











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introducción
No todas las discontinuidades en un macizo rocoso tienen un mismo origen en su formación (e.g.en distinto tiempo pueden existir diferentes estados de esfuerzos en el macizo rocoso); pero si fuera el caso, una sola causa que genera discontinuidades en el macizo rocoso puede crear más de un conjunto disjunto (e.g. diaclasas, fracturas de corte, de tracción y de compresión). Por tanto, un macizo rocoso puede tener más de una familia de discontinuidades.
En un macizo de un solo tipo de material rocoso, las propiedades geométricas de cada una de las familias de discontinuidades (como la ondulación, la rugosidad, el espesor) por lo general son distintas. Una de las propiedades más influyentes para diferenciar cada una de las familias de discontinuidades es sin duda laorientación espacialde esta; por tanto, en la práctica se usa esta variable como la principal para diferenciar entre familias.
De este modo, se puede usar métodos de diferenciación de familias (métodos de agrupamiento de datos [en inglés Clustering methods]) para encontrar de forma automática las orientaciones más esperadas de un conjunto de datos que son de un mismo macizo rocoso. Sin embargo, no es tan fácil porque la orientación espacial de un plano se la determina no por un escalar sino por un vector de 3×1. Aun así, existen métodos para hacer este cálculo de diferenciación de familias por agrupamiento estadístico y además de forma automática. En este artículo se explica un algoritmo que posibilita el agrupamiento automático de orientaciones que se ha implementado en un software de aplicación denominado DiscontClust.
2. Método de agrupamiento de orientación de planos
El método que se usó en el desarrollo del software a aplicación para el agrupamiento automático de datos de orientaciones de planos es el método espectral presentado para el caso de discontinuidades en macizos rocosos por Jimenez-Rodriguez and Sitar (2006) [1].
Se toma en cuenta un conjunto de datos con N medidas de la orientación de las discontinuidades en la roca con el fin de agrupar en K familias (el número de familias la define uno mismo, debido a que el método no le dice a uno cuántas familias son las óptimas).
El algoritmo es el siguiente.
1. Calcule la matriz de afinidad
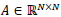 sabiendo que cada elemento de esa matriz está dada por
sabiendo que cada elemento de esa matriz está dada por
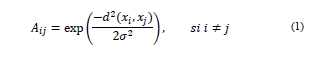
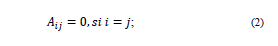
donde el operador
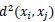 se define como la medida de similitud (la distancia) basada en la función seno de los vectores unitarios
se define como la medida de similitud (la distancia) basada en la función seno de los vectores unitarios
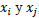 ; es decir
; es decir
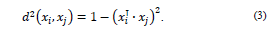
El escalar
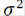 controla cómo la medida de similitud entre dos medidas decae con la distancia entre estas dos orientaciones observadas; mientras mayor es el valor de
controla cómo la medida de similitud entre dos medidas decae con la distancia entre estas dos orientaciones observadas; mientras mayor es el valor de
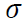 menor es el decaimiento de afinidad cuando la distancia incrementa. El valor de
menor es el decaimiento de afinidad cuando la distancia incrementa. El valor de
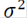 se recomienda se elija dentro del intervalo
se recomienda se elija dentro del intervalo
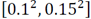 para tener un valor adecuado de la agrupación. Jimenez-Rodriguez and Sitar (2006) [1] recomiendan un valor de
para tener un valor adecuado de la agrupación. Jimenez-Rodriguez and Sitar (2006) [1] recomiendan un valor de
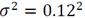 .
.
2. Defina
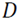 , la matriz de afinidad, como la matriz diagonal de elementos
, la matriz de afinidad, como la matriz diagonal de elementos
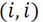 que se calcula como la suma de la iésima fila de A. Aquí, cada elemento
que se calcula como la suma de la iésima fila de A. Aquí, cada elemento
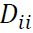 es la suma de las afinidades de la observación
es la suma de las afinidades de la observación
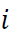 respecto las demás observaciones en el conjunto total de datos.
respecto las demás observaciones en el conjunto total de datos.
3. Calcule la matriz
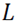 (llamada la matriz de afinidad normalizada) dada por
(llamada la matriz de afinidad normalizada) dada por
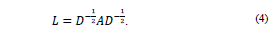
4. Calcule los primeros
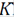 mayores autovalores de L y sus correspondientes autovectores
mayores autovalores de L y sus correspondientes autovectores
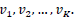
5. Cree la matriz 𝑉 tras agrupar los Kautovectores
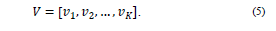
6. Forme la matriz
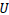 a partir de
a partir de
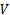 tras normalizar esta última en cada fila, de tal forma que cada fila tenga una longitud unitaria; esto es
tras normalizar esta última en cada fila, de tal forma que cada fila tenga una longitud unitaria; esto es
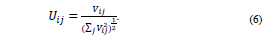
7. Tomando en cuenta que cada fila de
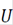 representa un punto en el espacio
representa un punto en el espacio 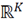 , realice la agrupación de cada fila de
, realice la agrupación de cada fila de
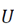 en subconjuntos, esto usando el algoritmo de K-means.
en subconjuntos, esto usando el algoritmo de K-means.
