










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkEnsayos sobre POLÍTICA ECONÓMICA
Print version ISSN 0120-4483
Ens. polit. econ. vol.27 no.59 Bogotá Jan./Dec. 2009
On the Consumer Behavior in Urban Colombia: The Case of Bogotá
Sobre el comportamiento del consumidor en la zona urbana colombiana:
el caso de Bogotá
Sobre o comportamento do consumidor na zona urbana colombiana:
o caso de Bogotá
Jorge Barrientos Marín*
*This paper was presented at the Income and Consumption Session in the Latino American Caribbean and Economic Association Meeting (LACEA-LAMES). Bogotá, Colombia, 2007.
I am solely responsible for the interpretation and any mistake. Dept. of Economics. University of Antioquia.
E-mail: jbarr@economicas.udea.edu.co
Document received: 1 October 2009; final version accepted: 31 Janury 2009.
In this paper we are interested in estimating semi-parametric Engel curves for different categories of goods using data drawn from the 1997 Family Expenditure Survey (ECV1997). Most of the papers about consumer behavior include food and clothing shares in the analysis. Since people in developing countries spend a great deal of time going to work, through their use of public transportation, then it is interesting to take this into account in this study. Due to joint determination of expenditure shares and total expenditure, we adjust for any possible endogeneity, which is a familiar problem in demand analysis. So, not only estimation but also adaptive testing is provided by non-parametric procedures. Our estimations produce quadratic food and transportation Engel curves, which is an interesting result.
JEL classification: C14, D12, D1.
Keywords: Engel curve, expenditure share, semiparametric model, endogeneity, instrumental variable, bootstrap.
Este artículo estima las curvas de Engel semiparamétricamente para alimentación, ropa y transporte público, usando la ECV-DANE de 1997. La mayoría de los artículos sobre el tema excluyen el transporte, lo que constituye una de nuestras motivaciones, pues en países con bajos ingresos como Colombia la mayoría de las personas se movilizan utilizando el transporte público, en especial para ir a sus trabajos. Es probable que enfrentemos problemas de endogeneidad al estar conjuntamente determinados el gasto total y el gasto en los diferentes bienes. Adicionalmente, llevamos a cabo contrastes no paramétricos. Nuestras estimaciones produjeron en algunos casos curvas de Engel casi cuadráticas para alimentos y transporte, lo cual es un indicativo de que los alimentos pueden ser un lujo para algunos y el transporte, un bien inferior.
Clasificación JEL: C14, D12, D1.
Palabras clave: curva de Engel, gasto en bienes, modelos semiparamétricos, endogeneidad, variables instrumentales, remuestreo.
Neste artigo eu estou interessado em estimar as curvas Engel semi-paramétrico para alimentação, roupa e transporte público, usando a ECV-DANE (1997). A maior parte dos artigos sobre o tema não inclui o transporte, o que é uma motivação, pois em países de baixo rendimento como a Colômbia, o transporte público é o meio que usa a maioria das pessoas para se mobilizar, em especial para ir ao trabalho. É provável que enfrentemos problemas de processos endógenos ao estar conjuntamente determinados ao gasto total e ao gasto nos diferentes bens. Além disso, realizamos contrastes não-paramétricos. Nossas estimativas produzem em alguns casos curvas de Engel quase quadráticas para alimentos e transporte, indicando que os alimentos podem ser para alguns um luxo e o transporte um bem inferior.
Classificação JEL: C14, D12, D1.
Palavras chave: curva de Engel, gasto em bens, modelos semi-paramétricos, endogeneidade, variáveis instrumentais, mostra.
I. Introduction
Empirical economics analysis of Engel curves has been an important topic for almost 50 years, since the early studies of Working (1943), Leser (1963), Deaton and Muellbauer (1980a, 1980b), in which they have developed parametric structures for investigating demand and Engel functions. From semi- and non-parametric points of view, Banks, Blundell and Lewel (1997), Blundell, Duncan and Pendakur (1998), Blundell, Browning and Crawford (2003) and Lyssouto, Pashardes and Stengos. (2002) have developed non-parametric and semi-parametric approaches to investigate consumer behavior in the United Kingdom.
