










Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Citado por Google
Citado por Google -
 Similares em
SciELO
Similares em
SciELO -
 Similares em Google
Similares em Google
Compartilhar

 Permalink
PermalinkRevista Facultad de Ingeniería Universidad de Antioquia
versão impressa ISSN 0120-6230versão On-line ISSN 2422-2844
Rev.fac.ing.univ. Antioquia n.42 Medellín out./dez. 2007
Rev. Fac. Ing. Univ. Antioquia. N.o 42. pp. 105-119. Diciembre, 2007
Clasificación de grupos de investigación colombianos aplicando análisis envolvente de datos
Ranking Colombian research groups applying Data Envelopment Analysis
María Isabel Restrepo R, Juan Guillermo Villegas R*
Departamento de Ingeniería Industrial, Facultad de Ingeniería, Universidad de Antioquia, Calle 67 N. º 53-108, oficina 21-435, Medellín, Colombia.
(Recibido el 25 de mayo de 2007. Aceptado el 10 de agosto de 2007)
Resumen
En este artículo se aplica el análisis envolvente de datos (DEA) como herramienta para la medición de productividad y posterior clasificación de los grupos de investigación colombianos. Para llevar a cabo dicha clasificación se implementaron modelos DEA basados en supereficiencia y eficiencia cruzada combinados con análisis de conglomerados. Los modelos propuestos se aplicaron al caso de los grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia con resultados prometedores.
---------- Palabras Clave: medición del desempeño, análisis envolvente de datos, productividad académica, supereficiencia, eficiencia cruzada.
Abstract
Data Envelopment Analysis (DEA) is presented as a tool for productivity assessment and classification of research groups. DEA models based on super-efficiency and cross efficiency together with cluster analysis for this classification were implemented. The proposed models were applied in the case of the Engineering research groups at Universidad de Antioquia.
---------- Key words: Performance measurement, Data Envelopment Analysis, Academic productivity, Super-efficiency, Cross Efficiency.
Introducción
Desde el año 2004, Colciencias Instituto Colombiano para el Desarrollo de la Ciencia y la Tecnología Francisco José de Caldas viene realizando la clasificación de los grupos de investigación colombianos usando el índice ScientiCol [1] el cual mide y pondera la producción de los diferentes grupos de investigación en tres grandes categorías: productos o resultados que generan nuevo conocimiento (artículos de investigación, libros de investigación, productos o procesos tecnológicos patentados o registrados, etc.), productos relacionados con formación de investigadores (tesis y trabajos de grado; y participación en programas académicos de posgrado) y productos relacionados con la apropiación social del conocimiento (servicios técnicos o consultoría cualificada, productos de divulgación o popularización de resultados de investigación).
Este tipo de políticas han generado una dinámica importante en los grupos de investigación; para junio de 2006, 2.057 grupos habían sido reconocidos oficialmente, y de estos el 86% estaba clasificado en alguna de las tres categorías que usa Colciencias para evaluar la madurez y producción de un grupo de investigación (A, B o C) [2].
Sin embargo, al analizar el índice utilizado aparecen algunas objeciones de miembros de la comunidad académica nacional [3]: no se incluye el número de miembros de un grupo en los cálculos, el umbral definido para clasificar en las tres categorías es demasiado bajo y no permite clasificar realmente los grupos que estén por encima de éste, no es claro por qué se incluyen dos veces los productos de mayor calidad (tipo A) y no se considera la citación de los productos de nuevo conocimiento.
En el índice también es necesario revisar: la necesidad de fijar ponderaciones a priori, la ausencia de información que permita a los grupos conocer los productos en los que deberían mejorar para clasificarse mejor y la ausencia de estrategias que identifiquen grupos de investigación sobresalientes que puedan ser tomados como referencia. Finalmente, el origen del umbral (fijo) para clasificar los grupos en las diferentes categorías (un grupo típico de cuatro investigadores y una producción equivalente de dos artículos de alto nivel tipo A [1]), que no toma en cuenta la información de los grupos por evaluar, puede hacer que se convierta en una meta subvalorada fácil de cumplir, como parece según el análisis realizado por Duitama [3]. Con metodologías alternativas como las que se proponen en este artículo se pueden resolver algunas de estas objeciones.
El análisis envolvente de datos (DEA) se ha utilizado ampliamente para la medición de eficiencia en el ámbito académico y educativo. En este artículo se analiza su utilidad como alternativa para la clasificación de los grupos de investigación colombianos. Para ello se aplicaron algunos de los modelos de clasificación tradicionales de DEA al caso de los grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia.
Este artículo está organizado de la siguiente manera: inicialmente se introduce DEA y se presentan los trabajos previos relacionados con la medición de productividad investigativa y académica; luego se describen las metodologías empleadas en DEA para clasificar las unidades organizacionales evaluadas y se presentan los resultados de una prueba piloto de dichas metodologías aplicadas en la clasificación de los grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia, y finalmente en la sección cinco se presentan las conclusiones, posibles extensiones y oportunidades de investigación futura.
Revisión de la literatura
El análisis envolvente de datos, conocido como DEA (del inglés Data Envelopment Analysis) es una técnica no paramétrica para la medición de la eficiencia relativa de unidades organizacionales en situaciones donde existen múltiples entradas y salidas. Los orígenes de DEA se remontan a los años 70, cuando A. Charnes, W. W. Cooper y E. Rhodes [4] desarrollaron la técnica. Desde su introducción la investigación en DEA ha sido prolífica, tanto en el ámbito teórico como aplicado, en la bibliografía disponible [5] se cuentan más de 2.000 trabajos en diversas áreas, tales como: medición de procesos logísticos, selección de equipos industriales, regulación de servicios públicos, estudios sectoriales, entre otras.
Las entidades que son evaluadas con DEA se conocen como DMU (Decision Making Units), término que permite referirse a un grupo amplio de unidades organizacionales que pueden ser divisiones de una organización, empresas, entes territoriales e incluso países. Supóngase que se van a evaluar n DMU, cada una consume diferentes cantidades de las m entradas para producir s salidas. La DMU j consume la cantidad xij de la entrada i y produce la cantidad yrj de la salida r.
Para medir el desempeño de la DMU o se resuelve un problema de optimización, que busca maximizar la razón de sus salidas entre sus entradas. Como se tienen múltiples entradas y múltiples salidas se construye una salida virtual y una entrada virtual usando ponderaciones ur y vi para cada salida y cada entrada, respectivamente. Adicionalmente, como es usual en la medición del desempeño, ninguna DMU (incluida la DMU o) puede tener una eficiencia mayor al 100%. Se tiene entonces, el siguiente problema de optimización:

Al modelo descrito por las expresiones 1 y 2 se le conoce como modelo CCR, en forma de razón, por la expresión utilizada en su función objetivo y restricciones. El programa fraccional 1-2 puede linealizarse transformándose en uno de programa lineal, resultando el siguiente modelo:

A este segundo modelo se le conoce como CCR en el espacio de los multiplicadores, donde las variables de decisión son los valores de u y v que serán utilizados para ponderar cada una de las entradas y salidas en la construcción de la entrada y la salida virtual de la expresión 1. El programa lineal formulado en 3-7 tiene un problema dual asociado:

Este último modelo de DEA es conocido como CCR en el espacio de la envolvente, en él se mide el desempeño de la DMU o (θ) como la contracción radial de las entradas que es posible realizar (9) garantizando que se obtiene un nivel mínimo de salidas (10) Para lograrlo se utiliza una DMU virtual que es una combinación lineal de las entradas (9) y salidas (10) de todas las DMU, construida usando las variables λ j (11).
Los modelos de DEA descritos previamente se caracterizan por estar orientados a entradas, ya que la mejora en el desempeño se logra contrayendo las entradas (9). También es posible obtener un modelo DEA orientado a las salidas, el cual se obtiene minimizando el inverso de la expresión 1. Una transformación similar a la realizada al modelo 1-2 da lugar al siguiente programa lineal:

El programa lineal 13-17 se conoce como CCR orientado a salidas (CCR-O) en el espacio de los multiplicadores. Es interesante ver cómo para orientar la evaluación a salidas no es necesario realizar transformación alguna a los datos. El problema dual asociado con el modelo 13-17 es:

El modelo 18-22 se conoce como CCR orientado a salidas en el espacio de la envolvente, y busca maximizar la salida que se puede obtener dado un nivel máximo de entradas.
Existen otros modelos de DEA en los cuales se exploran rendimientos variables a escala, entradas no discrecionales, salidas no deseables y muchas otras alternativas. El lector interesado en ampliar el conocimiento relacionado con DEA, sus modelos básicos, fundamentos y aplicación puede recurrir a la referencia [5].
DEA para la medición de eficiencia de unidades académicas
DEA se ha utilizado ampliamente en el sector público y privado nacional e internacional. Algunas de las aplicaciones más importantes en el ámbito universitario han permitido la medición de la eficiencia y comparación de departamentos académicos [6], universidades [7] y proyectos o grupos de investigación [8, 9, 11, 12], entre otros.
Johnes y Johnes [8] utilizaron DEA para comparar y evaluar el desempeño investigativo de los departamentos de economía del Reino Unido, el modelo utilizado considera como salidas las publicaciones de los miembros de los departamentos en diferentes revistas académicas y como entradas el número de profesores, se realizaron estudios con más entradas y salidas demostrándose que la metodología es bastante robusta en cuanto a la elección de los datos (entradas y salidas). También se discute el impacto que tiene la financiación externa en la medición de la eficiencia y su consideración como entrada o como salida. Además se realizaron comparaciones con los resultados obtenidos por el UFC (University Funding Council) con correlaciones aceptables.
Korhonen et al. [9] usaron DEA para medir la eficiencia investigativa de los departamentos de la Escuela de Economía y Administración de Negocios de Helsinki. Para realizar el análisis se definieron cinco criterios para evaluar la investigación: calidad de la investigación, actividades de investigación, impacto de la investigación, educación de investigadores jóvenes y actividad en la comunidad científica. Para cada criterio se utilizaron indicadores apropiados que fueron ponderados usando el proceso analítico jerárquico [10]. Los modelos DEA utilizados tienen retornos variables a escala y algunas extensiones que permiten incorporar preferencias.
Guang y Wang [11] desarrollaron un nuevo modelo de DEA que permite evaluar la eficiencia de proyectos de investigación en ciencias de la información, el modelo fue utilizado para evaluar 21 proyectos de la República Popular China. Como entradas se utilizaron el tamaño de los grupos y su presupuesto, como salidas se tomaron las publicaciones internacionales indexadas y algunos indicadores de citación de dichas publicaciones (total de citas, citas promedio por artículo, etc.). El modelo desarrollado permite evaluar las eficiencias y clasificar los grupos de investigación. También se realizó un estudio de los grupos más eficientes para identificar las prácticas de gestión del conocimiento que utilizan.
Finalmente, Arenas et al. [12] aplicaron un modelo básico de DEA a los grupos de investigación de la Universidad Tecnológica de Pereira. Las entradas fueron el número de investigadores de cada grupo y las salidas los productos de nuevo conocimiento. Los resultados obtenidos se compararon con la clasificación realizada por Colciencias en 2004 con resultados similares. A diferencia de los modelos presentados en este artículo, los modelos utilizados en [12] son (en principio) modelos que solo evalúan las DMU, no son modelos con los que se puedan clasificar los grupos evaluados (modelos para ranking y clasificación). Además, en [12] se comparó el resultado de la eficiencia obtenida por medio de un modelo básico de DEA con la clasificación de los grupos realizada por Colciencias, mientras que en este artículo se propone la clasificación de los grupos primero evaluándolos, luego clasificándolos por medio de modelos DEA para ranking y fifinalmente agrupándolos con análisis de conglomerados.
Modelos DEA para la clasificación de grupos de investigación
El objetivo original de DEA es medir la eficiencia relativa de las DMU; sin embargo, existen varios métodos que extienden DEA para clasificar las DMU [13]. Algunos métodos importantes son: eficiencia cruzada [14], supereficiencia [15] y benchmarking [16]. En este artículo se utilizan dos métodos diferentes para clasificar las DMU: eficiencia cruzada por ser el primero que se desarrolló en DEA para clasificación de las DMU y porque con este se evalúan las DMU no solo con sus propios pesos sino también con los pesos de las otras unidades, y supereficiencia por ser el método más implementado en software comercial [13]. Estos dos métodos se describen a continuación.
Eficiencia Cruzada
El método basado en la eficiencia cruzada fue el primero de los enfoques desarrollados en DEA para clasificar las DMU [14] y se ilustra ampliamente en Doyle y Green [17]. Este método calcula los puntajes de DEA n veces para cada DMU, utilizando para ello los pesos óptimos obtenidos al evaluar cada una de las n DMU. Los resultados pueden resumirse usando una matriz de eficiencia cruzada, cuyos elementos se calculan aplicando la expresión 23:

El valor de Ekj se obtiene al evaluar la DMU j con los pesos óptimos para la DMU k. Así, en la diagonal de la matriz se tienen los valores de eficiencia originales. El puntaje de eficiencia cruzada para la DMU j se define como:

Donde CEj es el promedio de las eficiencias cruzadas obtenidas por la DMU j al utilizar los pesos óptimos de las demás DMU. El problema de optimización 3-7 puede tener óptimos alternos, con diferentes valores de u y v, esto hace que puedan tenerse varios valores de eficiencia cruzada. Para resolver esta situación, una vez evaluada la DMU o, se resuelve un segundo problema de optimización que busca minimizar o maximizar la suma de las eficiencias cruzadas de las demás DMU, según el enfoque que se escoja: benevolente (máx.) o agresivo (mín.). En este trabajo se decidió utilizar modelos de eficiencia cruzada benevolentes orientados a salidas según lo descrito por Doyle y Green [17]. Es razonable pensar que la orientación adecuada es a salidas, ya que un grupo de investigación ineficiente difícilmente buscaría reducir sus recursos para lograr la eficiencia y mejor buscaría aumentar sus productos. La formulación de dicho modelo es la siguiente:

En este modelo 25-30 se busca encontrar los pesos de las entradas y salidas tales que se maximice la función objetivo 25, la cual representa el desempeño ponderado del conjunto de DMU, excluyendo la unidad k. Las restricciones 26 y 27 garantizan que los pesos para las entradas y salidas encontrados en el proceso de optimización estén relacionados con la eficiencia simple de la DMU k (ηk*) obtenida usando un modelo CCR orientado a salidas, en 28 se garantiza que la eficiencia de cada DMU j, j ≠ k sea menor o igual a uno, por último en 29 y 30 se garantiza la no negatividad de las variables de decisión.
Supereficiencia
Esta idea desarrollada por Andersen y Petersen [15] consiste en eliminar del problema 1-2 la restricción 2 correspondiente a la DMU en evaluación o, esto hace posible que las DMU eficientes obtengan valores de eficiencia superiores a uno. Este método es utilizado para clasificar las DMU eficientes y para detectar observaciones atípicas o para realizar análisis de sensibilidad. El modelo que se utilizó en este trabajo es el siguiente:

La base para este modelo es un CCR orientado a salidas en el espacio de la envolvente, en éste, la eficiencia η no tiene que cumplir con la restricción η ≥ 1. Para las DMU ineficientes, se tomaron los valores de eficiencia como puntaje de clasificación.
Prueba piloto: clasificación de los grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia con DEA
En total se recopilaron los datos de los 16 grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia, que estaban clasificados en alguna categoría A, B o C de Conciencias en el mes de noviembre de 2006. Siendo este un estudio piloto de la metodología se prefirió eliminar lar referencias explicitas a los nombres de los grupos de investigación (usando letras mayúsculas para identificarlos). La información utilizada corresponde a laregistrada en el GrupLAC [18] de cada uno de los grupos de investigación.
Para probar las metodologías basadas en DEA como herramienta para clasificar grupos de investigación se utilizaron los modelos descritos anteriormente. Los modelos de optimización necesarios fueron implementados usando la herramienta para análisis envolvente de datos desarrollada por Restrepo y Villegas [19]; esta herramienta utiliza el Toolbox de optimización de Maltab®, su diseño permite ampliar los modelos básicos de DEA, para incluir las extensiones tal como se hizo en este trabajo con los modelos de eficiencia cruzada y supereficiencia.
A diferencia del enfoque utilizado por Conciencias que solo evalúa según los productos de cada grupo, en este trabajo se utilizaron el tamaño y la experiencia como entradas. Para medir el tamaño se usó el número de integrantes; para medir la experiencia se utilizó el número de años desde su creación. Esto supone que a un grupo de mayor tamaño o con mayor trayectoria se le exigirá una mayor cantidad de productos que a un grupo pequeño o con menor experiencia.
Se utilizaron cinco salidas diferentes; tres para medir la producción de conocimiento: artículos de investigación, capítulos de libro y libros de investigación, una para medir la formación de nuevos investigadores: tesis y trabajos de grado y una para reunir los productos relacionados con la apropiación social del conocimiento: productos de divulgación o popularización de resultados de investigación. La información correspondiente a los 16 grupos de investigación se resume en la tabla 1.
Se realizó un análisis de correlación entre las variables de entrada y salida. Los resultados se encuentran en la tabla 2, y en ella se puede observar que aunque algunas correlaciones son altas por ejemplo la de artículos de investigación con tesis y trabajos de grado, aunque las dos variables miden dimensiones de la investigación diferentes y se considera conveniente conservarlas, en los modelos posteriores de clasificación se analizará el impacto que pueda tener la eliminación de algunas de ellas. Igualmente, la baja correlación entre las variables de entrada (número de integrantes y años de actividad) sustenta la utilización de ambas.
Inicialmente, para evaluar la eficiencia de los 16 grupos de investigación se utilizó un modelo CCR orientado a salidas en el espacio de la envolvente con retornos constantes a escala, ya que los modelos con retornos variables a escala presentan problemas de infactibilidad al momento de realizar la clasificación de las DMU con supereficiencia [20]. Se eligió la orientación a salidas porque en el caso de los grupos de investigación es mejor que aumenten su producción (salidas) en vez de reducir sus entradas, además si se trabaja con un modelo CCR el resultado de la eficiencia es el mismo sin importar la orientación.
En el modelo se consideraron todas las entradas y salidas propuestas. Los resultados se presentan en la tabla 3, donde la primera columna corresponde al nombre del grupo, la segunda a la eficiencia obtenida y la tercera a los grupos de investigación utilizados en la combinación lineal que evalúa al grupo de investigación con sus respectivos λj. (lo que se conoce en DEA como conjunto de referencia). La evaluación fue realizada con la herramienta para DEA en Matlab® desarrollada por Restrepo y Villegas [19].
Un 56,3% (9) de los grupos evaluados resultaron eficientes, y en total se presentó una eficiencia promedio del 82,9%. Esta cantidad tan alta de grupos eficientes debe tomarse con precaución considerando el reducido número de DMU disponibles.
Para que DEA tenga un mayor poder de discriminación se recomienda tener un número de DMU de por lo menos dos veces el producto del número de entradas y salidas consideradas, si no, se corre el riesgo de que muchas de las DMU sean evaluadas como eficientes, no porque realmente lo sean sino por los pocos grados de libertad que tiene el modelo [21]. En este caso se tienen 16 y no se cumple con dicho criterio, sin embargo se decidió continuar con el análisis de la metodología, además algunos modelos que se analizarán más adelante (con menos salidas) sí cumplen con esta recomendación. Se espera que en una prueba posterior se pueda cumplir holgadamente este principio, para superar esta limitación y poder asegurar que DEA es una buena herramienta para la evaluación de los grupos de investigación.
Tabla 1 Entradas y salidas de 16 grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia
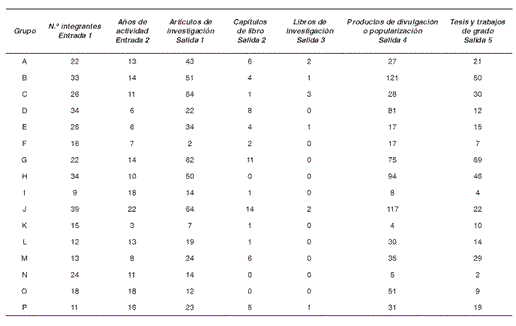
Tabla 2 Correlación entre las variables de entrada y salida de 16 grupos de investigación de la Facultad de Ingeniería de la Universidad de Antioquia
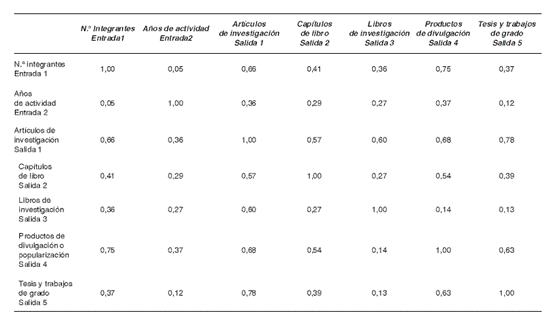
Tabla 3 Resultados modelo CCR orientado a salidas para los 16 grupos evaluados

