











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Cited by Google
Cited by Google  Similars in
SciELO
Similars in
SciELO  Similars in Google
Similars in Google 
 Permalink
Permalink1. Introduction
At present, it is necessary for software products to obtain a quality certification in order to compete in an increasingly demanding market [1,2]. Software testing is one of the activities that contributes to quality in the software development process [3]. They allow detecting defects in the source code during the development of a software product [4,5]. The tests are left for the last stages of the project and are not carried out with the necessary quality. Due to this, it is necessary and it is of great benefit, the automation of the testing process in order to reduce its costs and increase its effectiveness [6-9].
One of the main tasks related to the design of the test cases is the creation of test data, which represents approximately 40% of the total test costs [10,11] . Generating test data is a crucial task, as extensive testing is very costly in time and effort [12]. In this context, the appropriate design of the test suit is important, including a selection of the appropriate values, to detect a large number of defects [13], which is the objective of the software test.
Software testing continues to occupy space in the scientific papers of multiple researchers. In particular, the generation of test paths and values to support the design of test cases [14-16], as well as the processes related to software testing [17-19].
There are some proposals that focus on planning and calculating the indispensable means to carry out the tests [20], as well as on the automatic generation of scenarios [21] and test values [11] in addition to other proposals that introduce metaheuristics for the automated generation of tests that address their solution as an optimization problem [22-24]. The main objectives of these proposals are the reduction of the time associated with this process, the simplification of its execution by developers and testers, and the obtaining of wide degrees of coverage, reducing the time used to carry it out. An exception is the mutation test because the test cases are selected from the defects they detect, but for this, the test suit is run on the mutated code. This requires additional effort in running the mutant tests.
Therefore, it is necessary to work on proposals that consider those values that can identify a greater number of defects, as well as the paths that have the greatest significance. The integration of different test case design techniques [25] can allow the generation of values that can determine a greater number of defects. The values that respond to different techniques must have a greater capacity to detect errors. Then, with these values, combinations of values are generated in reduced form. One way to consider the effectiveness of the tests is to introduce in the heuristics and in the objective function, some criteria of the significance of the values in terms of the number of errors that they can detect.
This work presents an optimization model focused on error detection, to achieve a reduction of the unit test suite from the moment of its generation, using heuristic algorithms. The proposal has been implemented in a tool that allows the generation of a unit test suite in production environments, considering the significance of values and paths for error detection.
2. Related work
There are different works that apply metaheuristic algorithms for the generation of test values.
In [26], it is provided a comparative analysis investigating the impact of four common constraint handling techniques (Check, Solve, Tolerate, and Replace) on six widely used combinatorial test set (coverage matrix) generation algorithms: The Automatic Efficient Test Generator (AETG), Deterministic Density Algorithm (DDA), In-Parameter-Order (IPO), Particle swarm optimization (PSO), Simulated annealing (SA) and Tabu search (TS). They posit that the constraint controller is a crucial factor influencing the performance of the test suite generation algorithms on which it is developed. The Verify technique implemented with the Minimal Forbidden Tuple (MFT) approach is the fastest option for handling constraints. The replacement technique that resolves constraints as a post-processing phase tends to produce smaller constrained coverage matrices than the currently widely used Verify and Solver techniques, especially for one-test-at-a-time framework test suite generation algorithms. They also show that it is important to choose a constraint controller specifically suitable for the algorithm and the specific goal (size of the test suite, computational cost, or fault-revealing ability). For example, to generate the smallest constrained coverage matrices, Replace is the best choice for AETG, DDA, and PSO; while Tolerate might be more promising for SA and TS. This study only provides information for the choice of constraint controller, so that the performance of existing and newly designed test suite generation algorithms can be improved. It also offers a better understanding of the strengths and weaknesses of constraint management techniques.
In [27], two metaheuristic algorithms are merged to improve the efficiency of the generated test cases. It uses a genetic algorithm to generate good test data from previously generated candidates and the tabu search is added to the mutation step of the genetic algorithm to reduce search time.