8. Asigne el punto original
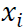 a un grupo
a un grupo
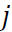 si y solo si la fila
si y solo si la fila
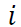 de la matriz
se ha asignado al grupo
en el anterior paso.
de la matriz
se ha asignado al grupo
en el anterior paso.
El algoritmo de arriba realiza una transformación de las 𝑁 observaciones de las orientaciones de las discontinuidades desde el espacio original cartesiano en
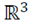 al nuevo espacio en
Las coordenadas de los puntos en el espacio transformado se dan por la normalización de las filas de aquella matriz que se obtiene de los autovectores provenientes de la descomposición espectral de la matriz de afinidad de las observaciones iniciales.
al nuevo espacio en
Las coordenadas de los puntos en el espacio transformado se dan por la normalización de las filas de aquella matriz que se obtiene de los autovectores provenientes de la descomposición espectral de la matriz de afinidad de las observaciones iniciales.
3. Programa computacional aplicado DiscontClust
El programa computacional aplicado DiscontClust fue codificado en el lenguaje intérprete GNU Octave para su versión igual o mayor a la 3.8.0; i.e. Octave (>= 3.8.0). El lenguaje GNU Octave es un lenguaje que ha nacido con el fin de ofrecer al público la versión libre y no comercial del lenguaje MATLAB. En un principio (en la década de los 90 del siglo pasado y hasta mediados del primer decenio de este siglo), los dos lenguajes eran muy similares; sin embargo, hoy en día MATLAB ha reestructurado sus funciones de tal modo de posibilitar y ofrecer a sus usuarios el concepto de programación orientada a objetos y además MATLAB ha ido desarrollado una serie de paquetes completos para cada especialización de las ciencias y las disciplinas de la ingeniería. Hoy en día, MATLAB y Octave se los puede considerar como lenguajes distintos, con sus propios alcances y reglas, aunque con una sintaxis similar.
El núcleo principal del programa DiscontClust (i.e. mainToolBox) está compuesto por diez funciones procedimentales, de las cuales seis se usan para presentar los datos (data presentation functions), una para preparar los datos antes del análisis (preanalysis function), dos funciones que realizan tareas independientes (auxiliar functions) al ser llamado por una sola función principal (main function) que realiza el cálculo de agrupación; tal como se muestra en el listado de las funciones del programa en la Figura 1.
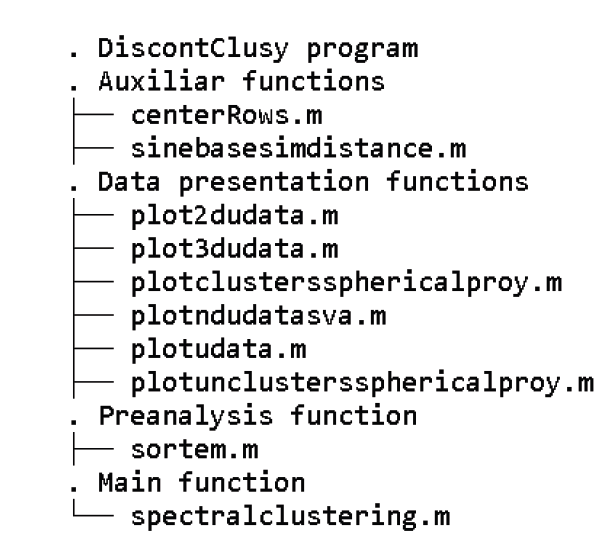
Estas diez funciones se alojan en un directorio para poder ser usado con la combinación de otros programas que requieran hacer esta operación. Las funciones se pueden hacer correr desde la consola de GNU Octave o desde otros programas.
Para tener mayores capacidades de preanálisis con datos de orientaciones espaciales de discontinuidades y para también tener mayores capacidades gráficas en el postanálisis usted debe usar la librería BuzyPlus que puede descargarlo de este enlacede GitHub (librería también desarrollado por el presente autor).
Esta librería es aparte a este desarrollo, pero unos cuántos archivos principales (no todos) se coloca dentro del directorio del presente desarrollo DiscontClust con el fin de tener las mínimas capacidades gráficas en los ejemplos y validaciones de esta herramienta.
De este modo, el programa DiscontClust tiene en su propio directorio las siguientes nueve funciones provenientes del programa BuzyPlus (Figura 2).
Para facilidad del usuario de DiscontClust todos estos archivos se han puesto en un paquete de instalación (llamado en Octave package y conocido con la sigla pkg.


Este paquete se instala en la consola de Octave mediante el administrador de paquetes del mismo nombre; que para el caso presente se instalaría del siguiente modo
pkg install discontclust-0.1.0.tar.gz
El paquete tiene dependencias de tres librerías básicas de Octave, estas son io (>=2.4.5), image(>=2.6.1), y statistics(>= 1.3.0).
