











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introduction
Measurement and evaluation (M&E) activities are considered key in terms of knowledge of the status of an entity under monitoring [1]. The M&E are a mechanism through which it is possible to identify the behavior related to an entity under analysis, detecting early deviations and/or anomalies regarding its expected behavior [2].
It is necessary to consider the use of a formal measurement and evaluation (M&E) framework that allows the definition of concepts, terms, and the required relationships to understand the M&E process, which will provide a quantitative point of view about the monitored entity [3]. The entity to be monitored could be tangible (e.g. a person) or abstract (e.g. a system); for that reason, it is important to early describe it for the identification of properties or characteristics feasible of quantification. However, such description or characterization should be agreed by stakeholders to foster the measurement process automatization. The measurement and evaluation framework C-INCAMI (Context - Information Need, Concept Model, Attribute, Metric, and Indicator) [2, 4] is a conceptual framework with an underlying ontology, which defines the concepts, terms, jointly with the necessary relationships useful for specifying an M&E process. In this way and through its use, it is possible to get a common understanding related to which the entity represents (e.g. a person, a system, a vehicle, etc.), its characterization through attributes, the metrics responsible for the quantification of each attribute, and the indicators as a mechanism for interpreting each measure using the decision criteria. Thus, there is a project definition organized under a given framework, that allows defining the entity, describing it through a discrete perspective (i.e. characteristics or attributes) useful for quantifying a point of view. The quantification is carried forward using metrics which contains the association among the attribute to be analyzed (e.g. the value of the corporal temperature), the device to be used (e.g. a digital thermometer), and the definition about the range of expected values, units, scale, jointly with the indicator definition, responsible for interpreting each value following decision criteria.
Therefore, each measurement and evaluation project can be defined in terms of the C-INCAMI framework, using the GOCAME strategy as a guide (Goal-Oriented Context-Aware Measurement and Evaluation)[5]. The result is an eXtensible Markup Language (XML) file organized under the concepts defined in the framework, which is readable and understandable by humans and machines, to foster the measurement project interoperability and its implementation (i.e. automatization)[6]. In general, the object or subject to be monitored are referred to as an entity, because the meaning and attributes are unknown up to the project definition is read. In such a moment, for example, it is possible to know whether the entity is a person or a system. In other words, the measurement Project definition (i.e. a simple XML file) is a self-contained file that specifies the entity, their attributes, metrics to quantify each attribute, decision criteria used for interpreting the measures, among other aspects.
The data stream processing strategy (DSPS) is a data stream engine based on Apache Storm (https://storm.apache.org), which automatizes an M&E project defined in terms of the C-INCAMI framework. It allows integrating heterogeneous data sources using technologies such as IoT, and to make decisions in real-time. DSPS uses a case-based Organizational Memory (OM) which stores the previous experiences and knowledge related to the entities under monitoring. In this way, when some situation for an entity is detected, an alarm could be thrown jointly with a set of recommendations from the OM [7, 8]. It could be possible that an entity has no previous experience or specific knowledge in a situation (e.g. the M&E project is new). However, this does not mean that the OM is empty, because it keeps the knowledge and previous experiences from all the projects. If it is possible to look for a similar semantically entity, then it would be possible to reuse its specific knowledge by analogy (i.e. an approximated recommendation is better than nothing). Thus, it would be adequate to identify whether it is possible to detect entities semantically similar in an M&E project based on the C-INCAMI framework. In this way, the main contribution in this work is to carry out systematic mapping of the literature to identify and find the techniques, and methods that allow the detection of semantically similar entities through the use of the research method termed Systematic Mapping Studies (SMS) [9-13].
This paper is organized as follows. Section 2 presents the research work and the Systematic Mapping Studies methodology. Section 3 describes the execution of the protocol related to the SMS research method. Section 4 outlines the results related to the study. Section 5 proposes a comparative analysis between the obtained documents jointly with a citation analysis. Section 6 summarizes reached conclusions and future works.
