










Services on Demand
Journal
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkRevista Facultad de Ingeniería Universidad de Antioquia
Print version ISSN 0120-6230
Rev.fac.ing.univ. Antioquia no.76 Medellín July/Sept. 2015
https://doi.org/10.17533/udea.redin.n76a06
ARTÍCULO ORIGINAL
DOI: 10.17533/udea.redin.n76a06
Daily river level forecast based on the development of an artificial neural network: case study in La Virginia -Risaralda
Pronóstico del nivel diario de un río basado en el desarrollo de una red neuronal artificial: estudio de caso en La Virginia –Risaralda
Tito Morales-Pinzón1,2*, Juan David Céspedes-Restrepo1, Manuel Tiberio Flórez-Calderón1
1Grupo de Investigación Gestión Ambiental Territorial, Facultad de Ciencias Ambientales, Universidad Tecnológica de Pereira. Carrera 27 N.º 10-02 Barrio Alamos. C. P. 660003. Pereira, Colombia.
2Observatorio Ambiental Urbano-Regional de Risaralda, Universidad Tecnológica de Pereira. Carrera 27 N.º 10-02 Barrio Alamos. C. P. 660003. Pereira, Colombia.
* Corresponding author: Tito Morales Pinzón, e-mail: tito@utp.edu.co
DOI: 10.17533/udea.redin.n76a06
(Received October 07, 2014; accepted May 24, 2015)
ABSTRACT
The municipality of La Virginia (Risaralda, Colombia) is constantly affected by floods that originate from increased water levels in the Cauca River. Disaster relief agencies do not currently have adequate monitoring systems to identify potential overflow events in time-series observations to prevent flood damage to homes or injury to the general population. In this paper, various simulation models are proposed for the prediction of flooding that contributes as a technical tool to the development and implementation of early warning systems to improve the responsiveness of disaster relief agencies. The models, which are based on artificial neural networks, take hydroclimatological information from different stations along the Cauca River Basin, and the trend indicates the average daily level of the river within the next 48 hours. This methodology can be easily applied to other urban areas exposed to flood risks in developing countries.
Keywords: Artificial neural networks, flood forecasting, flood risk
RESUMEN
El municipio de La Virginia (Risaralda, Colombia) está constantemente afectado por inundaciones que se originan debido al aumento de los niveles de agua en el río Cauca. Los organismos de socorro y atención de desastres actualmente no tienen sistemas adecuados de vigilancia para identificar eventos potenciales de desbordamiento en el tiempo, y así evitar daños por inundaciones a las viviendas o daños a la población en general. En este trabajo, se proponen diversos modelos de simulación para la predicción de inundaciones que contribuye como una herramienta técnica para el desarrollo e implementación de sistemas de alerta temprana para mejorar la capacidad de respuesta de los organismos de socorro. Los modelos, están basados en redes neuronales artificiales y toman la información hidroclimatológica de diferentes estaciones existentes a lo largo de la cuenca del río Cauca, donde la tendencia indica el nivel medio diario del río durante las siguientes 48 horas. Esta metodología se puede aplicar fácilmente a otras zonas urbanas expuestas a los riesgos de inundación en países en desarrollo.
Palabras clave: Redes neuronales artificiales, pronóstico de inundaciones, riesgo de inundación
1. Introduction
La Virginia is a municipality of the Risaralda department in the Andean Region in Colombia. It is located at latitude 4°54'50" North and longitude 75°54'43" West [1], in the valley of the Cauca and Risaralda Rivers. This area has important economic agricultural activity, characterised by an emphasis on coffee [2], as part of the economic dynamics of the municipality, which revolves around agriculture and livestock, extraction of drag materials, fishing and tourism [3]. According to projections made by the National Administrative Department of Statistics [4], the municipality has approximately 31,657 inhabitants, located primarily in the urban area (98.3%).
While passing through downtown La Virginia, the Cauca and Risaralda Rivers often produce floods from their convergence. A disaster of this magnitude in this urban area affects approximately 1190 people and 58 households on average per event [This value was calculated based on the 24 events that occurred during the period 1980-2010, according to information compiled by [5]]. In some extreme cases, the floods have caused approximately 20,000 casualties [6]. This condition of coexistence with the disaster, represented by the frequent floods that occur, has been present throughout the history of the town. The first reports of flooding date from 1922, just two decades after the first urban development [5].
