











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Citado por Google
Citado por Google  Similares en
SciELO
Similares en
SciELO  Similares en Google
Similares en Google 
 Permalink
Permalink1. Introducción
1.1. La concordancia: definición y antecedentes en adquisición de ELE
La concordancia se define como una relación entre rasgos sublexicales -pares «valor: atributo»- de los ítems léxicos (O’Grady, 2005). En español dichos rasgos son «persona», «número» y «género», junto a sus valores. Corbett (2006) denominó controlador al ítem léxico que determina la concordancia y objetivo al elemento cuya forma es determinada por aquel. Además, definió al dominio como el entorno sintáctico en el cual ocurre la concordancia. Esta se establece por una covarianza sistemática de rasgos. En este trabajo el controlador será nominal, presente y expresará sus rasgos abiertamente. Por otra parte, los objetivos consistirán en artículos (definidos e indefinidos), adjetivos y pronombres (demostrativos, posesivos, indefinidos); además, concordarán con un solo controlador obligatoriamente. Los dominios relevantes serán el sintagma nominal, el sintagma verbal (predicativo) y la oración subordinada. La concordancia se considerará asimétrica -el género y número de los objetivos dependen del controlador nominal-.
La literatura de adquisición ha arrojado los siguientes resultados en lo que respecta a la producción. Fernández- García (1999) investigó la concordancia de género en el sintagma nominal en siete aprendientes ingleses de nivel intermedio a partir de entrevistas grabadas. En general, hubo menos errores en contextos masculinos. Se detectó, en primer lugar, que el masculino se usó mayormente como default en artículos indefinidos y adjetivos. Además, se verificó más precisión con artículos que con adjetivos. Los sustantivos que marcaban las clases en -o /-a (libro) lograron mayor precisión que los no marcados (flor). También existieron menos errores para aquellos motivados semánticamente en el sexo biológico. Asimismo, los alumnos produjeron menos errores con los sustantivos animados (tío) que con los inanimados (tenedor). Por su parte, Liceras, Díaz y Mongeon (2000) compararon la adquisición de género y número en L1 y L2 en el contexto del sintagma nominal y de elipsis (las faldas negras / las negras) en cuatro niños con (edades entre los 4 y 8 años. Los errores de concordancia de género (el zapatos; el cama) en L1 y L2 tenían porcentajes muy similares, despareciendo eventualmente en L1 y persistiendo en L2. En cuanto al número, los errores en L2 eran siempre menos que los de género y eventualmente desaparecían, como sucede en L1. En otro estudio, Francheschina (2001) siguió a un hablante de inglés que había alcanzado nivel superior. El participante exhibió un alto grado de precisión en la concordancia de artículos, adjetivos, demostrativos y pronombres. Sin embargo, los errores de género eran siempre más que los de número, concentrándose estos últimos en los adjetivos. Asimismo, el sujeto observado extendió más veces el uso del masculino a contextos femeninos que viceversa en adjetivos y artículos. Entretanto, Bruhn de Garabito y White (2002) estudiaron el género en estudiantes de secundaria cuya lengua materna era el francés, divididos en dos grupos según estuvieran terminando el primer o el segundo año de español. Aunque la precisión en general fue alta, esta resultó mejor en los artículos que en los adjetivos. Sumado a esto, se verificaron más errores en el artículo definido que en el indefinido. Dichos errores fueron mayores con controladores de género motivados semánticamente que con aquellos motivados morfológicamente -sugiriendo que los alumnos estaban prestando atención a la morfología-. Nuevamente, hubo más sobreextensiones del masculino a contextos femeninos, es decir, una preferencia de masculino como default. Asimismo, White et al. (2004) investigaron la producción y la comprensión en la concordancia de género y número con estudiantes franceses e ingleses de ELE, divididos a su vez en grupos de nivel inicial, medio y superior. En lo que atañe a la producción, tanto tomando en cuenta bigramas Artículo + Nombre, como trigramas Art. + N + Adj., la precisión en general fue alta. Se volvió a observar mayor facilidad para adquirir la concordancia del artículo respecto de los adjetivos por un lado y más precisión en el número respecto al género, por el otro. También se notó nuevamente la tendencia a utilizar el masculino como default. En cuanto a la incurrencia en errores, se constató que desaparecerían a medida que subía el nivel. En suma, pues, se detectó un efecto de competencia -la precisión difería significativamente de acuerdo con el nivel- y uno de rasgo -diferencia significativa en la producción de (valores de) rasgos correctos requeridos por el contexto, por ejemplo, masculino correcto en el adjetivo si el controlador era masculino-. Sin embargo, no hubo un influjo de la lengua materna, dado que los resultados de los aprendientes ingleses no diferían significativamente de los obtenidos por los franceses. Por otra parte, Echevarría & Prévost (2004) investigaron la concordancia de plural en los adjetivos atributivos (prenominales) y en los cuantificadores mucho, bastante y demasiado, para alumnos de francés como lengua materna de nivel intermedio y superior. En lo que atañe a los adjetivos, la concordancia obtuvo altos niveles de precisión. La precisión en mucho resultó muy alta, por lo que en la tarea de producción se observó el orden mucho > demasiado > bastante en los niveles de corrección. Posteriormente, Bruhn de Garavito (2008) analizó el plural en hablantes de francés L1 divididos en dos grupos de edades entre los 14 y 17 años pertenecientes, respectivamente, al nivel 1 y 2 de ELE. El investigador encontró