In [28], it is introduced a Particle Swarm Optimization (PSO) based test data generation method that can generate a test data set to cover multiple target paths in a single run. In the work, a new training function is designed that can guide the data collection to achieve multipath coverage and avoid premature convergence. For the multipath coverage problem, different fitness functions are applied to evaluate the best individual position and the best overall position. There are several concepts covered in the proposal. Route fitness: the sum of the weighted branches, distance function. Fitness for the best individual position: it is the minimum of the single-path fitness functions; it guides the particles so that they do not converge on a specific path. Fitness function for the best global position: the sum of those single-route fitness functions guides the population to achieve multi-route coverage and avoid premature convergence.
In [29], genetic algorithms that start from the domain are used to generate suitable values that satisfy previously defined test criteria. The established criteria are: obtaining complete coverage of the branch, controlling the number of iterations, and obtaining a set of test data for structural tests. It is applied to several problems whose complexity varies, from a solver of quadratic equations to a generic ordering module that includes several procedures. In these cases, full branch coverage was obtained. To obtain better quality in the generated test data, they design a fitness function that generates data near to subdomain boundary.
In [30], an alternative based on the combination of population metaheuristics with a Tabu List for the generation of test cases is presented. The performance of the solution is tested with a set of programs of varying complexity. It takes into account the coverage in the function by using the particle swarm algorithm to compare the value it gets with a pre-established coverage criterion.
However, there are still some limitations in these proposals. For example: algorithm parameters may affect the efficiency of test data generation, and manual construction and instrumentation of training functions are time-consuming, especially for complicated programs. Furthermore, these proposals do not take into account the criterion of the significance of the values they generate in terms of the number of errors that they can detect. Its validations include comparisons of generation time and a number of combinations of values generated, but do not analyze the effectiveness of the combinations of values generated.
3. Background of this work
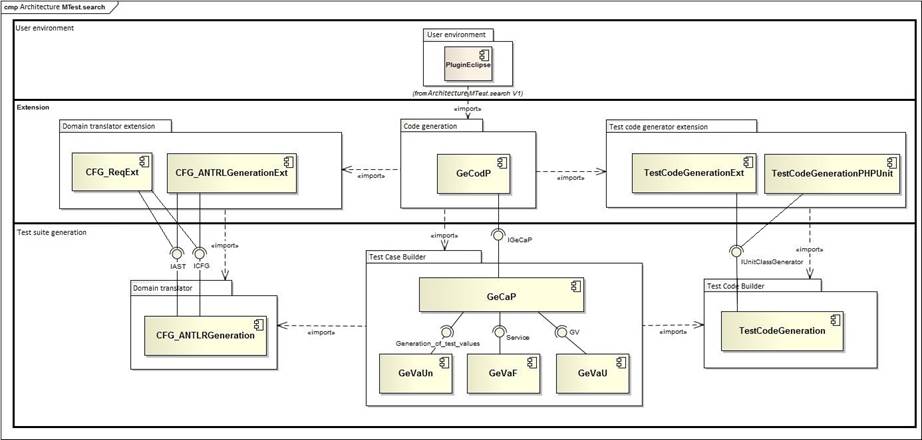
The fundamental objective of the previous proposals is to reduce the time associated with this process, to simplify its execution by developers and testers, and to obtain wide degrees of coverage by reducing the time used to carry it out. Although coverage criteria associated with Software Engineering techniques are used, there is no emphasis on the use of Software Engineering (IS) design techniques that can provide additional information to generate test suites with high levels of error detection. This model is part of the framework, MTest.search. This framework integrates test execution workflows, optimization models for test case reduction, and integrated software tools that support workflow execution [31]. In this paper, the proposed heuristic function
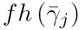 is expressed in terms of knowing how much the new combination contributes to the equivalence partitions that were already identified in the combinations of previous values generated. Therefore, this is valid only for functional tests and does not consider the significance of input values, scenarios, or paths.
is expressed in terms of knowing how much the new combination contributes to the equivalence partitions that were already identified in the combinations of previous values generated. Therefore, this is valid only for functional tests and does not consider the significance of input values, scenarios, or paths.