Flood events in the municipality can occur either suddenly or slowly, but in both cases, the configuration of the phenomena depends on natural and human factors [6]. Natural factors are the distribution of rainfall, morphometry and watershed physiography as well as the Risaralda River impoundment following the increase in the level of the Cauca River. However, despite the importance of these elements, the main factor in defining the threat is of anthropogenic nature and involves the occupation of the flood plains of the Cauca and Risaralda Rivers. The occupancy model that has led to this situation was set during the history of the town and is the result of the weaknesses in the land use planning process, as mentioned in the study regarding housing protection danger areas in the county of La Virginia; "the Municipality of La Virginia is a complex phenomenon, where the lack of coherent planning of the past has allowed location of housing in areas of threat" (quoted by [7]).
Because of the frequency and severity of flooding in the city, strategies for risk management must be incorporated into city planning. This requires the development of technical tools at an early stage, allowing the implementation of early-warning systems (EWS) for flood threats. There are currently tools for prediction and monitoring, as well as different types of mathematical models, such as those based on the Navier-Stokes equations for laminar flows, the Kalman filter, genetic algorithms, and ARIMAs (autoregressive integrated moving average time-series analysis) [8] which usually require great volumes of information of the studied context (hydrological, hydraulic and geomorphological variables).
However, as opposed to the weaknesses of these mathematical models in flood forecasting, such as those discussed by [9], thanks to the massive parallelism of its structure, the Artificial Neural Networks models [onwards ANN] have many advantages including adaptive learning, self-organization, fault tolerance, easy insertion into existing technology, and the possibility of operation in real-time in problems related with filtering applications, control and identification of patterns, among others. This is largely due to their capacity of process information in parallel, allowing the development of calculations at very high speeds and exceeding the real-time constraints of most applications that try to serve to these purposes [10].
In Latin America, a flood warning system has been developed for the Biobío River in Chile, which was constructed from historical data collected from 29 floods [11]. A study conducted by the University of Asunción in Paraguay developed six deterministic and stochastic mathematical models using different methodologies, including ANN, to study the flood phenomenon in the Paraguay River, and they found that the most accurate methodology for describing the river dynamics was ANN [12].
Current studies aim to similar conclusions: in Sudan, an ANN model was developed to predict flooding levels in the River Nile. In this study, ANN methodology demonstrated various advantages in relation to other models (especially in the number of variables required to give accurate predictions) [13]. Also, in Taiwan, five models were constructed to forecast the water level of the Tanshui River; according to the results, among all the learning models considered, the artificial neural networks (ANN) yielded more favourable results than other forecast models of water level [14]. There are also many studies of this type in which ANN models demonstrate that they are superior to physical-based hydrodynamic models because they can preserve nonlinear characteristics between input and output variables [15-17].
Other investigations, such as "Impact of multi-resolution analysis of artificial intelligence models inputs on multi-step ahead river flow forecasting" in Harvey River, Western Australia and "Real-time multi-step-ahead water level forecasting by recurrent neural networks for urban flood control" demonstrate the benefits that learning models based in artificial neural networks have in predicting the dynamics of rivers [18, 19]. The same studies proved also that performance can be improved by creating hybrid models based on ANN models.
These experiences show that ANN models are reliable for predicting floods and identifying threats of this type [12]. This feature is often attributed to the model's ability to combine historical information with algorithms that describe the behaviour of the aspects that determine such phenomena. However, ANN models have also been used in different applications to predict the weather, the temperature, the price of electricity, and landslides, among others [20], thus demonstrating their ability to describe complex problems.
The scope of this research is to do a comparison between different flood forecasting models based on different ANN structures and hydrometeorological information, with the objective of estimating the model performance under different configurations related to limited resources of small municipalities.
2. Methodology
2.1. The Cauca River Basin
The Cauca River Basin is one of the most important basins in Colombia because it contains the sugar industry, part of the coffee industry, the Antioquia mining and agricultural development, and a significant portion of the manufacturing industry in western Colombia.
The primary stream bed of the basin, the Cauca River, originates in the Colombian Massif near Páramo Sotará and crosses the country from south to north, crossing the departments of Cauca, Valle del Cauca and Risaralda, where it meets the urban area of La Virginia [1]. The Cauca River Basin has a total area of 63,300 km2, equivalent to approximately five per cent of the territory of the country [21] (see Figure 1).