In this study we are interested in estimating the relationship between total expenditure and budget shares using data drawn from the 1997 Family Expenditure Survey1. Additionally, we estimate the conditional mean of share expenditures by controlling the regression model by family characteristics such as gender, age, schooling (of household head) and the social stratum. It is worth remarking that the Engel curve analysis allows us to carry out welfare analysis. Moreover, Engel curve play an important role in models of income distribution and poverty.
Most of the papers concerned with consumer behavior have in common three broad categories of goods: food, drink/tobacco and clothing shares. In this paper we have included public transportation share instead of drink/tobacco share. However, most papers do not make special reference to public transportation. We introduce transportation because people, especially in developing countries, are transported by local public service. We mean, each day there are many people (especially workers) who travel throughout the city of Bogotá to work, usually from the south to the north of the city.
It is well known that food share is very important in consumer behavior analysis because access to food (nutritional component, calories etc) is considered an important measure of social welfare; so it is important to know what the pattern of food consumption is in the urban zone in a low-income country. Bogotá is a city in which there are many differences (among households); additionally Bogota attracts people from different regions of the country with different preferences and tastes. Clothing share is also included in this study in order to compare the food Engel curve with the clothing Engel curve. We are motivated to compare both curves because we think that food is a basic good while clothing is a necessity but not a basic good. Some co-variates, which usually have a linear effect such as age, gender, size and stratum (households are classified, by the local government, according to some characteristics especially those referred to as the quality of house building) are introduced parametrically. We make note that our estimations produce quadratic food and transportation Engel curves, which is a key feature because the current empirical evidence displays linearity of food Engel curve for poorest people in richer countries.
It should be remarked that a problem we may well have to consider is the endogeneity of regressors. Note that in this context total expenditure may well be jointly determined with expenditure shares. The approach used to solve this problem is instrumental variable estimation. We remark on two recently developed procedures in the context of semi- and non-parametric regression to tackle the problem of endogenous regressors: the so-called non-parametric two step least square (NP2SLS) according to Newey and Powell (2003), and the non-parametric two steps with generated regressors and constructed variables (NP2SCV) according to Sperlich (2005). Newey’s approach is a cumbersome procedure involving the choice of a basis expansion at the first step. However, Sperlich’s approach only requires a non-, semi- or even parametric construction of regressors of interest in the first step. An empirical paper where this approach is applied can be found in Barrientos (2006).
We don’t examine the share-total expenditure relationship when the household survey data contains a fraction of reported zero expenditure shares. There are many explanations for observed zero expenditure. Firstly, it can result from false reporting by the respondent or the enumerator. Secondly, it is possible to have so low frequency of purchase that at the moment of the survey no purchase is recorded for some households. Finally, it could be possible that some households do not actually purchase the good during the period required by the survey. In general, the source of the zero expenditure shares is unobservable. We need other robust methods (different to non-parametric ones) to get robust Engel curves. Consequently, we get rid of zero expenditure observations.
The contribution of this study can be summarized as follows. Firstly, we investigate consumer behavior (through Engel curves) by estimating a system of partial linear models (PLM). We include in our regressions some demographic characteristics concerning the household head. Secondly, to adjust our estimations for endogeneity we use Sperlich’s approach by estimating a non-parametric model; family income and other exogenous covariates are our main instrumental variables set. In the context of Engel curve it is a common practice to correct endogeneity by instrumenting total expenditure with family income. Finally, we consider testing both linearity and quadratic effects of the estimated non-parametric function (in PLM) by performing adaptive testing hypothesis.
Papers related to this one are Banks et al. (1997), Blundell et al. (1998), Blundell et al. (2003), Lyssiotou et al. (2002), Barrientos (2006) and references therein. Concerning the Colombian case, it is worth noting that there are not many papers about consumer behavior. Nevertheless, Lasso (2003), among others, tries to get non-parametric estimation of Engel curve. However, we found some problems in their estimations. Firstly, they do not adjust estimated models for endogeneity. Secondly, any non-parametric estimation should be accompanied with non-parametric testing of non-linearity or quadratic specification.
The layout of this paper is as follows. Section II makes a short introduction to the literature about estimation of Engel curves. In Section III we introduce the methodology for estimating the underlying (system of) conditional mean. In Section IV we present the data and results about estimating Engel curves. And finally, we conclude.
