










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería e Investigación
Print version ISSN 0120-5609
Ing. Investig. vol.34 no.1 Bogotá Jan./Apr. 2014
https://doi.org/10.15446/ing.investig.v34n1.42790
http://dx.doi.org/10.15446/ing.investig.v34n1.42790
CodeRAnts: A recommendation method based on collaborative searching and ant colonies, applied to reusing of open source code
Coderants: método de recomendación basado en la búsqueda colaborativa y las colonias de hormigas. Aplicado a la reutilización del código fuente abierto
I. Caicedo-Castro1 and H. Duarte-Amaya2
1Isaac Caicedo. BSc in Computer Science Engineering, Pontificia Universidad Bolivariana, Colombia. MSc in Engineering, University of Los Andes, Colombia. Dr. Eng. (c), Universidad National de Colombia, Colombia. Affiliation: Full time professor, University of Córdoba, Colombia.
E-mail: ibcaicedoc@unal.edu.co
2Helga Duarte. BSc in Systems and Computing Engineering, Universidad National de Colombia, Colombia. MSc in Engineering, Universidad National de Colombia, Colombia. PhD in Computer Sciences, Joseph Fourier University, Grenoble I, France. Affiliattion: Full time professor, Universidad National de Colombia, Colombia.
E-mail: hduarte@unal.edu.co
How to cite: Caicedo, I., Duarte, H., CodeRAnts: A recommendation method based on collaborative searching and ant colonies, applied to reusing of open source code., Ingeniería e Investigación, Vol. 34, No. 1, April, 2014, pp. 72 – 78.
ABSTRACT
This paper presents CodeRAnts, a new recommendation method based on a collaborative searching technique and inspired on the ant colony metaphor. This method aims to fill the gap in the current state of the matter regarding recommender systems for software reuse, for which prior works present two problems. The first is that, recommender systems based on these works cannot learn from the collaboration of programmers and second, outcomes of assessments carried out on these systems present low precision measures and recall and in some of these systems, these metrics have not been evaluated. The work presented in this paper contributes a recommendation method, which solves these problems.
Keywords: Recommender Systems on Software Engineering, recommendation method based on collaborative searching, software reuse, open source software, ant colony.
RESUMEN
Este artículo presenta CodeRAnts: un nuevo método de recomendación basado en la técnica de búsqueda colaborativa e inspirada en la metáfora de la colonia de hormigas. Este método es propuesto con el objetivo de llenar el vacío en el estado del arte en cuanto a los sistemas de recomendación diseñados para reutilizar software, cuyos trabajos previos presentan dos problemas. El primero, es que los sistemas de recomendación basados en esos trabajos no pueden aprender de la colaboración de los programadores, y segundo, que los resultados de las pruebas realizados sobre estos sistemas presentan medidas bajas de precisión y remembranza, incluso, en algunos de estos sistemas no se hizo una evaluación de estas métricas. La contribución de este trabajo es un método de recomendación que resuelva dichos problemas.
Palabras clave: Sistemas de recomendación para ingeniería de software, método de recomendación basado en la búsqueda colaborativa, reutilización de software, software de fuente abierta y colonia de hormigas.
Received: April 28th 2013 Accepted: December 4th 2013
Introduction
This paper presents the concepts and design taken into account in CodeRAnts, which is a new recommendation method proposed to assist software engineers and computer programmers in the reuse of source code by allowing them to retrieve useful snippets of code (potentially written in any programming language) for the implementation of new software products. CodeRAnts is based on two approaches. The first is collaborative searching, which takes advantage of the similarity and repetition of queries that have been used by programmers, who are the stakeholders in the search for snippets of code. The second is the ant colony metaphor. We consider this approach to tackle two issues. First, it pretends to solve the cold start problem; for example, a system that implements CodeRAnts can suggest snippets of code, even as it receives new queries. Secondly, it initiates the use of system of recommendations, the structure used to save the queries will have little information; therefore, it is necessary to solve the problem related with the data sparsity of the query-ranking matrix, which is used in collaborative searching.
The preliminary evaluation carried out in this work shows better values for the metrics of precision and recall than those achieved in the state of the art. These metrics are the most commonly used to evaluate recommender systems (Basu et al., 1998; Billsus and Pazzani, 1998; Sarwar et al., 2000a,b; Picault et al., 2010; Bedi and Sharma, 2012). In mathematical terms, precision (see expression 1) is the number of retrieved and relevant items, divided by the total number of retrieved items. On the other hand, recall (see expression 2) is the number of retrieved relevant items, divided by the total number of relevant items.

Motivation
According to Ricci et al. (2010), a recommender system is a set of software tools and techniques which provide suggestions of worthy items for users. These suggestions are related to several decision-making processes that are difficult when users have a large amount of optional items to choose from. In the e-commerce context, these processes are related to the buying of items such as books. Amazon's recommender system, for example, assists its users in finding books that meet their needs.