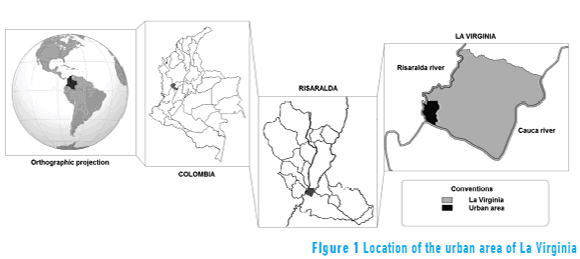
From its origin until La Virginia town, the Cauca river crosses Colombia collecting water from other rivers in more than 32 departments. Risaralda and La Vieja rivers are some of the most important tributary sources, with an average flow of 27.2 m3/s and 95.0 m3/s, respectively [22]. La Vieja, the largest tributary river in the middle of the basin, crosses the departments of Valle, Quindío and Risaralda [22].
2.2. Artificial Neural Networks for prediction of average daily levels in the Cauca River
In this study, the typology of ANN chosen to be constructed was the multi-layer perceptron (MLP). This type of ANN is the most widely used in nonlinear problems of time series prediction, for which it has demonstrated high reliability (see Figure 2). As suggested by [10, 15, 16], the MLP is composed of at least three layers, or levels, of neurons. The first level is the input layer; it is responsible for capturing external stimuli or information that feeds the model. The second level, the hidden layer, receives information from the input layer to process. The third layer, the output layer, receives the processed information and delivers the output variables to the network.
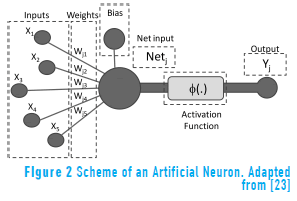
In this model, the input variables are the daily average level and total daily precipitation for the Cauca and Risaralda Rivers, which pass through La Virginia municipality. These variables were defined based on the availability and quality of hydrometeorological information in the section studied of the Cauca river basin, and it was assumed that their behaviour represents fundamental aspects related with the floods in La Virginia.
However, in order to establish some indication about the future variables performance, the selected points to collect information were defined in upstream sections of the Cauca and Risaralda basins before the meeting point of the two rivers in La Virginia. This was done under the assumption that precipitation upstream of the basin (at time t-1) defines the behaviour and the level of the river in the future (time t). To select the optimal points to collect data, a hydrology concept was used, i.e., the concentration time, which is the time it takes the water from a basin to make the journey upstream to its mouth [24]. At this point, it is necessary to explain that the information of La Vieja basin was not used within the defined variables. The assumptions were that given the proximity of its river mouth to the municipality of La Virginia (about 15 km along the drainage) and the hydraulic concentration time of the Cauca river basin, the contribution of La Vieja river in terms of flow would be contained (for the analyzed unit time -one day-) in the measurement of the average level of the Cauca River.
The concentration time was calculated with the equation defined by [25], which also includes variables such as the channel length and the mean slope. The area of the basin is included in the calculation, replacing variables such as runoff and the volume of catchment rainwater.
Next, the hydroclimatological stations were defined due their proximity to the points associated with the concentration times along the watercourse. The average daily water level and total daily precipitation variables were used as the starting point to define the input variables in the model.
The output variables were defined based on their capacity to contribute to the municipal contingency plans with respect to disasters prevention caused by flooding. Thereby, the average daily river level for the Cauca River station at La Virginia point, using time periods of t, t+1, and t+2 (the current day, a day later and two days later, respectively) was considered the best option for the model's output variable (see Table 1).
The selected variables were compared using the Pearson correlation coefficient. This criteria was used for deciding the variables that were included in the networks modelled.
When implementing an Artificial Neural Network Model, the optimum number of neurons and hidden layers in the network architecture cannot be determined analytically; they are generally found experimentally by trial and error [26]. Thus, various networks were constructed with different configurations and then the number of neurons was gradually increased and decreased to obtain a model with the proper adjustment. The predictive capacity in the different networks was compared by calculating the mean square error.
As recommended by [27], the initial number of neurons in the hidden layer was estimated using the Kolmogorov theorem (For any continuous function, it is possible to create an artificial neural network of forward propagation of three layers that appropriately reproduces the behaviour of the function. This network must have n processing elements in the input layer, m in the output layer and 2n +1 in the hidden layer).
Additionally, in accordance with [10], a sigmoidal function was applied to the neurons of the hidden layer and a linear function to the neurons of the output layer. To avoid noise and to shield the input signal from the model, the original data were normalised.
