










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Facultad de Ingeniería Universidad de Antioquia
Print version ISSN 0120-6230
Rev.fac.ing.univ. Antioquia no.65 Medellín Oct./Dec. 2012
ARTÍCULO ORIGINAL
Expert knowledge-guided feature selection for data-based industrial process monitoring
Selección de variables guiada por conocimiento del experto para el monitoreo basados en datos de procesos industriales
César Uribe, Claudia Isaza*
Department of Electronic Engineering. Universidad de Antioquia. Calle 67 No. 53-108 Bl.19 Of. 426, Medellín, Colombia.
*Autor de correspondencia: teléfono: + 57 + 4 + 219 85 60, fax: 57 + 4 + 219 55 84, correo electrónico: cisaza@udea.edu.co (C. Isaza)
(Recibido el 10 enero de 2012. Aceptado el 6 noviembre del 2012)
Abstract
Industrial processes are characterized to be in open environments with uncertainty, unpredictability and nonlinear behavior. Rigorous measuring and monitoring is required to strive for product quality, safety and finance. Therefore, data-based monitoring systems have gain interest in academia and industry (e.g. clustering). However industrial processes have high volumes of complex and high dimensional data available, with poorly defined domains and sometimes redundant, noisy or inaccurate measures with unknown parameters. When a mechanistic or structural model is not available or suitable, selecting relevant and informative variables (reducing the high dimensionality) eases pattern recognition to identify functional states of the process. In this paper, we address the feature selection problem in data-based industrial processes monitoring where a mathematical or structural model is not available or suitable. Expert knowledge-guidance is used inside a wrapper feature selection based on clustering. The reduced set of features is capable of represent intrinsic historical-data structure integrating the expert knowledge about the process. A monitoring system is proposed and tested on an intensification reactor, the 'open plate reactor (OPR.)', over the thiosulfate and the esterification reaction. Results show fewer variables are needed to correctly identify the process functional states.
Keywords: Feature selection, processes monitoring, fault detection, fuzzy clustering
Resumen
Los procesos industriales se caracterizan por estar en ambientes abiertos, inciertos y no lineales. La medición y monitoreo de estos busca calidad, seguridad y economía en los productos. Los sistemas de monitoreo basados en datos han ganado un gran interés en la academia y en la industria, pero los procesos industriales tienen grandes volúmenes de datos complejos y de alta dimensión, con dominios poco definidos, medidas redundantes, ruidosas e imprecisas y parámetros desconocidos. Cuando un modelo mecánico no está disponible, seleccionar las variables relevantes e informativas (reduciendo la dimensión de los datos) facilita la identificación de los patrones en los estados funcionales del proceso. En este artículo se propone usar el conocimiento del experto como guía dentro de un wrapper de selección de descriptores basado en agrupamiento para reducir el conjunto de variables necesarias para representar la estructura intrínseca de los datos históricos del proceso. Un sistema de monitoreo es propuesto y evaluado en un reactor de intensificación, el Open Píate Reactor, en las reacciones de tiosulfato y esterificación. Los resultados muestran que sólo algunas variables son necesarias para identificar correctamente los estados funcionales del proceso.
Palabras clave: Selección de variables, monitoreo de procesos, detección de fallos, agolpamiento difuso
Introduction
Large volumes of complex and high dimensional data available set a barrier for developing efficient decision support and monitoring systems [1]. Using relevant and informative variables eases data understanding, classification accuracy and computational efficiency [2], [3], For example, Mukse et al. [4] used the Pareto optimal trade–off between the process information that can be obtained and the sensor cost for the selected process measurements, but a process model is needed. Sikora et al. [5] designed an effective and efficient genetic algorithm for a wrapper feature selection method based on Hausdorff distance measure in a supervised manner. Fraleigth et al. [6] developed a sensor system selection for model-based real-time optimization. Verron et al. [7] proposed supervised fault diagnosis with feature selection based on discriminant analysis and mutual information. Bensch et al. [8] tackled the problem of identifying the features responsible for success or failure in the manufacturing process in a supervised context. These methods focus on constructing process models and identify the gap with the actual system using supervised learning. However, complex processes do not always have classical models available [9]. Thus, several researchers focused on the development of robust and reliable monitoring systems based on data analysis.
