



![DOES PREDICATIVE STRUCTURE [VERB + DIRECT OBJECT] HAVE PREDICTIVE CHARACTER? A SYNTACTIC-SEMANTIC CHARACTERIZATION FOR SENTIMENT ANALYSIS PURPOSES](/img/en/prev.gif)







 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introducción
El término «corpus» usado en un contexto lingüístico moderno tiene varias connotaciones en relación con su tamaño, representatividad y formato electrónico. Existe un consenso general sobre las características que debe tener un corpus digital: debe estar formado por textos auténticos en formato electrónico -legible y a máquina- y además, debe incluir ejemplos que representan una lengua o una variedad en particular (McEnery, Xiao, & Tono, 2006). Se define al corpus como una colección de textos o de partes de textos que han sido puestos en formato electrónico y seleccionados de acuerdo a determinados criterios para representar una lengua o una variedad de lengua y que es usado como fuente de datos para investigación lingüística. (Sinclair, 2005), (Crystal, 2008), (McEnery & Hardie, 2011). La lingüística de corpus (LC) es una metodología que permite realizar investigaciones confiables utilizando grandes cantidades de datos. Gracias al avance en el campo de las tecnologías de la información (IT), la LC se rige por pasos y procedimientos definidos para realizar la recopilación de datos y el análisis científico de éstos. Sus procedimientos exploran y describen el lenguaje objetivamente dejando atrás la especulación subjetiva.
Existen diferentes tipos de corpus de acuerdo a sus funciones. Así por ejemplo, en un corpus general se pueden encontrar varios tipos de textos producidos en uno o en diferentes países. También se pueden encontrar los corpus de muestra o monitor, los cuales son diacrónicos y contienen ejemplos de variedad de textos que permiten realizar análisis sobre los cambios y evolución de una lengua. Dentro de los corpus especializados que compilan textos con el fin de realizar descripciones e investigaciones específicas de una lengua, encontramos los corpus de aprendientes. Estos corpus se definen como «colecciones electrónicas de datos naturales o casi naturales producidos por estudiantes extranjeros o de segunda lengua (L2) y reunidos según criterios de diseño explícitos» (Granger, 2002, p. 7), (Gilquin, 2015, p. 1). De acuerdo a Granger, (2002) Los corpus electrónicos de aprendientes deben ser codificados de manera estandarizada, homogénea y documentados de acuerdo a su origen y procedencia. Los datos de los corpus de aprendientes se diferencian de otros corpus en dos aspectos: primero, están totalmente en formato digital, lo cual permite su estudio usando diferentes herramientas lingüísticas de software para obtener un análisis rápido y eficiente y; segundo, la cantidad de datos recopilados es considerable, por lo cual se constituye en una base confiable para describir y ejemplificar la lengua de los aprendientes (Granger, 2003). Estos corpus proveen datos que dan a conocer los mecanismos de adquisición de lenguas, ya sean éstas foráneas o segundas lenguas (p. 5).
Los corpus de aprendientes surgieron al final de la década de 1980 como una forma científica válida para analizar la producción oral o escrita de los estudiantes. Estos corpus tienen las mismas características atribuidas a otros corpus; sin embargo, los datos en este caso se obtienen de la producción oral o escrita de los estudiantes colocada en un formato electrónico o multimodal (audiovisuales) para ser analizada por medio de software especializado. Los corpus de aprendientes son colecciones auténticas de uso del lenguaje contextualizado que contiene muestras de la adquisición de un segundo idioma o de un idioma extranjero.
La lingüística de corpus computacional (LCC) se encarga del diseño de herramientas informáticas para lograr una mejor comprensión del lenguaje y un análisis confiable, eficiente y automático (Bolaños, 2015, p. 31). En Colombia la LCC es relativamente nueva, ya que los estudios lingüísticos se han basado en corpus sin el uso de herramientas de la lingüística computacional. Esta situación se puede evidenciar en los trabajos más recientes basados en corpus, (Londoño, 2008), (Parada, Ruiz, & Sánchez, 2017). Lo anterior es evidencia de la necesidad de ilustrar a los lingüistas investigadores colombianos y de la región sobre la importancia del diseño de corpus computacionales de aprendientes. El presente artículo se configura como un primer paso para llenar este vacío.