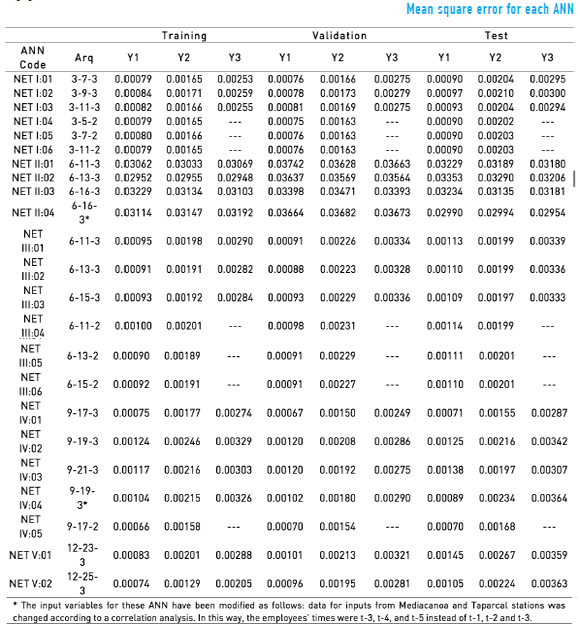
The available information consisted of 1132 to 1455 patterns, depending on the processes used for training, validation, testing and verification. 23 different networks were tested. Following suggestions from [28], each network was trained using Microsoft Excel spreadsheets and the Premium Solver macro version 12.5, which was designed for Excel 2007 by Frontline Systems. The generalised reduced gradient algorithm was used to train the networks. Once completed for all test networks, this process helped to estimate the mean square error for the network outputs (Y1, Y2 and Y3) as a performance measure. To check the performance of the selected network, scatter plots and a correlation analysis (r) were used between the predicted and actual values.
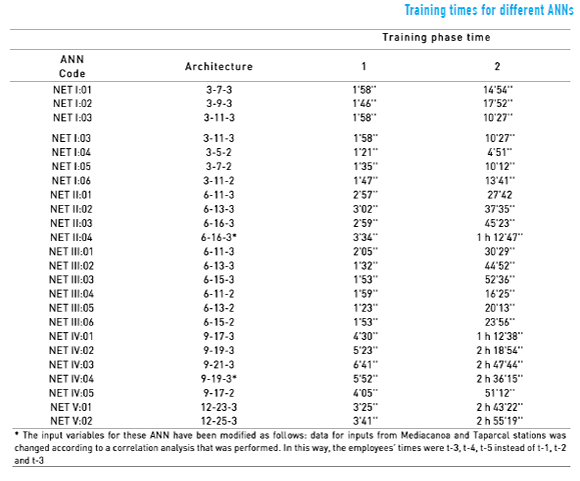
2.3. Neural network training times
The training was conducted in two stages, each of which consisted of 500 iterations. This method was employed to continuously confront training error and validation for each model and to avoid over-training the networks.
Office 2007 Excel was used for the training process, with the addition of the Premium Solver software V 12.5, developed by Frontline Systems Company, Inc. This complement allowed the use of a larger number of variables than the standard solver of Excel (this was a fundamental requirement because it was required for training the complex networks).
The training times may vary according to the computing ability (defined by the characteristics of the computer used to perform the calculations). For the training of the networks herein, a Dell Inspiron 580S computer with an Intel ® Core™ i3 processor and six gigabytes of RAM was used. The operating system was the 64-bit version of Windows 7 Home Premium
3. Results and discussion
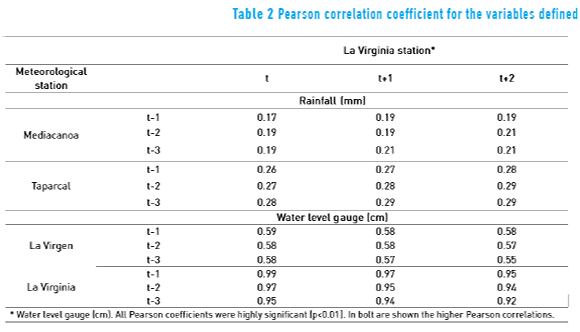
From the statistical analysis of data, there are significant correlations of input variables related to La Virginia station with the output variables of the network. Significant positive correlations were found for the annual precipitation and the water level gauge of different meteorological stations (see Table 2).
Twenty three ANNs were constructed and classified in five groups. These groups were defined based on the input variables used for each one of them. Also, they were classified according to two criteria: the complexity of the networks (implying higher computational requirements) and information constraints.