Data-based monitoring systems use measurement's information to identify process behaviors as functional states or classes. Such information is classified according to its resemblance with previously classified historical data [10]. However, in industrial processes, class labels are unknown and most of the knowledge is held by the expert. Such knowledge constrains knowledge discovery, avoid the data over fitting problem [11] and describes the relationship between attributes, categories and correlations among them. The expert judgment approach may result in an effective feature selection without bias by the distribution of the training set [12]. Real-life applications require the involvement of domain experts to validate the allocation of operating states of the process into classes resulting from clustering. Nevertheless, high dependency upon expert knowledge is not desirable due to their inability to examine large amounts of data in a rigorous fashion without the effects of boredom or frustration [13]. Using computational intelligence techniques seems to be an alternative to take into account the process expert knowledge. In this context, techniques that use data artificially labed by the expert are valuable to diagnosis and classification systems. [14].
In this paper, a wrapper feature selection guided by the process expert's knowledge is proposed. Expert's knowledge is not used for supervised training but as guidance in order to look for clustering results as similar as the expert data partition maintaining a cluster structure. The method is applied on fault detection and monitoring (i.e. classification of the process dynamic in a predefined functional state) of the 'open plate reactor (OPR.)'' [15, 16] on the thiosulfate reaction and the esterification reaction.
Next section shows the proposed wrapper framework for feature selection: feature search, clustering algorithms, clustering quality assessment. Third section details the open plate reactor application over two chemical reactions (esterification and thiosulfate). Results are presented in section four. Last section shows conclusions and future work.
Wrapper feature selection guided by the expert knowledge
The wrapper methodology [2], offers a simple and powerful way to address the problem of variable selection [17], regardless of the chosen learning machine or quality subset criterion [18]. The performance of the induction algorithm guides the search, producing better results than filter feature selection methods for specific applications [19].
Figure 1 shows a detailed graphic of the proposed methodology. Historical data (i.e. database of the process) is defined in the N x n space, as a set Ω; N is the number of elements, n is the number of features in the original feature set F 
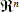 and Fr with r ≤ n represented as Ω ↓ Fr. The clustering algorithm partitions the data subset into c clusters, optimizing some metric J over the data. Consider the clustering algorithm as Y=J(Ω ↓ Fr, λ) where λ are the clustering method parameters. Let YωT=[y1,y2,…,yN], yi {1,2,…,c} be the partition produced by the clustering algorithm and Q(Yω, Yε)= φ be the performance function that assesses similarity between two partitions (e.g. expert and clustering partition). The feature search procedure generates the optimal set of features FOP by testing different forms of the map Ωr=f(Ω, φ).
and Fr with r ≤ n represented as Ω ↓ Fr. The clustering algorithm partitions the data subset into c clusters, optimizing some metric J over the data. Consider the clustering algorithm as Y=J(Ω ↓ Fr, λ) where λ are the clustering method parameters. Let YωT=[y1,y2,…,yN], yi {1,2,…,c} be the partition produced by the clustering algorithm and Q(Yω, Yε)= φ be the performance function that assesses similarity between two partitions (e.g. expert and clustering partition). The feature search procedure generates the optimal set of features FOP by testing different forms of the map Ωr=f(Ω, φ).
Feature search
Finding the optimal feature subset FOP requires either an exhaustive search that involves the evaluation of 2n subsets (becoming infeasible since n is large) [19] or the monotonicity of a pertinence measure. Two different sequential search strategies were implemented to analyze the case study: Sequential Forward Selection (SFS) and Sequential Backward Elimination (SBE). SFS starts with the subset F0, n partitions are obtained using clustering and its quality is computed. First, each feature subset includes only one variable. The feature subset Ω1 associated with the highest quality φ, is set to be the first selected variable in the vector v. Each feature that is not yet included in v is included and the quality of the n - 1 partitions is computed. The vector v with two features that led to the highest quality is selected as the new vector of selected features. These steps are repeated, adding one feature per iteration until a pre-specified number of characteristics is achieved (e.g. the total number of characteristics) or a performance criterion is met. Sequential Backward Elimination makes the search in the opposite direction. Starting with the full set of features, at each step the features are removed one by one.
Clustering algorithm
Data-based monitoring systems based on clustering try to find similarities in the process data and group them into classes that correspond to functional states. The term ''similarity'' should be understood as a mathematical measure of similarity, in some well-defined sense (e.g. distance based, hierarchy based, possibility based among others). In crisp clustering, when a data partition is build, a single sample belongs to only one cluster. The fuzzy clustering extends this notion, and each data belongs to all clusters with different membership degrees.