The open source software engineering context is similar to that used by ecommerce. Today, there is a substantial amount of open source code available on the World Wide Web, which is stored inside repositories and available through search engines (e.g., Koders, Krugle Sourceforge, Google code, GitHub, and CodePlex). This source code belongs to world class software products (e.g., Linux operating system kernel, JBoss application server, GNU Emacs, etc). This plethora of source code is available to be reused. In fact, software reuse is acknowledged as an important activity because it allows programmers to use preexisting core assets or artifacts rather than creating them from scratch. Indeed, Raymond (1999, p. 4) highlights the importance of software reuse: "Good programmers know what to write. Great ones know what to rewrite (and reuse)".
Moreover, computer scientists such as Mcilroy (1968), Standish (1984), Brooks (1987), Poulin et al. (1993), Boehm (1999), and Pohl and Böckle (2005), have highlighted the following advantages of reusing software: i) reducing time and costs, ii) improving the quality of software, iii) reducing amount of defects and iv) by reusing code there is a higher chance of detecting failures and fixing them.
Search engines allow programmers to find useful source code; however, some problems still remain: i) the probability that two people choose the same word to describe a concept is less than 20% (Furnas et al., 1987; Harman, 1995), ii) users who consider search engines useful for finding code are those who know how to employ the search (Bajracharya and Lopes, 2010), iii) in a study by Coyle and Smyth (2007) more than 20,000 queries were used: its results showed that, on average, Google delivered at least one useful result only 48% of the time, iv) in the domain of collaborative-based recommender systems, research indicates that the design problems of search engines are twofold: solitary nature and one-size-fits-all. (Resnick and Varian, 1997; Balabanovic and Shoham, 1997; Schafer et al., 1999; Jameson and Smyth, 2007; Smyth, 2007; Morris, 2008).
On the one hand, solitary nature means that searches take the form of an isolated interaction among the user and the search engine. Due to this drawback, search engines overlook the experience of users, which is useful for offering a more accurate result list in comparison to the others with similar preferences. On the other hand, one-size-fits-all means that several users achieve the same result list when they use the same query in spite of having different preferences.
The same researchers highlight the importance of recommender systems technology, in particular, the concepts of collaboration and user preferences, in order to cope with the above mentioned search engine design problems. Preference is information about users' needs and the collaboration concept refers to preferences supplied by a group (or community) of users. The solution proposed, consists of influencing recommendations with information learned from users' preferences and their collaboration, thereby, suggestions are guided by users' behavior rather than only the items' features.
For instance, if a user performs the following query: "I need some-thing with four legs where I can sit down". The search engine's answer is a result list with items like: horses, tigers, chairs and tables. These objects match the user's query. A search engine replies regardless of the user's preferences and the collaboration of similar users. Even though the user selects the chair, the search engine is not able to learn the preference of the active user, and hence, the engine cannot change the relevance level of the chair for future users with the same preference. Conversely, a recommender system suggests items based on what it has learned from the users' preferences and collaboration. In this case, the suggestion of the recommender system is to use a chair. This illustrative example depicts the advantages of recommendation techniques based on collaboration, which motivated the design of CodeRAnts.
Related Work
In the context of software engineering, Robillard et al. (2010) define recommender systems as a set of software applications that provide information items, which are considered valuable to perform software engineering tasks, e.g., reusing artifacts, maintenance of software products and the identification of defects and bugs.
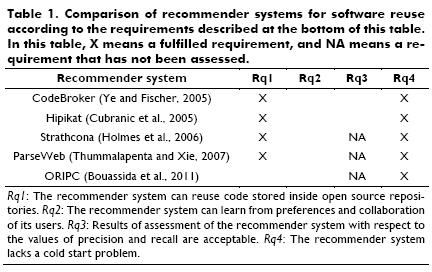
Various recommender systems have been created to assist software tasks, e.g., eRose (Zimmermann et al., 2005), Suade (Robillard et al. 2008), Dhruv (Ankolekar et al., 2006), and Expertise Browser (Mockus and Herbsleb, 2002). However, in the particular context of software reuse, several recommender systems have been made: CodeBroker (Ye and Fischer, 2005), Hipikat (Cubranic et al., 2005), Strathcona (Holmes et al., 2006), ParseWeb (Thummalapenta and Xie, 2007), and ORIPC (Outil de Recommandation et Instanciation des Patrons de Conception) (Bouassida et al., 2011).
All prior recommender systems for software reuse have presented two important drawbacks, which represent the gap in the state of the art: i) These recommender systems are not able to learn from users' preferences and their collaboration. Therefore, these systems cannot learn to identify items which were considered useful by users in past, hence, these systems will not suggest them in the future. Consequently, these recommender systems have the same problems as search engines that are mentioned above, i.e., solitary nature and onesize-fits-all. ii) Only in Hipikat and CodeBroker were precision and recall measures were evaluated and these indicators are still far from being satisfactory. It is possible that in the other systems, these metrics were not assessed because a dataset with information about programmers retrieving source code did not exist, as in the case of other kinds of systems based on collaborative filtering, which are assessed with classical datasets such as Jester (http://www.ieor.berkely.edu/~goldberg/jester-data) and MovieLens (http://www.grouplens.org/node/73).
