










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkIngeniería e Investigación
versão impressa ISSN 0120-5609
Ing. Investig. v.28 n.3 Bogotá Set./dez. 2008
Juan Mora-Florez1, Gérman Morales-España2 y Rene Barrera-Cárdenas3
1 Ingeniero electricista y M.Sc., en Potencia Eléctrica, Universidad Industrial de Santander, Colombia., Ph.D., en Ingeniería Eléctrica, Universitat de Girona, España. Docente, Programa de Ingeniería Eléctrica, Universidad Tecnológica de Pereira, Colombia. Líder, del grupo de Investigación en Calidad y Estabilidad de Sistemas Eléctricos ICE3. jjmora@utp.edu.co
2 Ingeniero electricista, Universidad Industrial de Santander, Colombia. Estudiante de M.Sc., en Economía y Administración de Industrias de Red, Instituto de Investigación Tecnológica, Departamento de Electricidad y Sistemas, Escuela Técnica Superior de Ingeniería (ICAI), Universidad Pontificia Comillas, España. german.morales.e@upco.es
3 Ingeniero electricista y M.Sc., en Potencia Eléctrica, Universidad Industrial de Santander, Colombia. Asistente de investigación, Universidad Industrial de Santander, Colombia. abarrera@uis.edu.co
RESUMEN
En este artículo se presenta una estrategia de identificación del tipo de falla y localización de la misma, en un sistema de distribución de energía eléctrica. La estrategia se basa en una técnica muy sencilla, conocida como los k vecinos más cercanos, la cual simplemente estima una distancia entre las características que describen el dato a clasificar y los datos presentados en la etapa de entrenamiento del algoritmo. Cuando un nuevo dato se presenta al algoritmo propuesto, se clasifica con el mismo tipo del ejemplo que se determine como el más cercano. Para la asignación de la zona ante una falla en el sistema de potencia, se presenta en este documento una caracterización de las señales de tensión y de corriente, medidas en la cabecera del circuito, que sirven de entrada al algoritmo. Como salida se tiene la zona donde se localiza la falla. La estrategia de clasificación se probó en un sistema de distribución real y como resultado se obtuvieron promedios de 93% como índice de confianza en el localzador, lo que muestra el alto desempeño de la aplicación propuesta. Los resultados de la investigación señalan cómo utilizando características obtenidas del fundamental de tensión y corriente se puede localizar la zona en falla con alto desempeño, contribuyendo así a localizar rápidamente la falla, brindar atención oportuna y como consecuencia mejorar los índices de continuidad del suministro de energía eléctrica en los sistemas de distribución.
Palabras clave: k vecinos más cercanos, localización de fallas, sistemas de distribución, continuidad de suministro.
ABSTRACT
This paper reports a strategy for identifying and locating faults in a power distribution system. The strategy was based on the K-nearest neighbours technique. This technique simply helps to estimate a distance from the features used for describing a particular fault being classified to the faults presented during the training stage. If new data is presented to the proposed fault locator, it is classified according to the nearest example recovered. A characterisation of the voltage and current measurements obtained at one single line end is also presented in this document for assigning the area in the case of a fault in a power system. The proposed strategy was tested in a real power distribution system, average 93% confidence indexes being obtained which gives a good indicator of the proposals high performance. The results showed how a fault could be located by using features obtained from voltage and current, improving utility response and thereby improving system continuity indexes in power distribution systems.
Keywords: k-nearest neighbours, fault location, power distribution system, supply continuity.
Recibido: abril 28 de 2008
Aceptado: noviembre 4 de 2008
Introducción
El problema de la localización de fallas en sistemas eléctricos ha tomado gran importancia debido fundamentalmente a dos aspectos. El primero está asociado al crecimiento de los sistemas de potencia, tanto el número de líneas en operación como su longitud total (Mora, 2006). El segundo está fundamentalmente asociado a la gran cantidad de fallas que se presentan en las líneas y a la disminución de los índices asociados a la continuidad del sistema, reglamentados por los entes reguladores (Bollen, 2000; CREG, 1998-2002).
