










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkIngeniería e Investigación
Print version ISSN 0120-5609
Ing. Investig. vol.35 no.3 Bogotá Sept./Dec. 2015
https://doi.org/10.15446/ing.investig.v35n3.43991
DOI: http://dx.doi.org/10.15446/ing.investig.v35n3.43991.
An information search model for online social Networks - MOBIRSE
Un modelo de búsqueda de información para las redes sociales en Línea - MOBIRSE
J.A. Astaiza1, I.D. Cerón2, M.A. Niño-Zambrano3, and G.A. Ramírez-González4
1 Jhon Alberto Astaiza Perafán: Systems Engineer, School of Electronic Engineering and Telecommunications. University of Cauca, Popayan, Colombia.
E-mail: jpastaiza@unicauca.edu.co.
2 Iván Darío Cerón Moreno: Systems Engineer, School of Electronic Engineering and Telecommunications. University of Cauca, Popayan, Colombia.
E-mail: ivandceron@unicauca.edu.co.
3 Miguel Angel Niño Zambrano: PhD(c) in Telematics Engineering, Affiliation: Full-time Professor at School of Electronic Engineering and Telecommunications. University of Cauca, Popayan, Colombia.
E-mail: manzamb@unicauca.edu.co.
4 Gustavo Adolfo Ramírez González: PhD in Telematics Engineering, Affiliation: Full-time Professor at School of Electronic Engineering and Telecommunications. University of Cauca, Popayan, Colombia.
E-mail: gramirez@unicauca.edu.co.
How to cite: Astaiza, J.A., Cerón, I.D., Niño-Zambrano, M.A., & Ramírez-González, G.A. (2015). An information search model for online social Networks - MOBIRSE. Ingeniería e Investigación, 35(3), 76-83. DOI: http://dx.doi.org/10.15446/ing.investig.v35n3.43991.
ABSTRACT
Online Social Networks (OSNs) have been gaining great importance among Internet users in recent years. These are sites where it is possible to meet people, publish, and share content in a way that is both easy and free of charge. As a result, the volume of information contained in these websites has grown exponentially, and web search has consequently become an important tool for users to easily find information relevant to their social networking objectives. Making use of ontologies and user profiles can make these searches more effective. This article presents a model for Information Retrieval in OSNs (MOBIRSE) based on user profile and ontologies which aims to improve the relevance of retrieved information on these websites. The social network Facebook was chosen for a case study and as the instance for the proposed model. The model was validated using measures such as At-k Precision and Kappa statistics, to assess its efficiency.
Keywords: Ontologies, user profile, online social network, information retrieval, search model.
RESUMEN
En los últimos años las Redes Sociales Online (RSO) han venido cobrando gran importancia entre los usuarios de Internet, puesto que son sitios donde se puede conocer personas, publicar y compartir contenidos de una manera fácil y gratuita. Esto ha provocado que el volumen de información contenida en estos sitios web crezca de manera exponencial. Por lo tanto, la búsqueda web se convierte en una herramienta importante para que los usuarios puedan encontrar fácilmente la información relevante para sus objetivos en la red social. Esta búsqueda puede ser más efectiva aprovechando las ontologías y el perfil de usuario. El presente artículo plantea un modelo para la recuperación de información en RSO (MOBIRSE), basado en el perfil de usuario y ontologías, encaminado a mejorar la relevancia de la información recuperada en estos sitios web. Se tomó como caso de estudio la red social Facebook, sobre la cual se instanció el modelo propuesto. El modelo se validó haciendo uso de medidas como la Precisión At-k y las estadísticas Kappa, para comprobar su eficiencia.
Palabras clave: Ontologías, perfil de usuario, redes sociales online, recuperación de la información, modelo de búsqueda.
Received: June 12th 2014 Accepted: July 30th 2015
Introduction
Online Social Networks (OSNs) have been gaining popularity among Internet users due to their ease for communication and the multiple services they offer, causing the volume of their information to increase exponentially. One of the services offered by the OSNs is the search option that helps users to easily find friends, groups, posts and other information stored on these sites. It can be seen that OSNs suffer from the same problems as traditional web browsers, as the information retrieved does not usually meet the user's needs. Considering this issue, it can be said that the retrieval of information relevant to OSN users becomes a highly desirable objective for applications of these sites, reducing the overload of information irrelevant to the user and the OSN.
