










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Facultad de Ingeniería Universidad de Antioquia
Print version ISSN 0120-6230On-line version ISSN 2422-2844
Rev.fac.ing.univ. Antioquia no.59 Medellín July/Sept. 2011
Pronóstico de la demanda de energía eléctrica horaria en Colombia mediante redes neuronales artificiales
Forecasting of hourly electric load in Colombia using artificial neural networks
Santiago Medina Hurtado*, Julián Moreno Cadavid, Juan Pablo Gallego Valencia
Universidad Nacional de Colombia – Sede Medellín, Carrera 80 No. 65 - 223 Bloque M8, Medellín
Resumen
El pronóstico de la demanda de energía eléctrica de un país o un sector determinado es una tarea de suma importancia no solo desde el punto de vista operativo, sino también del comercial. En este artículo se propone un modelo de pronóstico para la demanda de energía eléctrica en Colombia a nivel horario de una semana completa, mediante una Red Neuronal Artificial. El modelo utiliza información histórica en forma de datos rezagados de la serie de tiempo de demanda, así como información de eventos calendario previamente identificados que producen cambios significativos en los patrones de la demanda de energía a lo largo del año, por otra parte, el modelo propuesto considera un rezago en la información disponible para realizar los pronósticos de alrededor de tres semanas. Tal modelo fue validado a partir de datos reales de consumo de carga para una región específica de Colombia. Los resultados obtenidos fueron contrastados con un modelo auto regresivo (AR) y un modelo auto regresivo con variables exógenas (ARX). Tales resultados fueron satisfactorios en términos de la disminución general del error de ajuste, así como del comportamiento durante períodos de tiempo atípicos los cuales son difíciles de pronosticar con modelos tradicionales.
Palabras clave:Pronóstico, demanda de energía eléctrica, redes neuronales artificiales.
Abstract
The electric load forecasting of a country or a determined sector is a very important task not just from the operative point of view, but from the commercial. A Neural Network based full-week hourly electric load forecasting model is proposed for Colombia. This model uses historical information delays as well as previously identified date events which produce significant changes in the electric load patrons through the year, the model also consider a three weeks delay in the available information used in forecasts. The model was validated using real electric load data from a specific Colombian region. The results were compared with an auto-regressive model (AR) and an auto-regressive model with exogenous variables (ARX). The general error decay and the good approximation during the atypical time periods, which are difficult to forecast, make it a satisfying model.
Keywords: Forecasting, electric load, artificial neural networks.
Introducción
Obtener un pronóstico acertado de la demanda de energía es fundamental para soportar los diferentes procesos de decisión que llevan a los agentes del sector eléctrico de un país. Para el caso particular del operador de mercado, una mayor precisión en el pronóstico a corto plazo implica una programación más eficiente de los recursos de generación de electricidad, lo que se traduce en una disminución de costos; mientras que en el largo plazo se constituye como un indicador fundamental para la generación de señales de inversión para futura capacidad instalada.
El estudio de modelos de pronóstico para esta variable alrededor del mundo ha sido extenso y variado, incluyendo metodologías como el análisis estadístico clásico usando modelos ARIMA, suavisamiento exponencial y regresión con análisis de componentes principales [1]; tambien se han utilizado métodos heurísticos como las redes neuronales artificiales [2-5], así como metodologías hibridas entre redes neuronales y análisis wavelet [6] y redes neuronales junto con teoría de la información [7]. Otras aproximaciones más recientes incluyen las máquinas de soporte vectorial [8], combinándolas con clustering difuso [9], y la utilización de descomposición wavelet y filtros de Kalman [10].