II. The Shape of Engel Curves
An usual structure in consumer behavior analysis is the so-called Working-Leser specification. In this model each expenditure share is defined over the logarithm of total expenditure. Thus the model has a simple structure given by:
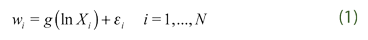
where wi is the budget share, ln Xi is the log total expenditure and εi is an error term satisfying 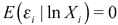 . Empirical analysis using parametric specification as in (1) can be found in the literature on consumer behavior, see for instance Deaton and Muellbauer (1980a, 1980b) and references therein. Note that this model has a one-dimension estructure. In this paper, we make an extension of model (1) given by
. Empirical analysis using parametric specification as in (1) can be found in the literature on consumer behavior, see for instance Deaton and Muellbauer (1980a, 1980b) and references therein. Note that this model has a one-dimension estructure. In this paper, we make an extension of model (1) given by
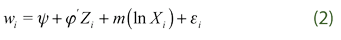
where wi denotes expenditure share, m(ln Xi ) is an unknown function of the total expenditure, Zi is a matrix of household backgrounds (age, schooling, gender), including some demographic variables like household size and household stratum. The term εi is supposed to satisfy the standard assumption 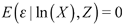 . Most of the papers about consumer behavior using fully-parametric approaches, usually include
. Most of the papers about consumer behavior using fully-parametric approaches, usually include 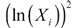 to capture possible non-linearities in the Engel curve. Note that in this paper, such hypothesis is not needed, because, by definition m(.) could have any functional form; moreover, leaving m(.) unrestricted permits a commodity that is initially a luxury to become a necessity at higher income levels.
to capture possible non-linearities in the Engel curve. Note that in this paper, such hypothesis is not needed, because, by definition m(.) could have any functional form; moreover, leaving m(.) unrestricted permits a commodity that is initially a luxury to become a necessity at higher income levels.
As we remarked in the introduction of this work, family income is used to adjust our Engel curves for endogeneity, which is caused by the joint determination of the total expenditures and the expenditure share. Additionally, we use as instruments some exogenous variables contained in the matrix Z. For this purpose we used the non-parametric method developed by Sperlich (2005), which gets rid any assumption about the range of matrix of instruments. Moreover, Sperlich’s approach could be performed by using a single instrument.
III. Estimating and Testing
A. Partially Linear Model and Instrumental Variables
In order to get an appropriate approach to Engel curves, we estimate the PLM given in (2), which is motivated because they allow us to include other regressors that typically show linear effects (dummies or any categorical covariate). At the same time we consider reducing the curse of dimensionality, which may be the main weakness of non-parametric technique, by estimating this semi-parametric PLM. To get a √n-consistent estimator of ø we use Robinson’s approach (1998). So let Φ be an estimator of ø, then (2) can be rewritten as:
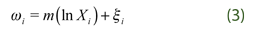
where 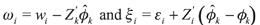 is the new composite error term for all i and k. The intercept Ψ term can be √n-consistently estimated by
is the new composite error term for all i and k. The intercept Ψ term can be √n-consistently estimated by 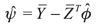 where
where 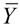 are
are 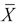 the sample mean. Then (3) can be estimated consistently using standard kernel regression estimator developed independently from each other by Nadaraya (1964) and Watson (1964).
the sample mean. Then (3) can be estimated consistently using standard kernel regression estimator developed independently from each other by Nadaraya (1964) and Watson (1964).
Now we turn to the problem mentioned in the Introduction about constructing regressors to overcome the endogeneity problem. A detailed explanation can be found in Sperlich (2005). Let xi be an unobservable or endogenous variable and let X'i be a generated regressor2, it is then possible to write 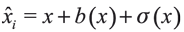 , where b(.) is the bias term such that b(.) » 0 as n » ∞ and σ (.) is the variance term. In order to obtain consistent estimates of the conditional mean and thus construct xi, with the help of instruments or even with help from different data sets it is possible to estimate the reduced regression form, semi-, non- or even parametrically (first step) and then use it in the structural regression (second step), instead of the original regressor. The procedure can be described as follows: let {Wi} be the set of exogenous variables. We carry out the estimation of Engel curves by constructing total expenditure using all exogenous variables as instruments in the non-parametric (multidimensional) regression of xi on Wi , so at the first step we get an estimator of x given by x' =g' (W) and after, in a second step, we use x' to estimate our PLM.