que la adquisición del plural seguía las etapas plural nulo > plural en /-s/ > plural en /-es/. En otro estudio, Montrul et al. (2008) se enfocaron en las diferencias de la concordancia de género entre estudiantes de ELE de habla inglesa (grupo 1) y aquellos nacidos en EE. UU. hijos de padres mexicanos expuestos al inglés antes de los cinco años (grupo 2). El grupo de control estaba conformado por hablantes nativos de inglés. En la tarea de producción de sintagmas nominales [Art. + N + Adj.] apareció un efecto de grupo, obteniendo el grupo 2 mejores resultados que el 1. Se verificó también un efecto de animicidad: mayor precisión en los sustantivos transparentes (-o / -a como en vaso, maestra) animados que en los inanimados. También se halló un efecto de morfología: los sustantivos terminados en consonante (el camión, la canción) con mejores resultados que los terminados en -e (el puente, la suerte); además, los opuestos (la mano) fueron los que se erraron más, especialmente con los adjetivos. Asimismo, se observó un efecto de valor de rasgo: masculino mejor que femenino; pero ningún efecto de modificador (artículo / adjetivo). De modo similar, Alarcón (2011) replicó la tarea de producción del estudio anterior con estudiantes de L2 ingleses e hijos de inmigrantes nacidos en EE. UU. expuestos al español antes de los 5 años. Ambos grupos tenían una competencia similar de nivel superior; durante la investigación, participaron hablantes nativos incluidos dentro de un grupo de control. Se halló significancia en los siguientes factores: a) grupo: mejor en los hijos de inmigrantes que en los estudiantes de L2; b) rasgo: mejor en el masculino que en el femenino; c) morfología: mejor en sustantivos transparentes que en menos transparentes; d) rasgo*grupo: la diferencia en precisión entre masculino y femenino fue mayor en el caso de los aprendientes ingleses; e) rasgo*morfología: la diferencia en precisión entre nombres más y menos transparentes resultó mayor para el femenino; f) rasgo*modificador: la precisión fue significativamente mayor para los artículos que para los adjetivos en el caso del masculino; g) grupo*morfología: ambos grupos con mejores resultados en sustantivos transparentes que menos transparentes pero, al igual que en d), con diferencia mayor entre los aprendientes ingleses. Recientemente, Foote (2015) investigó el rol de la transparencia morfológica del controlador en la concordancia de género (singular), con aprendientes ingleses de ELE de nivel intermedio y superior. En el experimento se utilizaba una tarea de completamiento del tipo: la pared (N1) del baño (N2) está... limpia/*o. Las variables manipuladas fueron: i) género: el género del núcleo N1 del SN (masculino / femenino); ii) morfología: la transparencia de marca de género en el N1 (transparente / opaca); iii) correspondencia: la igualdad o desigualdad entre los géneros del N1 y el N2 (igual / distinto); iv) grupo: el nivel de competencia (intermedio / superior / nativo). Los resultados arrojaron una interacción significativa grupo*correspondencia: los aprendientes de nivel intermedio cometían significativamente más errores que los de nivel superior; y estos, más que los nativos. Además, hubo más errores en la condición de no igualdad de género entre N1 y N2, por lo queno hubo un efecto de transparencia morfológica ni de género.
1.2. Objetivos
El objetivo general de este trabajo fue identificar algunos factores influyentes en la producción de concordancia plural en cuatro aprendientes italianos de ELE. Para ello, se utilizó el marco de las redes complejas (Newman, 2010), un método poco aplicado en adquisición de L2. Para cada alumno, se crearon redes «de amistad» en las cuales las palabras / actores establecen enlaces / relaciones de concordancia erróneas con otras palabras / actores. A partir de este planteamiento, se intentó encontrar efectos respecto de los atributos de las palabras que influyeran en la aparición o desaparición de enlaces de concordancia con error en la evolución temporal de la adquisición1.
2. Recolección de datos
En esta sección se analizarán los datos obtenidos de cuatro casos de estudiantes adultos, de lengua nativa italiana, estudiantes de ELE en el Instituto Cervantes de Milán durante el año académico 2008-2009. Cada alumno poseía un nivel distinto de competencia lingüística según el Marco Común Europeo de Referencia. Inicialmente, se hicieron entrevistas de 30 minutos entre el alumno y el investigador autor de este trabajo. La tarea consistió en sostener conversaciones no estructuradas sobre temas acordes al nivel de competencia de los participantes. Dichas entrevistas tuvieron lugar durante aproximadamente cada 20 días, según la disponibilidad de los alumnos. Cada aprendiente realizaba simultáneamente el curso de español que le correspondía. Durante el tiempo de la investigación, hubo entre doce y catorce entrevistas con cada sujeto. De este modo, el corpus está constituido por los siguientes conjuntos de transcripciones: SONIA (nivel A1/A2), con 12 transcripciones; NATI (nivel B1), con 14 transcripciones; JAKO (nivel B2), con 14 transcripciones; y MIRKA (nivel C1), con 12 transcripciones. La codificación y transcripción de los datos se hizo mediante el formato CHAT, siguiendo a Mac Whinney (2020). Cada concordancia se codificó con dos términos, aunque era posible que hubiese más términos «objetivo»: por ejemplo, en los libros azules se codificaron dos instancias: los libros y libros azules. Para la realización del conteo, se utilizó el programa CLAN. A modo de ilustración, considérese el siguiente fragmento de transcripción MIRKA [sesión 6]:
46 *STU: entonces <lo que> [//] ehh@fp yo creo que ehh@fp los animales ehh@fp tienen derechos. 47 *STU: pero <no> [/] no son lo [*3] mismos derechos [*0] ehh@fp que ehh@fp
48 +...