Algunos grupos eficientes son más importantes al momento de evaluar los grupos ineficientes. Esto se evidencia en el número de veces que aparecen en el conjunto de referencia tabla 4. Los grupos G, B y D sirven varias veces como referencia, mientras que otros, que también fueron declarados eficientes, no participan en la evaluación de los demás (A, E, H, J y P). Esta podría ser una primera herramienta para la clasificación de los grupos eficientes dándole una mejor clasificación a los grupos eficientes que aparecen más veces en la evaluación de los demás. Es importante resaltar aquí la primera ventaja de DEA sobre la metodología utilizada por Colciencias, en este trabajo, no fue necesario fijar umbrales o criterios de ponderación previos para los productos. El desempeño de un grupo ineficiente no se determinó con base en umbrales fijos y externos sino con base en el desempeño de los grupos de investigación más eficientes (que hacen parte de la población analizada).
Tabla 4 Grupos eficientes, conteo del número de apariciones en los conjuntos de referencia

Además a cada grupo de investigación ineficiente se le sugiere una combinación de entradas  y salidas
y salidas  necesaria para alcanzar la eficiencia (lo que en DEA se conoce como proyección), calculada con las expresiones 36 y 37:
necesaria para alcanzar la eficiencia (lo que en DEA se conoce como proyección), calculada con las expresiones 36 y 37:

Donde  y
y  son los valores óptimos de las holguras obtenidos en la segunda fase de los modelos DEA [5]. Siendo el modelo utilizado uno orientado a salidas los valores más importantes son las salidas necesarias para lograr la eficiencia, los cuales se muestran en la tabla 5. Así, por ejemplo, el grupo M que tiene una eficiencia del 95% debería aumentar en (aproximadamente) 11 el número de artículos de investigación, en 8 los productos de divulgación y en 10 las tesis y trabajos de grado, para ser evaluado como eficiente. Mientras que el grupo N, que es el de menor eficiencia debería casi cuadriplicar su producción en artículos, y aumentar todavía más el trabajo en divulgación de sus resultados (pasando de 5 a 74 productos de divulgación o popularización) y en formación de investigadores (pasando de 2 a 53 trabajos de grado).
son los valores óptimos de las holguras obtenidos en la segunda fase de los modelos DEA [5]. Siendo el modelo utilizado uno orientado a salidas los valores más importantes son las salidas necesarias para lograr la eficiencia, los cuales se muestran en la tabla 5. Así, por ejemplo, el grupo M que tiene una eficiencia del 95% debería aumentar en (aproximadamente) 11 el número de artículos de investigación, en 8 los productos de divulgación y en 10 las tesis y trabajos de grado, para ser evaluado como eficiente. Mientras que el grupo N, que es el de menor eficiencia debería casi cuadriplicar su producción en artículos, y aumentar todavía más el trabajo en divulgación de sus resultados (pasando de 5 a 74 productos de divulgación o popularización) y en formación de investigadores (pasando de 2 a 53 trabajos de grado).
Tabla 5 Grupos ineficientes: proyección a la frontera eficiente

Clasificación de los grupos de investigación usando modelos con supereficiencia
La tabla 6 resume los resultados obtenidos al aplicar los modelos con supereficiencia descritos. Los grupos que reciben un mayor puntaje (mejor clasificación) son los grupos D, C y G (en ese orden), grupos que también resultan bien evaluados si se considera el número de veces que aparecen en el conjunto de referencia de los grupos ineficientes. Con este segundo método, aparece como importante el grupo P. Luego aparece el grupo B que también fue importante en el conteo de la tabla 4.
En un resultado similar al del conteo aparecen después los grupos eficientes E, H, J y A y finalmente los grupos ineficientes según su eficiencia original (ya que en los modelos con supereficiencia este resultado no cambia).
Clasificación de los grupos de investigación usando eficiencia cruzada
Finalmente, se utilizó un modelo de eficiencia cruzada benevolente orientado a salidas. Nótese, que la eficiencia cruzada toma valores entre 0 y 1, siendo mejores los valores cercanos a 1. Las eficiencias cruzadas obtenidas se resumen en la tabla 7.
Nuevamente, los grupos G y B son clasificados de primeros (algo que era de esperarse según lo observado cuando se realizó el conteo de la tabla 4). Los grupos J y M que antes no tenían buenas clasificaciones logran estar en los primero lugares (por ejemplo, M es ineficiente, sin embargo al aplicar las ponderaciones óptimas de los demás grupos logra buenas evaluaciones en la mayoría de los casos). El grupo C sigue estando en los primeros lugares. El grupo que ha estado en los últimos lugares (N), y los últimos seis grupos siguen siendo los mismos (O, L, K, I, F, N), con algunos intercambios de posición.
Tabla 6 Resultados modelo DEA con supereficiencia para los 16 grupos evaluados

Tabla 7 Eficiencia cruzada para los 16 grupos evaluados

A pesar de que las clasificaciones obtenidas con los tres métodos (conteo, supereficiencia y eficiencia cruzada) son similares, se decidió continuar solamente con el método que utiliza eficiencias cruzadas. Se tomó está decisión porque la eficiencia cruzada permite evaluar un grupo de investigación no solo con sus ponderaciones, sino también con las ponderaciones óptimas de otros grupos. Haciendo que grupos que no son eficientes pero que están cerca de serlo obtengan buenas clasificaciones (como el caso del grupo M). También permite clasificar mejor grupos que no son representativos al momento de evaluar a los demás (P) pero que cuando se aplican modelos con supereficiencia obtienen puntajes altos. Además recientemente han aparecido reparos a la clasificación con modelos de supereficiencia y se sugieren como herramienta para la detección de DMU atípicas y no de clasificación [22].
Parte de la discusión al momento de medir la eficiencia está relacionada con la elección de las entradas y salidas que caracterizarán el desempeño de una DMU. El caso de los grupos de investigación no escapa a esta situación. Para analizar la robustez de este método, se realizó una comparación de las medidas de eficiencia cruzada cuando se eliminan algunas de las salidas; los resultados se presentan en la tabla 8. En adelante al modelo con eficiencia cruzada y las cinco salidas se les llamará eficiencia cruzada base. Diez de los 16 grupos de investigación no tienen libros de investigación, cuando se eliminan los libros de las salidas la clasificación obtenida es muy similar a la obtenida con la eficiencia cruzada base (columna 2 de la tabla 8) tienen un coeficiente de correlación de Kendall [23] τ = 0,82 con el modelo de eficiencia base. Por último se probó un modelo de eficiencia cruzada bastante simple, que solamente requiere los artículos de investigación, los productos de divulgación y las tesis y trabajos de grado, éste tiene un índice de correlación de Kendal τ = 0,71 con el modelo de eficiencia cruzada base. En todos los modelos probados en la tabla 8, el índice de correlación de Kendall indica una clasificación similar entre los dos modelos y el modelo de eficiencia cruzada base, con niveles de confi anza superiores al 99%.
Tabla 8Clasificación con eficiencia cruzada eliminando salidas