Then, there are different groups according to criteria of construction and operation. Thus, Group I represents a low complexity of the structure and required information, Group II is medium in both criteria, Group III is medium in complexity of the structure and high in required information, and Group IV and V are high in both criteria. For Group I is much easier to train a simple network because it only requires information of daily average level of Cauca River in La Virginia station (this is located in the same urban area of the municipality).
Similarly, Group II represents models that can be implemented with an average investment of information and computational capability. These models have a simple architecture and they also work with variables related to the total daily precipitation (a much easier variable to measure than variables like the average daily level or flow).
The results showed that the ANN that with the lowest mean square error for the training stage was the NET-IV:05 network corresponding with one of the networks in the group of ANN of major resources required. However, the NET-IV:01 network (one of the simplest networks) showed more skill than NET-IV:05 when processing new information. Thus, we present the NET-IV:01 network as the most accurate because it has better performance than the other networks in the validation and verification process.
Using the mean square error as criteria, models do not behave as expected, because a significant investment in complexity and the high requirement of information does not necessarily generate a proportional effect on the accuracy of predictions. For example, networks belonging to Group V have a higher mean square error when they are compared with simpler networks. This would indicate that small municipalities do not require high investments to develop models with an adequate level of reliability.
Based on the estimates, we verified that the model network NET-IV:01 appropriately fits the behaviour of the output variable Y1 (the level of the Cauca River at time t on the current day). The scatter plot in Figure 3 shows a high level of adjustment and a determination coefficient (r2) of 0.981. This means that the model has an acceptable error rate when predicting the average daily level of the river using data from previous days.
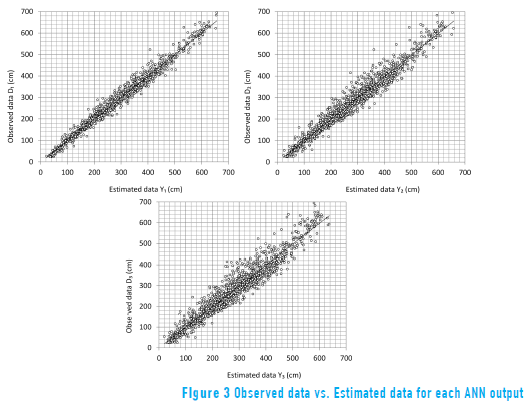
The constructed network can be used to predict values of the variables Y2 and Y3 (Cauca River level at times t+1 and t+2). The determination coefficients were 0.958 and 0.924 for Y2 and Y3, respectively. The dispersion between the predicted and real data is greater as the forecast horizon increases.
The error analysis shows that the forecast values for Y1, Y2 and Y3 are statistically independent and that they have a constant variance (see Figure 4).
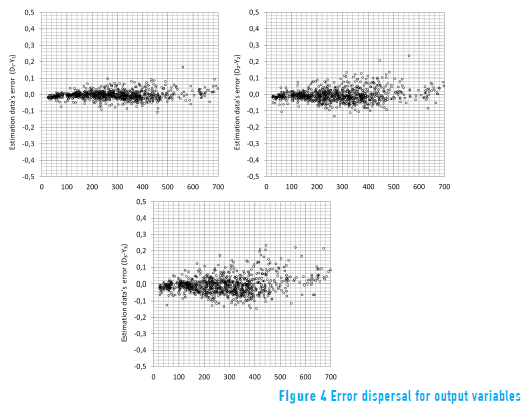
Based on the scatter plot of the error, the model is correctly adjusted to forecast for one day (time t), with an error in many cases of less than 3% (normalised-value, for 75% of the cases), and most are not greater than 5% (90% of the cases). The variable Y2 has a similar adjustment level, i.e., a strong trend toward the line that indicates the error is zero (0), and reason to suggest that for 75% of the cases, the error will be less than 4 % and generally (90% of the data), the error less than 6%.
A similar behaviour is observed for the variable Y3; the error dispersion plot shows a behaviour where, although the values are grouped around the straight line, there is a greater range of errors than for the first two variables, Y1 and Y2 (see Figure 4).
The validation and verification simulation sets had a standard deviation of 18.04 cm error in the model estimates (Error = Real Data - Estimate) for variable Y1. A statistical analysis based on the calculation of quartiles and percentiles suggests that, based on the error distribution obtained, for 50% of the estimates made with the ANN, the error will be less than 9.47 cm, seventy-five per cent of the estimates will have an error of less than 17.33 cm, and ninety per cent of the estimates will have an error of less than 31.19 cm.