2. Research method
As indicated, this research is designed to follow the guidelines for SMS as specified in [9-13] and it is applied to the Data Stream Processing and Data Science. A Systematic Mapping Study may be more appropriate than a Systematic Literature Review (SLR) when we realize that there is very little evidence or that the research topic is very broad. In this way, applying a SMS allows tracing the evidence in a domain to a high level of granularity. For example, in [14] the wide search related to requirements elicitation process model is preferred instead of a specific and deep search because the global perspective is prioritized.
The subject of semantic similarity of entities, feasible of monitoring under a real-time decision-making process, is not a common or frequent aspect. However, the application of systematic mapping in machine learning and data mining is not new, for example, the systematic mapping has been applied in process mining [15], missing values techniques in software engineering data [16], machine learning applied to software testing [17], data quality based on computational intelligence techniques [18], among others.
In this section, the review protocol will be detailed to carry out the systematic review. The following steps will be considered: a) Identification of a need for revision, b) Specification of research questions, c) Determination of the search strategy, d) Specification of the data extraction process, e) Specification of the synthesis process and f) Application of the selection criteria of the articles found. Next, the research questions are described.
2.1 Specification of research questions
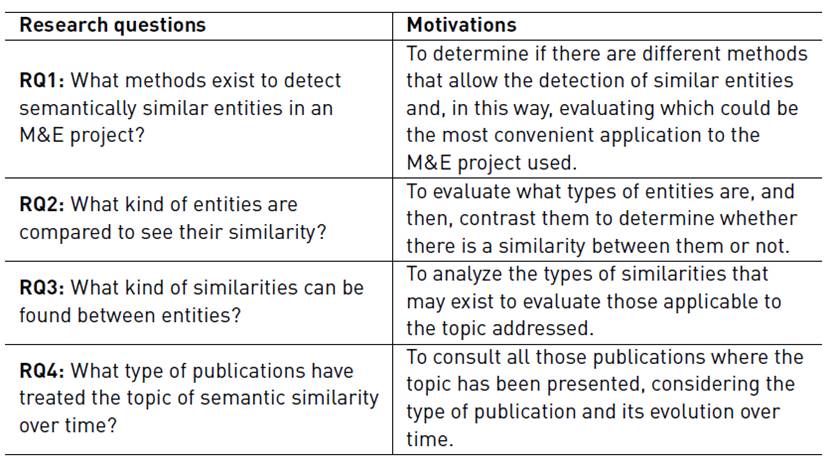
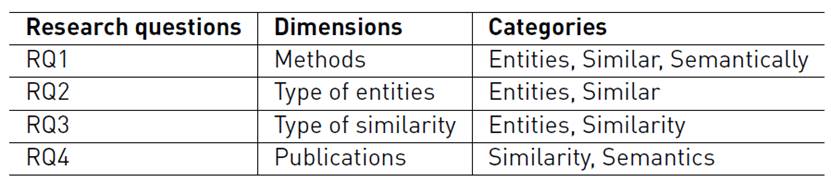
In this work, the objective is related to carrying out a systematic mapping of the literature in order to find techniques and methods that allow us to detect semantically similar entities in measurement processes. Following the methodology used, the Research Questions (RQ) which guide the work are defined. The main research question is defined, as follows RQ1: What methods exist to detect semantically similar entities in an M&E project? From the main question, the following questions arise , RQ2: What kind of entities are compared to see their similarity? RQ3: What types of similarities can be found between entities? and finally RQ4: What type of publications have treated the topic of semantic similarity over time? Table 1 introduces each research question, describing its definition jointly with the associated motivations.
