











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
PermalinkIntroduction
Tree of Science (ToS) is a web-based tool that uses graph algorithms to optimize the search and selection of published papers. ToS was created at Universidad Nacional de Colombia (Robledo et al., Osorio-Zuluaga, and López-Espinosa, 2014), and the algorithm is explained elsewhere (Zuluaga et al., 2016). ToS is a specialized tool for researchers interested in tracking the way in which a particular topic evolves over time. Firstly, users must download Web of Science (WoS) query results. Then, they upload the file to ToS (tos.manizales.unal.edu.co). With this data, ToS shows the results in the form of a tree: root, trunk, and leaves. Papers in the roots are the classics, while those in the trunk are considered structural publications, and current papers are the leaves. In addition, ToS uses scientometric techniques to recommend relevant literature.
Scientometrics refer to the study of science, technology, and innovation from a quantitative perspective. Moreover, it focuses on the measurement of the impact of articles, journals, and institutions, along with the mapping of scientific areas (Leydesdorff, 2013). Examples include citation analysis (Koseoglu, Sehitoglu, and Craft, 2015), co-author analysis (loannidis, 2015), and the impact of institutions (Singh, Uddin, and Pinto, 2015). Thus, the importance of scientometrics is based on the possibility of identifying high impact articles and main researchers, and on recognizing emerging areas of knowledge (Hood and Wilson, 2001).
Scientometrics emerged in the 1930s with the analysis of the distribution frequency of productivity between chemistry and physics by Alfred J. Lotka (1926). After analyzing a number of publications, he concluded that the proportion of researchers making small contributions was 60%. Later, Derek J. de Solla Price (1963), known as the father of scientometrics, formulated Price's Law, which explains that 25% of scientific authors are responsible for 75% of published articles (preferential attraction model). Finally, another important initial contribution in this field was the h-index (Garfield, 1972; Hirsch, 2005), which measures the impact of papers and is well known in the scientific community nowadays. Consequently, these results showed patterns in the scientific world, which can be identified by mathematical and statistical analysis.
Currently, thanks to advances in technology, such as the Internet, it is possible to apply and develop sophisticated scientometric techniques in different fields. For example, a study in nanotechnology and nanoscience shows metrics such as the annual growth rate, authorship patterns, and an index of collaboration (Karpagam, Gopalakrishnan, Natarajan, and Ramesh Babu, 2011). Another investigation in bioenergy from biomass explains the exponential growth and changes in this field (Konur, 2012). Therefore, scientometrics have been a useful tool in recent years to identify emerging areas of science.
Although scientometrics have evolved in the last few years, one of the main challenges is to find accurate methods for the characterization of a scientific area (Koseoglu, Sehitoglu, and Craft, 2015). For this reason, various researchers have proposed other indexes to determine the impact of publications. These include the CDS-index (Vinkler, 2011), multivariate analysis techniques, time series (Leydesdorff, 2013) , and modeling techniques (Mutschke and Mayr, 2014) . However, co-citation analysis has become a well-established topic in scientometrics to identify "sleeping beauty publications" (Fang, 2019 p. 307). Examples of applications of this scientometric techniques are found in reviews about obesity (Landinez, Robledo, and Montoya 2019), Corporate Social Responsibility (Duque and Cervantes-Cervantes, 2019), and in agriculture (Robledo-Buriticá, Aguirre-Alfonso, and Castaño-Zapata, 2019).
During the last years, some graph algorithms have been implemented in co-citation analysis to select relevant literature. For instance, HITS algorithm (Kleinberg, 1999) was applied to reduce ranking bias (Jiang et al. 2016) and Google's PageRank algorithm, to find the most prestigious papers (Chen et al. 2007). Nevertheless, much uncertainty still exists about tracking global knowledge using co-citation analysis (Parolo, Kujala, Kaski, and Kivela, 2019). Hence, this study seeks to improve the ToS algorithm to streamline the research process on a specific topic, in order to fulfill the need for non-conventional literature review techniques (Alulema and Largo, 2019) that other studies have proposed (Sepúlveda and Cravero, 2015).