In this article the Learning Algorithm for Multivariate Data Analysis (LAMDA) is used. LAMDA method has been widely used in the literature for the construction of systems for monitoring industrial processes [14, 16, 17, 20-24], LAMDA [25] is based on finding the overall adequacy level of each individual to each class, called Global Adequacy Degree (GAD). The GAD is the membership degree of each object to each class. Its value is estimated using the contributions of the features based on a marginal concept of adequacy which replaces the use of traditional distance approximations. The contribution of each descriptor is called the Marginal Adequacy Degree (MAD) and it is computed using a possibility function. The class adequacy concept is expressed as the ''fuzzy'' truth value of a compound sentence using logical connectives between elementary assertions. Attributes can be numeric, symbolic or mixed (which is an advantage compared to other fuzzy classifiers that can only handle numeric descriptors). Also, LAMDA methodology does not require a number of classes to be specified as parameter, thus, it is capable of producing a data partition estimating the number of classes based on the data distribution. For a complete description of the LAMDA methodology see [25, 26].
Feature evaluation criteria
Partitions results are evaluated comparing the clustering algorithm and the process expert partition. The expert's partition is not used as classification vector in supervised way because even though the proposed method looks for producing partitions similar to the expert proposal, it still looks for finding underlying structures among data in order to identify similarities in the historical data [27].
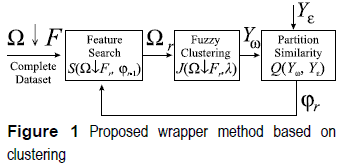
The Index of Dissimilarity Idn proposed by Lopez de Mantaras in [28, 29] allows to compare two data partitions with different number of classes and it has been recently used to compare partitions of industrial process [14]. The contingency matrix is established for two partitions: A (whose classes are denoted (α1, α2,..., αi, ..., αp)) and B (whose classes are denoted (b1,b2,...,bj,..., br)). The probabilities corresponding to each class and the probability of the intersection between a class of A partition and a partition class B are noted as Eq.1:
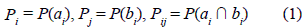
where αi 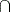 bi is formed by the elements that belong simultaneously to the latter class αi and class bi. The probabilities satisfy Eq. 2:
bi is formed by the elements that belong simultaneously to the latter class αi and class bi. The probabilities satisfy Eq. 2:
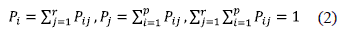
The probability of elements belonging to this class αi and class bi is computed with Eq. 3. M is the cardinality N and the total number of individuals ordered M(X).
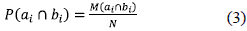
The Idn is zero only if the contingency matrix is ''almost diagonal'' or ''quasi-diagonalizable'', that is, when the partitions are either equal or compatible or equal modulo zero. The Idn is estimated from the conditional information between partitions A and B.
A normalized index of dissimilarity Idn = φ between the clustering partition Yω and expert partition Yε is defined in Eq. 4.
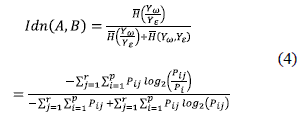
If the partition Yω is consistent or equal to Yε, Idn = 0 and Idn = 1 in the opposite case.
Cases studies: Open Plate Reactor -OPR
The OPR is a plate heat exchanger of new design [15]. One side is used as a chemical continuous reactor while the other side a cooling/heating thermal fluid flows. The primary reactant R1 flows from the inlet to the outlet of the reactor (see figure 2). The secondary reactant R2 can then be injected along the reactor side with R2 Depending on the reaction, the utility flow is used to cool (exothermic reaction) or heat (endothermic reaction) the reactor side.
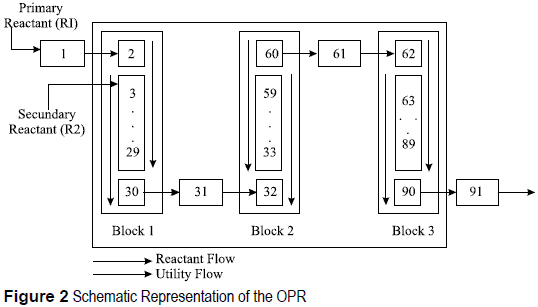
Figure 2 shows the schematic representation of the pilot plant; two feeding loops ensure the introduction of the reactants in the reactor at normal temperature [15]. The OPR has 27 available sensor measurements from temperatures and pressures from different cells of the reactor.