49 *STU: lo <que deben tener las> [//] que tienen las personas [*0]. 50 %err: los mismos derechos.
51 *STU: no se si me explico.
52 *STU: los [*0] seres humanos [*0] ehh@fp tenemos +... 53 *STU: es algo un poco malo que decir.
54 *STU: pero tenemo [*] más derechos que los animales. 55 %err: tenemos
56 *STU: en el sentido que [*] ehh@fp <me>[/] me doy cuenta que a veces los animales [*0] son muy sensibles [*0].
3. Redes de concordancia y atributos
Se crearon cuatro redes acumulando los casos de concordancia con error de las sesiones. Las redes eran dirigidas, donde la flecha indicaba el origen del error (Ej.: la casas recibiría la representación , mostrando que el error se ubica en el artículo). Si el error estaba en ambos términos, entonces la flecha era bidireccional. Así, se tomaron solamente los casos de concordancia de error, es decir, se trataba de redes de crecimiento de error. Para ello, se agruparon las sesiones en tres etapas (de crecimiento acumulado) según el siguiente esquema:
1. SONIA y MIRKA: i) hasta la sesión 4; ii) hasta la sesión 8; iii) hasta la sesión 12.
2. NATI y JAKO: i) hasta la sesión 5; ii) hasta la sesión 9; iii) hasta la sesión 14.
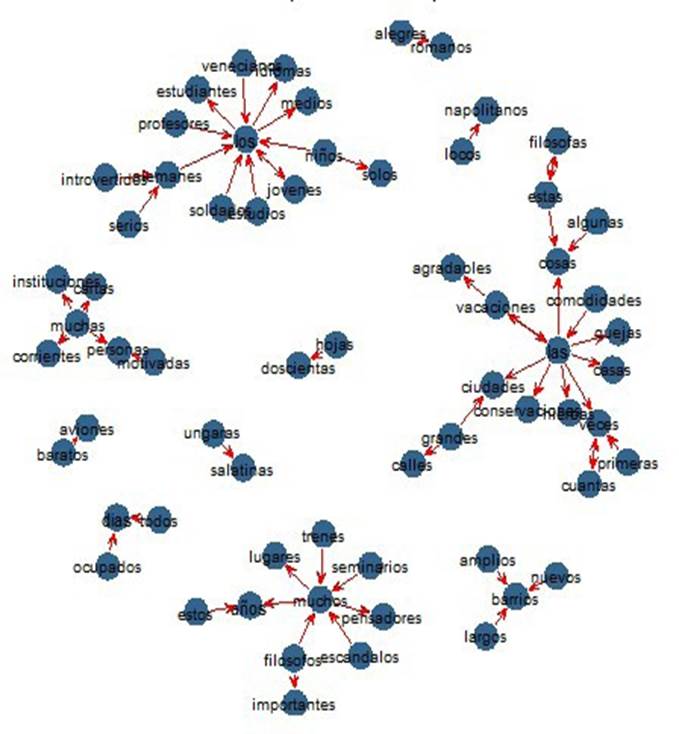
Nótese que las redes mantienen constantes los nodos / palabras y lo que se agrega en cada etapa son las aristas. La Figura 1 muestra la red de SONIA (hasta la sesión 12). Por otro lado, la Figura 2 ilustra las redes de todos los aprendientes.
Por otra parte, se crearon variables que caracterizaban cada término dentro de una concordancia (nodo en la red), las cuales son descritas a continuación (el primer nivel se considera el de referencia):
-ERROR. Cantidad de errores de concordancia en los que interviene el término. Por ejemplo, el plural profesores puede estar involucrado en las concordancias producidas: los profesores, los profesore, mucho profesores; con lo cual estaría involucrada en dos concordancias erróneas.
-ESPA. Concordancia en español (sin error).
-MOD. Tipo de modificador del controlador. Niveles: 0 = no es modificador; 1 = artículo definido; 2 = artículo indefinido; 3 = determinante (adjetivos posesivos, indefinidos, demostrativos, interrogativos, exclamativos); 4 = adjetivos (calificativos, numerales, ordinales).
-ES. Se especificó si en la palabra había una desinencia que requería la inserción de e epentética [-(e)s]; según: 0 = sin e epentética; 1 = con e epentética.

-ANIM. Si el controlador era o no animado. Es decir, si la entidad a la que refiere el nombre puede moverse o no por propia voluntad, según: 0 = no es controlador; 1 = inanimado, 2 = animado.
-ESP1. Se codificó la vocal final de la palabra más la desinencia de plural en español del primer término. Según: 1 = us [Ej.: sus]; 2 = is [Ej.: mis]; 3 = os [ej.: rojos]; 4 = as [ej.: blancas]; 5 = es [ej.: azules]; 6 = *es [ej.: útiles (-e- epentética)]
-ESP2. Se codificó la vocal final de la palabra más la desinencia de plural en español del segundo término (mismos niveles que ESP1).