Clasificación de los grupos de investigación usando DEA y análisis de conglomerados
DEA se usa algunas veces en conjunto con metodologías de estadística univariada y multivariada como herramientas complementarias [5]. En este caso se usó el análisis de conglomerados con distancia euclidiana y criterio de agrupación distancia media entre centroides [24] para la clasificación de los grupos en diferentes categorías (para obtener un resultado análogo al que se obtiene con el índice Scienticol). Utilizando los resultados de un modelo CCR-O que tiene solo tres productos (artículos de investigación, productos de divulgación o popularización y tesis y trabajos de grado) y la eficiencia cruzada obtenida con los mismos productos, se agruparon los grupos en tres categorías.
Los resultados obtenidos con los dos modelos DEA se presentan en las dos primeras columnas de la tabla 9, la tercera columna de la tabla indica en cuál de las categorías fue clasificado cada grupo. La figura 1 ilustra dicha clasificación. Puede observarse cómo tres grupos (19%) que tienen una buena eficiencia CCR-O y también una buena eficiencia cruzada son clasificados en una sola categoría (los grupos de mejor desempeño), una segunda categoría la componen nueve grupos (56%) que son eficientes CCR-O y tienen una eficiencia cruzada media o que aunque no son eficientes tienen una eficiencia CCR-O aceptable y una buena eficiencia cruzada (los grupos con un desempeño intermedio). Y finalmente cuatro grupos (25%) que tienen un mal desempeño en la eficiencia CCR-O, en la eficiencia cruzada o en ambas, son clasificados en un tercer grupo.
Conclusiones
En este artículo se presentó DEA como una nueva metodología para la evaluación y clasificación de grupos de investigación. Por medio de una prueba piloto con varios grupos se pudo comprobar que los modelos DEA orientados a salidas, las extensiones implementadas para la clasificación y la integración con otras herramientas de estadística multivariada forman una metodología robusta y sencilla. Con el uso de DEA se observa que se pueden aliviar algunos de los problemas del índice ScientiCol, ya que en la metodología descrita aquí, cada grupo de investigación es libre de escoger los mejores pesos para sus productos, se pueden incluir en la evaluación entradas tan importantes como el tamaño del grupo y la experiencia del mismo. Igualmente, la evaluación de los grupos se realiza por comparación con los demás grupos que participan y no usando umbrales fijos. Además, para los grupos que no fueron bien evaluados se identifican el aumento necesario en sus salidas, y entre los grupos bien evaluados se identifican aquellos que tienen una mayor importancia.
En cuanto a las oportunidades de investigación y trabajos futuros, dada la flexibilidad de DEA se pueden implementar si es necesario, modelos DEA que en conjunto con otras metodologías (por ejemplo, AHP) incorporen ponderaciones que reflejen la importancia relativa de los diferentes productos en cada disciplina de conocimiento. Se espera también realizar una prueba con una muestra más grande, buscando que haya un mayor poder de discriminación en la evaluación. Así mismo, es necesario realizar análisis que estudien la sensibilidad de los resultados a omisión de componentes estocásticos, problemas asociados a errores de medida y los sesgos asociados a errores en la especificación.
Tabla 9 Clasificación de los grupos de investigación evaluados usando análisis de conglomerados


