










Servicios Personalizados
Revista
Articulo
 texto en
texto en  Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares en
SciELO
Similares en
SciELO -
 Similares en Google
Similares en Google
Compartir

 Permalink
PermalinkIngeniería e Investigación
versión impresa ISSN 0120-5609
Ing. Investig. v.30 n.3 Bogotá sep./dic. 2010
Martha Dunia Delgado Dapena1 , Yucely López Trujillo2 e Indira Chávez Valiente3
1 Ingeniera Informatica. M.Sc., en Informática Aplicada. Ph.D., en Ciencias Técnicas, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. Centro de estudios de ingeniería de sistemas (CEIS), Facultad de Ingenieria Informatica, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. marta@ceis.cujae.edu.cu
2 Ingeniera Informatica. M.Sc., en Informática Aplicada. Ph.D., en Ciencias Técnicas, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. Centro de estudios de ingeniería de sistemas (CEIS), Facultad de Ingenieria Informatica, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. ylopez@ceis.cujae.edu.cu
3 Ingeniera Informatica. M.Sc., en Informática Aplicada. Ph.D., en Ciencias Técnicas, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. Centro de estudios de ingeniería de sistemas (CEIS), Facultad de Ingenieria Informatica, Insitituto Superior Politécnico "José Antonio Echevarria" (CUJAE), La Habana, Cuba. ichavez@ceis.cujae.edu.cu
RESUMEN
En este trabajo se presenta una propuesta de estructura de almacenamiento y los mecanismos de recuperación utilizados para aplicar el razonamiento basado en casos (RBC) en la generación de procedimientos de prueba funcionales en proyectos de software. Esta propuesta parte de los requisitos funcionales del proyecto de software y en ella se enuncian los algoritmos propuestos para considerar la semejanza entre cada par de proyectos, así como los que permiten adaptar la solución encontrada en la base de casos a las características de los nuevos proyectos.
Palabras claves: razonamiento basado en casos, ingeniería de software, calidad de software, pruebas funcionales, inteligencia artificial.
ABSTRACT
This paper presents a proposal for storage structure and retrieval mechanisms used for implementing case-based reasoning (CBR) in generating functional test procedures in software projects. This proposal was based on software project t functional requirements and sets out the proposed algorithms for considering the similarity between each pair of projects as well as those leading to adapting the solution found in the case base.
Keywords: case based reasoning, software engineering, software quality, functional testing, artificial intelligence.
Recibido: junio 5 de 2009
Aceptado: noviembre 15 de 2010
Introducción
El tema de la calidad del software es de gran actualidad. Sin embargo, aunque las empresas dedican grandes recursos a la adopción o definición de estándares de calidad los resultados alcanzados no cubren las expectativas, ya que la productividad es baja, la cantidad de recursos a consumir es casi impredecible y el resultado casi nunca tiene la calidad y profesionalidad requerida. Desde las primeras etapas en el ciclo de vida de un software se pueden comenzar a planificar las pruebas a realizar (Everett, 2007; Pressman, 2005) incluso antes de llegar a la etapa de codificación, con esto se evita insertar errores en la aplicación que pueden volverse muy difíciles de encontrar en fases posteriores.
A pesar de constituir una buena práctica, muy pocos se acogen a esta idea y comienzan a pensar en las pruebas sólo después de tener el código. La mayoría de los equipos de desarrollo de software cuentan con tiempo limitado para la creación de pruebas minuciosas y bien planificadas, lo cual trae consigo que se ejecuten fundamentalmente pruebas funcionales y sin una planificación previa. Bajo estas condiciones puede pensarse en trabajar sobre la acumulación, en la computadora, de la experiencia que se obtiene en cada una de las pruebas, de forma tal que se disponga de un banco de casos para apoyar la fase de pruebas en nuevos proyectos, y en particular la generación de casos y procedimientos de prueba partiendo de otros que se han utilizado antes y que han permitido detectar defectos en proyectos previos.