, where b(.) is the bias term such that b(.) » 0 as n » ∞ and σ (.) is the variance term. In order to obtain consistent estimates of the conditional mean and thus construct xi, with the help of instruments or even with help from different data sets it is possible to estimate the reduced regression form, semi-, non- or even parametrically (first step) and then use it in the structural regression (second step), instead of the original regressor. The procedure can be described as follows: let {Wi} be the set of exogenous variables. We carry out the estimation of Engel curves by constructing total expenditure using all exogenous variables as instruments in the non-parametric (multidimensional) regression of xi on Wi , so at the first step we get an estimator of x given by x' =g' (W) and after, in a second step, we use x' to estimate our PLM.
As we mentioned above we use family income as instrument, and additionally we include as instruments age and schooling of household head. Note that we are worried about endogeneity due to joint determination of total expenditure, lnX1, and expenditure share (endogeneity due to simultaneity). Suppose that lnX1 is endogenous such that:
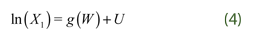
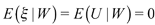 , but
, but 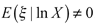 Putting (3) and (4) together we get
Putting (3) and (4) together we get
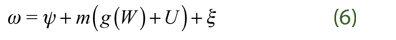
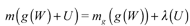 , which somehow means that we assume additivity in the exogenous impact of the explanatory variables, which is possible as an assumption. So, we get:
, which somehow means that we assume additivity in the exogenous impact of the explanatory variables, which is possible as an assumption. So, we get: 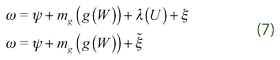
where 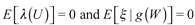 . Then, the expression (2) is the model that we estimate only with the additional burden of a consistent estimation of such function g(.).
. Then, the expression (2) is the model that we estimate only with the additional burden of a consistent estimation of such function g(.).
B. Testing Parametric v.s. Non-parametric Effects
We are interested in testing hypothesis of linearity or quadratic effect, which depends on the form of estimated regression function in model (2). So we establish the null hypothesis as follows: H0:m(x)=mγ(x) for some γ, withm mγ=(x) γxl, where l = 1 and l = 2 denotes linear and quadratic relationship between total expenditure and budget share.
Testing hypothesis can be performed by modifying the Hardle, Huet, Mammen and Sperlich (2004)’s procedure. To this end we use three test statistics. The first one is defined as the square of the differences between the partially linear model and the fully-parametric estimator, extending the concept introduced by Hardle and Mammen (1993). In order to test the validity of our hypothesis, we also consider the test statistics introduced by Gozalo and Linton (2001) and Rodriguez-Poo, Sperlich and Vieu (2005) given by:
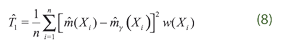
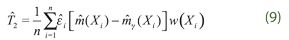
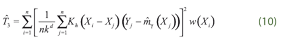
where 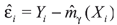 are the residuals of the model under the null hypothesis. Now we discuss the performed procedure to compute the critical values. Note that our idea is based on a combination of adaptive test statistics with bootstrap scheme (Horowitz and Spokoiny (2001)). Having estimated semi-parametric and non-parametric models
are the residuals of the model under the null hypothesis. Now we discuss the performed procedure to compute the critical values. Note that our idea is based on a combination of adaptive test statistics with bootstrap scheme (Horowitz and Spokoiny (2001)). Having estimated semi-parametric and non-parametric models 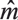 γ and and (.) respectively, we construct the original test statistics denoted by
γ and and (.) respectively, we construct the original test statistics denoted by  jk. As the distribution of varies jkwith k we define the standard test statistic denoted by
jk. As the distribution of varies jkwith k we define the standard test statistic denoted by

where 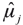 and
and 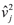 are the estimated mean and variance of the test jk for j = 1,2,3,. Then we compute the test statistics based on the resampling data (boootstrap), denoted by:
are the estimated mean and variance of the test jk for j = 1,2,3,. Then we compute the test statistics based on the resampling data (boootstrap), denoted by:
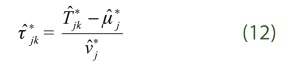
This procedure creates a family of test statistics 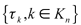 where the choice of k makes the difference between the null and global alternative hypotheses. In order to maximize power we take the maximum of
where the choice of k makes the difference between the null and global alternative hypotheses. In order to maximize power we take the maximum of 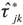 over a finite set of bandwidth values Kn with cardinality L. Then we define the final test statistics by:
over a finite set of bandwidth values Kn with cardinality L. Then we define the final test statistics by:

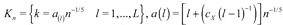 , and
, and 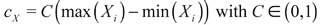 . The testing procedure rejects H0 if at least one of the k ε k ncauses original test statistic to be significantly larger than the bootstrap analogues. In Horowitz and Spokoiny (2001) the estimators for variance and bias are asked to be consistent under alternative hypotheses. Note that this is only necessary for efficiency; for consistency of the test, it is sufficient for the difference between real variance and estimate to be bounded.