The Semantic Web has provided researchers and developers with useful information retrieval (IR) tools, such as ontologies (Mora et al., 2013), metadata languages and inference engines, all of which make the current Web meaningful by helping Internet users obtain responses to their queries in a faster and cleverer way.
User profile (UP) (Abel et al., 2013; Gauch et al., 2007) is a concept that allows the preferences and particular interests of a user or group of users to be represented.
When this concept is used in IR systems, it enables the results to fit better the IR characteristics.
OSNs have been quick in exploiting this element, and have used it to classify the resources that they offer. Nevertheless, each OSN handles user profiles differently, as their focus or objective can differ, meaning that a wide variety of user profiles can be found.
This article puts forward a model for information retrieval in Online Social Networks, based on user profile and ontologies, to improve the relevance of information retrieved in these websites. The model proposed offers the possibility of retrieving information personalized to each user of the OSN, based on the preferences of the user profile and the interaction of the user with the OSN, making the relevance of retrieved information in these sites better than the actual search engines.
Theoretical framework
Since the proposed model involves the use of ontologies to represent the UP, a preliminary study was conducted to determine whether it was more suitable to create an ontology or to use an existing one. Several projects emerged from the above study, among which (Golemati et al., 2007) stands out, proposing a general and customizable ontology that can be used by any application according to its characteristics. This ontology uses the top-down approach, is based on the static characteristics of the user, and can be extended through inheritance or by adding classes (Table 1).

Recent studies have focused on recommendation systems and information retrieval systems based on user profiles represented in ontologies (Biancalana et al., 2013; Calegari et al., 2013; Moreno et al., 2013). These studies allow the use of reasoning techniques in order to find users' interests and propose content according to them. In our case we do not intend to propose content, but find relevant content in the social network.
Many elements are found in IR that can be of great help in improving the relevance of the information retrieved. Query expansion (Formoso et al., 2013; Ghorab et al., 2013; Shokouhi, 2013) is a very important element in IR models, since it is responsible for improving the original query and expanding it, given that generally users send short and not very specific queries (Cui et al., 2003). As a result, the focus is on identifying and combining similar terms, and linking them to concepts identified in the original query.
Moreover, it also takes into account previous studies that involve the use of UP based on ontologies to improve the relevance of retrieved information. In this case, the study by (Sieg et al., 2007) is centered on modeling the user context, making use of three elements: the needs of the user in the short-term, the semantic knowledge of a specific domain, and the long-term interests. The idea is to assign scores to the interests derived from the existing concepts in the domain ontology, which makes it possible to derive a hierarchy of topics that may be of interest to the user.
This is done by updating UP is achieved by the activation mechanism of propagation. Moreover, the collection of the information to construct and/or maintain the user profile is done in an implicit way. The concepts are also weighted, i.e. they have a weighting assigned to them initially.
Other important research taken into account was the one carried out by (Daoud et al., 2009), which represents UP as a graph of the most relevant concepts in the ontology, in the same search session, and not as an instance of the whole ontology.
By the other hand, in the UP short-term interests, the research by (Zuluaga et al., 2008) was considered for the construction and maintenance of the profile, such as: the use of weighted concepts and the session limit mechanism, which takes into account a certain threshold and is used to determine whether or not a new query its within the current profile. For the construction of the UP in the present work, the following phases were defined: building the search profile based on search activities, initializing and maintaining the search profile throughout the search session and finally, detecting a new session limit, when a new query is made.
The project proposed by (Siping et al., 2008) was also important for the ontology developed, as it allowed the ontology of the present work to be adapted to the user's search needs. Furthermore, this ontology was constructed using the Skeletal methodology (Uschold et al., 1996). A software tool (Protege 3.1.1) was also used to complete the description and RDF to describe the ontology.
Online Social Networks formed another key subject for the development of our model. These contain many features and are of various types, all of which were taken into account when defining the model.
The study carried out brought to light the fact that data such as names, surnames, date of birth, email and biography are present in all OSNs analyzed. Furthermore, it was seen that there are common services offered by all the OSNs on which this study was conducted, such as messaging, contacts, publications and search engines, which led us to consider that these services are the most accepted by users and that must necessarily be included in the model.