2. Marco teórico
En esta sección se describen los criterios y principios en la elaboración de un corpus computacional de aprendientes y se hace un recuento de los últimos estudios con este tipo de corpus en Latinoamérica.
Los corpus electrónicos de aprendientes (CEA) deben cumplir determinados principios de diseño ya que deben ser compilados teniendo en cuenta criterios específicos de la lingüística de corpus, pero además pertenecen a un tipo de corpus específico con datos obtenidos de la producción oral o escrita de los estudiantes de lenguas. La Figura 1 proporciona algunas pautas que se deben tener en cuenta en el diseño de un corpus de aprendientes de acuerdo a Granger (2002).

Al diseñar este tipo de corpus se deben tener en cuenta, además de los aspectos señalados, las variables de los aprendientes (edad, ambiente de aprendizaje, nivel de competencia, género, lengua materna, región, exposición a la segunda lengua) y las variables propias de la tarea o actividad encomendada (medio, campo, género, extensión, tema, herramientas que se pueden usar) (Granger, 2003). Todos estos aspectos conforman la información relevante al compilar un corpus de estudiantes de lengua.
Una de las razones para compilar un corpus es analizar el nivel de interlengua entre los estudiantes mediante el análisis de errores (AE). El AE permite, entre otras: clasificar y analizar los errores, determinar los factores que contribuyen al éxito o fracaso del aprendizaje y metodologías de enseñanza, conocer las causas y origen de los errores, emitir juicios sobre gramática y validez de normas lingüísticas en determinada lengua (Vázquez, 2009). Con el auge de las nuevas tecnologías surge el análisis de errores asistido por computador (del inglés Computer-Aided-Error Analysis - CEA) el cual basa la investigación en corpus electrónicos de aprendientes teniendo en cuenta los procedimientos de la lingüística de corpus (LC) para identificar, clasificar y describir los errores. Los resultados obtenidos por medio del CEA contribuyen con innovación en el procesamiento de los datos que son analizados por medio de software para mejorar las competencias y habilidades lingüísticas y para diseñar materiales más acordes y tareas más significativas en el proceso de aprendizaje de lenguas extranjeras. Los diferentes análisis han permitido desarrollar modelos de tratamiento de errores que buscan profundizar en la identificación y reflexión de los mismos, con el fin de sensibilizar y orientar a los aprendientes hacia la autocorrección y fomentar su investigación (Alexopoulou, 2005). Por otra parte, diferentes autores, (Vázquez, 2009; Alba Quiñones, 2009) proponen taxonomías de errores y pruebas con el fin de identificarlos.
Se puede afirmar entonces que los corpus de aprendientes se recopilan cumpliendo determinados criterios y que uno de los fines de su existencia es realizar análisis de errores. Una vez que el corpus ha sido compilado siguiendo los principios de la lingüística de corpus y conforme a los corpus de aprendientes, el siguiente paso es iniciar la anotación del corpus.
