










Serviços Personalizados
Journal
Artigo
 texto em
texto em  Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkIngeniería e Investigación
versão impressa ISSN 0120-5609
Ing. Investig. v.31 n.1 Bogotá jan./abr. 2011
Operators for reclassification queries in a temporal multidimensional model
Francisco Moreno1, Fernando Arango2
1 Systems Engineer. Ph.D. Engineering, Universidad Nacional de Colombia, venue Medellín. fjmoreno@unal.edu.co
2 B.Sc. Civil Engineering. M.Sc and Ph.D., Universidad Nacional de Colombia, venue Medellín. farango@unal.edu.co
ABSTRACT
Data warehouse dimensions are usually considered to be static because their schema and data tend not to change; however, both dimension schema and dimension data can change. This paper focuses on a type of dimension data change called reclassification which occurs when a member of a certain level becomes a member of a higher level in the same dimension, e.g. when a product changes category (it is reclassified). This type of change gives rise to the notion of classification period and to a type of query that can be useful for decision-support. For example, What were total chess-set sales during first classification period in Toy category? A set of operators has been proposed to facilitate formulating this type of query and it is shown how to incorporate them in SQL, a familiar database developer language. Our operators' expressivity is also shown because formulating such queries without using these operators usually leads to complex and nonintuitive solutions.
Keywords: temporal data warehouse, OLAP, reclassification, classification period.
Received: Feuary 01th 2010. Accepted: Feuary 7th 2011
Introduction
Data warehouses (DW) (Kumar, 2008; Golfarelli, 2009a) have proved their usefulness in integrating information systems and supporting decision-making during recent years. DWs are usually modelled using a multidimensional view of data. A multidimensional model has a set of dimensions associated with a subject of interest for an organisation called fact. A dimension is composed of levels structured as a hierarchy according to analysis needs (Torlone, 2003). For example, in a time dimension with day, month, and year levels, days are grouped into months and months into years; whereas in a product dimension having product and category levels, products are grouped into categories.
A fact usually includes measures, namely, indicators allowing one to evaluate an organisation's specific activities (Malinowski, 2008). Measures can be aggregated throughout dimension levels, allowing information from different granularity levels to be analysed. For example, consider a fact sale, having a total sold measure associated with time and product dimensions. This way of organising data facilitates formulating queries such as, "What was the total daily, monthly or annual sale of a certain product?
Usually, dimensions are considered static in DW while facts are considered dynamic because new facts are periodically added to DW. However, dimension schema and dimension data can also change (Golfarelli, 2009b). This paper focuses on a type of dimension data change called reclassification and on a type of query arising from such changes. Reclassification occurs when a member of a certain level changes its parent (a member of a higher level from the same dimension), e.g. when a product classified as a toy is reclassified as being educational.
Reclassification is common in several domains: a product changes category, a salesperson shifts position in a store, a store or a customer changes status, a player changes team, a hurricane moves from one region to another. In product reclassification, it is possible for a product to undergo several reclassifications during its lifespan. For example, a chess set can be classified as a toy during period Per1, then be classified as educational during period Per2, and again be reclassified as a toy. This succession of reclassifications may give rise to queries such as, "What was the total sale of chess sets during the first period when it was classified as a toy?" "What was the total sale of chess sets during the three first periods when it was classified as educational?" "What was the classification period when total chess sets sold has been the highest and which category were they in?" "Are sales of a product better in periods when classified as educational compared to periods when classified as a toy?"
The answers to the previous queries can help identify suitable periods for reclassifying products to increase their sales. In other domains, analogous queries can help adjust personnel shifting policies, evaluate players' performance as they shift through teams, evaluate the impact of cyclical natural phenomena as well as policies designed to minimise their damage, e.g. "Did the area of destroyed crops decrease the second time El Niño affected Peru?" A set of operators is proposed in this paper for facilitating the formulation of this type of query.