En el entorno local también se encuentran algunos trabajos desarrollados alrededor de esta problemática. Por ejemplo en [11, 12] los autores buscan pronosticar la demanda de energía en un día en la ciudad de Medellín por medio dealgoritmos genéticos y lógica difusa respectivamente. Estos trabajos difieren en que el primero se enfoca en el pronóstico del consumo en el sector industrial de la ciudad de Medellín, mientras que el segundo considera la demanda total. En [13] se hace una extensa revisión bibliográfica sobre el tema y se busca pronosticar la demanda mensual de energía por medio del método de componentes no observables. Por otro lado en [14] se exploran las ventajas de pronosticar la demanda mensual en Colombia utilizando redes neuronales y redes neuro difusas versus modelos econométricos bien conocidos.
Independiente de los resultados y particularidades de estos trabajos, todos ellos evidencian la urgencia del sector eléctrico nacional e internacional por volver cada vez más eficiente sus procesos de generación y distribución partiendo de un adecuado pronóstico que apoye la planeación de las operaciones. Esto es particularmente importante si se tiene en cuenta que la realización de pronósticos con valores lejanos a los reales afecta la calidad de la operación del sistema eléctrico con repercusiones económicas. Por ejemplo, un pronóstico superior a la demanda real tiene como consecuencia la programación de más recursos de generación que los necesarios, mientras que un pronóstico inferior obliga al despacho de recursos no programados inicialmente, presentándose en ambos casos un aumento en los costos.
En general los trabajos anteriormente mencionados se desarrollaron para pronósticos con datos disponibles a lo sumo con una semana de rezago y buscan pronosticar la demanda de energía para un solo día o de manera mensual. En contraste, el modelo propuesto en este artículo considera un rezago en la información de alrededor de tres semanas acorde con la regulación y al tiempo que generalmente se demora en llegar la información real de las zonas de registro al operador del sistema, con el fin de pronosticar la demanda horaria de una semana entera (168 horas). Para lograr esto se propone una estructura de red neuronal que se reentrena cada vez se corre un pronóstico y que considera tanto información histórica cuantitativa (asociada a los datos rezagos de la serie) como cualitativa (asociada a los eventos calendario que producen cambios significativos en la demanda de energía a lo largo del año).
El resto de este artículo se encuentra organizado como se describe a continuación. En la sección 2 se presenta el marco conceptual en el cual se basa el modelo propuesto. Posteriormente se presenta en la sección 3 un análisis estadístico y en frecuencia de las series de tiempo consideradas. Las secciones 4 y 5 muestran respectivamente la formulación del modelo y los resultados obtenidos contrastándolos con dos modelos tradicionales, un modelo auto regresivo (AR) y otro auto regresivo con variables exógenas (ARX). Por último se presentan algunas conclusiones junto con el planteamiento de trabajos futuros en la sección 6.
Metodología
Para el problema general de modelado y pronóstico de series de tiempo existen diversas metodologías dentro de los cuales se destacan los métodos estadísticos, los modelos en espacio de estados y los llamados modelos heurísticos, entre los que se encuentran las técnicas de inteligencia artificial. Estos últimos son muy utilizados para capturar relaciones no lineales entre las variables explicativas y las variables dependientes. Dentro de este tipo de modelos se encuentran las Redes Neuronales Artificiales (RNA), las cuales buscan emular el funcionamiento de las redes neuronales de los seres vivos respecto a su esquema de conexión así como la transmisión y el almacenamiento de información.
En general las RNA se fundamentan en elementos simples, llamados neuronas, las cuales trabajan en paralelo dentro de capas, que a su vez se conectan entre sí por medio de enlaces ponderados, también llamados pesos sinápticos. El modelo se ajusta por medio de un proceso llamado entrenamiento en el que se estiman los pesos que ponderan las conexiones entre las neuronas de cada capa. Este proceso se realiza generalmente por medio un método de optimización numérico, tomando generalmente como criterio la minimización de un índice de error, como por ejemplo el error medio cuadrático (MSE por sus siglas en inglés) ó la suma de los cuadrados de los errores (SSE por sus siglas en inglés).
