










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Cited by Google
Cited by Google -
 Similars in
SciELO
Similars in
SciELO -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkSemestre Económico
Print version ISSN 0120-6346
Semest. Econ. vol.12 no.25 Medellín July/Dec. 2009
Predicciones de modelos econométricos y redes neuronales: el caso de la acción de SURAMINV*
Econometric and neural network model forecasts: the case of SURAMINV stock
Predições de modelos econométricos e redes neuronais: o caso a ação de SURAMINV
Jaime Enrique Arrieta Bechara**; Juan Camilo Torres Cruz***; Hermilson Velásquez Ceballos****
** Economista Universidad EAFIT, Medellín, Colombia. Magíster en Finanzas Universidad EAFIT, Medellín, Colombia. Jefe Mesa Derivados Valores Bancolombia. Teléfono 4042578, Medellín, Colombia. Correo Electrónico: jarriet1@eafit.edu.co
*** Economista del Desarrollo, Universidad Pontificia Bolivariana, Medellín, Colombia. Especialista en Ingeniería Financiera, Universidad Nacional de Colombia, Medellín, Colombia. Magíster en Finanzas Universidad EAFIT, Medellín, Colombia. Trader de divisas. Teléfono 2579154, Medellín, Colombia. Correo Electrónico: jtorres7@eafit.edu.co.
**** Licenciado en matemáticas, Universidad del Quindío, Armenia, Colombia. Magíster en Matemáticas Aplicadas Universidad EAFIT, Medellín, Colombia. Doctor en Ciencias Matemáticas Universidad Politécnica de Valencia, Valencia, España. Profesor de tiempo completo Universidad EAFIT, Medellín, Colombia. Miembro del grupo de investigación Simulación y Modelación Matemática (categoría D en Colciencias), Departamento de Ciencias Básicas de la Universidad EAFIT. Teléfono 2619500, Medellín, Colombia. Correo Electrónico: evelas@eafit.edu.co
Recibido: agosto 31 de 2009 Aprobado: diciembre 14 de 2009
Resumen
El objetivo del presente estudio radica en construir algunos modelos estadísticos, econométricos y de inteligencia artificial que permitan realizar predicciones sobre el comportamiento de mercado de la acción de SURAMINV (Suramericana de Inversiones S. A.). Se obtuvo evidencia a favor de la utilización de modelos econométricos y de inteligencia artificial construidos a partir de componentes principales, los cuales permiten lograr predicciones sobre el comportamiento diario de la acción de SURAMINV, contrastando la hipótesis de la teoría de eficiencia débil de mercado. El trabajo va más allá que otros desarrollados sobre el tema, en el sentido de que más que lograr un buen pronóstico in sample busca obtener resultados out of sample, controlando de esta manera la existencia de data snooping y, por tanto, suministrando información que puede ser aprovechada en estrategias de negociación.
Palabras Clave
Red neuronal artificial (RNA), inteligencia artificial, modelos econométricos, análisis de componentes principales (ACP), eficiencia de mercado.
Clasificación JEL C45; C51; C53; G11; G14; G17
Contenido
Introducción; 1. Marco teórico de los modelos; 2. Series de datos; 3. Resultados de predicción; 4. Conclusiones; Bibliografía.
Abstract
The purpose of this paper is to construct statistical, econometric and artificial intelligence models that permit market behavior forecasts of the SURAMINV stock. Evidence was found in favor of using econometric and artificial intelligence models constructed form main components that enable the daily behavior of the SURAMINV stock contrasting with the market's weak efficiency theory. The paper goes further than others that relate to the same topic in the sense that instead of looking for a good in sample forecast, it looks for out of sample results, controlling this way snooping data and therefore providing information that can be used in negotiation strategies.
Key Words
Artificial neural network (ANN), artificial intelligence, econometric models, main component analysis (MCA), market efficiency.
JEL Classification C45; C51; C53; G11; G14; G17
Content
Introduction, 1. Model theoretical frame; 2. Data series; .3 Forecast results; 4. Conclusions; Bibliography.
Resumo
O objetivo do presente estudo radica em construir alguns modelos estadísticos, econométricos e de inteligência artificial que permitam realizar perdições sobre o comportamento de mercado da ação de SURAMINV. Encontrou se evidencia a favor da utilização de modelos econométricos e de inteligência artificial construídos a partir de componentes principais, os quais permitem lograr predições sobre o comportamento diário da ação de SURAMIVN, contrastando a hipótese da teoria de eficiência débil de mercado. O trabalho vai mais ala que outros desenvolvidos sobre o tema, no sentido de que mais que lograr um bom prognóstico in sample, controlando assim a existência de data snooping e por tanto subministrando informação que pode ser aproveitada em estadísticas de negociação.
Palavras chave
Rede neuronal artificial (RNA), inteligência artificial, modelos econométricos, análise de componentes principais (ACP), eficiência de mercado.
Classificação JEL C45; C51; C53; G11; G14; G17
Conteúdo
Introdução; 1. Marco teórico dos modelos; 2. Series de data; 3. Resultados de predição; 4. Conclusões; Bibliografia
Introducción
La teoría de eficiencia de mercado es uno de los pilares del desarrollo moderno de las finanzas. Según esta teoría, y como lo explica Fama (1970), los precios de las acciones son el reflejo de toda la información disponible, por lo que ningún agente puede obtener retornos extraordinarios en los mercados de manera consistente.
Roberts (1967) distingue tres diferentes tipos de eficiencia en los mercados: débil, semifuerte y fuerte, las cuales se diferencian en el tipo de información con la que cuentan los agentes. La hipótesis de la eficiencia débil es que las series históricas del mercado, incluyendo precios, volúmenes y demás datos referentes a las transacciones, no poseen ningún tipo de información que pueda ser aprovechable por los agentes para obtener rendimientos extraordinarios de forma consistente. Según este planteamiento, no es posible predecir precios ni rendimientos futuros de los activos a partir de esta información.