2.2 Search strategy
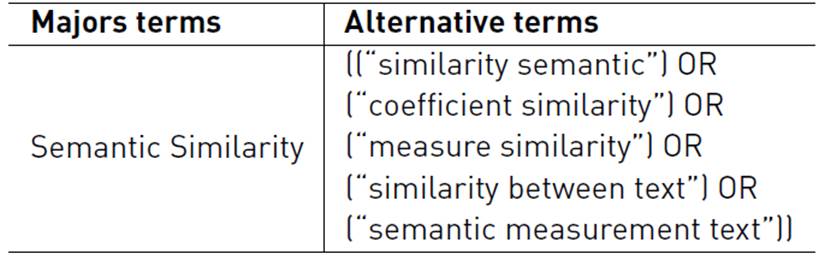
Once the research questions have been defined, we describe the search strategy established to carry out the research work. Table 2 shows the defined search chain, according to the main objective established.
Once the search chain is defined, it is necessary to identify and define its associated strategy. Table 3 summarizes the search strategy, establishing the parameters considered to perform it.
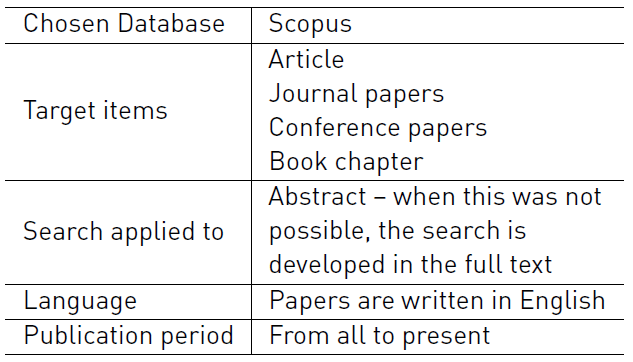
The selected database for carrying forward the search strategy was Scopus, focusing on the articles, journal papers, conference papers, and book chapters.
2.3 The selection process of articles
Once the search strategy has been established, the summary of the selection strategy of articles is presented in Table 4. It indicates the inclusion and exclusion criteria aligned with the selected methodology on both the abstracts as full articles.
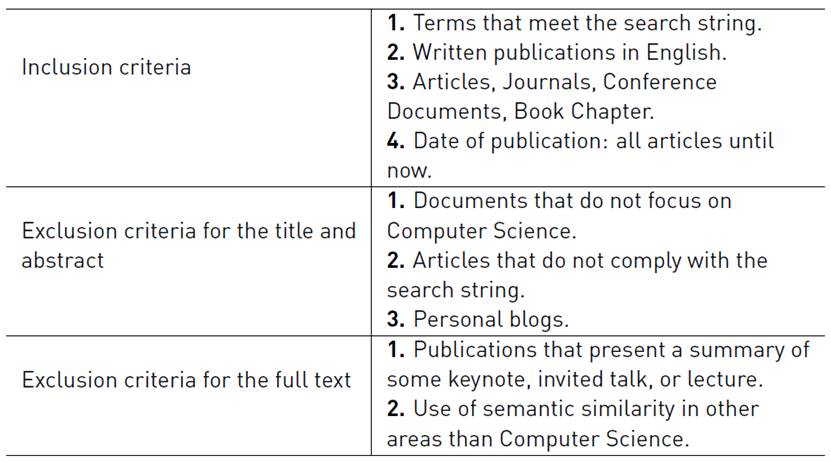
At the time of selecting the articles, the steps performed were the following: a) All duplicate items were removed; b) The articles were filtered using the results from the previous step, applying the inclusion and exclusion criteria established in Table 4; c) Using the filtered results, an analysis was carried forward to select the definitive corpus.
2.4 Data extraction process
Using the obtained articles from the selection process (i.e. the definitive list of papers for the research), the data extraction form is prepared, indicating the classification scheme, detailing the corresponding dimensions, and categories (See Table 5].
As a supporting material, an Excel file was prepared to incorporate all the articles found and indicating the reasons for including or excluding each one based on the reading of the Abstract/full Article.