Proposed Model
MOBIRSE is an Information Retrieval Model in Online Social Networks that is based on the use of user profile and ontologies to improve the relevance of information retrieved in these websites. This section presents the definition of the model, including its elements, constraints and modules. Also depicted are the suggestions for its implementation. It should be noted that the methodology used to generate the model was proposed by (Niño et al., 2004).
The key elements identified for the model are as follows:
-
OSN search engine: represents the search service provided by the OSN.
-
Resources: represents those items that are stored in the OSN, such as photos, videos, links and plain text.
-
OSN API: represents the element through which the resources and services of the OSN are accessed.
-
User Profile: represents the tastes and preferences of the user through an ontology, which is defined using the Web Ontology Language (OWL) standard format.
-
IR mechanism: represents a series of processes applied to the resources returned by the OSN search engine, in order to improve the relevance of these.
-
Query: represents the original query entered by the user.
-
Query expansion mechanism: represents a series of processes applied to the query in order to complement the original query.
With respect to the constraints of the proposed model, it must be noted that it is oriented only to OSN sites. The OSN should provide a development API that has access to both the user profile information and to the search results that the OSN offers. For this project the OSN Facebook was used. Finally, the resources that will be taken into account for updating the user profile will be those that contain plain text such as publications, events, page descriptions, etc.
Conceptual model
To abstract the most important elements of a specific reality, it is necessary to generate a conceptual model.
Figure 1 shows the modules that make part of the definition of MOBIRSE and the relationships between them, thus creating an overall view of the earliest approach.
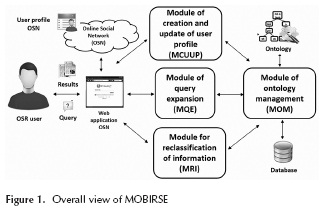
The Web App application is the application responsible for capturing the actions requested by the user and displaying the information from the other modules. In addition, it makes use of the API of the specific OSN to obtain the UP information from the interaction with the OSN and the search results.
Module of ontology management
The module of ontology management (MOM) is responsible for performing all the management tasks related to the ontology, management being understood in the functions of access, save, infer and other operations that can be performed on it.
Module of creation and update of user profile
The module of construction and update of user profile (MCUUP) is responsible for creating and updating the ontology that represents the user profile. To achieve this, the ontology proposed by (Golemati et al., 2007) was used, and modified to the needs of our research.
The functions performed by the MCUUP vary depending on the type of request prompted: to create a new UP or to upgrade an existing one. The features it offers are:
-
Obtain a new instance of the ontology: returns a blank instance of the ontology, used to create a new UP.
-
Read the UP from the database: loads user profile information into an instance of the ontology from the database repository.
-
Save information from the UP: maps the information from the UP into a relational database schema, which is a replica of the ontology that represents the user profile.
-
Extract terms: this is the function responsible for extracting simple and compound terms contained in a source of plain text such as: publications, events, messages, queries, etc. It should be noted that the way this feature works is based on the proposal of (Baziz et al., 2005).
-
Propagate weightings (PW): this is the most important feature of this module (Figure 2) and is responsible for updating the weightings of the concepts in the ontology, using the semantic similarity measure proposed by (Slimani et al., 2006).
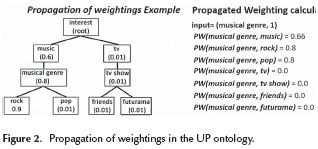
To achieve this, the weighting that is propagated from one concept to another must be taken into account, which is given by the following expression:
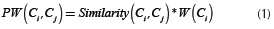
Where:
Ci: Represents the concept identified in the ontology, to which the propagation process will be applied.
Cj: Represents any concept of the ontology to which a percentage of the Ci weighting intends to be propagated.
Similarity (Ci ,Cj ): Represents the semantic similarity value of the concept Cj with respect to the concept Cj.
W(Cj): Represents the weighting or score of the concept Ci.
Taking into account of the value to propagate given by Equation (1), the new weighting of the affected concept Cj is given by the following expressions:
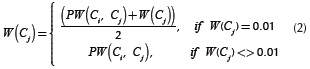
For each concept identified, the propagation algorithm of (Troussov et al., 2008) was applied.