El tema de investigación asociado a la localización de la falla se fundamenta en el hecho de que la restauración de fallas permanentes se puede acelerar si se conoce el sitio donde estas ocurren. Para el caso de fallas transitorias, con un localizador de fallas se identifican las partes débiles en el sistema de potencia y con mantenimiento preventivo se evitan fallas futuras. La localización de fallas es un problema complejo en los sistemas eléctricos, especialmente en el caso de redes de distribución, por la naturaleza altamente ramificada del sistema, gran número de cargas trifásicas y monofásicas intermedias, diversos calibres de conductor, medidas en un terminal de la línea, entre otros (Mora et al., 2007, pp. 1715 –1721).
Una aproximación para localizar las fallas consiste en utilizar las técnicas de aprendizaje de máquina, propias del campo de la inteligencia artificial. A partir de estas técnicas se puede reconocer cuál es la zona en falla y así determinar qué acciones se pueden realizar para la restauración del sistema. En caso de sistemas que no estén automatizados, la restauración del sistema depende de la rapidez del equipo de mantenimiento para corregir la falla. En caso de sistemas automatizados, la restauración del servicio es mucho más expedita, debido que se pueden aplicar estrategias de reconfiguración del sistema de distribución que permitan aislar la zona en falla y brindar servicio a las áreas circundantes que no están bajo ella.
En este artículo se propone un método de localización de fallas basado en una técnica de clasificación conocida como el vecino más cercano, ya utilizado como herramienta de regresión (Mora et al., 2008, pp. 100-108). Esta solución es de fácil implementación y de bajo costo tanto económico como computacional. El localizador propuesto usa como información los atributos extraídos de las señales de tensión y corriente medidos en la subestación de distribución.
Como contenido, en la sección dos se presentan los fundamentos básicos de la técnica utilizada. En la sección tres, la propuesta metodológica, mientras que la caracterización y extracción de atributos de la señal se presenta en la sección cuatro. Las pruebas del localizador se reseñan en la sección cinco, y finalmente, se brindan las conclusiones más importantes de la investigación.
Fundamentos del método del vecino más cercano (K Nearest neighbors- k-NN)
En esta sección se despliegan los fundamentos básicos de la técnica basada en los k vecinos más cercanos. Una discusión profunda sobre la técnica no está dentro del alcance de este artículo, pero se puede consultar en (Aha et al., 1991).
Una forma práctica y de fácil aplicación para predecir o clasificar un nuevo dato, basado en observaciones conocidas o pasadas, es la técnica del vecino más cercano. A manera de ejemplo, el caso de un médico que está tratando de predecir el resultado de un procedimiento quirúrgico puede predecir que el resultado de la cirugía del paciente será aquel del paciente más parecido que conoce, que haya sido sometido al mismo procedimiento. Esto puede resultar un tanto extremo, ya que un solo caso similar en el cual la cirugía falló puede influir de manera excesiva sobre otros casos, ligeramente menos similares, en los cuales la cirugía fue un éxito. Por esta razón el método del vecino más cercano se generaliza a uso de los k vecinos más cercanos.
Esta técnica se basa, simplemente, en recordar todos los ejemplos que se vieron en la etapa de entrenamiento. Cuando un nuevo dato se presenta al sistema de aprendizaje, este se clasifica según el comportamiento del dato más cercano (Aha et al., 1991; Moreno, 2004).
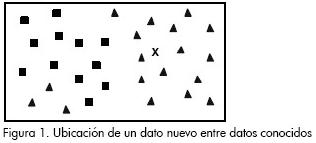
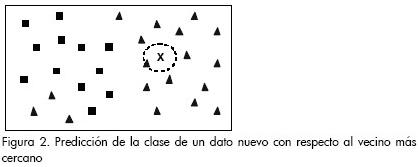
A manera de ejemplo, se puede observar cómo es la clasificación del vecino más cercano. Se tienen los datos pertenecientes al conjunto de entrenamiento, tal como se muestra en la Figura 1 (triángulos y cuadrados), y se quiere conocer la etiqueta de un nuevo dato (marcado como x). Entonces el procedimiento a seguir consiste en buscar el ejemplo que esté más cerca de este nuevo dato x, y asignarle su etiqueta (triángulo), tal como se señala en la Figura 2.