Dentro de los modelos de RNA existen diversos tipos de estructuras dependiendo de la disposición de los enlaces que conectan las neuronas o si existen bucles dentro de la red. Una estructura ampliamente utilizada en el pronóstico de series de tiempo es el Perceptrón Multicapa [15] (PM), el cual presenta las siguientes características: a) no existen bucles ni conexiones entre las neuronas de una misma capa, b) las funciones de activación son iguales para cada neurona de una misma capa y c) tiene una sola neurona en la capa de salida. La estructura de este tipo de red se observa en la figura 1.
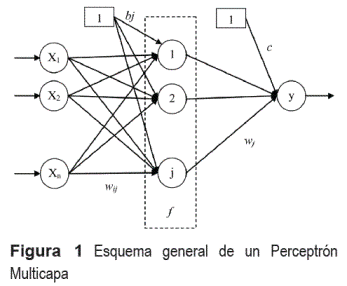
La representación matemática de la figura 1, se indica en la ecuación (1) donde:
y es la variable pronosticada
xi.. es la i-ésima variable de entrada
wj son los pesos que conectan la j-ésima salida de la capa oculta a la capa de salida
Wij son los pesos que conectan la i-ésima entrada al modelo con la j-ésima neurona de la capa oculta
bj son los sesgos (bias) o intercepto de las j-ésima neurona oculta
c es el sesgo (bias) o intercepto de la neurona y de salida
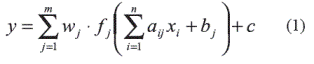
Wj, aij, bi, c son los parámetros del modelo que deben ser ajustadas mediante el algoritmo de entrenamiento. En total son (n + 1) (m + 1) parámetros a ajustar, donde n es el número de entradas al modelo y m es el número de neuronas en la capa oculta de la red.
Interpretando esta ecuación, el modelo resulta ser una regresión caracterizada por la función f, la cual puede ser lineal o no lineal y determina la forma en que se relacionan las entradas al modelo con la salida.
Análisis estadístico y en frecuencia de las series de demanda
Al analizar la serie de tiempo de la demanda de energía eléctrica sea a nivel agregado para todo el país (al menos en el caso Colombiano) o desagregado por zonas de consumo (UCPs como en este caso), se puede observar una tendencia creciente a través de los años, la cual es imperceptible en el corto plazo. En contraste, al analizar la escala mensual puede observarse una estacionalidad debida a los patrones de consumo de los diferentes meses del año. En el caso Colombiano tales diferencias no corresponden en mayor medida, como ocurre en otros países, a las estaciones climáticas si no a fenómenos sociales o económicos como el efecto del calendario escolar, festividades, etc. A escala diaria también se presentan patrones pero en este caso debidos a factores como los horarios productivos, los horarios habituales de alimentación, etc. Para ejemplificar estos comportamientos la figura 2 muestra la serie de demanda a nivel horario para una UCP específica en tres escalas de tiempo diferentes: anual mensual y diaria.
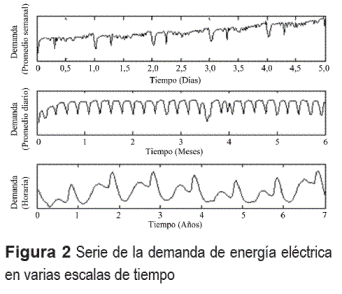
El análisis de autocorrelación muestral de la serie horaria evidencia una fuerte estructura de correlaciones entre los datos a nivel diario e incluso semanal y anual. En la figura 3 se muestra la función de autocorrelación donde puede apreciarse el comportamiento sistémico de la autocorrelación dado que todos los valores sobrepasan las bandas de significancia.
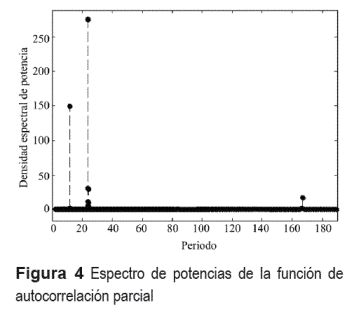
Una mejor visualización de este fenómeno se observa calculando el espectro de potencias de la función de autocorrelación el cual permite, al ser robusto al ruido, ver de manera clara las estacionalidades de la serie. Este resultado se presenta en la figura 4 donde se observan una gran dependencia de cada dato horario con sus rezagos de 12, 24 y 168 horas.