Diferentes metodologías en desarrollo de software incluyen las pruebas, y algunas hacen más énfasis en ellas, como es el caso del desarrollo guiado por pruebas -en inglés Test-Driven Development- (Augustine, 2005) y otras lo ven como una fase del desarrollo que debe garantizar la calidad del producto final (Jacobson, 2004), pero todas las propuestas coinciden en que es un tema de suma importancia y debe planificarse desde las etapas tempranas de desarrollo del software. Varios trabajos refieren la importancia de estimar el esfuerzo asociado a las pruebas para decidir su automatización o ejecución en cada caso (Singh y Misra, 2008), así como la automatización de pruebas en entornos específicos (Xie y Memon, 2007; Masood, Bhatti, Ghafoor y Mathur, 2009; (KO y Myers, 2010). Existe un conjunto de propuestas que abordan directamente el tema de la reducción de casos de prueba (Heimdahl, 2004; Mogyorodi, 2008; Polo, 2005; Black, 2004; éstas utilizan algoritmos donde es vital disponer del tiempo necesario para la etapa de pruebas, siendo esto a veces imposible.
Han surgido nuevos procesos y metodologías para diseñar pruebas (Myers, 2004; Guvenc, 2006; Meyer, 2006; Gutiérrez, 2007; Dias; 2008; Naslavsky, 2008), pero en general ellas no permiten la reutilización de casos o procedimientos generados con anterioridad.
La propuesta que se presenta en este artículo toma en cuenta solamente las pruebas a los requisitos del software (funcionales o de caja negra), cuyo objetivo fundamental es validar si el comportamiento observado de él cumple o no con las especificaciones. Este trabajo forma parte de un proyecto más ambicioso a cargo de un grupo de investigadores y profesores del Centro de Estudios de Ingeniería de Sistemas (CEIS) perteneciente a la Facultad de Informática del Instituto Superior Politécnico José Antonio Echeverría (Cujae), cuyo objetivo fundamental es hacer propuestas para la planificación y reutilización de pruebas funcionales.
El proyecto abarca tres fases: una primera, en la que se traduce la especificación de requisitos del software, escrito en un lenguaje no formal, a un listado de requisitos funcionales reducido a un verbo y un sustantivo que caracterizan la funcionalidad en cuestión. En la segunda fase se llevan a cabo varios procesos que generan un conjunto de casos y procedimientos de prueba para un proyecto de software partiendo de pruebas funcionales desarrolladas a proyectos anteriores. Por último, una tercera fase, en la que se reduce el conjunto de casos y procedimientos de prueba propuestos de acuerdo a determinados criterios de prioridad y que serán considerados como la primera aproximación al plan de pruebas funcionales.
Este reporte está enfocado en la segunda fase del proyecto, relacionada con los algoritmos y mecanismos que permiten la generación de procedimientos de prueba funcionales en un proyecto de software.
Para lograr una herramienta de apoyo a este tipo de decisión parece aconsejable utilizar técnicas de inteligencia artificial (IA). Si se considera que a los posibles expertos les resulta muy difícil establecer cadenas de reglas generalizables que permitan inferir los casos de prueba y procedimientos de prueba a utilizar en cualquier tipo de proyecto, y les es más fácil expresar su conocimiento en términos de casos ya ocurridos, parece aconsejable emplear el razonamiento basado en casos -RBC- (Althoff, 2001).
El RBC ha tenido aplicaciones en la ingeniería de software (Shepperd, 2003; Ganesan, 2000; García, 2001). En particular, en las pruebas de software se han utilizado varias técnicas de IA, de las que algunos ejemplos son el análisis de resultados utilizando una red neuronal y algoritmos de minería de datos presentados en Last (2006), la priorización de casos de prueba utilizando algoritmos genéticos y otras técnicas (Elbaum, 2004; Fraser, 2007).
Razonamiento basado en casos para reutilizar procedimientos de prueba en proyectos de software
Estructura de la base de casos
La información referente a los proyectos y los defectos detectados en las revisiones a éstos se almacenan en un repositorio presentado en Delgado (2006), que ha sido enriquecido con los conceptos de casos y procedimientos de prueba, así como los mecanismos de recuperación que permiten recuperar los casos de prueba (CP) y los procedimientos de prueba (PP), asociados con los proyectos almacenados en la base de casos y que son semejantes al nuevo proyecto en el que se trata de generar los CP. Es importante precisar que esta propuesta es para generación en etapas tempranas, donde la información de entrada es requisito del nuevo proyecto.
Ha sido necesario introducir la asociación entre el requisito del proyecto y una descripción de los diferentes escenarios a considerar en su prueba funcional (descripción de prueba funcional, DPF). Esta descripción contiene el orden de las acciones involucradas en el desarrollo de la funcionalidad y que incluyen todos los escenarios posibles que deben ser considerados en la prueba funcional del requisito. La estructura interna de esta entidad ha sido tomada de la definición realizada por Delgado (2006).