. The testing procedure rejects H0 if at least one of the k ε k ncauses original test statistic to be significantly larger than the bootstrap analogues. In Horowitz and Spokoiny (2001) the estimators for variance and bias are asked to be consistent under alternative hypotheses. Note that this is only necessary for efficiency; for consistency of the test, it is sufficient for the difference between real variance and estimate to be bounded. In summary, to obtain bootstrap critical values we consider the following steps. 1) Estimate 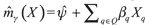 . 2) Use the bootstrap scheme to get εi* for each i = 1, ..., n. 3) For each i = 1, ..., n generate
. 2) Use the bootstrap scheme to get εi* for each i = 1, ..., n. 3) For each i = 1, ..., n generate 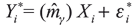 , where εi* is sampled randomly and we use the data
, where εi* is sampled randomly and we use the data 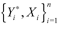 to estimate γ(x) under H0. 4) Repeat the process 1-3 B times to obtain and use these B values to construct the empirical bootstrap distribution. The bootstrap errors εi* are generated by multiplying the original estimated residuals from the model under null hypothesis,
to estimate γ(x) under H0. 4) Repeat the process 1-3 B times to obtain and use these B values to construct the empirical bootstrap distribution. The bootstrap errors εi* are generated by multiplying the original estimated residuals from the model under null hypothesis, 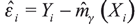 , by a random variable with standard distribution. This procedure provides exactly the same first and second moments for ε'i* and for εi*.
, by a random variable with standard distribution. This procedure provides exactly the same first and second moments for ε'i* and for εi*.
IV. Data Used in this Application and Results
In this study we consider three broad categories of goods: food, clothing and public transportation shares. We use data from Bogota D.C. Total income, total expenditure and expenditure shares are measured in pesos (yearly) at constant 1997 prices. Our ECV1997 sample contains households in which the household head was working at the moment of the survey. For clothing and transport shares there are expenditures reported at zero, the fraction of which is 12% and 10%, respectively. If we get rid of zeros, these restrictions leave us with a sample of 610 observations. Each Graph presents the estimated curve together with 95% bootstrap pointwise confidence bands (dashed lines).
In the estimation of our regression functions, normal bootstrap errors are used to generate bootstrap sample for computing confidence bands, as well as for computing critical values to test linear and quadratic null hypotheses. Bandwiths for bootstrapping are obtained by adaptive methods. This parameter is different to that to get the estimation of non-parametric curve which is obtained by the leave-one-out cross-validation method to automatic bandwidth choice. In all cases we present kernel regression for the quartic kernel 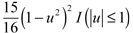 where I (.) is the indicator function. Table 1 gives us some descriptive statistics for expenditure data. According to this one, we have that in this sample, on average, a typical home consists of a male (household head) in his forties (45.3) who has 9.52 years of education and 4 members per home, all of them residing mainly in strata 3 and 4. Graphs 1-3 and Table 2 comprise results about Partial Linear Model.
where I (.) is the indicator function. Table 1 gives us some descriptive statistics for expenditure data. According to this one, we have that in this sample, on average, a typical home consists of a male (household head) in his forties (45.3) who has 9.52 years of education and 4 members per home, all of them residing mainly in strata 3 and 4. Graphs 1-3 and Table 2 comprise results about Partial Linear Model.