Table 1 presents a summary of the literature review on recommender systems for software reuse. In this table, the third requirement (Rq3) is missing because these systems lack of the second one (Rq2), due to a recommender system, which cannot learn from preferences and collaboration of its users, shares the design problems of search engines (onesize-fits-all and solitary nature). The contribution of this work is a recommendation technique designed to fulfill all requirements described in this table.
Design of CodeRAnts
CodeRAnts is designed to be implemented in a recommender system with a proxy architecture, where this system is the proxy of a code search engine (e.g., Koders). Fig. 1 depicts a recommender system that implements the CodeRAnts method and this system may be plugged to a search engine (or other recommendation system like Strathcona). The explanation of its operation is as follows: 1) The proxy agent receives the query, q, which comes from user agent, 2) the proxy agent redirects 𝑞 to code search engine, 3) the code search engine retrieves a result list, α, with links to code that could be useful for the user, 4) the proxy agent sends forward α to recommender systems 5) recommender systems compute a new result list, R, in accordance with the recommendation technique described below (CodeRAnts), and sends R to the user agent.
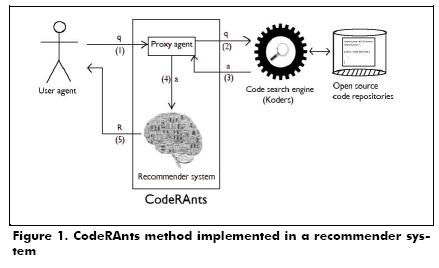
CodeRAnts method
Similar to Collaborative Searching (Smyth et al., 2010), the design goal of CodeRAnts is to take advantage of similarity and repetition of queries performed by programmer communities as a source of recommendations.
Nevertheless, the collaborative searching approach has similar research challenges to that of collaborative filtering, i.e., data sparsity of the input-ranking matrix and cold start problem for queries recently used. Therefore, in order to address these drawbacks, we have taken into account the ant colony metaphor, which was successfully used by Bedi and Sharma (2010) to overcome these problems in the context of collaborative filtering, achieving good values of precision and recall through off-line assessment.
Algorithms based on this metaphor are those that reproduce the behavior of real ants in order to build better solutions, by using artificial pheromones as a means of communication among ants, which tend to lay pheromone trails while walking from their nests to the food source and vice versa.
Ants do not communicate directly with each other. These insects are guided by pheromone smell and hence, ants choose paths marked by the highest concentration of pheromones. The indirect communication among ants through pheromone trails enables them to find a shorter path between their nest and food sources.
The CodeRAnts method consists of creating a directed graph, whose vertexes represent queries performed in the past and the weight edge is based on textual similarity, the correlation, and the confidence between vertexes.
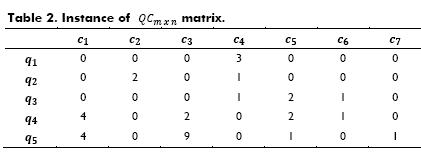
Let Q={q1,q2,...,qm} be a set of queries performed by programmers in the past and C={c1,c2,...,cn}, a set of snippets of code. In the same way that the collaborative searching method proposed by Smyth et al. (2010), computes the matrix, the CodeRAnts method also computes the matrix QCmxn, such that QCi,j, corresponds to the amount of times that the snippet of code 𝑐𝑗 was retrieved when the query cj was used by a programmer in the past.
Similar to the technique proposed by of Bedi and Sharma (2012), the CodeRAnts method is structured in two processes. The first is performed off-line; it consists of creating the directed graph, which shall be used as a set of paths with pheromone trails for ants. The second is on-line and it is designed to generate recom-mendations through ant movement in order to find the goal, namely, to collect a ranking for each snippet of source code.
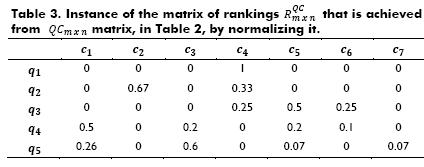
The off-line process is described in the following two steps: i) the matrix of rankings 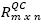 is initialized by normalizing the
is initialized by normalizing the 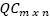 matrix:
matrix: 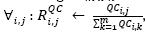 where
where 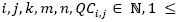
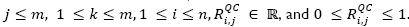 .
.
For the purpose of illustrating this step, let us consider the matrix depicted in Table 2, where q1= comprimir, q2=compac, q3 =compress, q4=, zip and q3=conpresser,. Table 3 shows the normalized matrix, namely, 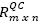 .
.
ii) the directed graph G=(V,E) is created; let V be a set of ver-texes and let E be a set of edges. The vertexes represent queries performed by programmers in the past, hence, V=Q. On the other hand, edges are links between queries. Each edge represents a path where ants have laid pheromone trails at certain time t; therefore, edge weigh is the level of pheromone track at time t, that is denoted by queries 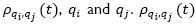 is computed based on similarities and confidence among vertexes. If the level of pheromone among two vertexes is equal to zero, then there is no edge between both vertexes.
is computed based on similarities and confidence among vertexes. If the level of pheromone among two vertexes is equal to zero, then there is no edge between both vertexes.