The software tools that support MTest.search have been developed following a component-based architecture shown in Figure 1. They are organized in three layers: test suite generation, extension, and user environment. "User environment" layer: It contains the tools customized to the specific production environments of the user. There is currently a plugin for the Eclipse development environment (IDE), starting with version 3.5. It contains the client application that captures the input domain information and displays the reduced language test suite or corresponding output artifact.
"Extension" layer: It contains the extensions developed for various input domains and output formats. This layer provides mechanisms to extend to other input domains and output formats. It contains the extensions of the CFG_ANTLRGeneration component of the "Test suite generation" layer:
CFG_ReqExt for descriptions of requirements such as input domain and
CFG_ANTLRGenerationExt for source code in Java language.
GeCodP that allows advanced users to use the extension mechanisms provided for the domain model, the test model and the execution model. It is the one in charge of communication with the rest of the components and the user environment.
TestCodeGeneration is an extension of the "Test suite generation" layer component that incorporates the generation of test code in new output formats.
"Test suite generation" layer: It is responsible for generating unit test cases regardless of input domain and output format. Contains the components:
CFG_ANTLRGeneration for the generation of the control flow graph from the input domain.
GeCaP for the generation of the reduced test suite using the GeVaUn, GeVaF and GeVaU components.
TestCodeGeneration for the transformation of the test suite in the different output codes.
Algorithms for generating independent paths from Java source code and for generating JUnit code from test cases were developed in [32]. These algorithms are included in the CFG_ANTLRGeneration and TestCodeGeneration components, respectively.
GeCaP encapsulates the interaction with the other components of the extension layer. The user environment layer integrates through interaction with GeCaP all the functionalities contemplated in the developed components. In this paper, it can be seen that the proposal implemented in the support tool generates a reduced set of values and, in addition, obtains the results in less time than the proposals consulted in the previous bibliographies.
The reduction model is in the central core, but connected to source code translators that allow transforming it to the reduction model, and the inputs of the reduction model can also be arranged for the generation of test code. This tool focuses on productive environments through client applications that can be developed. In particular, [33] presents a tool developed for the Eclipse environment that generates code in JUnit from source code in Java language and that contains translators to analyze this language.
MTest.search includes a specific optimization model for functional test reduction (MOPF) presented in [31] and extension mechanisms to incorporate new reduction models. In [34], an optimization model for unit test reduction (MOPU) is defined that includes only path coverage, without taking into account the importance of values and paths. The extension mechanisms to add new input and output languages are detailed in [33].
4. Materials and methods. Search-based reduction model for unit tests
The fundamental contribution of this work is the definition of an optimization model that allows generating reduced unit test suites, incorporating in [35] the significance of paths and input values. The GeVaU component presented in [36] implements the model proposed in this paper. This component was developed to generate combinations of values to perform unit tests (GeVaU) where the generated combinations take into account the independent paths of the unit to be tested.
The search process was defined, which is the generation of the initial solution, the operators, and the stop criterion. To generate the initial solution, it was decided to use a random construction of the initial state. Therefore, a vector of length equal to the number of variables in the problem is generated. The new solutions to the problem are generated from the use of operators. The mutation operator is used at one point. This operator consists of randomly selecting one, or two or three positions of the coded solution and changing its value for another randomly within the possible values that this variable can take. Unlike other proposals, this one takes into account white box design techniques.
The unit test search-based reduction model (MOPU) assumes the hypothesis that, if combinations of values are selected that have been chosen from the application of test case design techniques considering the significance of paths and input values, then the test suite will detect more errors. Therefore, a model is proposed that maximizes path coverage with a reduced number of combinations of test values, considering the significance of the values in terms of error detection. The optimization aims to find a reduced set of test values that maximize the coverage of the route and thus provide a possible solution to the combinatorial explosion problem.