2.5 Synthesis process
The synthesis process is an integral part of the used methodology. It is responsible for evaluating each found article, eliminating duplicates and selecting only those that comply with the search string, the inclusion and exclusion criteria, the indicated keywords as well as the types of filtered documents (i.e. journal articles, conference papers, among others). Next, each abstract of the downloaded articles was read, selecting those that gave a partial or total response to the research questions (see Table 1]. Finally, the articles were selected as long as they could give answers to the research questions previously defined.
3. Execution of SMS
In this section, the execution of the defined protocol is detailed. The search is performed according to the search string established in Table 2, considering as well as the search strategy specified in Table 3. Next, the results were filtered using the inclusion and exclusion criteria (See Table 4] to refine the search for articles of the selected theme. Figure 1 shows a screenshot related to the first application of the search string in the Scopus (see Table 2], which ran at 14-Oct-2019 18:30hs (Argentina).
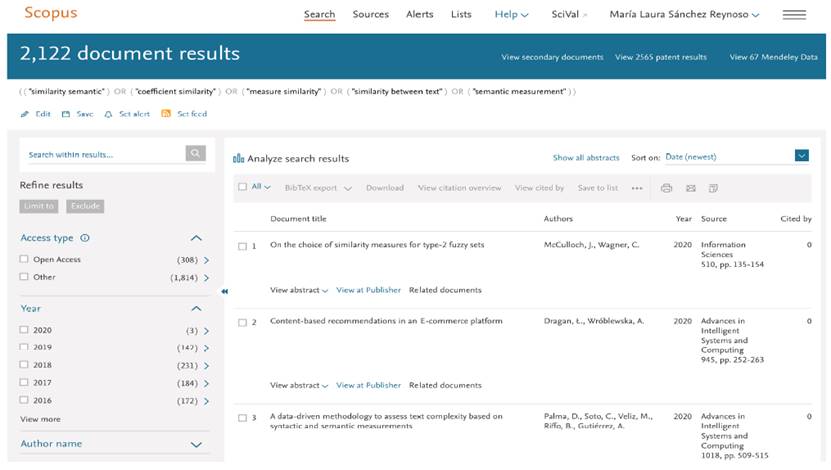
Applying the original search string defined in Table 2, 2,122 records were found. However, incorporating (“entity” OR (“entities”)) AND at the beginning of the search string, allows refining the search string establishing that the terms entity or entities must be present in the listed documents as a result. The refined search string answered with 111 documents, then filtered using the following conditions i) Subject Area: it was limited to the “Computer Science” and “Engineering” areas, ii) Document Type: limited to conference papers, articles, and book chapters, iii) Keywords: the words “Semantics”, “Semantic Similarity”, and “Similarity” were chosen, iv) Language: English. Once the filters were simultaneously applied, just 25 documents were obtained.
The selection of the articles was carried forward through the reading of the abstract, considering the best and alternative terms, jointly with the research questions. Thus, after reading them, only 6 documents were retained from the original 25 documents, corresponding all of them to journals between 2010 and 2018.
4. Summary of the results obtained
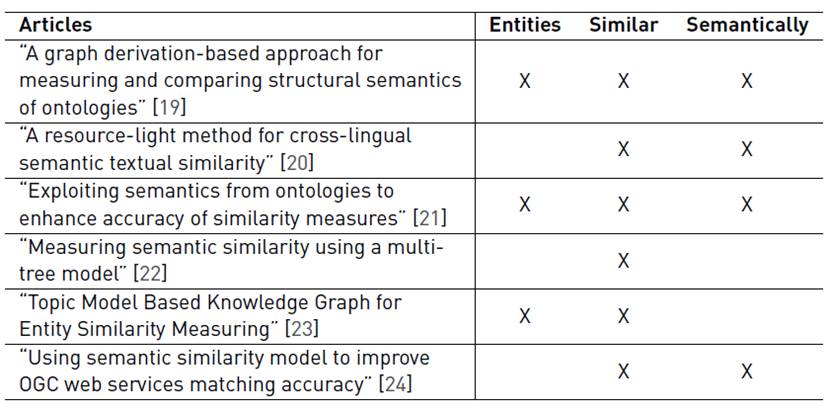
From the final list related to the selected documents, four articles simultaneously satisfy the requirements related to filters, relevance, and research questions.