El presente trabajo aborda el problema de la predictibilidad de los activos financieros, característica que ha sido estudiada prácticamente desde la misma fecha en la que empezaron los mercados en los que ellos se negocian. Sin embargo, se ha presentado un proceso de perfeccionamiento y sofisticación de las herramientas empleadas para dichas predicciones, que tiene hoy en día un amplio abanico de posibilidades para este fin. La literatura existente sobre predictibilidad en los mercados financieros y evaluación de estrategias de negociación es muy amplia, pero se pueden destacar en el campo internacional los estudios mencionados a continuación.
Hua y Yann (1996) desarrollan un modelo de redes neuronales recurrentes para hacer predicciones a mediano plazo del mercado accionario de Taiwán, usando entradas obtenidas del análisis ARIMA de las series objeto de estudio. Los resultados permitieron observar que entrenando la red con datos semanales con cuatro años de historia, se pueden obtener buenas predicciones del mercado en un horizonte de seis meses.
Fernández, González y Sosvilla (2000) desarrollan una regla de negociación para el índice general de la Bolsa de Madrid, utilizando redes neuronales y análisis técnico. Concluyen que dicha regla obtiene mejores rendimientos de forma consistente frente a una estrategia Buy y Hola1, mientras el mercado se encuentra estable o a la baja, pero que cuando el mercado se encuentra en tendencia alcista, la mejor estrategia es la pasiva. Por su parte, Chen, Leung y Daouk (2003) buscan modelar y predecir la dirección de los retornos del índice de la bolsa de acciones de Taiwán a través de estrategias de negociación con base en redes neuronales probabilísticas, obteniendo mejores rendimientos que la estrategia Buy y Hold.
Parisi, Parisi y Guerrero (2003) a través del uso de redes neuronales artificiales hacen predicciones de los cambios de signo semanales de los índices bursátiles Bovespa (Brasil), CAC40 (Francia), Dow Jones Industrial (Estados Unidos), FTSE100 (Reino Unido), GDAX(Alemania), Hang Seng (Hong Kong), KLS (Malasia), Nikkei225 (Tokio), STI (Tailandia) y S&P500 (USA), y encuentra que esta técnica presenta mayor poder predictivo sobre las series estudiadas frente a modelos ARIMA.
Álvarez y Álvarez (2003) utilizan algoritmos genéticos y redes neuronales para predecir los precios del yen y la libra esterlina. Adicionalmente, hacen una fusión de datos a través de la cual combinan los resultados obtenidos por ambos métodos con el fin de mirar la existencia de sinergias para mejorar los resultados en la predicción. Pese a lo sofisticado de las herramientas no se ve una mejora considerable en los resultados de predicción de tipos de cambio frente a trabajos anteriores.
Sallehuddin y otros (2007), proponen un modelo híbrido para la predicción de diferentes índices económicos y financieros asiáticos. El modelo propuesto es una combinación de redes neuronales tipo GRANN (Grey Relational Artificial Neural Networks) y un modelo lineal ARIMA. Obtienen como resultado que el modelo híbrido propuesto presenta una mejor predicción que los demás modelos con los que fue comparado.
La literatura sobre el tema con aplicación a mercados colombianos es también muy amplia; se destacan trabajos como Pantoja (2006), donde se realiza una comparación de resultados de predicción a partir de modelos ARIMA y redes neuronales para once series de precios de mercados colombianos; se obtiene evidencia de mejor desempeño en las redes, pero se detecta que en la presencia de estacionalidad los modelos ARIMA son muy potentes. Gil y Pérez (2005), por su parte, realizan una comparación entre un modelo tipo GARCH y uno de redes neuronales para la predicción de la acción de Acerías Paz del Río. Concluyen que por ser las redes modelos más flexibles y adaptables, se pueden considerar como una buena alternativa para la predicción de series de tiempo, pero, a su vez, los consideran más como un complemento a las técnicas tradicionales que como un reemplazo.
Pertuz (2005) estima y analiza modelos de series de tiempo y redes neuronales para la acción de Bavaria entre enero de 2002 y abril de 2005. Se utilizan modelos ARIMA y de redes neuronales con retardos y se concluye que estas últimas presentan un mejor desempeño. Jalil y Misas (2007) hacen una comparación en la predicción del tipo de cambio a través del uso de modelos de redes neuronales y de tipo lineal, y obtienen mejores resultados de predicción con los primeros.
Villada, Cadavid y Molina (2008) proponen un modelo de redes neuronales para el pronóstico del precio de la energía eléctrica colombiana. Las estructuras de redes utilizadas tienen como entradas las series de precios diarios y el nivel medio de los embalses. Se hace una comparación con un modelo tipo GARCH el cual muestra un mejor desempeño de pronóstico dentro de la muestra, pero se observa que fuera de la muestra las redes tienen mejor predicción.
Como se puede observar, existe una gran variedad de literatura sobre predicción de mercados a través de diferentes técnicas, y se puede concluir a favor o en contra de la teoría de eficiencia de mercado en forma débil. Este estudio pretende ampliar la discusión sobre el tema y otorgar nuevos criterios que permitan contrastar la teoría financiera en mercados colombianos.
Son muchos los trabajos realizados en los que se busca evaluar la eficiencia de los mercados, y hay conclusiones a favor y en contra de dicha teoría. Lo cierto es que en todo el mundo tiene mucha aceptación entre operadores de mercados financieros la implementación de estrategias que pretendan predecir comportamientos futuros a través de indicadores técnicos o modelos construidos a partir de las series históricas de las transacciones.