From the search-based reduction model for tests in the article [31], the variables described below are maintained starting from:
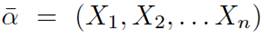 , vector containing the input variables or attributes but for the code to be tested;
, vector containing the input variables or attributes but for the code to be tested;
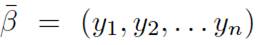 , vector containing the domain description of each attribute that belongs to
, vector containing the domain description of each attribute that belongs to
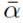 ;
;
C, level of coverage to be achieved;
n, number of input variables but for the code to test;
But since the proposal of this article works for unit tests with white box techniques, it is generated from the source code. Therefore, it is necessary to define the model with the incorporation of variables, functions, and a penalty mechanism as shown below:
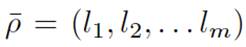 , vector containing the conditional statements present in the code to be tested;
, vector containing the conditional statements present in the code to be tested;
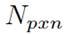 , matrix with the truth values of each conditional for each independent path of the code to be tested;
, matrix with the truth values of each conditional for each independent path of the code to be tested;
m, number of conditionals of the code to be tested;
p, number of independent paths of the code to be tested;
Then Equation (1) is redefined to add the significance of input values and paths:
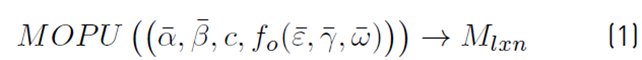
as the model by which the matrix is obtained
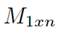 containing a test suite that satisfies the independent paths, with coverage criterion C.
containing a test suite that satisfies the independent paths, with coverage criterion C.
l: is the number of combinations to obtain in the generation of the test suit that satisfies the independent paths, with coverage criteria C.
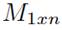 , is the matrix that contains the generated value combinations and where each row j corresponds to a vector
, is the matrix that contains the generated value combinations and where each row j corresponds to a vector
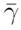 .
.
To include the path and input value significance criteria, the objective function was defined in Equation (2):
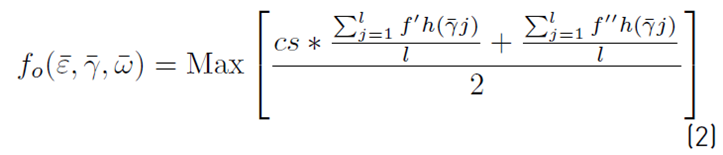
Where:
l: is the number of test cases of the suit.
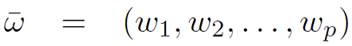 : is the vector with the significance of p independent paths.
: is the vector with the significance of p independent paths.
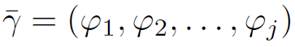 : is the vector containing the test suit.
: is the vector containing the test suit.
cs: is the path coverage of the test suite.
This function evaluates the test suite considering two heuristics:
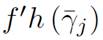 shown in Equation (3) y
shown in Equation (3) y
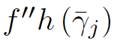 shown in Equation (4), for the significance of the paths and the input values respectively such that
shown in Equation (4), for the significance of the paths and the input values respectively such that
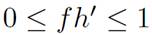 .
.
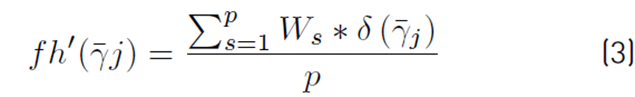

Where:
p: Total number of independent paths.
W
s
Path significance s, value between 0 and 1 such that
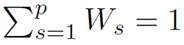 ,
,
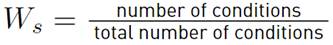
CT Total number of variables in the problem.
Equation (5) represents the number of conditionals within the path that are satisfied by combining values j, which was just generated.|

To generate the initial test suite, a penalty mechanism is used that guarantees that in this first suit all paths are satisfied with at least one test case. To do this, a penalty mechanism has been incorporated as part of the model, which is shown in Equation (6). If the new combination of values is such that:
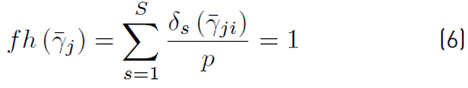
Then
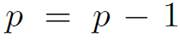 . The proposal presented in this paper reduces the input domains to discrete values using the transformation vector
. The proposal presented in this paper reduces the input domains to discrete values using the transformation vector
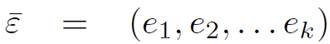 , similarly to [31]. The difference is that the transformation vector adds the condition and loop techniques to the existing ones.