-
Add concept: Function responsible for adding new concepts to the ontological structure. Terms that are not paired with a concept in the ontology are processed to look for some type of hierarchical relationship with the existing concepts. To do this, use will be made of hypernym5, hyponym6 and synonym7 terms provided by Wordnet8. To add a new concept to the ontology, five basic cases have been identified:
-
No relationship exists between the new concept and those present in the ontology: In this case a new node (concept) would simply be created, with the weighted term attributes, i.e. name and weight, and it will be added as an offspring of the "Others" section.
-
There is a hyponym concept in the ontology and it is the offspring of a root concept: the new concept is added as an offspring of the root concept, and the new concept becomes a parent of the hyponym concept.
-
A concept hypernym of the new concept exists in the ontology, which is a leaf node: the new node is added as offspring of the hypernym concept.
-
A hyponym and hypernym concept of the new concept exists in the ontology: The new concept is added as an offspring node of the hypernym concept, and the hyponym concept becomes the offspring of the new concept.
-
A concept exists for which it is a synonym: In this case a label with the synonym is added to the synonym concept in the ontology. There is no change in the hierarchy.
Module of query expansion (MQE)
The module of query expansion (MQE) is responsible for processing the original query from the Web App, to identify concepts of the Ontological User Proile that are related to the query, and thereby improve the original query and ultimately the results from the OSN search engine.
The MQE expands the concepts that will be returned to the Web App. To do this, it uses the vector space model in order to identify the concept most similar to the query. Once this is done, it goes on to extract the offspring of that concept in order to return a list of the concepts most closely related to the original query.
In pseudocode form, the following shows the general process for obtaining terms expanded from the original query.
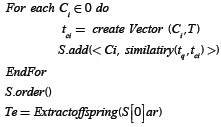
Where:
-
q: The query sent from the Web App
-
O= {c1,c2,...,cn}: The set of concepts that represent the ontology user profile.
-
T: Terms extracted using O.
-
tq = {ti ,t2,...,tn} : The vector of terms that represent the query sent from the Web App as a function of the terms contained in T.
-
tci = {t1,t2,...,tn} : The vector of terms that represent each concept Ci, of the ontology, as a function of the terms contained in T.∀i , = 1,...,n
-
Similarity(tq,tci): The similarity value given as the cosine between the vector of terms of the query q y and the vector of terms of the concept Ci ,∀i,i = 1,...,n
-
S: Array9 for storing tuples of the form < Ci Similarity (tq,tci>, with Ci ∈ 0, ∀i ,i =1,..., n . Isordered in descending order to remove the tuple with the highest similarity value
-
Te: Array that will store the expanded terms that will be returned to the Web App.
-
The Extract Offspring function is responsible for extracting the offspring of the concept with the greatest similarity value with respect to the query.
Module of reclassification of information (MRI)
The module of reclassification of information (MRI) is responsible for weighting by relevance the search results sent by the Web App, which are provided by the OSN search service. To perform this operation, the UP of the user in question and the type of query that they enter must be considered.
The MRI reclassifies the retrieved documents according to the UP. To do this it uses a variant of the vector model which uses the ontology that represents the UP to assign weightings to the documents, and reclassify them accordingly. The document reclassification process was based on the proposal of (Sieg et al., 2007), which takes into account the semantic evidence of the ontology and the cosine similarity measure to assign weightings for the documents to be reclassified.
To carry out this process, it is necessary to define:
-
That documents, query and concepts should be represented in terms of vectors, which store the frequency of occurrence of terms in the retrieved documents. This frequency is calculated using the tfidf measure (Manning et al., 2008).
-
The cosine similarity measure was used for determining the degree of similarity between pairs of vectors, with values ranging from 0 to 1.
Given the above, the process of document reclassification is as follows:
-
The concept is extracted from the ontology most similar to the document.
-
Cosine similarites are calculated:
-
Between the document and the query.
-
Between the query and the concept most similar to the document.
- A score is assigned to the document, taking into account the similarity of the document to the query, the similarity of the most similar concept with the query, and the weighting of that concept.
Implementation of MOBIRSE
To implement the model, use was made of the following technologies and tools:
-
Programming language, C# with framework 3.5 from. NET.
-
Protege 3.1.1.
-
Jena.NET Framework.
-
APIS IKVM. OpenJDK.ClassLibrary10, JAWS11, in order to access WordNet.