Formulación del modelo de pronóstico
El modelo de pronóstico propuesto en este artículo consiste en una Red Neuronal Artificial con una estructura de Perceptrón Multicapa (descrito en el numeral 2) con una sola capa oculta, utili-zando como función de activación de esa capa la función tangente - sigmoidal, especificada en la ecuación (2).
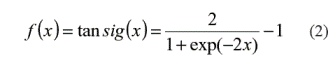
Se define como salida la demanda de energía en una hora determinada del día, lo cual significa que para pronosticar una semana completa el modelo se debe ejecutar una vez por cada período del día y por cada día de la semana, es decir, 168 veces.
Definición de las entradas
Para las entradas del modelo se destacan dos fuentes de información disponible que pueden ayudar a la caracterización de la demanda a lo largo del horizonte de predicción, una cuantitativa y otra cualitativa. La primera se refiere a los datos históricos relacionados con la serie de tiempo considerando el análisis de los rezagos realizado en el numeral 3 así como la disponibilidad real de los datos; mientras que la segunda es una asignación de etiquetas a cada tipo de día dependiendo de su ubicación en la semana o del evento particular que se celebre en esta fecha. Tales etiquetas corresponden a una clasificación de los días del año según su comportamiento típico (identificado a partir de conocimiento experto), tomando valores como "día de semana normal", "domingo", "viernes santo" "primero de enero", etc. En total se consideraron 42 etiquetas, las cuales por cuestiones de confidencialidad no pueden ser mencionadas en detalle.
En total las entradas seleccionadas fueron 11, de las cuales 3 son entradas regresoras de forma que puedan ser capturadas las dinámicas estacionales de la serie; 7 son categóricas de forma que la información cualitativa de eventos especiales pueda ser interpretada de forma coherente por el modelo y la entrada restante es una variable aleatoria normalmente distribuida que actúa como excitación persistente al modelo. De manera formal, si Lh,d es la demanda de la hora h del día d que se quiere pronosticar las variables de entrada son:
• Lh,d-21: Demanda de la misma hora tres semanas atrás
• Lh,d-364: Demanda de la misma hora 52 semanas atrás, es decir aproximadamente un año
• Lh*,d-21: Demanda promedio del día, tres semanas atrás
• d: Tipo de día que se quiere pronosticar
• d-1: Tipo de día anterior al que se quiere pronosticar
• d+1: Tipo de día posterior al que se quiere pronosticar
• d-21: Tipo de día del rezago tres semanas atrás al día que se quiere pronosticar
• d-364: Tipo de día del rezago 52 semanas antes al día que se quiere pronosticar
• h: Periodo del día que se va a pronosticar
• Numero de semana del año en la que se desarrollará el pronóstico
• Variable aleatoria normalmente distribuida N(0,1)
Como el modelo pretende calcular el pronóstico de una semana completa, y una parte importante de las entradas al modelo propuesto son rezagos, lo ideal sería contar con información de demanda de la semana inmediatamente anterior, sin embargo existen varias restricciones operativas y regulatorias que impiden la adquisición de este conjunto de datos. Es por esta razón que en las variables de entrada se consideran datos con un rezago mínimo de tres semanas.
Algoritmo de entrenamiento
El modelo propuesto fue implementado en Matlab utilizando el toolbox de Redes Neuronales y, para definir el mejor algoritmo de entrenamiento y el número de neuronas que debe contener la capa oculta, se empleó el procedimiento descrito a continuación.