La divergencia existente entre la teoría y la práctica justifica la realización de trabajos de este tipo, en los que se busque evaluar la eficiencia de mercado en la negociación de activos específicos. Concretamente, es de gran relevancia evaluar la predictibilidad del comportamiento de la acción de Suramericana de Inversiones S. A. (SURAMINV) por ser la acción que lideró durante el período de estudio las negociaciones en la Bolsa de Valores de Colombia, al ser la de mayor participación en el Índice General de la Bolsa de Colombia (IGBC) y, a la vez, la de mayor volumen transado. El objetivo del trabajo radica entonces en construir modelos estadísticos, econométricos y de inteligencia artificial que permitan realizar predicciones sobre el comportamiento de mercado de la acción de SURAMINV.
En el trabajo se encontró evidencia de que por medio de la utilización de modelos econométricos y de inteligencia artificial, construidos a partir de componentes principales, se pueden lograr predicciones sobre el comportamiento diario de la acción de SURAMINV, contrastando la hipótesis de la teoría de eficiencia débil de mercado. El trabajo va más allá que otros desarrollados sobre el tema, en el sentido de que más que lograr un buen pronóstico in sample busca obtener resultados out of sample, controlando de esta manera la existencia de data snooping y por tanto suministrando información que puede ser aprovechada en estrategias de negociación.
El presente artículo se divide en cinco partes, incluyendo esta introducción. Luego, en la primera sección, se hace referencia al marco conceptual de los modelos utilizados en el trabajo, haciendo especial énfasis en el soporte teórico de las redes neuronales artificiales por ser un método relativamente nuevo en nuestro medio. En la segunda parte del artículo se explican los criterios de selección, el origen y el tratamiento de los datos con los que se alimentan los modelos. Las secciones tercera y cuarta recogen, respectivamente, los resultados y análisis obtenidos de las estimaciones realizadas y las conclusiones y principales resultados.
1. Fundamentos teóricos y conceptuales de los modelos
En la presente sección se recoge el marco conceptual de los modelos utilizados para la elaboración del trabajo, empezando por el análisis de componentes principales (ACP) como procedimiento para el tratamiento de los datos de entrada y luego abordando los modelos econométricos y las redes neuronales como métodos de predicción.
1.1 Análisis de componentes principales (ACP)
El ACP es una herramienta estadística propuesta inicialmente por Pearson (1901) y es ampliamente utilizada para resumir la información de un conjunto de series y utilizarla como entradas de modelos econométricos o de inteligencia artificial. El objetivo de este análisis es obtener a partir de una muestra de p variables, X1, X2, ..., Xp, un número k≤ p de nuevas variables o componentes principales Z1, Z2, ..., Zk, que estén incorrelacionadas y expliquen la mayor parte de la variabilidad de las variables de entrada iniciales.
El proceso para obtener la primera componente principal parte de la expresión de la misma como combinación lineal de las variables originales:
Z1i, = u1, X11, u12, X2i, + ... + u1p, Xp1, (1)
La información del sistema de ecuaciones al representar la información para cada observación i = 1, 2, ..., n se puede recoger en forma matricial como:
Procediendo de manera similar al caso univariado tenemos que:
V(Z1) = E(Z1 - E(Z1))2 = E(Z21 ) = E(Z'1 Z1) = E[([XU1)]' XU1] = E(U' 1 X' X U) (3)
Por el principio de analogía:
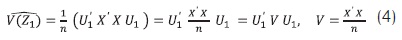
El problema de optimización a resolver en cada componente principal es:
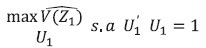 (5)
(5) Sea λ el multiplicador de lagrange y consideremos:
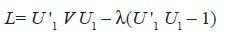 (6)
(6)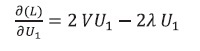 (7)
(7)La ecuación (7) es la derivada de una forma cuadrática.
Utilizando las condiciones de primer orden para la optimización:
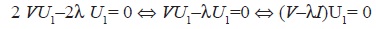 (8)
(8)Si descartamos la solución trivial U1= 0 se requiere que det(V - λI) = 0, siendo entonces un problema de determinación de las raíces características, tomando como solución aquella que corresponda al mayor valor propio de acuerdo con el objetivo planteado en el problema de optimización. Para encontrar las otras componentes se sigue el mismo proceso descrito. La forma de establecer el número de componentes a retener y de obtener las puntuaciones es abordada ampliamente en la literatura de análisis multivariado, como es el caso de los trabajos de Jolliffe (2002), Roweis (1998) y Uriel y Aldás (2005).
1.2 Modelos de regresión múltiple
Los modelos de regresión múltiple para la identificación de patrones o relaciones entre conjuntos de datos han estado durante mucho tiempo dentro de las herramientas más empleadas en trabajos de predicción debido a su amplia aceptación científica. Es mucha la literatura existente sobre el desarrollo teórico y matemático de este tipo de modelos e igualmente sobre su aplicación en series financieras, y son por estas razones muy conocidos en el medio académico. Dadas estas condiciones, se considera que no es necesario entrar a detallar nuevamente la teoría de estos modelos, como sí se hará con las redes neuronales artificiales. Sin embargo, es importante mencionar que la investigación fue muy rigurosa en cuanto al cumplimiento de todos los supuestos teóricos que exigen los modelos econométricos. Los modelos econométricos utilizados, al incluir en su especificación series de tiempo, fueron desarrollados teniendo en cuenta los supuestos generales que permiten no tener regresiones espurias, como efectivamente se evidencia en el trabajo.
Algunos de los trabajos en los que se profundiza sobre este tipo de modelos son Engle, Robert y Granger (1991), Mills (1993), Hamilton (1994), Johansen (1995), Hendry (1995), Lutkepohl y Kratzig (2004), Lutkepohl (2005) y Juselius (2008).
1.3 Redes neuronales artificiales (RNA)
De acuerdo a McNelis (2005), como los métodos de aproximación lineal y polinomial, una red neuronal es un método que por medio de un conjunto de algoritmos busca establecer la relación entre un conjunto de variables de entrada, {xi}, i = 1, ..., n con un conjunto de una o más variables de salida, {yi}, j = 1, .., k. La diferencia de la red con los otros métodos de aproximación consiste en que esta usa una o más capas ocultas, en las que las variables de entrada van siendo transformadas y comprimidas por una función especial. Tal como lo resaltan Acosta, Salazar y Zuluaga (2000), la red representa la forma en la que el cerebro humano procesa datos de entrada sensoriales, recibidos como neuronas de entrada, hasta el reconocimiento como neuronas de salida.