, similarly to [31]. The difference is that the transformation vector adds the condition and loop techniques to the existing ones.
In addition to the existing components, a new GeVaUExt component was implemented that incorporates these new elements and extends GeVaU. In this new method, the change between the method that only considers the coverage of paths and the one that includes the significance of input values and paths can be observed.
5. Results. Application of the model by using the tools developed
The validation of the proposal is aimed at showing that the generated test suite has high levels of path coverage, that the test cases included in the generated suite contain the input values and paths with the highest levels of significance, and that the generated test suite is effective in detecting errors.
Two case studies and one experiment were designed. In the case studies, the quality of the generated test suite is evaluated in terms of the importance of the input values and paths in two applications of different complexity. The experiment evaluates the effectiveness in error detection of the proposal made in this article.
The case studies that were selected have different complexities and functionalities, in which an analysis is carried out considering the effectiveness of the implemented algorithms and the quality of the test set. For each case study, several suites are generated with GeVaUExt. In the first case, the inclusion of the most significant values is analyzed and in the second case, mutants are implemented that are executed with the generated suite to know the effectiveness in detecting errors. The results of the extension are compared against the results of the previous component.
Case study 1: Buy online
The case study is based on the fact that several customers can make purchases in online stores where they must register on the platform and then place several orders according to the quantity that exists in the store. For this case study, two functionalities were chosen. The description of each of the functionalities is as follows:
Reserving product request quantity, where the user may or may not successfully reserve a requested quantity depending on the actual quantity in the store.
Reporting the products in stock limits according to the minimum and maximum quantities.
The system generates significant values for each value of the variables by applying test case design techniques, depending on the equivalence class, according to the domain it belongs to. Some generated values are in the numeric domain and others are of type string.
Tables 1 and 2 show the conditions that describe the scenarios in the functionalities of reserving the number of products and reporting the products, respectively. Table 3 and 4 show the paths for each of the functionalities with their respective value (T, F, -) by condition, significance and expected result for each of the paths.
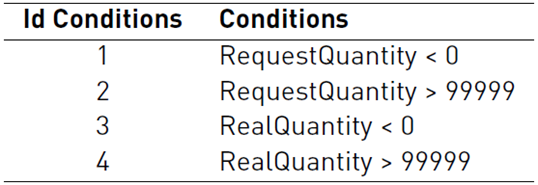
The case study has the following objectives:
To determine the effectiveness of the implemented algorithms to select the test cases with the most significant input values. For this, the following question is proposed.
Do the generated test suites contain the test cases with the most significant values?
To determine the effectiveness of the implemented algorithms to select the test cases for the most significant paths. For this, the following question is proposed:
Do the generated test suites contain a greater number of test cases associated with the most significant paths?
Case study 2: Classification of triangles
The functionality of the case study consists basically in classifying a triangle as scalene, isosceles, or equilateral, in addition to verifying whether or not the sides form a triangle. Tables 5 and 6 show the conditions and the paths with their values per condition.
The case study has the following objectives:
1. To determine the quality of the test suites generated by the implemented algorithms, in terms of the number of errors detected. For this, the following question is proposed: What percentage of mutants are killed by each suite generated by the implemented algorithms?
Five test suites were generated in five executions and with 2000 iterations for both functionalities using the implementations.
To answer the first question of the buy online case study: do the generated test suites contain the test cases with the most significant values?
The significant values of the paths were fixed with a value equal to 1.0 for both functionalities. Table 7 shows the number of times the values of the variables are repeated in each of the generated suits.
In this case, the values of greatest significance are 0 and 99999 with a significance of 1.0 for both variables that have a numerical domain. These values are contained in each of the test suites, having a higher frequency in most of the suits, and being very useful for error detection.