The OPR is studied under two chemical reactions; thiosulfate and esterification; described below. Failures in the OPR for the thiosulphate reaction and the esterification reaction were introduced in the process in the form of disturbances on the main variables: increase and decrease of temperatures and flows of the utility, primary and secondary reactants and increase and decrease of the compositions of the primary and secondary reactants.
Thiosulphate reaction
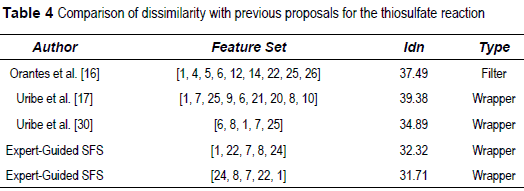
The thiosulphate reaction has the following characteristics: its stoichiometry and kinetic are known, the reaction is irreversible, fast and highly exothermic.
Table 1 shows a description of all functional states over the thiosulfate reaction. The database used is composed by the measure of the 27 variables with 17 simulated faults over 2076 time samples. The reaction scheme is in Eq. 5:
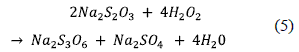
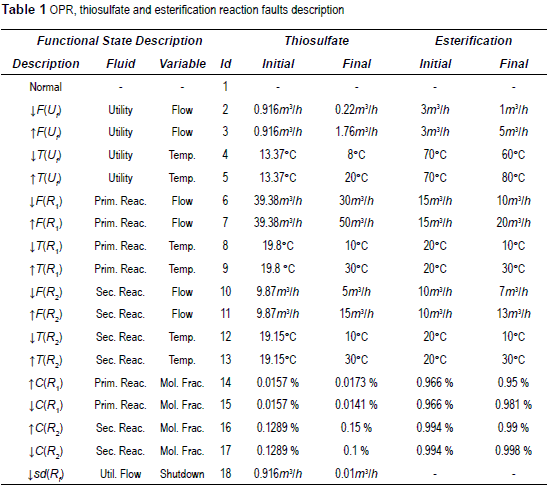
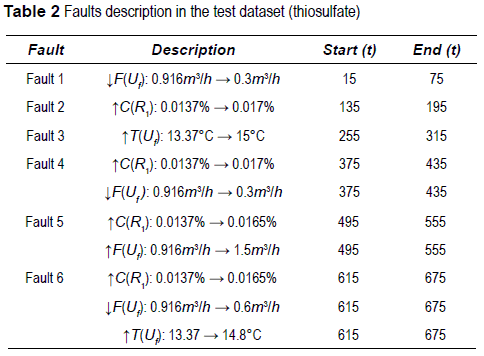
In order to validate the generated model using just the selected subset of sensors (the selected features), a test database with 735 new samples described only by the selected features was simulated. Six new faults were induced in the test dataset as described in table 2.
Estertification reaction
The esterification reaction is slow and weakly exothermic. To accelerate it, it is necessary to heat the reaction medium. In this case, the utility flow serves as fluid heating. In total, 16 faults have been applied to the reactor. Failures in the OPR are disturbances on the temperatures and flow rates of main reactantO (C4H8O) secondary or injected reactant (C6H10O3), cooling system (utility), and composition in primary and secondary reagents, see table 2.
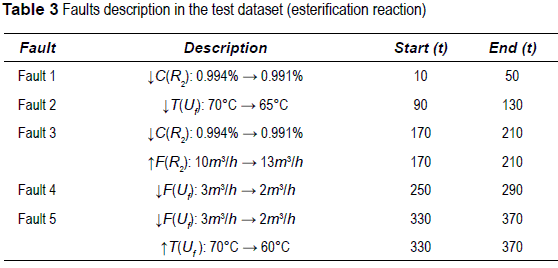
Validation on the esterification reaction results is made over a test database consisting of 410 new samples described only by the selected feature was simulated. Five new faults were induced in the test dataset as described in table 3.