Before delving into the similarity between queries, it is important to clarify certain issues concerning the language used to form queries. Recall from the previous section that a system, which imple-ments CodeRAnts, has proxy architecture and it is plugged into a search engine, thereby query language is the same as that sup-ported by the engine. For instance, if the recommender system is plugged into Koders, the queries are formed with words from natural language and with the same syntax supported by Koders by using identifiers such as cdef, fdef, mdef, idef, and sdef that refer to names of classes, files, methods, interfaces, and structures, respectively. In this particular case, a query could be: cdef:util mdef:compress. With this query, classes whose name contains the word util and whose method contains the word compress are searched.
The similarity among queries is defined in Expression 3, where 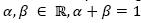 . These constants represent weights for balancing two similarity measures. The first, simw(qi,qj) is the similarity among queries based on the number of edition operations performed (the edit distance proposed by Levenshtein (1966), edDis(qi,qj)) to transform qi into qj (see Expression 4). If qi=qj, then simw(qi,qj)=1, this is, simw(qi,qj) reaches its maximum value due to the edition distance equal to cero, edDis(qi,qj)=0. Following with the above mentioned example, an engineer may use the following words for the query: compress, conpresser (in French), or comprimir (in Spanish). If qi= conpresser, qj = compress, and th=5 (threshold equal to five), then simw(qi,qj)=0.4, because there are three edits to change a query into the other one: 1) conpresser → compresser (substitution of the letter n for m), 2) compresser → compresse (removal of letter r) and 3) compresse → compress (removal of letter e). Table 4 presents all computations of edit distance and simw between queries from the above mentioned example.
. These constants represent weights for balancing two similarity measures. The first, simw(qi,qj) is the similarity among queries based on the number of edition operations performed (the edit distance proposed by Levenshtein (1966), edDis(qi,qj)) to transform qi into qj (see Expression 4). If qi=qj, then simw(qi,qj)=1, this is, simw(qi,qj) reaches its maximum value due to the edition distance equal to cero, edDis(qi,qj)=0. Following with the above mentioned example, an engineer may use the following words for the query: compress, conpresser (in French), or comprimir (in Spanish). If qi= conpresser, qj = compress, and th=5 (threshold equal to five), then simw(qi,qj)=0.4, because there are three edits to change a query into the other one: 1) conpresser → compresser (substitution of the letter n for m), 2) compresser → compresse (removal of letter r) and 3) compresse → compress (removal of letter e). Table 4 presents all computations of edit distance and simw between queries from the above mentioned example.
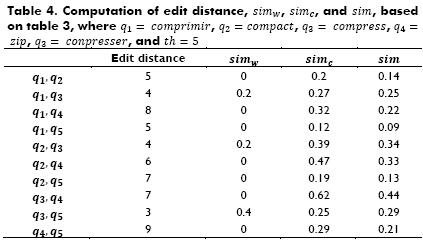
The edit-distance-based measure is the extent of the typographical similarity between two queries. This has been considered in this work because sometimes, typographical mistakes are included within the users' query. Nevertheless, this measure does not con-sider the semantic similarity between two queries, e.g., qi=they, and qj=the. Therefore, sim(qi,qj) is also based on the correlation between the rankings associated with both queries.
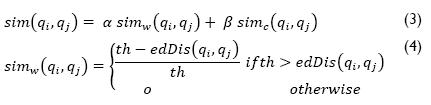
Let simc(qi,qj) be the similarity based on correlation coefficient between queries; it is calculated using Expression 5. Cqi,qj is the correlation coefficient between the row vectors RiQC and RjQC, which is defined in Expression 6, where Cqi,qj ϶ 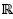 and
and 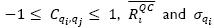 represent the average and the standard deviation of the row vector RiQC, respectively. If the value of Cqi,qj trends to one, it means that both queries are correlated, but if the value is close to zero, there is no correlation, otherwise there is an inverse correlation. Table 4 shows all computations of simc between queries, taking into account the matrix of rankings
represent the average and the standard deviation of the row vector RiQC, respectively. If the value of Cqi,qj trends to one, it means that both queries are correlated, but if the value is close to zero, there is no correlation, otherwise there is an inverse correlation. Table 4 shows all computations of simc between queries, taking into account the matrix of rankings 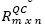 depicted in Table 3.
depicted in Table 3.
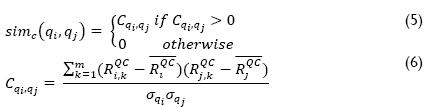
Confidence between queries is computed using Expression 7. 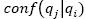 is the conditional probability of making the query qj given the query qi. Table 5 also shows all computations of confi-dence between queries in the above mentioned example.
is the conditional probability of making the query qj given the query qi. Table 5 also shows all computations of confi-dence between queries in the above mentioned example.
