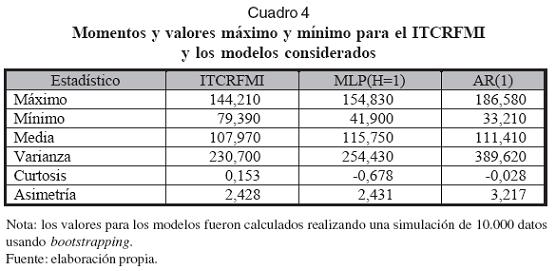
En el Gráfico 6 se puede apreciar el pronóstico determinístico del modelo. Finalmente, en el Cuadro 4 se presentan algunas de las propiedades de la serie analizada y del modelo de redes neuronales, las cuales fueron estimadas para una muestra de 10.000 datos usando bootstrapping. Su análisis indica que la distribución de probabilidades del modelo reproduce con alguna precisión la distribución de los datos de la serie real.
Para contrastar las ventajas del MLP, un modelo AR(1) fue estimado. Los estadísticos del ajuste a la muestra son presentados en el Cuadro 3 y señalan cómo el MLP recoge de mejor forma la dinámica de la serie estudiada. Una prueba del radio de verosimilitud fue aplicada a los dos modelos considerando que ellos son independientes. El estadístico obtenido fue 1,066 con p = 0,012, el cual indica que los pronósticos de ambos modelos son significativamente diferentes el uno del otro, lo que confirma la ventaja de la modelación usando la red neuronal artificial.
La relación σno_lineal/σlineal = 0,978, donde σlineal y σno_linealrepresentan la desviación estándar de los residuos de los modelos MLP y AR(1), respectivamente, da una idea de la ganancia relativa del ajuste de ambos modelos a los datos. Su valor cercano a la unidad indica que el modelo no lineal es necesario para caracterizar algunos períodos donde la dinámica de la serie es más compleja.
A partir del análisis anterior puede concluirse que la red neuronal obtenida es una representación más adecuada de la dinámica del ITCRFMI en relación con un modelo autorregresivo, ya que se ha demostrado que la serie es no lineal.
Conclusiones
Tanto el modelado como el pronóstico de variables económicas y financieras son importantes problemas que han recibido mucha atención tanto de profesionales como de investigadores durante las últimas décadas; consecuentemente, se han dedicado muchos esfuerzos para desarrollar metodologías que buscan superar las falencias y limitantes teóricas, conceptuales y prácticas que se presentan cuando cada serie particular es analizada a la luz de los modelos tradicionales. En este mismo sentido, resulta importante analizar la capacidad de modelado y predicción desde cada modelo y cada serie disponible en particular, esto es, determinar para cada serie cuál o cuáles son los modelos que mejor representan sus características, y para cada modelo, establecer cuáles son las características de las series que representa mejor.
En este estudio se realiza una primera contribución en esta dirección, ya que se analiza la serie del ITCRFMI con una red neuronal del tipo perceptrón multicapa, cuya especificación y aceptación está basada en criterios estadísticos, y se compara con un modelo autorregresivo que usa las mismas entradas. Los principales resultados obtenidos están relacionados con los siguientes aspectos: se demuestra a partir de criterios estadísticos que la serie sigue una dinámica no lineal; la red neuronal desarrollada captura las relaciones determinísticas de orden no lineal entre el valor actual de la ITCRFMI y el valor del mes anterior, de tal forma que los residuales obtenidos son menores en magnitud en relación con un modelo lineal que usa los mismos regresores. Consecuentemente, el modelo desarrollado es potencialmente un mejor predictor de la serie en comparación con un modelo lineal.
Existen otros modelos no lineales que podrían ser usados para representar la dinámica de la serie estudiada, de tal forma que en un trabajo futuro se hace necesario comparar dichos modelos para establecer cuál de ellos representa mejor la dinámica del ITCRFMI.
Agradecimientos
Los autores expresan sus agradecimientos a dos evaluadores anónimos, cuyos comentarios permitieron mejorar ampliamente la calidad del artículo.
Notas al pie de página
1. Este es un ejercicio de modelado y no de predicción, ya que se busca un modelo que pueda representar la dinámica de la serie estudiada y no el modelo que permita pronosticarla con la mayor precisión posible.