2.1. Sistema de anotación
Los corpus de aprendientes, como cualquier otro tipo de corpus, comienzan como textos en bruto de versiones escritas en formato electrónico o textos transcritos de la producción oral de los estudiantes. Un corpus de aprendientes es más productivo cuando ha sido anotado porque adquiere un valor agregado. La anotación es la práctica de agregar información interpretativa y lingüística a un corpus electrónico de datos del lenguaje hablado o escrito (Leech, 2005, p. 25). La información agregada viene en forma de etiquetas, que son entidades individuales agregadas a una parte o partes del discurso. Las etiquetas son únicas y pueden identificar características del corpus analizado. Existen diversos tipos de esquemas de anotación y requieren diferentes etiquetas según el objetivo del investigador; por ejemplo, la lingüística descriptiva utiliza etiquetas para identificar partes del habla para así obtener una anotación gramatical en un corpus. Otro ejemplo es la anotación semántica, que requiere asignar un campo semántico a una palabra y se usa para refinar búsquedas y clasificaciones de acuerdo con el propósito de la investigación. Un corpus de aprendientes también puede tener anotaciones de errores para clasificarlos y analizarlos. El corpus recopilado durante la presente investigación fue etiquetado de acuerdo a ocho categorías de errores que en total suman 56 tipos de errores de acuerdo al Manual de Etiquetado de Errores de la Universidad de Lovaina (Dagneaux et al., 2005). Todas las categorías y etiquetas de error pueden observarse en el Anexo 1 del presente artículo.
2.2. Alineación del corpus
En el caso particular de un corpus de errores, la alineación se refiere a la identificación de patrones de error identificados mediante las etiquetas de error. Para realizar este procedimiento se utiliza un software especializado que agrupa en listas los tipos de errores.
2.3. Estadística de los errores en un corpus de aprendientes
Este paso se refiere a la obtención de estadísticas de los patrones de error o de los patrones lingüísticos buscados objeto de la investigación. En el caso del presente corpus, se obtuvieron las estadísticas de los errores por categoría y por tipo.
2.4. Estado de la lingüística de corpus computacional en Colombia y en Latinoamérica
A pesar de que la lingüística de corpus computacional ha tenido su auge desde los años 80 en Colombia, apenas se empieza a considerar para la realización de análisis lingüísticos. La lingüística de corpus computacional se ha venido posicionando en países como México donde se han realizado trabajos con corpus computacionales de aprendientes (López, 2008). En su mayoría los trabajos reportados por AELINCO Research in Corpus Linguistics se refieren a investigaciones con corpus de aprendientes recolectados en Europa, (Hernandez, 2013; Szabó, 2013; Crespo, 2016) entre otros. Desde hace varios años Chile se configura como el país que más ha aprovechado este método de compilación siendo el más prolífico en este tipo de investigaciones a nivel latinoamericano. Esto se puede ver en el auge de trabajos relacionados con la lengua materna y en la enseñanza del inglés como lengua extranjera (ILE): (Garrido, 2012; Cabrera, Elejalde, & Vine, 2014; Ortega, 2014; Saavedra & Campos, 2018) entre otros. Colombia es un país con mucho potencial para el uso de corpus computacionales de aprendientes por la necesidad de analizar grandes cantidades de datos provenientes de la interlengua de los estudiantes. Al revisar algunos de las últimos trabajos con corpus de aprendientes en Colombia no se encuentran corpus computacionales (Vásquez, 2008; Parada et al., 2017) lo cual dificulta llevar a cabo análisis comparativos y contribuye al estancamiento en esta área, de ahí la importancia del presente análisis.
Es necesario, pues, que la lingüística de corpus computacional se posicione en Colombia para que a futuro se puedan hacer análisis a gran escala usando herramientas de software que garanticen la confiabilidad en el análisis de grandes cantidades de datos. El presente trabajo busca abrir las puertas a este fascinante mundo de la lingüística computacional.
3. Metodología: Análisis de errores y lingüística de corpus
El problema de investigación que se propone abordar el presente estudio es el vacío que existe en Colombia y en gran parte de Latinoamérica sobre literatura referente a la construcción de corpus computacionales.
La presente investigación se sustenta en la metodología de la lingüística de corpus computacional en la compilación del corpus de aprendientes en formato electrónico, (Granger, 2002; Granger, 2003; Gilquin, 2015).
A continuación, se describirán los pasos seguidos para construir un corpus computarizado de estudiantes de inglés como idioma extranjero a nivel universitario.