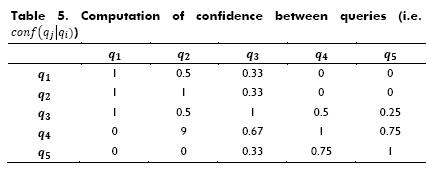
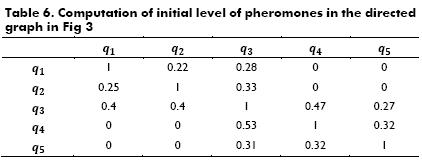
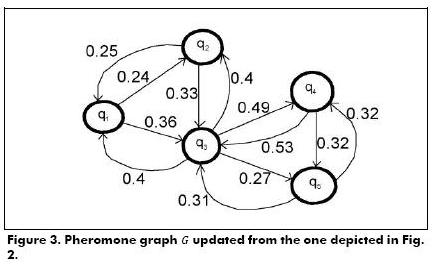
Fig. 2 depicts the directed graph created by using Expression 8, with initial pheromone paths, when t=0, namely, ρqi,qj (0), where k ∈ , and k →0 (i.e., k tends to be very small). t(qi,qj) is a function based on similarity and confidence among queries, it is computed using Expression 9 (adapted from Bedi and Sharman, 2012). Table 6 shows all computations performed to create the directed graph.

Once the directed graph G=(V,E) has been created, as in the example depicted in Fig. 2, the on-line process may start. In this process, an active query vertex is selected by searching the vertex most similar to the query, q, sent by a programmer. Given that this algorithm is inspired in the ant colony, for all the generated ants, there is a time to live (TTL) parameter associated with the number of iterations that the ants can explore in the graph G. If the destination vertex is not found within TTL limit, each ant is removed. Due to the fact that the destination vertex is not known, or in the worst case does not exist, it is mandatory to setup a stop point (the TTL parameter) for the on-line process in order to prevent it from running indefinitely.
The virtual ants' source of food consists of ranking most of the items. Hence, ants move through queries, which are similar to or probably related with the active query in order to collect their rank for those snippets of code that are not ranked for the active query. The on-line process of CodeRAnts is described in the following steps:
i) Seek an active query vertex, α, which is selected if it is the most similar to query, q, sent by a programmer. Suppose an engineer makes a query with the word comprimir (i.e., q="comprimir"); by using edition distance as a method for measuring similarity between queries,q1 is the most similar vertex in the graph depicted in Fig. 3 because there is no edition distance between q and q1 due to the fact that both are exactly alike. Hereafter, for this example, q1 is the active query vertex (i.e., q1=α) in the graph depicted in Fig. 2.
ii) Create x amount of ants, where x is equal to number of outgoing edges from active query vertex, α. In Fig. 2, if the active query vertex is q1, then two ants are created, because this vertex has two outgoing edges.
iii) Each x-th ant selects the next vertex to be visited with the probability 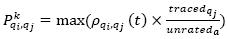 (adapted from Bedi and Sharman, 2012), where
(adapted from Bedi and Sharman, 2012), where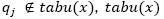 is a set of vertexes which the x-th ant has visited.
is a set of vertexes which the x-th ant has visited. 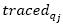 denotes the amount of code snippets traced by the vertex qj, which have not been ranked by the active vertex
denotes the amount of code snippets traced by the vertex qj, which have not been ranked by the active vertex 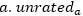 is the total number of code snippets that have not been ranked by the active vertex α. The x-th ant will stop when all its adjacent vertexes are in the set tabux(x). The whole process will finish when all ants may not move anymore or when the ants' TTL reaches its maximum value.
is the total number of code snippets that have not been ranked by the active vertex α. The x-th ant will stop when all its adjacent vertexes are in the set tabux(x). The whole process will finish when all ants may not move anymore or when the ants' TTL reaches its maximum value.
Taking q1 as the active query vertex, Table 3 shows that snippets of code c1, c2, c3, c5, c6 and c7 do not have a ranking in q1. Among the neighbors of q1, q2 there is a ranking for c2 and q3 has a ranking for c5 and c6, hence, these rankings are collected. Therefore, c1, c3, and c7 are still without a ranking. Thereafter, ants keep moving, by choosing q3 as the new destination vertex because the path between q1 and q;3 has the greatest concentration of pheromones. This step is repeated without passing twice through the same vertex until ants reach their goal (i.e., to rank all snippets of code), or until maximum TTL is reached. It is important to clarify that when a certain snippet of code, ci, is ranked by at least two neighbor vertexes, the ranking provided by the neighbors is stored, descending sorted, in accordance with trails of pheromone between the active vertex and its neighbors. For instance, when ants are on the vertex q3, the snippet of code c1 shall be ranked by its neighbor vertexes q4 and q5. In this example, the ranking provided by q4 is stored before the other one provided by q5, due to the fact that trails of pheromones between q3 and q4 are stronger than the concentration of pheromones among q3 and q5.
iv) Generate suggestions through the method proposed by Resnick et al. (1994), with the expression 10, where 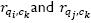 represent the rankings of vertexes qi and qj for the snippet of code ck, respectively.