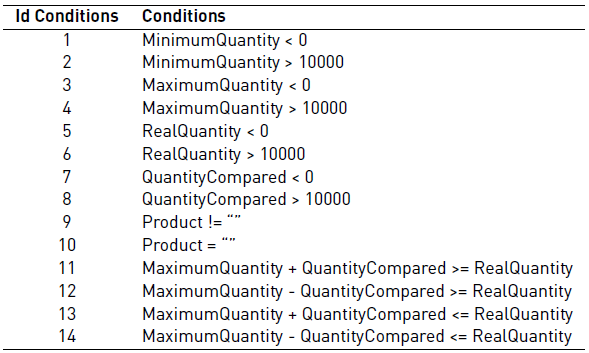
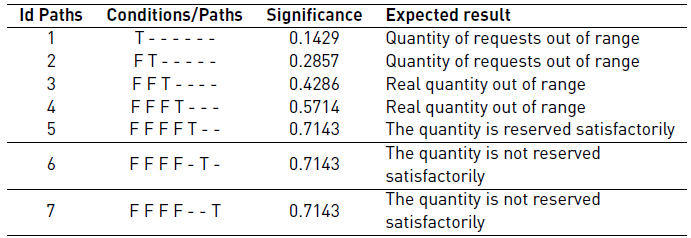
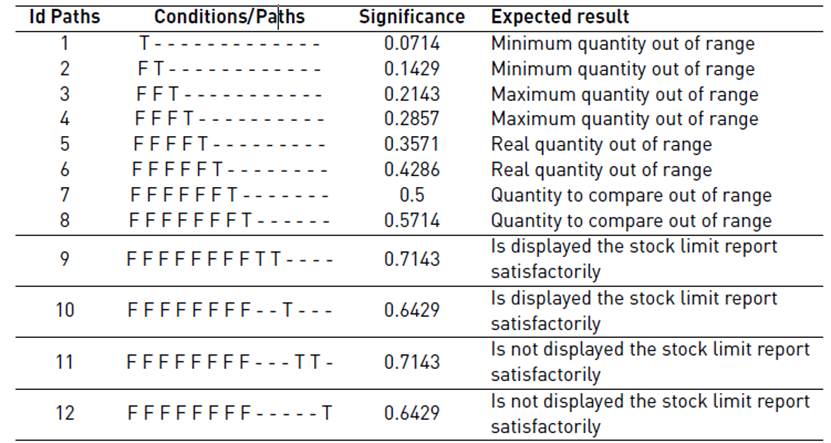

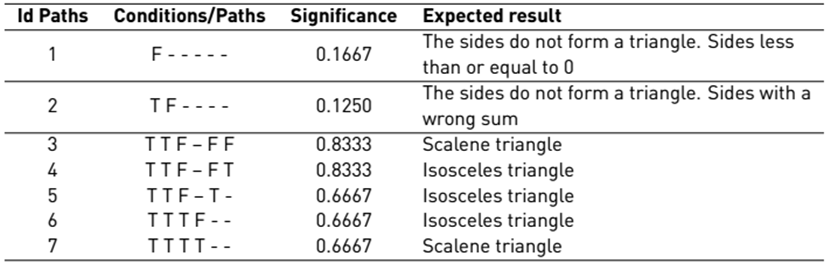
Table 7 Number of times the values are repeated in each test suit, setting a single significance value of the paths
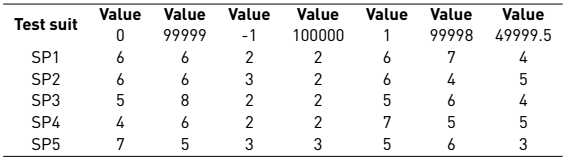
The values 99998 and 1 tend to be repeated more in the first and fourth suit, respectively; however, their significance is high with a value of 0.8 so it can also detect errors.
The value 49999.5, which has less significance, tends to have a higher frequency than -1 and 100,000 since both values can only be contained in test cases that cover the first four paths or scenarios because they are outside the range of 0 and 99999 by what the significant value of these values is not the correct one to obtain the test suit.