In the first work [19], the authors describe a process organized in three stages for measuring and comparing ontologies. In this sense, the concept of stable semantic measure is introduced. Even when the semantic similarity is applied to the ontologies, the underlying idea could be related to the entity under monitoring as a way for determining the semantic similarity between them.
In the second work [20], the authors propose an unsupervised approach for measuring the semantic similarity in short texts. It is very interesting because the text description is an alternative to incorporate at the moment in which an entity is defined.
In the third work [21], the author proposes ColorSim, a way in which the semantic similarity could be quantified considering the embedded semantic in OWL 2 (Web Ontology Language) annotations.
In the fourth work [22], the authors introduce a new technique for computing the semantic similarity between two entities. It is very interesting because the technique is based on structured knowledge coming from an ontology or taxonomy. The technique proposes the use of the multi-tree concepts for determining its similarity based on the underlying ontology or taxonomy.
In the fifth work [23], the authors propose to develop a thematic model to calculate the similarity between graphical entities. This article is interesting for our work because it proposes the use of a thematic model to measure similarity, allowing us to make a comparison with the previous articles where they also mention techniques and methods to measure semantic similarity. The underlying idea is to compute the similarity based on a topic model related to the document content jointly with the hierarchical content organization obtained from the knowledge graph.
In the sixth work [24], the authors propose a semantic similarity measurement model to determine the semantic similarity in geographic information. The semantic proposal addresses the geographical query strategies, improving the precision of keyword-oriented queries. The underlying idea falls in using metadata coming from the OGC geographic information services for contrasting them with the desired service by users. Thus, the matching between the expected services from the users and those offered are prioritized through the similarity computation using metadata and query, making easy the searching and reaching the desired service.
The selected articles allow simultaneously answering each research question aligned with the objective of this research. The number is not high, but the results are pertinent to the research line and useful from the conceptual viewpoint.
5. Comparative analysis of results obtained
Considering the selected articles, four articles have satisfied simultaneously the requirements related to filters, relevance and research questions. Thus, it is possible to compare them to evaluate their content from the perspective of the authors.
In Table 6 below, it is possible to appreciate in detail the articles selected for the SMS along with the comparison between them.
In [19], the authors mention the use of a graphical derivation representation (GDR) approach to semantic measurement, which captures the structural semantics of ontologies. They focus on the experimental comparison based on new ontological measurement entities and distance metrics;that is to say that, in this article the concepts of entities and metrics are taken into account, allowing it to be selected in order to evaluate in our work the technique proposed by the authors and how they carry out the experimental process. The approach is based on a graph derivation of ontologies for reaching a stable semantic measurement. The authors outline different issues in relation to the expression of concepts in ontologies, for example, the possibility of expressing the same concept in different ways in two distinct ontologies. The approach is substantiated in three stages describing the first stage as a Graph Derivation Representing (GDR) based approach in which each ontology’s concept is derived through the application of a given set of rules. In the next stage, it will merge a set of GDR to produce an integrated GDR for the whole ontology. Finally, in the last phase, the ontologies’ relationships are treated to homogenize concepts (e.g. identify and unify the expression of those concepts expressed differently in two or more ontologies). Thus, both GDRs could be compared in terms of a level of correlation between ontological entities.