Figura 1 Eficiencia cruzada y eficiencia CCR-O para los 16 grupos de investigación evaluados
Referencias
1. Instituto Colombiano para el Desarrollo de la Ciencia y la Tecnología Francisco José de Caldas, Colciencias, Índice para la medición de Grupos de Investigación, Tecnológica o de Innovación mayo de 2006. http://zulia.colciencias.gov. co:8098/portalcol/downloads/archivosSoporteConvocatorias/ 1448.pdf. Consultado el 14 de marzo de 2007. [ Links ]
2. Colciencias (Dirección General), Resultados del reconocimientoy medición de grupos de investigación – primer semestre año 2006 http://zulia.colciencias.gov. co:8098/portalcol/downloads/archivosEventos/177.pdf. Consultado el 14 de marzo de 2007. [ Links ]
3. Duitama, John. F. Análisis del Índice ScientiCol http:// investigacion.udea.edu.co/archivos/documentos/analisisdelindicescienticol. pdf. Julio de 2006. Consultado el 14 de marzo de 2007. [ Links ]
4. A. Charnes. W. Cooper. E. Rhodes Measuring the efficiency of decision making units. European Journal of Operational Research. Vol. 2. 1978. pp. 429-444. [ Links ]
5. W. Cooper. L. Seiford. K. Tone. Introduction to data envelopment analysis and its uses: with DEA-solver software and references. Ed. Springer. 2006. 353 p. [ Links ]
6. J. E. Beasley. Comparing university departments. Omega, Vol. 18. 1990. pp. 171-183. [ Links ]
7. D. Visbal. Evaluación de la eficiencia relativa en el uso de recursos de las universidades públicas colombianas mediante la metodología Data Envelopment Analysis. CLAIO 2006, Programa extendido con Resúmenes. Montevideo: Héctor Cancela y María E. Urquhart. 2006. Vol. 1. p. 77. [ Links ]
8. J. Johnes. G. Johnes. Research funding and performance in U.K. University Departments of Economics: A frontier analysis. Economics of Education Review. Vol. 14. 1995. pp. 301-314. [ Links ]
9. P. Korhonen. R. Tainio. J. Wallenius. Value efficiency analysis of academic research. European Journal of Operational Research. Vol. 130. 2001. pp. 121-132. T. L. [ Links ]
10. T. Saaty. How to Make a Decision: The Analytic Hierarchy Process Interfaces. Vol. 24. 1994. pp. 19-43 [ Links ]
11. J. Guan. J. Wang. Evaluation and interpretation of knowledge production effi ciency. Scientometrics. Vol. 59. 2004. pp. 131-155. [ Links ]
12. W. Arenas. J. Soto. O. Rivera. La evaluación de los grupos de investigación según Colciencias versus su evaluación según el Análisis Envolvente de Datos. Scientia et technica. Vol. 10. 2004. pp. 184-194. [ Links ]
13. N. Adler. L. Friedman. Z. Sinuany-Stern. Review of ranking methods in the data envelopment analysis context. European Journal of Operational Research. Vol. 140. 2002. pp. 249-265. [ Links ]
14. T. R. R. Sexton. H. Silkman. A. J. Hogan. Data envelopment analysis: Critique and extensions. New Directions for Program Evaluation. Vol. 32. 1986. pp. 73-105. [ Links ]
15. P. Andersen. N.C. Petersen. A Procedure for Ranking Efficient Units in Data Envelopment Analysis. Management Science. Vol. 39. 1993. pp. 1261-1264. [ Links ]
16. A.M. Torgersen. F.R. Førsund. S.A.C. Kittelsen. Slackadjusted efficiency measures and ranking of efficient units. Journal of Productivity Analysis. Vol. 7. 1996. pp. 379-398. [ Links ]
17. J. Doyle. R. Green. Efficiency and Cross-Efficiency in DEA: Derivations, Meanings and Uses, The Journal of the Operational Research Society. Vol. 45. 1994. pp. 567-578. [ Links ]
18. Colciencias. Directorio de Grupos Colombianos de Investigación Científica y Tecnológica e Innovación. http://scienti.colciencias.gov.co:8081/digicyt.war/Consultado el 25 de noviembre de 2006. [ Links ]
19. M.I. Restrepo. J.G. Villegas. Análisis Envolvente de Datos: introducción y herramienta pública para su utilización en el ámbito universitario. Documento de Trabajo. 2006. [ Links ]
20. J. Zhu. Robustness of the efficient DMUs in data envelopment analysis. European Journal of operational research. Vol. 90. 1996. pp. 451-460. [ Links ]
21. R.G. Dyson. R. Allen. A.S. Camanho. V. Podinovski. C.S. Sarrico. E.A. Shale. Pitfalls and protocols in DEA. European Journal of Operational Research, Vol. 132. 2001. pp. 3- 17. [ Links ]
22. R.D. Banker. H. Chang. The super-efficiency procedure for outlier identification, not for ranking efficient units. European Journal of Operational Research. Vol. 175. 2006. pp. 1311-1320. [ Links ]
23. H. Abdi. The Kendall Rank correlation. En N. J. Salkind (Ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks: Sage. 2006 [ Links ]
24. L. G. Díaz Monroy. Estadística multivariada. Inferencia y métodos. Universidad Nacional de Colombia. 2002. pp. 259-293. [ Links ] ____________________
* Autor de correspondencia: teléfono: 57+4+210 55 75, fax: 57+4+210 55 18, correo electrónico: jvillega@udea.edu.co (J. Villegas).