Ahora, si se considera el caso donde hay un cuadrado dentro de los datos correspondientes a los triángulos (ruido), y se desea clasificar el nuevo dato (x), utilizando el ejemplo más cercano tal como se muestra en la Figura 3, se tiene un posible error.
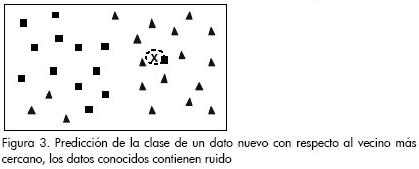
Se puede notar debido al ruido, el nuevo dato se clasifica como cuadrado. Para considerar el problema del ruido se puede cambiar el algoritmo de clasificación y utilizar un mayor número de vecinos, y así generar la etiqueta del nuevo dato usando mayoría simple, y no un solo dato. Esta generalización del método se llama k-vecinos más cercanos (Moreno, 2004). En este caso se hace k=5 y se puede observar que el nuevo dato pertenece a la clase triángulos, tal como gráficamente se muestra en la Figura 4.
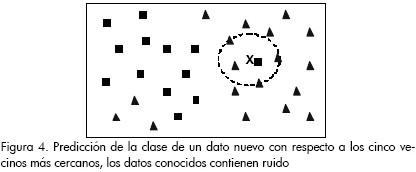
Con este nuevo enfoque se consigue resolver el problema del ruido. Entre más grande es k, más robusta la clasificación ante ruido. Sin embargo, el valor de k tiene un límite, si se hiciera máximo cualquier dato nuevo siempre se tendrá la etiqueta de la clase que más datos haya en el conjunto de entrenamiento (Aha et al., 1991). Por ejemplo, para el caso presentado en la Figura 4, si se asigna k=31 los datos nuevos siempre serán clasificados como triángulos debido a que se tienen 18 triángulos y 13 cuadrados.
Para la estimación de la distancia se utilizan dos estrategias conocidas como distancia euclidiana y distancia Mahalanobis, las cuales se presentan en su forma vectorial para una distancia entre dos vectores en (1) y (2), respectivamente.
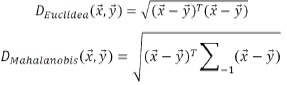
Propuesta metodológica para el desarrollo del localizador
A continuación se presenta la metodología propuesta para localzar la región probable de falla y la aplicación posterior del clasificador. El proceso está dividido en cinco etapas generales, que comprenden la zonificación de la red, la adquisición de registros de falla, el preprocesamiento de la señal, el entrenamiento y la prueba del localizador basado en k vecinos más cercanos.
Etapa 1: Zonificación de la red
El problema de localización de fallas es más sencillo si el sistema de potencia se divide en zonas, a las cuales se asigna un conjunto de atributos de entrada. Cada zona corresponde a una de las clases que se deben identificar con la técnica de clasificación.
El criterio de zonificación se fundamenta en la división del sistema de potencia de tal manera que la identificación de una zona como la más probable de falla permita reducir el tiempo de localización de la misma al equipo de mantenimiento de la red. Una zona no debe contener más de un lateral con las mismas fases, para evitar el problema de la múltiple estimación presentada por los métodos clásicos de localización basados en la estimación de la impedancia (Das, 1998). En consecuencia, los criterios de zonificación son: topología de la red, localización de protecciones, longitud de alimentadores, importancia del ramal, disponibilidad de datos de fallas para entrenar el clasificador y, finalmente, las prácticas operativas de la empresa.