Related work
Although several multidimensional query languages have been proposed (Cabibbo, 1997; Datta, 1999; Pedersen 2001; Jensen,
2004; Whitehorn, 2005), they lack elements considering the dynamic aspect of dimensions. However, some studies have considered this aspect. Hurtado (1999) and Blaschka (1999) have proposed operators for deleting, inserting and updating dimension schema and dimension data. Kaas (2004) has proposed operators for changing DW schema, including operators for inserting and deleting dimensions and levels. Other authors (Eder, 2001; Body, 2002; Morzy, 2004; Golfarelli, 2006; Ravat, 2006; Rechy-Ramirez, 2006; Wrembel, 2007) have focused on DW versioning, i.e. how to transform and/or query data covering several DW versions arising from dimension changes. A recent survey on DWs considering temporal aspects can be found in Golfarelli (2009b).
A few works have specifically dealt with reclassification. Chamoni (1999), Pedersen (2001) and Malinowski (2008) have used intervals to record them. However, they have not proposed operators facilitating the formulation of queries like those outlined in section 1. On the other hand, a multidimensional model supporting changes in dimension schema and dimension data is proposed in (Mendelzon, 2000) and (Vaisman, 2004). They have also proposed a query language called TOLAP. A query such as, "What was the total sale of chess sets when classified as a toy?" can be formulated in TOLAP; however, this language is not orientated towards solving queries such as those outlined in section 1. Moreno (2009a) informally identified this type of query and Moreno (2010) proposed an operator that can be considered a first approach to solving some of these queries. A different and more complete approach is followed here; such new approach can easily be incorporated into SQL.
Temporal multidimensional model
The multidimensional model presented here was based on work
by Moreno (2009b), in turn based on work by Mendelzon
(2000). 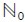 represented the set of natural numbers including zero and
represented the set of natural numbers including zero and 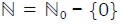 .
.
Dimensions
A dimension schema was a 5-tuple (DNAME, ND, 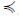 , All,⊥) where: i) DNAME was the name of the dimension schema, ii)
ND was a set of levels. Each level n ε ND was associated with a set of members (level values), i.e. a domain denoted by dom(n). A member could include attributes (Golfarelli, 2009b) providing supplementary information about a level, iii) was a partial order in set ND. n1, n2 ε ND, n1 n2 meant that n1 rolled up to n2 (n1 was grouped into n2). ' was denoted as the transitive reduction of , iv) All ε ND was the top level of partial order . εn ε ND, All; dom(All) = {all}, and v) ⊥ ε ND was the bottom level of partial order . εn ε ND,⊥ n.
, All,⊥) where: i) DNAME was the name of the dimension schema, ii)
ND was a set of levels. Each level n ε ND was associated with a set of members (level values), i.e. a domain denoted by dom(n). A member could include attributes (Golfarelli, 2009b) providing supplementary information about a level, iii) was a partial order in set ND. n1, n2 ε ND, n1 n2 meant that n1 rolled up to n2 (n1 was grouped into n2). ' was denoted as the transitive reduction of , iv) All ε ND was the top level of partial order . εn ε ND, All; dom(All) = {all}, and v) ⊥ ε ND was the bottom level of partial order . εn ε ND,⊥ n.
Example 1. Consider dimension schema (PRODUCT, {Product, Category, All}, , All, Product), where ' = {(Product, Category), (Category, All)}. A member of level Product could include attributes such as name, price and description
Adding time to dimensions
Time was represented as discrete: a point on a timeline corresponding to a positive integer. A positive integer represented an instance of a temporal unit, e.g. an hour, day or a month. For clarity, 'day 1' (or a value such as 'January 1 2011') has been written instead of just 1. In addition, x, y, z ε  , [x, z] represented an interval corresponding to a set of positive integers: x <= y <= z. Functions Start(I) and End(I) returned the first and the last positive integer of interval I, respectively.
, [x, z] represented an interval corresponding to a set of positive integers: x <= y <= z. Functions Start(I) and End(I) returned the first and the last positive integer of interval I, respectively.
There was a finer than relationship among temporal units. For example, a day is included in a specific month; thus temporal unit day is finer than temporal unit month. On the other hand, week is not finer than month, and month is not finer than week. μ1 and μ2 were temporal units, if μ1 was finer than μ2, then this would be written as μ1 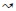 μ2.