It should be made clear that the implementation of the model was made as a library, in order for it to be used by any web application developed in .NET.
Considering the above, the proposed architecture is shown in Figure 3.
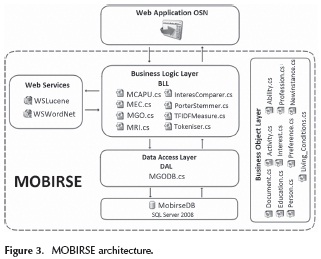
The architecture developed is client/server. The client corresponds to a Web browser and the server is a Web application, ASPNET, which uses web services technologies in order to access the services of WordNet and Lucene12. Three well-defined layers (business, access to data and physical access) were developed in the web applicationin order to make maintenance and performance easier. In the business layer the modules outlined in previous sections were developed, which make efficient use of the object-oriented model. Finally, this implementation was packaged as a library application interface (API), with well-defined interfaces, so that it can be reused in other Web applications, as shown in the following case study.
Experimentation and Validation of MOBIRSE
To validate the proposed model, a web application called Facebook Meta Search Engine was developed, which makes use of the model implemented previously. This meta search engine has the following features:
-
It is coupled to the OSN Facebook.
-
It is developed using C# language.
-
Access to the information from the OSN is achieved via Facebook C# SDK.
To update UP, wall posts and searches performed by the user are taken into account. Moreover, to create the application a multilayer architecture was installed, as is shown in Figure 4. In this figure it can be seen how the MOBIRSE library is used to support the operations described in each of the steps of the model to develop the business logic of the web search engine of the chosen social network.
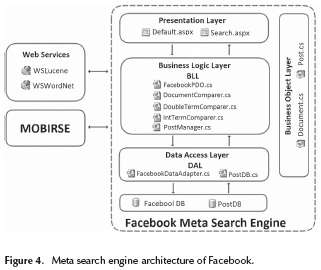
Figure 5 shows the graphical interface of the Facebook Meta Search Engine (FMSE) user developed as a Facebook application so that the users of the network can access their data and searches from their own profile.
To determine the performance of MOBIRSE, a test phase was developed in which At-K precision measures and Kappa statistics were used, applied to real Facebook users and compared with the current search features offered by that network.
To carry out the above it was necessary to take into account the following:
-
This process relied on ten users belonging to the Systems Engineering program, because to determine the Kappa index the group should be homogenous. The users were asked beforehand to change their Facebook profiles to English, i.e. so all their likes, favourites and so on were in this language. Likewise, they were asked to ensure that all wall postings (their own or those posted by their friends) were in English too.
-
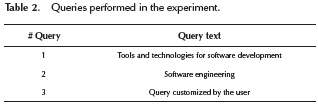
Queries performed are shown in Table 2:
-
The first ten results returned for each query were assessed, given that the study by Thorsten et al. (Joachims et al., 2007), shows that it is a valid way to measure relevance in search engines or metasearch engines.
In the test phase, At-K Precision (Manning et al., 2008) was used, which enables the precision in the first K results in the ranking of an information retrieval system to be known. Kappa index was also calculated to be able to evaluate the agreement of the jurors on the relevance of the results returned by FMSE. It should be noted that for this particular case the Kappa index of Fleiss (Fleiss, 1971) was calculated, since it allows evaluation of the agreement of more than two jurors.
Figure 6 presents the precision in K retrieved documents (K = 10) for the Facebook search and allows them to be compared with FMSE. The average precision for different values of K can be seen, with results ranging between 62% and 100% for FMSE, thus showing a higher degree of precision compared with traditional Facebook search engine. Further, Figure 6 shows that the FMSE results maintain better precision values than those provided by the traditional search engine of Facebook.
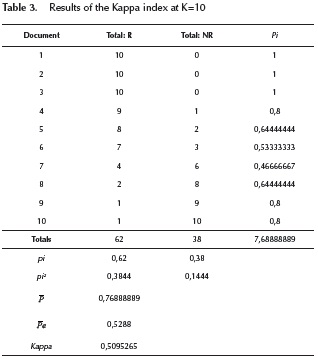
Figure 6 shows the calculation of the Kappa index for the top 10 results returned by FMSE.