Los siguientes atributos, sobre rasgos del controlador, se extrajeron de la base de datos BuscaPalabras (Davis & Perea, 2005):
Concretud (CONC): índice subjetivo en escala de 1 a 7 que indica cuán concreta es una palabra de menos (+ abstracta) a más (+ concreta).
Familiaridad (FAM): índice subjetivo en escala de 1 a 7, que indica cuán frecuentemente una palabra es oída, leída o producida diariamente.
Imaginabilidad (IMA): índice subjetivo en escala de 1 a 7 que indica la intensidad con la que una palabra evoca imágenes.
Frecuencia (LEXESP): frecuencia de la palabra en el corpus “BuscaPalabras”, en escala por mil.
Además, se crearon dos variables basadas en la distancia de Levenstein (Nerbonne et al., 2013; Oakes, 1998), con el objetivo de medir la similitud entre las raíces léxicas del español y el italiano; y entre los morfemas de género y número plural. El algoritmo de Levenstein calcula la distancia entre dos secuencias de caracteres como el número mínimo de operaciones necesarias para transformar una secuencia en la otra. Estas operaciones son: DELETE (borrar); SUBSTITUTE (sustituir); INSERT (insertar). A partir de esto, se asignaron los siguientes pesos para las operaciones: i) DELETE = 0.3; ii) SUBSTITUTE = 0.6; INSERT = 1. Por ejemplo, en la instancia much-os amig-os [SONIA, sesión 1, línea 7] (it. molt-i amic-i) la similitud entre las terminaciones de ambos términos de la concordancia se calculó como: . En ambos términos es necesario operar una sustitución (= 0.6) de i por o y una inserción de s (= 1), cuya suma es 1.6. También se practicó una corrección sumando 0.2 al valor arrojado por el algoritmo en los casos en los que interviene una -e- epentética. Esto es así porque el algoritmo no distingue entre una terminación -es donde la e es epentética [canciones] y otra en que no lo es [calles]. A modo de ejemplo, en el caso de las lecciones [SONIA, sesión 8, línea 370] (it. le lezioni) donde el segundo término tiene -e- epentética, se calculó:.
Además de la similitud entre las desinencias, se calculó la similitud entre las raíces léxicas de ambos términos. Para ello, se extrajo la raíz de cada uno de los términos y se aplicó la distancia de Levenstein. Por ejemplo, en much-os person-as [SONIA, sesión 1, línea 56] (it. molt-e person-e) se calculó como: .
Por otra parte, se realizaron las siguientes operaciones de pre-procesamiento. En primer lugar, se transformó al logaritmo la frecuencia del controlador, sumándole una unidad (Corpus “BuscaPalabras”): .Como resultado de estas operaciones, se recolectaron en total 1857 casos de concordancia. Sin embargo, los atributos relacionados con el controlador (excepto ANIM) a veces no tenían datos registrados en la base de datos de BuscaPalabras. Debido a ello, hubo 161 casos en los que faltaban datos en una o más de estas variables. Los casos faltantes representaron el 8.6 % de la base de datos. Para tal efecto, se utilizó el paquete mice [Multivariate Imputation by Chained Equations] de (Van Buuren & Groothuis-Oudshoorn, 2011), que realiza imputación múltiple.
Por otra parte, se empleó la correlación de Spearman entre las variables extraídas de BuscaPalabras: Imaginabilidad (IMA), Concretud (CONC), Familiaridad (FAM)y Frecuencia en escala logarítmica (LEXESP). Las variables fueron escaladas en la ecuación (). Una vez realizadas, se observó una correlación positiva moderada
(0.68) entre Imaginabilidad y Concretud, como era de suponerse: entre más concreta resulte una palabra, más fácil resulta evocar imágenes de esta. Además, existió una correlación positiva entre Familiaridad y Frecuencia (0.50): entre más frecuente resulta una palabra, más familiar parece. Se aplicó, pues, un Análisis de Componentes Principales (PCA, por sus siglas en inglés). La técnica permite obtener nuevas variables ortogonales llamadas componentes principales, que se calculan como combinación lineal de las variables cuantitativas originales (Peña, 2002). En la primera componente, denominada IMA.CONC, cargaban las variables Imaginabilidad y Concretud; y en la segunda, Familiaridad y LEXESP, denominadaFAM.LEX. En suma, se resolvió la colinealidad pasando de cuatro variables de controlador con correlación a dos componentes sin correlación entre sí.
Por último, se decidió discretizar los atributos cuantitativos utilizando clustering por mezcla de gausianas. Para ello, se utilizó el paquete mclust de R (Strucca et al., 2016) con el fin de hacer el agrupamiento. Durante el proceso, se discretizaron los atributos: IMA.CONC y FAM.LEX. El atributo FAM.LEX se discretizó en dos categorías poniendo como punto de corte a la mediana; ya que el clustering no resultó efectivo. A continuación, en la Tabla 1 se ilustran los resultados obtenidos, mientras que en la Tabla 2 se describen los atributos de los nodos.