μ2.
Time was incorporated into other dimensions (other than the TIME dimension) in two ways. The first was by adding an interval to each member of a level to record its timespan in the DW. The second way was by adding an interval between two members to record their corresponding association (classification) periods.
Consider a dimension schema (DNAME, ND, , All, &⊥). A pair of levels (n1, n2) ε , n2 ≠ All, could be associated with temporal
unit μ defining temporal reclassification granularity (TRG)
between n1 and n2. The pair (n1, n2) would then be said to be temporal.
Example 2. Consider Example 1. A product is classified in a category during a period of days. Therefore, TRG μ = Day would be associated with the pair (Product, Category) to record associations between products and categories on a daily basis.
A dimension schema instance was a 2-tuple (D, FR) where D was dimension schema and FR a set of rollup functions. ND was the set of levels of D; n1, n2 ε ND, and partial order in the set ND then: i) for each temporal pair (n1, n2) ε ' with TRG μ, there would be rollup function RUP_n1_n2: dom(n1) x dom(μ) ε dom (n2) and ii) for each non-temporal pair (n1, n2) ε ', there would be rollup function RUP_n1_n2: dom(n1)εdom(n2). Note that RUP_n1_n2 wass a metaname: n1 and n2 referred to level names.
Example 3. Consider the dimension schema given in Example 2
and domains: dom(Category) = {Toy, Educational}, dom
(Product) = {Prod1, Prod2}, dom(All) = {all}, and dom(Day) = 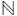 . The rollup functions between the members of levels in ' of
ND are shown in Table 1. For example, RUP_Product_Category(Prod1, day 1) = Toy.
. The rollup functions between the members of levels in ' of
ND are shown in Table 1. For example, RUP_Product_Category(Prod1, day 1) = Toy.
Facts
A fact schema was a 3-tuple (FNAME, FL, M) where: i) FNAME was the name of the fact schema, ii) FL = {n1, ..., nk} was a set of levels. Each level ni ε FL was the bottom level () in a dimension schema, and iii) M = {m1, ..., mm} was a set of measures. Each measure mi was associated with a domain dom(mi).
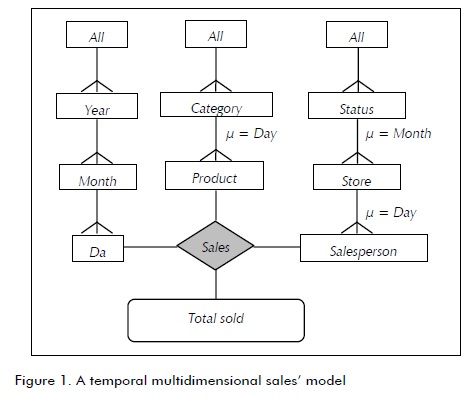
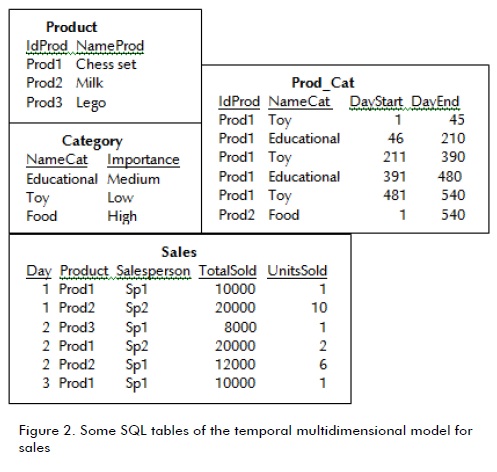
Example 4. Consider the fact schema (SALES, {Product, Salesperson, Day}, {TotalSold, UnitsSold}), see Figure 1. Malinowski's notation (2008) was used for representing the conceptual model, which was based on entity-relationship model notations. TRG representation was included (Moreno, 2009b).