On the other hand, in [20], the authors propose an unsupervised and simple approach to measuring semantic similarity between texts in different languages. Using three different datasets, the semantic similarity was measured on short texts. Thus, the authors show that the proposed approach achieves similar performance to supervised and resource-intensive methods, showing stability across different language pairs. The process consists of comparing two texts expressed in different languages and identifying how similar they are, using the Natural Language Processing (NLP). Initially, the language's corpus for each source language is obtained. Next, a word embedding model is built for each language. Thus, the embeddings language for each short text is obtained. Authors employ a translation matrix related to both languages for contrasting the similarity using a model derived from the short texts, obtaining a bilingual modeling space. From there, both sentences could be compared using the cosine distance to know the level of proximity between them semantically speaking. Taking into account the objective of our research, this article is selected after applying the SMS protocol, because it is interesting to describe the approach they take to measure semantic similarity which helps to answer previously defined research questions as well as to analyze the technique and procedure carried out in the measurement. It can be observed in Table 6 that this article describes concepts such as similarly and semantically, which are part of our search chain defined to execute SMS.
The authors in [21] propose ColorSim, which is a measure of similarity that considers the semantics of the OWL2 annotations, to accurately calculate the relationship of two commented ontology entities. They make a comparison between ColorSim and the most advanced approaches and then report the results obtained from exploiting the knowledge coded in ontologies to measure similarity. This article is selected in our research to learn how the authors approach the concept of measuring similarity using a measurement that allows precision to be calculated. Also, the proposal considers the hierarchical aspects of the ontological entities to compute the level of similarity between them, avoiding, in this way, high similarity rates when the structural meaning is divergent. Thus, contents and hierarchical relationships are jointly considered to avoid the isolation of relationships and/or contents when the level of similarity needs to be computed.
Finally, in [22], the authors describe a new technique for calculating semantic similarity between two entities. The proposed method is based on structured knowledge extracted from an ontology or taxonomy. A concept of multiple trees is defined, and a technique is described that uses a multiple tree similarity algorithm to measure the similarity of two multiple trees constructed from taxonomic relationships between entities in an ontology. The idea of selecting this article consists of analyzing the technique proposed by the authors to measure the semantic similarity between two entities. The initial assumption indicates that is possible to represent a concept from an ontology or taxonomy as a hierarchical tree that is ordered based on its features and relationships. Thus, given two concepts and their corresponding ontologies, each concept could be expressed as a tree using its associated features and relationships indicated within is ontology. In this way, having two different concepts expressed as a tree, a new tree could be built from the merging of the previous ones to compute the joint weighting from the leaf to the root. Such weighting represents the level of similarity between the original trees. This strategy is non-linear and as a difference with other linear approaches (e.g. cosine distance, etc), this strategy considers the feature meaning, but also the relationships between them for computing the similarity.
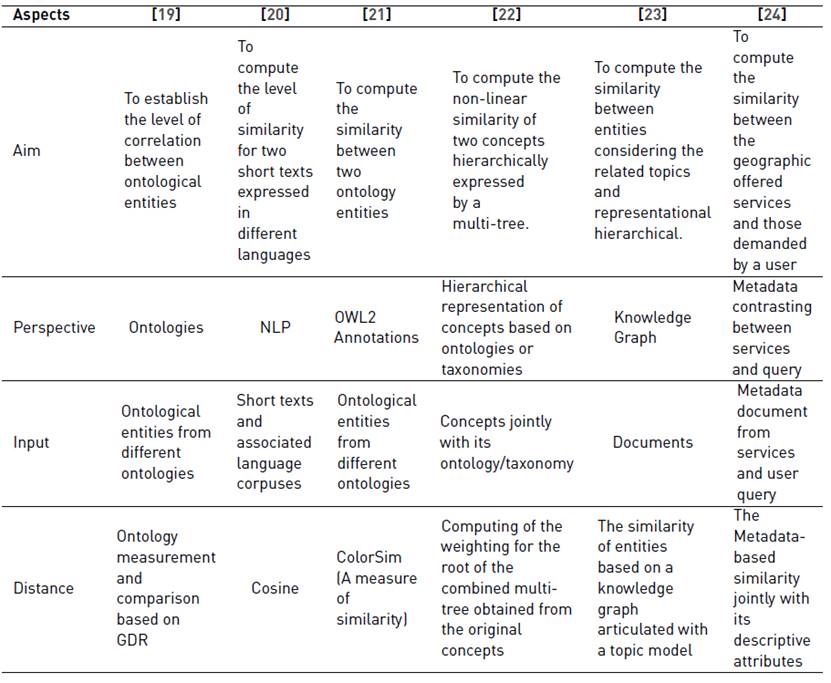
Table 7 shows the aim, perspective, inputs and how the distance is computed in all the alternatives (even the excluded before). On the one hand, about the distance computing, no one uses the same way to compute such similarity, while [19] propose the computing based on ontologies and comparing a GDR, [20] uses the cosine distance based on Word2Vec models, [21] employs ColorSim based on OWL 2's annotations, [22] boards the computing considering thee hierarchy by multi-trees, [23] takes into consideration a knowledge graph and topic model for obtaining the similarity, and [24] computes the similarity based on metadata documents from services. On the other hand, the used perspective for each one is based on ontologies for [19, 21, 22], while it is NLP in [20], knowledge graph and topic models [23], and metadata documents [24] .