Lista de referencias
1. Anders, U. y Korn, O. (1999). Model selection in neural networks. Neural Networks, 12, 309-323. [ Links ]
2. Ayala, M. y Castillo, R. D. (2005). Un modelo de predicción para el valor TRM: un acercamiento desde las redes neuronales artificiales. Recuperado de: http://www.usergioarboleda.edu.co/observatorio_economico/Redes_Neuronales/Sistemas_Inteligentes.htm [ Links ]
3. Banco de la República (2002). Reportes del Emisor (40). [ Links ]
4. Calderón, A. (1995). La tasa de cambio real en Colombia: mitos y realidades. Coyuntura Económica, XXV (2), 101-111. [ Links ]
5. Cao, L. y Soofi, A. S. (1999). Nonlinear deterministic forecasting of daily dollar exchange rates. International Journal of Forecasting, 15, 421430. [ Links ]
6. Clements, M. P. y Smith, J. (2001). Evaluating forecasts from SETAR models of exchange rates. Journal of International Money and Finance, 20, 133-148. [ Links ]
7. Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems 2, 202-314. [ Links ]
8. El Shazly, M. y El Shazly, H. E. (1999). Forecasting currency prices using a genetically evolved neural network architecture. International Review of Financial Analysis, 81, 67-82. [ Links ]
9. Darbellay, G. y Slama, M. (2000), Forecasting the short-term demand for electricity: do neural networks stand a better chance? International Journal of Forecasting, 16, 71-83. [ Links ]
10. De Gooijer, J. G., Ray, B. K. y Krager, H. (1998). Forecasting exchange rates using TSMARS. Journal of International Money and Finance, 17, 513-534. [ Links ]
11. Echavarría, J. J y Gaviria, A. (1992). Los determinantes de la tasa de cambio y la coyuntura actual en Colombia. Coyuntura Económica, XXII, 4, 101-111. [ Links ]
12. Engle, R. (1982). Autoregressive conditional heterocedasticity with estimates of the variance of United Kingdom inflations. Econometrica (50), 987-1007. [ Links ]
13. Faraway, J. y Chatfield, C. (1998). Time series forecasting with neural networks: a comparative study using the airline data. Journal of Applied Statistics (47), 231-250. [ Links ]
14. Fukumizu, K. (2003). Likelihood ratio of unidentifiable models and multilayer neural networks. Annals of Statistics, 31 (3), 833-851. [ Links ]
15. Funahashi, K. (1989). On the approximate realization of continuous mappings by neural networks. Neural Neworks, 2, 183-192. [ Links ]
16. Granger, C. y Teräsvirta, T. (1993). Modeling nonlinear economic relationships. Oxford: Oxford University Press. [ Links ]
17. Gómez, J. (1999). A model of the nominal and real exchange rates in Colombia. Serie Borradores de Economía (129). Bogotá: Banco de la República. [ Links ]
18. Heravi, S., Osborn, D. y Birchenhall, C. (2004). Linear versus neural network forecasts for European industrial production series. International Journal of Forecasting (20), 435-446. [ Links ]
19. Hornik, K., Stinchcombe, M. y White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2, 359-366. [ Links ]
20. Ince, H. y Trafalis, T. B. (2006). A hybrid model for exchange rate prediction. Decision Support Systems, 42(2), 1054-1062. [ Links ]
21. Kilian, L. y Taylor, M. P. (2003). Why is it so difficult to beat the random walk forecast of exchange rates? Journal of International Economics, 60, 85-107. [ Links ]
22. Kuan, C. y Liu, T. (1995). Forecasting exchange rates using feedforwad and recurrent neural networks. Journal of Applied Econometrics (10), 347-364. [ Links ]
23. Langebaek, A. (1993). Tasa de cambio real y tasa de cambio de equilibrio. Serie Archivos de Macroeconomía. Departamento Nacional de Planeación, Unidad de Análisis Macroeconómico. Documento 19, 27 p. [ Links ]
24. LeCun, Y., Bottou, L., Orr, G. B. y Muller, K. R. (1998). Efficient backprop. En: Neural networks: Tricks of the trade (pp. 5-50). Springer Lecture Notes in Computer Sciences 1524. [ Links ]
25. Masters, T. (1993). Practical neural network recipes in C++. New York: Academic Press. [ Links ]
26. Masters, T. (1995). Neural, novel and hybrid algorithms for time series prediction. New York: John Wiley and Sons. [ Links ]
27. Meisel, A. (1994). Cómo determinar si el peso está sobrevaluado o subvaluado. Borradores Semanales de Economía (6). Bogotá: Banco de la República. [ Links ]
28. Milas, C. y Otero, J. (2002). Modelling oficial and parallel exchange rates in Colombia under alternative regimes: a non-linear approach. Economic Modelling, 20, 165-179. [ Links ]
29. Patiño, C. I. y Alonso, J. C. (2005). Determinantes de la tasa de cambio nominal en Colombia: evaluación de pronósticos. Manuscrito no publicado. [ Links ]
30. Revéiz, A. (2002). Evolution of the Colombian peso within the currency bands, nonlinear analysis and stochastic modeling. Rev. Econ. Ros., 5(1), 37-91. [ Links ]
31. Sarle, W. (1994). Neural networks and statistical models. Documento presentado en The 19th Annual SAS Users Group Int. Conference, Cary, NC: SAS Institute, pp. 1538-1550. [ Links ]
32. Swanson, N. y White, H. (1997a). Forecasting economic time series using adaptive versus nonadaptive and linear versus non-linear econometric models. International Journal of Forecasting (13), 439-461. [ Links ]
33. Swanson, N. y White, H. (1997b). A model selection approach to real time macroeconomic forecasting using linear models and artificial neural networks. Review of Economics and Statistics (39), 540-550. [ Links ]
34. Tseng, F. M., Tzeng, G. H., Yu, H. C. y Yuan, B. J. C. (2001). Fuzzy ARIMA model for forecasting the foreign exchange market. Fuzzy Sets and Systems, 118, 9-19. [ Links ]
35. Van Djck, D. (1999), Smooth transition models: extensions and outlier robust inference. Tesis de Ph. D. no publicada, Erasmus University, Rotterdam, Holanda. [ Links ]
36. Zhang, G., Patuwo, B. y Hu, M. (1998). Forecasting with artificial neural networks: the state of the art. International Journal of Forecasting (14), 35-62. [ Links ]