Graph 1 displays the semi-parametric estimations of the food Engel curve. The vertical axis refers to the budget share adjusted by family background. Partially consistent with Engels’ law, the curve slopes downwards for higher expenditure levels. Food is a broad aggregate of 21 commodities which, on average, consumes 24.3% of the household budget in Bogotá. Table 3 presents parametric OLS estimates of the Engel curve which show that the quadratic in log expenditure is highly significant. According to Gorman (1981) a quadratic Engel curve implies a demand system of rank three, so Almost Ideal Demand System of Deaton and Muellbauer (1980) and any Linear Expenditure System are inappropriate for demand analysis in Bogota, and in general in regions with strong inequalities among the population.
A quadratic food Engel curve is an interesting result. The food Engel curve is usually (almost) linear in the richer populations of Spain (see Delgado and Miles, 1996), the U.K. (Banks et al., 1997) and the USA (Lewbel, 1991), suggesting that the quadratic is a feature of the income levels in our sample ECV1997 and the stage of economic development. In our data, as expenditure rises, food share increases to attain a maximum, but for higher expenditures levels the food share decreases. The shape of this Engel curve suggests that food is a normal good for low-income families in the sample and an inferior one for the others. According to this feature we could think that food basket of the poorest people should be deficient in either quantity or quality.
Graph 2 displays the semi-parametric estimate of the clothing Engel curve. This commodity comprises clothing and footwear (for men, women and children) and, on average, consumes 4.2% of the household budget. Note the (almost) linear effect of total expenditure on clothing share. This behavior is explained because clothing, unlike food or transport, is a necessary good but not a basic one. Though clothing is important and necessary, people have to feed and take the bus or a taxi to get their workplace. The stable behavior of clothing share across households means that people prefer meeting their basic needs.
Graph 3 displays the semi-parametric estimation of the transport Engel curve. This commodity comprises of tickets for buses (urban and rural) and money spent on taxi journeys and, on average, consumes 7.8% of the household budget. It is worth noting that as long as total expenditure is increasing the amount devoted to transport share is decreasing for high level of expenditure. This behavior is typical of households in developing regions where the form of the Engel curve usually implies that public transportation is an inferior good for many people. It is possible that a typical household head, who improves his income, considers buying a car for private transportation.
Age has an interesting effect on consumer behavior. Each estimation produces a significant and negative effect; Table 1 shows us that 76% of household heads in our ECV1997 sample are men: from a sociological point of view men do not care as much about fashion as women; Barrientos (2006b) estimates the non-parametric effect of age on consumer behavior coming to the same conclusion obtained in this investigation: spending in clothing decreases with age, in particular for household heads of 40 and over. Note that non-parametric estimation gives us the possibility of observing the effect of whole age range on expenditure commodities whereas parametric procedures produce an estimated parameter; thus a single effect (linear) can be observed.
Table 2 shows us the semi-parametric effect of total expenditure on budget shares. Note that size has a positive effect in all cases but is significant for food and transport shares. This behavior is clear: more people imply more expenditure share. In general, it seems that from a parametric point of view no variable is important for clothing share. Schooling has different but significant effects. On the one hand, schooling has a positive effect on transportation share; but on the other hand, it has a negative effect on food share. Note that food share does not include meals out of home, so people (household head and maybe other members) are likely to feed out of home if they have increasing income, so schooling affects food share negatively via family income. This result is similar for fully-parametric estimation reported in Table 2. The Engel curves include stratum effects which are small and only marginally significant.
If the model is chosen correctly, these results quantify the extent to which each variable affects consumer behavior. We remark some results about the linear and quadratic effects of total expenditure on budget shares. To perform adaptive testing procedure we define a set of Kn (with cardinality L = 10) of bandwidths k’s to range from 0.24 to 0.87. As we mentioned above, optimal bandwidth to estimate underlying regression function is obtained by cross-validation (these are the same as those used in the estimation). Moreover, it is worth mentioning that bootstrap for testing hypotheses are generated in a different way from the one for generating confidence bands. In practice (we mean in applications) we have to over-smooth for bootstrap tests and under-smooth for confidence bands (Barrientos and Sperlich 2006).