Comparing the output variable Y1 (Cauca River level at time t) with the output variable Y2 (Cauca River level in period t +1), the change in the degree of fit of the model is low, presenting a variation in the mean error of 6.63 cm. However, the variation in the error distribution for variable Y2 is larger than that of Y1, presenting a difference of 12.40 cm at the 90th percentile with respect to the output variable Y1. According to the error distribution of the simulations of the output variable Y2, 50% of the estimates made within two days are accurate within 14.53 cm (the median value represents the distribution divided in half according to the frequency of the observed data), seventy-five per cent within 27.23 cm, and in ninety per cent of the estimates, the error will be less than 43.59 cm.
In contrast, the behaviour of the variable Y3 behaves differently than output variables Y1 and Y2 in regard to the distribution of the data. For Y3, the average error is 13.17 cm greater than that found for Y1. According to the distribution of the simulated data, fifty per cent of the estimates of Y3 will have errors less than 19.70 cm, seventy-five per cent will have errors less than 36.05 cm, and ninety per cent will have error values of less than 57.86 cm.
In addition to resulting in a higher error than the other output variables, the Y3 variable has a behaviour that matches the behaviour of the problem addressed. Thus, Y3 can be used to track the general trend of the Cauca River level in specific conditions.
3.1. Neural network training time
ANN models with a less training time and a simpler structure represent a lower investment of development and operation, this is a useful characteristic for small municipalities. The increase of neurons in the hidden layer of the model increases the complexity, which is reflected in the need to invest more time in the training process of the network. Thus, the net that required less training time was network NET I:04, having only 5 neurons in its hidden layer, as opposed to network NET V:02, with 25 neurons in its hidden layer and whose total training time is nearly three hours.
Additionally, there is usually a higher requirement on the computation time in those networks that have three output variables, as observed in networks NET I:01/NET I:05, NET III:01/NET III:04, NET III:02/NET III:05, NET III:03/NET III:06, and NET IV:01/NET IV:05, which share the same architecture in terms of the number of neurons in the input and hidden layers but that differ in the number of neurons in the output layer.
With respect to the current problem, an ANN with a large number of variables and that requires large training or retraining times, such as networks having a number equal to or greater than 19 neurons in the hidden layer (see Figure 5), are highly inefficient if the level of adjustment that they require can be reached or exceeded by less complex networks. However, an increase in complexity will not occur in all cases from a large number of neurons in the hidden layer and in the output; therefore, the long computation time for training necessarily implies a low level of the ANN's efficiency. This is evidenced in network group NET II, which contains the ANNs with high mean square error values and low training times (see Figure 5). These models have a low demand on computational time and a low level adjustment, a situation that makes them less suitable in relation to the current problem in comparison with the other ANNs evaluated.
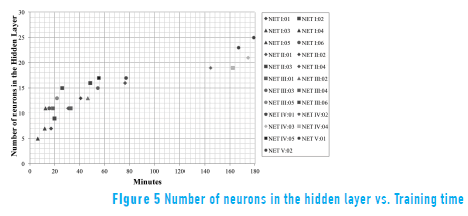
Results obtained from the measurement of training times vs. the number of neurons in the hidden layer and the level of adjustment suggest that, for this problem, the NET IV:01 and NET IV:05 networks presented high levels of efficiency because they showed a good level of adjustment, are less vulnerable to failures by partial damage to the network and have training times that are close to the mean of the other networks (1 h 02 '28").
4. Conclusions
According to the methods explored in this study, it is possible to implement an artificial neural network multilayer perceptron model to predict the level in the Cauca River, with appropriate model adjustments and thereby estimate the flood's risk in La Virginia. This approach could eventually allow the development of early warning systems for disaster prevention and response in cities that are located beside the river valley in Colombia.
Because models constructed using the ANN methodology do not require a priori conceptualisation of the interrelationships that develop within the studied system, they can be built and deployed quickly, efficiently and with very low development and operation costs. In the case study described, the proposed Artificial Neural Network only requires Microsoft Office Excel as platform for development/operation and information of only two meteorological stations.
The ability to adapt and learn from ANN models through historical data allows the models continuously adjust to changes that arise in the immediate context of the studied system. This feature allows flooding problems to be addressed even in the face of high variability phenomena, such as climate change.
For small municipalities having limited resources or information, it is possible to build an ANN with an appropriate level of adjustment and having a good performance of prediction of risk flood (models with low mean square error values). These models would help to small municipalities to management processes focused on early warnings.
Appendix
Appendix A-1
The concentration time given by Bransby-Williams is [25] (Eq. 1):
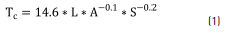
where:
Tc is the concentration time for the basin (hours),
L is the length of the longest watercourse (km),
A is the watershed area (km2), and
S is the average slope (m/m).