Experimental results and discussion
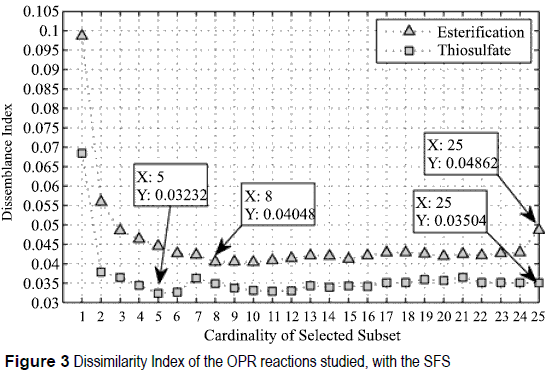
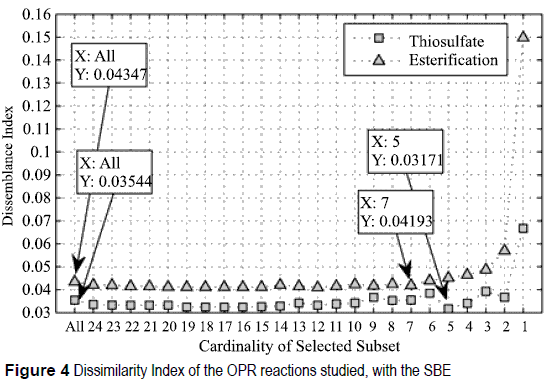
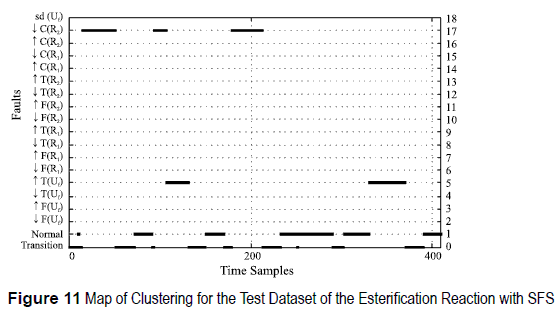
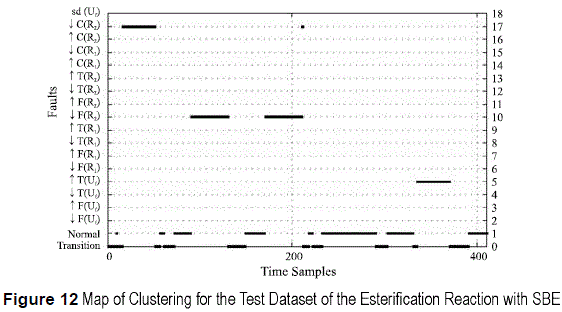
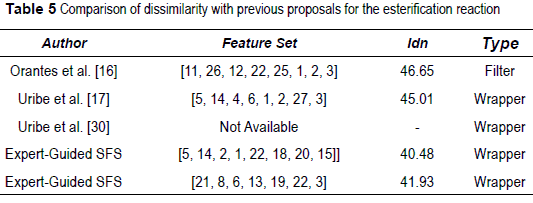
Variables representing input pressures for primary and secondary reactants were eliminated since they are constant. Feature selection is applied to the remaining 25 variables. The data subset associated with the lowest Idn value is represented by the set of features that minimize the dissemblance between the partition produced by the clustering algorithm and the partition proposed by the expert knowledge. For the thiosulfate reaction, the feature set f tSFS (5) = {1,22,7,8,24} and f tSBE (5) = {24,8, 7,22,1} are selected as the best set of features reaching Idn = 0.03232 and Idn = 0.03171 respectively, see figure 3. For the esterification reaction, features sets f eSFS (8) = {5,14,2,1,22,18,20,15} and f eSBE (7) = {21,8,6,13,19,22,3} with dissemblance index values of Idn = 0.04048 and Idn = 0.04193, see figure 4.