Una vez instalado en su máquina, para su uso, el usuario debe cargarlo mediante la siguiente oración
pkg load discontclust
De este modo, si las tres librerías básicas están instaladas, el encabezado normal cuando se quiera hacer correr un archivo de lotes con la implementación de DiscontClust sería como se muestra en la Figura 3.
4. Funcionamiento del programa
El programa de aplicación DiscontClust necesita un archivo de texto como entrada donde deben estar las medidas de orientaciones de planos de discontinuidades que se van a someter al algoritmo de búsqueda automática.
En este archivo de texto plano (plain text), cada fila corresponde a la información de la orientación de una discontinuidad; de tal modo que si se tiene 𝑚 datos se tiene 𝑚 filas en el archivo. Cada fila está compuesta por dos números separados por un espacio; el primer número indica siempre la dirección de buzamiento de la discontinuidad (dado en grados sexagesimales) y el segundo número indica el buzamiento de la misma, también en grados sexagesimales. El siguiente listado muestra los primeros dos y finales dos datos de las orientaciones de la primera validación que se explica en la siguiente sección.
48 7 46 0 : : 277 58 278 55
Esto indica que se tiene discontinuidades con orientaciones
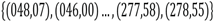 dados en un par ordenado de dirección de buzamiento y buzamiento.
dados en un par ordenado de dirección de buzamiento y buzamiento.
También el programa necesita de forma opcional que se introduzca el tipo de proyección esférica en el cual se quiere representar los datos agrupados e introducir el valor de la variable sigma. En caso que no se coloquen estos, los valores por defecto son a una proyección esférica equiárea y una valor de .
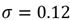 En el paquete mínimo incluido en DiscontClust solo acepta la proyección más usada, la proyección esférica equiárea; si quiere usar la equiángulo debe instalar el paquete BuzyPlus.
En el paquete mínimo incluido en DiscontClust solo acepta la proyección más usada, la proyección esférica equiárea; si quiere usar la equiángulo debe instalar el paquete BuzyPlus.
Las variables de salida son tres: knTParrayCell, lCell y knNormEigVecCell, pero la más importante es la primera variable knTParrayCell; las dos restantes son opcionales y sirven para hacer las gráficas de los puntos en el espacio
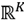 .
.
La estructura de la variable de salida knTParrayCell es una lista (en Octave se llama una célula, i.e. Cell) de dimensión 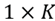 donde en cada elemento se almacena un arreglo de dimensión
donde en cada elemento se almacena un arreglo de dimensión
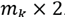 , siendo
, siendo
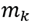 el número de datos perteneciente a cada familia. La primera columna del arreglo indica la dirección de buzamiento de la discontinuidad y la segunda columna indica el buzamiento. El siguiente listado muestra los primeros dos y últimos dos datos de las dos familias del anterior ejemplo.
el número de datos perteneciente a cada familia. La primera columna del arreglo indica la dirección de buzamiento de la discontinuidad y la segunda columna indica el buzamiento. El siguiente listado muestra los primeros dos y últimos dos datos de las dos familias del anterior ejemplo.
[1,1] =
48 7
46 0
: :
211 1
32 0
105 55
79 58
: :
277 58
278 55
El listado indica que en la primera familia se tiene agrupadas las orientaciones que tienen una orientación de
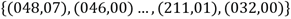 y en la segunda familia las orientaciones de
y en la segunda familia las orientaciones de
 De esto, el dato
De esto, el dato
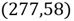 indica una discontinuidad con una orientación dada por una dirección de buzamiento de
indica una discontinuidad con una orientación dada por una dirección de buzamiento de
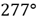 y un buzamiento de
y un buzamiento de
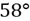 por ejemplo.
por ejemplo.
Esta variable se puede usar dentro del mismo Octave para posteriores desarrollos o se puede exportar a un archivo de texto; libertad de manipulación que tiene el usuario al ser un desarrollador en el lenguaje Octave.
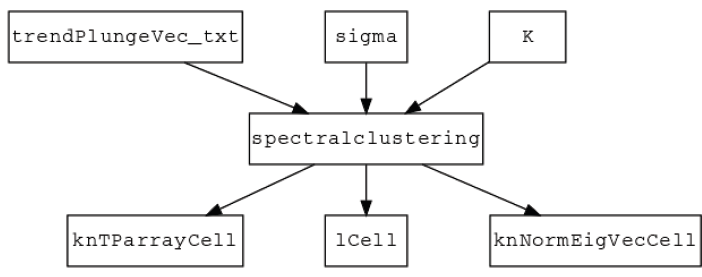
La Fig. 4 muestra las variables de entrada y salida que entran en el algoritmo spectralclustering.
5. Validaciones
En esta sección se muestra las validaciones de programa DiscontClust tomando los ejemplos que están en el artículo de publicado de Jimenez-Rodriguez and Sitar (2006) [1] donde presentan este método.