3.1. Recolección del corpus
El corpus de textos lo conforman 515 textos escritos: 112 son ensayos de comparación y contraste y 403 son párrafos de opinión. Las siguientes son las etapas seguidas en la recolección y alistamiento del corpus de aprendientes:
-Aplicación de encuesta y registro de participación: Este instrumento estaba conformado por 27 preguntas divididas en tres secciones: perfil del estudiante, perfil académico y aspectos socioculturales. Se buscaba determinar datos tales como la edad, el estrato socio-económico, la lengua materna, el manejo de otras lenguas etc.
-Compilación del corpus: El corpus de la presente investigación se compiló en la Universidad del Norte, en Barranquilla, (Colombia) durante el segundo semestre del año 2015. En total, 2 088 estudiantes universitarios de pregrado en diferentes carreras estaban inscritos en los cursos de inglés como lengua extranjera en los niveles B1.1 a B2.3, de acuerdo a la clasificación del Marco Común Europeo de Referencia - MCER. De esa población, 515 estudiantes firmaron un formulario de consentimiento para participar en esta investigación.
Por medio de instrumentos con preguntas sobre diferentes temas de la vida cotidiana se recopilaron 403 párrafos de opinión y 112 ensayos de comparación y contraste. Los estudiantes iniciaron el proceso de escritura desarrollado durante varias clases, en las que recibían comentarios y sugerencias de cada docente. Los trabajos recolectados para el presente análisis corresponden al ejercicio final de escritura con tiempo limitado. El análisis se centró en los niveles B1.1 a B2.3 de acuerdo al MCER (Council of Europe, 2001). La duración del curso fue de un semestre (16 semanas) para un total de 64 horas de exposición a la lengua con una intensidad de cuatro horas de clase semanales. Todos los cursos se desarrollaron como seminarios con un producto por clase que era evaluado, corregido y recibía comentarios. Desde los niveles B1.1 a B1.3, los estudiantes entregaron tanto sus borradores como el trabajo final escritos a mano, pues los laboratorios de informática se reservan para los estudiantes avanzados que tienen mayor producción escrita. Desde el nivel B2.1 hasta el B2.3, los borradores y el trabajo final se entregaron en archivo electrónico. En total, el corpus compilado de estos estudiantes tenía 149 325 tokens, 12 164 tipos y 12 337 lemas. En la Tabla 1 se presenta la distribución de los alumnos según los niveles del MCER.

En cada nivel, desde B1.1 hasta B2.3, los estudiantes recibieron una lista de posibles temas para escribir sus composiciones. Este grupo de estudiantes no tuvo acceso a dispositivos electrónicos. Los estudiantes del nivel B2.1 hasta el B2.3 realizaron un ensayo de comparación y contraste. En este caso, los estudiantes tuvieron acceso a diccionarios en línea y a fuentes secundarias a través de las bases de datos de la plataforma de la universidad o a través de documentos sugeridos o proporcionados por sus maestros durante el semestre. Se considera que al ser los ensayos un tipo de texto crítico es relativamente difícil cortar y pegar información a sus textos sin quedar en evidencia en los programas detectores de plagio usados en la institución. En todos los casos, los estudiantes tuvieron un tiempo limitado de una clase de dos horas para realizar la tarea final recopilada para la presente investigación.
-Técnicas de estimulación usadas para generar producción escrita de los estudiantes: Estas técnicas buscan generar un tipo de respuesta abierta en la que se puede establecer el estado de la interlengua de los estudiantes (Corder, 1981, p. 61). Los textos son el resultado de una serie de actividades que guían al estudiante a generar una respuesta escrita. Tanto en los párrafos de opinión como en los ensayos los estudiantes recibían posibles temas para desarrollar. En la Figura 2 se esbozan los pasos realizados en el proceso de escritura de los párrafos, el cual fue similar aunque con un resultado esperado diferente en el caso de los ensayos.