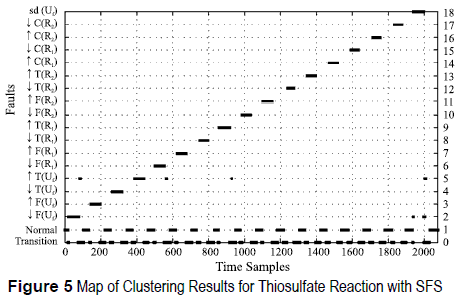
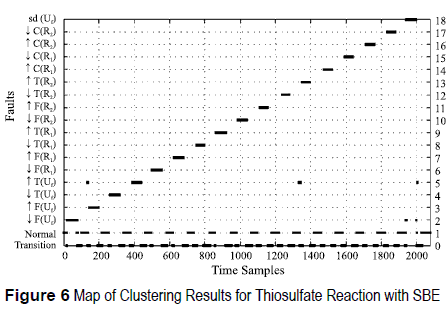
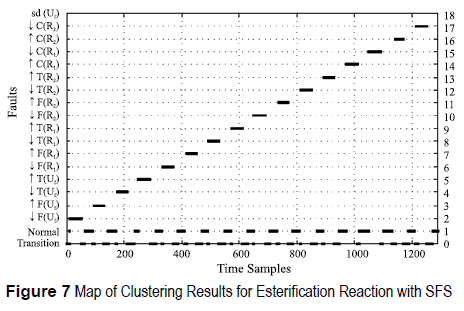
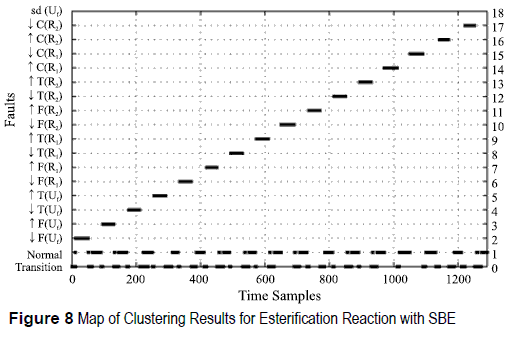
Figures 5, 6, 7 and 8 show the classification results of the training datasets when using just the selected features. The monitoring system identifies all functional states for both chemical reactions studied, with similar results for SFS and SBE. Additionally, a new class is defined, the transition class. This class represents a deviation from the Normal state and it is not included by the process expert. False alarms appears at the end of some faults, most of them are misclassification with the increase of Temperature of the Utility Flow ↑T(Uf) since the utility flow acts as temperature regulation and influences directly all functional states.
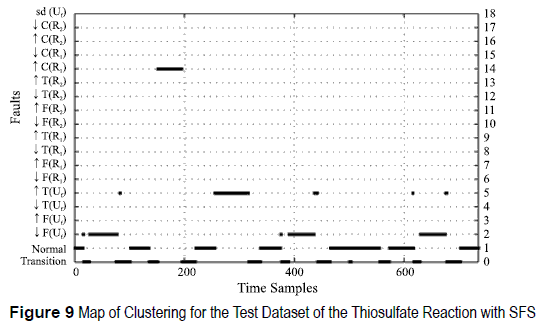
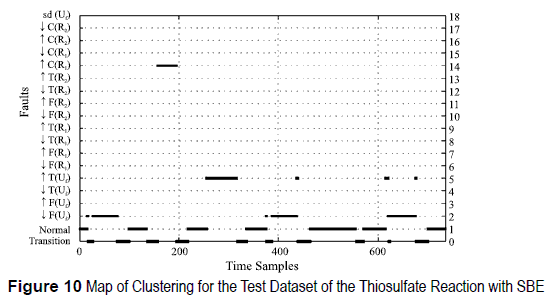
The resulting classifiers are tested on validation datasets, obtaining the results shown in figures 9 , 10, 11 and 12. For the thiosulfate reaction, when using SFS, the first three single disturbances are correctly identified. The classifier is able to identify the fault when several disturbances are presented simultaneously. Perturbation 5 is classified as normal because the combined effect of both perturbations cancels out. The reactor is fed with more primary reactant, but the utility fluid cools more, which corresponds to a normal operating state. For the esterification reaction both procedures, SFS and SBE, produce different sets of features. Fault 4 is identified as normal in both cases, since the esterification reaction is very exothermic, so the impact of such small variation does not affect la reaction. In the SBE search, the second perturbation corresponding to ↓T(Uf), is misclassified with functional state ↑F(R2) this is because a decrease on the utility fluid temperature increases the temperature of the reaction, and this increase appears when there is an increase of flow of the Secondary Reactant.
Previously in [16], the authors proposed a ranking method based on information-theoretic measures to evaluate the amount of information within each variable to select the most informative ones. Additionally, [17] and [30] explore wrapper approaches for unsupervised feature selection. Tables 4 and 5 show a comparison of previous feature selection results on the same process showing a better performance, with lower Idn value.
Conclusions and future work
An expert-guided wrapper for feature selection on data-based industrial process monitoring is presented. Expert knowledge is incorporated in the feature search to look for a subset of features able to represent the expert knowledge, but not in a supervised way, since it is important to take into account the data structure itself. Sequential Forward Selection (SFS) and Sequential Backward Elimination (SBE) were used as search methods, coupled with LAMDA as clustering algorithm and the Index of Dissimilarity to assess the cluster quality measure comparing the expert-–knowledge partition with the clustering results.