Etapa 2: Adquisición de la base de datos de falla
Cuando un evento de falla ocurre en el sistema de potencia se registran las señales de tensión y corriente medidas en la subestación, como insumo fundamental para el localizador. A partir de estos registros se crea una base de datos, en la cual cada registro se asocia con el tipo de falla y su localización. La base de datos puede ser obtenida mediante una combinación de registros reales de falla, o empleando un software especializado para realizar simulaciones con un circuito base, modelado con los parámetros del circuito real. En este caso se hizo una simulación extensiva de fallas usando Matlab® y Alternative Transients Program – ATP (Mora et al., 2006, pp. 1-6). Las resistencias de falla para simulación se encuentran en un rango entre 0 y 40 Ω (Dagenhart, 2000, pp. 30-32).
Etapa 3: Pre-procesamiento de la señal
Esta etapa consiste en la obtención del conjunto de atributos que representan la falla. Cada conjunto está asociado con una etiqueta que corresponde a la zona en la cual ocurrió la falla. En este caso se consideraron sólo atributos de fácil obtención, de tal forma que la propuesta final no sea condicionada por las limitaciones de equipos. Los atributos aquí presentados se calculan de una forma simple para evitar la incertidumbre asociada al proceso de estimación de las magnitudes eléctricas, tal como se presenta en la sección cuatro.
Etapa 4: Entrenamiento del clasificador
La primera parte de esta etapa es la selección del conjunto de atributos para el proceso de entrenamiento. En esta selección se analizan las combinaciones de atributos constituyentes del conjunto de entrenamiento que posibilitan una clasificación adecuada, y por tanto, la localización correcta de la zona bajo falla.
Para la selección del mejor método de distancia y del valor de k se utilizó el método de la validación cruzada, el cual básicamente consiste en dividir el conjunto de entrenamiento en v subconjuntos (Chih et al., 2003). Utilizando un valor de k y uno de los métodos de distancia, se entrena con un subconjunto y se prueba el desempeño con los otros v-1 subconjuntos. Esta prueba se repite con cada uno de los subconjuntos para determinar el comportamiento del método ante la configuración propuesta (valor de k y método de estimación de distancia). El método se repite para diversas combinaciones de parámetros hasta encontrar la mejor. Aunque el procedimiento no es óptimo, sirve para obtener una buena configuración del algoritmo localizador.
En este artículo, y tal como a manera de establece se establece en la sección cinco, se ofrecen los resultados de las pruebas para la combinación de dos, tres y cuatro atributos. A partir de las pruebas de cada combinación posible de atributos se selecciona el conjunto cuyos resultados de precisión son más altos. La precisión o índice de confianza se usa como medición de desempeño del localizador, y se calcula como se muestra en la ecuación (3).
Etapa 5: Pruebas de precisión del localizador basado en la técnica de clasificación
Las pruebas de precisión se realizan para estimar el comportamiento de la técnica de clasificación ante datos que no fueron usados en el proceso de entrenamiento. Los datos de prueba deben corresponder a los mismos atributos y recibir el mismo procesamiento que el efectuado para los datos utilizados en el proceso de entrenamiento. La precisión del método se calcula como se presenta en (3).
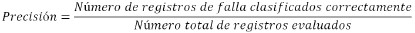
La medida de la precisión en el reconocimiento de las zonas en falla es un buen indicador que permite predecir el comportamiento del clasificador ante nuevas situaciones. Este parámetro se toma como indicador para seleccionar la mejor alternativa de configuración de la estrategia propuesta para resolver el problema de localización de fallas.
Caracterización del sistema mediante la obtención de atributos
En esta sección se presenta la caracterización de las señales de tensión y de corriente medidas en la subestación antes, durante y después de una falla en el sistema de distribución. La caracterización se fundamenta en la utilización de la señal transitoria y en estado estable (Mora, 2006; Mora et al., 2007, pp. 1715–1721).