Adicionalmente, la DPF es relacionada con cada uno de los PP diseñados para ejecutar su prueba funcional y éstos a su vez están referenciados por cada uno de los CP en los que se utilizan.
La estructura definida para almacenar los PP se muestra en la Tabla 2. Los PP son identificados en la base de proyectos por la combinación del par <verbo> <sustantivo> que definen su nombre.
El sustantivo que nombra el PP constituye la referencia a un marco o frame dentro de una jerarquía de frames en la que se expresan las relaciones entre las entidades de un dominio particular y que son utilizadas en esta propuesta para la recuperación de PP entre proyectos similares. La estructura del frame que modela una entidad particular es la que se muestra en la Tabla 1.

Los CP en su sección de entradas hacen además referencia al paso del PP en el que el probador del proyecto debe introducir los valores de los atributos y entidades correspondientes. El almacenamiento separado de PP y CP garantiza que el mismo PP pueda ser utilizado en varios CP. Como puede observarse, ambas estructuras están ligadas a la lógica funcional propia del requisito que se quiere probar, donde se combinan el orden de acciones a ejecutar descritas en el PP y determinadas por el verbo, con los valores propios del CP determinados por el o los sustantivos que definen las entidades y atributos referenciados en el CP y que están directamente relacionados con la jerarquía de frames.
Ahora bien, para poder reutilizar la información sobre los pasos u orden de ejecución de las acciones que están en el PP en nuevos proyectos, ha sido necesario definir un conjunto de patrones de PP (Patrón_PP) basados en las definiciones de patrones de Delgado (2006).
Cada patrón representa el conjunto de pasos que debe seguir el probador durante la ejecución de la prueba, para acciones específicas como por ejemplo "registrar", independientemente de si se desea probar la funcionalidad "registrar estudiante" o la funcionalidad "registrar profesor". Con esta definición, cada PP se relaciona con uno o varios Patrón_PP, lo que permitirá reutilizar ese Patrón_PP en la generación de nuevos PP en proyectos con características similares a los almacenados en la base de proyectos.

Los Patrón_PP forman parte de una red semántica en la que existen tres tipos de relaciones: "es un", "incluye a" y "se extiende de". Estos tipos de relaciones están determinadas por las relación existente entre los verbos que identifican cada uno de los Patrón_PP. En la Tabla 4 se describe el significado semántico de estas relaciones, considerando A y B dos Patrón_PP pertenecientes a la red semántica.

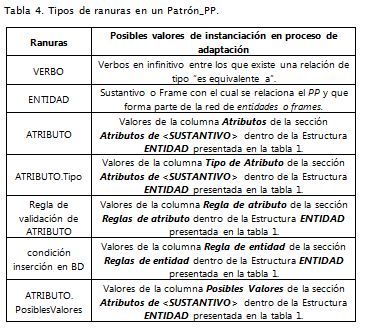
Hay un cuarto tipo de relación entre los verbos que expresa su equivalencia con la relación "es equivalente a", por ejemplo, entre los verbos "registrar" y "crear". Este tipo de relación se considerará asociando un único Patrón_PP al conjunto de verbos equivalentes.
El Patrón_PP contiene ranuras que podrán ser instanciadas en el momento de la adaptación de los PP de un problema particular. En la Tabla 4 aparecen los tipos de ranuras que pueden aparecer en un Patrón_PP y donde pueden ubicarse los valores para su instanciación durante el proceso de adaptación de PP.
Determinación de la semejanza entre proyectos
Para poder ejecutar la fase de recuperación del sistema de RBC, es decir, recuperar los proyectos (casos), es necesario antes analizar cuáles son los rasgos que distinguen a cada proyecto de software. En este caso se considera como rasgo predictor a cada requisito del proyecto, tal como se presenta en la propuesta realizada para revisiones a proyectos de software, en Delgado (2006).
La función de semejanza entre proyectos es
f(wi,δi(xi(O0),xi(OB)))=∑ni=lwiδi(xi(O0),Xi(OB))/∑ni=l wi donde wi es el nivel de importancia o significación de cada requisito dentro del nuevo problema. Esto permite dar mayor importancia, dentro del proyecto que se desea revisar, a los requisitos que el analista o inspector consideren como los más significativos. El valor por defecto de wi es 1.