We used 1000 normal bootstrap samples and performed testing procedure according to aforementioned algorithm. Because over-smothing parameter to generate bootstrap sample is crucial to compute critical values, we carried out test hypothesis with different bandwidths, but we did not find significant differences in results. Therefore, we report critical values for a single over-smoothing parameter for each underlying regression gfs = 3.0 for food share, gcs = 2.3 for clothing share and gts = 2.1 for transport share. According to performed testing procedure, for clothing share we are able to reject linearity of log total expenditure at α = 0.1% with t1 and t2; with t3 we reject linear effect of total expenditure on clothing share at α = 6.5%.
On the other hand, we tested quadratic effect for the food and transportation Engel curve. According to the evidence, both transportation and food Engel curve displays imperfect quadratic forms. Of course, linearity is strongly rejected; we are unable to reject quadratic effect, however. Note that neither t2 nor t3 rejects the null hypothesis of quadratic effect of total expenditure on food expenditure (α = 20% and α = 95% respectively). According to the testing procedure, there is no evidence against quadratic effect of total expenditure on public transportation (α = 48% and α = 96% with t2 and t3). These results are coherent with the shape of the estimated curves in Graphs 1-3. This fact gives us an idea about the robustness and reliability of our methods.
V. Conclusions and Future Research
General results obtained from the estimation of Engel curves show that modelling the effects of total expenditure on the different budget shares deserves a better treatment than usually found in one-dimensional semi-parametric analysis. Bhalotra and Cliff (1998) ask if the non-linearity of the Engel curves could reflect specification error. It is a point to be included in the future.
Note that in this paper we only take into account a partial household composition (we only control for size, gender, schooling and strata). Therefore, a reasonable extension of empirical analysis with PLM could be carried out by introducing more demographic variation to obtain variety in behavior (regions, labor market, temporal dummy to capture price effects, etc.). Moreover, we could be interested in allowing Zij vary in any way with j and testing Stlusky symmetry hypothesis, for that it would be necessary to impose a function to get general equivalence scale in order to fulfill conditions of proposition 5 in Blundell et al. (2003).
Another interesting point to investigate is whether changes in consumer preferences take place over time and make an extension to dynamic models. One can take data from the 2003 Family Expenditure Survey, for example, to compare consumer behavior. Additionally, more categories of goods (health, furniture, house, rent, etc) should be included to investigate, for instance, whether health expenditure is a luxury good.
Finally, every paper about non-parametric applications to consumer behavior should report non-parametric elasticities. It is not easy, because this requires estimations of the first derivatives. In the parametric world elasticities often are constant between families, whereas in nonparametric universe, elasticity is a function (involving the first derivative of the Engel curve), so by definition the elasticity would be different among individuals. So future research should include non-parametric elasticities.
Comentarios
1 Family Expenditure Survey, or ECV for its Spanish name, contains information of households collected by Departamento Nacional de Estadística (DANE).
2 Both bias and variance have orders of O(g2) and 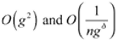 respectively, to fulfil the assumptions of Theorem 2 in Sperlich (2005).
respectively, to fulfil the assumptions of Theorem 2 in Sperlich (2005).