Se tomaron los datos históricos disponibles (alrededor de cinco años) para una UCP específica y se dividieron en dos conjuntos: datos de entrenamiento y datos de validación, en una proporción de 80% y 20% respectivamente. Con estos datos organizados en tuplas entrada-salida definidas según la sección anterior, se probaron los siguientes cuatro algoritmos de entrenamiento para verificar cual generaba mejores resultados en términos del ajuste de la serie: Retro-propagación, Levenberg - Marquardt, Regulación Bayesiana, y Gradiente Escalado Conjugado. Para cada uno de estos se entrenaron modelos con un número diferente de neuronas en la capa oculta, iniciando en 4 neuronas y luego incrementando este valor de cuatro en cuatro hasta llegar a 40 neuronas. Este procedimiento exhaustivo e iterativo, permitió optimizar el número de neuronas equilibrando desempeño y tiempo de ejecución. Los resultados obtenidos se muestran en la figura 5 considerando como criterio de desempeño el Error Absoluto Promedio Porcentual (MAPE) que muestra la desviación promedio porcentual de cada pronóstico horario de los datos de validación en relación con los valores reales de demanda.
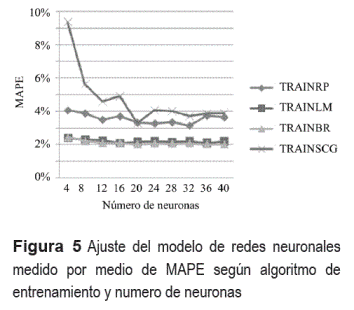
A partir de los datos presentados en la figura 5 pudo establecerse que la mejor combinación algoritmo de entrenamiento - número de neuronas es el algoritmo Levenberg - Marquardt con 16 neuronas en la capa oculta, siendo esta configuración la seleccionada para el modelo de pronóstico propuesto.
Resultados y discusión
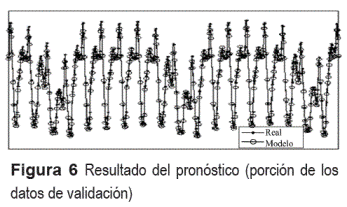
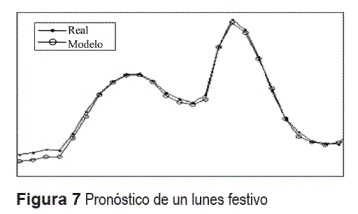
Para validar el modelo planteado se tomaron nuevamente los datos históricos reales de 5 años y se realizaron pronósticos en diferentes puntos de interés dividiéndolos en datos de entrenamiento y de validación en la misma proporción. De los resultados obtenidos, tal como lo muestra a manera de ejemplo la figura 6, se puede concluir que el modelo logra capturar las componentes estacionales tanto semanales como diarias de la serie. Otro punto importante es que el modelo logra aproximar con buena precisión días especiales que no se encuentran en los patrones estacionales, como por ejemplo los lunes festivos (véase figura 7).
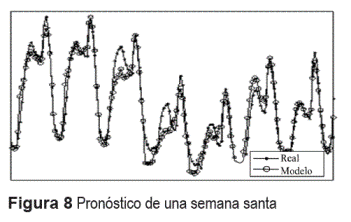
Por su parte la figura 8 muestra el pronóstico para una semana santa. En este caso se puede notar que, a pesar de que el modelo en general sigue el comportamiento de los datos reales, se presenta un menor ajuste que en los dos ejemplos anteriores, esto debido a que se cuenta con poca información de estos eventos y además pueden presentar una variación considerable de año a año.
Para darle mayor validez a los resultados obtenidos, se implementaron dos modelos adicionales con el fin de contrastarlos con el modelo propuesto. El primero consiste en un modelo auto regresivo (AR) cuyas entradas son las primeras dos variables del modelo RNA (las variables rezagadas tres semanas y un año), mientras que el segundo es un modelo auto regresivo con variables exógenas (ARX) cuyas entradas son exactamente las mismas que las del modelo RNA. Ambos modelos fueron ajustados por medio de mínimos cuadrados.