δi(xi(O0),xi(OB))=fr((wk,δi(zi(xi(O0)),zi(xi(OB))))2k=l, es la función que evalúa la semejanza entre un par de requisitos y que es utilizada para combinar los valores de semejanza entre los verbos y los sustantivos para obtener el valor de semejanza entre dos requisitos.
fr((wk,δij(zk(yi),zk(yj)))2k=l)=∑k=l2wk.δij(zk(yi),zk(yj))
Para determinar la semejanza entre los sustantivos y los verbos se utilizó una red semántica en la cual se consideran dos tipos de relaciones: las relaciones jerárquicas ("es un", "es una instancia de") y las relaciones de equivalencia ("es equivalente a"). La función empleada en la determinación de la semejanza entre los verbos δij(z1(yi),z1(yj)) y entre los sustantivos δij(z2(yi),z2(yj)) es la presentada en Delgado (2006).
Los casos comparados con el nuevo problema se almacenarán en una lista lineal ordenada por valor descendente de la función f. Esta información será utilizada en la generación de la nueva solución.
Generación y adaptación de la nueva solución
Después de realizar la búsqueda se toma el caso o proyecto con valor mayor de f como potencial solución y se analiza si en este caso son cubiertos todos los requisitos que están presentes en el nuevo problema; de no ser así, se completa la solución potencial con los requisitos del segundo caso más parecido y así sucesivamente hasta completar los requisitos del nuevo problema o terminar de analizar el conjunto de casos recuperados.
Al asociar un requisito del nuevo proyecto xi(ON) con otro de un proyecto almacenado en la base de casos xj(ON) se puede asignar al requisito del nuevo problema el conjunto de CP y PP que es recuperado, pero antes es necesario valorar el nivel de semejanza entre ambos requisitos para valorar si pueden tomarse los CP y PP tal como aparecen en la base de casos, o es necesario hacer alguna adaptación. Si el valor de f es "1", pueden tomarse tal como están, porque es exactamente el mismo requisito, pero si no es el mismo se tienen dos casos que merecen un tratamiento diferenciado:
En el desarrollo de estos algoritmos se utilizan dos umbrales que permiten decidir cuándo un par de verbos y un par de sustantivos de requisitos pueden ser considerados semejantes, ellos son: μ1 y μ2 definidos para los verbos y sustantivos, respectivamente.



Los PP generados son utilizados para generar los CP correspondientes utilizando la información almacenada en la red de entidades y el conjunto de PPP que ya han sido generados. Los PP y CP obtenidos son puestos a consideración del usuario y éste puede hacer ajustes a la solución e incorporar nuevas consideraciones de acuerdo a la situación concreta que modela el proyecto, y esa nueva solución se almacenará en la base de ejemplos como un nuevo caso.
Conclusiones
Este trabajo hace una propuesta para la generación de procedimientos de pruebas funcionales, basada en el uso del razonamiento basado en casos para reutilizar información que haya sido generada con anterioridad. El aporte fundamental de la propuesta a juicio de sus autores está en el diseño de los algoritmos que permiten la recuperación y adaptación de procedimientos de prueba almacenados en la base de proyectos y que permite que se aproveche la experiencia anterior.
No obstante, la investigación no es una propuesta terminada, pues se trabaja en el desarrollo de las restantes fases del proyecto para llegar a ofrecer una solución que llegue hasta la priorización de qué casos de prueba ejecutar considerando restricciones de tiempo. En el momento en que se escribe este reporte se trabaja en la implementación de una herramienta que haga posible la experimentación en el ámbito docente como una primera prueba para comprobar los resultados que se pueden obtener con la propuesta.