5.1. Validación 1: macizo rocoso Sitio c1904
El material de esta validación la puede descargar de este enlace.
Se digitalizaron los 327327 datos de la Fig. 3c del artículo de Jimenez-Rodriguez and Sitar (2006) [1]. La digitalización se hizo con el programa Geonetdigitizer (Suarez-Burgoa, 2015 [2]) y los datos se almacenaron en un archivo de texto llamado validation1data.txt (que puede descargarlo aquí).
Los datos de esa figura tomada como ejemplo para la validación de este programa corresponden a unos datos reproducidos por Herda et al., (1991) [3] catalogado como Sitio c1904 y corresponde a medidas de fracturas en un macizo rocoso.
Inicialmente, los datos digitalizados no están diferenciados, solo después de la aplicación del programa se obtiene el agrupamiento por familias de forma automática. Para ello, se hace correr el un archivo de lotes configurado para realizar la tarea llamando a las diversas funciones que componen el programa DiscontClust. Esta codificación es guardada en el archivo de lotes validation1dataSCR.m.
El siguiente listado muestra el contenido del archivo de lotes validation1dataSCR.

En las siguientes líneas se explica qué es lo que ordena a Octave el contenido del archivo de lotes mostrado arriba.
La primera línea indica al intérprete de Octave que es un archivo de lotes y no una función.
La segunda línea efectiva (efectiva, que no tiene comentario) instala el paquete discontclust-0.1.0.tar.gz.
Las siguientes tres líneas efectivas del código (efectiva que no tiene comentario) cargan librerías básicas de Octave. Respectivamente importa la librería io que es la librería para manipular los comandos de entrada y salida de datos; luego importa la librería image para graficar; y finalmente la librería statistics que tiene la función de K-means.
Inmediatamente después se carga la la librería discontclust.
Después del comentario General plot parameters está claro que las dos siguientes líneas indican la proyección esférica con la que se graficarán los puntos (que representan las orientaciones) y el tamaño del símbolo de los puntos.
Del mismo modo, después del comentario Import data from 'txt' file, las siguientes líneas definen el nombre del archivo texto donde están almacenados los datos que lo importa del archivo para almacenarlo en un arreglo en la variable trendPlungeArray. Los datos deben estar en el directorio de trabajo de Octave.
Con el comentario Performing the spectral clustering se inicia el bloque para hacer el proceso de agrupamiento automático. Las dos primeras líneas definen el número de familias que se quiere encontrar con el algoritmo (que en este caso dice que serán dos) y asigna el valor de 𝜎 igual a 0.12. La tercera línea (la más importante) llama para hacer correr la función spectralclustering dando como variables de entrada: los datos de las orientaciones de las discontinuidades, el valor del número de familias y el valor de sigma previamente asignados. El resultado se almacena en una variable llamada knTParrayCell.
La última línea efectiva del archivo de lotes hace correr la función plotclusterssphericalproy con la celda que almacena todas las orientaciones agrupadas en dos grupos o familias, resultado del proceso de agrupamiento. Esta función (como su nombre lo indica) grafica los resultados en una ventana nueva mediante el programa gnuplot.
En la variable de salida knTParrayCell se almacena las mismas medidas pero agrupadas en K familias.
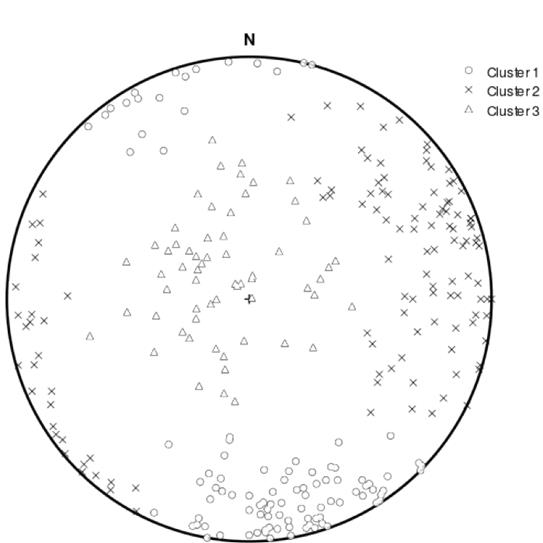
La Fig. 6 muestra cómo el programa reconoce dos familias de discontinuidades de forma automática, dando un resultado igual al presentado en el artículo original.
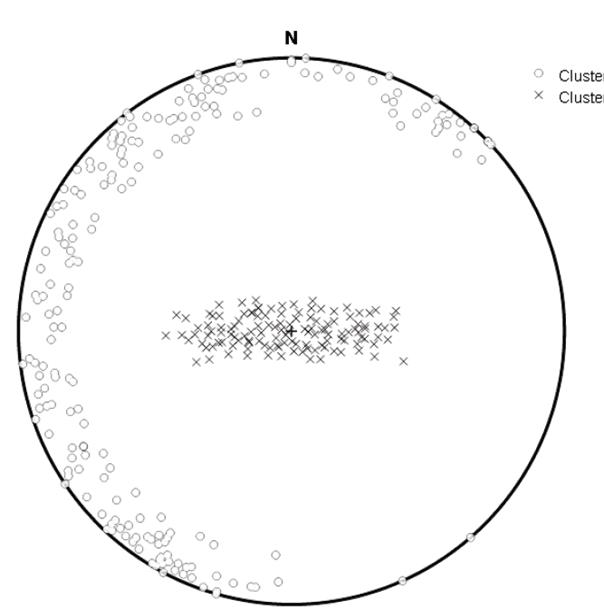
Fuente: El Autor.