References
1. Bhalotra, S.; Cliff, A. “Intrahousehold Resources Allocation in Rural Pakistan: A Semi-parametric Analysis”, Journal of Applied Econometrics, vol. 13, num. 5, pp. 463-480, 1998. [ Links ]
2. Banks, J.; Blundell, R.; Lewbel, A. “Quadratic Engel Curves and Consumer Demand”, The Review of Economics and Statistics, vol. 79, num. 4, pp. 527-539, 1997. [ Links ]
3. Barrientos Marín, J.; Sperlich, S. The Size Problem of Kernel Based Bootstrap Test When the Null Is Non-parametric, University of Alicante, Social Science Research Network-SSRN: http://ssrn.com/abstract=1010939 Submitted, 2006. [ Links ]
4. Barrientos Marín, J. “Estimation and Testing An Additive Partially Linear Model in a System of Engel Curves”, University of Alicante, IVIE Working Paper, WP-AD 2006-23. [ Links ]
5. Blundell, R.; Duncan, A.; Pendakur, K. “Semi-parametric Estimation and Consumer Demand”, Journal of Applied Econometrics, vol. 13, num. 5, pp. 435-461, 1998. [ Links ]
6. Blundell, R.; Browning, M.; Crawford, I. “Non-parametric Engel Curve and Revelead Preference”, Econometrica, vol. 71, num. 1, pp. 205-240, 2003. [ Links ]
7. Deaton, A.; Muellbauer, J. “An Almost Ideal Demand System”, American Economic Review, vol. 70, pp. 321-326, 1980a. [ Links ]
8. Deaton, A.; Muellbauer, J. Economic and Consumer Behavior, Cambridge, Cambridge University Press, 1980b. [ Links ]
9. Delgado, M. A.; Miles, D. Households Characteristics and Consumption Behavior: A Non-parametric Approach. Empirical Economics, 1996. [ Links ]
10. Gorman, W. M. “Some Engel Curves”. A. Deaton (ed), Essays in the Theory and Measurement of Consumer Behavior in Honor of Sir Richard Stone, Cambridge, Cambridge University Press, pp. 7-29, 1981. [ Links ]
11. Gozalo, P. L.; Linton, O. B. “Testing Additivity in Generalized Non-parametric regression models with Estimated Parameters”, Journal of Econometrics, num. 104, pp. 1-48, 2001. [ Links ]
12. Hardle, W.; Mammen, E. “Comparing Non-parametric Versus Parametric Regression Fits”, Annals of Statistics, vol. 21, num. 4, 1926-1947, 1993. [ Links ]
13. Hardle, W.; Huet, S.; Mammen, E.; Sperlich, S. “Semi-parametric Additive Indices for Binary Response and Generalized Additive Models”, Econometric Theory, num. 20, pp. 265-300, 2004. [ Links ]
14. Härdle, W.; Müller, M.; Sperlich, S.; Werwatz, A. Non-parametric and Semi-parametric Models, Springer Series in Statistics, Springer-Verlag, 2004. [ Links ]
15. Horowitz. J, L.;Spokoiny, V. “An Adaptive, Rate-optimal Test of Parametric Mean-Regression Model Against A Non-parametric Alternative”, Econometrica, vol. 69, num. 3, pp. 599-631, 2001. [ Links ]
16. Lasso, F. “Economías de escala en los hogares y pobreza”, Revista de Economía del Rosario, vol. 6, núm. 1, pp. 23-52, 2003. [ Links ]
17. Lewbel, A. “The Rank of Demand Systems: Theory and Non-parametric Estimations”, Econometrica, num. 59, pp. 711-730, 1991. [ Links ]
18. Leser, C. E. V. “Form of Engel Functions”, Econometrica, vol. 31, num. 4, pp. 694-703, 1963. [ Links ]
19. Nadaraya, E. A. “On Estimating Regression”, Theory Probability Applied, num. 10.l, 1964. [ Links ]
20. Newey, W. K.; Powell, J. “Instrumental Variables Estimation of Non-parametric Models”, Econometrica, num. 71, pp. 1565-1578, 2003. [ Links ]
21. Lyssiotou, P.; Pashardes, P.; Stengos, T. “Age Effects on Consumer Demand: An Additive Partially Linear Regression Model”, The Canadian Journal of Economics, vol. 35, num. 1, pp. 153-165, 2002. [ Links ]
22. Robinson, P. “Root N-Consistent Semiparametric Regression”, Econometrica, vol. 56, pp. 931-54, 1988. [ Links ]
23. Rodriguez-Póo, J. M.; Sperlich, S.;Vieu, P. “An Adaptive Specification Test For Semi-parametric Models”, Working Paper, University of Carlos III de Madrid, 2005. [ Links ]
24. Sperlich, S. A Note on Non-parametric Estimation with Constructed Variables and Generated Regressors, Social Science Research Network-SSRN: http://ssrn.com/abstract=1010923.2005 [ Links ]
25. Watson, G. S. “Smooth Regression Analysis”, Sankhy a Ser. A 26, 1964. [ Links ]
26. Working, H. “Statistical Laws of Family Expenditure”, Journal of the American Statistical Association, vol. 38, pp. 4-56, 1943.
[ Links ]