The proposed methodology was successfully applied to a complex industrial process known as the Open Plate Reactor (OPR), on the thiosulfate and the esterification reaction. The objective was identify abnormal behaviors in the process when using relative simple sensor (temperature), even though some states concerns changes on flow composition of primary and secondary reactants. First, using a training data set, the subset of feature is selected and a behavioral model is constructed using just the reduced set of features. Then, the generated model was tested on a validation data set consisting of perturbations different than those used in training, including simultaneous faults. In both cases, the proposed approach was able to select a set of features capable of generating a behavioral model robust enough to identify not only all functional states on the train data set but correctly identify faults on the test dataset.
The proposed procedure was compared with previous approaches dealing with the same chemical reactions. A fewer number of features were needed to correctly identify all the functional states of the complex chemical process. The feature subset shows a good response and performance since the index of dissimilarity was lower than other approaches, indicating a high similarity with the expert-knowledge proposal. The main improvement of this methodology is introducing the unsupervised learning and expert guidance in the search process. The use of a non-iterative clustering algorithm leads to fast performance on the search over the feature subset space. Even though some specific methods were used at each block of the wrapper, the presented framework can be applied to any clustering method. Future work will consist in comparing different methods of feature selection, clustering, cluster quality and partition comparing to determine which among the methods proposed in the literature has better performance on specific applications.
Acknowledgement
Thanks to Dr. A. Orantes and DISCO Group at LAAS/CNRS for the access to the OPR databases. Thanks to CODI-Universidad de Antioquia and COLCIENCIAS for financial support.
References
1. F. Akbaryan, P. Bishnoi. ''Fault diagnosis of multivariate systems using pattern recognition and multisensor data analysis technique''. Computers & Chemical Engineering. Vol. 25. 2001. pp. 1313-1339. [ Links ]
2. I. Guyon, S. Gunn, M. Nikravesh, L. Zadeh. ''Feature Extraction: Foundations and Applications'' Studies in Fuzziness and Soft Computing. Vol. 207. pp. 1-22. [ Links ]
3. D. Aha, R. Bankert. A comparative evaluation of sequentialfeature selection algorithms. In Proceedings of the Fifth International Workshop on Artificial Intelligence and Statistics. Springer-Verlag. 1995. Fort Lauderdale. USA. pp. 1-7. [ Links ]
4. K. Muske, C. Georgakis. A methodology for optimal sensor selection in chemical processes. Proc. American Control Conference the 2002. Villanova, Pennsylvania, USA. 2002. pp. 4274-4278. [ Links ]
5. R. Sikora, S. Piramuthu. ''Efficient genetic algorithm based data mining using feature selection with hausdorff distance''. Inf. Tech. and Management. Vol. 6. 2005. pp. 315-331. [ Links ]
6. L. Fraleigh, M. Guay, J. Forbes. ''Sensor selection for model-based real-time optimization: relating design of experiments and design cost''. Journal of Process Control. Vol. 13. 2003. pp. 667-678. [ Links ]
7. S. Verron, T. Tiplica, A. Kobi. ''Fault detection and identification with a new feature selection based on mutual information''. Journal of Process Control. Vol. 18. 2008. pp. 479-490. [ Links ]
8. M. Bensch, M. Schroder, M. Bogdan, W. Rosenstiel. Feature selection for high-dimensional industrial data. Proceeding of the European Symposium of Artificial Neural Networks. 2005. Brugues, Belgium. pp. 375-380. [ Links ]
9. T. Kourti. ''Process analysis and abnormal situation detection: from theory to practice''. Control Systems Magazine IEEE. Vol. 22. pp. 10-25. [ Links ]
10. T. Kempowsky. Surveillance de procédées à base de méthodes de classification. Ph.D. dissertation. INSA Toulouse. 2004. pp. 16-20. [ Links ]
11. P. Domingos. ''The role of Occam's razor in knowledge discovery''. Data Mining and Knowledge Discovery. Vol. 3. 1999. pp. 409-425. [ Links ]