A fact instance of a fact schema (FNAME, FL, M), FL = {n1, ..., nk} and M = {m1, ..., mm}, was a 2-tuple (fl, m) where fl = {member(n1), ..., member(nk)} was a set of members and m = {value(m1), ..., value(mm)} was a set of values from measures. Each member(ni)ε dom(ni) was a member of a bottom level (⊥) in a dimension schema instance. Each value(mi)ε dom(mi) was a value for measure mi. A fact table was a set of fact instances.
Example 5. Consider domains: dom(Product) = {Prod1, Prod2}, dom(Salesperson) = {Sp1, Sp2}, and dom(Day) = . A fact table Sales for the fact schema SALES in Example 4 was {({Prod1, Sp1, day 1}, {1000, 2}), ({Prod1, Sp2, day 1}, {1500, 3}), ({Prod2, Sp1, day 2}, {2000, 4}), ({Prod2, Sp2, day 2}, {500, 1})}.
Classification period
Informally, a classification period (CP) is an interval during which a member of a level is associated with a member of a higher level, e.g. a CP for a product in a category, a CP for a salesperson in a store, a CP for a store regarding its status. A formal definition of a CP is presented between member a of level n1 and member b from higher level nk of n1. n1, n2, n3, ..., nk were levels of a dimension schema, k > 1, where n1 ' n2 ' n3 ... ' nk. U≠ Ø were the set of TRGs along path n1 ' n2 ' n3 ... ' nk, a ε dom(n1) and b ε dom(nk). A CP of a in b was an interval I with
temporal granularity μ', where: i) εμ ε U, μ' μ, ii) εt ε I, RUP_n1_nk(a, t) = b, iii) if RUP_n1_nk(a, Start(I) - 1) was defined then RUP_n1_nk(a, Start(I) - 1) ≠ b and iv) if RUP_n1_nk(a, End(I) + 1) was defined then RUP_n1_nk(a, End(I) + 1) ≠ b.
Note that conditions iii) and iv) guaranteed that I was a maximum interval during which a was associated with b. If U = Ø then during its lifespan in the DW a was always associated with b; therefore, I was considered as the unique CP of a in b, where Start(I) and End(I) corresponded to the lifespan of a in the DW.
Example 6. Consider again Example 4. The corresponding rollup values (categories) to Prod1 are shown in Table 2.
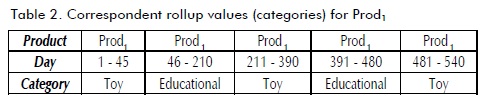
Table 2 shows that [day 1, day 45], [day 211, day 390] and [day 481, day 540] were CPs of Prod1 in Toy category. Now, considering the ordering of CPs between two members and defining the nth CP concept. I would be a CP of a in b. I was the first CP of a in b if there were no CP I' of a in b so that End(I') < Start(I). I was the second CP of a in b, if there were only CP I' of a in b so that End(I') < Start(I). In general,  = {l1, l2, ..., ln} would be a set of CPs of a in b; therefore, li ε would be the nth CP of a in b, where
= {l1, l2, ..., ln} would be a set of CPs of a in b; therefore, li ε would be the nth CP of a in b, where 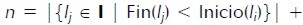
 . This number has been called CP number. For instance, in Example 6 [day 1, day 45] was the first CP of Prod1 in Toy category, [day 211, day 390] was the second one, and [day 481, day 540] was the third one.
. This number has been called CP number. For instance, in Example 6 [day 1, day 45] was the first CP of Prod1 in Toy category, [day 211, day 390] was the second one, and [day 481, day 540] was the third one.