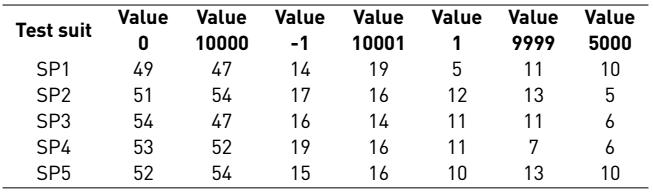
Table 8 shows the number of times the values of the variables are repeated in each test case.
The values of the variables with the numerical domain are shown, where the 0 and 10,000 that have the highest significant value equal to 1.0 are contained in the test cases of each of the test sets, with the highest number of repetitions. While the values of the string domain variable with a significant value equal to 1.0 are also contained in the test cases more frequently than the value with a significance equal to 0.7.
Answering the second question of the online purchase case study: Do the generated test suites contain a greater number of test cases associated with the most significant paths?
The significant values of all the values of variables with a value equal to 1.0 for the two functionalities were set. In the
Figure 2 shows the number of test cases covering each of the paths to reserve the number of products.
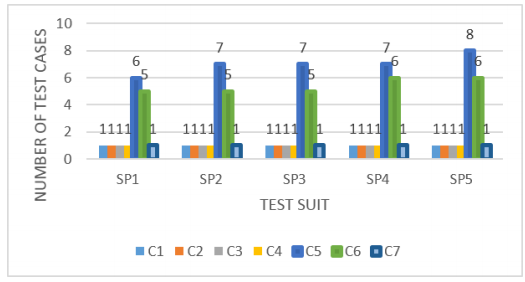
Figure 2 Number of test cases covered by each path to reserve the number of products by setting a single significance value of the input values
The most significant paths are 5, 6, and 7 whereas paths 5 and 6 are the ones that contain the most test cases.
Table 8 Number of times that the values are repeated to report the products in limits of existence, setting a single significance value of the paths
However, in path 7 it can only be covered by a single test case since the request quantity variable has to have a value less than or equal to 0, and in this case, the value it can always take is 0, otherwise, it is -1 so this is not in the range of 0 and 99999.
Figure 3 shows the number of test cases that cover each of the paths to report products at stock limits.
In the graph, it can be seen that the number of test cases in each path varies in each of the test suites. Path 9, which is more significant, contains more test cases in each of the generated suits. However, path 11, which also has the highest significant value, is one of the paths that contain the fewest test cases. This is because it is a path that can be covered by a few combinations given the conditions it must satisfy.
The experiment was designed, with five executions of the triangle classification algorithm, to answer the following question: What percentage of mutants kills each suite generated by the implemented algorithms?
The effectiveness of each test case was measured by applying the mutation technique. For this, 65 mutants were designed with the aim of executing the test suite generated with the proposed algorithms and determining their effectiveness in detecting errors in the mutated code.
The mutation operators used were: AOR (Substitution of an Arithmetic Operator) 27 mutants, LCR (Replacement of a Logical Connector) 4 mutants, UOI (Unique Operator Insertion) 23 mutants, ROR (Replacement of a Relational Operator) 10 mutants and SDL 1 mutant [36].
Subsequently, the test cases were generated, and coded in Junit and the tests were run on each of the mutants to analyze the number of dead mutants. When carrying out the analysis, it was found that all the test cases generated in the mutation kill at least one mutant. Therefore, it was considered to make a modification in the proposed algorithm by introducing other elements of coverage such as coverage of conditions, loops, and equivalence partition. After including the new coverage criteria with the extension, test suits were generated using the hill climber and genetic algorithms. The comparison gave the result that with the first proposal effectiveness greater than 80% was obtained and with the other two algorithms the effectiveness is greater than 95%. Table 9 shows the number of test values generated under different criteria.