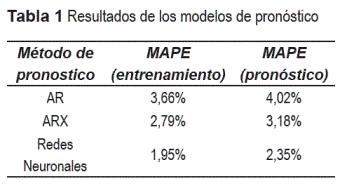
Para realizar la comparación se generó un pronóstico de cerca de 320 días con un retardo en la información de tres semanas. La tabla 1 muestra los resultados obtenidos en términos del MAPE para los tres modelos.
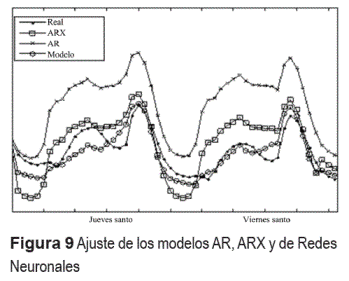
Adicionalmente la figura 9 muestra el ajuste de los tres modelos en dos días críticos (difíciles de pronosticar): un jueves y un viernes santo. Aquí se puede notar como el modelo AR es el más alejado de la demanda real, esto debido a que solo captura las componentes estacionales de la serie pero no incluye información que pueda explicar eventos fuera de estas estacionalidades. Este problema se presenta en menor medida con los modelos ARX y RNA los cuales se aproximan mejor gracias a la incorporación de variables explicativas, siendo mejor el segundo.
Aunque estos resultados parecen indicar que el modelo de Red Neuronal Artificial (RNA) propuesto es mejor a los modelos autoregresivos AR y ARX, todavía es necesario llevar a cabo un análisis de los errores de pronóstico obtenidos, también conocidos como residuales. El análisis parte por lo general de una verificación grafica entre cada variable independiente y la serie de errores, esto permite darnos una idea de su relación mediante la detección de comportamientos sistemáticos, los cuales, si son detectados, indicarían que aún quedaría información en dichos errores que el modelo ajustado aun no ha extraído. En una situación ideal los errores deben moverse aleatoriamente en un banda sin presentar observaciones extremas, tendencias o conglomerados de volatilidad, este comportamiento se conoce como ruido blanco, lo cual implica que no hay una estructura de autocorrelación significativa en la serie de errores obtenidos (los errores son independientes).
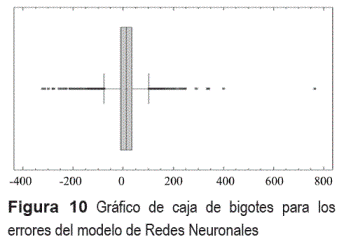
Al realizar el análisis estadístico correspondiente para el modelo RNA propuesto se determinó un coeficiente de asimetría de 19,9 y un coeficiente de curtosis de 281,5. Estos datos junto con la información suministrada por el gráfico de caja de bigotes presentado en la figura 10 indican que los errores no son normales.
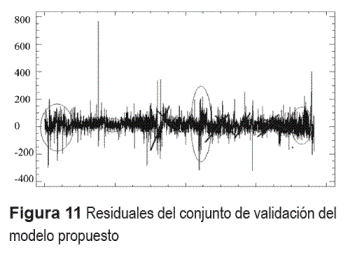
De manera más detallada en la figura 11 se muestra el comportamiento de los errores para los datos de validación del modelo RNA. La serie de los errores muestran un comportamiento alrededor de la media, sin embargo se nota la presencia de picos, comportamientos sistemáticos (indicado con líneas), y presencia de periodos de volatilidad variable (indicado con círculos).
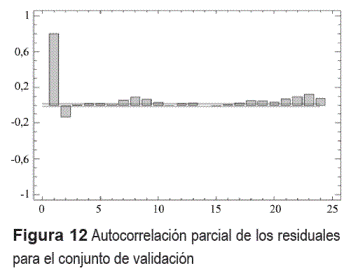
Adicionalmente, tal como se muestra en la figura 12, el análisis de autocorrelación parcial indica que todavía existe un comportamiento autoregresivo significativo en los errores ya que la mayor parte de los coeficientes de correlación están por fuera de los límites de confianza al 95%.