Using Eq. (1), the length of the longest watercourse for 24 and 48 hours for each of the streams involved was estimated.
Appendix A-2
The predictive capacity is calculated using a modified estimator for the mean square error (Eq. 2):
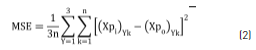
where:
Xpi is the normalised output,
k is the sample size, and
Y is the number of prognostic variables.
Appendix B
In order to correct the different scales used in the ANN, the original input data were normalised using next expression (3):
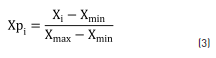
where:
Xpi is the normalised input,
Xiis the independent input data,
Xmin is the minimum input data, and
Xmax is maximum input data.
Appendix C-1

Appendix C-2
Appendix C-3
5. Acknowledgment
The authors wish to thank the projects "Metabolismo urbano y análisis ambiental del aprovechamiento de agua no convencional en edificaciones más sostenibles" (Vicerrectoría de Investigaciones, Innovación y Extensión, Universidad Tecnológica de Pereira, Colombia) and "Observatorio Ambiental Urbano-Regional de Risaralda" (Facultad de Ciencias Ambientales, Universidad Tecnológica de Pereira, Colombia) for financing this study; they also want to express appreciation for the grant awarded to Juan David Céspedes by Colciencias (Departamento Administrativo de Ciencia, Tecnología e Innovación de Colombia).
6. References
1. J. Pulecio. Mitigación de inundaciones ocasionadas por los ríos Risaralda y Cauca en el Municipio de La Virginia, Departamento de Risaralda. Informe final de Consultoría a la Corporación Autónoma Regional de Risaralda (CARDER). Pereira, Colombia. 2010. pp. 1-24. [ Links ]
2. H. Vásquez, M. Holguín, G. Osorio. Base Ambiental con Énfasis en Riesgos. Municipio de La Virginia. Documento técnico de la Corporación Autónoma Regional del Risaralda -CARDER-. Pereira, Colombia. 2002. pp. 1-104. [ Links ]
3. Alcaldía de La Virginia - Risaralda. Nuestro Municipio: Geografía. Available on: http://www.lavirginia-risaralda.gov.co/informacion_general.shtml. Accessed: March 22, 2011. [ Links ]
4. Departamento Administrativo Nacional de Estadística (DANE). Boletín Censo General 2005. Perfil La Virginia, Risaralda. DANE. Bogotá, Colombia. 2010. pp. 1-6. [ Links ]
5. Dirección de Gestión de Riesgos (DGR), Corporación OSSO. Disaster Information System – DESINVENTAR. Available on: http://www.desinventar.net/DesInventar/main.jsp?countrycode=col. Accessed: May 15, 2011. [ Links ]
6. Comité Local para la Prevención y Atención de Desastres del Municipio de La Virginia (CLOPAD). Plan Local de Emergencia y Contingencia Municipio de La Virginia. CLOPAD. La Virginia, Colombia. 2009. pp. 1-151. [ Links ]
7. Corporación Autónoma Regional del Risaralda (CARDER). Diagnóstico de Riesgos Ambientales, Municipio de La Virginia. CARDER. Pereira, Colombia. 2002. pp. 1-50. [ Links ]
8. Consorcio Evaluación de Riesgos Naturales (ERN). Metodología de evaluación probabilista de riesgos naturales. Central American Probabilistic Risk Assessment (CAPRA). Available on: http://www.ecapra.org/es/metodolog%C3%ADa-de-evaluaci%C3%B3n-probabilista-de-riesgos-naturales. Accessed: February 26, 2011. [ Links ]
9. D. Matich. Redes Neuronales: Conceptos Básicos y Aplicaciones. Informe. Universidad Tecnológica Nacional. Rosario, Argentina. 2001. Available on: http://www.scribd.com/doc/48697993/Virus-Hack-Redes-Neuronales-Conceptos-Basicos-y-Aplicaciones. Accessed: March 3, 2011. [ Links ]
10. E. Caicedo, J. López. Una aproximación práctica a las redes Neuronales Artificiales. 1st ed. Ed. Programa Editorial Universidad del Valle. Cali, Colombia. 2009. pp. 1-217. [ Links ]