Tabla 1 Discretización de atributos utilizando clustering por mixtura de gausianas
| Atributo | Descripción | Discretización | Ejemplos del Corpus |
|---|---|---|---|
| IMA.CONC.f | PCA1 | 0=[-3.48;0.58) 1=[0.58;2.35] | nuevos conocimientos (-3.11); los servicios (-1.19) |
| muchas personas (1.31); los hospitales (2.17) | |||
| FAM.LEX.f | PCA2 | 0=[-4.24;0.17) 1=[0.17;1.98] | los sultanes (-4.42); las comodidades (-0.64) |
| [corte: mediana] | los años (1.22); los hombres (1.89) |
Tabla 2 Atributos de los nodos formulados para el análisis
| Variable | Descripción | Clase | Niveles |
|---|---|---|---|
| MOD | Tipo de modificador del controlador | Cualitativa | 0 = no es modificador, 1 = artículo definido; 2 = artículo indefinido; |
| 3 = determinante; 4 = adjetivo | |||
| ERROR | Cantidad de errores de concordancia | Cuantitativa | [0, 1, 2…] |
| en los que interviene la palabra. | |||
| ES | ¿Tiene la palabra plural con e epentética? | Cualitativa | 0 = NO, 1 = SI |
| ANIM | ¿Es la palabra controlador animado? | Cualitativa | 0 = no es controlador; 1 = controlador inanimado; |
| 2 = controlador animado. | |||
| FAM.LEX | Índice PCA de familiaridad y frecuencia | Cualitativa | 0 = no es controlador; 1 = baja; 0 = alta |
| léxica del controlador (discretizado) | Cualitativa | ||
| IMA.CONC | Índice PCA de imaginabilidad y concretud (discretizado) | Cualitativa | 0 = no es controlador; 1 = baja; 0 = alta |
| Léxica del controlador | Cualitativa | ||
| ESP1 | Tipos de terminaciones del «objetivo» | Cualitativa | 1 = us [ej.: sus]; 2 = is [ej.: mis]; 3 = os [ej.: rojos]; |
| 4 = as [ej.: blancas]; 5 = es [ej.: azules]; | |||
| 6 = es* [ej.: útiles (-e- epentética)] | |||
| ESP2 | Tipos de terminaciones del «controlador» | Cualitativa | 1 = us [ej.: sus]; 2 = is [ej.: mis]; 3 = os [ej.: rojos]; |
| 4 = as [ej.: blancas]; 5 = es [ej.: azules]; | |||
| 6 = es* [ej.: útiles (-e- epentética)] | |||
| MORF | Similitud de la palabra entre terminaciones de español e italiano | Cuantitativa | 0.6, 2] |
| STEM | Similitud de la palabra entre las raíces | Cuantitativa | [0.7, 6] |
| léxicas de español e italiano |
4. Análisis estadístico de evolución temporal
En este punto, se aplicó el llamado Actor-Based Stochastic Model (Snijders, 1996; Snijders et al., 2007, 2010), un modelo estadístico de evolución temporal de redes. El modelo trata a cada nodo de una red como un actor. Ya que los enlaces de la red se modelan como si fueran estados, se considera el cambio como un proceso de Markov -en cada punto del tiempo el estado actual de la red determina probabilísticamente el estado de la red en el instante sucesivo, sin influencia de estados pasados-. En este modelo, el proceso es continuo, es decir, la red observada en cada punto es el resultado de microcambios continuos realizados en minipasos. En cada uno de estos, dicho actor debe decidir si preserva, elimina o establece enlaces con otros actores. Este cambio se halla influenciado por factores endógenos a la red -por ejemplo, la tendencia a la reciprocidad de los enlaces: si soy tu amigo, eres mi amigo-; o exógenos a ésta: covariables del actor -los atributos del nodo- o covariables diádicas -interacciones entre atributos de dos nodos conectados por un enlace, como presencia de la característica en ambos nodos-. Además, en la evolución temporal pueden cambiar características de los actores influenciados por la estructura de la red.2 Por lo tanto, se pueden seguir dos dinámicas: una de la red y otra de características comportamentales de los actores. Las relaciones entre los actores están representadas en la matriz de adyacencia
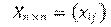 (n actores); con
(n actores); con
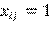 si hay un enlace entre los actores i y j, y
si hay un enlace entre los actores i y j, y
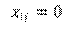 si no lo hay.3
si no lo hay.3
Los atributos de comportamiento de los actores deben ser categóricos u ordinales y se los denotará como
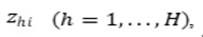 , el valor del h-ésimo atributo del i-ésimo actor. Por lo tanto, cada actor tendrá las observaciones
, el valor del h-ésimo atributo del i-ésimo actor. Por lo tanto, cada actor tendrá las observaciones
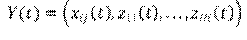 , en cada tiempo discreto . El proceso de cambio se descompone en dos subprocesos.
, en cada tiempo discreto . El proceso de cambio se descompone en dos subprocesos.