The Fleiss Kappa index was then calculated, where R indicates Relevant, NR Not relevant, and Pi is a measure that indicates the number of judge-judge pairs that are in agreement, relative to the number of all possible judge-judge pairs.
According to Table 3, the Kappa index for the first 10 documents shows that the number of people that agree is significant and lies within a moderate agreement according to the ranges established by Landis and Koch (Landis et al., 1977).
Discussion
The experimental results show that the metasearch engine implemented (FMSE) that makes use of the model proposed makes a significant improvement on the information retrieval mechanisms used by traditional search engines of the social networks. In the specific case of Facebook, it brought important advantages such as increased retrieval of relevant documents and a better ranking of them in the set of results displayed to the user.
Conclusions
MOBIRSE, an information search model for online social networks was proposed. This model incorporates elements of Online Social Networking information, information retrieval techniques such as user profile, and IR algorithms that allow customized search capabilities to be incorporated for the users of online social networks.
The first implementation of the MOBIRSE is an application called Facebook Meta Search Engine, and the experimental results showed that the proposed model provides a significant improvement compared to the information retrieval mechanisms used by the traditional search engines in online social networks. This, given that it offers a number of important advantages such as an increase in the recovery of relevant documents and a better ranking of the documents in the results set displayed for the user.
The use of ontologies to represent the user profile in the process of information retrieval in online social networks is of great importance, as they allow the interests and preferences of the user to be identified, which can be used to improve the relevance of the documents retrieved in these websites.
Acknowledgments
The authors would like to acknowledge the support of the University of Cauca in providing the resources necessary for the completion of this project. They are also grateful to Colin McLachlan for suggestions regarding the English text.
Notes
6 Hyponyms, unlike hypernyms, are words of limited meaning, which can provide concrete examples of other words of broader meaning. Words such as carnation, rose, jasmine, are hyponyms of flower.
7 Synonyms are words that have a similar or identical meaning to each other.
8 Wordnet is a general purpose language ontology packaged in a web service to recover concepts related to a concept given in English.
9 Array: represents a collection of elements.
10 IKVM.OpenJDK.ClassLibrary: allows the running of the Java code on the .NET platform.
11 JAWS: API developed in Java programming language that allows data retrieval from the WordNet database.
12 Lucene is a development API from Apache software that contains functions for implementing information retrieval systems.
References
Abel, F., Herder, E., Houben, G.-J., Henze, N., & Krause, D. Cross-system user modeling and personalization on the social web. User Modeling and User-Adapted Interaction journal, Vol. 23, No. 2, Apr. 2013, pp. 169 - 209. [ Links ]
Baziz, M., Boughanem, M., & Aussenac-Gilles, N. Evaluating a Conceptual Indexing Method by Utilizing WordNet. Vol. No. 2005, pp. 8. [ Links ]
Biancalana, C., Gasparetti, F., Micarelli, A., & Sansonetti, G. An approach to social recommendation for context-aware mobile services. ACM Transactions on Intelligent Systems and Technology (TIST), Vol. 4, No. 1, Jan. 2013, pp. 1-31. DOI: 10.1145/2508037.2508041. [ Links ]
Calegari, S., & Pasi, G. Personal ontologies: Generation of user profiles based on the YAGO ontology. Information Processing and Management, Vol. 49, No. 3, 2013, pp. 640 - 658. DOI: 10.1016/j.ipm.2012.07.010. [ Links ]
Cui, H., Wen, J.-R., Nie, J.-Y., & Ma, W.-Y. Query expansion by mining user logs. IEEE Transactions on Knowledge and Data Engineering, Vol. 15, No. 4, 2003, pp. 829 - 839. DOI: 10.1109/TKDE.2003.1209002 [ Links ]