11. R. González, X. Vargas, A. López, L. Belmar. Sistema de alerta de crecidas en el río Biobío. Uso recursivo de un modelo de Redes Neuronales. Proceedings of the III Encuentro de Aguas. Santiago, Chile. 2002. Available on: http://www.bvsde.paho.org/bvsacd/encuen/gonza.pdf. Accessed: March 14, 2011. [ Links ]
12. C. Guerreño, O. Ferreira, L. Chamorro, R. Almirón. "Análisis de Modelos Matemáticos Aplicados al Estudio del Río Paraguay". Revista de Ciencia y Tecnología. Vol. 1. 2001. pp. 111-118. [ Links ]
13. S. Hag. "Artificial Neural Networks (ANNs) for flood forecasting at Dongola Station in the River Nile, Sudan". Alexandria Engineering Journal. Vol. 53. 2014. pp. 655-662. [ Links ]
14. W. Chih. "Comparing lazy and eager learning models for water level forecasting in river-reservoir basins of inundation regions". Environmental Modelling & Software. Vol. 63. 2015. pp. 137-155. [ Links ]
15. B. Unal, M. Mamak, G. Seckin, M. Cobaner. "Comparison of an ANN approach with 1-D and 2-D methods for estimating discharge capacity of straight compound channels". Advances in Engineering Software. Vol. 41. 2010. pp. 120-129. [ Links ]
16. C. Wei, L. Wen, H. Ming. "Comparison of ANN approach with 2D and 3D hydrodynamic models for simulating estuary water stage". Advances in Engineering Software. Vol. 45. 2012. pp. 69-79. [ Links ]
17. B. Balouchi, M. Nikoo, J. Adamowski. "Development of expert systems for the prediction of scour depth under live-bed conditions at river confluences: Application of ANNs and the M5P model tree". Applied Soft Computing Journal. Vol. 34. 2015. pp. 51-59. [ Links ]
18.H. Badrzadeh, R. Sarukkalige, A. Jayawardena. "Impact of multi-resolution analysis of artificial intelligence models inputs on multi-step ahead river flow forecasting". Journal of Hydrology. Vol. 507. 2013. pp. 75-85. [ Links ]
19. F. Chang, P. Chen, Y. Lu, E. Huang, K. Chang. "Real-time multi-step-ahead water level forecasting by recurrent neural networks for urban flood control". Journal of Hydrology. Vol. 517. 2014. pp. 836-846. [ Links ]
20. G. Ovando, M. Bocco, S. Sayago. "Redes Neuronales para Modelar la Predicción de Heladas". Revista Agricultura Técnica. Vol. 65. 2005. pp. 65-73. [ Links ]
21. Universidad del Valle, Corporación Autónoma Regional del Valle del Cauca (CVC). Volumen I: Caracterización del Río Cauca Tramo Salvajina – La Virginia. Available on: http://www.cvc.gov.co/cvc/Mosaic/Publicacionesf1.html#volumen1. Accessed: April 12, 2011. [ Links ]
22. Universidad del Valle, Corporación Autónoma Regional del Valle del Cauca (CVC). Volumen IV y V: Caracterización de Ríos Tributarios del Rio Cauca Tramo Salvajina – La Virginia. Available on: http://www.cvc.gov.co/cvc/Mosaic/Publicacionesf1.html#volumen4. Accessed: April 3, 2011. [ Links ]
23. M. Gestal. Introducción a las Redes de Neuronas Artificiales. Universidade da Coruña. http://sabia.tic.udc.es/mgestal/cv/RNAtutorial/TutorialRNA.pdf. Accessed: March 20, 2011. [ Links ]
24. F. Sánchez. Medidas Puntuales de Permeabilidad. Universidad de Salamanca. Available on: http://hidrologia.usal.es/temas/Slug_tests.pdf. Accessed: March 20,2011. [ Links ]
25. M. Wanielista, R. Kersten, R. Eaglin. Hydrology: water quantity and quality control. 2nd ed. Ed. John Wiley & Sons. New York, USA. 1997. pp. 1-592. [ Links ]
26. M. Bruen, J. Yang. "Functional networks in real-time flood forecasting -a novel application". Advances in Water Resources. Vol. 28. 2005. pp. 899-909. [ Links ]
27. L. Feng, J. Lu. "The practical research on flood forecasting based on artificial neural networks". Expert Systems with Applications. Vol. 37. 2010. pp. 2974-2977. [ Links ]
28. J. García, A. López, J. Romero, A. García, C. Camacho, J. Cantero, et. al. "Hojas de cálculo para la simulación de redes de neuronas artificiales (RNA)". Questiió. Vol. 26. 2002. pp. 289-305. [ Links ]