Figura 6. Diagrama esférico equiárea de la orientación de las discontinuidades, donde se diferencian dos familias a partir de la agrupación automática usando el programa DiscontClust.

Fuente: El Autor
Figura 7. El entorno gráfico del programa Octave-Online luego de haber hecho correr el archivo de lotes de esta validación.
Esta validación (y cualquiera de las siguientes, más los ejemplos) se puede hacer correr en la nube ingresando a un desarrollo en línea de Octave en la página web https://octave-online.net/. Para ello debe crear una cuenta personal, dentro de ella subir los archivos discontclust−0.1.0.tar.gz, validation1data.txt y validation1dataSCR.m para finalmente hacer correr el archivo de lotes escribiendo en la terminal simplemente run validation1dataSCR. La Fig. 7 muestra el entorno gráfico de esta aplicación en la nube, donde se hizo correr el archivo de lotes de esta validación.
Se observa en la Fig. 7 que la ventana del entorno gráfico se divide en ocho puertos de vista. En la parte superior (en todo el ancho) está una franja con el nombre de la aplicación y en la parte derecha la opción del MENU que activa la vista larga vertical de la derecha, donde se observa el poseedor de la cuenta y una serie de opciones donde se puede compartir el desarrollo, cambiar la clave, ayudas, etc. Luego en la vista larga vertical de la parte izquierda se tiene información de los archivos que están en el directorio en la nube en la cuenta del usuario, se puede apreciar claramente el paquete con todos sus archivos y los dos archivos de extensión .txt y .m. En la parte central la vista se divide en cinco, en la parte izquierda se tiene algunas ayudas rápidas, mientras que en el resto se tiene las cuatro vistas, en la parte inferior derecha la línea de comando donde se ve run validation1dataSCR, por encima de este se muestra (sea el caso) el historial de la línea de comando. En la parte izquierda se tiene la lista variables que están en memoria, como ser
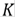 , ans, knNormEigVecCell, lCell, projectionType, sigma, symbolSize y trendPlunge Array.
, ans, knNormEigVecCell, lCell, projectionType, sigma, symbolSize y trendPlunge Array.
Finalmente, en la parte superior se tiene la ventana donde aparece los resultados gráficos, que en este caso es el diagrama en proyección esférica con los resultados de las familias agrupadas, este gráfico se puede exportar en una imagen de extensión .png o un dibujo vectorial de extensión .svg.
¡Con Octave-OnLine no necesita instalar Octave en su máquina!
5.2. Validación 2: macizo rocoso mina San Manuel
El material de esta validación la puede descargar de este enlace.
Para esta segunda validación, se digitalizó 283 puntos de la Fig. 4d del mismo artículo de Jimenez-Rodriguez and Sitar (2006) [1]. También, la digitalización se hizo con el programa Geonetdigitizer (Suarez-Burgoa, 2015 [2]) y los datos se almacenaron en un archivo de texto llamado validation2data.txt.
Los datos así digitalizados pertenecen a la toma de datos manual de un afloramiento de la mina de cobre San Manuel en Arizona EE.UU, reportado en Klose et al. (2005). [4]
Esta vez, se configuró el archivo de lotes de tal forma que con esos datos se encuentren tres familias.
La Fig. 8 muestra cómo el programa reconoce esas tres familias de discontinuidades de forma automática, dando también un resultado igual al presentado en el artículo original.
5.3. Validación 2: macizo rocoso de serpentinita
El material de esta validación la puede descargar de este enlace.
En esta tercera y última validación se digitalización 174 datos que corresponden a medidas manuales (por el método de a línea de rastreo) de orientaciones de discontinuidades en un afloramiento de serpentinita al sur de España Jimenez-Rodriguez and Sitar (2006). [1]
En este caso, se hizo mayores procedimientos de análisis debido a que el artículo con el que se está validando el funcionamiento del programa DiscontClust obtiene para los mismos datos: dos y tres posibles familias de agrupación; asimismo, los autores grafican los datos en el espacio transformado
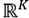 para observar que las agrupaciones son correctas. Los mismos gráficos son producidos con el programa que se ha elaborado, con DiscontClust.
para observar que las agrupaciones son correctas. Los mismos gráficos son producidos con el programa que se ha elaborado, con DiscontClust.