Daoud, M., Tamine-Lechani, L., Boughanem, M. (2009, Mar). A session based personalized search using an ontological user profile. Paper presented at the Proceedings of the 2009 ACM symposium on Applied Computing. DOI: 10.1 145/1529282.1529670. [ Links ]
Fleiss, J. Measuring nominal scale agreement among many raters. Psychological Bulletin, Vol. 76, No. 5, Nov. 1971, pp. 378 - 382. DOI: 10.1037/h0031619. [ Links ]
Formoso, V., Fernández, D., Cacheda, F., Carneiro, V. Using profile expansion techniques to alleviate the new user problem. Information Processing and Management, Vol. 49, No. 3, 2013, pp. 659 - 672. DOI: 10.1016/j.ipm.2012.07.005. [ Links ]
Gauch, S., Speretta, M., Chandramouli, A., Micarelli, A. User Profiles for Personalized Information Access. The Adaptive Web, Vol. 4321, No. 2007, pp. 54 - 89. DOI: 10.1007/978-3-540-72079-9_2. [ Links ]
Ghorab, M. R., Zhou, D., O'Connor, A., Wade, V. Personalised information retrieval: survey and classification. User Modeling and User-Adapted Interaction, Vol. 23, No. 4, 2013, pp. 381 - 443. DOI: 10.1007/s11257-012-9124-1. [ Links ]
Golemati, M., Katifori, A., Vassilakis, C., Lepouras, G., Halatsis, C. Creating an ontology for the user profile: Method and applications. Proceedings of the First RCIS Conference, Vol. No. 2007, pp. 407 - 412. [ Links ]
Joachims, T., Radlinski, F. Search Engines that Learn from Implicit Feedback. Computer, Vol. 40, No. 8, 2007, pp. 3440. DOI: 10.1109/MC.2007.289. [ Links ]
Landis, J., Koch, G. The measurement of observer agreement for categorical data. Biometrics, Vol. 33, No. 1, Mar. 1977, pp. 159 - 174. [ Links ]
Manning, C. D., Raghavan, P., Schütze, H. (2008). Introduction to Information Retrieval (Vol. I). Cambridge: Cambridge University Press. DOI: 10.1017/CBO9780511809071. [ Links ]
Mora, M. G., Castillo, J. N. P. Una introducción a la Web semántica. Vínculos, Vol. 2, No. 4, Jun. 2013, pp. 19 - 30. [ Links ]
Moreno, A., Valls, A., Isern, D., Marin, L., Borràs, J. Sigtur/e-destination: ontology-based personalized recommendation of tourism and leisure activities. Engineering Applications of Artificial Intelligence, Vol. 26, No. 1, Jan. 2013, pp. 633 - 651. DOI: 10.1016/j.engappai.2012.02.014. [ Links ]
Niño, M. A., Cobos, C. A., & Mendoza, M. E. (2004). Unicauca Virtual: Metamodelos de Universidad Virtual y Herramientas de Soporte. Paper presented at the VII Congreso Iberoamericano de Informática Educativa, Mexico. [ Links ]
Shokouhi, M. (2013, Jul). Learning to personalize query auto-completion. Paper presented at the Proceedings of the 36th international ACM SIGIR conference on research and development in information retrieval, New York. DOI: 10.1145/2484028.2484076. [ Links ]
Sieg, A., Mobasher, B., & Burke, R. (2007, Nov). Web search personalization with ontological user profiles. Paper presented at the Proceedings of the sixteenth ACM conference on conference on information and knowledge management. DOI: 10.1145/1321440.1321515. [ Links ]
Siping, H., & Fang, M. (2008). Ontological User Profiling on Personalized Recommendation in e-Commerce. Paper presented at the 2008 IEEE International Conference on e-Business Engineering, Lausanne. [ Links ]
Slimani, T., Yaghlane, B. B., & Mellouli, K. A New Similarity Measure based on Edge Counting. World Academy of Science, Engineering and Technology, Vol. 23, No. 2006, pp. 34 - 38. [ Links ]
Troussov, A., Sogrin, M., Judge, J., & Botvich, D. (2008, Sep). Mining socio-semantic networks using spreading activation technique. Paper presented at the Proceedings of I-KNOW '08 and I-MEDIA '08, Graz, Austria. [ Links ]
Uschold, M., & Gruninger, M. Ontologies: Principles, methods, and applications. Knowledge Engineering Review, Vol. 11, No. 2, Jun. 1996, pp. 93-136. DOI: 10.1017/S0269888900007797. [ Links ]
Zuluaga, A. M. O., Franco, J. A. C., Valencia, L. F., & Ramos, A. C. MAIPU: Modelo de adaptación de información basado en perfil de usuario para personalizar las ventas de productos a través de portales Web. Revista Avances en Sistemas e Informática, Vol. 5, No. 3, 2008, pp. 93 - 100. [ Links ]