Las redes feedforward son las más usadas en aplicaciones de economía y finanzas. Se caracterizan porque los datos se transmiten de las neuronas de capas anteriores a las de capas posteriores: un conjunto de información de entrada va siendo procesado por las diferentes neuronas de la red para establecer la relación con la variable de salida. La figura 1 ilustra la arquitectura de una red neuronal feedforward con una capa oculta de dos neuronas, tres variables de entrada {xi}, i = 1,2,3, y una Salida, y.
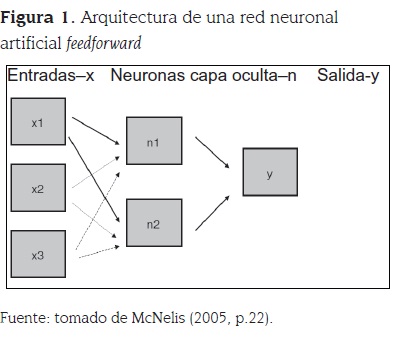
Las capas ocultas se pueden interpretar como el procesamiento que realizan los agentes de toda la información económica y financiera conocida, con el fin de formar sus expectativas hacía el futuro. Este procesamiento en el cerebro de los agentes, representado en las transformaciones realizadas en las capas ocultas de la red, es el que conduce a reacciones y a tomar decisiones en los mercados en los que realizarán compras o ventas.
Las neuronas procesan los datos de entrada de dos formas: primero haciendo combinaciones lineales de los datos de entrada y luego procesando esas combinaciones por medio de funciones de activación o transferencia. Las funciones más comunes en economía y finanzas son las no lineales compresoras, las cuales reportan salidas no proporcionales a las entradas y son, además, las que mejor representan el comportamiento económico de los agentes. Por su parte, para la capa de salida la función de transferencia más usada es la lineal por ser continua para todos los reales, arrojando como resultado exactamente el mismo valor de la entrada neta que le llega y, por tanto, siendo equivalente a no aplicar función de transferencia.
Una de las funciones de activación compresora más usadas en este tipo de trabajos es la tangente hiperbólica, también conocida como la función tansig o tanh, la cual comprime las combinaciones lineales de las entradas en el rango comprendido entre -1 y +1 y está representada matemáticamente por:
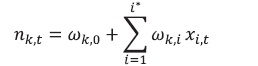 (9)
(9)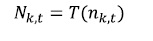 (10)
(10)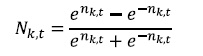 (11)
(11)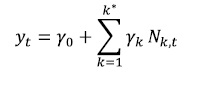 (12)
(12)Donde T(nk,t) es la función de activación tansig para la neurona de entrada nk,t.
En los problemas de predicción económica o financiera, se utiliza normalmente el algoritmo de entrenamiento backpropagation por las virtudes que posee, ya que es capaz de resolver problemas que no son linealmente separables, reduce el tiempo de entrenamiento de la red por la utilización del procesamiento paralelo para encontrar la relación entre patrones dados y no necesita la especificación de un algoritmo por anticipado para llegar al algoritmo correcto. Estas ventajas están ampliamente documentadas en la literatura, donde resaltan autores como Wong (1995) y Yao, Li y Tan (1997).
Backpropagation es un aprendizaje con un mecanismo de propagación-adaptación en dos fases: la primera consiste en entrar un determinado patrón y propagarlo por todas las capas de la red hasta llegar a una salida, la cual es comparada con la salida que se desea obtener, determinando un término de error. Este término de error inicia la segunda fase, ya que se convierte en una señal que se propaga hacia atrás, actualizando todos los pesos de la red.
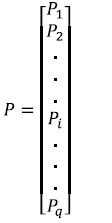
Asumiendo una red de una sola capa oculta para efectos de ilustración, el proceso de entrenamiento parte de ingresar a la red un patrón p de entrenamiento de q componentes:
 (13)
(13)La salida final en función de la entrada neta y de los pesos de la última capa estaría dada por:
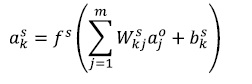 (14)
(14)La salida final de la red se comparará con su valor deseado tk para determinar el error de cada unidad de salida:
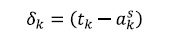 (15)
(15)El error de cada patrón ingresado a la red estará dado entonces por:
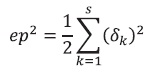 (16)
(16) Donde ep2 es el error medio cuadrático para cada patrón de entrada p y δk es el error en la neurona k de la capa de salida con l neuronas.
El proceso que se acaba de describir debe ser repetido para el número total de patrones de entrenamiento (r) y luego minimizar el error medio cuadrático total descrito por:
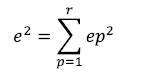 (17)
(17) Donde e2 es el error en el proceso de aprendizaje en una iteración, después de haber ingresado los r patrones a la red.
El error originado en función de los pesos genera un espacio de n dimensiones, donde n se refiere al número de pesos de la red. Al tratar de minimizar este error en el proceso de aprendizaje, se tomará la dirección del gradiente negativo del error en esta superficie, es decir, aquella dirección en la que el error decrece, ya que este es el criterio para la actualización de los pesos:
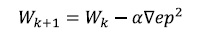 (18)
(18)El gradiente negativo de ep2 se denotará como -Vep2 y se calcula como la derivada del error respecto a los pesos de conexión de toda la red.