Bibliografía
Althoff, K., Case-Based Reasoning. Handbook of Software Engineering and Knowledge Engineering., Kaiserslautern, Germany, Fraunhofer Institute for Experimental Software Engineering (IESE), 2001. [ Links ]
Augustine, S., Managing Agile Projects. Publicaciones Prentice Hall PTR, 2005. [ Links ]
Black, R., Pragmatic Software Testing-Becoming and Effective and Efficient Test Profesional., Publicaciones Wiley, 2007. [ Links ]
Delgado, M., Lorenzo, I., Carralero, J., Travieso, J., Rosete, A., Una propuesta de apoyo a las Revisiones de Proyectos de Software utilizando Razonamiento Basado en Casos., Revista Iberoamericana de Inteligencia Artificial, Vol. 10, No. 30, 2006, pp. 55-68. [ Links ]
Dias, A. C., Horta, G., Supporting the Selection of Model-based Testing., Approaches for Software Projects, AST '08: Proceedings of the 3rd international workshop on Automation of software test, ACM, mayo 2008. [ Links ]
Elbaum, S., Rothermel, G., Malishevsky, M., Selecting a Cost-Efective Test Case Prioritization Technique., Software Quality Journal, 2004 - Springer. [ Links ]
Everett, G. McLeod, R., Software Testing: Testing across the entire software development life cycle., John Wiley Edition, 2007. [ Links ]
Fraser, G., Wotawa, F., Test-Case Prioritization with Model-Checkers, 25th conference on IASTED International, 2007. [ Links ]
Ganesan, K., Khoshgoftaar, T., Allen, E., Case-Based Software Quality Prediction., International Journal of Software Engineering and Knowledge Engineering, Vol. 10, No. 2, 2000, pp. 139-152. [ Links ]
García, F., Corchado, J., Laguna, M., CBR Applied to Development with Reuse Based on mecanos., Proceedings of the 13th International Conference on Software Engineering and Knowledge Engineering, Buenos Aires, Argentina, 2001. [ Links ]
Gutiérrez, J., Generación automática de objetivos de prueba a partir de casos de uso mediante partición de categorías y variables operacionales., XVI Jornadas de Ingeniería del Software y Bases de Datos, JISBD07, España, 2007. [ Links ]
Guvenc, M., Writing Testable and Code-able Requirements., Quality Software and Testing, Volumen 4, 2006. [ Links ]
Heimdahl M., George D., Test-Suite Reduction for Model Based Tests: Effects on Test Quality and Implications for Testing., 19th IEEE International Conference on Automated Software Engineering (ASE'04), 2004, pp. 176-185. [ Links ]
Jacobson, I., Booch, G., Rumbaugh, J., El Proceso Unificado de desarrollo de Software., Vol. 1, Editorial Félix Varela, 2004. [ Links ]
Ko, A., Myers, B., Extracting and Answering Why and Why Not Questions about Java Program Output., ACM Transactions on Software Engineering and Methodology, Vol. 20, No. 2, Article 4, August 2010. [ Links ]
Last, M., The Uncertainty Principle of Cross-Validation., 2006 IEEE International Conference on Granular Computing, 2006. [ Links ]
Masood, A., Bhatti, R., Ghafoor, A., Mathur, A., Scalable and Effective Test Generation for Role-Based Access Control Systems., IEEE Transactions on Software Engineering, Vol. 35, No. 5, September/October 2009. [ Links ]
Meyer, B., XP and TDD: Extreme Programing and Test-Driven Development., Chair of Software Engineering, Zurich, 2006. [ Links ]
Mogyorodi, E., Requirements-Based Testing: Ambiguity Reviews., Testing Experience: The Magazine for Professional Testers, 2008. [ Links ]
Myers, G. J., The Art of Software Testing., 2da Edición, Editorial John Wiley, 2004. [ Links ]
Naslavsky, L., Ziv, H., Richardson, D., Using Model Transformation to Support Model-BasedTest Coverage Measurement., AST '08: Proceedings of the 3rd international workshop on Automation of software test, ACM, mayo 2008. [ Links ]
Polo, M., Priorización de casos de prueba mediante mutación., Taller sobre Pruebas de Ingeniería del Software, PRIS 2007. Vol. 1, No. 4. [ Links ]
Pressman, R., Ingeniería del Software: un enfoque práctico., Vol. 1, Editorial Félix Varela, 5ta edición, 2005. [ Links ]
Shepperd, M., Case-based Reasoning and Software Engineering., Empirical Software Engineering Research Group, Universidad de Bournemouth, UK, 2003. [ Links ]
Singh, D., Misra, A. K., Software Test Effort Estimation, ACM SIGSOFT Software Engineering Notes, Vol. 33, No. 3, May 2008. [ Links ]
Xie, Q., Memon, A., Designing and Comparing Automated Test Oracles for GUI-Based Software Applications., ACM Transactions Software Engineering and Methodology, Vol. 16, No. 1, Article 4, Febrary 2007. [ Links ]