Query operators for CPs
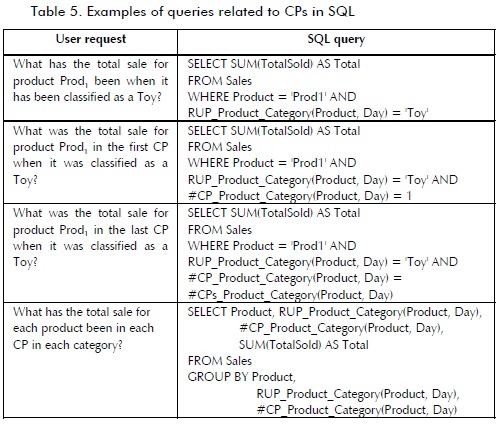
Consider again Example 6. The rollup operation RUP_Product_ Category (Prod1, day 1) returned the category (Toy) of Prod1 in day 1. However, this operation did not return the corresponding interval of Prod1 in Toy category or the CP number. A set of query operators for CPs has thus been proposed for obtaining such data. Operators must be based on real users' requests, such as those described in Section 1 and Table 3.
n1, n2, n3, ..., nk were levels for a dimension schema, k > 1, where n1 ' n2 ' n3 ... ' nk.U ≠ Ø was the set of TRGs along path n1 ' n2 ' n3 ... ' nk; and μ' was an arbitrary temporal unit, where "μ Î U, μ' μ. Table 4 presents our query operators for CPs. If U = Ø, i.e. all pairs along path n1 ' n2 ' n3 ... ' nk were non-temporal, then #CP_n1_nk and #CPs_n1_nk returned 1, and ICP_n1_nk returned an interval I with temporal granularity μ', where Start(I) and End(I) corresponded to the lifespan of a in the DW, where a was a member of the domain of n1.
Incorporating query operators for CPs in SQL
Here we show how to incorporate our query operators for CPs into SQL which is a familiar language for database developers. Another alternative is MDX (Whitehorn, 2005), a multidimensional query language (non-temporal). Figure 2 shows some SQL tables corresponding to the schema shown in Figure 1. Table Prod_Cat represents a temporal relationship between Product and Category. Table 5 presents some queries related to CPs. an SQL solution is now presented (without using our proposed operators) for the last query in Table 5. First, the CPs for each product in each category are enumerated:
CREATE VIEW CPs AS SELECT IdProd, NameCat, ROW_NUMBER() OVER (PARTITION BY IdProd, NameCat ORDER BY Day-Start) AS NrCP, DayStart, DayEnd FROM Prod_Cat;
Now we found the total sold of each product in each CP:
SELECT IdProd, NameCat, NrCP, SUM(TotalSold) AS Total FROM CPs, Sales
WHERE IdProd = Product AND Day BETWEEN DayStart AND DayEnd
GROUP BY IdProd, NameCat, NrCP;
Note that although the analytic function ROW_NUMBER facilitated formulating this query, the corresponding expression in Table 5 is simpler and more intuitive. On the other hand, simulating a query that includes CP operators between two nonadjacent levels (e.g., salesperson and status) is much more complex and longer. This has not been shown due to space limitations.
Conclusions and future work
The concept of classification period was introduced due to reclassifications which may occur amongst dimension level members. This concept gives rise to a type of query which can help in decision-making in several domains such as sales, sports, human resources and natural phenomena.
A set of operators has been proposed to facilitate formulating CP queries and it has been shown how these operators can be incorporated into a language such as SQL. The encoding effort required to simulate our operators in SQL has also been shown, thus demonstrating its expressiveness.
The following work is planned. Extending our operators to the field of spatial DWs, so that queries may be formulated such as, "What was the total sold by a salesperson in his/her two first CPs when he/she was associated with the stores contained in a particular region?" Allowing overlapping CPs, e.g. a product could be associated with several categories simultaneously. It is also planned splitting a CP, e.g. suppose a manager is re-elected in a department. Instead of defining a unique CP for the manager in that department, two CPs could be defined: one corresponding to his first term and another to his/her second term. Performance in each term could thus be assessed.