Se puede demostrar que los términos de error para la capa de salida estarán dados por:
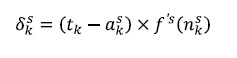 (19)
(19)Este algoritmo es llamado Backpropagation o de propagación inversa por el hecho de que el error se propaga hacía atrás en la red. Por su parte, el error en la capa oculta estaría dado por:
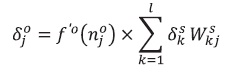 (20)
(20)Con el valor del gradiente del error se actualizan todos los pesos de la red empezando por los de la capa de salida:
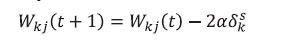 (21)
(21)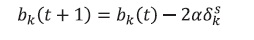 (22)
(22)Donde α es la tasa de aprendizaje que varía entre 0 y +1.
Después de actualizar los pesos y ganancias de la capa de salida se hace el mismo proceso con la capa oculta, terminado así el proceso de actualización de pesos con base en los errores en una red de tres capas:
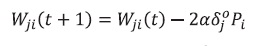 (23)
(23)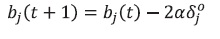 (24)
(24)Las expresiones para generalizar este proceso a una red de más capas se pueden deducir fácilmente de la ecuación (20).
2. Series de datos empleadas en el estudio
Las selección de las series de datos históricos empleadas para el estudio fue realizada teniendo en cuenta los fundamentales macroeconómicos y las relaciones entre mercados financieros que han sido ampliamente documentadas en diversos trabajos como los de Chen, Firth y Rui (2002) y Phylaktis y Ravazzolo (2005). Además, fueron tenidos en cuenta como criterios la disponibilidad de los datos en la periodicidad requerida y el conocimiento de los investigadores sobre el funcionamiento del mercado financiero colombiano.
El conjunto de variables se presenta en el anexo A y consta de 77 variables, expresadas en términos de precios desde el 21 de junio de 2002 hasta 11 de marzo de 2008 (1493 datos). En la figura 2, que presenta la serie de precios de la acción de SURAMINV para el período de estudio.
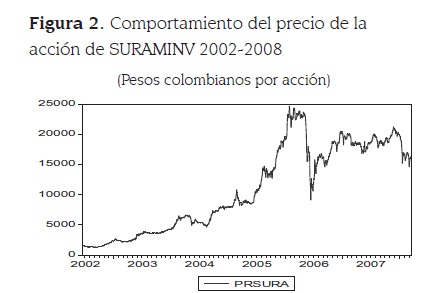
Para cumplir con los supuestos formales de algunos de los procesos utilizados en la construcción de los modelos, las 77 variables inicialmente seleccionadas se sometieron a un proceso de estandarización por el hecho de tener diferentes escalas. El nuevo conjunto de datos estandarizado fue sometido al análisis de componentes principales (ACP), y se logró reducir el conjunto de entrada a 5 componentes principales en el caso de los precios, los cuales explican el 93,89% de la variabilidad total de los datos. Por su parte, al realizar el mismo proceso para las 77 series de rendimiento, se reduce el conjunto de información a 21 componentes principales con una explicación de la variabilidad inicial de 65,53%.
El paso siguiente en la organización de los datos es la división de la muestra, para obtener dos subconjuntos: uno para la estimación del modelo (in sample) y otro que no interviene en la estimación y que se utiliza para la prueba (out of sample). Aunque se probaron varias divisiones de la muestra para el entrenamiento de los modelos, se obtuvieron mejores resultados con la separación 83% inicial para entrenamiento y 17% para prueba. Por último, como lo recomiendan Yao y Tan (2000), fue necesario subdividir cada una de las muestras para estimación de estos modelos in sample en tres grupos: entrenamiento, validación y prueba.
3. Resultados de las predicciones
Se estimaron modelos de regresión múltiple a partir de los componentes principales de los precios y rendimientos. Como se mencionó previamente, el hecho de que los modelos estén siendo estimados sobre componentes principales garantiza que las variables de entrada cumplan con las condiciones exigidas por los supuestos teóricos sobre los que se construyen este tipo de modelos, además de evitar que se ingrese información redundante a los mismos y que se obtengan regresiones espurias.
La tabla 1 presenta los resultados de la estimación para el caso de las 5 componentes principales de los precios, mostrando que todas estas resultan ser estadísticamente significativas. Además, se incluyen procesos AR(1), MA(1) y MA(6), los dos primeros interpretados como la influencia de la sesión anterior de mercado en la sesión actual, y el MA(6) por su parte podría asociarse al “efecto día de la semana”2 que se presenta en los mercados.3
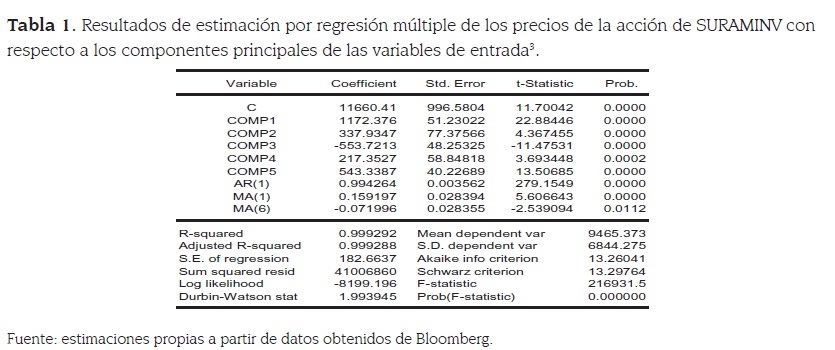
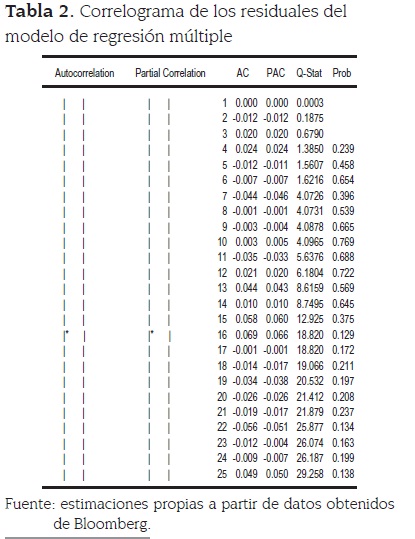
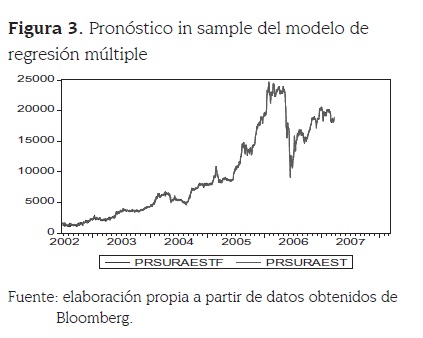
El R-cuadrado obtenido en la estimación es 0.999292, lo cual está indicando muy buen ajuste dentro de la muestra4. Es importante mencionar que a pesar de que parece existir un cambio de régimen en el mercado a partir de la caída de los precios observada a mediados del 2006, el modelo logra capturar casi la totalidad de la dinámica que presenta la serie dentro de la muestra. Además, hay que resaltar que los residuales de la estimación, tal como se muestra en el correlograma presentado en la tabla 2, son ruido blanco, por lo que se puede descartar la posibilidad de relaciones espurias o problemas de estimación, a pesar de estar trabajando con precios. El análisis del ajuste in sample permite concluir que la estimación por regresión múltiple tiene un muy buen desempeño dentro de esta parte de los datos, ya que como se observa en la figura 3, captura adecuadamente la dinámica de la serie.