Como resultado de esta caracterización, es posible obtener atributos que sirven como entradas para el localizador basado en los k vecinos más cercanos. Mediante el uso de estos atributos se pretende localizar la zona de falla en el sistema de distribución. Los atributos propuestos son obtenidos de las variaciones entre el estado estable de falla y prefalla de tensión, corriente y potencia.
Variación de la tensión ( ΔV )
Al atributo asociado a la variación del valor eficaz entre los estados estables de falla y prefalla se le conoce como hueco cuando se trata de la señal de tensión (Bollen, 2000).
Para obtener esta variación se requiere del valor eficaz del fundamental de prefalla y de falla, y el atributo corresponde a la diferencia de estas magnitudes. Para estimar el valor eficaz se utiliza una ventana deslizante de un ciclo de señal, con actualización muestra a muestra.
Tal como se presenta en la Figura 5, se utilizan los tres valores, uno para cada fase. A partir de aquí, y en este documento, siempre que se utilice ΔV se está haciendo referencia a la terna conformada por ΔVa, ΔVb y ΔVc. El uso de las tres señales está justificado ya que la magnitud de la variación del valor eficaz de la tensión puede ser el mismo para fallas en dos sitios. Así, una falla monofásica lejana del punto de medida con una resistencia de falla baja, puede tener la misma variación de tensión en la fase en falla que para el caso en que esta ocurra en un nodo cercano y con una resistencia de falla alta. La situación anterior se muestra en las Figuras 5 y 6. En la Figura 5 se presenta el comportamiento de las señales de tensión para el caso de una falla monofásica A-T en el sistema de prueba de la Figura 7, en la barra 4 y con una resistencia de falla de 26Ω. En la Figura 6 se muestra el valor eficaz de la tensión para el caso de una falla monofásica A-T, en la barra 11, con una resistencia de falla de 4Ω. Para el caso del ejemplo citado, se muestra cómo la magnitud del cambio del valor eficaz de la fase en falla (ΔVa ) es muy parecido (aproximadamente 3.700 V). En las fases que no están en falla esta variación es sensiblemente diferente (ΔVb y ΔVc). Adicionalmente, los descriptores asociados a los huecos de tensión se pueden obtener para señales de fase (ΔV ) y de línea (ΔVL ).
Variación de la magnitud de corriente (ΔI)
Al igual que el atributo anterior, la variación de la magnitud de la corriente está definida como la diferencia del valor eficaz entre los estados estables de falla y prefalla. Al igual que para los huecos de tensión, se utilizan los tres valores, uno para cada fase. A partir de aquí, y en este documento, siempre que se utilice ΔI se está haciendo referencia a la terna conformada por ΔIa, ΔIb y ΔIc.
Los atributos asociados a la variación del valor eficaz de la corriente se pueden obtener para señales de fase ( ΔI ) y de línea (ΔIL ).
Variación de la potencia del sistema (ΔS)
La variación de la potencia del sistema está asociada a la variación de la carga. La presencia de la falla hace que cambie el circuito visto desde la subestación y por tanto su nivel de carga.
Respecto del estado estable la variación de potencia puede ser utilizada para conocer la carga que ha sido desconectada. Adicionalmente, el cambio en el factor de potencia ofrece una indicación adicional de la característica de la carga (Das, 1998).
Al igual que los atributos anteriores, se utilizan los tres valores, uno para cada fase. A partir de aquí, y en este documento, siempre que se utilice ΔS se está haciendo referencia a la terna conformada por ΔSa, ΔSb y ΔSc.