Por último se realizaron tres pruebas diferentes para determinar la aleatoriedad de los errores. En la primera prueba se cuenta el número de veces que la serie de datos esta encima y debajo de la mediana, El número de veces es igual a 2.714, en comparación con un valor esperado, si la secuencia fuera aleatoria, de 7.657. Dado que el valor P de esta prueba es inferior a 0,05, se rechaza la hipótesis de que la serie es aleatoria a un nivel de confianza del 95%. La segunda prueba cuenta el número de veces en que la secuencia aumentó o disminuyó (corridas). Este valor fue de 7.007, en comparación con un valor esperado de 10.208 si la secuencia fuera aleatoria. Dado que el valor P de esta prueba es inferior a 0,05, se rechaza la hipótesis de que la serie es aleatoria a un nivel de confianza del 95%. La tercer prueba, conocida como Box-Pierce se basa en la suma de los cuadrados de los primeros 24 coeficientes de autocorrelación. Dado que el valor P de esta prueba es inferior a 0,05, se rechaza la hipótesis de que la serie es aleatoria a un nivel de confianza del 95%.
De los anteriores análisis se puede concluir que los errores del conjunto de datos de validación del modelo RNA propuesto no se comportan como un ruido blanco, es decir, que no se distribuyen normalmente N(0, σ). Dichos errores son estacionarios en media más no en varianza, pues se observan conglomerados de volatilidad, es decir, que la volatilidad no es uniforme durante todo el intervalo considerado. No obstante esta situación, y considerando que conclusiones similares se obtuvieron de los análisis de los errores para los modelos AR y ARX contrastados, la RNA propuesta sigue siendo una buena opción como modelo de pronóstico, pues es el modelo con el que se obtiene el menor porcentaje de error absoluto medio MAPE.
Conclusiones
Como una solución al problema de pronóstico de la demanda de energía eléctrica a nivel horario en este artículo se propone un modelo basado en una RNA, más específicamente un PM, incorporando como variables de entrada tanto valores rezagados como variables cualitativas que dan cuenta de fenómenos calendario. Para obtener una mejor comprensión de las series de tiempo analizadas, así como para definir el conjunto de las variables de entrada regresoras, se llevó a cabo un análisis estadístico y en frecuencia.
Luego de definidas las entradas del modelo, se realizó un procedimiento iterativo para encontrar la mejor combinación de algoritmo de entrenamiento y número de neuronas de la capa oculta, dando como resultado el algoritmo Levenberg - Marquardt con 16 neuronas. Ya con el modelo definido se llevaron a cabo varias pruebas de validación, las primeras respecto al ajuste del modelo y su capacidad de pronóstico, y las segundas para contrastarlo con modelos tradicionales como AR y ARX. En ambos casos se utilizó el MAPE como medida de rendimiento y se demostró de manera gráfica y cuantitativa la utilidad del modelo propuesto.
Como conclusión respecto a las variables de entrada se resalta la importancia de incorporar información adicional a los regresores de la misma serie de demanda en forma de variables explicativas para lograr que el pronóstico de días especiales sea más ajustado.
Respecto al trabajo futuro existen varios aspectos que se desean analizar. El primero es la incorporación de algoritmos para limpieza de los datos que se traduzca en un mejoramiento del desempeño de los modelos, esto pues se observó que muchos datos de la serie eran puntos atípicos debidos a problemas de medición de la demanda. El segundo es evaluar otras estructuras de modelos heurísticos empleando las mismas variables de entrada, como otros tipos de redes neuronales y sistemas híbridos, para determinar si se pueden mejorar aún más los pronósticos y corregir el problema de los residuales, con lo cual se pretende seguir proponiendo más y mejores herramientas para los tomadores de decisiones en el sector eléctrico.