En el análisis, se obliga al programa que realice con los mismos datos tres análisis, un primer análisis en el que encuentre dos familias de discontinuidades, un segundo análisis que encuentre tres familias, y un tercer análisis que encuentre más de tres familias. Para los dos primeros casos el programa DiscontClust tiene sus representaciones gráficas en
 , pero para una dimensión de
, pero para una dimensión de
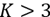 no se tiene una representación gráfica por no poderse representar el espacio
en un diagrama cartesiano ortogonal.
no se tiene una representación gráfica por no poderse representar el espacio
en un diagrama cartesiano ortogonal.
Del mismo modo al caso de los dos anteriores ejemplos, se observa que el programa DiscontClust ha respondido de forma exacta los resultados de la investigación con la que se está validando. La Fig. 9 muestra las representaciones gráficas en el diagrama estereográfico del proceso de agrupación a dos familias más su respectiva gráfica en el espacio
 , para
, para
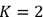 .
.
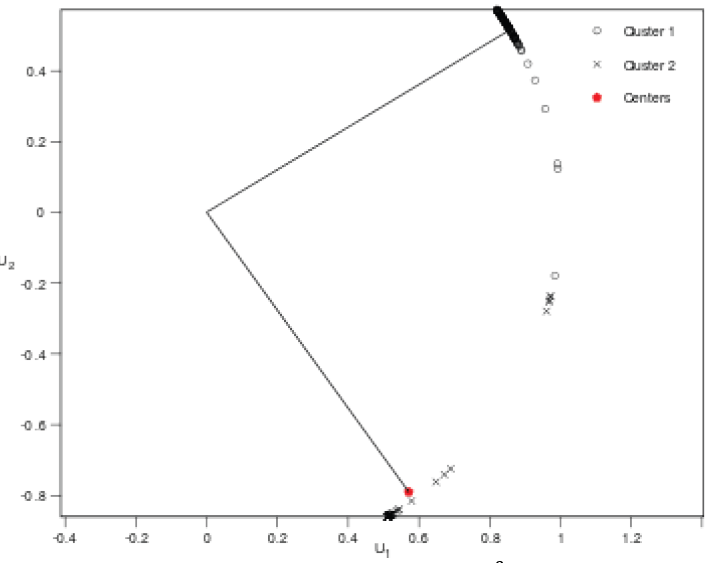
Del mismo modo que el caso anterior, la Fig. 10 muestra las representaciones gráficas en el diagrama estereográfico del proceso de agrupación ahora de tres familias más su respectiva gráfica en el espacio
, para
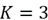 .
.
La Fig. 11 muestra el diagrama esférico equiárea del proceso de agrupación a cuatro familias de los mismo datos.
Fuente: El Autor.
Figura 9. a) Diagrama de proyección esférica equiárea con las dos familias diferenciadas. b) Puntos de los datos en el espacio transformado
 concentrados en dos ejes. Resultados del proceso de agrupación automática de datos de discontinuidades para dos familias.
concentrados en dos ejes. Resultados del proceso de agrupación automática de datos de discontinuidades para dos familias.
Fuente: El Autor.
Figura 10. a) Diagrama de proyección esférica equiárea con las tres familias diferenciadas. b) Puntos de los datos en el espacio transformado ℝ 3 concentrados en dos ejes. Resultados del proceso de agrupación automática de datos de discontinuidades para tres familias.
Fuente: El Autor.
Figura 11. Diagrama esférico equiárea de la orientación de las discontinuidades, donde se diferencian cuatro familias a partir de la agrupación automática usando el programa DiscontClust.
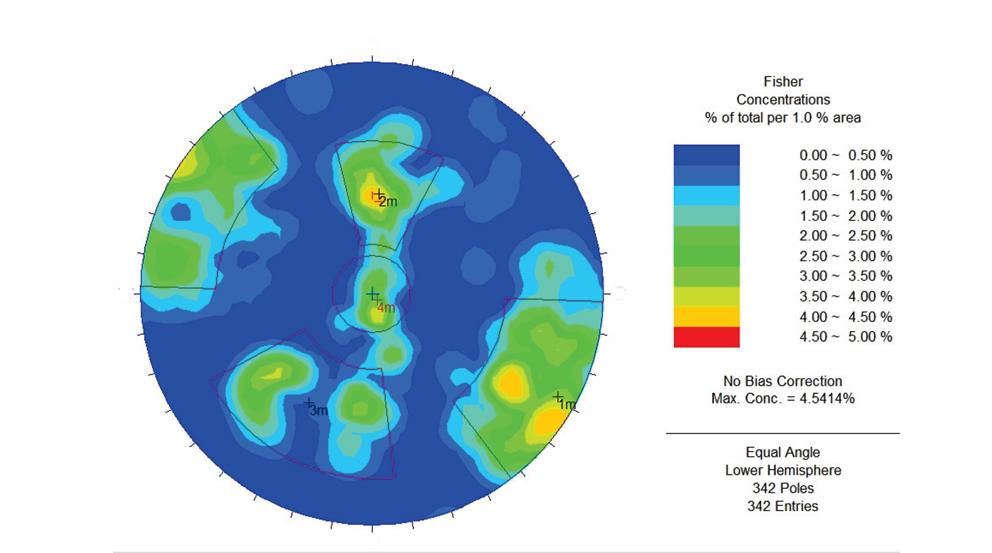
Fuente: Suarez-Burgoa, 2008 [5].