12. T. Cheng, C. Wei, V. Tseng. ''Feature selection for medical data mining: Comparisons of expert judgment and automatic approaches''. Computer-Based Medical Systems. 2006. pp. 165-170. [ Links ]
13. B. Bums, A. Danyluk. ''Feature selection vs theory reformulation: A study of genetic refinement of knowledge-based neural networks''. Mach. Learn. Vol. 38. 2000. pp. 89-107. [ Links ]
14. C. Isaza. Diagnostic par techniques d'apprentissage floues: Conception d'une méthode de validation et d'optimisation des partitions. Ph.D. dissertation. Laboratoire d'Analyse et d'Architecture des Systèmes du CNRS. Toulouse, France. 2007. pp. 5-23. [ Links ]
15. L. Prat, A. Devatine, P. Cognet, M. Cabassud, C. Gourdon, S. Elgue, F. Chopard. ''Performance evaluation of a novel concept ''open plate reactor'' applied to highly exothermic reactions''. Chemical Engineering and Technology. Vol. 28. 2005. pp. 1028–1034. [ Links ]
16. A. Orantes, T. Kempowsky, M. Lann, L. Prat, S. Elgue, C. Gourdon, M. Cabassud. ''Selection of sensors by a new methodology coupling a classification technique and entropy criteria''. Chemical Engineering Research and Design. Vol. 85. 2007. pp. 825-838. [ Links ]
17. C. Uribe, C. Isaza, O. Gualdron, C. Duran, A. Carvajal. A wrapper approach based on clustering for sensors selection of industrial monitoring systems. Proceedings of the 2010 International Conference on Broadband. Wireless Computing, Communication and Applications. Japan. 2010. pp. 428-487. [ Links ]
18. I. Guyon, A. Elisseeff. ''An introduction to variable and feature selection''. J. Mach. Learn. Res. Vol. 3. 2003. pp. 1157-1182. [ Links ]
19. S. Guerif, Y. Bennani. ''Selection of clusters number and features subset during a two-levels clustering task'' Artificial Intelligence and Soft Computing. 2006. pp. 28-33. [ Links ]
20. C. Isaza, A. Orantes, T. Kempowsky, M. Le Lann. Contribution of fuzzy classification for the diagnosis of complex systems. The 7th IFAC International Symposium of Fault Detection. Supervision and Safety of Technical Processes. 2009. Barcelona, España. pp. 1132-1137. [ Links ]
21. T. Kempowsky, A. Subias, J. Aguilar-Martin. ''Process situation assessment: From a fuzzy partition to a finite state machine''. Engineering Applications of Artificial Intelligence. Vol. 19. 2006. pp. 461-477. [ Links ]
22. J. Aguilar, C. Isaza, E. Diez, M. LeLann, J. Waissman. ''Process Monitoring Using Residuals and Fuzzy Classification with Learning Capabilities''. Advances in Soft Computing. Vol. 42. 2007. pp. 275-284 [ Links ]
23. C. Isaza, M. Lann, J. Aguilar. Diagnosis of chemical processes by fuzzy clustering methods: New optimization method of partitions. 18th European Symposium on Computer Aided Process Engineering (ESCAPE 10). 2008. pp. 1-6. [ Links ]
24. A. Orantes. Methodologie pour le placement des capteurs a base de methodes de classification en vue du diagnostic. Ph.D. dissertation. Laboratoire d'Analyse et d'Architecture des Systemes du CNRS. 2005. pp. 29-39. [ Links ]
25. J. Aguilar, R. deMantaras. The process of classification and learning the meaning of linguistic descriptors of concepts. Approximate Reasoning in Decision Analysis. 1982. M.M. Gupta et E. Sanchez (eds.) North Holland. pp. 165-175. [ Links ]
26. J. Aguado, J. Aguilar. A mixed qualitative-quantitative selfleaniing classification technique applied to diagnosis. QR'99 The Thirteenth International Workshop on Qualitative Reasoning. 1999. Loch Awe. pp. 124-128. [ Links ]
27. X. Nguyen, J. Epps, J. Bailey. Information theoretic measures for clustering comparison: is a correction for chance necessary? ICML. New York, USA. 2009. pp. 135. [ Links ]
28. R. Mantaras. ''A distance-based attribute selection measure for decision tree induction''. Mach. Learn.. Vol. 6. 1991. pp. 81-92. [ Links ]
29. R. Mantaras. Autoapprentissage d'une partition: application au classement iteratif de donnees multidimensionelles. Ph.D. dissertation. Univ. Paul Sabatier. Toulouse. 1979. pp. 20-37. [ Links ]
30. C. Uribe, C. Isaza. Unsupervised feature selection based on fuzzy partition optimization for industrial processes monitoring. Proccedings of the 2011 IEEE International Conference on Computational Intelligence for Measurement Systems and Applications. 2011. Ottawa, pp 1-5. [ Links ]