Referencias
1. J. W. Taylor, L. M. de Menezes, P. E. McSharry. "A comparison of univariate methods for forecasting electricity demand up to a day ahead". International Journal of Forecasting. Vol. 22. 2006. pp. 1-16. [ Links ]
2. S. Kiartzis, C. Zoumas, J. Theocharis, A. Bakirtzis, V. Petridis. "Short-term load forecasting in an autonomous power system using artificial neural networks". Power Systems, IEEE Transactions on . Vol. 12. 1997. pp. 1591-1596. [ Links ]
3. E. A. Mohamed, M. M. Mansour, S. El-Debeiky, K. G. Mohamed. " Egyptian Unified Grid hourly load forecasting using artificial neural network". International Journal of Electrical Power \& Energy Systems . Vol. 20. 1998. pp. 495-500. [ Links ]
4. K. Topalli, I. Erkmen. "A hybrid learning for neural networks applied to short term load forecasting". Neurocomputing . Vol. 51. 2003. pp. 495-500. [ Links ]
5. N. Mahdavi, M. Menhaj, S. Barghinia. "Short-Term Load Forecasting for Special Days Using Bayesian Neural Networks". Power Systems Conference and Exposition, 2006. IEEE/PES . 2006. pp. 1518-1522. [ Links ]
6. Z. Y. Dong, B. L. Zhang, , Q. Huang. "Adaptive neural network short term load forecasting with wavelet decompositions". IEEE Porto Power Tech Proceedings. 2001. pp. 1-77. [ Links ]
7. W. Sun, J. Lu, Y. He. "Information Entropy Based Neural Network Model for Short-Term Load Forecasting". Transmission and Distribution Conference and Exhibition: Asia and Pacific. 2005 IEEE/PES . 2005. pp.1-5. [ Links ]
8. M. Espinoza, J. A. Suykens, B. D. Moor. "Load Forecasting Using Fixed-Size Least Squares Support Vector Machines". Computational Intelligence and Bioinspired Systems. Vol. 3512. 2005. pp. 1018-1026. [ Links ]
9. G. S. Hu, Y. Z. Zhang, F. F. Zhu. "Short-Term Load Forecasting Based on Fuzzy C-Mean Clustering and Weighted Support Vector Machines". Procudings of the Third International Conference on Natural Computation. Haikore (China). Vol. 5. 2007. pp. 654-659. [ Links ]
10. T. Zheng, A. A. Girgis, E. B. Makram. "A hybrid wavelet-Kalman filter method for load forecasting". Electric Power Systems Research Vol. 54. 2000. pp. 11-17. [ Links ]
11. H. Tabares, J. Hernández. "Pronóstico puntos críticos de la serie temporal consumo de energía eléctrica del sector industrial en la ciudad de Medellín usando algoritmos genéticos". Rev. Fac. Ing. Univ. Antioquia. Vol. 40. 2007. pp. 95-105. [ Links ]
12. H. Tabares, J. Hernández. "Aproximación por lógica difusa de la serie de tiempo demanda diaria de energía eléctrica". Rev. Fac. Ing . Univ. Antioquia. Vol. 47. 2009. pp. 209-217. [ Links ]
13. C. J. Franco, J. D.Velásquez, Y. Olaya. "Caracterización de la demanda mensual de electricidad en Colombia usando un modelo de componentes no observables". Cuadernos de Administración especial de finanzas . Vol. 21. 2008. pp. 221-235. [ Links ]
14. H. S. Medina, A. J. García. "Predicción de la demanda de energía eléctrica en Colombia mediante un sistema de inferencia difuso neuronal". Revista Energética. Vol. 33. 2005. pp. 15-24. [ Links ]
15. B. Martin, A. Sanz. Redes Neuronales y Sistemas Borrosos. 3a. ed. Ed. RA-MA. Madrid (España). 2006. pp. 442. [ Links ]
(Recibido el 26 de febrero de 2010. Aceptado el 8 de febrero de 2011)
*Autor de correspondencia: teléfono: + 57 + 4 + 425 52 26, fax: + 57 + 4 + 425 53 65, correo electrónico: smedina@unal.edu.co. (S. Medina)