El primero modela la frecuencia con la que suceden los cambios (de enlaces y del comportamiento de los actores) en los minipasos. Es una función de tasa de arribo que depende del efecto de la tasa del periodo , de efectos de covariables del actor y de efectos de posición del actor en la red (por ejemplo, la cantidad de enlaces de un nodo). Son:
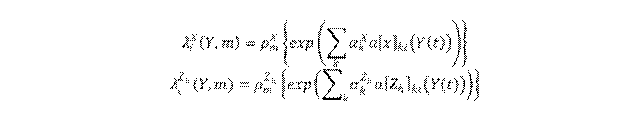
Por tanto, los tiempos de espera entre minipasos de cada actor sigue una distribución exponencial de parámet- ro (). Si hay tasa constante: , . Por otra parte, se modela el subproceso de cambio determinístico; es decir, en cuál enlace o atributo comportamental se produce el cambio. Los atributos de comportamiento cambian siempre en una unidad -crecen o decrecen-. La función se descompone en tres partes: una función de evaluación, una función de satisfacción y un término de error (modelado a partir de la distribución de Gumbel): . La segunda función pe- naliza la pérdida de un enlace o el decrecimiento de un valor comportamental como pérdida de satisfacción. Sin embargo, no será usado dicho componente en el análisis. La parte fundamental es, pues, la función de evaluación, que especifica los efectos de estructura o de comportamiento. En este punto, el actor seleccionará el cambio que maximiza dicha función. Al igual que con la función de tasa de arribo, hay dos; una para cada dinámica:
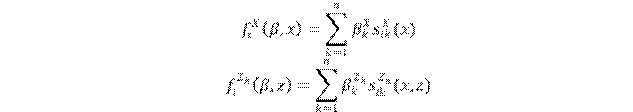
En donde son parámetros, son funciones que dependen de la estructura de la red y son funciones que dependen del comportamiento del actor, pero también del comportamiento o características estructurales (de red) de sus vecinos.
Por fin, la probabilidad de que un actor cambie de estado (enlace o comportamental) se define como:
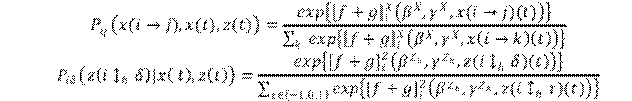
A continuación, se describen los efectos de estructura incluidos en el modelo elegido para este estudio.
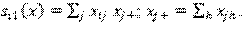 -Outdegree-Popularity. Es el número de enlaces salientes de los nodos conectados a un nodo i-ésimo.
-Outdegree-Popularity. Es el número de enlaces salientes de los nodos conectados a un nodo i-ésimo.
-Indegree-Popularity. Es el número de enlaces entrantes de los nodos conectados a un nodo i-ésimo.
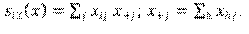
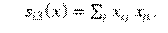 -Reciprocity. Es el número de enlaces recíprocos entre dos nodos.
-Reciprocity. Es el número de enlaces recíprocos entre dos nodos.
-Anti isolates. Efecto de conexión con otros nodos, los cuales estarían aislados sin dicha conexión.
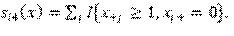
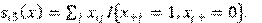 -Isolate - popularity. Efecto de estar conectado con actores cuyo grado de enlaces entrantes es 1.
-Isolate - popularity. Efecto de estar conectado con actores cuyo grado de enlaces entrantes es 1.
-out-in degree^(1/2) assortativity. La tendencia de que los nodos con alto grado de enlaces salientes estén conectados a nodos con alto grado de enlaces entrantes.
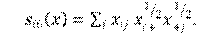
-Balance. Similitud entre los enlaces salientes del nodo i-ésimo y los enlaces salientes de los otros nodos con los cuales se conecta dicho nodo i-ésimo.
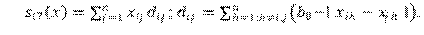
-In-struct equivalence. Similitud entre los enlaces entrantes del nodo i-ésimo y los enlaces entrantes de los otros nodos con los cuales se conecta dicho nodo i-ésimo.
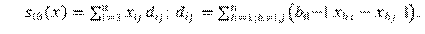
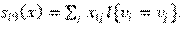 -SameX. Mismo comportamiento entre los actores (nodos) y [homofilia respecto de atributos cualitativos].
-SameX. Mismo comportamiento entre los actores (nodos) y [homofilia respecto de atributos cualitativos].
-sameXRecip. Mismo comportamiento (homofilia) en enlaces bidireccionales.
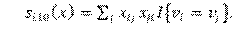
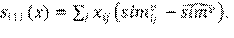 -SimX. Suma de las similitudes centradas (respecto de un determinado atributo
-SimX. Suma de las similitudes centradas (respecto de un determinado atributo
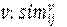 ) entre i y los otros actores j con los que está conectado [Asortatividad para atributos cuantitativos].
) entre i y los otros actores j con los que está conectado [Asortatividad para atributos cuantitativos].
-SimRecipX. Similitud respecto de enlaces bidireccionales.
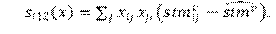
-EgoX. El número de enlaces salientes pesados por un valor de covariable del actor.
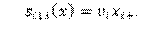
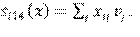 -AltX. La suma de la covariable sobre todos los actores con los cuales tiene un enlace.
-AltX. La suma de la covariable sobre todos los actores con los cuales tiene un enlace.
-EffFrom. Dependencia de un atributo de otras variables de comportamiento
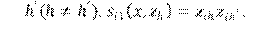
Entonces, las funciones de evaluación para la dinámica de la red y la del comportamiento se definen como:
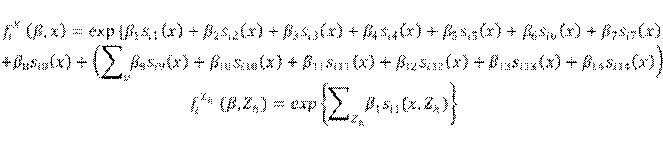
Las tasas de arribo son constantes (sin efectos de covariables o de estructura): ; . Para la dinámica de comportamiento se considera la cantidad de errores de una palabra / nodo.4 Se utilizó RSiena (Ripley et al., 2018).