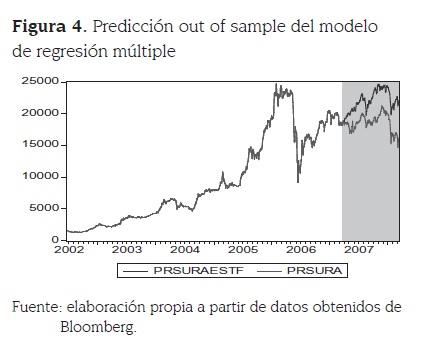
Cuando se extiende el análisis anterior a los datos out of sample se puede observar que a pesar de no existir un buen ajuste, lo cual se refleja en el coeficiente R-Cuadrado calculado que presenta un valor de 0.3593, se logra capturar algo de las tendencias de corto plazo de la serie de precios. El área sombreada de la figura 4 contrasta la predicción out of sample del modelo con los datos reales.
Al estimar modelos de regresión múltiple de los rendimientos de SURAMINV con respecto a las 21 componentes principales obtenidas a partir de las series de rendimientos, se observaron resultados de estimación con una capacidad mucho menor de pronóstico in sample y predicción out of sample.
Para abordar el problema de predicción por medio de las redes neuronales es necesaria la optimización del error de estimación a través de la comprobación de diferentes estructuras, número de capas, número de neuronas por capa, tipo de funciones de transferencia, aprendizaje y entrenamiento. La realización de este proceso implicó el entrenamiento de cientos de redes, por lo que tiene gran importancia la utilización de algoritmos que sean eficientes desde el punto de vista de los tiempos computacionales.
El entrenamiento a partir de las 5 componentes principales de las series de precios permitió obtener modelos con buen desempeño en términos de predicción; se destaca que los mejores resultados se obtuvieron con una estructura de una capa oculta de 16 neuronas, en la que se emplea la función de transferencia tansig, y una neurona en la capa de salida que trabajan con la función purelin. A la vez, esta red utiliza la función de gradiente descendiente con momento para el aprendizaje y el algoritmo Levenberg-Mardquart para el entrenamiento.
La tabla 3 resume los estadísticos de evaluación de este modelo, cuyas ecuaciones se pueden observar en el anexo B. Es importante resaltar que se obtuvo un excelente ajuste in sample y que a la vez se captura la dinámica out of sample de los datos reales. Igualmente, se mejora de forma importante el ajuste a los datos fuera de muestra con respecto a los resultados obtenidos por medio de la regresión múltiple. Esto se evidencia en el coeficiente R-cuadrado calculado, el cuál presenta un valor de 0.5493.
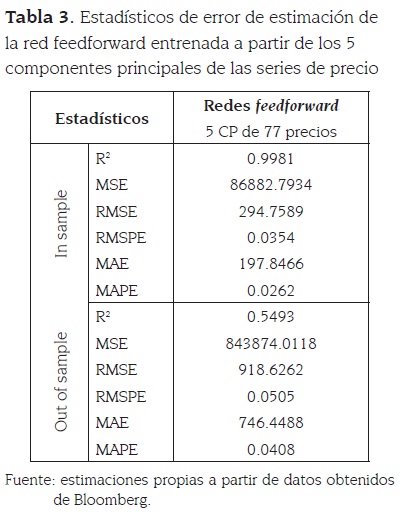
La figura 5 presenta en el área sombreada la predicción fuera de muestra del modelo y los datos verdaderamente observados, y resalta que tal como lo muestran los estadísticos de evaluación, se logra capturar gran parte de la dinámica de la serie.
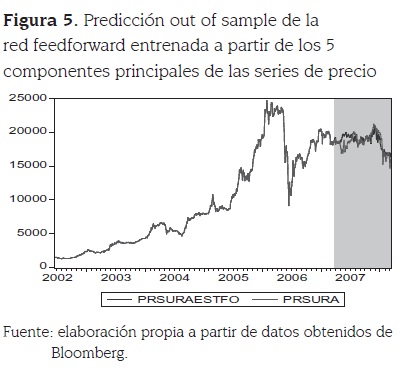
La evaluación de los residuales del modelo se realizó por medio de la prueba de raíces unitarias Dickey-Fuller aumentada sin intercepto y sin tendencia, y se obtuvo que las probabilidades se ubican en la región de rechazo de la hipótesis nula de existencia de raíces unitarias por lo que no hay evidencia empírica que muestre falta de estacionariedad en los residuales.