This paper is structured as follows: First, a few basic definitions about graph theory are presented. Secondly, the methodology is described, detailing the algorithm step by step. Next, the SAP algorithm is applied to create a graph of citation analysis about Word-of-Mouth Marketing, in order to compare it with the current ToS results. Finally, conclusions are addressed, and limitations and implications are discussed.
Some basic definitions
Some basic definitions about graph theory are explained below, according to Johnsonbaugh (1999):
Definition 1 (undirected graph): A graph (or undirected graph) consists of a set of vertices V and a set of edges E, arranged in such a way that each edge e Є E is associated with an unordered pair of vertices. If there is a unique edge e associated with the vertices v and w, it is written as follows: e = (v, w) or e = (w,v). In this context, (v,w) denotes an edge between v and w in an undirected graph and not an ordered pair.
Definition 2 (directed graph): A directed graph (or digraph) G consists of a set of vertices V and a set of edges E, arranged in such a way that each edge e Є E is associated with an ordered pair of vertices. If there is a unique edge e associated with the ordered pair (v, w) of vertices, it is written as follows: e = (v, w), which denotes an edge from v to w, where v is the initial vertex and w is the terminal vertex of the edge e.
Definition 3 (indegree and outdegree of vertex): Let v be a vertex of a directed graph G. The degree of entry of v, denoted by indegree (v), is the number of edges in G with terminal vertex v. The degree of output of v, denoted by outdegree (v), is the number of edges in G whose initial vertex is v.
Definition 4 (subgraph): Let G = (V, E) a graph. G' = (V\E') is a subgraph of G if:
1. V' ⊆ Vand E' ⊆ E.
2. For each edge e' Є E', if e' is incident on v' and w', then v', w' Є V'.
Definition 5 (connected graph): A graph G is connected if there is a walk between every pair of distinct vertices in the graph.
Definition 6 (connected component): A connected component of a graph G isa connected subgraph S of G such that no other connected subgraph of G contains S.
Data
In order to test the algorithm, we used data from Web of Science (WoS). This dataset contains information about articles published by journals from different areas of knowledge. From it, we can extract the citation relationships between papers, authors, publication dates, journals, volume, page, and the Digital Object Identifier (DOI). Similarly, we can create a citation graph with the papers and their references (Zuluagaetal., 2016).
SAP Algorithm
The SAP algorithm was implemented in Python with the graph package igraph. The operation of SAP is explained below.
Description
1. The SAP algorithm consists in six steps: From a subset of papers V, which is obtained from WoS, a directed graph G = (V, E), with all the papers and references is generated, where each directed edge (i, j) of E is a citation from paper p i to p j .
2. Graph G is filtered:
2.1 The largest connected component is obtained.
2.2 Loops are eliminated from the graph obtained in
(2.1).
2.3 Duplicated edges are removed from the graph obtained in (2.2).
2.4 Vertices with indegree 1 and outdegree 0 are eliminated, along with their edges, from the graph obtained in (2.3). This graph is noted by G' = (V',E').
Igraph Description:
2.1 Graph.clusters(), which shows the different components of the graph, and the giant() function are used to select the largest component.
2.2 and 2.3. Graph.simplify() is used to remove repeated loops and edges.
2.3 Graph.vs.select() is used to select the vertices that do not have indegree 1 and outdegree 0.
3. Root classification:
3.1 Vertices with outdegree 0 are selected from V'.
3.2 V root is defined as the set of all vertices obtained in (3.1).
3.3 If r is a root, its SAP is defined as its indegree
Igraph Description:
3.1 Graph.vs.select() is used to choose the vertices with outdegree 0.
3.2 Indegree() is used to determine the input degree
4. Leaves classification:
4.1 Vertices with indegree 0 are selected from V ' .
4.2 V extended leaf is defined as the set of all vertices obtained in (4.1).
4.3 Vertices whose age (time since publication) is not less than the newest vertex age less 5 of V extended leaf , are selected from the vertices obtained in (4.1).
4.4 leaf is defined as the set of all vertices obtained in (4.3).