Se testearon las siguientes hipótesis:
El nodo (palabra) es origen de error, según un determinado atributo [EgoX].
El nodo (palabra) no es origen de error, según un determinado atributo [AltX].
Un determinado atributo es similar en ambos nodos (palabra) [SimX, SameX].
El error es recíproco, según un determinado atributo [SimRecipX, sameXRecip].
La acumulación de errores en una palabra crece, según un determinado atributo [EffFrom].
Las Tablas 4 a 7 muestran los resultados significativos del modelo estimado para cada aprendiente.5 En estas aparecen las palabras de controlador con alta imaginabilidad y concretud, así como aquellas que funcionan como adjetivos y las que conllevan -e- epentética susceptibles a la incurrencia en errores. De modo similar, las palabras con controlador de familiaridad / frecuencia léxica alta tienden tanto a generar como a recibir errores. Por otra parte, las palabras terminadas en es (ej., cantantes, amables), las que conllevan -e- epentética y las que tienen alta similitud de raíz / desinencia con el italiano tienden a tener valores similares con el otro término de la concordancia errónea. Solamente en el caso de MIRKA se halló un efecto de influencia en la acumulación de error, respecto de controladores con valores imaginabilidad / concretud altos. Por lo tanto, no hubo efectos significativos de reciprocidad de errores. En la Tabla 3 se resume lo dicho.
Tabla 3 Resumen de resultados para cada hipótesis
| Hipótesis | SONIA | NATI | JAKO | MIRKA |
|---|---|---|---|---|
| i) | FAM.LEX | MOD = «4»; ES | IMA.CONC | - |
| ii) | FAM.LEX | - | - | - |
| iii) | ES; ESP = «es»; STEM | ESP = «es» | MORF | ESP = «es»; ES |
| iv) | - | - | - | - |
| v) | - | - | - | IMA.CONC |
Una manera de evaluar la bondad de ajuste del modelo consiste en comparar el modelo observado con otros resultados posibles simulados a partir del modelo ajustado. Se simularon 1000 redes generadas a partir de los parámetros del modelo y se calculó para cada una la probabilidad de cada grado entrante [in degree: cantidad de enlaces entrantes a un nodo], tomando de cero a tres grados. Los resultados se muestran mediante un violin plot para cada grado mostrando la distribución sobre los mil valores obtenidos. En el punto rojo se indica el valor observado. El p-valor, por su parte, muestra la probabilidad de observar la distribución de grado observada en las mil simulaciones -o más extrema-. Cuanto más alto, mejor ajuste es decir, que la hipótesis nula es «el modelo ajusta bien» y, por ende, no debe rechazarse []. Se puede notar, pues, que ningún modelo ajustado rechaza la hipótesis nula (ver Figura 3).
Tabla 4 Resultados del análisis de errores de SONIA (Maximum Convergence Ratio: 0.236).
| Function | Effect | Coef | StEr | Pval | Sig | Conv |
|---|---|---|---|---|---|---|
| Red | constant red rate (period 1) | 1.162 | 0.239 | p < 0.001 | *** | 0.086 |
| Red | constant red rate (period 2) | 0.238 | 0.103 | 0.021 | * | 0.045 |
| Red | Reciprocity | 3.366 | 1.483 | 0.0232 | * | 0.070 |
| Red | indegree - popularity | 0.761 | 0.249 | 0.0022 | ** | 0.019 |
| Red | anti isolates | 3.938 | 1.429 | 0.0058 | ** | 0.007 |
| Red | stem similarity | 2.256 | 1.056 | 0.0326 | * | 0.075 |
| Red | same esp_3 | 4.235 | 1.705 | 0.013 | * | 0.060 |
| Red | same es | 1.873 | 0.903 | 0.038 | * | 0.089 |
| Red | fam.lex alter | 0.695 | 0.329 | 0.0343 | * | 0.001 |
| Red | fam.lex ego | 12.922 | 3.065 | p < 0.001 | *** | 0.058 |
| Error | rate error (period 1) | 0.604 | 0.206 | 0.0034 | ** | 0.011 |
| Error | rate error (period 2) | 0.310 | 0.102 | 0.0025 | ** | 0.035 |
Tabla 5 Resultados del análisis de errores de NATI (Maximum Convergence Ratio: 0.126).
| Function | Effect | Coef | StEr | Pval | Sig | Conv |
|---|---|---|---|---|---|---|
| Red | constant red rate (period 1) | 2.741 | 0.783 | 5e-04 | *** | 0.076 |
| Red | constant red rate (period 2) | 0.591 | 0.202 | 0.0034 | ** | 0.018 |
| Red | Reciprocity | 2.628 | 0.517 | p < 0.001 | *** | 0.038 |
| Red | outdegree - popularity | 0.625 | 0.121 | p < 0.001 | *** | 0.036 |
| Red | isolate - popularity | 2.478 | 0.536 | p < 0.001 | *** | 0.009 |
| Red | mod_4 ego | 1.569 | 0.699 | 0.0248 | * | 0.050 |
| Red | same esp_3 | 1.748 | 0.523 | 8e-04 | *** | 0.060 |
| Red | es ego | 45.032 | 4.495 | p < 0.001 | *** | 0.008 |
| Error | rate error (period 1) | 1.401 | 0.249 | p < 0.001 | *** | 0.031 |
| Error | rate error (period 2) | 0.355 | 0.085 | p < 0.001 | *** | 0.002 |
Tabla 6 Resultados del análisis de errores de JAKO (Maximum Convergence Ratio: 0.107).