De manera similar que en los modelos de regresión múltiple, los resultados obtenidos al modelar los precios fueron muy similares a los observados cuando se buscó predecir rendimientos.
4. Conclusiones
La investigación permitió contrastar la teoría de eficiencia débil de mercado en la acción de Suramericana de Inversiones S. A. (SURAMINV), acción líder en el mercado bursátil colombiano dentro del período considerado para el estudio: junio 2002- marzo 2008. En términos generales se obtuvo que en este mercado, contrario a la hipótesis defendida por esta teoría, sí es posible hacer buenas predicciones. El trabajo fue más allá que muchos otros de su estilo en el sentido en que, además de lograr un buen pronóstico in sample, demuestra que es posible obtener buenas estimaciones del comportamiento de la acción out of sample y, por tanto, evalúa de manera más confiable la verdadera posibilidad de aprovechamiento financiero de los resultados.
Partiendo de 77 variables expresadas en términos de precios y rendimientos logarítmicos, se empleó el análisis de componentes principales para reducir el tamaño de la muestra, evitar la utilización de información redundante y garantizar el cumplimiento de las condiciones exigidas por los supuestos teóricos de algunos de los modelos trabajados. Los datos disponibles fueron divididos en dos grupos buscando controlar la posibilidad de data snooping: el primero, in sample, se usa para el ajuste de los modelos y el segundo, out of sample, que no interviene en el entrenamiento, se emplea para evaluar la capacidad predictiva de los modelos.
La evidencia empírica del trabajo dejó claramente expuesta la superioridad de los modelos construidos para la predicción de precios sobre los de rendimientos. Aunque este es un resultado esperado, es importante resaltar que la diferencia en cuanto a poder de predicción es muy significativa en la medida en que los modelos construidos sobre retornos no capturan de forma adecuada la dinámica de los datos out of sample. El trabajo con precios no representa una dificultad si se tiene en cuenta que a partir de una buena predicción de los mismos se pueden obtener retornos aprovechables desde el punto de vista financiero. Además, al trabajar con precios es importante mencionar que para la construcción de los modelos se aplicó toda la rigurosidad que exige el desarrollo teórico de cada uno de ellos, teniendo especial cuidado en evitar que los resultados sean el reflejo de relaciones espurias.
La modelación a través de regresión múltiple de los precios de la acción con respecto a sus componentes principales arrojó como resultado un buen ajuste in sample. Sin embargo, al hacer la evaluación de la predicción out of sample, se observó que aunque se captura la dinámica de la serie real, sigue existiendo una brecha de ajuste muy importante.
Los resultados de las redes muestran que al igual que en el caso de los modelos econométricos, se logra capturar adecuadamente la dinámica de los datos in sample. Sin embargo, en las predicciones de precios se observa un notorio avance respecto al desempeño de los modelos fuera de la muestra en el sentido en que se logra capturar la dinámica de la serie real mucho mejor que con los modelos econométricos y, a la vez, se mejora considerablemente el ajuste. La red con mejor desempeño fue la feedforwad alimenta con las 5 componentes principales de los precios, cuyos resultados superan a los de todos los otros modelos empleados en el estudio.
Bibliografía
1. Acosta B, María Isabel, Salazar I., Harold Y Zuluaga, Camilo (2000). Tutorial de redes neuronales. [En línea] Universidad Tecnológica de Pereira, Facultad de Ingeniería Eléctrica. Pereira, Colombia. Disponible en: http://ohm.utp.edu.co/neuronales/main.htm. [Consultado el 15 de Enero de 2009] [ Links ]
2. Álvarez, M. Y Álvarez, A. (2003). Predicción no lineal de tipos de cambio: algoritmos genéticos, redes neuronales y fusión de datos. Documentos de trabajo, Universidad de Vigo. N.1. [ Links ]
3. Chen, Gongmeng; Firth, Michael y Rui, Oliver (2002). Stock market linkages: evidence from Latin America. En: Journal of Banking & Finance, Vol. 26, No 6, p. 1113-1141. [ Links ]
4. Chen, A. S., Leung, M.T. y Daouk, H. (2003). Application of neural networks to an emerging financial market: forecasting and trading the Taiwan Stock Index. En: Computers & Operations Research, Vol. 30, No. 6, p. 901-923 [ Links ]
5. Engle, Robert y Granger, Clive (1991). Long run economic relationships readings in cointegration. Oxford University Press, 312p. [ Links ]
6. Fama, Eugene F. (1970). Efficient capital markets: a review of theory and empirical work. En: Journal of Finance, American Finance Association, vol. 25, N.2 , p. 383-417. [ Links ]
7. Fernández, F.; González, C. y Sosvilla, S. (2000). On the profitability of technical trading rules based on artificial neural networks: evidence from the Madrid stock market. En: Economics Letters, Elsevier, Vol. 69, No 1, p. 89-94. [ Links ]
8. Gil Zapata, Martha y Pérez Ramírez, Fredy (2005). Análisis y predicción de la acción de la empresa Acerías Paz del Río utilizando un modelo GARCH y redes neuronales artificiales. En: Revista Ingenierías, Universidad de Medellín, Medellín, Vol. 4, No 7, p. 83-97. [ Links ]
9. Hamilton, James (1994). Time series analysis. Princeton University Press, 820p. [ Links ]
10. Hendry, David (1995). Dynamic econometrics. Oxford University Press, 904p. [ Links ]
11. Hua, J., Yann, Y. (1996). Stock market trend prediction using ARIMAbased neural networks. En: International Conference on IEEE. Vol. 4, N o 3-6, p. 2160-2165. [ Links ]