Pruebas y resultados
Descripción del sistema de prueba
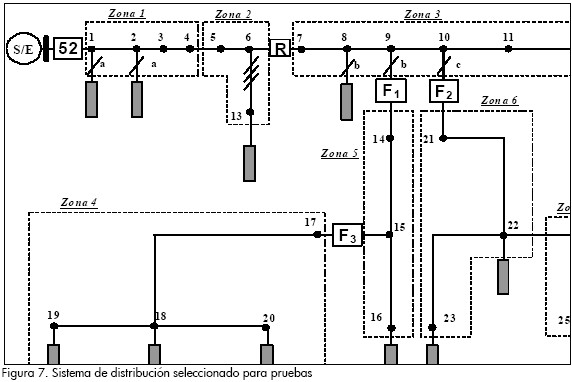
Para probar la estrategia propuesta se propone un sistema de distribución de energía eléctrica real ubicado en la ciudad de Saskat-chewan, Canadá. Este circuito, que pertenece a la empresa Sask Power & Light y se muestra en la Figura 7, ha sido utilizado en otras investigaciones, tal como se presenta en Mora, 2006; Mora et al., 2007, pp. 1715–1721 y Das, 1998.
Para el sistema de la Figura 7, F indica los fusibles de la línea, R el reconectador y 52 es el código ANSI del interruptor principal ubicado en la subestación S/E.
Definición de las clases o zonas a reconocer
En esta investigación, las zonas en las que se divide el sistema de distribución se presentan en el sistema de la Figura 7. La zonificación propuesta consta de siete zonas diferentes, las cuales deben identificarse como en falla por el localizador propuesto, para agilizar la tarea de restauración del servicio.
Selección de datos de entrenamiento y prueba
Fallas monofásicas, bifásicas, trifásicas y bifásicas a tierra, fueron simuladas en cada nodo del sistema para los valores de resistencia de falla de 0,5, 2, 4, , 40Ω (Dagenhart, 2000, pp. 30-32). El conjunto de entrenamiento se selecciona considerando datos de cada tipo de falla y considerando el 23,8% de la base de datos de falla. El 66,2% de los registros de falla se utilizaron para la prueba de la metodología propuesta.
Definición de las pruebas
El localizador propuesto se prueba considerando los cuatro tipos de fallas y para diferentes entradas de atributos. Adicionalmente, se analizan todas las posibilidades de combinaciones de dos, tres y cuatro atributos de entrada. En la sección de resultados se presentan las mejores combinaciones de atributos a partir de la precisión o índices de confianza, obtenidos tal como se indica en la ecuación (3).
Resultados
En la Tabla 1 se muestran los mejores resultados obtenidos en las pruebas, para el caso del identificador del tipo de falla, el localizador monofásico, el bifásico, el bifásico a tierra y el trifásico.
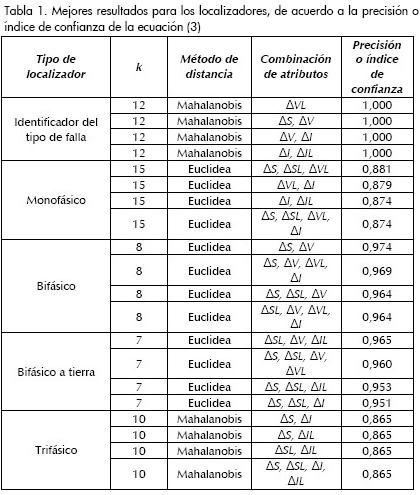
Para el ajuste de los localizadores se realizaron pruebas según cada uno de los tipos de falla, de tal manera que el valor de k y del método de distancia no está influenciado por el de los atributos utilizados para la clasificación.
De acuerdo a la Tabla 1, el resultado para el tipo de falla es el correspondiente a un índice de precisión igual a uno, con lo cual se puede apreciar que existen diferentes combinaciones de atributos para los cuales el identificador basado en el método de los k vecinos más cercanos identifica adecuadamente el tipo de falla.
Para el caso de la falla bifásica, el índice de precisión es de alrededor de 0,97 en las pruebas presentadas. La interpretación de este resultado está asociada a que de cada 100 fallas que ocurren en el sistema de distribución utilizados como prueba, se puede localizar la zona en la que ocurrieron 97 de ellas. Una interpretación similar se ofrece para el caso de fallas monofásicas, bifásicas a tierra y trifásicas.