4.5 If v belongs to V extended_leaf , its SAP is defined as the number of pahts that exist between v and the roots.
Igraph Description:
4.1 Graph.vs.select() is used to choose the vertices with indegree 0.
4.5 Graph.shortest_paths_dijstra() is used to identify paths between the vertices of (V lea f U V extended leaf ) and the roots.
5. Trunk classification
5.1 Vertices of V root are selected.
5.2 Vertices of (5.1) are sorted in descending order according to their SAP value.
5.3 V root selected is defined as the first 10 vertices obtained in (5.2).
5.4 Vertices of V leaf are selected.
5.5 Vertices of (5.4) are sorted in descending order according to their SAP value.
5.6 V leaf selected is defined as the first 60 vertices obtained in (5.5).
5.7 All the vertices that belongs to at least one path between V root selected and V leaf selected , are selected.
5.8 V trunk is defined as the vertices obtained in (5.7).
5.9 If f is a trunk, its SAP is defined as the sum of the SAPs of the vertices that belong to (Vroot selected) ∪ V leaf selected , and are connected with t by one or more paths.
5.10 Vertices whose age (time since publication) is not older than the newest vertex of V trunk , are selected from the vertices obtained in (5.8).
5.11 Vpotential leaf is defined as the set of all the vertices obtained in (5.10).
Igraph Description
5.1 And 5.4 Graph.vs.select() is used to choose the vertices.
5.2 Graph.get_all_simple_paths() is used to select the vertices between V root selected and V leaf selected to save trunk vertices and compute its SAP.
6. Tree construction: Subgraph G = (V, E) of G' = (V',E'), where V = (Vroot ∪ V leaf ∪ V trunk ), and E is considered a subset of the edges of E' which only affects the vertices of V is called "Tree of Science" (Robledo et al. 2014).
Application
We compared the results from the ToS with the SAP algorithm to illustrate its operation. The similarities and differences between the two procedures are presented here.
The first step is to define the research topic, in order to obtain the data from WoS. In this case, Word-of-Mouth Marketing (WOMM) is used as the search equation for the time period from January 2001 to August 22, 2017.
Title = (marketing) AND Topic = (Word of Mouth) Indexes: SCI-EXPANDED, SSCI, A&HCI
Exactly 317 papers were extracted with these references. With this data, both algorithms were applied in order to identify the SAP improvements. Table 1 shows the difference between them. The results in the roots and trunk of both algorithms are similar: 90% and 70% respectively. However, ToS performs better in terms of number of citations: 2,819 results in the roots and 1,752 in the trunk. Despite this, SAP has an outstanding performance with more than three times the citation results from ToS.
Table 1 Differences between ToS and SAP algorithm
| Similarities | Root | Trunk | Leaves | |
| 90% | 70% | 23% | ||
| Differences in citations | ToS | 2 819 | 1 752 | 741 |
| SAP | 666 | 1 001 | 2 442 | |
Source: Authors
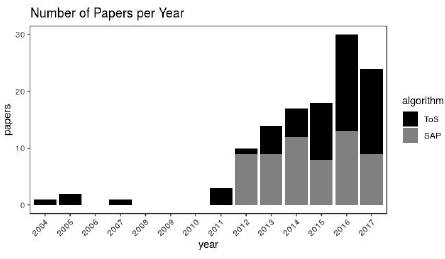
Another important result of the SAP is the age of the papers on the leaves. According to Robledo et al. (2014), leaves are current papers, and a quality indicator of an investigation is the number of recent references. Moreover, Price (1976) suggests that at least 50% of the references should be from the past five years. The SAP meets this requirement by selecting papers from the past five years for the leaves (Figure 1).
Conclusions
ToS is a scientometric tool which performs the citation analysis of a graph and shows the results in a form of a tree: root, trunk, and leaves. Most of the results presented by ToS are relevant and important (Robledo et al. 2014). However, there is a lack of precision in the leaves; sometimes publications are not connected to the roots and trunk, and additionally, the leaves are occasionally not current literature. Thus, the goal of this study is to propose a new algorithm called SAP, which improves the results in the leaves.
Results show that SAP is more accurate in this field. It presents the most important current literature. However, this study is limited, and so it must be further expanded, for example, to the evaluation both of different research topics and indicators, in order to understand the pros and cons of the new algorithm.