Comparing the selected articles, all of them refer to the underlying concepts associated with entities, similarity, and semantic, proposing different kinds of techniques, methods or models which allow measuring the semantic similarity among entities.
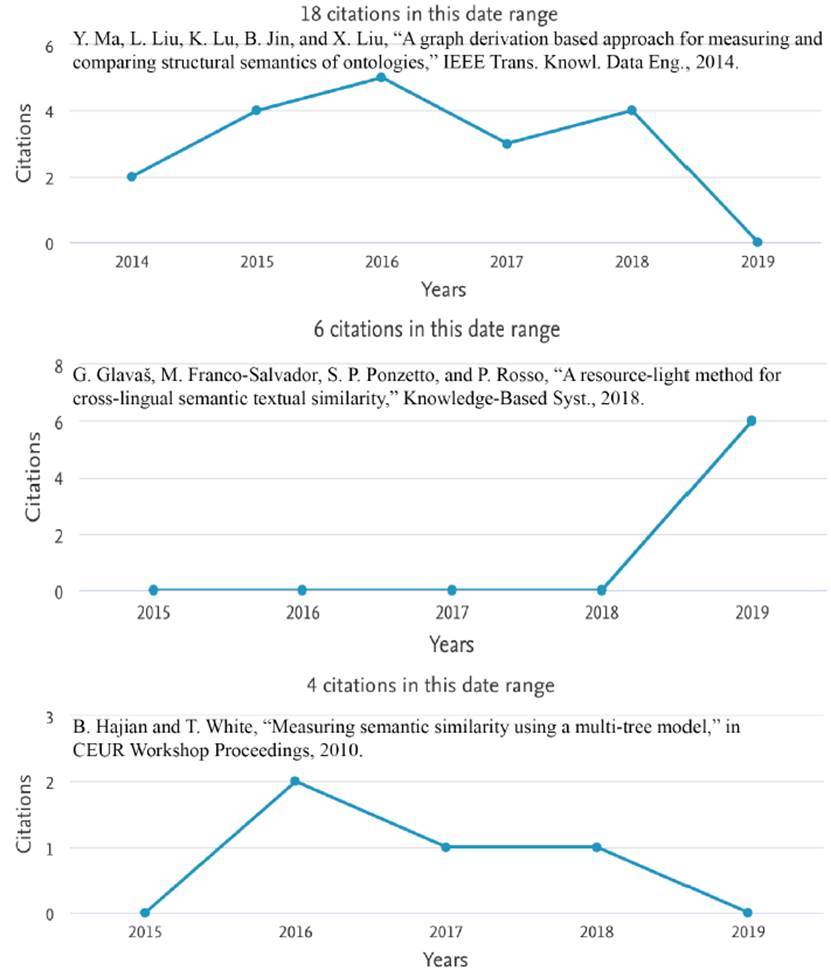
Figure 2 introduces comparatively the citation index of each retained article, analyzing the citation evolution. The articles [21, 23, 24] are not present in the previous figure because they do not have citation associated, in other words, the citation index is zero.