represent the rankings of vertexes qi and qj for the snippet of code ck, respectively. 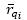 and
and 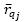 denote the average rankings of vertexes qi and qj, respectively.
denote the average rankings of vertexes qi and qj, respectively. 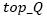 is the number of first neighbors of the vertex qi with the biggest trail of pheromones. For example, if
is the number of first neighbors of the vertex qi with the biggest trail of pheromones. For example, if 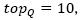 , then
, then 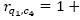
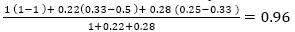
v) Finally, update 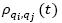 with Expression 11, where ε is the evaporation rate of pheromones and δ is computed with Expression 12, where
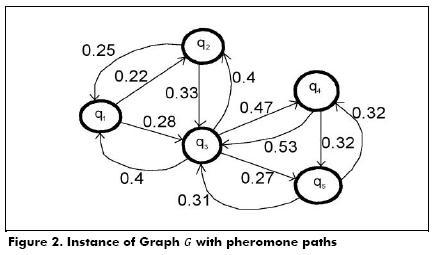
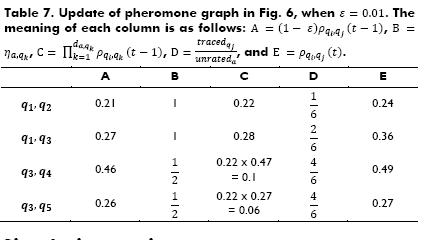
with Expression 11, where ε is the evaporation rate of pheromones and δ is computed with Expression 12, where 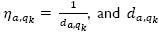 , represents the distance from vertex α to vertex qk. Table 7 and Fig. 3 depict the update to the pheromone graph, when ε=0.01.
, represents the distance from vertex α to vertex qk. Table 7 and Fig. 3 depict the update to the pheromone graph, when ε=0.01.
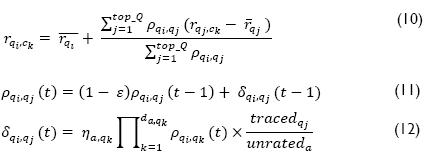
Simulation setting
Shani and Gunawardana (2010) present three methods to evaluate recommender systems, namely, off-line, user studies and on-line. In this work, CodeRAnts was evaluated through the first method with a simulation program written in Java. The program generates a bag-of-terms by assigning random values to the matrix termsCode, which holds the frequency of each term in the source code (i.e., if termsCode[3][4] is equal to 15, it means that the term t3 appears fifteen times in the snippet of codec4). The dataset is randomly generated due to the fact that there is not a real published dataset of interaction between programmers and search engines, or programmers and recommender systems based on collaborative searching.
A search engine and programmers are simulated in order to train and test the simulated recommender system, which implements the CodeRAnts method. In the training phase, programmers randomly choose certain snippets of code by performing searches through a simulated search engine. Queries are randomly selected from a dataset and these terms appear with high frequency in the snippet of code. In this way, the programmers' knowledge for performing a code search is simulated. The queries are words from natural language, which are used to write source code. This phase aims to fill the 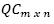 matrix, by recording which snippets of code are selected by programmers during the searches.
matrix, by recording which snippets of code are selected by programmers during the searches.
After the training phase, the simulator program performs the off-line phase of the CodeRAnt method. Then, the on-line phase begins the testing phase and other simulated programmers perform source code searches through a simulated recommender system. During the training phase, simulated programmers search at most 99 snippets of code and while testing phase is performed, the other instances seek at most, 25 snippets of code, which are stored in the dataset (i.e., relevant items). In both phases, programmers perform from 5 to 10 queries in order to search a snippet of code. Each query is randomly selected from a bag-of-que-ries. When a programmer finds a snippet of code, it is counted as a retrieved item in order to compute precision and recall metrics. Three fourths of the set of programmers are used for training and one fourth of this set is used for testing. Assessments were performed with sets of 30, 50, 100, 500, 1000, 5000, and 10000 programmers. Other parameters considered in the assessment are: α=0.75, β=0.25, th=1, timeout = 10, ε =10−2, and k= 10−3. These parameters were chosen by running the simulation several times. Thus, we tuned the parameters until the best performance was achieved. The next section shows the results of the assessments with this experimental setting.
Results and discussion
Table 8 shows the results of the simulation. The average of precision and recall values is 0.53 and 0.71 respectively. These values are better than those achieved by Cubranic et al. (2005) with Hipikat, in average, 0.11 and 0.65 for precision and recall, respectively. Furthermore, the outcomes of the simulation performed on CodeRAnts are better than those observed by Ye and Fischer (2005) with CodeBroker, namely, with this system precision is not greater than 0.4, but recall reached 1.