| Function | Effect | Coef | StEr | Pval | Sig | Conv |
|---|---|---|---|---|---|---|
| Red | constant red rate (period 1) | 1.523 | 0.485 | 0.0017 | ** | 0.017 |
| Red | constant red rate (period 2) | 0.359 | 0.120 | 0.0027 | ** | 0.009 |
| Red | Reciprocity | 2.575 | 0.680 | 2e-04 | *** | 0.009 |
| Red | out-in degree^(1/2) assortativity | 2.411 | 0.440 | p < 0.001 | *** | 0.029 |
| Red | in-struct equivalence | 0.683 | 0.353 | 0.0532 | . | 0.065 |
| Red | morf similarity | 2.672 | 1.000 | 0.0075 | ** | 0.013 |
| Red | ima.conc ego | 3.288 | 0.881 | 2e-04 | *** | 0.005 |
| Error | rate error (period 1) | 0.556 | 0.168 | 9e-04 | *** | 0.006 |
| Error | rate error (period 2) | 0.184 | 0.068 | 0.0071 | ** | 0.036 |
Tabla 7 Resultados del análisis de errores de MIRKA (Maximum Convergence Ratio: 0.387).
| Function | Effect | Coef | StEr | Pval | Sig | Conv |
|---|---|---|---|---|---|---|
| Red | constant red rate (period 1) | 0.849 | 0.113 | p < 0.001 | *** | 0.015 |
| Red | constant red rate (period 2) | 0.893 | 0.104 | p < 0.001 | *** | 0.086 |
| Red | Reciprocity | 3.309 | 0.387 | p < 0.001 | *** | 0.007 |
| Red | Balance | 0.533 | 0.142 | 2e-04 | *** | 0.014 |
| Red | anti in-isolates | 0.769 | 0.451 | 0.0884 | . | 0.023 |
| Red | same esp_3 | 2.728 | 0.864 | 0.0016 | ** | 0.007 |
| Red | same es | 0.801 | 0.295 | 0.0065 | ** | 0.006 |
| Red | ima.conc alter | 0.212 | 0.136 | 0.1192 | 0.008 | |
| Error | rate error (period 1) | 0.568 | 0.122 | p < 0.001 | *** | 0.025 |
| Error | rate error (period 2) | 0.821 | 0.146 | p < 0.001 | *** | 0.042 |
| Error | error: effect from ima.conc | 0.479 | 0.206 | 0.0199 | * | 0.029 |

5. Discusión
El objetivo de este trabajo fue identificar algunos factores influyentes en la aparición de errores en un corpus longitudinal de concordancias plurales para cuatro alumnos de ELE. Para ello, se crearon redes complejas según tres oleadas de acumulación de errores. Es estas, un enlace indicaba la aparición de una concordancia errónea entre dos términos / nodos. Inicialmente, se caracterizó cada nodo con una serie de atributos. Para ello, se usó una técnica estadística de evolución de redes para predecir la aparición de un enlace (error de concordancia) en la siguiente oleada según la influencia de los atributos especificados en los nodos. Un efecto significativo reportado en la revisión de literatura es que las concordancias con adjetivos son más difíciles que aquellas con artículo (Fernández-García, 1999; White et al., 2004; Montrul et al., 2008; Alarcón, 2011). En NATI, se puede notar que los términos (nodos) que funcionan como adjetivos tienden a crear relaciones de concordancias erróneas con otros términos, a medida que pasa el tiempo, y en la dirección de origen del error. Otro hecho constatado es que el plural en -es [-e- epentética] se adquiere luego del plural en -s (Bruhn de Garavito, 2008). Es razonable suponer que las concordancias que involucren plurales en -es resulten más desafiantes. Se halló en NATI, además, que las palabras con plurales que involucran -e- epentética son origen de error. Es más, en SONIA y MIRKA se tiende a establecer una relación errónea si ambos términos conllevan -e- epentética [pantalones azules]. Sin embargo, en SONIA, NATI y MIRKA también se encontró el efecto de similitud con terminaciones en s en los dos términos con singulares no canónicos terminados en -e [fuentes grandes]. Por otra parte, la revisión de literatura también se reporta un efecto de animicidad para el género (Fernández-García, 1999; Montrul et al., 2008), ausente en el presente análisis. No obstante, se incluyeron otras características del controlador, encontrándose que las palabras de controlador con alta imaginabilidad y concretud tendieron a ser origen del error en JAKO. Asimismo, ejercieron un efecto en el aumento acumulado del error en MIRKA. Por otro lado, las palabras con controlador de familiaridad / frecuencia léxica alta tendieron tanto a generar como a recibir errores. Dichos efectos abogan por la inclusión en los estudios de más características del controlador, además de la animicidad. Por último, las palabras que conllevan alta similitud de raíz / desinencia con el italiano tienden a tener valores similares con el otro término de la concordancia errónea en SONIAy JAKO.
A modo de cierre, se considera que ste trabajo ha contribuido al estudio de la adquisición de ELE incorporando una herramienta de análisis temporal; es decir, que tenga en cuenta la naturaleza dinámica del aprendizaje de una lengua extranjera.