12. Jalil, A. Y Misas, M. (2007). Evaluación de pronósticos del tipo de cambio utilizando redes neuronales y funciones de pérdida asimétricas. En: Revista Colombiana de Estadística, Vol. 30 No 1, p 143-161. [ Links ]
13. Johansen, Soren (1995). Likelihood - based inference in cointegrated vector autoregressive models. Oxford University Press, 280p. [ Links ]
14. Jolliffe, I.T. (2002). Principal Component Analysis. 2a ed., New York, Springer, 502p. [ Links ]
15. Juselius, Katarina (2008). The cointegrated VAR model. Oxford University Press, 477p. [ Links ]
16. Lutkepohl, Helmut (2005). New Introduction to Multiple Time Series Analysis. Springer, 764p. [ Links ]
17. Lutkepohl, Helmut y Kratzig, Markus (2004). Applied Time Series Econometrics. Cambridge University Press, 352p. [ Links ]
18. Mcnelis, Paul D. (2005). Neural networks in finance: gaining predictive edge in the market. Londres, Elsevier Academic Press. 233p. [ Links ]
19. Mills, Terence (1993). The econometric modelling of financial time series. Cambridge University Press, 384p. [ Links ]
20. Muirhead, Robb J. (1982, 2005). Aspects of Multivariate Statistical Theory. New Jersey. Jhon Wiley & Sons, 704p. [ Links ]
21. Pantoja, María (2006). Analysis of time series forecasting with neuronal networks, ARIMA models and GARCH process for non stationary time series. Departmento de Engineria Industrial, Universidad de los Andes, Bogotá D.C. [ Links ]
22. Parisi, A. Parisi, F. y Guerrero, J. L. (2003). Redes neuronales en la predicción de índices accionarios internacionales. En: El trimeste Económico, No 70, p 721-744. [ Links ]
23. Pertuz, J. (2005). Modelos para pronosticar series de tiempo financieras con redes neuronales Backpropagation dependiente del tiempo. Seminario Día Matlab, Ponencia #2, UDES. Noviembre. [ Links ]
24. Pearson, K. (1901). On Lines and Planes of Closest Fit to Systems of Points in Space. En: Philosophical Magazine, Vol. 2, No 6, p. 559-572. [ Links ]
25. Phylaktis, Kate y RAVAZZOLO, Fabiola (2005). Stock market linkages in emerging markets: implications for international portfolio diversification. En: Journal of International Financial Markets, Institutions and Money, Vol. 15, No 2, p. 91-106. [ Links ]
26. Roberts, H. (1967). Statistical versus clinical predictions of the stock markets. Unpublished manuscript. Center for Research in Security Prices, Chicago, University of Chicago, mayo, s.p. [ Links ]
27. Roweis, Sam (1998). EM Algorithms for PCA and SPCA. Advances in Neural Information Processing Systems. Denver, The MIT Press, p 626-632 [ Links ]
28. Sallehuddin, R. Hj., Shamsuddin, S. M., Mohd Hashim, S. Z. y ABRAHAM, Ajith (2009). Forecasting time series data using hybrid grey relational artificial neural network and auto regressive integrated moving average. En: Applied Artificial Intelligence, Vol. 23 No 5, p. 443-486. [ Links ]
29. Uriel, Ezequiel y Aldás, Joaquín (2005). Análisis multivariante aplicado. Madrid, Thomson Paraninfo. 531p. [ Links ]
30. Villada, F., Cadavid, D. y Molina, J. (2008). Pronóstico del precio de la energía eléctrica usando redes neuronales artificiales. En: Revista facultad de ingeniería, Universidad de Antioquia, No 44, junio, p. 111-118. [ Links ]
31. Wong, Bo Kai (1995). A bibliography of neural network business application research: 1988-September 1994. En: Expert Systems No 12, Vol. 3. [ Links ]
32. Yao J., Li, Y. y Tan, C. (1997). Forecasting the exchange rates of CHF vs USD using neural networks. En: Journal of Computational Intelligence in Finance, Vol.2, No 5, p. 7-13. [ Links ]
33. Yao, J. y Tan, C. (2000). A case study on using neural networks to perform technical forecasting of Forex. En: Neurocomputing, No 34, p. 79-98. [ Links ]
* Este artículo es producto del trabajo de la tesis titulada “Predicción del comportamiento diario de la acción de SURAMINV: redes neuronales y modelos econométricos”, la cual fue presentada para obtener el título de Maestría en Finanzas de la Universidad EAFIT, Medellín, Colombia: realizado en el período enero-agosto de 2009, el cual fue financiado por la Universidad EAFIT.
1 Estrategia de inversión pasiva consistente en comprar activos financieros y mantenerlos por largos períodos de tiempo, sin importar las fluctuaciones de corto plazo de los precios de mercado. Esta estrategia está fundamentada en la expectativa de muchos agentes de que en el largo plazo los mercados financieros generan buenas tasas de retorno sin importar las variaciones o volatilidad de corto plazo.
2 Esta interpretación no fue tomada de otro trabajo y no corresponde con lo que algunos autores interpretan por el efecto día de la semana, en este caso hace referencia a los choques aleatorios que se presentan durante un día de la semana se reflejan en la semana siguiente, ya que los agentes durante esa semana han entendido las razones de ese choque.
3 En la tabla 1 se observa que el coeficiente del AR(1) es muy cercano a 1, indicando que posiblemente hay problemas de estacionariedad. También se observa en esta tabla que la suma de residuales al cuadrado es muy grande. En las regresiones con variables que son series de tiempo uno de los aspectos importantes a tener en cuenta es la posibilidad de una regresión espurea. En este caso se seguio la propuesta de ENGLE y GRANGER y se determino que esta regresión no tiene ese problema. Las componentes principales utilizadas son variables estacionarias y por tanto tampoco existe la posibilidad de cointegración.
4 Es importante reconocer que este criterio solo no es un buen indicador de ajuste, por lo cual se decidió poner a prueba esta evidencia de buen ajuste empleando la diferencia entre lo observado y lo pronosticado sea ruido blanco, lo que indico que efectivamente la bondad del ajuste del modelo.