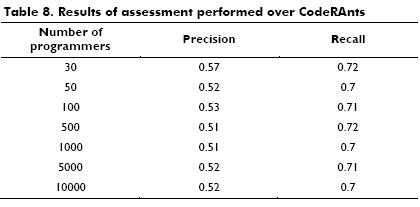
Nevertheless, although with the simulations we achieved better values than those obtained by other researchers, this assessment method is not rigorous and its outcomes are slanted, given that the above mentioned systems were evaluated through user-based assessments. Cubranic et al. (2005) evaluated Hipikat with a group of real programmers and the Eclipse source code (version 2.1). In a similar fashion, Ye and Fischer (2005) carried out experiments over CodeBroker with real programmers, but with the Java 1.1.8 core library and the JGL 1.3 library. Thereby, for future studies, CodeRAnts must be assessed with the other systems using the same experimental method and setting. Additionally, CodeRAnts was assessed with a randomly generated dataset; hence, for further work we must collect a real dataset through user-based experiments.
The results of these experiments reveal that edit-distance-based similarity between queries is not useful because the best performance is achieved when the threshold parameter is equal to one. Hence, this is almost the same procedure as checking whether both queries are equal. In the future, we will assess other similarity measures (e.g., cosine distance, Euclidean distance, and etcetera).
Conclusions and directions for further work
The contributions of this study are: i) a recommendation method that can be implemented like a proxy of a code search engine or an above mentioned recommender system (e.g., Strahtcona), in order to allow them to improve their answers and recommendations for programmers; due to this, these systems could learn from users' collaboration through CodeRAnts. ii) a recommendation method which tackles the cold start problem given that a system which implements CodeRAnts can suggest snippets of code, although it receives new queries that do not belong to set Q, by searching other similar in this set. Moreover, through the ant colony technique, a system which implements CodeRAnts can suggest snippets of code, despite the fact that the matrix 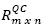 does not have a ranking for these snippets given certain queries through the search performed by ants, through possibly related or correlated queries, and collecting ranking for these snippets, iii) a recommendation method, that in a simulated environment, has better preliminary values of precision and recall than prior systems designed for software reuse; however, it is important to highlight that the results of the simulations are not definitive evidence of the quality of recommendation provided through of CodeRAnts method because in the simulation settings the bag-of-terms and the dataset are randomlygenerate; moreover, CodeRAnts was not evaluated with the same experimental method and setting carried out in the other systems by other researchers.
does not have a ranking for these snippets given certain queries through the search performed by ants, through possibly related or correlated queries, and collecting ranking for these snippets, iii) a recommendation method, that in a simulated environment, has better preliminary values of precision and recall than prior systems designed for software reuse; however, it is important to highlight that the results of the simulations are not definitive evidence of the quality of recommendation provided through of CodeRAnts method because in the simulation settings the bag-of-terms and the dataset are randomlygenerate; moreover, CodeRAnts was not evaluated with the same experimental method and setting carried out in the other systems by other researchers.
For future studies the following are proposed: i) collect a real dataset through user-based experiments, ii) carry out the evaluation of CodeRAnts with the other systems with the same experimental method and setting and iii) test other similar measures (e.g., cosine distance, Euclidean distance, etc.).
References
Ankolekar, A., Sycara, K., Herbsleb, J., Kraut, R., Welty, C., Supporting online problem-solving communities with the semantic web., Memoirs from 15th International conference on World Wide Web, ACM Press, 2006, pp. 575-584. [ Links ]
Bajracharya, S. K., Lopes, C. V., Analyzing and mining a code search engine usage log., 2010, Empirical Software Engineering, pp. 1-43. [ Links ]
Balabanovic, M., Shoham, Y., Fab: content-based, collaborative recommendation., Commun, Vol. 40, No. 3, 1997, ACM, pp. 66-72. [ Links ]
Basu, C., Hirsh, H., Cohen, W., Recommendation as classification: Using social and content-based information in recommendation., Proceedings of the 15th National Conference on Artificial Intelligence, 1998, AAAI Press, pp. 714-720. [ Links ]
Bedi, P., Sharma, R., Trust based recommender system using ant colony for trust computation., Expert Systems with Applications, Vol. 39, No. 1, 2012, pp. 1183 - 1190. [ Links ]
Billsus, D., Pazzani, M. J., Learning collaborative information filters., Proceedings of the 15th International Conference on Machine Learning, ICML '98, San Francisco, CA, USA, 1998, Morgan Kaufmann Publishers Inc, pp. 46-54. [ Links ]