Figura 12. Diagrama esférico equiángulo de la orientación de las discontinuidades de la casa de máquinas de Porce 3, donde se diferencian cuatro familias encontradas de forma heurística manual a partir de un diagrama de concentraciones.
6. Ejemplos
A continuación se presenta dos ejemplos más con datos tomados en macizos rocosos en Colombia.
6.1. Ejemplo 1: macizo rocoso de la casa de máquinas de Porce 3
El material de esta validación la puede descargar de este enlace.
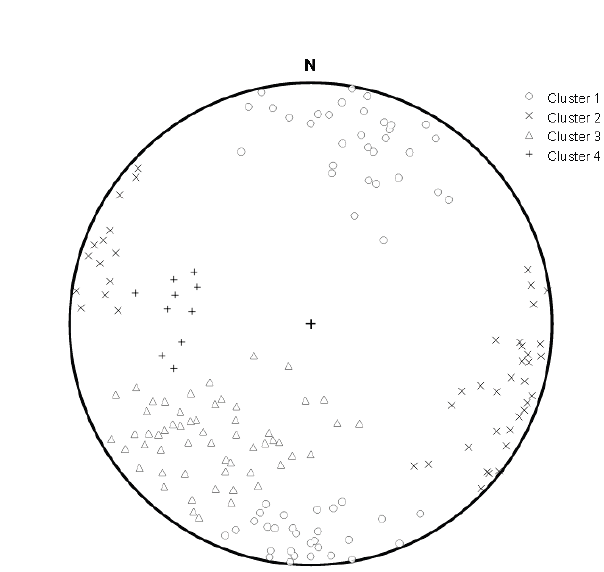
Para este primer ejemplo, se tuvo acceso a la lectura de 342 datos de medidas de orientaciones de discontinuidades en el techo de la casa de máquinas del proyecto hidroeléctrico Porce 3 entre las progresivas
 Con esos datos, Suarez-Burgoa (2008) [5] elaboró un diagrama de concentraciones de polos (mostrado en proyección equiangular) y a criterio heurístico se encontraron cuatro familias de discontinuidades agrupadas en tres ventanas rectangulares y una ventana circular, tal como se muestra en la Fig. 12. Esta es la práctica habitual en la actualidad por la carencia de una herramienta separada de distribución libre que posibilite la selección automática como la que se expone en este texto.
Con esos datos, Suarez-Burgoa (2008) [5] elaboró un diagrama de concentraciones de polos (mostrado en proyección equiangular) y a criterio heurístico se encontraron cuatro familias de discontinuidades agrupadas en tres ventanas rectangulares y una ventana circular, tal como se muestra en la Fig. 12. Esta es la práctica habitual en la actualidad por la carencia de una herramienta separada de distribución libre que posibilite la selección automática como la que se expone en este texto.
Con el programa DiscontClust se encontraron también cuatro familias, pero dos de ellas se alejan del criterio de selección actual. La Fig. 13 muestra los resultados del proceso de agrupación de familias (encontrada con este programa) puesto encima de la imagen del diagrama de concentraciones de polos (obtenida con el programa BuzyPlus), aquel mencionado en el estudio (esta vez es una proyección equiárea porque el programa DiscontClust en su versión reducida limita solo a esta proyección).
Se observa que dos de las familias encontradas con el criterio heurístico manual son parecidas a las familias obtenida por el proceso automático, pero dos de ellas se sobreponen tal como se muestra en la Fig. 14.
Las familias F2 y F4 fueron encontradas por el proceso automático y las G3 y G4 por el método heurístico manual. Aquí hay una contradicción cuando por ambos criterios se obtienen conjuntos que comparten elementos.
La condición de la elección de familias es que estos sean conjuntos disjuntos (es decir, que no compartan elementos con otros grupos); esto indica a que uno de los métodos no está obteniendo los conjuntos de forma correcta. A la luz de un proceso automático bajo un fundamento matemático-estadístico, es más factible dar crédito al método automático que el método manual. Otro aspecto que uno puede observar, es que la agrupación de polos no necesariamente forma un conjunto escogido por una ventana rectangular o circular.
6.2. Ejemplo 2: macizo rocoso Anticlinal Monterralo
El material de esta validación la puede descargar de este enlace.
Los datos que se analizan en este ejemplo corresponden a los planos de afloramientos todos ellos que pertenecen al Anticlinal de Monterralo, ubicado en el Piedemonte Llanero en la Coordillera Oriental de Colombia. Los datos fueron digitalizados de la tesis de Sanchez-Villar (2011) [6] mediante el programa GeonetDigitizer [Suarez-Burgoa, 2015] [2] y luego fueron analizados con el programa DiscontClust.