References
Blaschka, M., Sapia, C., Höfling, G., On schema evolution in multidimensional databases., 1st DaWaK, Florencia, Italia, 1999, pp. 153 - 164. [ Links ]
Body, M., Miquel, M., Bèdard, Y., Tchounikine, A., A multidimensional and multiversion structure for OLAP applications., 5th DOLAP, McLean, USA, 2002, pp. 1 - 6. [ Links ]
Cabibbo, L., Torlone, R., Querying multidimensional databases., 6th DBPL-6, Estes Park, USA, 1997, pp. 319-335. [ Links ]
Golfarelli, M., Lechtenbörger, J., Rizzi, S., Vossen, G., Schema Versioning in Data Warehouses., Data and Knowledge Engineering, Vol. 59, No. 2, 2006, pp. 435-459. [ Links ]
Golfarelli, M., Rizzi, S., Data Warehouse Design: Modern principles and methodologies., 1st Edn., McGraw-Hill Osborne Media, New York, 2009a. [ Links ]
Golfarelli, M., Rizzi, S., A Survey on Temporal Data Warehousing.,Int. Journal of Data Warehousing and Mining, Vol. 5, No. 1, 2009b, pp. 1-17. [ Links ]
Hurtado, C. A., Mendelzon, A. O., Vaisman, A. A., Updating OLAP dimensions., ACM 2nd DOLAP, Kansas City, USA, 1999, pp. 60 -66. [ Links ]
Jensen, C. S., Kligys, A., Pedersen, T. B., Timko, I., Multidimensional Data Modeling for Location-based Services., VLDB Journal, Vol. 13, No. 1, 2004, pp. 1-21. [ Links ]
Kaas, C., Pedersen, T. B., Rasmussen, B., Schema evolution for stars and snowflakes., 6th ICEIS, Porto, Portugal, 2004, pp. 425-433. [ Links ]
Kumar, N., Gangopadhyay, A., Bapna, S., Karabatis, G., Chen, Z. Measuring interestingness of discovered skewed patterns in data cubes., Decision Support Systems, Vol. 46, No. 1, 2008, pp. 429-439. [ Links ]
Malinowski, E., Zimányi, E., Advanced data warehouse design: from conventional to spatial and temporal applications., Nueva York, Springer, 2008. [ Links ]
Mendelzon, A. O., Vaisman, A. A., Temporal queries in OLAP., 26th VLDB., El Cairo, Egipto, 2000, pp. 242-253. [ Links ]
Moreno, F., Arango, F., Fileto, R., Season Queries on a Temporal Multidimensional Model., 11th IM2 (presentación oral corta), Valencia, España, 2009a. [ Links ]
Moreno, F., Arango, F., Fileto, R., A multigranular temporal multidimensional model., 32nd Mipro, Opatija, Croacia, 2009b, pp. 206-210. [ Links ]
Morzy, T., Wrembel, R., On querying versions of multiversion data warehouse., ACM 7th DOLAP, Washington D.C., USA, 2004, pp. 92-101. [ Links ]
Pedersen, T. B., Jensen, C. S., Dyreson, C. E., A Foundation for Capturing and Querying Complex Multidimensional Data., Information Systems, Vol. 26, No. 5, 2001, pp. 383-423. [ Links ]
Ravat, F., Teste, O., Supporting Data Changes in Multidimensional Data Warehouses., Int. Review on Computers and Software, Vol.1, No. 3, 2006, pp. 251-259. [ Links ]
Rechy-Ramirez, E., Benitez-Guerrero, E., A model and language for bitemporal schema versioning in data warehouses., 15th CIC, Ciudad de Mexico, Mexico, 2006, pp. 309-314. [ Links ]
Torlone, R., Conceptual Multidimensional Models., Multidimensional Databases: Problems and Solutions., M. Rafanelli (ed.), Nueva York, Idea Group, 2003, pp. 69 - 90. [ Links ]
Vaisman, A. A., Mendelzon, A. O., Ruaro, W., Cymerman, S. G., Supporting Dimension Updates in an OLAP Server, Information Systems, Vol. 29, No. 2, 2004, pp. 165-185. [ Links ]
Whitehorn, M., Zare, R., Pasumansky, M., Fast Track to MDX, Nueva York, Springer, 2005. [ Links ]
Wrembel, R., Bebel, B., Metadata Management in a Multiversion Data Warehouse., Journal of Data Semantics, Vol. 8, No. 1, 2007, pp. 118-157. [ Links ]


{kind=link}
{kind=link}