Boehm, B. W., Managing software productivity and reuse., IEEE Computer, Vol. 32, No. 9, 1999, pp. 111-113. EPA, Title 40 Sub-chapter I-Solid waste, 258 criteria for municipal solid waste landfills., Environmental Protection Agency, USA, 2000. [ Links ]
Bouassida, N., Kouas, A., Ben-Abdallah, H. A design pattern recommendation approach., 2nd Interntional Conferences on Software Engineering and Service Science (ICSESS), 2011, IEEE Press. [ Links ]
Brooks, F., No silver bullet essence and accidents of software engineering., Computer, Vol. 20, No. 4, 1987, pp. 10-19. [ Links ]
Coyle, M., Smyth, B., Information recovery and discovery in collaborative web search., Proceedings of the 29th European conference on IR research, ECIR'07, Berlin, Heidelberg, Springer-Verlag, 2007, pp. 356-367. [ Links ]
Cubranic, D., Murphy, G. C., Singer, J., Booth, K. S., Hipikat: Aproject memory for software development., IEEE Trans. Software Eng., Vol. 31, No. 6, 2005, pp. 446-465. [ Links ]
Furnas, G. W., Landauer, T. K., Gomez, L. M., Dumais, S. T., The vocabulary problem in human-system communication. Commun. ACM, Vol. 30, No. 11, 1987, pp. 964-971. [ Links ]
Holmes, R., Walker, R., Murphy, G., Approximate structural context matching: An approach for recommending relevant examples., IEEE Trans. Software Eng., Vol. 32, No. 1, 2006, pp. 952-970. [ Links ]
Jameson, A., Smyth, B., The adaptive web. Chapter Recommendation to groups, Berlin, Heidelberg, Springer-Verlag, 2007, pp. 596-627. [ Links ]
Levenshtein, V. I., Binary codes capable of correcting deletions, insertions and reversals., Soviet Physics Doklady, 1966, pp. 707-710. [ Links ]
Mcilroy, D., Mass-produced software components. Software Engineering, conference by the NATO Science Committee, 1968, pp. 952-970. [ Links ]
Mockus, A., Herbsleb, J., Expertise browser: Aquantitative approach to identifying expertise. 24th International Conference on Software Engineering, New York, United States of America, IEEE CS Press, 2002, pp. 503-512. [ Links ]
Morris, M. R., A survey of collaborative web search practices., Proceedings of the 26th annual SIGCHI conference on Human factors in computing systems, CHI '08, 2008, New York, NY, USA, ACM, pp. 1657-1660. [ Links ]
Picault, J., Ribiere, M., Bonnefoy, D., Mercer, K., Recommeder systems Handbook, chapter 10: How to Get the Recommender Out of the Lab?, 2010, Springer-Verlag, pp. 579-614. [ Links ]
Pohl, K., Böckle, G., Software Product Line Engineering, Foundations, Principles, and Techniques., Springer-Verlag, Germany, 2005. [ Links ]
Poulin, J. S., Caruso, J. M., Hancock, D. R., The business case for software reuse. IBM Syst. J., Vol. 32, No. 4, 1993, pp. 567-594. [ Links ]
Raymond, E. S., The Cathedral and the Bazaar., 1st ed., Sebastopol, CA, USA, O'Reilly & Associates, Inc., 1999. [ Links ]
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., Riedle, J., Grouplens: An open architecture for collaborative filtering of netnews., Conference on computer supported cooperative work, Chapel Hill, ACM Press, 1994, pp. 175-186. [ Links ]
Resnick, P., Varian, H. R., Recommender systems., Commun. ACM, Vol. 40, No. 3, 1997, pp. 56-58. [ Links ]
Ricci, F., Rokach, L., Shapira, B., Recommeder systems Handbook, chapter 1: Introduction to Recommeder systems Handbook., Springer-Verlag, 2010, pp. 1-38. [ Links ]
Robillard, M., Walker, R., Zimmermann, T., Foreword. Workshop on Recommendation Systems for Software Engineering., ACM Press, 2008. [ Links ]
Robillard, M., Walker, R., Zimmermann, T., Recommmedation systems for software engineering., Software IEEE, Vol. 27, No. 4, 2010, pp. 80-86. [ Links ]
Sarwar, B. M., Karypis, G., Konstan, J. A., Riedl, J. T., Application of dimensionality reduction in recommender system - a case study., ACM WebKDD 2000 Web Mining for ECommerce Workshop, Vol. 1625, No. 1, 2000, pp. 264-268. [ Links ]
Schafer, J. B., Konstan, J., Riedi, J., Recommender systems in ecommerce., Proceedings of the 1st ACM conference on Electronic commerce, EC '99, New York, NY, USA, ACM, 1999, pp. 158-166. [ Links ]
Shani, G. Gunawardana, A., Recommeder systems Handbook, chapter 8: Evaluating Recommendation Systems., Springer-Verlag, 2010, pp. 257-297. [ Links ]
Smyth, B., Case-based recommendation., In: The Adaptive Web, 2007, pp. 342-376. [ Links ]
Smyth, B., Coyle, M., Briggs, P., Recommeder systems Handbook, chapter 18: Communities, Collaboration, and Recommender Systems in Personalized Web Search., Springer-Verlag, 2010, pp. 579-614. [ Links ]
Thummalapenta, S., Xie, T., Parseweb: A programming assistant for reusing open source code on the web. IEEE/ACM International conferences on Automated Software Engineering, ACM Press, 2007, pp. 204-213. [ Links ]
Ye, Y., Fischer, G., Reuse-conducive development environments., Automated Software Eng., Vol. 12, No. 2, 2005, pp. 199-235. [ Links ]
Zimmermann, T., Zeller, A., Weissgerber, P., Diehl, S., Mining versión histories to guide software changes., IEEE Trans. Software Eng., Vol. 31, No. 6, 2005, pp. 429-445. [ Links ]