El valor promedio de confianza en el localizador, dados los mejores resultados, es de 0,933, con lo cual se puede afirmar que de cada 100 fallas de cualquier tipo aproximadamente 93 de ellas se localizan adecuadamente.
En cuanto al análisis de los atributos de entrada, en la Tabla 1 se presentan diversas posibilidades de configuración de cada uno de los localizadores, mostrando la flexibilidad de la propuesta presentada en este documento. Considerando el tipo de falla, es probable identificarla con un máximo índice de certidumbre usando únicamente la variación de las tensiones de línea. Para el caso de la identificación de la zona en falla, se observa que con la variación de la potencia es probable encontrar un buen resultado, siempre y cuando este atributo se combine con otros, como la variación de la tensión y la de la corriente.
Conclusiones
En este artículo se presenta y prueba una estrategia de localización de fallas en sistemas de distribución de energía eléctrica. La estrategia está fundamentada en la técnica de los k vecinos más cercanos, a partir de la cual se desarrolla un localizador de la zona en falla. Como entradas a este localizador se utilizan atributos obtenidos a partir de registros de tensión y corriente medidos en la subestación.
El localizador propuesto se presenta y valida mediante pruebas que consideran diferentes tipos de fallas y valores de resistencia de falla. El sistema de prueba corresponde a un sistema de distribución real con una alta complejidad. La evaluación extensiva lograda para cada tipo de falla permite determinar los atributos con los cuales se alcanzaron los mejores resultados en los índices de confianza (93% en promedio), con lo que se muestra la validez de la estrategia de localización propuesta.
Finalmente, este tipo de implementaciones permiten mantener los índices de continuidad de los circuitos, cumpliendo así con los requerimientos de las entidades reguladoras de la calidad del servicio de energía eléctrica
Bibliografía
Aha, D., Kibler, D., Albert, M., Instance-based learning algorithms., Machine Learning, Springer Netherlands, 1991. [ Links ]
Bollen, M., Understanding Power Quality Problems: Voltages Sags and Interruptions., IEEE press, 2000. [ Links ]
Chih, H., Chung, C., Jen, L., Practical guide to support vector classification., Reporte técnico. Department of Computer Science, National Taiwan, Tech. Rep., 2003. [ Links ]
CREG 1998-2002., Comisión de Regulación de Energía y Gas CREG., Resoluciones CREG 070 de 1998, CREG 096 de 2000, CREG 084 de 2002, CREG 084 de 2002. [ Links ]
Dagenhart, J. The 40- Ground-Fault Phenomenon., IEEE Transactions on Industry Applications, Vol. 36, No. 1, 2000, pp. 30-32. [ Links ]
Das, R., Determining the Locations of Faults in Distribution Systems., Tesis doctoral, presentada en la University of Saskatchewan Saskatoon, Canada, 1998. [ Links ]
Mora, J., Localización de Fallas en Sistemas de Distribución., Tesis doctoral presentada en la Universidad de Girona, España, 2006. [ Links ]
Mora, J., Carrillo, G., Barrera, V., Fault Location in Power Distribution Systems Using a Learning Algorithm for Multivariable Data Analysis., IEEE Transaction on Power Delivery, Vol. 22, No. 3, July 2007, pp. 1715–1721. [ Links ]
Mora, J., Bedoya, J., Melendez, J., Extensive Events Database Development using ATP and Matlab to Fault Location in Power Distribution Systems., Transmission & Distribution Conference and Exposition: Latin America, TDC '06. IEEE/PES, 2006. [ Links ]
Mora, J., Morales, J., Vargas, H., Estrategia de regresión basada en el método de los k vecinos más cercanos para la estimación de la distancia de falla en sistemas radiales., Rev. Fac. Ing. Univ. Antioquia, No. 45, Septiembre, 2008, pp. 100-108. [ Links ]
Moreno, F., Clasificadores eficaces basados en algoritmos rápidos de búsqueda del vecino mas cercano., Departamento de lenguajes y sistemas informáticos, Universidad de Alicante, 2004. [ Links ]