Luego de la compilación de los textos, los archivos fueron sometidos a procesos diferentes porque estaban en formatos diferentes. Por ejemplo, en los niveles B1.1 a B2.1 el trabajo final de los estudiantes fue escrito a mano, el proceso comenzó con el escaneo de los textos seguido de su transcripción. Después de transcribir todos los textos, asegurándose de que no se hicieron adiciones o eliminación de palabras, los archivos se verificaron dos veces para asegurar que eran exactamente como el original. A continuación, se convirtieron a formato txt para llevar a cabo la anotación de los errores. Los estudiantes de los niveles B2.2 a B2.3 hicieron la versión digital directamente, por lo tanto, esos textos se convirtieron inmediatamente en el mismo formato que los anteriores para el etiquetador de errores. Un total de 403 textos escritos a mano fueron compilados y transcritos en archivos de Microsoft Word. Después de la preparación anterior, todos los archivos estaban listos para comenzar con el proceso de etiquetado de errores. La Figura 3 muestra un ejemplo de un archivo escrito a mano que se transcribió a un archivo de Microsoft Word.

-Etiquetado del corpus: El etiquetado del corpus hace parte de la descripción de los errores. Es la primera etapa en la que se reconoce su existencia. La identificación y clasificación de los errores se hizo de acuerdo al Manual de Etiquetado de Errores versión 1.2 (Error Tagging Manual versión 1.2) de la Universidad de Lovaina (Dagneaux et al., 2005). El etiquetador, además de describir el nivel lingüístico y el tipo de errores, presenta una explicación de los posibles procesos que subyacen a las etapas de la interlengua. El manual de etiquetado distingue entre ocho categorías y casi cada categoría se divide en subcategorías para un total de 56 etiquetas de error. En cada caso, la primera letra de la etiqueta muestra la categoría de error. La Figura 4 presenta las categorías de error utilizadas en el presente estudio. Cada categoría de error representó varios tipos de error.

Cada anotación se hizo siguiendo las ocho categorías de la versión 1.2 del etiquetador referenciado anteriormente (Dagneaux et al., 2005). Este etiquetador es el sistema más apropiado porque se especializa en la anotación de errores de corpus de aprendientes de lengua. Las etiquetas incluyen la descripción de los errores más comunes de los estudiantes de inglés como lengua extranjera y cuya lengua materna es el español. Este etiquetador es ampliamente conocido por los analistas de errores, por lo que su uso garantiza que en el futuro se pueden hacer trabajos comparables para tener la validación externa de los datos. La Figura 5 muestra un ejemplo de cómo se hizo la etiquetación de errores. Cuando se detectó un error, la etiqueta se colocó justo antes del error y la corrección sigue el error entre dos signos de dólar: $ corrección $ como lo indica el manual:

Al terminar la etapa de etiquetado de errores en todo el corpus y la doble revisión de su consistencia se procedió con la alineación del corpus.
-Extracción y alineación del corpus por tipo de error: El siguiente paso después de hacer el etiquetado de errores es la extracción y alineación del corpus. Este proceso se realiza por medio de un software de extracción que busca las etiquetas y las agrupa de acuerdo a cada tipo de error. Las etiquetas se extraen dentro de un contexto que permite un análisis adecuado. La alineación del corpus se hizo por medio del software Word Smith (Scott, 2008) y LancsBox (Brezina, McEnery, & Wattam, 2015) que permiten la identificación de patrones de lengua y la obtención de estadísticas de los datos con sus respectivas gráficas. A continuación, se puede apreciar en las figuras 6, 7 y 8 la incurrencia en tres diferentes tipos de errores en sus respectivos contextos.
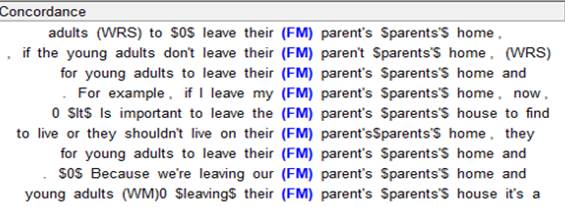
La Figura 6 muestra al error FM (Forma, Morfología) en nueve ocurrencias diferentes y con sus respectivos contextos. En este caso se detectan los errores en el morfema genitivo sajón.