From the three documents, the document [19] is the most cited article, reaching a citation peak in 2016 with five references. In this sense, it is worthy to mention that it has had a continuous citation from 2014 to 2018, being without citation during 2019. The minimum citation was in 2014 with two citations, remaining the rest of the years above this citation level (with exception of 2019). However, the document [20] has six citations until now limited to 2019 only. In other words, even when [19] has an accumulated citation index upper than [20], the last one has a better impact per year. In contrast, the document [22] accumulates 4 citations distributed between 2016 and 2018, without peaks that allow standing out from the previous ones.
It is possible to establish a scoring for the articles based on the citation indexes in order to provide a relative importance associated with the specific interest of each one. In this sense, taking into consideration the level of citation, the historical scoring model would provide the following order:
“A graph derivation based approach for measuring and comparing structural semantics of ontologies” with 18 citations,
“A resource-light method for cross-lingual semantic textual similarity” with 6 citations,
“Measuring semantic similarity using a multi-tree model” with 4 citations,
In addition to the previous scoring and based on Figure 2, it should be highlighted that taking the average by the year or the relative importance bounded to the last two years, the order previously indicated could change the first two positions such as it is synthesized in Table 8.
That is to say, considering the average by year the new order would be [20] (6 citations/year), [19] (3.6 citations/year), [22] (0.44 citation/year), and [21, 23, 24] (0 citations/year). Even, considering the citations indexes bounded to the last two years (i.e. 2019 and 2018) the mentioned order is kept as follows [20] (6 citations), [19] (4 citations), [22] (1 citation), and [21, 23, 24] (0 citations/year).
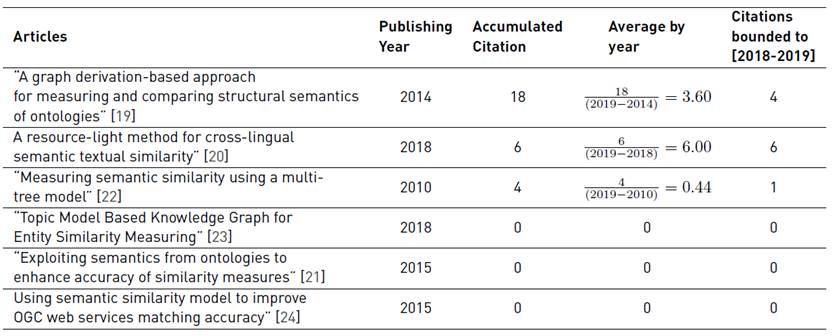
Thus, it is should be mentioned that the accumulated citation index provides a historical perspective, while the average by year represents an interest average rate which is interesting to be contrasted to analyze tendencies and peaks.
6. Conclusions and future work
This paper presented the application of a systematic mapping study. In this kind of study, all the evidence could be limited and plotted for a domain at a high level of granularity. The main and alternative terms introduced as part of the collecting method were “entity”, “entities”, “similarity semantic”, “coefficient similarity”, “measure similarity”, “similarity between text”, and “semantic measurement text”.
The underlying idea related to the entities semantically similar is to reuse the knowledge and previous experiences when some similar entity has no evidence, or it is very limited. Thus, by the reuse of the knowledge and previous experiences, a recommendation system based on the organizational memory could deliver analogous courses of action for decision making.
In this mapping, a total of 2,122 documents were found, reduced to 111 by applying the exclusion and analysis criteria. Thus, a set of filters was applied focusing on computer science and engineering areas, among other aspects. Finally, just four works simultaneously satisfied the requirements associated with the objective of the research in concordance with the applied method.
The semantic similarity applied to entities under monitoring in the measurement and evaluation projects is a challenge. Real-time decision making depends on the obtained measures, the monitored entity, and the context in which it is immersed.
As a future work, a comparative analysis among the strategies, functionalities, and algorithms related to the semantic similarity computing will be carried forward.