Fuente: El Autor.
Figura 13. Diagrama esférico equiárea de la orientación de las discontinuidades de la casa de máquinas de Porce 3, donde se diferencian cuatro familias a partir de la agrupación automática usando el programa DiscontClust, en el fondo un diagrama de concentraciones logrado con el programa BuzyPlus.

Fuente: El Autor.
Figura 14. Esquema en proyección esférica equiárea comparando las diferencias de dos familias encontradas a partir de la agrupación automática usando el programa DiscontClust y dos familias encontradas de forma heurística manual a partir de un diagrama de concentraciones.
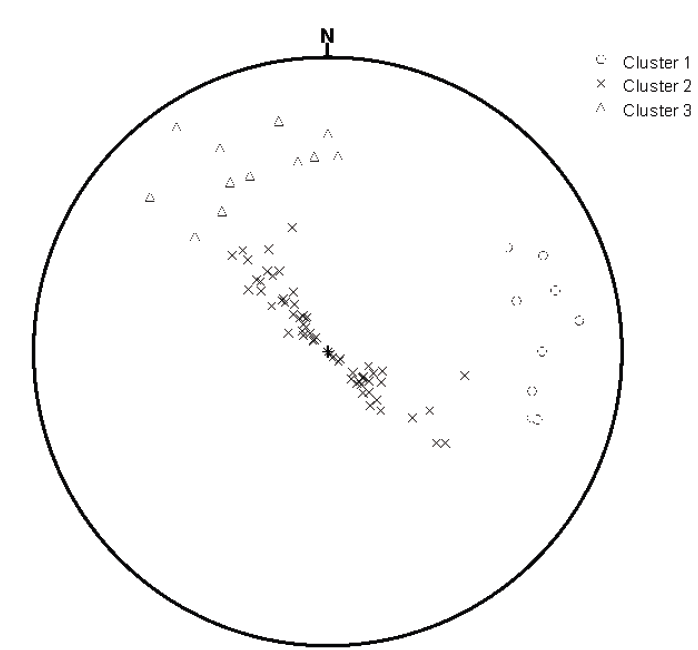
Fuente: El Autor.
Figura 15. Esquema en proyección esférica equiárea de tres familias encontradas a partir de la agrupación automática usando el programa DiscontClust para el Anticlinal Monterralo.
La Fig. 15 muestra que el programa encuentra tres familias de discontinuidades y que son coherentes con el concepto de un anticlinal: la primera familia corresponde al flanco sudeste, la tercera familia corresponde al flanco noroeste y la segunda a la parte central del anticlinal. Esto indica que la selección de familias de forma automática es coherente con el concepto de anticlinal para estos datos; y esa agrupación ayudaría a determinar si algún grupo de discontinuidades forman parte de una estructura más compleja, como fue con el presente ejemplo de un anticlinal.
7. Conclusiones
El algoritmo presentado por Jimenez-Rodriguez and Sitar (2006) [1] para la lograr el agrupamiento automático de datos de orientaciones de discontinuidades es uno entre muchos que logra esta tarea (como se detalla en la sección introductoria de Jimenez-Rodriguez and Sitar, 2006); sin embargo, la implementación de este algoritmo (que se ha hecho en este trabajo en el programa Octave) hace que el código sea robusto y corto, aumentando la eficiencia en la operación que desempeña.
Un proceso de agrupamiento de orientaciones de discontinuidades es más creíble y más susceptible a replicar si aquella elección se basa en un algoritmo más que aquel agrupamiento logrado por criterios heurísticos que dependen la experiencia de la persona que analiza y de los resultados de un diagrama de densidades de polos.
El agrupamiento automático acelera el proceso de interpretación de discontinuidades en macizos rocosos si este se implementa en un código de libre uso que puede incluso hacerse correr en la nube.
El algoritmo presentado aquí convertido en un código en el programa Octave y distribuido de forma libre se puede estudiar, entender, modificar y mejorar por medio del usuario, y además se puede implementar con otros desarrollos de cálculo donde esta operación sea necesaria. Además que se puede traducir a otros lenguajes computacionales a través de la interpretación del código abierto.
8. Descarga del programa
El código del programa DiscontClust está alojado en el sitio anfitrión de proyectos informáticos GitHub, él se descarga del siguiente enlace:
https://github.com/losuarezburgoa/discontClust
A través de este sitio se hace las respectivas descargas, aportes y peticiones de participación en el proyecto. Copyright© 2019 en adelante, Universidad Nacional de Colombia y Ludger O. Suárez Burgoa. Este código abierto es software libre: usted puede re-distribuirlo y/o modificarlo bajo los términos de la Licencia BSD-2 o superior vigente http://opensource.org/licenses/bsd-license.php.
El autor se descarga de toda responsabilidad del uso del presente código computacional. Este código se distribuye con la esperanza de que sea útil, pero sin ninguna garantía; sin la garantía implícita en su comercialización o idoneidad para un propósito particular.