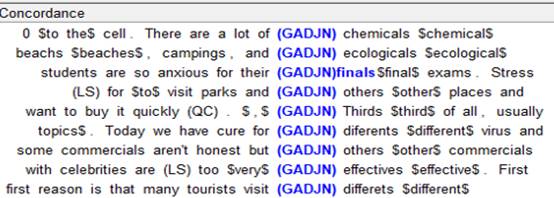
La figura anterior ejemplifica el error GADJN en nueve ocasiones. El error consiste en usar morfemas plurales con el adjetivo.
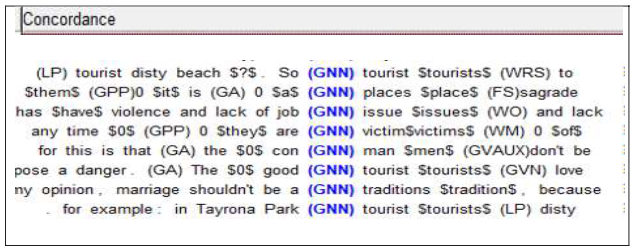
En el anterior caso, se ejemplifica el error GNN que se refiere a errores en la adición u omisión del morfema plural. Igual que en los casos anteriores la etiqueta de error tiene un contexto que facilita el entendimiento y el análisis de cada caso. Se evidencia en las Figuras 6, 7, y 8 que el software de extracción permite la alineación de los errores con un contexto que permite hacer un análisis más acertado de las posibles causas de error si así se desea. Si el investigador desea ver más contexto mientras hace el análisis, simplemente con un clic se puede visualizar el párrafo total y así se logra hacer un análisis más acertado. Esta alineación también permite obtener las estadísticas exactas del número de errores por categoría y por tipo de error. Todos los pasos y procesos descritos en la recopilación de datos siguiendo la metodología de corpus lingüístico y la metodología de análisis de errores en su descripción constituyeron las etapas para el desarrollo de este corpus de aprendientes.
4. Conclusiones
A partir de los resultados obtenidos, puede reafirmarse que la relevancia del análisis de la interlengua de estudiantes colombianos radica en la necesidad de teorizar con el fin de mejorar las prácticas de enseñanza y aprendizaje del inglés como lengua extranjera. El presente trabajo hace un aporte científico a la lingüística aplicada por medio de la metodología de la lingüística de corpus y el análisis de errores asistido por computador (Computer-Aided-Error Analysis - CEA) lo cual permite obtener resultados confiables.
En el caso del presente estudio, el corpus construido se ofrece como una guía para la construcción de nuevos corpus de aprendientes y sirve como herramienta en el seguimiento de los procesos de aprendizaje de lenguas extranjeras. La elaboración de estos corpus junto con los estudios sobre el análisis de errores ayudan a clarificar las etapas que se llevan a cabo en la adquisición de una lengua y permiten entender cómo se internalizan las reglas gramaticales. Los corpus computacionales de aprendientes pueden ser utilizados para hacer análisis semánticos, lexicográficos, pragmáticos, sociolingüísticos, gramaticales, de registro, de distinción de dialectos, de estilo, de estudios literarios, de análisis del discurso, de lingüística forense, etc.
Por su parte, el etiquetador asegura la consistencia en el etiquetado de errores, lo cual garantiza la confiabilidad en los resultados. El uso de etiquetadores de errores estándar permite la comparación de resultados con investigaciones que utilicen la misma metodología, por lo cual resulta necesario hacer más análisis con métodos estandarizados. Cabe aclarar que el uso de un corpus de aprendientes permite buscar patrones de errores. Sin embargo, cuando no se encuentra un patrón, no significa que los alumnos ya hayan adquirido ese tipo de estructura. Por ende, es necesario realizar un análisis más profundo para sacar este tipo de conclusiones.