Table 9 Number of different values generated by the component with the three implementations
| Variables | C1 | C2 | C3 | C4 | C5 | C6 |
| Side 1 | 13 | 6 | 6 | 12 | 11 | 13 |
| Side 2 | 13 | 5 | 11 | 9 | 11 | 12 |
| Side 3 | 15 | 6 | 9 | 11 | 12 | 14 |
Being:
C1: Total entry of values.
C2: Number of different values generated by the previous implementation.
C3: Number of different values with the hill climber with 20 test cases.
C4: Number of different values with the genetic algorithm with 20 test cases.
C5: Number of different values with the hill climber with 60 test cases.
C6: Number of different values with the genetic algorithm with 60 test cases.
As can be seen in Table 9, the improvements generate more combinations of test values than the previous version. This is due to the inclusion of coverage techniques that contain values contributed from the application of test case design techniques that had not been taken into account and are more effective for detecting errors. Therefore, it would be coherent to think about improving the proposed optimization model to include the significance of values in the detection of errors. More than one test case is generated for each path as the coverage criterion is expanded.
Figure 4 shows the original code that implements the triangle classification algorithm.
Figure 5 shows the mutated code, from the original code of the triangle classification algorithm, for the AOR operator.
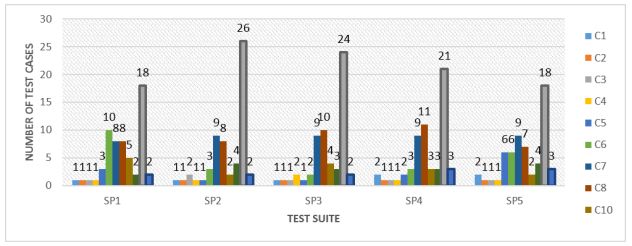
Figure 3 Number of test cases covered by each path to report products at limits of existence by setting a single significance value of the input values

Where it can be seen that the mutation is a change of the arithmetic operator of addition by division indicated in a circle.
Figure 6 shows the last mutant. Test cases from each of the suites were then run on the mutants. Table 10 shows the effectiveness of each of the suits.
The results show that the last test suit is better compared to the rest, with 100% effectiveness. However, despite the fact that the others are not 100% effective, they are still good at detecting errors since they managed to cover more than 95% of the errors inserted by the mutants.
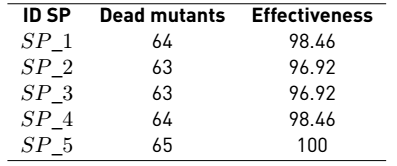


The above results were compared with the execution of the GeVaU shown in Table 11.
As can be seen, the test suites generated by GeVaUExt are much more effective than those generated by GeVaU.
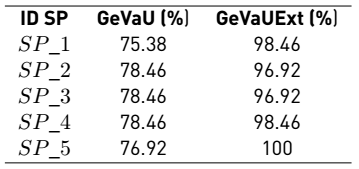
Having the highest percentage of effectiveness, it allows detecting a greater number of errors.
With the incorporation of the significance of the input values and the paths proposed in this work, it can be seen that the error coverage of the test cases of each of the suits is effective. This reveals a high ability to find errors. A suit of tests is obtained with the most significant values of the variables and a greater number of test cases are generated for the paths with the greatest significance.
6. Conclusions
This work presents a search-based optimization model for the generation of unit tests integrating different test case design techniques. The transformations of the test model to the extended model are exposed. The optimization model maximizes the coverage of the path with a reduced number of combinations of test values, considering the importance of the values in terms of error detection. Regarding coverage, compared to the results presented in the other bibliographies, this proposal improves the previous proposals since it guarantees that at least one test case is generated for each path. Better results are obtained in effectiveness, compared to this same proposal since there were no data from other bibliographies because the significance of the values is not taken into account. By including more test cases, a better chance of detecting more errors is guaranteed. If combinations of values are selected that have been chosen from the application of test case design techniques considering the significance of the input values and the paths, the test suite will detect more errors. For future work, it is recommended to continue evaluating the effectiveness of the generated suites and to make adjustments to the significance of the input values and the significance of the paths.

